Het hebben van inzicht in uw Java-toepassing is van cruciaal belang om te begrijpen hoe het nu werkt, hoe het een tijd in het verleden werkte, en het vergroten van uw inzicht in hoe het in de toekomst zou kunnen werken. Vaak is het analyseren van logs de snelste manier om te ontdekken wat er fout is gegaan, waardoor logging in Java van cruciaal belang is om de performance en gezondheid van je applicatie te garanderen, en om eventuele downtime te minimaliseren en verminderen. Het hebben van een gecentraliseerde logging- en monitoringoplossing helpt de Mean Time To Repair te verminderen door de effectiviteit van uw Ops- of DevOps-team te verbeteren.
Door het volgen van goede praktijken krijgt u meer waarde uit uw logs en maakt u het gemakkelijker om ze te gebruiken. U kunt gemakkelijker de hoofdoorzaak van fouten en slechte prestaties vaststellen en problemen oplossen voordat ze gevolgen hebben voor eindgebruikers. Dus laat me vandaag een aantal best practices met je delen waar je bij zou moeten zweren als je met Java applicaties werkt.
- Gebruik een standaard logging bibliotheek
- Selecteer je appenders verstandig
- Gebruik betekenisvolle berichten
- Logging Java Stack Traces
- Logging Java Exceptions
- Gebruik het juiste log-niveau
- Log in JSON
- Houd de logstructuur consistent
- Voeg context toe aan uw logs
- Java Logging in Containers
- Don’t Log Too Much or Too Little
- Houd het publiek in gedachten
- Vermijd het loggen van gevoelige informatie
- Gebruik een Log Management Oplossing om & Java Logs te Centraliseren
- Conclusie
- Aandelen
Gebruik een standaard logging bibliotheek
Logging in Java kan op een paar verschillende manieren worden gedaan. Je kunt een speciale logbibliotheek gebruiken, een algemene API, of zelfs logs naar een bestand of direct naar een speciaal logsysteem schrijven. Denk echter vooruit bij het kiezen van de logging library voor je systeem. Dingen om te overwegen en te evalueren zijn prestatie, flexibiliteit, appenders voor nieuwe log centralisatie oplossingen, enzovoort. Als je jezelf direct bindt aan een enkel framework kan de overstap naar een nieuwere library een aanzienlijke hoeveelheid werk en tijd kosten. Houd dat in gedachten en ga voor de API die je de flexibiliteit geeft om in de toekomst van logboekbibliotheek te wisselen. Net als bij de overstap van Log4j naar Logback en naar Log4j 2, hoef je bij het gebruik van de SLF4J API alleen de dependency te veranderen, niet de code.
Als je nieuw bent met Java logging libraries, bekijk dan onze beginners gidsen:
- Log4j Tutorial
- Logback Tutorial
- Log4j2 Tutorial
- SLF4J Tutorial
Selecteer je appenders verstandig
Appenders definiëren waar je log events zullen worden afgeleverd. De meest voorkomende appenders zijn de Console en Bestand appenders. Hoewel ze nuttig en algemeen bekend zijn, voldoen ze misschien niet aan uw eisen. Het kan bijvoorbeeld zijn dat u uw logs op een asynchrone manier wilt schrijven of dat u uw logs over het netwerk wilt versturen met appenders zoals die voor Syslog, zoals deze:
<Appenders> <Console name="Console" target="SYSTEM_OUT"> <PatternLayout pattern="%d %level %c - %m%n"/> </Console> <Syslog name="Syslog" host="logsene-syslog-receiver.sematext.com" port="514" protocol="TCP" format="RFC5424" appName="11111111-2222-3333-4444-555555555555" facility="LOCAL0" mdcId="mdc" newLine="true"/></Appenders>
Houd echter in gedachten dat het gebruik van appenders zoals hierboven getoond uw logboekpijplijn gevoelig maakt voor netwerkfouten en communicatiestoringen. Dat kan ertoe leiden dat logs niet naar hun bestemming worden verzonden, wat onaanvaardbaar kan zijn. Je wilt ook voorkomen dat logging je systeem beïnvloedt als de appender op een blokkerende manier is ontworpen. Bekijk voor meer informatie onze blogpost Logging libraries vs Log shippers.
