In dit bericht gaan we kijken naar de meest gebruikte machine learning algoritmen. Er is een enorme verscheidenheid aan algoritmen, en het is gemakkelijk om in de war te raken als je termen hoort als “instance-based learning algorithms” en “perceptron”.
Normaal gesproken worden alle machine learning algoritmen ingedeeld in groepen op basis van ofwel hun leerstijl, functie, of de problemen die ze oplossen. In dit bericht vindt u een classificatie op basis van leerstijl. Ik zal ook de veelvoorkomende taken noemen die deze algoritmen helpen oplossen.
Het aantal machine learning algoritmen dat vandaag de dag wordt gebruikt is groot, en ik zal niet 100% van hen noemen. Ik wil echter wel een overzicht geven van de meest gebruikte.
- Supervised learning algorithms
- Classificatie-algoritmen
- Naive Bayes
- Multinomiale Naïeve Bayes
- Logistische regressie
- Beslissingsbomen
- SVM (Support Vector Machine)
- Regressie-algoritmen
- Lineaire regressie
- Onbewaakte leeralgoritmen
- Clustering
- K-means clustering
- K-nearest neighbor
- Dimensionaliteitsreductie
- Association rule learning
- Handhavingsleren
- Q-Learning
- Ensemble learning
- Bagging
- Boosting
- Random forest
- Stacking
- Neurale netwerken
- Conclusie
Supervised learning algorithms

Als u niet bekend bent met termen als “supervised learning” en “unsupervised learning”, bekijk dan onze AI vs. ML post waar dit onderwerp in detail wordt behandeld. Laten we nu eens vertrouwd raken met de algoritmen.
Classificatie-algoritmen
Naive Bayes

Bayesiaanse algoritmen zijn een familie van probabilistische classifiers die in ML worden gebruikt op basis van de toepassing van het theorema van Bayes.
Naive Bayes classifier was een van de eerste algoritmen die voor machinaal leren werden gebruikt. Hij is geschikt voor binaire en multiklas classificatie en maakt het mogelijk voorspellingen te doen en gegevens te voorspellen op basis van historische resultaten. Een klassiek voorbeeld zijn spamfiltersystemen die tot 2010 Naive Bayes gebruikten en bevredigende resultaten lieten zien. Toen echter Bayesiaanse vergiftiging werd uitgevonden, begonnen programmeurs andere manieren te bedenken om gegevens te filteren.
Met behulp van de stelling van Bayes kan worden bepaald hoe het optreden van een gebeurtenis de waarschijnlijkheid van een andere gebeurtenis beïnvloedt.
Zo berekent dit algoritme bijvoorbeeld de waarschijnlijkheid dat een bepaalde e-mail wel of geen spam is op basis van de typische woorden die worden gebruikt. Veelgebruikte spamwoorden zijn “aanbieding”, “nu bestellen”, of “extra inkomen”. Als het algoritme deze woorden detecteert, is er een grote kans dat de e-mail spam is.
Naive Bayes gaat ervan uit dat de kenmerken onafhankelijk zijn. Daarom wordt het algoritme naïef genoemd.
Multinomiale Naïeve Bayes
Naïeve Bayes classificeert niet alleen, maar er zijn ook andere algoritmen in deze groep. Bijvoorbeeld Multinomiale Naive Bayes, die gewoonlijk wordt toegepast voor documentclassificatie op basis van de frequentie van bepaalde woorden in het document.
Bayesiaanse algoritmen worden nog steeds gebruikt voor tekstcategorisatie en fraudedetectie. Ze kunnen ook worden toegepast voor machine vision (bijvoorbeeld gezichtsdetectie), marktsegmentatie en bio-informatica.
Logistische regressie
Ondanks dat de naam contra-intuïtief kan lijken, is logistische regressie eigenlijk een soort classificatie-algoritme.
Logistische regressie is een model dat voorspellingen doet met behulp van een logistische functie om de afhankelijkheid tussen de output- en inputvariabelen te vinden. Statquest heeft een geweldige video gemaakt waarin ze het verschil tussen lineaire en logistische regressie uitleggen met als voorbeeld obese muizen.
Beslissingsbomen
Een beslissingsboom is een eenvoudige manier om een besluitvormingsmodel in de vorm van een boom te visualiseren. De voordelen van beslisbomen zijn dat ze gemakkelijk te begrijpen, te interpreteren en te visualiseren zijn. Ook vergen zij weinig inspanning voor de voorbereiding van de gegevens.
