Java アプリケーションを可視化することは、現在どのように動作しているか、過去にどのように動作したかを理解し、将来どのように動作するかを理解するために非常に重要です。 多くの場合、ログを分析することは、何がうまくいかなかったかを検出する最も早い方法です。したがって、Java でのログ取得は、アプリケーションのパフォーマンスと健全性を確保し、ダウンタイムを最小限に抑え、短縮するために重要です。 集中型のログおよび監視ソリューションを使用すると、運用または DevOps チームの有効性を向上させることにより、平均修復時間を短縮できます。
優れた実践に従うことにより、ログからより多くの価値を引き出し、それを簡単に使用できるようになります。 エラーやパフォーマンスの低下の根本原因をより簡単に突き止め、エンド ユーザーに影響を与える前に問題を解決できるようになります。 そこで今日は、Javaアプリケーションで作業するときに誓うべきベストプラクティスをいくつか紹介しましょう。 掘り下げましょう。
標準のログ ライブラリを使用する
Javaでのログ取得は、いくつかの異なる方法で行うことができます。 専用のロギング・ライブラリ、共通の API、あるいは単にログをファイルに書き出したり、専用のロギング・システムに直接書き込んだりすることができます。 しかし、あなたのシステムのためのロギングライブラリを選択するとき、前もって考えてください。 考慮・評価すべき点は、パフォーマンス、柔軟性、新しいログ集中化ソリューションのためのアペンダー、などである。 単一のフレームワークに直接縛られる場合、新しいライブラリに切り替えるにはかなりの作業と時間がかかる可能性があります。 そのことを念頭に置き、将来的にロギングライブラリを交換する柔軟性を与えてくれるAPIを選ぶようにしましょう。 Log4j から Logback、そして Log4j 2 への切り替えと同じように、SLF4J API を使うときに必要なことは依存関係を変えることだけで、コードを変えることではありません。
もしあなたが Java ログ・ライブラリに慣れていないなら、私たちの初心者ガイドをチェックしてください:
- Log4j チュートリアル
- Logback チュートリアル
- Log4j2 チュートリアル
- SLF4J チュートリアル
賢くあなたのアペンダーを選択
アペンダーとはあなたのログイベントが配信される場所を定義するものです。 最も一般的なアペンダーは、コンソールとファイルアペンダーです。 便利で広く知られている一方で、それらはあなたの要求を満たさないかもしれません。 たとえば、非同期でログを書きたい場合や、次のような Syslog 用のアペンダーを使用して、ネットワーク経由でログを配信したい場合があります:
<Appenders> <Console name="Console" target="SYSTEM_OUT"> <PatternLayout pattern="%d %level %c - %m%n"/> </Console> <Syslog name="Syslog" host="logsene-syslog-receiver.sematext.com" port="514" protocol="TCP" format="RFC5424" appName="11111111-2222-3333-4444-555555555555" facility="LOCAL0" mdcId="mdc" newLine="true"/></Appenders>
ただし、上記のようなアペンダーを使用すると、ネットワーク エラーや通信中断の影響をログ収集パイプラインで受けやすくなることを覚えておいてください。 その結果、ログが目的地に配送されないことがありますが、これは受け入れがたいことかもしれません。 また、アペンダーがブロックする方法で設計されている場合、システムに影響を与えるロギングを避けたいと思うでしょう。 詳細については、ログ記録ライブラリ vs. ログ シッパーズのブログ投稿を確認してください。
意味のあるメッセージを使用する
ログを作成する際に重要なことの1つですが、それほど簡単ではないことの1つが、意味のあるメッセージを使用することです。 ログ イベントには、与えられた状況に固有のメッセージを含め、それらを明確に記述し、それらを読む人に知らせる必要があります。 あなたのアプリケーションで通信エラーが発生したとします。
LOGGER.warn("Communication error");
しかし、次のようなメッセージを作成することもできます:
LOGGER.warn("Error while sending documents to events Elasticsearch server, response code %d, response message %s. The message sending will be retried.", responseCode, responseMessage);
