今回は、最も広く使われている機械学習アルゴリズムについて見ていきます。 その種類は非常に多く、「インスタンスベース学習アルゴリズム」や「パーセプトロン」といった言葉を聞くと混乱してしまいがちです。
通常、すべての機械学習アルゴリズムは、その学習スタイル、機能、または解決する問題のいずれかに基づいてグループに分けられます。 この投稿では、学習スタイルに基づく分類を紹介します。 また、これらのアルゴリズムが解決するのに役立つ一般的なタスクについても言及します。
今日使用されている機械学習アルゴリズムの数は多いので、その100%について言及することはしません。 8194>
- Supervised learning algorithms
- 分類アルゴリズム
- Naive Bayes
- Multinomial Naive Bayes
- Logistic regression
- SVM (Support Vector Machine)
- 回帰アルゴリズム
- Linear regression
- 教師なし学習アルゴリズム
- クラスタリング
- K-means clustering
- Dimensionality reduction
- Association rule learning
- 強化学習
- Q-Learning
- アンサンブル学習
- Bagging
- Boosting
- ランダムフォレスト
- Stacking
- ニューラルネットワーク
- Conclusion
Supervised learning algorithms

「教師あり学習」「教師なし学習」などの用語がよくわからない場合は、「AI vs ML」でこのトピックを詳しく取り上げていますのでご確認ください。
分類アルゴリズム
Naive Bayes

ベイズアルゴリズムは、ベイズの定理を応用した ML で用いられる確率的分類器の一群である。
ナイーブベイズ分類器は、機械学習に使われた最初のアルゴリズムの一つである。 二値分類や多値分類に適しており、過去の結果から予測やデータの予報を行うことができる。 典型的な例としては、2010年まで使われていたスパムフィルタリングシステムがあり、満足のいく結果を示している。 しかし、ベイズ ポイズニングが発明されると、プログラマーはデータをフィルタリングする他の方法を考え始めました。
ベイズの定理を使用すると、あるイベントの発生が別のイベントの確率にどのように影響するかを伝えることが可能です。 一般的なスパムの言葉は、「オファー」、「今すぐ注文」、または「副収入」です。 アルゴリズムがこれらの単語を検出した場合、電子メールがスパムである可能性が高くなります。
