Mensen creëren, delen en slaan gegevens op in een sneller tempo dan ooit in de geschiedenis. Als het gaat om het innoveren van het opslaan en verzenden van die gegevens, maken we bij Facebook niet alleen vooruitgang in hardware – zoals grotere harde schijven en snellere netwerkapparatuur – maar ook in software. Software helpt bij de gegevensverwerking door middel van compressie, waarbij informatie, zoals tekst, afbeeldingen en andere vormen van digitale gegevens, wordt gecodeerd met minder bits dan het origineel. Deze kleinere bestanden nemen minder ruimte in op harde schijven en worden sneller verzonden naar andere systemen. Het comprimeren en decomprimeren van informatie heeft echter een keerzijde: tijd. Hoe meer tijd er wordt besteed aan het comprimeren tot een kleiner bestand, hoe langzamer de gegevens worden verwerkt.
Heden ten dage is Deflate, het kernalgoritme van Zip, gzip, en zlib, de heersende standaard voor gegevenscompressie. Al twee decennia lang biedt het een indrukwekkend evenwicht tussen snelheid en ruimte, en als gevolg daarvan wordt het gebruikt in bijna elk modern elektronisch apparaat (en, niet toevallig, gebruikt om elke byte van het blogbericht dat u nu leest te verzenden). In de loop der jaren hebben andere algoritmen ofwel betere compressie ofwel snellere compressie geboden, maar zelden beide. Wij geloven dat we dit hebben veranderd.
We zijn verheugd om Zstandard 1.0 aan te kondigen, een nieuw compressie algoritme en implementatie ontworpen om te schalen met moderne hardware en kleiner en sneller te comprimeren. Zstandard combineert recente doorbraken op het gebied van compressie, zoals Finite State Entropy, met een prestatiegericht ontwerp – en optimaliseert vervolgens de implementatie voor de unieke eigenschappen van moderne CPU’s. Het resultaat is een verbetering ten opzichte van andere compressie-algoritmen en een breed toepassingsgebied met een zeer hoge decompressiesnelheid. Zstandard, nu beschikbaar onder de BSD licentie, is ontworpen om te worden gebruikt in bijna elk lossless compressie scenario, inclusief vele waar de huidige algoritmen niet toepasbaar zijn.
- Compressie vergelijken
- Kalibaarheid
- Onder de motorkap
- Geheugen
- Een formaat ontworpen voor parallelle uitvoering
- Branchless design
- Finite State Entropy: A next-generation probability compressor
- Repcode modeling
- Zstandard in de praktijk
- Kleine gegevens
- Woordenboeken in actie
- Kies een compressie niveau
- Probeer het eens
- Er komt nog meer
Compressie vergelijken
Er zijn drie standaard metrieken voor het vergelijken van compressie algoritmen en implementaties:
- Compressie ratio: De oorspronkelijke grootte (teller) vergeleken met de gecomprimeerde grootte (noemer), gemeten in eenheidloze gegevens als een grootteverhouding van 1,0 of groter.
- Compressiesnelheid: Hoe snel we de gegevens kleiner kunnen maken, gemeten in MB/s van verbruikte invoergegevens.
- Decompressiesnelheid: Hoe snel we de oorspronkelijke gegevens kunnen reconstrueren uit de gecomprimeerde gegevens, gemeten in MB/s voor de snelheid waarmee gegevens worden geproduceerd uit gecomprimeerde gegevens.
Het type gegevens dat wordt gecomprimeerd kan deze metriek beïnvloeden, dus veel algoritmen zijn afgestemd op specifieke gegevenstypen, zoals Engelse tekst, genetische sequenties, of gerasterde afbeeldingen. Zstandard is echter, net als zlib, bedoeld voor algemene compressie voor een verscheidenheid aan gegevenstypes. Om de algoritmen weer te geven waarop Zstandard verwacht wordt te werken, zullen we in dit bericht de Silesia corpus gebruiken, een dataset van bestanden die de typische datatypes vertegenwoordigen die elke dag gebruikt worden.
Enkele algoritmen en implementaties die tegenwoordig veel worden gebruikt zijn zlib, lz4, en xz. Elk van deze algoritmen biedt verschillende compromissen: lz4 is gericht op snelheid, xz op hogere compressieratio’s, en zlib op een goed evenwicht tussen snelheid en omvang. De onderstaande tabel geeft de ruwe afwegingen weer van de standaard compressieverhouding en snelheid van de algoritmen voor het Silesia corpus door de algoritmen te vergelijken met lzbench, een pure in-memory benchmark bedoeld om de prestaties van ruwe algoritmen te modelleren.