Gebruik betekenisvolle berichten
Een van de cruciale dingen bij het maken van logs, maar een van de niet zo eenvoudige, is het gebruik van betekenisvolle berichten. Uw log events moeten berichten bevatten die uniek zijn voor de gegeven situatie, ze duidelijk beschrijven en de persoon die ze leest informeren. Stel je voor dat er een communicatiefout optreedt in je applicatie. Je zou het als volgt kunnen doen:
LOGGER.warn("Communication error");
Maar je zou ook een bericht als dit kunnen maken:
LOGGER.warn("Error while sending documents to events Elasticsearch server, response code %d, response message %s. The message sending will be retried.", responseCode, responseMessage);
Je kunt gemakkelijk zien dat het eerste bericht de persoon die de logs bekijkt informeert over enkele communicatie problemen. Die persoon zal waarschijnlijk de context hebben, de naam van de logger, en het regelnummer waar de waarschuwing gebeurde, maar dat is alles. Om meer context te krijgen zou die persoon naar de code moeten kijken, weten op welke versie van de code de fout betrekking heeft, enzovoort. Dit is niet leuk en vaak niet gemakkelijk, en zeker niet iets wat men wil doen terwijl men probeert een productie probleem zo snel mogelijk op te lossen.
De tweede melding is beter. Het geeft exacte informatie over wat voor soort communicatie fout is gebeurd, wat de applicatie aan het doen was op het moment, welke foutcode het kreeg, en wat het antwoord van de externe server was. Tenslotte informeert het ook dat het verzenden van het bericht opnieuw zal worden geprobeerd. Het werken met dergelijke berichten is beslist gemakkelijker en aangenamer.
Ten slotte, denk na over de grootte en de verbositeit van het bericht. Log geen informatie die te verbose is. Deze gegevens moeten ergens worden opgeslagen om nuttig te zijn. Eén heel lang bericht zal geen probleem zijn, maar als die regel honderden keren in een minuut wordt herhaald en je veel verbose logs hebt, kan het langer bewaren van zulke gegevens problematisch zijn en uiteindelijk ook meer kosten.
Logging Java Stack Traces
Eén van de zeer belangrijke onderdelen van Java logging zijn de Java stack traces. Kijk eens naar de volgende code:
package com.sematext.blog.logging;import org.apache.logging.log4j.LogManager;import org.apache.logging.log4j.Logger;import java.io.IOException;public class Log4JExceptionNoThrowable { private static final Logger LOGGER = LogManager.getLogger(Log4JExceptionNoThrowable.class); public static void main(String args) { try { throw new IOException("This is an I/O error"); } catch (IOException ioe) { LOGGER.error("Error while executing main thread"); } }}
De bovenstaande code zal resulteren in een exception die wordt gegooid en een log bericht dat wordt afgedrukt naar de console met onze standaard configuratie ziet er als volgt uit:
11:42:18.952 ERROR - Error while executing main thread
Zoals u kunt zien is er niet veel informatie daar. We weten alleen dat het probleem zich voordeed, maar we weten niet waar het gebeurde, of wat het probleem was, enz. Niet erg informatief.
Nu, kijk naar dezelfde code met een iets aangepast logging statement:
package com.sematext.blog.logging;import org.apache.logging.log4j.LogManager;import org.apache.logging.log4j.Logger;import java.io.IOException;public class Log4JException { private static final Logger LOGGER = LogManager.getLogger(Log4JException.class); public static void main(String args) { try { throw new IOException("This is an I/O error"); } catch (IOException ioe) { LOGGER.error("Error while executing main thread", ioe); } }}
Zoals je kunt zien, hebben we deze keer het exception object zelf in ons log bericht opgenomen:
LOGGER.error("Error while executing main thread", ioe);
Dat zou resulteren in het volgende error log in de console met onze standaard configuratie:
11:30:17.527 ERROR - Error while executing main threadjava.io.IOException: This is an I/O error at com.sematext.blog.logging.Log4JException.main(Log4JException.java:13)
Het bevat relevante informatie – d.w.z.d.w.z. de naam van de klasse, de methode waar het probleem zich voordeed, en tenslotte het regelnummer waar het probleem zich voordeed. Natuurlijk, in real-life situaties, zullen de stack traces langer zijn, maar je zou ze moeten opnemen om je genoeg informatie te geven voor een goede debugging.