Naive Bayes は、特徴が独立していると仮定します。
Multinomial Naive Bayes
ナイーブベイズ分類器とは別に、このグループには他のアルゴリズムもある。 たとえば、多項式 Naive Bayes は、通常、ドキュメントに存在する特定の単語の頻度に基づいてドキュメント分類に適用されます。
Bayesian アルゴリズムは、テキストの分類や不正検出などに今でも使用されています。 また、マシンビジョン (たとえば、顔検出)、マーケット セグメンテーション、およびバイオインフォマティクスにも適用できます。
Logistic regression
その名前が直感に反しているように見えても、ロジスティック回帰は実際には分類アルゴリズムの一種です。 Statquest が作成した素晴らしいビデオでは、肥満マウスを例にして、線形回帰とロジスティック回帰の違いを説明しています。 決定木の利点は、理解、解釈、視覚化が容易であることです。 また、データ準備のための労力もほとんど必要ありません。
しかし、大きな欠点もあります。 データのわずかな変動(分散)により、木が不安定になることがある。 また、一般化できないような複雑すぎる木を作ることも可能である。 これはオーバーフィットと呼ばれる。 この問題に対処するために、バギング、ブースティング、正則化が有効である。 8194>
決定木の各要素は次のとおりです:
- 主要な質問をするルート ノード。 これは、そこから下を指す矢印を持ちますが、それを指す矢印はありません。 たとえば、夕食にどのようなパスタを食べるべきかを決定するためのツリーを構築していると想像してください。 ツリーのサブセクションは、ブランチまたはサブツリーと呼ばれることもあります。
- 決定ノード。 これらは、ルートノードのサブノードで、さらにノードに分割することもできます。 決定ノードは “カルボナーラ?” または “キノコ入り?” になります。
- Leaves または Terminal ノード。 これらのノードは分割されません。
また、分割についても触れておくことが重要です。 これは、ノードをサブノードに分割する処理です。 たとえば、ベジタリアンでなければ、カルボナーラでもいい。 でも、もしそうなら、キノコの入ったパスタを食べましょう。 また、プルーニングと呼ばれるノード除去のプロセスもあります。
決定木のアルゴリズムは、CART(分類と回帰の木)と呼ばれています。 8194>
- 回帰木は変数が数値を持っているときに使用されます。