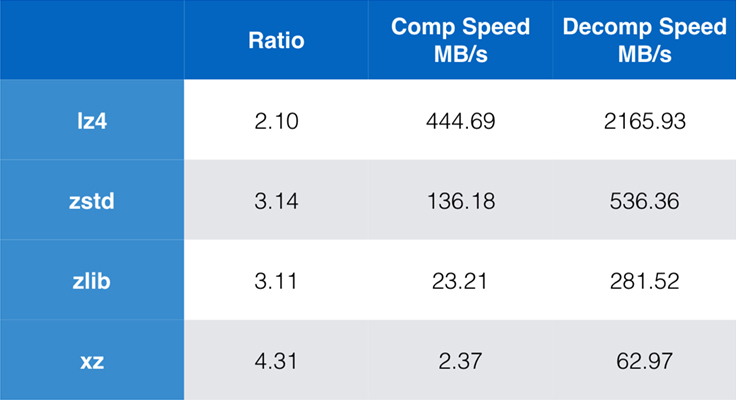
Zoals geschetst, zijn er vaak drastische compromissen tussen snelheid en grootte. Het snelste algoritme, lz4, leidt tot lagere compressieratio’s; xz, dat de hoogste compressieratio heeft, lijdt onder een lage compressiesnelheid. Zstandard echter, met de standaard instelling, laat aanzienlijke verbeteringen zien in zowel compressie snelheid als decompressie snelheid, terwijl het comprimeert met dezelfde ratio als zlib.
Weliswaar is pure algoritme prestatie belangrijk wanneer compressie is ingebed in een grotere toepassing, maar het is zeer gebruikelijk om ook command line tools te gebruiken voor compressie – zeg, voor het comprimeren van log files, tarballs, of andere soortgelijke gegevens bedoeld voor opslag of overdracht. In deze gevallen wordt de prestatie vaak beïnvloed door overhead, zoals checksumming. Deze grafiek toont de vergelijking van de opdrachtregel-tools gzip en zstd op Centos 7, gebouwd met de standaard compiler van het systeem.
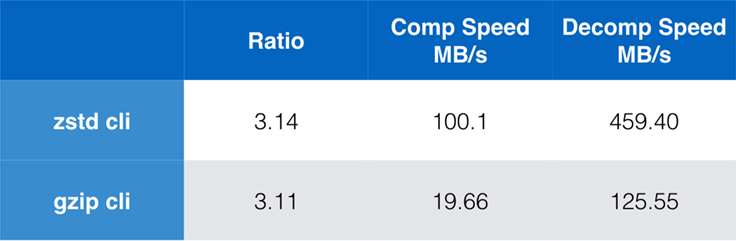
De tests zijn elk 10 keer uitgevoerd, waarbij de minimale tijden zijn genomen, en zijn uitgevoerd op ramdisk om overhead van het bestandssysteem te voorkomen. Dit waren de opdrachten (die de standaard compressieniveaus voor beide tools gebruiken):
zstd -c -3 silesia.tar > silesia.tar.zst # 67,432,740 byteszstd -d -c silesia.tar.zst > /dev/nullgzip -c -6 silesia.tar > silesia.tar.gz # 68,235,522 bytesgzip -d -c silesia.tar.gz > /dev/nullKalibaarheid
Als een algoritme schaalbaar is, heeft het de mogelijkheid om zich aan te passen aan een grote verscheidenheid van vereisten, en Zstandard is ontworpen om uit te blinken in het huidige landschap en om te schalen naar de toekomst. De meeste algoritmen hebben “niveaus” op basis van tijd/ruimte-afwegingen: Hoe hoger het niveau, hoe groter de compressie die wordt bereikt bij een verlies van compressiesnelheid. Zlib biedt negen compressieniveaus; Zstandard biedt er momenteel 22, wat flexibele, granulaire afwegingen tussen compressiesnelheid en ratio’s voor toekomstige gegevens mogelijk maakt. We kunnen bijvoorbeeld niveau 1 gebruiken als snelheid het belangrijkst is en niveau 22 als grootte het belangrijkst is.
