Sign up for our daily recaps of the ever changing search marketing landscape.
Note: このフォームを送信すると、Third Door Mediaの条件に同意したことになります。 私たちはあなたのプライバシーを尊重します。

インターネットのフォーラムやコンテンツ関連のFacebookグループでは、Googlebotがどのように働くのか、ここではGBと優しく呼ぶことにしますが、何が見えて何が見えないのか、どんなリンクを訪問しSEOにどう影響するのか、といった議論がしばしば勃発します
今回は私が3か月間行った実験の結果について紹介します。
この 3 か月間、GB はほぼ毎日、ビールを飲みに立ち寄る友人のように私を訪ねてきました。
ときには 1 人のときもありました:
: 66.249.76.136 /page1.html Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)
: 66.249.76.136 /page5.html Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)
: 66.249.76.140 /page3.html Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html) Mozilla 5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)1; +http://www.google.com/bot.html)
: 66.249.64.72 /page2.html Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)
: 66.249.64.72 /page6.html Mozilla/5.0 (compatible; Googlebot/2.2.0; +http://www.google.com/bot.html)1; +http://www.google.com/bot.html)
Sometimes it brought its buddies along:
: 64.233.172.231 /page1.html Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko; Google Search Console) Chrome/41.0.2272.118 Safari/537.36
: 66.249.69.235 /image.jpg Googlebot-Image/1.0
: 66.249.76.156 /page2.html Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML、Geckoのような) AppleWebkit/537.36 (KHTML, like Gecko) Chrome/41.0.2272.96 Mobile Safari/537.36 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)
そして、いろいろな遊びを楽しみました:
Catch: 私は、GB がいかにリダイレクト 301 を実行し、画像をクロールし、正規表現から実行するのが好きであるかを観察しました。 Googlebotは隠しコンテンツに隠れていた(親が主張するように、許容せず避ける)
Survival: 私はトラップを用意し、それがスプリングするのを待った
Obstacles:
Obstacles: My little friend would see how to deal with them.
As you can tell, I was not disappointed.私は様々な難易度の障害物を配置し、私の小さな友人がそれらにどう対処するかを見ました。 私たちはとても楽しくて、良い友達になりました。 私は、私たちの友情には明るい未来があると信じています。
しかし、本題に入りましょう!
私は、星間旅行代理店が銀河系やその先のまだ発見されていない惑星へのフライトを提供するというメリット関連のコンテンツでウェブサイトを構築しました。
私はユニークなコンテンツを提供し、すべてのアンカー/タイトル/オルト、および他の係数がグローバルにユニークであることを確認しました (フェイク ワード)。 読者が簡単に理解できるように、説明では、anchor cutroicano matestitoのような名前は使わず、anchor1などと表記します。
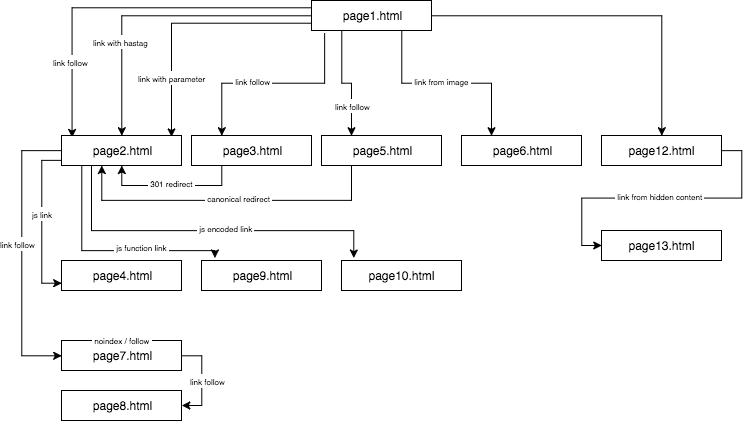