- 分類木はデータがカテゴリ(クラス)である場合に適用することができる。 そのため、ツリー図は、幅広い業界や分野で一般的に適用されています。 GreyAtom では、さまざまな種類の決定木とその実用的なアプリケーションの幅広い概要を提供しています。
SVM (Support Vector Machine)
サポートベクターマシンは、分類や、時には回帰タスクに使用するアルゴリズムの別のグループです。 SVM の目標は、データ ポイントを明確に分類する N 次元空間 (N は特徴の数に対応する) の超平面を見つけることです。 結果の精度は、選択した超平面に直接関係します。 この超平面は、あるクラスと別のクラスを分ける線としてグラフィカルに表現されます。 超平面の異なる側に位置するデータ点は、異なるクラスに帰属します。
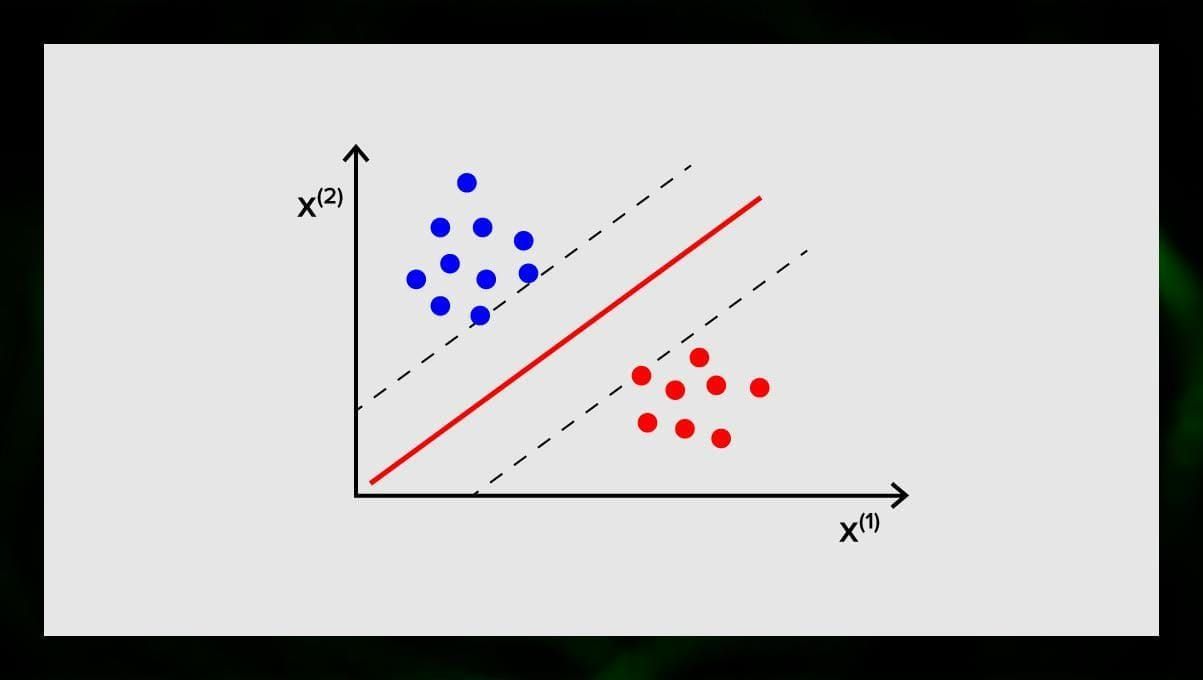
超平面の次元は、特徴の数に依存することに留意してください。 入力特徴の数が2であれば、超平面は単なる線になる。 入力特徴数が3の場合、超平面は2次元の平面になる。 特徴数が3個を超えると、グラフにモデルを描くことが難しくなる。 そこで、この場合はカーネル型を使って3次元空間に変換することになります。
なぜ、サポートベクターマシンと呼ばれるのでしょうか。 サポートベクターは超平面に最も近いデータ点です。 これらは超平面の位置や向きに直接影響を与え、分類器のマージンを最大化することを可能にします。 サポートベクターを削除すると、超平面の位置が変化します。 これらの点は、SVMを構築するのに役立ちます。
SVMは現在、異常を見つけるための医療診断、大気質制御システム、株式市場の金融分析や予測、産業界の機械の故障制御などで活発に使用されています。
回帰アルゴリズム
回帰アルゴリズムは、例えば証券のコストや特定商品の特定時期の売上を予測するような分析に有効です。
Linear regression
線形回帰は、観察されたデータに線形方程式を当てはめることによって、変数間の関係をモデル化しようとするもので、説明変数と従属変数があります。 従属変数とは、説明や予測をしたいものです。 説明的なものは、その名の通り、何かを説明するものである。 線形回帰を構築したい場合、従属変数と独立変数の間に線形関係があることを仮定します。 たとえば、家の平方メートルとその価格、またはその地域の人口とケバブ店の密度の間に相関があります。
その仮定をしたら、次に具体的な線形関係を把握する必要があります。 一組のデータに対する線形回帰式を求める必要があります。 8194>
注:回帰が直線を描く場合を線形、曲線の場合を多項式といいます。
教師なし学習アルゴリズム