Om meer te leren over hoe om te gaan met Java stack traces met Logstash zie Handling Multiline Stack Traces with Logstash of kijk naar Logagent die dat voor je kan doen out of the box.
Logging Java Exceptions
Wanneer je te maken hebt met Java exceptions en stack traces moet je niet alleen denken aan de hele stack trace, de regels waar het probleem verscheen, enzovoort. Je moet ook nadenken over hoe je niet met uitzonderingen om moet gaan.
Vermijd het stilzwijgend negeren van uitzonderingen. U wilt niet iets belangrijks negeren. Doe bijvoorbeeld niet het volgende:
try { throw new IOException("This is an I/O error");} catch (IOException ioe) {}
Ook, log niet zomaar een exception en gooi het verder. Dat betekent dat je het probleem gewoon de executiestapel hebt opgeduwd. Vermijd dit soort dingen ook:
try { throw new IOException("This is an I/O error");} catch (IOException ioe) { LOGGER.error("I/O error occurred during request processing", ioe); throw ioe;}
Als je geïnteresseerd bent om meer te leren over uitzonderingen, lees dan onze gids over Java exception handling waar we alles behandelen van wat ze zijn tot hoe ze op te vangen en te repareren.
Gebruik het juiste log-niveau
Wanneer je je applicatie code schrijft, denk dan twee keer na over een gegeven log bericht. Niet elk stukje informatie is even belangrijk en niet elke onverwachte situatie is een fout of een kritische melding. Gebruik de logging niveaus ook consequent – informatie van een vergelijkbaar type zou op een vergelijkbaar niveau van ernst moeten zijn.
Zowel SLF4J facade als elk Java logging raamwerk dat je gaat gebruiken bieden methoden die gebruikt kunnen worden om een juist log niveau aan te geven. Bijvoorbeeld:
LOGGER.error("I/O error occurred during request processing", ioe);
Log in JSON
Als we van plan zijn om te loggen en de gegevens handmatig in een bestand of de standaard output te bekijken, dan zal de geplande logging meer dan prima zijn. Het is gebruikersvriendelijker – we zijn er aan gewend. Maar dat is alleen haalbaar voor zeer kleine toepassingen en zelfs dan wordt voorgesteld om iets te gebruiken dat je in staat stelt om de metriek gegevens te correleren met de logs. Dergelijke operaties in een terminal venster zijn niet leuk en soms is het gewoon niet mogelijk. Als je logs wilt opslaan in het log management en centralisatie systeem, dan moet je loggen in JSON. Dat komt omdat parsing niet gratis is – het betekent meestal het gebruik van reguliere expressies. Natuurlijk kun je die prijs betalen in de log shipper, maar waarom zou je dat doen als je gemakkelijk in JSON kunt loggen. Loggen in JSON betekent ook eenvoudig omgaan met stack traces, dus nog een voordeel. Je kunt ook gewoon naar een Syslog compatibele bestemming loggen, maar dat is een ander verhaal.
