人々は、歴史上のどの時期よりも速いペースで、データを作成、共有、および保存しています。 データの保存と送信の革新に関して、Facebook では、より大きなハード ドライブやより高速なネットワーク機器などのハードウェアだけでなく、ソフトウェアも進化させています。 圧縮とは、テキストや画像などのデジタルデータを、元のデータよりも少ないビット数でエンコードすることで、データ処理を支援するソフトウェアです。 圧縮されたファイルは、ハードディスクの容量を減らし、他のシステムへの転送を高速化します。 しかし、情報の圧縮と解凍には、時間というトレードオフがあります。 より小さいファイルへの圧縮に時間がかかればかかるほど、データの処理に時間がかかります。
今日、データ圧縮標準として君臨しているのは、Zip、gzip、および zlib の中核アルゴリズムである Deflate です。 20 年間にわたり、速度とスペースの素晴らしいバランスを提供してきた結果、ほとんどすべての最新の電子デバイスで使用されています (そして、偶然ではありませんが、あなたが読んでいるブログ投稿のすべてのバイトを送信するために使用されています)。 長年にわたり、他のアルゴリズムがより優れた圧縮やより高速な圧縮を提供してきましたが、その両方が提供されることはほとんどありませんでした。 Zstandard 1.0 は、最新のハードウェアに対応し、より小さく、より速く圧縮できるように設計された新しい圧縮アルゴリズムと実装です。 Zstandard は、Finite State Entropy のような最近の圧縮のブレークスルーをパフォーマンス優先の設計と組み合わせ、そして、最新の CPU のユニークな特性に合わせて実装を最適化します。 その結果、他の圧縮アルゴリズムが行っているトレードオフを改善し、非常に高速な解凍速度で幅広い応用が可能になりました。 ZstandardはBSDライセンスで提供されており、現在のアルゴリズムが適用できない多くの場合を含め、ほぼすべての可逆圧縮シナリオで使用できるように設計されています。
圧縮の比較
圧縮アルゴリズムと実装を比較するための 3 つの標準的なメトリックがあります:
- 圧縮比。 元のサイズ (分子) と圧縮後のサイズ (分母) を比較し、1.0 以上のサイズ比として単位なしのデータで測定します。
- 圧縮速度: データをどれだけ速く小さくできるか、消費した入力データの MB/秒で測定します。
- 伸長速度: 圧縮されたデータから元のデータをどれだけ速く復元できるか、圧縮データからデータを生成する速度について MB/s で測定。 しかし、Zstandard は zlib と同様に、さまざまな種類のデータに対する汎用圧縮のためのものです。 Zstandardが期待されるアルゴリズムを表現するために、この記事では、毎日使われる典型的なデータ型を表すファイルのデータセットであるSilesiaコーパスを使用することにします。
今日一般的に使用されているアルゴリズムと実装には、zlib、lz4、および xz があります。 これらのアルゴリズムはそれぞれ異なるトレードオフを提供します。lz4 は速度を、xz はより高い圧縮率を、そして zlib は速度とサイズの良いバランスを目指しています。 下の表は、Silesia コーパスのアルゴリズムのデフォルトの圧縮比と速度の大まかなトレードオフを、アルゴリズムの生の性能をモデル化するための純粋なインメモリ ベンチマークである lzbench でアルゴリズムを比較することによって示しています。 最速のアルゴリズムである lz4 は低い圧縮率になり、最高の圧縮率を持つ xz は遅い圧縮速度に悩まされます。 しかし、Zstandardはデフォルトの設定で、zlibと同じ比率で圧縮しながら、圧縮速度と解凍速度の両方で大幅な改善を示しています。
圧縮がより大きなアプリケーションに組み込まれている場合、純粋なアルゴリズムのパフォーマンスは重要ですが、圧縮のためにコマンドライン ツールも使用することは非常に一般的です (たとえば、ログ ファイル、tarball、または保存や転送のためのその他の同様のデータを圧縮する場合など)。 このような場合、性能はチェックサムのようなオーバーヘッドに影響されることが多い。 このグラフは、システムのデフォルトのコンパイラーでビルドされた Centos 7 上での gzip と zstd コマンドライン ツールの比較を示しています。
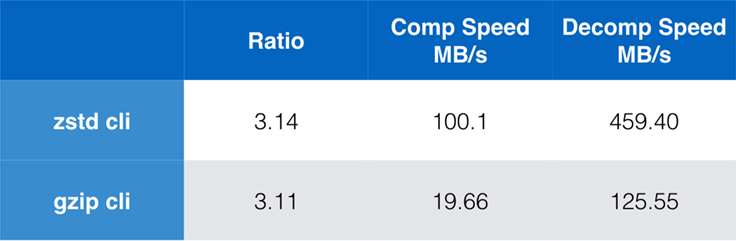
テストはそれぞれ 10 回実施し、最小限の時間を取り、ファイルシステムのオーバーヘッドを避けるために ramdisk で実施されました。 これらはコマンドでした (両方のツールのデフォルトの圧縮レベルを使用):