Ze hebben echter ook een groot nadeel. De bomen kunnen instabiel zijn door zelfs de kleinste variaties (variantie) in de gegevens. Ook is het mogelijk te complexe bomen te maken die niet goed generaliseren. Dit wordt overfitting genoemd. Bagging, boosting en regularisatie helpen dit probleem te bestrijden. We zullen het er later in dit artikel over hebben.
De elementen van elke beslisboom zijn:
- Wortelknooppunt dat de hoofdvraag stelt. Het heeft de pijlen die er vanaf naar beneden wijzen, maar geen pijlen die er naartoe wijzen. Stelt u zich bijvoorbeeld voor dat u een boom opbouwt om te beslissen wat voor pasta u moet eten.
- Branches. Een onderafdeling van een boom wordt een tak of soms een subboom genoemd.
- Beslissingsknooppunten. Dit zijn de subnodes voor de root node die ook kunnen worden opgesplitst in meer nodes. Uw beslissingsknooppunten kunnen zijn “carbonara?” of “met champignons?”.
- Bladeren of Eindknooppunten. Deze nodes splitsen zich niet. Ze vertegenwoordigen definitieve beslissingen of voorspellingen.
Ook is het belangrijk om splitsen te vermelden. Dit is het proces van het verdelen van een node in subnodes. Bijvoorbeeld, als je geen vegetariër bent, is carbonara oké. Maar als je dat wel bent, eet dan pasta met champignons. Er is ook een proces van knooppuntverwijdering dat snoeien wordt genoemd.
Decision tree algoritmen worden CART (Classification and Regression Trees) genoemd. Beslissingsbomen kunnen werken met categorische of numerieke gegevens.
- Regressiebomen worden gebruikt wanneer de variabelen numerieke waarde hebben.
- Classificatiebomen kunnen worden toegepast wanneer de gegevens categorisch zijn (klassen).
Beslissingsbomen zijn vrij intuïtief te begrijpen en te gebruiken. Dat is de reden waarom boomdiagrammen vaak worden toegepast in een breed scala van industrieën en disciplines. GreyAtom biedt een breed overzicht van verschillende soorten beslisbomen en hun praktische toepassingen.
SVM (Support Vector Machine)
Support vector machines zijn een andere groep van algoritmen die worden gebruikt voor classificatie en, soms, regressie taken. SVM is geweldig omdat het vrij nauwkeurige resultaten geeft met minimale rekenkracht.
Het doel van de SVM is een hypervlak te vinden in een N-dimensionale ruimte (waarbij N overeenkomt met het aantal kenmerken) dat de gegevenspunten duidelijk classificeert. De nauwkeurigheid van de resultaten houdt rechtstreeks verband met het hypervlak dat we kiezen. We moeten een vlak vinden dat de maximale afstand tussen de gegevenspunten van beide klassen heeft.
Dit hypervlak wordt grafisch voorgesteld als een lijn die de ene klasse van de andere scheidt. Gegevenspunten die aan verschillende zijden van het hypervlak vallen, worden aan verschillende klassen toegewezen.