Hieronder staat een grafiek van de compressie snelheid en ratio bereikt voor alle niveaus van Zstandard en zlib. De x-as is een afnemende logaritmische schaal in megabytes per seconde; de y-as is de bereikte compressieverhouding. Om de algoritmen te vergelijken, kunt u een snelheid kiezen om de verschillende ratio’s te zien die de algoritmen bij die snelheid bereiken. Op dezelfde manier kunt u een ratio kiezen en zien hoe snel de algoritmen zijn wanneer ze dat niveau bereiken.
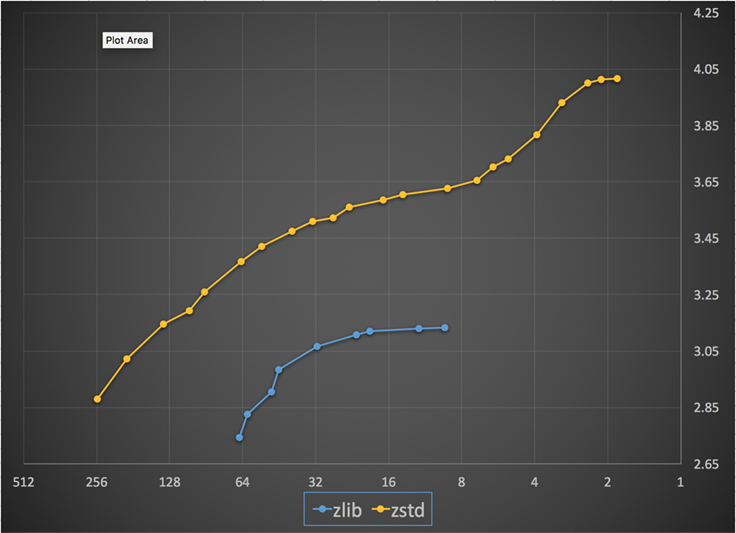
Voor elke verticale lijn (d.w.z. compressiesnelheid) behaalt Zstandard een hogere compressieverhouding. Voor het Silesia corpus was de decompressiesnelheid – ongeacht de ratio – ongeveer 550 MB/s voor Zstandard en 270 MB/s voor zlib. De grafiek toont een ander verschil tussen Zstandard en de alternatieven: Door gebruik te maken van één algoritme en implementatie, maakt Zstandard een veel fijnmaziger afstemming voor elk gebruik mogelijk. Dit betekent dat Zstandard kan concurreren met enkele van de snelste en hoogste compressie-algoritmen terwijl het een aanzienlijk decompressie-snelheidsvoordeel behoudt. Deze verbeteringen vertalen zich direct in snellere gegevensoverdracht en kleinere opslagvereisten.
Met andere woorden, in vergelijking met zlib, Zstandard schaalt:
- Bij dezelfde compressieverhouding, comprimeert het aanzienlijk sneller: ~3-5x.
- Bij dezelfde compressiesnelheid, is het aanzienlijk kleiner: 10-15 procent kleiner.
- Het is bijna 2x sneller bij decompressie, ongeacht de compressieverhouding; de opdrachtregel-tooling getallen tonen een nog groter verschil: meer dan 3x sneller.
- Het schaalt naar veel hogere compressie ratio’s, terwijl het bliksemsnelle decompressie snelheden behoudt.
Onder de motorkap
Zstandard verbetert zlib door een aantal recente innovaties te combineren en zich te richten op moderne hardware:
Geheugen
Door het ontwerp is zlib beperkt tot een 32 KB venster, wat een verstandige keuze was in de vroege jaren ’90. Maar de computeromgeving van vandaag heeft toegang tot veel meer geheugen – zelfs in mobiele en embedded omgevingen.
Zstandard heeft geen inherente limiet en kan terabytes aan geheugen aanspreken (hoewel het dat zelden doet). Bijvoorbeeld, de laagste van de 22 niveaus gebruiken 1 MB of minder. Voor compatibiliteit met een breed scala van ontvangende systemen, waar het geheugen beperkt kan zijn, wordt het aanbevolen om het geheugengebruik te beperken tot 8 MB. Dit is echter een aanbeveling voor tuning, geen beperking van het compressieformaat.
Een formaat ontworpen voor parallelle uitvoering
De CPU’s van vandaag zijn zeer krachtig en kunnen meerdere instructies per cyclus geven, dankzij meerdere ALU’s (rekenkundige logische eenheden) en een steeds geavanceerder ontwerp voor uitvoering buiten de volgorde.