zstd -c -3 silesia.tar > silesia.tar.zst # 67,432,740 byteszstd -d -c silesia.tar.zst > /dev/nullgzip -c -6 silesia.tar > silesia.tar.gz # 68,235,522 bytesgzip -d -c silesia.tar.gz > /dev/nullScalability
アルゴリズムが拡張可能であれば、さまざまな要件に適応する能力があり、Zstandard は現在の状況に優れ、将来に向けて拡張できるように設計されています。 ほとんどのアルゴリズムは、時間と空間のトレードオフに基づく「レベル」を持っています。 レベルが高いほど、圧縮速度は低下しますが、より大きな圧縮を達成することができます。 Zlibは9つの圧縮レベルを提供し、Zstandardは現在22のレベルを提供しています。これにより、将来のデータに対する圧縮速度と比率の柔軟できめ細かいトレードオフが可能になります。 例えば、速度が最も重要な場合はレベル1、サイズが最も重要な場合はレベル22を使用することができます。
以下は、Zstandard と zlib のすべてのレベルで達成された圧縮速度と比率のグラフです。 X 軸は 1 秒あたりのメガバイト数で減少する対数スケールで、Y 軸は達成された圧縮率です。 アルゴリズムを比較するために、速度を選択すると、その速度でアルゴリズムが達成するさまざまな比率を見ることができます。 同様に、比率を選択し、そのレベルを達成したときのアルゴリズムの速度を確認できます。
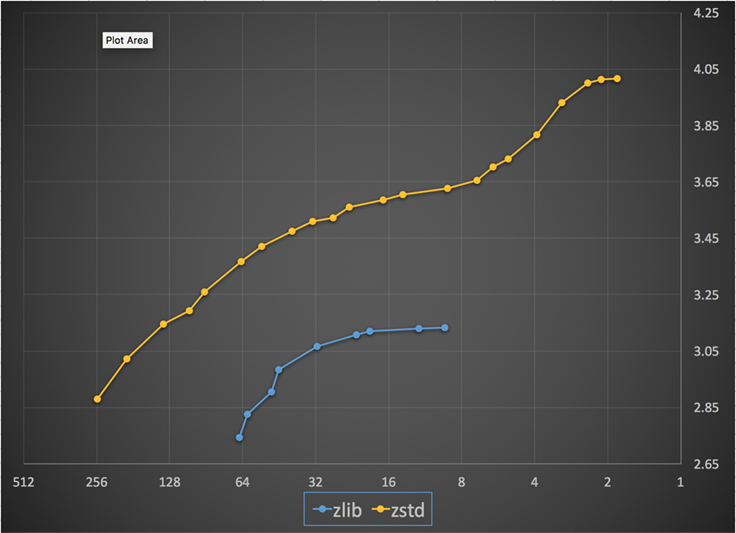
任意の垂直線 (すなわち、圧縮速度) に対して、Zstandard はより高い圧縮率を達成します。 Silesia コーパスでは、比率に関係なく、解凍速度は Zstandard で約 550 MB/秒、zlib で約 270 MB/秒でした。 このグラフは、Zstandardと代替品の間のもう一つの違いを示しています。 Zstandardは、1つのアルゴリズムと実装を使用することで、各ユースケースに対してより細かいチューニングを行うことが可能です。 つまり、Zstandardは、解凍速度の大幅な優位性を維持しながら、最速かつ最高レベルの圧縮アルゴリズムと競争することができます。 これらの改善は、データ転送の高速化とストレージ要件の縮小に直接つながります。
言い換えれば、zlib と比較して、Zstandard は次のように拡張します。
- 同じ圧縮率で、大幅に速く圧縮します。
- 同じ圧縮速度では、大幅に小さくなります: 10 ~ 15% です。
- 圧縮率に関係なく、解凍時にほぼ 2 倍速くなります。コマンド ライン ツールの数値ではさらに大きな違いがあり、3 倍以上速くなります。
- さらに高い圧縮率まで拡張でき、電光石火の解凍速度を維持します。
Under the hood
Zstandard は、いくつかの最近の革新的な技術を組み合わせ、最新のハードウェアをターゲットにすることにより zlib を改善しています。 しかし、今日のコンピュータ環境は、モバイルおよび組み込み環境においてさえ、より多くのメモリにアクセスできます。
Zstandard には固有の制限はなく、テラバイト単位のメモリをアドレスできます (ただし、そうなることはほとんどありません)。 たとえば、22 レベルのうち下位のレベルは、1 MB 以下を使用します。 メモリが制限されている可能性のある広範な受信システムとの互換性のために、メモリ使用量を 8 MB に制限することが推奨されます。 これはチューニングの推奨であり、圧縮フォーマットの制限ではありません。
A format designed for parallel execution
今日の CPU は非常に強力で、複数の ALU(算術論理装置)と高度なアウトオブオーダー実行設計により、1 サイクルに複数の命令を発行できます。
要するに、
a = b1 + b2
c = d1 + d2ならば、
aとcの両方が並行して計算される、ということです。 したがって、この例ではa = b1 + b2
c = d1 + acはaの計算を先に待ち、それからcの計算を開始します。つまり、現代の CPU を活用するには、データの依存関係がほとんどない処理の流れを設計しなければならないのです。 新世代のハフマン・デコーダであるHuff0は、1つのコアで複数のシンボルを並列にデコードすることができる。 このような利益は、複数のコアを使用するマルチスレッドで累積されます。
ブランチレス設計