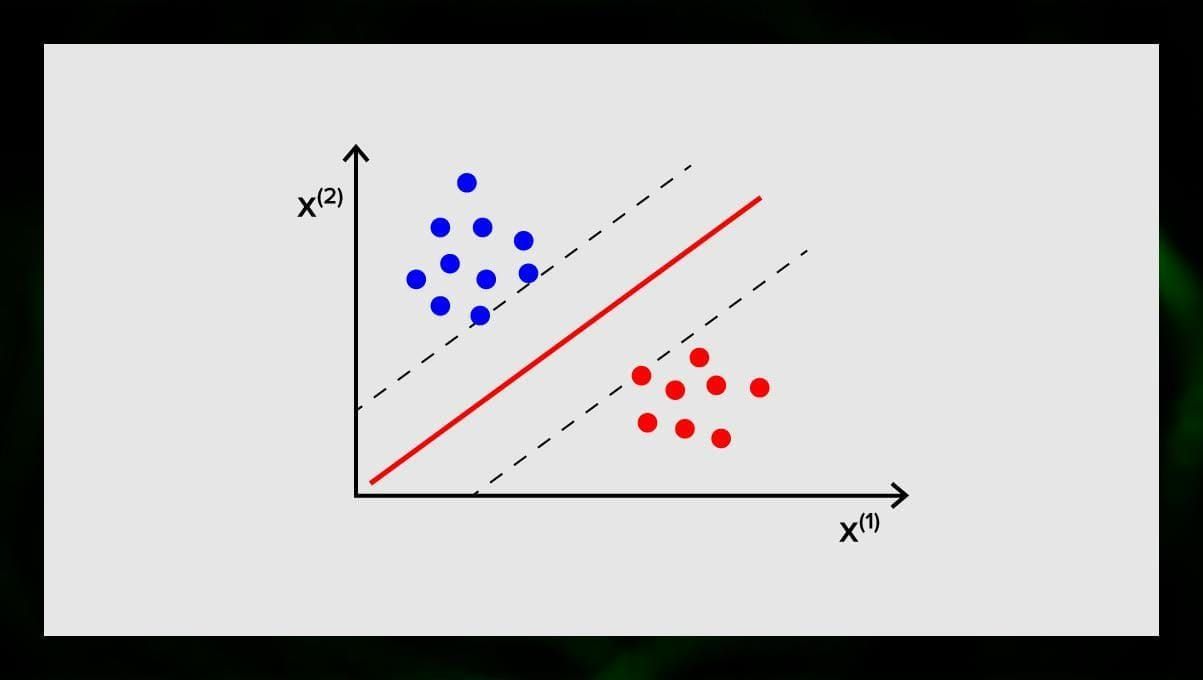
Merk op dat de dimensie van het hypervlak afhangt van het aantal kenmerken. Als het aantal invoergegevens 2 is, is de hyperplane slechts een lijn. Als het aantal inputkenmerken 3 is, wordt het hypervlak een tweedimensionaal vlak. Het wordt moeilijk om een model op een grafiek te tekenen als het aantal kenmerken meer dan 3 bedraagt. In dit geval gebruikt u dus Kernel types om het om te zetten in een 3-dimensionale ruimte.
Waarom wordt dit een Support Vector Machine genoemd? Steunvectoren zijn gegevenspunten die het dichtst bij het hypervlak liggen. Zij beïnvloeden rechtstreeks de positie en oriëntatie van het hypervlak en stellen ons in staat de marge van de classificator te maximaliseren. Door de supportvectoren te verwijderen, verandert de positie van het hypervlak. Dit zijn de punten die ons helpen om onze SVM te bouwen.
SVM worden nu actief gebruikt in medische diagnose om afwijkingen te vinden, in controlesystemen voor de luchtkwaliteit, voor financiële analyse en voorspellingen op de aandelenmarkt, en machine fout-controle in de industrie.
Regressie-algoritmen
Regressie-algoritmen zijn nuttig in analyses, bijvoorbeeld wanneer u probeert de kosten voor effecten of de verkoop voor een bepaald product op een bepaald tijdstip te voorspellen.
Lineaire regressie
Lineaire regressie probeert de relatie tussen variabelen te modelleren door een lineaire vergelijking aan te passen aan de waargenomen gegevens.
Er zijn verklarende en afhankelijke variabelen. Afhankelijke variabelen zijn dingen die we willen verklaren of voorspellen. De verklarende, zoals de naam al zegt, verklaren iets. Als je een lineaire regressie wilt opbouwen, ga je ervan uit dat er een lineair verband is tussen je afhankelijke en onafhankelijke variabelen. Bijvoorbeeld, er is een verband tussen de vierkante meters van een huis en de prijs of de dichtheid van de bevolking en kebab plaatsen in de omgeving.
Als je die veronderstelling eenmaal maakt, moet je vervolgens het specifieke lineaire verband uitzoeken. U moet een lineaire regressievergelijking vinden voor een reeks gegevens. De laatste stap is het berekenen van het residu.
Opmerking: wanneer de regressie een rechte lijn trekt, wordt ze lineair genoemd, wanneer ze een curve is – polynomiaal.
Onbewaakte leeralgoritmen

Laten we het nu hebben over algoritmen die in staat zijn verborgen patronen te vinden in ongelabelde gegevens.