In de meeste gevallen is het voldoende om de juiste configuratie op te nemen om logging in JSON in je Java logging framework mogelijk te maken. Laten we bijvoorbeeld aannemen dat we het volgende logbericht in onze code hebben opgenomen:
LOGGER.info("This is a log message that will be logged in JSON!");
Om Log4J 2 te configureren om logberichten in JSON te schrijven, zouden we de volgende configuratie opnemen:
<?xml version="1.0" encoding="UTF-8"?><Configuration status="WARN"> <Appenders> <Console name="Console" target="SYSTEM_OUT"> <JSONLayout compact="true" eventEol="true"> </JSONLayout> </Console> </Appenders> <Loggers> <Root level="info"> <AppenderRef ref="Console"/> </Root> </Loggers></Configuration>
Het resultaat zou er als volgt uitzien:
{"instant":{"epochSecond":1596030628,"nanoOfSecond":695758000},"thread":"main","level":"INFO","loggerName":"com.sematext.blog.logging.Log4J2JSON","message":"This is a log message that will be logged in JSON!","endOfBatch":false,"loggerFqcn":"org.apache.logging.slf4j.Log4jLogger","threadId":1,"threadPriority":5}
Houd de logstructuur consistent
De structuur van uw loggebeurtenissen moet consistent zijn. Dit geldt niet alleen binnen een enkele applicatie of set van microservices, maar zou moeten worden toegepast over je hele applicatie stack. Met gelijk gestructureerde log events is het makkelijker om ze te bekijken, te vergelijken, te correleren, of gewoon op te slaan in een speciale data store. Het is gemakkelijker om gegevens van uw systemen te bekijken als u weet dat ze gemeenschappelijke velden hebben zoals ernst en hostnaam, zodat u de gegevens gemakkelijk kunt slicen en dice-en op basis van die informatie. Voor inspiratie, kijk eens naar Sematext Common Schema, zelfs als je geen Sematext gebruiker bent.
Het behouden van de structuur is natuurlijk niet altijd mogelijk, omdat je volledige stack bestaat uit extern ontwikkelde servers, databases, zoekmachines, wachtrijen, etc., die elk hun eigen set van logs en logformaten hebben. Echter, om de geestelijke gezondheid van jou en je team te bewaren, minimaliseer je het aantal verschillende logberichtstructuren dat je kunt beheersen.
Een manier om een gemeenschappelijke structuur te behouden, is om hetzelfde patroon te gebruiken voor je logboeken, althans voor degenen die hetzelfde logboekraamwerk gebruiken. Als uw applicaties en microservices bijvoorbeeld Log4J 2 gebruiken, zou u een patroon als dit kunnen gebruiken:
<PatternLayout> <Pattern>%d %p %c{35}:%L - %m%n</Pattern></PatternLayout>
Door een enkele of een zeer beperkte set patronen te gebruiken, kunt u er zeker van zijn dat het aantal logformaten klein en beheersbaar blijft.
Voeg context toe aan uw logs
Informatiecontext is belangrijk en voor ons ontwikkelaars en DevOps is een logbericht informatie. Kijk eens naar de volgende log entry:
An error occurred!
We weten dat er ergens in de applicatie een fout is opgetreden. We weten niet waar het gebeurde, we weten niet wat voor soort fout het was, we weten alleen wanneer het gebeurde. Kijk nu eens naar een bericht met iets meer contextuele informatie:
com.sematext.blog.logging.ParsingErrorExample - A parsing error occurred for user with id 1234!
Hetzelfde log record, maar veel meer contextuele informatie. We weten in welke thread het gebeurde, we weten bij welke klasse de fout werd gegenereerd. We hebben het bericht ook aangepast om de gebruiker te vermelden voor wie de fout zich voordeed, zodat we terug kunnen gaan naar de gebruiker indien nodig. We kunnen ook extra informatie toevoegen zoals diagnostische contexten. Denk na over wat je nodig hebt en voeg het toe.
Om context informatie op te nemen hoef je niet veel te doen als het gaat om de code die verantwoordelijk is voor het genereren van het log bericht. Bijvoorbeeld, de PatternLayout in Log4J 2 geeft je alles wat je nodig hebt om de context informatie op te nemen. Je kunt een heel eenvoudig patroon gebruiken zoals dit:
<PatternLayout pattern="%d{HH:mm:ss.SSS} %-5level - %msg%n"/>
Dat zal resulteren in een logbericht dat lijkt op het volgende:
17:13:08.059 INFO - This is the first INFO level log message!
Maar je kunt ook een patroon gebruiken dat veel meer informatie zal bevatten:
<PatternLayout pattern="%d{HH:mm:ss.SSS} %c %l %-5level - %msg%n"/>
Dat zal resulteren in een logbericht zoals dit:
17:24:01.710 com.sematext.blog.logging.Log4j2 com.sematext.blog.logging.Log4j2.main(Log4j2.java:12) INFO - This is the first INFO level log message!