In essentie betekent het dat als:
a = b1 + b2
c = d1 + d2
dan worden zowel a als c parallel berekend.
Dit is alleen mogelijk als er geen relatie tussen beide is. Daarom, in dit voorbeeld:
a = b1 + b2
c = d1 + a
c moet wachten tot a eerst is berekend, en pas dan zal c berekening beginnen.
Het betekent dat, om voordeel te halen uit de moderne CPU, men een stroom van bewerkingen moet ontwerpen met weinig of geen data afhankelijkheden.
Dit wordt bereikt met Zstandard door het scheiden van data in meerdere parallelle stromen. Een nieuwe generatie Huffman decoder, Huff0, is in staat om meerdere symbolen parallel te decoderen met een enkele kern. Een dergelijke winst is cumulatief met multi-threading, waarbij meerdere kernen worden gebruikt.
Branchless design
Nieuwe CPU’s zijn krachtiger en bereiken zeer hoge frequenties, maar dit is alleen mogelijk dankzij een meerfasenaanpak, waarbij een instructie wordt opgesplitst in een pijplijn van meerdere stappen. Bij elke klokcyclus kan de CPU het resultaat van meerdere bewerkingen uitgeven, afhankelijk van de beschikbare ALU’s. Hoe meer ALU’s worden gebruikt, hoe meer werk de CPU verricht, en hoe sneller de compressie dus verloopt. De ALU’s gevoed houden met werk is van cruciaal belang voor moderne CPU-prestaties.
Dit blijkt moeilijk te zijn. Beschouw de volgende eenvoudige situatie:
if (condition) doSomething() else doSomethingElse()Wanneer hij dit tegenkomt, weet de CPU niet wat hij moet doen, omdat hij afhankelijk is van de waarde van condition. Een voorzichtige CPU zou wachten op het resultaat van condition alvorens aan een van beide vertakkingen te werken, hetgeen uiterst verspillend zou zijn.
De CPU’s van vandaag gokken. Ze doen dat op een intelligente manier, dankzij een vertakkingsvoorspeller, die hen in essentie vertelt wat het meest waarschijnlijke resultaat is van de evaluatie van condition. Als de gok juist is, blijft de pijplijn vol en worden voortdurend instructies gegeven. Wanneer de gok fout is (een verkeerde voorspelling), moet de CPU alle speculatief gestarte operaties stoppen, terugkeren naar de branch, en de andere kant opgaan. Dit wordt een “pipeline flush” genoemd, en is zeer kostbaar in moderne CPU’s.
Vijfentwintig jaar geleden was een “pipeline flush” geen probleem. Vandaag de dag is het zo belangrijk dat het essentieel is om formaten te ontwerpen die compatibel zijn met vertakkingsloze algoritmen. Laten we als voorbeeld eens kijken naar een bit-stream update:
/* classic version */while (nbBitsUsed >= 8) { /* each while test is a branch */ accumulator <<= 8; accumulator += *byte++; nbBitsUsed -= 8;} /*>/* branch-less version */nbBytesUsed = nbBitsUsed >> 3;nbBitsUsed &= 7;ptr += nbBytesUsed;accumulator = read64(ptr);Zoals u kunt zien, heeft de vertakkingsloze versie een voorspelbare werklast, zonder enige voorwaarde. De CPU zal altijd hetzelfde werk doen, en dat werk wordt nooit weggegooid als gevolg van een verkeerde voorspelling. De klassieke versie daarentegen doet minder werk wanneer (nbBitsUsed < 8). Maar de test zelf is niet gratis, en telkens wanneer de test verkeerd wordt geraden, resulteert dit in een volledige pijplijn flush, die meer kost dan het werk dat door de branchless versie wordt gedaan.
Zoals u kunt raden, heeft dit neveneffect gevolgen voor de manier waarop gegevens worden ingepakt, gelezen en gedecodeerd. Zstandard is gemaakt om vriendelijk te zijn voor vertakkingsloze algoritmen, vooral binnen kritieke lussen.
Finite State Entropy: A next-generation probability compressor
In compressie worden gegevens eerst omgezet in een verzameling symbolen (de modelleringsfase), en vervolgens worden deze symbolen gecodeerd met behulp van een minimaal aantal bits. Deze tweede fase wordt de entropiefase genoemd, ter herinnering aan Claude Shannon, die nauwkeurig de compressielimiet berekent van een verzameling symbolen met gegeven waarschijnlijkheden (de “Shannon-limiet” genoemd). Het doel is om dicht bij deze limiet te komen met zo weinig mogelijk CPU-bronnen.