Clustering
Clustering betekent dat we inputs in groepen verdelen op basis van de mate van hun gelijkenis met elkaar. Clustering is meestal een van de stappen om een complexer algoritme te bouwen. Het is eenvoudiger om elke groep afzonderlijk te bestuderen en een model te bouwen op basis van hun kenmerken, in plaats van met alles tegelijk te werken. Dezelfde techniek wordt voortdurend gebruikt in marketing en verkoop om alle potentiële klanten in groepen te verdelen.
Veel voorkomende clusteringalgoritmen zijn k-means clustering en k-nearest neighbor.
K-means clustering
K-means clustering verdeelt de verzameling elementen van de vectorruimte in een vooraf bepaald aantal clusters k. Een onjuist aantal clusters zal het hele proces echter ongeldig maken, dus het is belangrijk om het met variërende aantallen clusters te proberen. Het hoofdidee van het k-means algoritme is dat de gegevens willekeurig in clusters worden verdeeld, en dat daarna het middelpunt van elke cluster, verkregen in de vorige stap, iteratief wordt herberekend. Vervolgens worden de vectoren opnieuw in clusters verdeeld. Het algoritme stopt wanneer er op een bepaald punt na een iteratie geen verandering in de clusters optreedt.
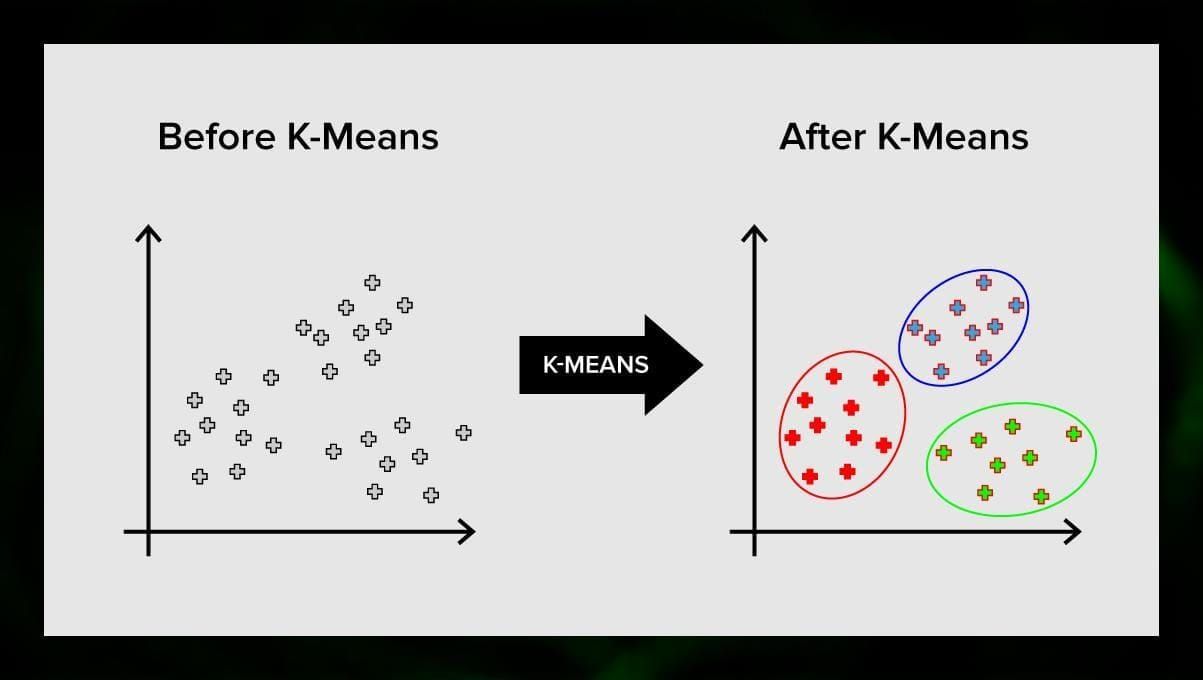
Deze methode kan worden toegepast om problemen op te lossen wanneer de clusters van elkaar verschillen of gemakkelijk van elkaar kunnen worden gescheiden, zonder overlappende gegevens.
K-nearest neighbor
kNN staat voor k-nearest neighbor. Dit is een van de eenvoudigste classificatiealgoritmen die soms bij regressietaken worden gebruikt.
Om de classificator te trainen, moet u beschikken over een gegevensverzameling met vooraf gedefinieerde klassen. De markering gebeurt manueel met medewerking van specialisten op het bestudeerde gebied. Met behulp van dit algoritme is het mogelijk om met meerdere klassen te werken of de situaties op te lossen waarin de invoer tot meer dan één klasse behoort.