Java Logging in Containers
Denk na over de omgeving waarin je applicatie zal draaien. Er is een verschil in logging configuratie wanneer je je Java code in een VM of op een bare-metal machine draait, het is anders wanneer je het in een containerized omgeving draait, en natuurlijk is het anders wanneer je je Java of Kotlin code op een Android toestel draait.
Om logging in een containerized omgeving op te zetten moet je de aanpak kiezen die je wilt nemen. U kunt gebruik maken van een van de meegeleverde logging drivers – zoals de journald, logagent, Syslog, of JSON-bestand. Om dat te doen, moet je onthouden dat je applicatie het logbestand niet naar de container ephemeral storage moet schrijven, maar naar de standaard output. Dat kan eenvoudig gedaan worden door je logging framework te configureren om de log naar de console te schrijven. Bijvoorbeeld, met Log4J 2 zou je gewoon de volgende appender configuratie gebruiken:
<Appenders> <Console name="Console" target="SYSTEM_OUT"> <PatternLayout pattern="%d{HH:mm:ss.SSS} - %m %n"/> </Console></Appenders>
Je kunt de logging drivers ook helemaal weglaten en logs direct naar je gecentraliseerde logs oplossing sturen, zoals onze Sematext Cloud:
<Appenders> <Console name="Console" target="SYSTEM_OUT"> <PatternLayout pattern="%d %level %c - %m%n"/> </Console> <Syslog name="Syslog" host="logsene-syslog-receiver.sematext.com" port="514" protocol="TCP" format="RFC5424" appName="11111111-2222-3333-4444-555555555555" facility="LOCAL0" mdcId="mdc" newLine="true"/></Appenders>
Don’t Log Too Much or Too Little
Als ontwikkelaars hebben we de neiging om te denken dat alles belangrijk kan zijn – we hebben de neiging om elke stap van ons algoritme of bedrijfscode als belangrijk te markeren. Aan de andere kant doen we soms het tegenovergestelde – we loggen niet waar we zouden moeten loggen of we loggen alleen FATAL en ERROR log niveaus. Beide benaderingen zullen het niet erg goed doen. Bij het schrijven van je code en het toevoegen van logging, denk na over wat belangrijk zal zijn om te zien of de toepassing goed werkt en wat belangrijk zal zijn om een verkeerde toestand van de toepassing te kunnen diagnosticeren en oplossen. Gebruik dit als je leidraad om te beslissen wat en waar te loggen. Houd in gedachten dat het toevoegen van teveel logs zal leiden tot informatiemoeheid en het niet hebben van genoeg informatie zal resulteren in het onvermogen om problemen op te lossen.
Houd het publiek in gedachten
In de meeste gevallen zult u niet de enige persoon zijn die naar de logs kijkt. Onthoud dat altijd. Er zijn meerdere actoren die naar de logs kunnen kijken.
De ontwikkelaar kan naar de logs kijken voor troubleshooting of tijdens debug-sessies. Voor zulke mensen kunnen logs gedetailleerd en technisch zijn, en zeer diepgaande informatie bevatten over hoe het systeem draait. Zo’n persoon zal ook toegang hebben tot de code of zal de code zelfs kennen en daar kun je van uitgaan.
Dan zijn er DevOps. Voor hen zullen log-events nodig zijn voor het oplossen van problemen en moeten ze informatie bevatten die nuttig is bij diagnostiek. U kunt uitgaan van de kennis van het systeem, de architectuur, de componenten en de configuratie van de componenten, maar u moet niet uitgaan van de kennis over de code van het platform.
Ten slotte kunnen uw applicatielogs worden gelezen door uw gebruikers zelf. In zo’n geval moeten de logs voldoende beschrijvend zijn om het probleem te kunnen oplossen, als dat al mogelijk is, of voldoende informatie geven aan het ondersteuningsteam dat de gebruiker helpt. Om Sematext bijvoorbeeld te gebruiken voor monitoring moet een monitoring agent worden geïnstalleerd en uitgevoerd. Als u zich achter een zeer restrictieve firewall bevindt en de agent kan geen metrieken naar Sematext verzenden, dan logt hij gericht fouten waarnaar Sematext gebruikers zelf ook kunnen kijken.