最初のメッセージは、ログを見る人にいくつかの通信問題について知らせることが容易に分かります。 その人はおそらく、コンテキスト、ロガーの名前、警告が発生した行番号を知っているでしょうが、それだけです。 より多くのコンテキストを得るために、その人はコードを見たり、エラーがどのバージョンのコードに関連しているかを知ったりする必要があります。 これは楽しくなく、しばしば簡単ではありません。また、実運用環境での問題をできるだけ早くトラブルシュートしようとしている間は、確実にやりたくないことです。 これは、どのような種類の通信エラーが発生したか、そのときアプリケーションが何をしていたか、どのようなエラーコードを受け取ったか、そしてリモートサーバーからの応答が何であったかについて正確な情報を提供します。 最後に、メッセージの送信が再試行されることも通知されます。
最後に、メッセージのサイズと冗長性について考えてみてください。 あまりに冗長な情報をログに残さないようにしましょう。 このデータは、有用であるためにどこかに保存される必要があります。 1 つの非常に長いメッセージは問題ありませんが、その行が 1 分間に何百回も繰り返され、冗長なログがたくさんある場合、そのようなデータの長い保持は問題となることがあり、最終的にはコストも高くなります。
Logging Java Stack Traces
Javaロギングで非常に重要な部分の 1 つがJavaスタック トレスです。 次のコードを見てください。
package com.sematext.blog.logging;import org.apache.logging.log4j.LogManager;import org.apache.logging.log4j.Logger;import java.io.IOException;public class Log4JExceptionNoThrowable { private static final Logger LOGGER = LogManager.getLogger(Log4JExceptionNoThrowable.class); public static void main(String args) { try { throw new IOException("This is an I/O error"); } catch (IOException ioe) { LOGGER.error("Error while executing main thread"); } }}
上記のコードは、例外がスローされ、デフォルトの構成でコンソールに出力されるログ メッセージは次のようになります。 問題が発生したことだけが分かっていますが、どこで問題が発生したのか、何が問題なのかなどは分かりません。
package com.sematext.blog.logging;import org.apache.logging.log4j.LogManager;import org.apache.logging.log4j.Logger;import java.io.IOException;public class Log4JException { private static final Logger LOGGER = LogManager.getLogger(Log4JException.class); public static void main(String args) { try { throw new IOException("This is an I/O error"); } catch (IOException ioe) { LOGGER.error("Error while executing main thread", ioe); } }}
次に、ログ記録ステートメントを少し変更した同じコードを見てみましょう。つまり、クラスの名前、問題が発生したメソッド、そして最後に問題が発生した行番号です。 もちろん、実際の状況では、スタック トレースはより長くなりますが、適切なデバッグのための十分な情報を提供するために、スタック トレースを含めるべきです。
Logstash で Java スタック トレースを処理する方法についての詳細は、Logstash による複数行スタック トレースの処理または Logagent を参照してください。
Logging Java Exceptions
Java の例外とスタック トレースを扱う場合、スタック トレース全体、問題が発生した行などについてだけ考えるべきではありません。 3433>
例外を黙って無視することは避けるべきです。 重要なものを無視することは避けたいものです。 たとえば、次のようなことはしないでください:
try { throw new IOException("This is an I/O error");} catch (IOException ioe) {}
また、例外を記録して、さらにそれを投げることはしないでください。 それは問題を実行スタックの上に押し上げただけということになります。 例外についてもっと学びたい場合は、Java の例外処理に関するガイドをお読みください。 すべての情報が同様に重要なわけではなく、すべての予期せぬ状況がエラーまたは重要なメッセージであるわけではありません。 また、一貫してログ レベルを使用する – 類似のタイプの情報は、同様の深刻度レベルにあるべきです。