De methode is gebaseerd op de aanname dat soortgelijke labels overeenkomen met dicht bij elkaar liggende objecten in de attribuutvectorruimte.
Moderne softwaresystemen gebruiken kNN voor visuele patroonherkenning, bijvoorbeeld voor het scannen en detecteren van verborgen pakketten onder in het winkelwagentje bij het uitchecken (bijvoorbeeld AmazonGo). K-nearest neighbor wordt ook gebruikt in het bankwezen om patronen in creditcardgebruik te detecteren. kNN-algoritmen analyseren alle gegevens en spotten ongebruikelijke patronen die wijzen op verdachte activiteiten.
Dimensionaliteitsreductie
Principal component analysis (PCA) is een belangrijke techniek om te begrijpen om ML-gerelateerde problemen effectief op te lossen.
Stel je voor dat je een heleboel variabelen hebt om te overwegen. Bijvoorbeeld, je moet steden clusteren in drie groepen: goed om te wonen, slecht om te wonen en zo-zo. Met hoeveel variabelen moet je dan rekening houden? Waarschijnlijk heel veel. Begrijp je de relaties tussen die variabelen? Niet echt. Dus hoe kun je alle variabelen die je hebt verzameld, gebruiken en je concentreren op een paar van hen die het belangrijkst zijn?
In technische termen: je wilt “de dimensie van je kenmerkruimte verkleinen.” Door het verminderen van de dimensie van uw feature ruimte, slaagt u erin om minder relaties tussen variabelen om te overwegen en je bent minder waarschijnlijk om overfit uw model.
Er zijn vele manieren om dimensionaliteit reductie te bereiken, maar de meeste van deze technieken vallen in een van de twee klassen:
- Feature Elimination;
- Feature Extraction.
Feature eliminatie betekent dat je het aantal kenmerken te verminderen door het elimineren van een aantal van hen. De voordelen van deze methode zijn dat ze eenvoudig is en de interpreteerbaarheid van uw variabelen handhaaft. Nadeel is echter dat je nul informatie krijgt van de variabelen die je hebt besloten te laten vallen.
Feature-extractie vermijdt dit probleem. Het doel bij de toepassing van deze methode is om een reeks kenmerken te extraheren uit de gegeven dataset. Feature Extraction heeft tot doel het aantal features in een dataset te verminderen door nieuwe features te creëren op basis van de bestaande (en vervolgens de oorspronkelijke features te verwijderen). De nieuwe gereduceerde set features moet zo worden gemaakt dat het in staat is het grootste deel van de informatie in de oorspronkelijke set features samen te vatten.
Principal component analysis is een algoritme voor feature-extractie. het combineert de invoervariabelen op een specifieke manier, en dan is het mogelijk de “minst belangrijke” variabelen te laten vallen, terwijl toch de meest waardevolle delen van alle variabelen behouden blijven.
Een van de mogelijke toepassingen van PCA is wanneer de afbeeldingen in de dataset te groot zijn. Een gereduceerde feature representatie helpt om taken als image matching en retrieval snel af te handelen.
Association rule learning
Apriori is een van de populairste associatie regel zoekalgoritmen. Het is in staat om grote hoeveelheden gegevens in een relatief korte tijd te verwerken.
Het punt is dat de databases van veel projecten tegenwoordig zeer groot zijn, gigabytes en terabytes bereikend. En ze zullen blijven groeien. Daarom heeft men een effectief, schaalbaar algoritme nodig om in korte tijd associatieve regels te vinden. Apriori is zo’n algoritme.
Om het algoritme te kunnen toepassen, is het nodig de gegevens voor te bereiden, door ze allemaal om te zetten naar de binaire vorm en de gegevensstructuur te veranderen.
Normaal gesproken voer je dit algoritme uit op een database die een groot aantal transacties bevat, bijvoorbeeld op een database die informatie bevat over alle artikelen die klanten in een supermarkt hebben gekocht.
Handhavingsleren

Handhavingsleren is een van de methoden van machinaal leren waarmee de machine wordt geleerd hoe hij met een bepaalde omgeving moet omgaan. In dit geval fungeert de omgeving (bijvoorbeeld in een videospelletje) als leraar. Hij geeft feedback op de beslissingen die de computer neemt. Op basis van deze beloning leert de machine de beste handelwijze te kiezen. Het doet denken aan de manier waarop kinderen leren een hete koekenpan niet aan te raken – door uitproberen en pijn voelen.