Een heel gebruikelijk algoritme is Huffman-codering, in gebruik binnen Deflate. Het geeft de best mogelijke prefix code, ervan uitgaande dat elk symbool wordt beschreven met een natuurlijk aantal bits (1 bit, 2 bits …). Dit werkt in de praktijk goed, maar de limiet van natuurlijke getallen betekent dat het onmogelijk is om hoge compressieratio’s te bereiken, omdat een symbool noodzakelijkerwijs ten minste 1 bit verbruikt.
Een betere methode heet rekenkundige codering, die willekeurig dicht bij de limiet van Shannon kan komen -log2(P), waardoor fractionele bits per symbool worden verbruikt. Dit levert een betere compressieverhouding op wanneer de waarschijnlijkheid hoog is, maar het gebruikt ook meer CPU-kracht. In de praktijk hebben zelfs geoptimaliseerde rekenkundige codeerders moeite met snelheid, vooral aan de decompressie kant, die delingen vereist met een voorspelbaar resultaat (b.v. geen drijvende komma) en die traag blijkt te zijn.
Finite State Entropy is gebaseerd op een nieuwe theorie genaamd ANS (Asymmetric Numeral System) van Jarek Duda. Finite State Entropy is een variant die veel coderingsstappen in tabellen voorrekent, wat resulteert in een entropie-codec die even nauwkeurig is als rekenkundige codering, met alleen optellingen, tabel lookups, en verschuivingen, wat ongeveer even complex is als Huffman. Het vermindert ook de wachttijd voor toegang tot het volgende symbool, omdat het onmiddellijk toegankelijk is vanuit de toestandswaarde, terwijl Huffman een voorafgaande bit-stream decodeeroperatie vereist. Uitleggen hoe het werkt valt buiten het bestek van dit bericht, maar als u geïnteresseerd bent, is er een reeks artikelen waarin de innerlijke werking wordt beschreven.
Repcode modeling
Repcode modeling comprimeert efficiënt gestructureerde gegevens, die reeksen van vrijwel gelijkwaardige inhoud bevatten, die slechts door een of enkele bytes verschillen. Deze methode is niet nieuw, maar werd voor het eerst gebruikt na de publicatie van Deflate, dus het bestaat niet binnen zlib/gzip.
De efficiëntie van repcode modeling hangt sterk af van het type gegevens dat wordt gecomprimeerd, variërend van een enkele tot een twee-cijferige compressieverbetering. Deze gecombineerde verbeteringen tellen op tot een betere en snellere compressie-ervaring, aangeboden binnen de Zstandard-bibliotheek.
Zstandard in de praktijk
Zoals eerder vermeld, zijn er verschillende typische gebruikssituaties van compressie. Wil een algoritme overtuigend zijn, dan moet het ofwel buitengewoon goed zijn in één specifiek gebruik, zoals het comprimeren van menselijk leesbare tekst, of zeer goed in vele verschillende gebruikssituaties. Zstandard kiest voor de laatste benadering. Een manier om na te denken over use-cases is het aantal keren dat een specifiek stuk gegevens kan worden gedecomprimeerd. Zstandard heeft voordelen in al deze gevallen.
Vele malen. Voor gegevens die vele malen worden verwerkt, is decompressiesnelheid en de mogelijkheid om te kiezen voor een zeer hoge compressieverhouding zonder afbreuk te doen aan de decompressiesnelheid voordelig. De opslag van de sociale grafiek op Facebook, bijvoorbeeld, wordt herhaaldelijk gelezen wanneer u en uw vrienden interactie hebben met de site. Buiten Facebook zijn voorbeelden van wanneer gegevens vele malen moeten worden gedecomprimeerd, bestanden die van een server worden gedownload, zoals de broncode voor de Linux-kernel of de RPM’s die op servers zijn geïnstalleerd, de JavaScript en CSS die door een webpagina worden gebruikt, of het uitvoeren van duizenden MapReduces over gegevens in een datawarehouse.