両方の SLF4J facade とあなたが使用することになる各 Java ログ フレームワークは、適切なログ レベルを提供するために使用できるメソッドを提供します。 たとえば、
LOGGER.error("I/O error occurred during request processing", ioe);
Log in JSON
ログを記録し、ファイルまたは標準出力でデータを手動で見ることを計画している場合、計画したログは、より良いものになります。 それはよりユーザー フレンドリーであり、私たちはそれに慣れています。 しかし、それは非常に小さなアプリケーションでのみ実行可能であり、その場合でも、メトリクスデータとログを相関させることができるものを使用することが推奨されます。 ターミナルウィンドウでそのような操作をするのは楽しいことではありませんし、時には単純に不可能なこともあります。 もしログをログ管理・集中管理システムに保存したいのであれば、JSONでログを記録すべきです。 なぜなら、解析はタダではないからです – 通常、正規表現を使うことになります。 もちろん、ログシッパーでその代償を払うこともできますが、簡単にJSONでログを記録できるのであれば、なぜそんなことをするのでしょう。 JSONでログを取るということは、スタックトレースを簡単に扱えるということでもあるので、さらに別の利点があります。 ほとんどの場合、Java ログ記録フレームワークで JSON でのログ記録を有効にするには、適切な設定を含めるだけで十分です。 たとえば、コードに次のようなログ メッセージが含まれていると仮定します。 これは、単一のアプリケーションまたはマイクロサービスのセット内に当てはまるだけでなく、アプリケーション スタック全体にわたって適用されるべきです。 同様に構造化されたログ イベントでは、それらを調べること、それらを比較すること、それらを関連付けること、または単に専用のデータ ストアにそれらを格納することが容易になります。 システムから送られてくるデータには、深刻度やホスト名などの共通フィールドがあることが分かっていれば、簡単に調べることができ、その情報に基づいてデータを簡単に切り刻むことができます。 もちろん、フルスタックは外部で開発されたサーバー、データベース、検索エンジン、キューなどで構成されており、それぞれがログとログ形式の独自のセットを持っているため、構造を維持することは常に可能というわけではありません。 しかし、あなたとチームの正気を保つために、制御できるさまざまなログ メッセージ構造の数を最小限にします。
共通の構造を保つ方法の 1 つは、ログに同じパターン、少なくとも同じログ フレームワークを使用しているものを使用することです。 たとえば、アプリケーションとマイクロサービスが Log4J 2 を使用する場合、次のようなパターンを使用できます。
<PatternLayout> <Pattern>%d %p %c{35}:%L - %m%n</Pattern></PatternLayout>
単一または非常に限定されたパターンのセットを使用することにより、ログ形式の数が少なく管理可能であり続けることを確認できます。 次のログ エントリを見てください。
An error occurred!
私たちは、アプリケーションのどこかにエラーが表示されたことを知っています。 どこで発生したのか、どのようなエラーだったのか、いつ発生したのかだけが分かっています。
com.sematext.blog.logging.ParsingErrorExample - A parsing error occurred for user with id 1234!
同じログ レコードですが、より多くのコンテキスト情報を持っています。 エラーが発生したスレッドも、エラーが発生したクラスもわかっています。 メッセージが変更され、エラーが発生したユーザーが含まれるようになったので、必要に応じてユーザーに連絡することができます。 また、診断用コンテキストなどの追加情報を含めることもできます。
コンテキスト情報を含めるには、ログ メッセージを生成する責任を負うコードに関して、それほど多くのことを行う必要はありません。 例えば、Log4J 2のPatternLayoutは、あなたがコンテキスト情報を含めるために必要なすべてを提供します。
<PatternLayout pattern="%d{HH:mm:ss.SSS} %-5level - %msg%n"/>
このような非常にシンプルなパターンで、次のようなログメッセージになります:
17:13:08.059 INFO - This is the first INFO level log message!
しかし、より多くの情報を含むパターンを含めることも可能です。
<PatternLayout pattern="%d{HH:mm:ss.SSS} %c %l %-5level - %msg%n"/>
この場合、次のようなログメッセージが表示されます。
17:24:01.710 com.sematext.blog.logging.Log4j2 com.sematext.blog.logging.Log4j2.main(Log4j2.java:12) INFO - This is the first INFO level log message!