この記事を読むときは、上記のマップを別ウィンドウで開いておくことをお勧めします。
First Link Counts Ruleでは、1つのページにおいて、Google Botはサブページへの最初のリンクだけを見ることになります。 1 ページに同じサブページへのリンクが 2 つある場合、このルールによると、2 つ目のリンクは無視されます。
これは多くの専門家によって広く監督されている問題ですが、特にオンライン ショップに存在し、ナビゲーション メニューがウェブサイトの構造を著しく歪めています。
ほとんどのショップでは、静的な(ページのソースで見える)ドロップダウン メニューがあり、たとえば、メイン カテゴリへの 4 つのリンクとサブカテゴリへの 25 の隠しリンクがあります。 ページの構造のマッピング中に、GB は (メニューのある各ページの) すべてのリンクを見ます。その結果、マッピング中にすべてのページの重要性が等しくなり、そのパワー (juice) が均等に配分され、おおよそ次のようになります。
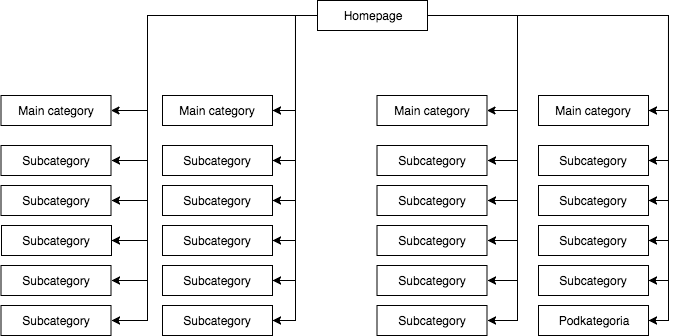
最も一般的ですが私の考えでは、間違ったページ構造です。
上の例は、すべてのカテゴリはメニューがあるすべてのサイトからのリンクなので正しい構造とは言えません。 したがって、トップページもすべてのカテゴリとサブカテゴリも同数の着信リンクを持ち、Webサービス全体のパワーが等しい力で流れている。 したがって、(通常、着信リンクの数によりパワーの大半を占める)トップページのパワーは、24のカテゴリーとサブカテゴリーに分割されているため、それぞれがトップページのパワーの4%しか受けていないのです。
How the structure should look:

Google のようにページの構造を高速テストしてクロールする必要がある場合、Screaming Frog は役に立つツールです。
この例では、ホームページのパワーは4つに分けられ、それぞれのカテゴリはホームページのパワー25パーセントを得て、サブカテゴリにその一部を配分しています。 この方法は、内部リンクの可能性も高くなります。 例えば、ショップのブログで記事を書き、サブカテゴリのひとつにリンクを張りたい場合、GBはウェブサイトをクロールしながらそのリンクに気づきます。 最初のケースでは、First Link Counts Ruleのため、実行されない。 サブカテゴリへのリンクがウェブサイトのメニューにあった場合、記事内のものは無視されます。
私はこの SEO 実験を次のアクションで開始しました。
この目的のために、次のソリューションをテストしました。
- Web サービスのホームページに、URL アンカーを持つフレーズに 1 つの外部 dofollow リンクを割り当てました(したがって、ホームページと特定のフレーズのサブページの外部リンクは問題外でした) – これはサービスのインデックス作成を加速させました。
- 私は、page1.html から来る最初の dofollow リンク (anchor1) からのフレーズで page2.html がランキングされ始めるのを待ちました。 この偽フレーズも、私がテストした他のフレーズも、ターゲットページで見つけることはできませんでした。 他のリンクが機能するのであれば、page2.htmlも他のリンクから他のフレーズで検索結果にランクインするのではと推測した。 45日ほどかかりました。 337>
キーワードがコンテンツにもメタタイトルにもないウェブサイトであっても、調査済みのアンカーでリンクされていれば、この単語を含むがキーワードにリンクされていないウェブサイトよりも簡単に検索結果で上位にランクインすることができるのです。
さらに、調査した語句を含むホームページ(page1.html)は、Webサービスの中で最も強いページ(78%のサブページからリンクされている)であり、それでも調査した語句でサブページ(page2.html)より低い順位になりました。
以下、私がテストした4種類のリンクを紹介します。これらはすべて、page2.htmlにつながる最初のdofollowリンクの後に来ています。
Link to a website with an anchor
< a href=”page2.html#testhash” >anchor2< /a >
dfollow リンクの後ろのコードで来る追加リンクの最初のものはアンカー(ハッシュタグ)付きリンクでした。 私は、リンクがそのページ (page2.html) につながっているにもかかわらず、URLが page2.html#testhash uses anchor2.