新しい CPU はより強力で非常に高い周波数を達成しますが、これは、命令が複数のステップのパイプラインに分割される、マルチステージのアプローチにのみ可能です。 各クロック サイクルで、CPU は利用可能な ALU に応じて複数の演算結果を発行することができます。 使用するALUが多ければ多いほど、CPUの処理量は増え、その結果、圧縮速度も速くなる。 ALUに仕事を与え続けることは、現代のCPUのパフォーマンスにとって非常に重要です。
これは難しいことがわかりました。
if (condition) doSomething() else doSomethingElse()これに遭遇したとき、CPUは
conditionの値に依存しているため、何をすべきかわかりません。 慎重なCPUなら、conditionの結果を待ってからどちらかの分岐を処理するだろうが、それは非常に無駄なことだ。 これは分岐予測器のおかげであり、conditionを評価した場合の最も可能性の高い結果を本質的に教えてくれるからです。 賭けが当たると、パイプラインはフルになり、命令が連続的に発行される。 賭けが外れた場合(予測ミス)、CPUは推測で開始したすべての演算を停止し、分岐に戻り、別の方向に進まなければならない。 これはパイプラインフラッシュと呼ばれ、最近のCPUでは非常にコストがかかる。25年前、パイプラインフラッシュは問題外だった。 今日では、分岐のないアルゴリズムと互換性のあるフォーマットを設計することが不可欠であるほど重要です。 例として、ビットストリームの更新を見てみましょう。
/* classic version */while (nbBitsUsed >= 8) { /* each while test is a branch */ accumulator <<= 8; accumulator += *byte++; nbBitsUsed -= 8;} /*>/* branch-less version */nbBytesUsed = nbBitsUsed >> 3;nbBitsUsed &= 7;ptr += nbBytesUsed;accumulator = read64(ptr);ご覧のように、ブランチレス版では、条件なしで、作業量が予測できます。 CPUは常に同じ作業を行い、その作業が予測ミスで投げ出されることはありません。 これに対し、古典的バージョンは
(nbBitsUsed < 8)のとき、仕事量が少なくなる。 しかし、テスト自体は無料ではなく、テストが誤って推測されるたびに、フル パイプライン フラッシュが発生し、分岐なしバージョンによって行われる作業よりもコストがかかります。お察しのとおり、この副作用はデータのパック、読み取り、デコードの方法に影響を及ぼします。 Zstandard は、分岐のないアルゴリズム、特に重要なループ内で、友好的になるように作成されました。 次世代の確率圧縮機
圧縮では、データはまず記号のセットに変換され (モデリング段階)、次にこれらの記号が最小限のビット数を使用してエンコードされます。 この第2段階は、クロード・シャノンを記念してエントロピー段階と呼ばれ、与えられた確率の記号の集合の圧縮限界(「シャノン限界」と呼ばれる)を正確に計算するものである。 目標は、できるだけ少ない CPU リソースでこの限界に近づくことです。
非常に一般的なアルゴリズムはハフマン符号化で、Deflate 内で使用されています。 これは、各シンボルが自然数のビット (1ビット、2ビット…) で記述されると仮定して、可能な限り最適なプレフィックスコードを与えます。
より良い方法は算術符号化と呼ばれ、シャノン限界
-log2(P)に任意に近づくことができ、そのためシンボルごとに小数ビットを消費します。 これは確率が高いほど圧縮率が高くなりますが、その分CPUの消費電力も多くなります。 実際には、最適化された算術コーダーでさえ、特に伸長側では、結果が予測可能な除算(例えば、浮動小数点ではない)を必要とし、その結果、速度が低下します。Finite State Entropy は、Jarek Duda による ANS (Asymmetric Numeral System) という新しい理論に基づきます。 Finite State Entropyは、多くの符号化ステップをテーブルに事前計算する変種であり、結果として、加算、テーブル検索、シフトのみを使用する、算術符号化と同程度の精度のエントロピーコーデックを実現し、ハフマンと同程度の複雑さを持つようになります。 また、ハフマンが事前にビットストリームの復号操作を必要とするのに対し、状態値からすぐに次のシンボルにアクセスできるため、待ち時間が短縮される。 1202>
Repcode modeling
Repcode modeling は、1 バイトまたは数バイトしか違わない、ほぼ同等の内容のシーケンスを特徴とする構造化データを効率的に圧縮します。 この方法は新しいものではありませんが、Deflate の発表後に初めて使用されたため、zlib/gzip 内には存在しません。