Java Logging in Containers
アプリケーションが実行される環境について考えてみましょう。 VM またはベアメタルマシン上で Java コードを実行している場合はロギング構成に違いがあり、コンテナー化された環境で実行している場合は違いがあり、もちろん、Android デバイス上で Java または Kotlin コードを実行している場合も違います。
コンテナー化環境でログを設定するには、取りたい方法を選択する必要があります。 Journald、logagent、Syslog、または JSON ファイルのような、提供されているロギング ドライバーの 1 つを使用することができます。 そのためには、アプリケーションがログファイルをコンテナのエフェメラルストレージに書き込まず、標準出力に書き込む必要があることを覚えておいてください。 これは、ログをコンソールに書き出すように、ロギングフレームワークを設定することで簡単に実現することができます。 たとえば、Log4J 2 では、次のアペンダ構成を使用します:
<Appenders> <Console name="Console" target="SYSTEM_OUT"> <PatternLayout pattern="%d{HH:mm:ss.SSS} - %m %n"/> </Console></Appenders>
また、完全にロギング ドライバーを省略して、ログを Sematext Cloud などの集中型ログ ソリューションに直接送信することもできます:
<Appenders> <Console name="Console" target="SYSTEM_OUT"> <PatternLayout pattern="%d %level %c - %m%n"/> </Console> <Syslog name="Syslog" host="logsene-syslog-receiver.sematext.com" port="514" protocol="TCP" format="RFC5424" appName="11111111-2222-3333-4444-555555555555" facility="LOCAL0" mdcId="mdc" newLine="true"/></Appenders>
多すぎず少なすぎないログ
開発者は、すべてが重要かもしれないと考えがちです – 自分のアルゴリズムやビジネスコードの各ステップを重要だとマークする傾向があります。 一方、私たちは時にその逆を行います。必要な場所にログを追加しなかったり、FATAL や ERROR のログ レベルのみをログに記録したりします。 どちらのアプローチも、あまりうまくはいきません。 コードを書き、ログを追加するとき、アプリケーションが適切に動作しているかどうかを見るために何が重要であるか、 そして、間違ったアプリケーションの状態を診断して修正するために何が重要であるかを考えてみてください。 これを指針として、何をどこでログ収集するのかを決めてください。 3433>
対象者を念頭に置く
ほとんどの場合、ログを見るのはあなただけではありません。 そのことを常に念頭に置いてください。 3433>
開発者は、トラブルシューティングのため、またはデバッグ セッションの間にログを見ることがあります。 そのような人にとって、ログは詳細で技術的であり、システムがどのように実行されているかに関連する非常に深い情報を含むことができます。 そのような人は、コードへのアクセス権を持っているか、コードを知っている可能性さえあり、それを想定することができます。 彼らにとって、ログイベントはトラブルシューティングのために必要であり、診断に役立つ情報を含んでいるはずです。 システム、そのアーキテクチャ、コンポーネント、およびコンポーネントの構成に関する知識は想定できますが、プラットフォームのコードに関する知識は想定すべきではありません。
最後に、アプリケーションログはユーザー自身によって読まれることがあります。 このような場合、ログは、可能であれば問題の解決に役立つ、またはユーザーを支援するサポート チームに十分な情報を提供するのに十分な説明的であるべきです。 たとえば、Sematextを監視に使用する場合、監視エージェントのインストールと実行が必要です。 非常に制限の多いファイアウォールの内側にいて、エージェントがSematextにメトリクスを送信できない場合、Sematextユーザー自身も見ることができるように、エラーを狙ったログが記録されます。