に変更されているにもかかわらず、GB がそのリンクをスルーして、anchor2 というフレーズの下に page2.html もインデックスするかどうかを見たかったのですが、残念ながら GB はそのつながりを決して覚えようとせず、そのフレーズのサブページ page2.html に力を向けることはなかったのです。 その結果、この記事を書いている日のanchor2というフレーズの検索結果には、リンクのアンカーにその単語が見つかるサブページpage1.htmlしかない。 testhash というフレーズでググっても、私たちのドメインはランクインしていません。
Link to a Website with a parameter
page2.html?parameter=1
当初、GB は URL のクエリー マークと anchor3 リンク内のアンカーのすぐ後のこの面白い部分に興味を持ち、私が何を言いたいのか理解しようと試みました。 それは、”なぞなぞ” と考えていました。 他の URL の重複コンテンツがインデックスされるのを避けるために、正規の page2.html は自分自身を指していました。 ログにはこのアドレスで 8 回のクロールが記録されていますが、結論はかなり悲しいものでした:
- 2 週間後、GB の訪問頻度は大幅に減少し、最終的にそのリンクをクロールせずに去っていきました。
- page2.html はフレーズ anchor3 でインデックスされておらず、URL parameter1 のパラメータもインデックスされていませんでした。 Search Consoleによると、このリンクは存在しません(着信リンクの中にカウントされません)が、同時に、フレーズanchor3はアンカーフレーズとしてリストされています。
Link to a website from a redirection
私はGBに私のウェブサイトをもっとクロールさせようと思いました。その結果GBが数日ごとに、ページ1.htmlにアンカーanchor4でdofollowリンクを入力、それが301コードでリダイレクトし、ページ2.htmlへつながるようになりました。 残念ながら、パラメータ付きのページの場合と同様に、45 日後に page2.html は page1.html のリダイレクトされたリンクに表示されるアンカー4のフレーズの検索結果にまだランクされていませんでした。
しかしながら、Google Search Console のアンカー テキスト セクションでは、アンカー4は表示されてインデックスされています。 これは、しばらくするとリダイレクトが期待どおりに機能するようになり、page2.html が同じ Web サイト内の同じターゲット ページへの 2 つ目のリンクであるにもかかわらず、anchor4 の検索結果にランクインすることを示す可能性があります。
正規タグによるページへのリンク
page1.html で、アンカー anchor5 で page5.html (フォローリンク)を参照して配置しました。 同時に、page5.html にはユニークコンテンツがあり、その先頭には page2.html への canonical タグがありました。
< link rel=”canonical” href=”https://example.com/page2.html”.
- page5.html へのアンカー 5 フレーズのリンクが page2.html に正準リダイレクトされる。
- page5.html は、canonical タグがあるにもかかわらずインデックスされました。
I would dare to claim that using rel=canonical to prevent the indexing of some content (e.g. while filtering) simply could not work.
Part 2: Crawl budget
SEO 戦略を設計する一方で、私は GB を自分の曲に合わせて、逆に踊らせてみたいと思っていました。 そのために、サーバーログ(アクセスログやエラーログ)のレベルでSEOの検証を行ったのですが、これが大きなアドバンテージになりました。 そのおかげで、GB のすべての動きと、私が SEO キャンペーンで導入した変更(Web サイトの再構築、内部リンクシステムの上下反転、情報の表示方法)に対する反応を知ることができました。
SEO キャンペーンでの私の仕事の 1 つは、GB がインデックスできる URL とインデックスさせたい URL のみにアクセスするような方法でサイトを再構築することでした。 一言で言えば、SEOの観点から我々にとって重要なページだけがGoogleのインデックスにあるべきということです。 一方、GBはGoogleにインデックスさせたいWebサイトだけをクロールさせるべきで、これは誰にでもわかることではありません。たとえば、オンラインショップが色、サイズ、価格によるフィルタリングを実装している場合、それはURLパラメータを操作することで行われます。たとえば:
example.com/women/shoes/?color=red&size=40&price=200-250
GB が動的 URL をクロールできるようにするソリューションは、ページをクロールする代わりにそれらを精査する(そしておそらくインデックスする)ために時間を割くことが判明するかもしれません。
example.com/women/shoes/
このように動的に作成された URL は、役に立たないだけでなく、薄いコンテンツと誤解される可能性があるため SEO にとって有害であり、その結果、Web サイトの順位が低下することになります。
この実験の中で、rel=”nofollow” を使用しない構造化、robots.txt ファイルでの GB のブロック、ボットには見えないフレームでの HTML コードの一部の配置 (ブロックした iframe) などの方法も確認したかったのです。
3種類の JavaScript リンクをテストしました。
onclick イベントを持つ JavaScript リンク
JavaScript で構築されたシンプルなリンク
< a href=”javascript:void(0)” onclick=”window.location.href =’page4.html'” >anchor6< /a >