repcode モデリングの効率は圧縮するデータの種類に大きく依存し、一桁から二桁の圧縮向上となります。 これらの複合的な改善により、Zstandard ライブラリ内で提供される、より良い、より速い圧縮エクスペリエンスがもたらされます。 アルゴリズムが魅力的であるためには、人間が読めるテキストの圧縮のような 1 つの特定のユースケースで非常に優れているか、または多くの多様なユースケースで非常に優れているかのどちらかである必要があります。 Zstandardは後者のアプローチをとっています。 ユースケースとは、ある特定のデータを何回解凍するかという考え方です。 Zstandard は、これらのすべてのケースで利点があります。 何度も処理されるデータでは、解凍速度と、解凍速度を犠牲にすることなく非常に高い圧縮率を選択できることが有利に働きます。 たとえば、Facebookのソーシャルグラフのストレージは、あなたとあなたの友人がサイトとやりとりする際に繰り返し読み込まれます。 Facebook 以外では、データを何度も解凍する必要がある場合の例として、Linux カーネルのソース コードやサーバーにインストールされている RPM などのサーバーからダウンロードしたファイル、Web ページで使用されている JavaScript や CSS、データウェアハウス内のデータに対して何千もの MapReduces を実行することなどが挙げられます
1 回だけ。 一度だけ圧縮されたデータ、特にネットワーク上での送信のために、圧縮はデータの流れの中で一瞬の出来事です。 サーバーのオーバーヘッドが少ないということは、サーバーが1秒間に処理できるリクエストの数が増えるということです。 クライアントのオーバーヘッドが少ないということは、データをより迅速に処理することができるということです。 例えば、Messengerで友人からメモを受け取ったときにレンダリングするデータなどです。 その結果、モバイル端末のページ読み込みが速くなり、バッテリーの消費量やデータプランの消費量も少なくなります。 特に Zstandard は、小さなデータを処理する方法によって、他のアルゴリズムよりもモバイル シナリオに適しています。 一見直感に反していますが、バックアップやログ ファイルなどのデータの一部が決して解凍されないが、必要に応じて読み取ることができる、ということはよくあります。 この種のデータでは、圧縮は通常、高速で、データを小さくし(状況に適した時間と空間のトレードオフで)、おそらくチェックサムを格納する必要があるが、それ以外は不可視でなければならない。 まれに解凍する必要がある場合、圧縮が運用のユースケースの速度を低下させないようにする必要があります。 これらのすべてのケースにおいて、Zstandard は gzip より何倍も速く圧縮および解凍する能力をもたらし、その結果圧縮されたデータはより小さくなります。 たとえば、Web サーバーとブラウザーの間の JSON メッセージ (通常数百バイト) や、データベース内のデータのページ (数キロバイト) などです。 MySQL、PostgreSQL、および MongoDB などのシステムはすべて、リアルタイム アクセスを意図したデータを保存します。 私たちは現在、IOPs (IO 操作/秒) が非常に高い世界に住んでいますが、ストレージ デバイスの容量は、ハード ドライブがデータ センターを支配していたときよりも低くなっています。 したがって、書き込まれるデータの量を減らす方法を模索するのは自然なことです。それは、サーバーあたりのデータ量を増やし、デバイスを低速で焼き切ることを意味します。 データ圧縮はこのための戦略であり、データベースもしばしばパフォーマンスのために最適化されます。つまり、読み取りと書き込みのパフォーマンスは同じくらい重要なのです。 データベースはデータにランダムにアクセスすることを好みますが、圧縮のほとんどの典型的な使用例では、ファイル全体を線形順序で読み取ります。 データ圧縮は基本的に、過去に基づいて未来を予測することによって機能するため、これは問題です。 予測が正確であればあるほど、データを小さくすることができます。
データベース内のページやモバイル デバイスに送信される小さな JSON ドキュメントなどの小さなデータを圧縮する場合、未来を予測するために使用できる「過去」はそれほど多くありません。 圧縮アルゴリズムでは、事前共有辞書を使用して効果的にジャンプスタートさせることで、この問題に対処しようとしています。 これは、圧縮の種として「過去」のデータの静的なセットを事前に共有することによって行われます。