さらに踏み込んで、ログを調べる可能性のある行為者をさらに特定することもできますが、この短いリストにより、ログ メッセージを書くときに何を考えるべきかを垣間見ることができるはずです。 パスワード、クレジットカード番号、社会保障番号、アクセストークンなど、これらはすべて、漏えいしたり、それを見るべきでない人がアクセスしたりすると、危険な場合があります。
機密情報は、トラブルシューティングに本当に必要なのかどうか考えてみてください。 クレジットカード番号の代わりに、トランザクション識別子とトランザクションの日付に関する情報を保持していれば十分なのでは? ユーザー識別子を簡単に保存できるのであれば、ログに社会保障番号を保存する必要はないのかもしれません。 そのような状況を考え、保存するデータについて考え、本当に必要なときだけ機密データを書き込むようにしましょう。
次に、機密情報を含むログをホストされたログサービスに出荷することです。 以下のアドバイスに従うべきでない例外はほとんどありません。 ログに機密情報があり、保存する必要がある場合、集中型ログ ストアに送信する前にマスクするか削除してください。 私たち自身の Logagent のようなほとんどの一般的なログ シッパーには、機密データの削除またはマスキングを可能にする機能があります。
最後に、機密情報のマスキングは、ロギング フレームワーク自体で行うことができます。 Log4j 2 を拡張することによって、どのようにそれを行うことができるかを見てみましょう。 ログイベントを生成するコードは次のようになります(完全な例はSematext Githubで見つけることができます):
public class Log4J2Masking { private static Logger LOGGER = LoggerFactory.getLogger(Log4J2Masking.class); private static final Marker SENSITIVE_DATA_MARKER = MarkerFactory.getMarker("SENSITIVE_DATA_MARKER"); public static void main(String args) { LOGGER.info("This is a log message without sensitive data"); LOGGER.info(SENSITIVE_DATA_MARKER, "This is a a log message with credit card number 1234-4444-3333-1111 in it"); }}
Githubから例全体を実行すると、出力は次のようになります:
21:20:42.099 - This is a log message without sensitive data21:20:42.101 - This is a a log message with credit card number ****-****-****-**** in it
クレジットカード番号がマスクされていることがわかります。 これは、与えられた Marker がログイベントに沿って渡されるかどうかをチェックし、定義されたパターンを置き換えようとするカスタム コンバータを追加したためです。 このようなコンバーターの実装は次のとおりです。
@Plugin(name = "sample_logging_mask", category = "Converter")@ConverterKeys("sc")public class LoggingConverter extends LogEventPatternConverter { private static Pattern PATTERN = Pattern.compile("\b({4})-({4})-({4})-({4})\b"); public LoggingConverter(String options) { super("sc", "sc"); } public static LoggingConverter newInstance(final String options) { return new LoggingConverter(options); } @Override public void format(LogEvent event, StringBuilder toAppendTo) { String message = event.getMessage().getFormattedMessage(); String maskedMessage = message; if (event.getMarker() != null && "SENSITIVE_DATA_MARKER".compareToIgnoreCase(event.getMarker().getName()) == 0) { Matcher matcher = PATTERN.matcher(message); if (matcher.find()) { maskedMessage = matcher.replaceAll("****-****-****-****"); } } toAppendTo.append(maskedMessage); }}