さて、ラベル付けされていないデータから隠れたパターンを見つけ出すアルゴリズムについて説明しましょう。
クラスタリング
クラスタリングとは、入力を互いの類似性の度合いに応じてグループに分けるということです。 クラスタリングは通常、より複雑なアルゴリズムを構築するためのステップの1つです。 一度にすべてを扱うよりも、各グループを個別に研究し、その特徴に基づいてモデルを構築する方がシンプルです。 同じ手法はマーケティングやセールスで常に使用され、すべての潜在顧客をグループに分けています。
非常に一般的なクラスタリング アルゴリズムは k-means clustering と k-nearest neighbor です。
K-means clustering
K-means clustering はベクトル空間の要素の集合をあらかじめ定義された数のクラスタ k に分割します。しかしクラスタの数が正しくないと全体のプロセスが無効になるので、クラスタの数を変えて試してみることが重要です。 k-meansアルゴリズムの主な考え方は、データをランダムにクラスタに分割し、その後、前のステップで得られた各クラスタの中心を繰り返し再計算することです。 その後、ベクトルは再びクラスタに分割される。 8194>
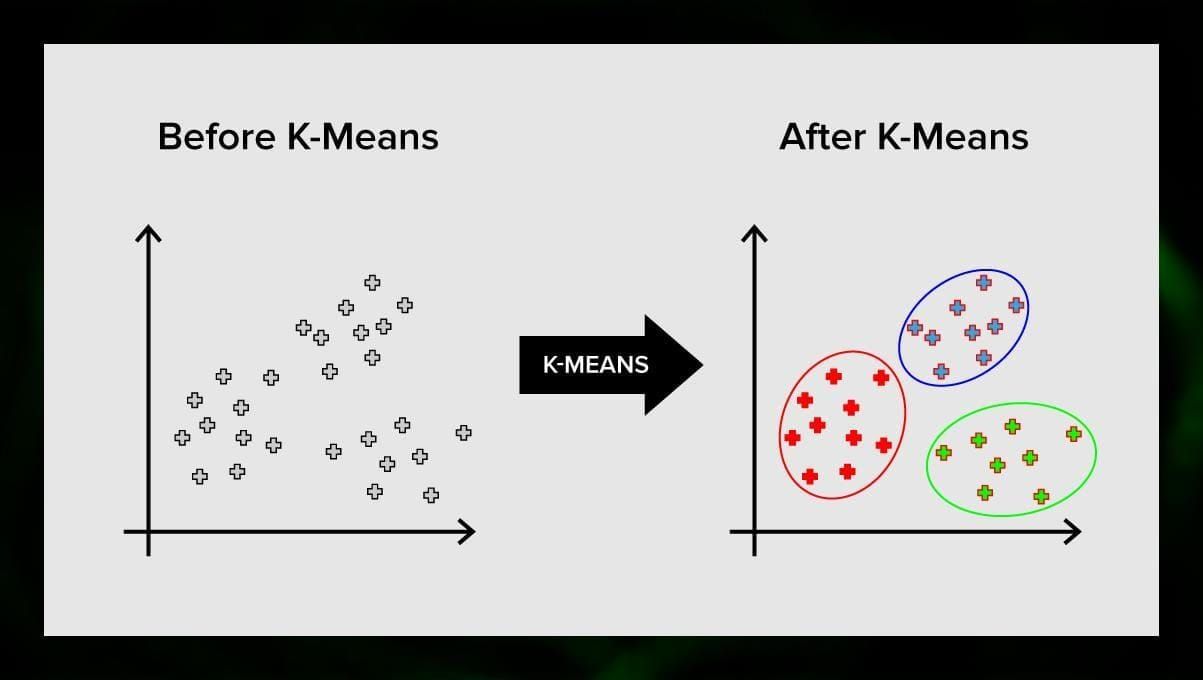
この方法は、クラスタが明確であるか、または互いに容易に分離でき、データが重複しない場合に問題を解決するために適用することができる。 これは最も単純な分類アルゴリズムの1つで、回帰タスクで使用されることもあります。
分類器を学習するには、事前に定義されたクラスを持つデータセットが必要です。 このマーク付けは、研究分野の専門家が参加して手動で行われます。 このアルゴリズムを使用すると、複数のクラスで作業したり、入力が複数のクラスに属する状況をクリアしたりすることができます。
この方法は、類似のラベルが属性ベクトル空間内の近いオブジェクトに対応するという前提に基づいています。
最新のソフトウェア システムでは、視覚パターン認識、たとえばチェックアウト時にカートの底にある隠れたパッケージをスキャンして検出するなど(たとえば、AmazonGo)に kNN を使用しています。 kNN アルゴリズムはすべてのデータを分析し、疑わしい活動を示す異常なパターンを見つけます。
Dimensionality reduction
主成分分析 (PCA) は、メモリ関連の問題を効果的に解決するために理解すべき重要なテクニックです。 例えば、都市を「住みやすい」「住みにくい」「まあまあ」の3つのグループにクラスタリングする必要があるとします。 どれだけの変数を考慮しなければならないでしょうか。 おそらく、たくさんあります。 それらの間の関係を理解していますか? そうでもありません。