We zouden nog verder kunnen gaan en nog meer actoren kunnen identificeren die in logs zouden kunnen kijken, maar deze verkorte lijst zou u een glimp moeten geven van waar u aan moet denken bij het schrijven van uw logberichten.
Vermijd het loggen van gevoelige informatie
Sensitieve informatie zou niet in logs aanwezig moeten zijn of zou moeten worden gemaskeerd. Wachtwoorden, creditcardnummers, sofi-nummers, toegangstokens, enzovoort – dat alles kan gevaarlijk zijn als het uitlekt of toegankelijk is voor mensen die het niet mogen zien. Er zijn twee dingen die u zou moeten overwegen.
Bedenk of gevoelige informatie echt essentieel is voor het oplossen van problemen. Misschien is het voldoende om in plaats van een creditcardnummer de informatie over de transactie-identificator en de datum van de transactie te bewaren? Misschien is het niet nodig om het sofi-nummer in de logs te bewaren wanneer u gemakkelijk de gebruikersidentificatie kunt opslaan. Denk na over zulke situaties, denk na over de gegevens die je opslaat, en schrijf alleen gevoelige gegevens weg als het echt nodig is.
Het tweede is het versturen van logs met gevoelige informatie naar een hosted logs service. Er zijn maar heel weinig uitzonderingen waarbij het volgende advies niet moet worden opgevolgd. Als je logs gevoelige informatie bevatten en moeten bevatten, maskeer of verwijder ze dan voordat je ze naar je gecentraliseerde logsopslag stuurt. De meeste populaire log shippers, zoals onze eigen Logagent, bevatten functionaliteit die het verwijderen of maskeren van gevoelige gegevens mogelijk maakt.
Ten slotte kan het maskeren van gevoelige informatie worden gedaan in het logging framework zelf. Laten we eens kijken hoe dit kan worden gedaan door Log4j 2 uit te breiden. Onze code die log events produceert ziet er als volgt uit (volledig voorbeeld is te vinden op Sematext Github):
public class Log4J2Masking { private static Logger LOGGER = LoggerFactory.getLogger(Log4J2Masking.class); private static final Marker SENSITIVE_DATA_MARKER = MarkerFactory.getMarker("SENSITIVE_DATA_MARKER"); public static void main(String args) { LOGGER.info("This is a log message without sensitive data"); LOGGER.info(SENSITIVE_DATA_MARKER, "This is a a log message with credit card number 1234-4444-3333-1111 in it"); }}
Als je het hele voorbeeld van Github zou uitvoeren, zou de output er als volgt uitzien:
21:20:42.099 - This is a log message without sensitive data21:20:42.101 - This is a a log message with credit card number ****-****-****-**** in it
Je kunt zien dat het creditcardnummer is gemaskeerd. Dit werd gedaan omdat we een aangepaste Convertor hebben toegevoegd die controleert of de gegeven Marker wordt doorgegeven langs de log event en probeert een gedefinieerd patroon te vervangen. De implementatie van zo’n Converter ziet er als volgt uit:
@Plugin(name = "sample_logging_mask", category = "Converter")@ConverterKeys("sc")public class LoggingConverter extends LogEventPatternConverter { private static Pattern PATTERN = Pattern.compile("\b({4})-({4})-({4})-({4})\b"); public LoggingConverter(String options) { super("sc", "sc"); } public static LoggingConverter newInstance(final String options) { return new LoggingConverter(options); } @Override public void format(LogEvent event, StringBuilder toAppendTo) { String message = event.getMessage().getFormattedMessage(); String maskedMessage = message; if (event.getMarker() != null && "SENSITIVE_DATA_MARKER".compareToIgnoreCase(event.getMarker().getName()) == 0) { Matcher matcher = PATTERN.matcher(message); if (matcher.find()) { maskedMessage = matcher.replaceAll("****-****-****-****"); } } toAppendTo.append(maskedMessage); }}
Het is erg eenvoudig en zou op een meer geoptimaliseerde manier geschreven kunnen worden en zou ook alle mogelijke formaten van credit card nummers moeten kunnen verwerken, maar het is voldoende voor dit doel.