Als we dit proces uitsplitsen, gaat het om de volgende eenvoudige stappen:
- De computer observeert de omgeving;
- Kiest een strategie;
- Handelt volgens deze strategie;
- Krijgt een beloning of een straf;
- Leert van deze ervaring en verfijnt de strategie;
- Herhaalt dit totdat de optimale strategie is gevonden.
Q-Learning
Er zijn een paar algoritmen die voor Reinforcement learning kunnen worden gebruikt. Een van de meest gebruikte is Q-learning.
Q-learning is een modelvrij reinforcement learning algoritme. Q-learning is gebaseerd op de beloning ontvangen van de omgeving. De agent vormt een nutsfunctie Q, die hem vervolgens de gelegenheid geeft een gedragsstrategie te kiezen, en daarbij rekening te houden met de ervaring van eerdere interacties met de omgeving.
Een van de voordelen van Q-learning is dat het in staat is het verwachte nut van de beschikbare acties te vergelijken zonder omgevingsmodellen te vormen.
Ensemble learning

Ensemble learning is de methode om een probleem op te lossen door meerdere ML-modellen te bouwen en deze te combineren. Ensemble-leren wordt voornamelijk gebruikt om de prestaties van classificatie-, voorspellings- en functiebenaderingsmodellen te verbeteren. Andere toepassingen van ensembleleren zijn het controleren van de beslissing van het model, het selecteren van optimale kenmerken voor het bouwen van modellen, incrementeel leren, en niet-stationair leren.
Hieronder volgen enkele van de meer gebruikelijke algoritmen voor ensembleleren.
Bagging
Bagging staat voor bootstrap aggregating. Het is een van de vroegste ensemble-algoritmen, met een verrassend goede prestatie. Om de diversiteit van classifiers te garanderen, gebruik je bootstrap replica’s van de trainingsdata. Dat betekent dat verschillende trainingsdata-subsets willekeurig – met vervanging – uit de trainingsdataset worden getrokken. Elke trainingssubset wordt gebruikt om een andere classifier van hetzelfde type te trainen. Vervolgens kunnen de individuele classifiers worden gecombineerd. Daartoe moet een gewone meerderheid van stemmen worden genomen over hun beslissingen. De klasse die door de meerderheid van de classifiers is toegewezen, is de beslissing van het ensemble.
Boosting
Deze groep van ensemble-algoritmen is vergelijkbaar met bagging. Boosting gebruikt ook een aantal classifiers om de gegevens opnieuw te bemonsteren, en kiest dan de optimale versie door meerderheidsstemming. Bij boosting train je iteratief zwakke classifiers om ze samen te voegen tot een sterke classifier. Wanneer de classifiers worden toegevoegd, wordt hun gewoonlijk een aantal gewichten toegekend, die de nauwkeurigheid van hun voorspellingen beschrijven. Nadat een zwakke classificeerder aan het ensemble is toegevoegd, worden de gewichten herberekend. Foutief geclassificeerde inputs krijgen meer gewicht, en correct geclassificeerde instanties verliezen gewicht. Het systeem concentreert zich dus meer op voorbeelden waar een foutieve classificatie werd verkregen.
Random forest
Random forests of random decision forests zijn een ensemble leermethode voor classificatie, regressie, en andere taken. Om een random forest te bouwen, moet je een veelvoud van beslisbomen trainen op willekeurige samples van trainingsdata. De output van het random forest is het meest frequente resultaat van de individuele bomen. Random beslissingsbossen bestrijden met succes overfitting door de _random _natuur van het algoritme.
Stacking
Stacking is een ensemble leertechniek die meerdere classificatie- of regressiemodellen combineert via een meta-classifier of een meta-regressor. De modellen op basisniveau worden getraind op basis van een volledige trainingsset, waarna het metamodel wordt getraind op de outputs van de modellen op basisniveau als features.
Neurale netwerken
Een neuraal netwerk is een opeenvolging van neuronen die door synapsen met elkaar zijn verbonden, wat doet denken aan de structuur van het menselijk brein. Het menselijk brein is echter nog complexer.