専門用語で言うと、「特徴空間の次元を下げる」ことです。 特徴空間の次元を減らすことにより、考慮すべき変数間の関係が少なくなり、モデルの過剰適合が少なくなります。
次元削減を達成する方法はたくさんありますが、これらの技術のほとんどは 2 つのクラスのいずれかに分類されます:
- 特徴の除去;
- 特徴の抽出。 この方法の利点は、簡単であることと、変数の解釈可能性を維持できることです。 しかし、欠点として、削除することにした変数から得られる情報はゼロになります。
特徴抽出はこの問題を回避します。 この方法を適用するときの目標は、与えられたデータセットから一連の特徴を抽出することです。 特徴抽出の目的は、既存の特徴に基づいて新しい特徴を作成することにより、データセットの特徴の数を減らすことです (そして、元の特徴を破棄します)。 主成分分析は特徴抽出のためのアルゴリズムであり、入力変数を特定の方法で結合し、すべての変数の最も価値のある部分を保持しながら「最も重要でない」変数を削除することが可能である
PCAの考えられる使用法の1つは、データセット内の画像が大きすぎる場合です。 8194>
Association rule learning
Aprioriは最も人気のある関連ルール検索アルゴリズムの1つである。 比較的短時間で大量のデータを処理することができます。
今日、多くのプロジェクトのデータベースは非常に大きく、ギガバイトやテラバイトに達しているということです。 そして、今後も増え続けるでしょう。 したがって、短時間で連想規則を見つけるための効果的でスケーラブルなアルゴリズムが必要である。 アプリオリはこのようなアルゴリズムの1つである。
このアルゴリズムを適用できるようにするには、データを準備し、すべてをバイナリ形式に変換し、データ構造を変更する必要がある。
強化学習

強化学習は、機械学習の方法の 1 つで、特定の環境と相互作用する方法を機械に教えるのを助けます。 この場合、環境 (たとえば、ビデオ ゲーム) が教師として機能します。 コンピュータが下した判断に対してフィードバックを与える。 この報酬をもとに、機械は最適な行動をとるよう学習していくのです。 これは、子供が熱いフライパンに触れないようにする方法を思い起こさせる。つまり、試行錯誤し、痛みを感じることである。
このプロセスを分解すると、次のような簡単なステップがあります。
- コンピュータは環境を観察し、
- 何らかの戦略を選択し、