これは非常に単純で、もっと最適化した方法で書くことができ、可能なすべてのクレジットカード番号形式も処理できますが、この目的には十分です。
コードの説明に入る前に、この例の log4j2.xml 構成ファイルもお見せしたいと思います。
<?xml version="1.0" encoding="UTF-8"?><Configuration status="WARN" packages="com.sematext.blog.logging"> <Appenders> <Console name="Console" target="SYSTEM_OUT"> <PatternLayout pattern="%d{HH:mm:ss.SSS} - %sc %n"/> </Console> </Appenders> <Loggers> <Root level="info"> <AppenderRef ref="Console"/> </Root> </Loggers></Configuration>
ご覧のように、コンバータを探す場所をフレームワークに伝えるため、構成に packages 属性を追加しました。 それから、ログメッセージを提供するために%scパターンを使用しました。 デフォルトの %m パターンを上書きすることができないので、そうします。 Log4j2が私たちの%scパターンを見つけると、それはログイベントのフォーマットされたメッセージを取り、それが見つかった場合、単純な正規表現を使用して、データを置き換える私たちのコンバータを使用します。 3433>
ここで注目すべきことは、マーカー機能を使用していることです。 正規表現マッチングは高価であり、すべてのログ メッセージに対してそれを行うことは望ましくありません。 そのため、作成した Marker で処理すべきログ イベントをマークし、マークされたものだけがチェックされるようにします。
Use a Log Management Solution to Centralize & Monitor Java Logs
アプリケーションが複雑になると、ログの量も大きくなっていきます。 ファイルにログを記録し、トラブルシューティングが必要なときだけログを使用すれば済むかもしれませんが、データ量が増えてくると、この方法ではすぐにトラブルシューティングが難しくなり、時間がかかります。 このようなときは、ログを一元化して監視するログ管理ソリューションの利用を検討してみてください。 Elastic Stack のようなオープン ソース ソフトウェアに基づく社内ソリューションを使用するか、または Sematext Logs のような市場で入手可能なログ管理ツールの 1 つを使用できます。
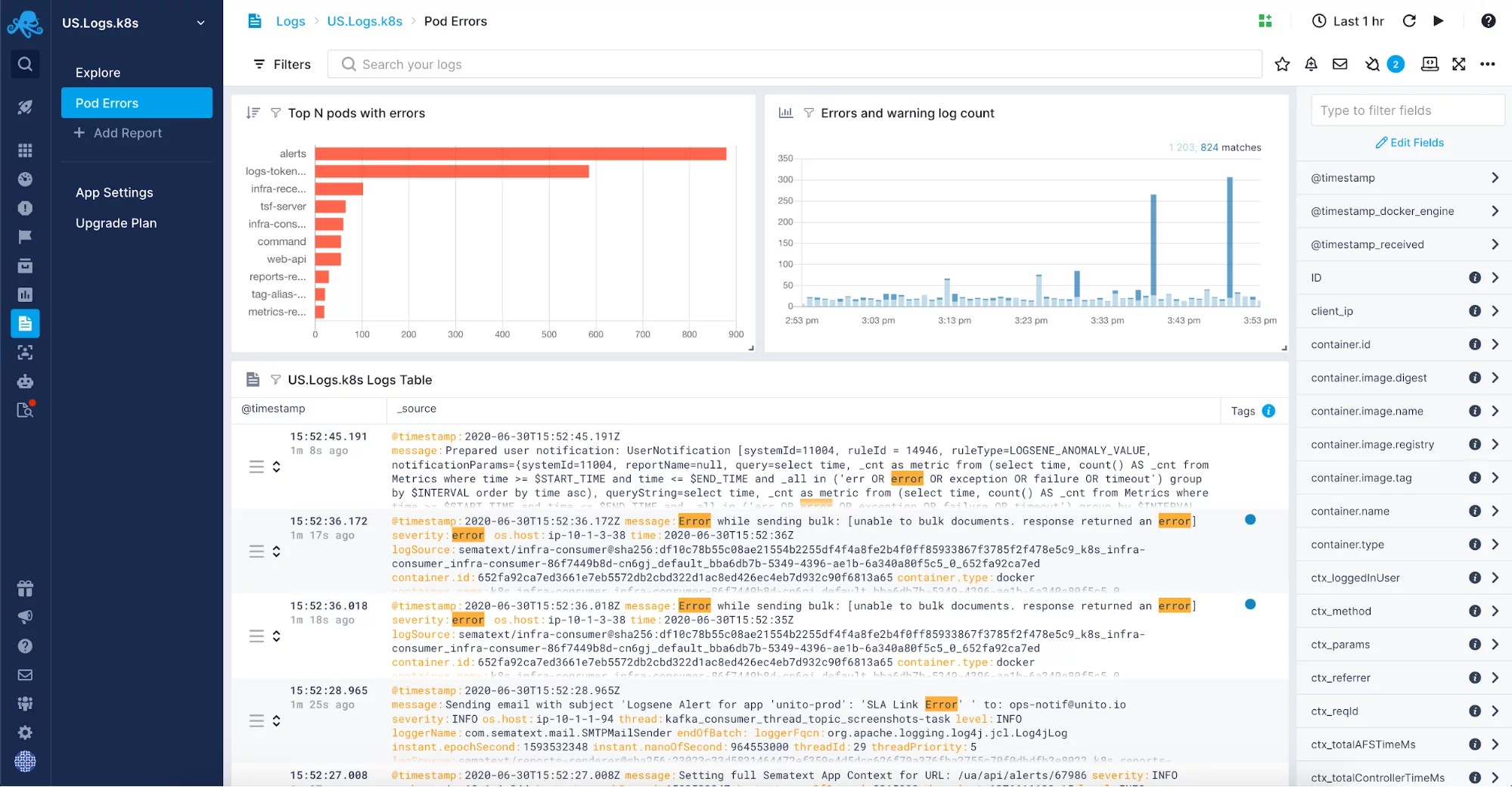
完全管理型のログ集中ソリューションにより、通常はかなり複雑で、さらに別のインフラの部分を管理しなくてもよいという自由が生まれます。 その代わりに、アプリケーションに集中することができ、ログの送信のみを設定する必要があります。 JVMガベージコレクション・ログのようなログを、マネージド・ログ・ソリューションに含めることができます。 JVM上で動作するアプリケーションとシステムのためにそれらをオンにした後、あなたは、ログ相関、ログ分析、およびJVMインスタンスでガベージコレクションを調整するのに役立つ単一の場所でログを集約したいと思うでしょう。 Sematext Logsが類似のソリューションとどのように比較されるかに興味がある場合は、最高のログ管理ソフトウェアに関する記事、またはトップログ分析ツールをレビューするブログ記事をご覧ください。 3433>
結論
すべての優れた実践方法をすぐに取り入れることは、特に、すでに稼働しているアプリケーションでは、簡単ではないかもしれません。 しかし、時間をかけて提案を次々に展開すれば、ログの有用性が向上するのを確認し始めるでしょう。 ログを最大限に活用するためのヒントについては、ログのベストプラクティスに関する他の記事もご覧になることをお勧めします。 Sematextでは、ロギング・コンサルティングを提供することで、組織のロギング・セットアップを支援しています。
コメントを残す