Wat geweldig is aan neurale netwerken is dat ze kunnen worden gebruikt voor in principe elke taak, van spam filteren tot computer vision. Normaal gesproken worden ze echter toegepast voor automatische vertaling, anomaliedetectie en risicobeheer, spraakherkenning en taalgeneratie, gezichtsherkenning en meer.
Een neuraal netwerk bestaat uit neuronen, of nodes. Elk van deze neuronen ontvangt gegevens, verwerkt deze, en geeft ze vervolgens door aan een ander neuron.
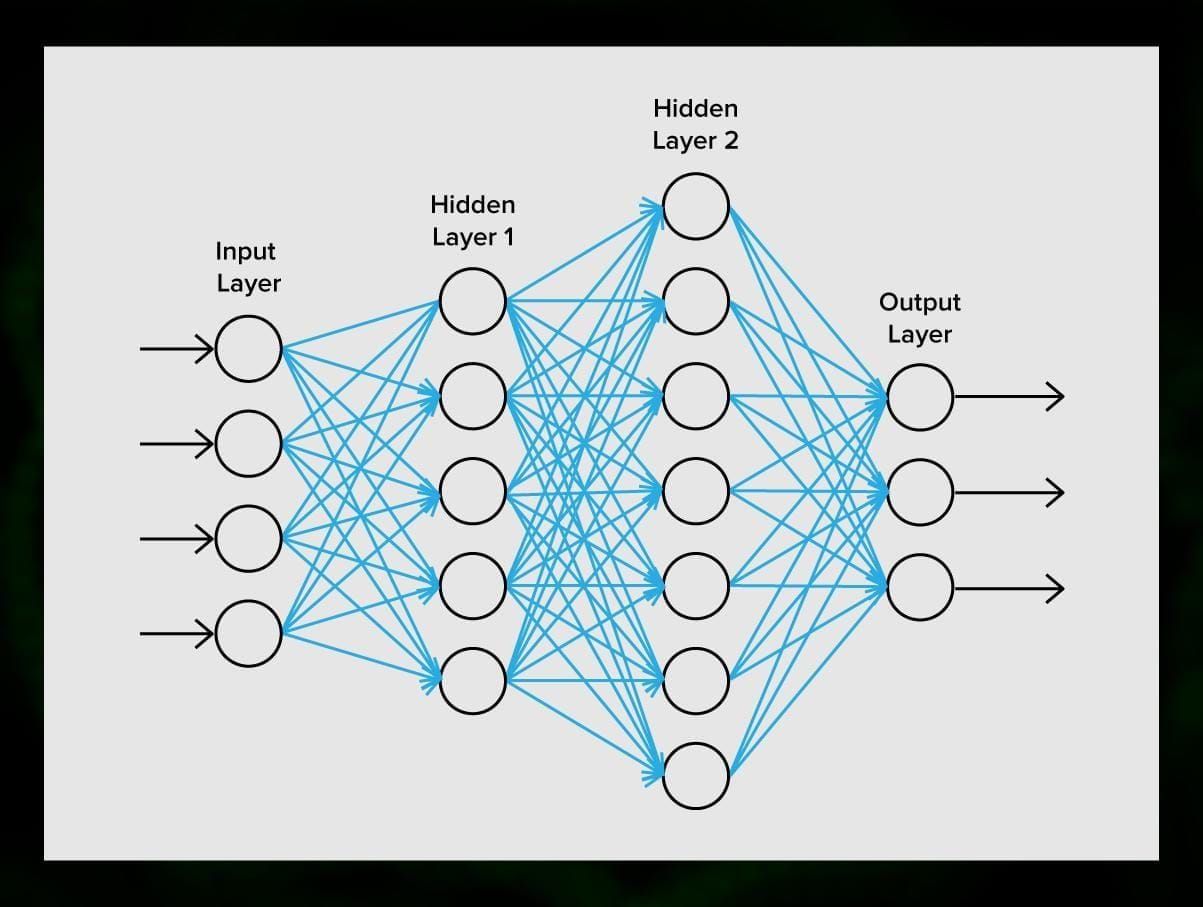
Elke neuron verwerkt de signalen op dezelfde manier. Maar hoe krijgen we dan een ander resultaat? De synapsen die neuronen met elkaar verbinden zijn hiervoor verantwoordelijk. Elk neuron is in staat vele synapsen te hebben die het signaal afzwakken of versterken. Ook zijn neuronen in staat hun eigenschappen in de loop van de tijd te veranderen. Door de juiste synapsparameters te kiezen, zullen we in staat zijn de juiste resultaten te verkrijgen van de omzetting van de ingevoerde informatie aan de uitgang.