- この戦略に従って行動し、
- 報酬またはペナルティを受け取り、
- この経験から学んで戦略を改良し、
- 最適戦略が見つかるまでこれを繰り返す。
Q-Learning
強化学習に使用できるアルゴリズムは2つほどある。 最も一般的なものの1つがQ学習である。
Q学習はモデルフリーの強化学習アルゴリズムである。 Q学習は環境から受け取る報酬に基づいて行われる。 エージェントは効用関数Qを形成し、その後に行動戦略を選択する機会を与え、環境との以前の相互作用の経験を考慮に入れる。
Q学習の利点の1つは、環境モデルを形成せずに、利用できる行動の期待有用性を比較することができることである。
アンサンブル学習

アンサンブル学習とは、複数のMLモデルを構築してそれらを組み合わせて問題を解決する方法である。 アンサンブル学習は、主に分類、予測、関数近似モデルの性能を向上させるために用いられる。
以下は、より一般的なアンサンブル学習アルゴリズムの一部である。
Bagging
Baggingとはbootstrap aggregatingの略で、ブートストラップ集計のことである。 これは初期のアンサンブルアルゴリズムの一つであり、驚くほど良い性能を持つ。 分類器の多様性を保証するために、学習データのブートストラップされた複製を使用します。 つまり、学習データセットから、異なる学習データのサブセットをランダムに-置換して-抽出するのです。 各訓練データの部分集合は,同じ種類の異なる分類器を学習するために利用されます. そして,個々の分類器を結合することができます. そのためには,その決定に対して単純な多数決を取る必要があります. 8194>
Boosting
このアンサンブルアルゴリズムのグループは、バギングに似ています。 Boostingも様々な分類器を用いてデータを再サンプリングし、多数決で最適なものを選びます。 ブースティングでは、弱い分類器を繰り返し訓練して、強い分類器に組み立てます。 分類器を追加する際には,通常,その予測の精度を表すいくつかの重みが帰属されます. 弱い分類器がアンサンブルに追加されると,その重みが再計算されます. 正しく分類されていない入力はより重くなり,正しく分類されたインスタンスはより重くなります. 8194>
ランダムフォレスト
ランダムフォレストまたはランダム決定森は、分類、回帰、およびその他のタスクのためのアンサンブル学習方法である。 ランダムフォレストを構築するためには、学習データのランダムなサンプルに対して多数の決定木を学習させる必要がある。 ランダムフォレストの出力は、個々の木の中で最も頻度の高い結果である。 8194>