Eenmalig. Voor gegevens die slechts eenmaal zijn gecomprimeerd, vooral voor verzending via een netwerk, is compressie een vluchtig moment in de gegevensstroom. Hoe minder overhead op de server, hoe meer aanvragen de server per seconde kan verwerken. Minder overhead op de client betekent dat er sneller op de gegevens kan worden gereageerd. Dit is typisch het geval bij client/server-situaties waarbij de gegevens uniek zijn voor de client, zoals een respons van de webserver die op maat is – bijvoorbeeld de gegevens die worden gebruikt om te renderen wanneer je een berichtje ontvangt van een vriend op Messenger. Het netto resultaat is dat je mobiele toestel pagina’s sneller laadt, minder batterij verbruikt en minder van je data-abonnement verbruikt. Met name Zstandard past veel beter bij de mobiele scenario’s dan andere algoritmes vanwege de manier waarop het met kleine gegevens omgaat.
Mogelijk nooit. Hoewel schijnbaar contra-intuïtief, is het vaak het geval dat een stuk van de gegevens – zoals back-ups of log-bestanden – nooit zal worden gedecomprimeerd, maar kan worden gelezen indien nodig. Voor dit soort gegevens moet compressie snel zijn, de gegevens klein maken (met een voor de situatie geschikte tijd/ruimte-ruil), en misschien een controlesom opslaan, maar verder onzichtbaar zijn. In het zeldzame geval dat de gegevens toch moeten worden gedecomprimeerd, wil je niet dat de compressie de operationele use case vertraagt. Snelle decompressie is gunstig omdat het vaak een klein deel van de gegevens is (zoals een specifiek bestand in de back-up of een bericht in een logbestand) dat snel moet worden gevonden.
In al deze gevallen biedt Zstandard de mogelijkheid om vele malen sneller te comprimeren en te decomprimeren dan gzip, waarbij de resulterende gecomprimeerde gegevens kleiner zijn.
Kleine gegevens
Er is nog een gebruikssituatie voor compressie die minder aandacht krijgt, maar heel belangrijk kan zijn: kleine gegevens. Dit zijn gebruikspatronen waarbij gegevens in kleine hoeveelheden worden geproduceerd en verbruikt, zoals JSON-berichten tussen een webserver en browser (doorgaans honderden bytes) of pagina’s met gegevens in een database (enkele kilobytes).
Databases bieden een interessante use case. Systemen zoals MySQL, PostgreSQL, en MongoDB slaan allemaal gegevens op die bedoeld zijn voor real-time toegang. Recente hardwarevoordelen, met name rond de proliferatie van flash (SSD) apparaten, hebben de balans tussen grootte en doorvoer fundamenteel veranderd – we leven nu in een wereld waar IOP’s (IO operaties per seconde) vrij hoog zijn, maar de capaciteit van onze opslagapparaten is lager dan toen harde schijven het datacenter regeerden.
Bovendien heeft flash een interessante eigenschap met betrekking tot schrijfduur – na duizenden schrijfbewerkingen naar hetzelfde deel van het apparaat, kan dat deel niet langer schrijfbewerkingen accepteren, wat vaak leidt tot het uit dienst nemen van het apparaat. Daarom is het logisch om te zoeken naar manieren om de hoeveelheid gegevens die wordt geschreven te verminderen, omdat dit meer gegevens per server kan betekenen en het apparaat langzamer kan opbranden. Datacompressie is een strategie hiervoor, en databases zijn ook vaak geoptimaliseerd voor prestaties, wat betekent dat lees- en schrijfprestaties even belangrijk zijn.
Er is echter een complicatie voor het gebruik van datacompressie met databases. Databases houden ervan om gegevens willekeurig te benaderen, terwijl de meeste typische gebruikssituaties voor compressie een volledig bestand in lineaire volgorde lezen. Dit is een probleem omdat gegevenscompressie in wezen werkt door de toekomst te voorspellen op basis van het verleden – de algoritmen bekijken uw gegevens sequentieel en voorspellen wat ze in de toekomst zouden kunnen zien. Hoe nauwkeuriger de voorspellingen, hoe kleiner de gegevens kunnen worden gemaakt.
Wanneer u kleine gegevens comprimeert, zoals pagina’s in een database of kleine JSON-documenten die naar uw mobiele apparaat worden verzonden, is er gewoon niet veel “verleden” om te gebruiken om de toekomst te voorspellen. Compressie-algoritmen hebben geprobeerd dit aan te pakken door vooraf gedeelde woordenboeken te gebruiken om effectief een jump-start te maken. Dit wordt gedaan door het vooraf delen van een statische set van “verleden” gegevens als een zaad voor de compressie.