Voordat we de code gaan uitleggen, wil ik je ook het log4j2.xml configuratie bestand voor dit voorbeeld laten zien:
<?xml version="1.0" encoding="UTF-8"?><Configuration status="WARN" packages="com.sematext.blog.logging"> <Appenders> <Console name="Console" target="SYSTEM_OUT"> <PatternLayout pattern="%d{HH:mm:ss.SSS} - %sc %n"/> </Console> </Appenders> <Loggers> <Root level="info"> <AppenderRef ref="Console"/> </Root> </Loggers></Configuration>
Zoals je kunt zien, hebben we het packages attribuut toegevoegd in onze Configuratie om het framework te vertellen waar het moet zoeken naar onze converter. Dan hebben we het %sc patroon gebruikt om het log bericht te geven. We doen dat omdat we het standaard %m patroon niet kunnen overschrijven. Zodra Log4j2 ons %sc patroon vindt zal het onze converter gebruiken die de geformatteerde boodschap van de log event neemt en een eenvoudige regex gebruikt en de data vervangt als het gevonden is. Zo simpel is het.
Eén ding dat hier opvalt is dat we de Marker functionaliteit gebruiken. Regex matching is duur en we willen dat niet voor elk logbericht doen. Daarom markeren we de log events die moeten worden verwerkt met de aangemaakte Marker, zodat alleen de gemarkeerde worden gecontroleerd.
Gebruik een Log Management Oplossing om & Java Logs te Centraliseren
Met de complexiteit van de applicaties, zal het volume van uw logs ook groeien. U kunt wegkomen met het loggen naar een bestand en alleen logs gebruiken wanneer troubleshooting nodig is, maar wanneer de hoeveelheid gegevens groeit, wordt het snel moeilijk en traag om op deze manier troubleshooting te doen. Wanneer dit gebeurt, overweeg dan het gebruik van een log management oplossing om uw logs te centraliseren en te monitoren. U kunt kiezen voor een interne oplossing op basis van open-sourcesoftware, zoals Elastic Stack, of gebruikmaken van een van de logbeheertools die op de markt verkrijgbaar zijn, zoals Sematext Logs.