Zstandard はこのアプローチに基づいて、辞書圧縮用に高度に最適化されたアルゴリズムと API を構築しています。 さらに、Zstandard には、カスタム アプリケーション用の辞書を簡単に作成するためのツール
(zstd --train)と、より大きなコミュニティと共有するための標準辞書を登録するための規定が含まれています。 圧縮率はデータ サンプルによって異なりますが、小規模なデータ圧縮は、辞書なしの圧縮よりも 2 倍から 5 倍向上します。Dictionaries in action
稼働中のデータベースのコンテキストで辞書を使用することは困難ですが (結局、データベースへの大きな変更が必要)、他の種類の小規模データで辞書が動作するのを見ることができます。 現代社会におけるスモールデータの共通語であるJSONは、小さく、繰り返しの多いレコードになる傾向があります。 公開されているデータセットは無数にありますが、このデモでは、HTTP経由で利用できるGitHubの「user」データセットを使用します。 以下はこのデータセットからのサンプルです:
{ "login": "octocat", "id": 1, "avatar_url": "https://github.com/images/error/octocat_happy.gif", "gravatar_id": "", "url": "https://api.github.com/users/octocat", "html_url": "https://github.com/octocat", "followers_url": "https://api.github.com/users/octocat/followers", "following_url": "https://api.github.com/users/octocat/following{/other_user}", "gists_url": "https://api.github.com/users/octocat/gists{/gist_id}", "starred_url": "https://api.github.com/users/octocat/starred{/owner}{/repo}", "subscriptions_url": "https://api.github.com/users/octocat/subscriptions", "organizations_url": "https://api.github.com/users/octocat/orgs", "repos_url": "https://api.github.com/users/octocat/repos", "events_url": "https://api.github.com/users/octocat/events{/privacy}", "received_events_url": "https://api.github.com/users/octocat/received_events", "type": "User", "site_admin": false }ご覧の通り、ここにはかなりの繰り返しがあります。 しかし、各ユーザーは1キロバイト弱であり、ほとんどの圧縮アルゴリズムがその脚を伸ばすためにはもっと多くのデータが必要です。 1,000人のユーザーのセットを非圧縮で保存するには、およそ850キロバイト必要です。 素直に各ファイルに
gzipまたはzstdを適用すると、300 KB 強に削減されます。 しかし、zstdを使用して 1 回限りの事前共有辞書を作成すると、サイズは 122 KB に減少し、元の圧縮率は 2.8 倍から 6.9 倍になります。 これは、zstd::
$ zstd --train -o ../json.zdict -r .sorting 982 files of total size 0 MB ...finding patterns ...statistics ...Save dictionary of size 65599 into file ../json.zdict$ du -h --apparent-size .846K .$ zstd --rm -D ../json.zdict -r .$ du -h --apparent-size .122K .:
圧縮レベルの選択
:
ですぐに利用できる重要な改善です。 このカスタマイズは強力ですが、厳しい選択を迫られることになります。 決定する最善の方法は、データをレビューし、測定して、どのようなトレードオフを行うかを決定することです。 Facebook では、デフォルトのレベル 3 は多くのユースケースに適していますが、ボトルネックが何か (多くの場合、ネットワーク接続またはディスク スピンドルを飽和させようとしている) に応じて、時々、これを少し調整します。 疑問がある場合は、デフォルトのレベル 3 か、速度対スペースのトレードオフのために 6 から 9 の範囲で何かを維持し、レベル 20 以上は、圧縮速度ではなくサイズだけを本当に気にする場合に保存してください。 移植性の高い C 言語で書かれているため、ビジネスを動かすサーバーであれ、ラップトップであれ、あるいはポケットの中の電話であれ、今日使用されている実質的にすべてのプラットフォームに適しています。 github リポジトリから入手して、シンプルな
make installでコンパイルし、gzip:$ zstd access.logaccess.log : 8.07% (6695078 => 540336 bytes, access.log.zst)ご想像どおり、コマンド パイプラインの一部として使用できます。たとえば、重要な MySQL データベースをバックアップするには、
$ mysqldump --single-transaction --opt pokemon | zstd -q -o /srv/backups/mysqldump.sql.zsttarコマンドは異なる圧縮実装をそのままサポートしているので、Zstandard をインストールしたら、Zstandard で圧縮した tarball で直ちに作業できます。 以下は、tarを使用した簡単な例で、gzip との速度差を示しています:$ time tar -I zstd -cf linux-4.6.4.tar.zst linux-4.6.4tar -I zstd -cf linux-4.6.4.tar.zst linux-4.6.4 3.15s user 0.50s system 107% cpu 3.396 total$ time tar -zcf linux-4.6.4.tar.gz linux-4.6.4tar -zcf linux-4.6.4.tar.gz linux-4.6.4 13.74s user 0.43s system 102% cpu 13.784 totalコマンドラインで使用する以外にも、API があり、リポジトリ内のヘッダーファイルで文書化されています (API の概要についてはここから)。 また、zlib インターフェイスを既に持っているツールとの統合を容易にするため、 zlib 互換のラッパー API (libWrapper) も含まれています。 最後に、基本的な使い方から、辞書やストリーミングなどより高度な使い方まで、多くのサンプルをGitHubリポジトリに掲載しています。
More to come
Zstandard は 1.0 に到達し、あらゆる種類の実稼働環境で使用できるようになりましたが、まだ終わりではありません。 将来のバージョンでは、
- ZLIB 用の pigz ツールに似た、大規模なデータ セットでさらに高速なスループットを実現するマルチスレッドのコマンド ライン圧縮を提供します。
- コミュニティが維持する、JSON、HTML、および一般的なネットワーク プロトコルなどの一般的なデータ セットのための圧縮辞書の事前定義セット。
1.0 への移行を支援してくれた、コードとフィードバックの両方の貢献者に感謝したいと思います。 これはまだ始まりに過ぎません。 Zstandard がその潜在能力を発揮するためには、皆さんの協力が必要であることを私たちは知っています。 前述の通り、私たちのGitHubプロジェクトからソースまたはビルド済みのバイナリを入手するか、Macユーザの場合はhomebrew
(brew install zstd)経由でインストールすれば、今日からZstandardを試すことができます。 フィードバックや興味深い使用例、追加の言語バインディング、お気に入りのオープン ソース プロジェクトとの統合の支援をお待ちしています。Footnotes
- 可逆データ圧縮がこの記事の焦点ですが、関連するが非常に異なる分野として、主に画像、音声、動画に使用する非可逆データ圧縮も存在します。 Deflate は、zlib および gzip の実装で使用されるアルゴリズムです。 Zlib は Deflate を提供するライブラリで、gzip はチェックサム処理と同様にデータを Deflate するために zlib を使用するコマンドラインツールです。 このチェックサムは大きなオーバーヘッドを持つことがあります。
- すべてのベンチマークは、Centos 7 マシンの 2.5 GHz で動作する Intel E5-2678 v3 で実行されました。 コマンドラインツール (
zstdとgzip) は、システムの GCC, 4.8.5 でビルドされました。 lzbenchで実行されるアルゴリズム・ベンチマークはGCC 6.
、
でビルドされています。
コメントを残す