Zstandard bouwt voort op deze aanpak met sterk geoptimaliseerde algoritmen en API’s voor woordenboekcompressie. Bovendien, Zstandard omvat tooling (zstd --train) voor het gemakkelijk maken van woordenboeken voor aangepaste toepassingen en voorzieningen voor het registreren van standaard woordenboeken voor het delen met grotere gemeenschappen. Terwijl de compressie varieert op basis van de gegevensmonsters, kan de compressie van kleine gegevens overal variëren van 2x tot 5x beter dan compressie zonder woordenboeken.
Woordenboeken in actie
Hoewel het moeilijk kan zijn om te spelen met een woordenboek in de context van een draaiende database (het vereist immers aanzienlijke wijzigingen aan de database), kunt u woordenboeken in actie zien met andere soorten kleine gegevens. JSON, de lingua franca van kleine gegevens in de moderne wereld, heeft de neiging om kleine, repetitieve records te zijn. Er zijn talloze openbare datasets beschikbaar; voor het doel van deze demonstratie zullen we de “gebruiker” dataset van GitHub gebruiken, beschikbaar via HTTP. Hier is een voorbeeld uit deze dataset:
{ "login": "octocat", "id": 1, "avatar_url": "https://github.com/images/error/octocat_happy.gif", "gravatar_id": "", "url": "https://api.github.com/users/octocat", "html_url": "https://github.com/octocat", "followers_url": "https://api.github.com/users/octocat/followers", "following_url": "https://api.github.com/users/octocat/following{/other_user}", "gists_url": "https://api.github.com/users/octocat/gists{/gist_id}", "starred_url": "https://api.github.com/users/octocat/starred{/owner}{/repo}", "subscriptions_url": "https://api.github.com/users/octocat/subscriptions", "organizations_url": "https://api.github.com/users/octocat/orgs", "repos_url": "https://api.github.com/users/octocat/repos", "events_url": "https://api.github.com/users/octocat/events{/privacy}", "received_events_url": "https://api.github.com/users/octocat/received_events", "type": "User", "site_admin": false }Zoals u kunt zien, is er nogal wat herhaling hier – we kunnen deze mooi comprimeren! Maar elke gebruiker is iets minder dan 1 KB, en de meeste compressie-algoritmes hebben echt meer data nodig om hun benen te strekken. Een set van 1.000 gebruikers kost ruwweg 850 KB om ongecomprimeerd op te slaan. Naïef gzip of zstd individueel toepassen op elk bestand brengt dit terug tot iets meer dan 300 KB; niet slecht! Maar als we een eenmalig, vooraf gedeeld woordenboek maken, met zstd, daalt de grootte tot 122 KB – waardoor de oorspronkelijke compressie ratio van 2.8x naar 6.9 gaat. Dit is een aanzienlijke verbetering, die out-of-box beschikbaar is met zstd:
$ zstd --train -o ../json.zdict -r .sorting 982 files of total size 0 MB ...finding patterns ...statistics ...Save dictionary of size 65599 into file ../json.zdict$ du -h --apparent-size .846K .$ zstd --rm -D ../json.zdict -r .$ du -h --apparent-size .122K .Kies een compressie niveau
Zoals hierboven getoond, biedt Zstandard een aanzienlijk aantal niveaus aan. Deze aanpassing is krachtig maar leidt tot moeilijke keuzes. De beste manier om te beslissen is uw gegevens te bekijken en te meten, en te beslissen welke afwegingen u wilt maken. Bij Facebook vinden we het standaardniveau 3 geschikt voor veel gebruikssituaties, maar van tijd tot tijd zullen we dit enigszins aanpassen, afhankelijk van wat ons knelpunt is (vaak proberen we een netwerkverbinding of schijfspoel te verzadigen); andere keren geven we meer om de opgeslagen grootte en zullen we een hoger niveau gebruiken.
Ultimately, voor de resultaten die het meest zijn afgestemd op uw behoeften, moet u zowel de hardware die u gebruikt als de gegevens waar u om geeft in overweging nemen – er zijn geen harde en snelle voorschriften die kunnen worden gemaakt zonder context. Wanneer u twijfelt, blijf dan bij het standaard niveau van 3 of iets tussen de 6 en 9 voor een goede afweging van snelheid tegen ruimte; bewaar niveau 20+ voor gevallen waar u echt alleen geeft om de grootte en niet om de compressie snelheid.