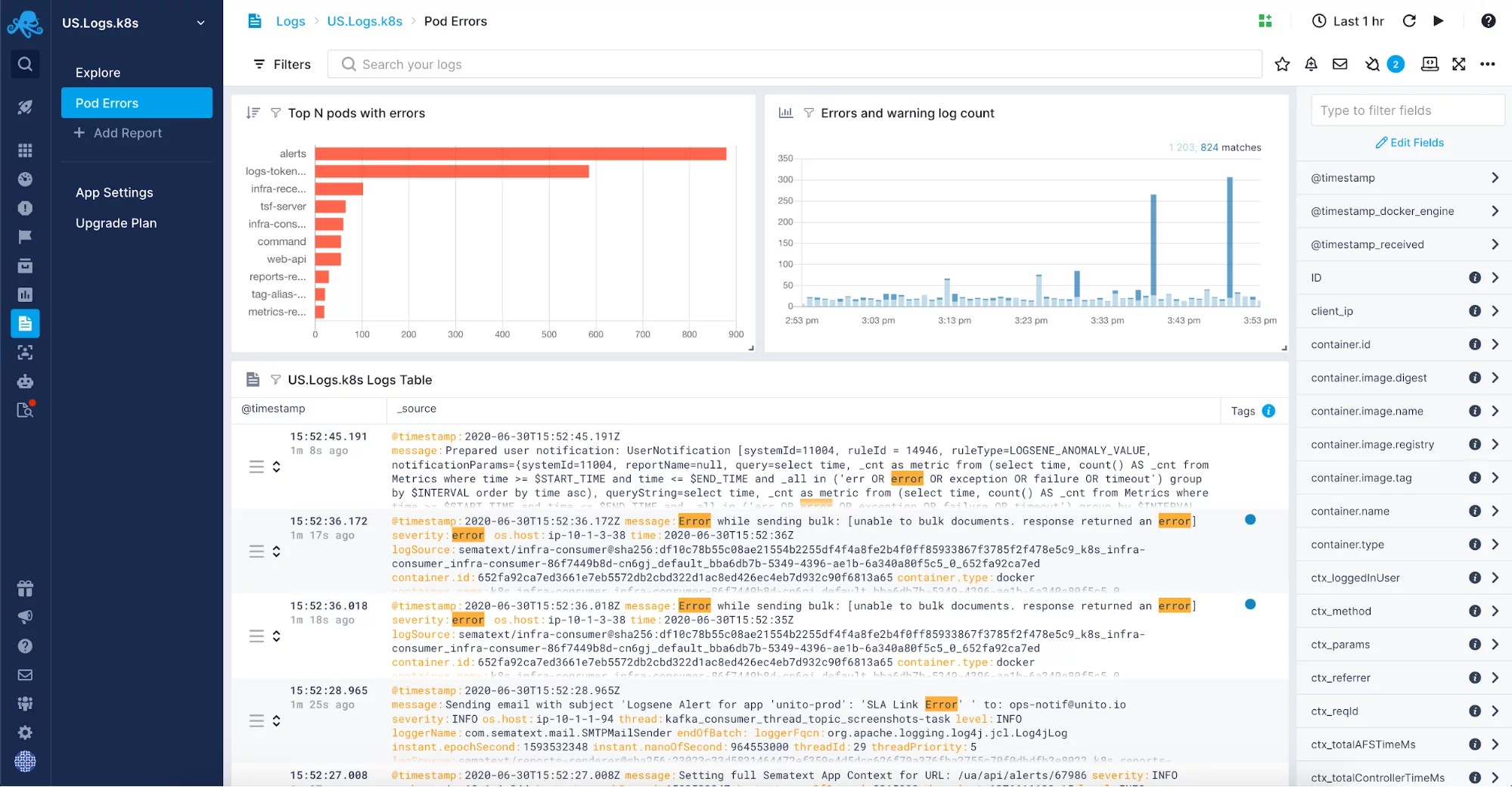
Een volledig beheerde oplossing voor het centraliseren van logs geeft u de vrijheid om niet nog een, meestal vrij complex, onderdeel van uw infrastructuur te hoeven beheren. In plaats daarvan kunt u zich concentreren op uw toepassing en hoeft u alleen de verzending van logboeken in te stellen. Misschien wil je logs zoals JVM garbage collection logs opnemen in je managed log oplossing. Nadat je ze hebt ingeschakeld voor je applicaties en systemen die op de JVM werken, zul je de logs op één plaats willen verzamelen voor log-correlatie, log-analyse, en om je te helpen de garbage collection in de JVM instances af te stellen. Dergelijke logs gecorreleerd met metrieken zijn een onschatbare bron van informatie voor het oplossen van garbage collection-gerelateerde problemen.
Als u geïnteresseerd bent om te zien hoe Sematext Logs zich verhoudt tot soortgelijke oplossingen, ga dan naar ons artikel over de beste log management software of de blog post waar we een aantal van de top log analyse tools beoordelen, maar we raden u aan de 14-dagen gratis proefversie te gebruiken om de functies volledig te verkennen. Probeer het en ontdek het zelf!
Conclusie
Het integreren van elke goede praktijk is misschien niet eenvoudig om meteen te implementeren, vooral voor applicaties die al live zijn en in productie werken. Maar als je de tijd neemt en de suggesties de een na de ander uitrolt, zul je een toename zien in de bruikbaarheid van je logs. Voor meer tips over hoe je het meeste uit je logs kunt halen, raden we je aan om ook ons andere artikel over logging best practices door te nemen, waar we de ins en outs uitleggen die je zou moeten volgen, ongeacht het type app waar je mee werkt. En vergeet niet dat we bij Sematext organisaties helpen met hun logging-instellingen door loggingconsultancy aan te bieden, dus als u problemen ondervindt, staan we u graag te woord.
Geef een antwoord