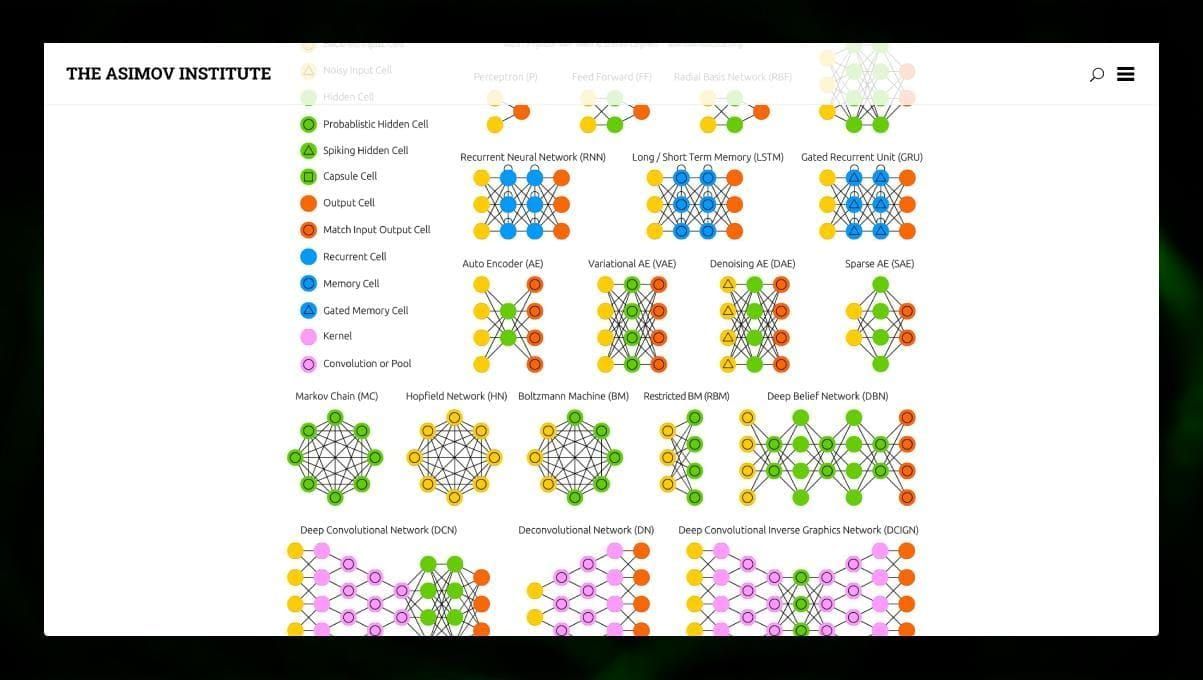
Er zijn veel verschillende soorten NN:
- Feedforward neurale netwerken (FF of FFNN) en perceptrons § zijn zeer rechtlijnig, er zijn geen lussen of cycli in het netwerk. In de praktijk worden dergelijke netwerken zelden gebruikt, maar zij worden vaak gecombineerd met andere typen om nieuwe te verkrijgen.
- Een Hopfield netwerk (HN) is een volledig verbonden neuraal netwerk met een symmetrische matrix van schakels. Een dergelijk netwerk wordt vaak een associatief geheugennetwerk genoemd. Net als een persoon die de ene helft van de tafel ziet, zich de tweede helft kan voorstellen, herstelt dit netwerk, wanneer het een ruisende tafel ontvangt, deze weer volledig.
- Convolutionele neurale netwerken (CNN) en diepe convolutionele neurale netwerken (DCNN) zijn heel anders dan andere soorten netwerken. Zij worden gewoonlijk gebruikt voor beeldverwerking, audio- of video-gerelateerde taken. Een typische manier om CNN toe te passen is het classificeren van beelden.
Veel verschillende soorten neurale netwerken zijn interessant om te observeren. Dat kan in de NN zoo.
Conclusie
Deze post is een breed overzicht van verschillende ML-algoritmen, maar er valt nog veel over te zeggen. Blijf op de hoogte van onze Twitter, Facebook, en Medium voor meer gidsen en berichten over de spannende mogelijkheden van machine learning.
Geef een antwoord