Probeer het eens
Zstandard is zowel een command line tool (zstd) als een bibliotheek. Het is geschreven in zeer portable C, waardoor het geschikt is voor vrijwel elk platform dat vandaag de dag wordt gebruikt – of het nu de servers zijn waarop uw bedrijf draait, uw laptop, of zelfs de telefoon in uw zak. U kunt het van onze github repository halen, het compileren met een eenvoudige make install, en het beginnen te gebruiken zoals u gzip zou gebruiken:
$ zstd access.logaccess.log : 8.07% (6695078 => 540336 bytes, access.log.zst)Zoals u zou verwachten, kunt u het gebruiken als onderdeel van een commando pijplijn, bijvoorbeeld om een back-up te maken van uw kritische MySQL database:
$ mysqldump --single-transaction --opt pokemon | zstd -q -o /srv/backups/mysqldump.sql.zstHet tar commando ondersteunt verschillende compressie implementaties out-of-box, dus zodra u Zstandard installeert, kunt u onmiddellijk werken met tarballs die met Zstandard zijn gecomprimeerd. Hier is een eenvoudig voorbeeld dat het gebruik toont met tar en het snelheidsverschil met gzip:
$ time tar -I zstd -cf linux-4.6.4.tar.zst linux-4.6.4tar -I zstd -cf linux-4.6.4.tar.zst linux-4.6.4 3.15s user 0.50s system 107% cpu 3.396 total$ time tar -zcf linux-4.6.4.tar.gz linux-4.6.4tar -zcf linux-4.6.4.tar.gz linux-4.6.4 13.74s user 0.43s system 102% cpu 13.784 totalBuiten het gebruik van de commandoregel, zijn er de APIs, gedocumenteerd in de header bestanden in het archief (begin hier voor een overzicht van de APIs). We voegen ook een zlib-compatibele wrapper API (libWrapper) toe voor eenvoudiger integratie met gereedschappen die al zlib interfaces hebben. Tenslotte voegen we een aantal voorbeelden bij, zowel van basis gebruik als van meer geavanceerd gebruik zoals woordenboeken en streaming, ook in de GitHub repository.
Er komt nog meer
W hoewel we 1.0 hebben bereikt en Zstandard klaar achten voor elke vorm van productie gebruik, zijn we nog niet klaar. Komende in toekomstige versies:
- Multi-threaded command line compressie voor nog snellere doorvoer op grote data sets, vergelijkbaar met de pigz tool voor zlib.
- Nieuwe compressie niveaus, in beide richtingen, die nog snellere compressie en hogere ratio’s mogelijk maken.
- Een door de gemeenschap onderhouden voorgedefinieerde set van compressie woordenboeken voor veel voorkomende data sets zoals JSON, HTML, en veel voorkomende netwerk protocollen.
We willen graag alle bijdragers bedanken, zowel van code als van feedback, die ons geholpen hebben om tot 1.0 te komen. Dit is nog maar het begin. We weten dat we uw hulp nodig hebben om Zstandard zijn potentieel te laten waarmaken. Zoals hierboven vermeld, kunt u Zstandard vandaag proberen door de broncode of vooraf gebouwde binaries van ons GitHub project te pakken, of, voor Mac gebruikers, installeren via homebrew (brew install zstd). We zouden het op prijs stellen als je ons feedback geeft en ons helpt bij het integreren met je favoriete open source projecten.
Footnotes
- Terwijl lossless datacompressie de focus is van dit bericht, bestaat er een verwant maar heel verschillend gebied van lossy datacompressie, voornamelijk gebruikt voor afbeeldingen, audio en video.
- Deflate, zlib, gzip – drie namen met elkaar verweven. Deflate is het algoritme dat wordt gebruikt door de zlib en gzip implementaties. Zlib is een bibliotheek die Deflate levert, en gzip is een command line tool die zlib gebruikt voor het Deflaten van gegevens en ook voor checksumming. Deze checksumming kan een aanzienlijke overhead hebben.
- Alle benchmarks zijn uitgevoerd op een Intel E5-2678 v3 die draait op 2,5 GHz op een Centos 7 machine. Command line tools (
zstdengzip) zijn gebouwd met het systeem GCC, 4.8.5. Algoritme-benchmarks uitgevoerd door lzbench werden gebouwd met GCC 6.
Geef een antwoord