GB はサブページの page4.html に簡単に移動してページ全体をインデックス化した。 サブページはanchor6のフレーズで検索結果にランクインしておらず、このフレーズはGoogle Search ConsoleのAnchor Textsセクションで見つけることができない。 結論は、リンクはジュースを転送しなかったということです。
- 古典的な JavaScript リンクは、Google がウェブサイトをクロールして、アクセスしたページをインデックスすることを可能にします。
Javascript link with an internal function
ゲームを上げることにしましたが、なんとGBはリンク公開後2時間足らずでその障害を克服してしまいました。
< a href=”javascript:void(0)” class=”js-link” data-url=”page9.html” >anchor< /a >
このリンク操作には、データからURLを読み取り、リダイレクト-希望通りユーザーのみ-ターゲットpage9.htmlへのリダイレクトを目指した外部関数を使っていたのですが、この関数もまた、GBは、そのリダイレクトに成功したのでした。 先のケースと同様に、page9.html は完全にインデックスされていました。
興味深いのは、他の着信リンクがないにもかかわらず、page9.html は Web サービス全体で GB が最も頻繁にアクセスするページであり、page1.html と page2.html に次いで 3 番目であることです。 しかし、ご覧の通り、もう通用しません。 SEO では、イエロー ページは別として、永遠に生き続けるものはありません。
JavaScript link with coding
それでも私はあきらめず、GB の顔に効果的にドアを閉める方法があるに違いないと思いました。 そこで、私は簡単な関数を構築し、データを base64 アルゴリズムでコーディングし、参照は次のようになりました:
< a href=”javascript.NET”: “javascript.NET”: “javascript.NET”:void(0)” class=”js-link” data-url=”cGFnZTEwLmh0bWw=” >anchor8< /a >
結果として、GB では data-URL 属性の内容をデコードしてリダイレクトする JavaScript コードを作成することは出来ませんでした。 そして、それはあったのです! ボットが好きなところにクロールできないように、rel=nonfollows を使用せずに Web サービスを構成する方法があるのです! この方法だと、クロールの予算を無駄にしないので、大きなウェブサービスの場合は特に重要で、最終的にGBが私たちの曲に合わせて踊ってくれます。 この機能が同じページの head セクションに導入されたか、外部の JS ファイルに導入されたかにかかわらず、サーバー ログにも Search Console にもボットの証拠はありません。
Part 3: 隠しコンテンツ
最後のテストでは、たとえば隠しタブ内のコンテンツが GB によって考慮されてインデックスされるか、一部の専門家が主張しているように Google がそのページを表示し隠しテキストを無視するか、確認したいと思いました。 そのために、私は page12.html に 2000 以上の記号からなるテキストの壁を置き、テキストの約 20% (400 の記号) のテキスト ブロックを Cascading Style Sheets で隠し、さらに表示ボタンを追加しました。 隠されたテキスト内には、アンカー anchor9 を持つ page13.html へのリンクがありました。
ボットがページをレンダリングできることは間違いありません。 Google Search ConsoleとGoogle Insight Speedの両方で観察することができます。 とはいえ、私のテストでは、show moreボタンをクリックした後に表示されるテキストのブロックが完全にインデックスされていることが判明しました。 テキストに隠されたフレーズは検索結果にランクインし、GBはテキストに隠されたリンクをたどっていた。 さらに、隠されたテキストブロックからのリンクのアンカーは、Google Search Console のアンカーテキストのセクションで確認でき、page13.html もキーワード anchor9.
で検索結果にランクインするようになりました。これは、コンテンツを隠しタブに置くことが多いオンラインショップでは非常に重要なことです。 今、私たちは、GB が隠しタブ内のコンテンツを見て、インデックスし、そこに隠されたリンクからジュースを転送することを確信しています。
この実験から得られる最も重要な結論は、修正リンク(パラメータ付きリンク、301 リダイレクト、正規リンク、アンカー リンク)を使用して、ファースト リンク カウンツ規則をバイパスする直接の方法は見つかっていない、ということです。 同時に、Javascriptのリンクを使ってウェブサイトの構造を構築することは可能であり、そのおかげでFirst Link Counts Ruleの制約から解放されるのです。 さらに、Google Botはブックマークに隠されたコンテンツを見てインデックスすることができ、ブックマークに隠されたリンクをたどります。
Sign up for our daily recaps of the ever changing search marketing landscape.
Note: This form submits, you agree to Third Door Media’s terms.Seef.
著者について

「『ただ』高い品質を認めてはいけない」。 そんなの誰でもできる。 空が限界なら、もっと高い空を探せばいい。” マックス・サイレック氏は、サイレック・デジタル社のCEOで、デジタルマーケティングコンサルタント、SEOエバンジェリストとして活躍しています。 そのキャリアを通じて、30人以上のチームとともに、何百もの企業の成功をサポートしてきました。 彼は10年近くデジタルマーケティングに従事し、テクニカルSEOを専門とし、マーケティングプロジェクトを成功に導いてきました
。
コメントを残す