Stacking
Stacking は、メタ分類器またはメタ回帰器を介して複数の分類または回帰モデルを結合するアンサンブル学習技法である。
ニューラルネットワーク
ニューラルネットワークは、シナプスで接続されたニューロンのシーケンスであり、人間の脳の構造を思い起こさせるものである。 しかし、人間の脳はさらに複雑です。
ニューラルネットワークの素晴らしいところは、スパム フィルタリングからコンピューター ビジョンまで、基本的にあらゆるタスクに使用できることです。 しかし、通常は、機械翻訳、異常検出とリスク管理、音声認識と言語生成、顔認識などに適用されます。
ニューラルネットワークは、ニューロン、またはノードで構成されています。 これらの各ニューロンは、データを受信して処理し、それを別のニューロンに転送します。
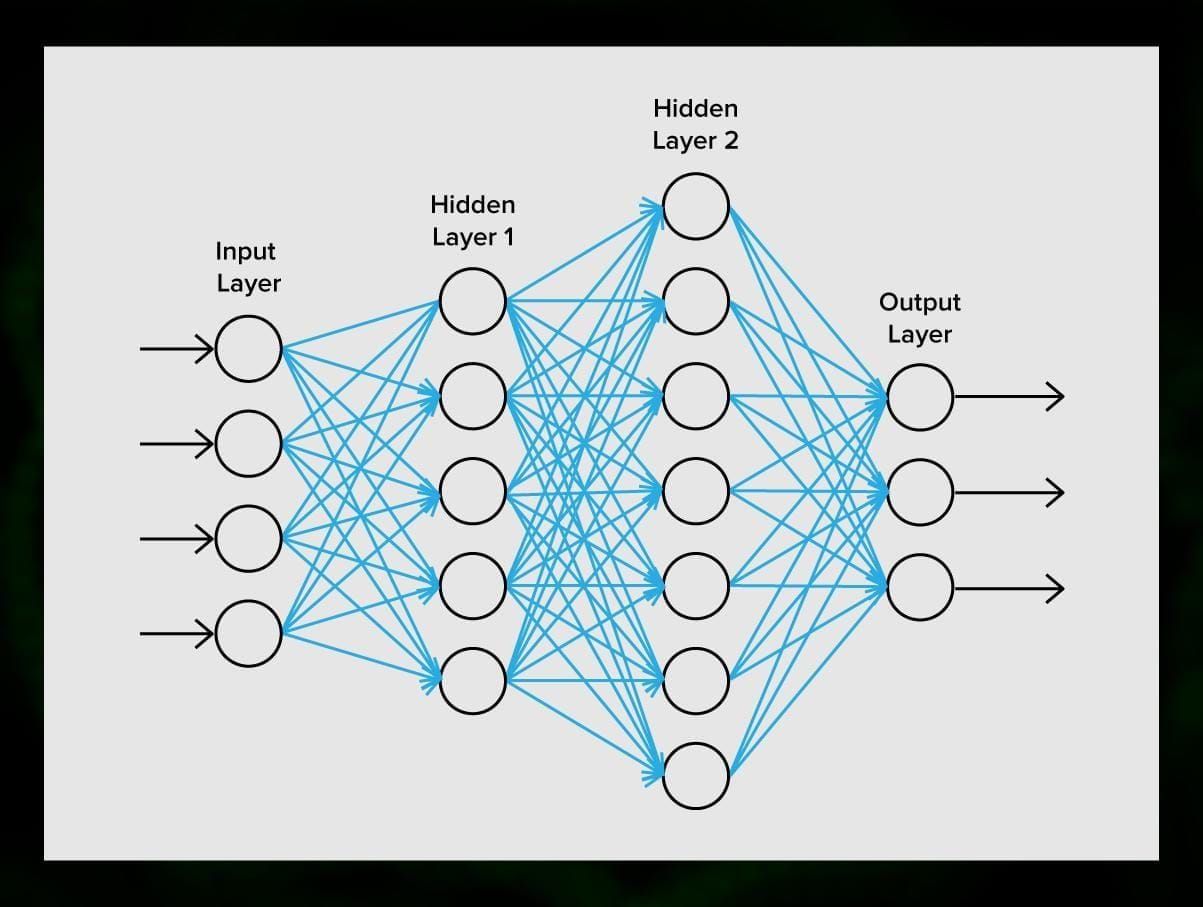
どのニューロンも同じように信号を処理します。 しかし、それではどのようにして異なる結果を得ることができるのでしょうか。 これには、ニューロン同士をつなぐシナプスが関与しています。 各ニューロンは、信号を減衰させたり増幅させたりするシナプスをたくさん持つことができる。 また、ニューロンは時間の経過とともにその特性を変化させることができます。 シナプスのパラメータを正しく選択することで、入力された情報の変換結果を出力で正しく得ることができる。
NN にはさまざまなタイプがある:
- Feedforward neural networks (FF または FFNN) と perceptrons §は非常に単純で、ネットワーク内にループやサイクルは存在しない。 実際にはこのようなネットワークはほとんど使われないが、他のタイプと組み合わせて新しいものを得ることが多い。
- ホップフィールドネットワーク(HN)は、リンクの対称行列を持つ完全連結型ニューラルネットワークである。 このようなネットワークはしばしば連想記憶ネットワークと呼ばれる。 このネットワークは、テーブルの半分を見た人が後半を想像できるように、ノイズの入ったテーブルを受け取ると、それを完全に復元する。 これらは通常、画像処理、オーディオまたはビデオ関連のタスクに使用されます。 CNN を適用する典型的な方法は、画像の分類です。
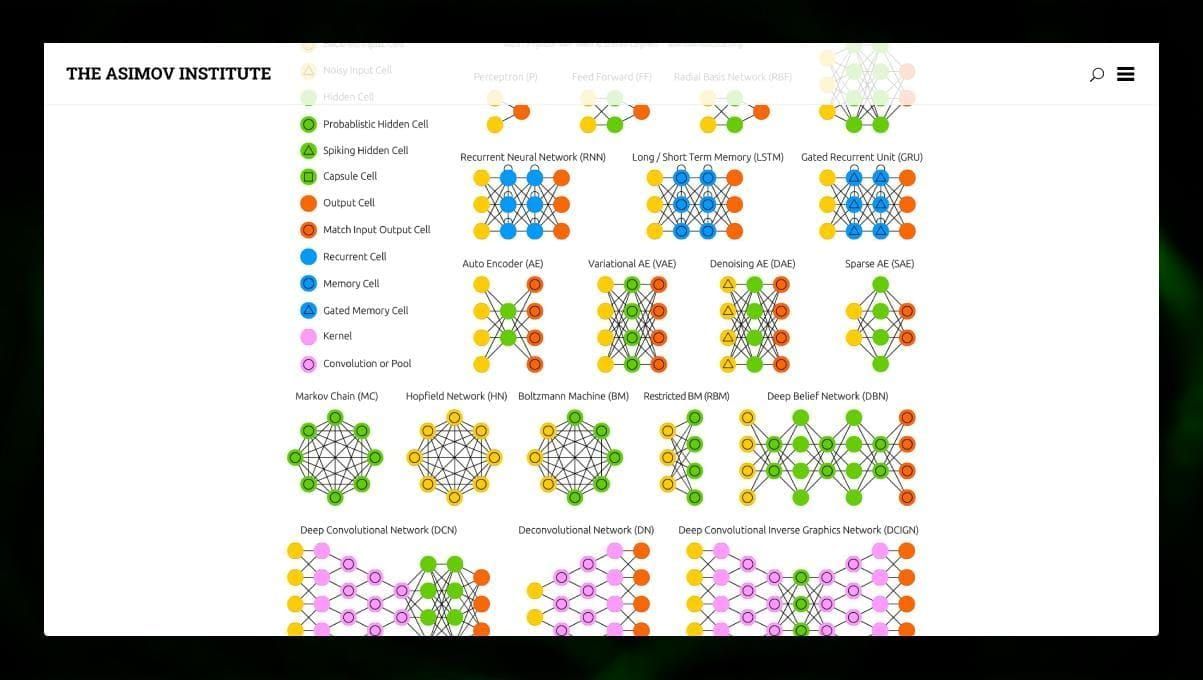
多くの異なるタイプのニューラル ネットワークを観察することは興味深いことです。 NN zooでそれを行うことができます。
Conclusion
この投稿では、異なるMLアルゴリズムについて広く紹介しましたが、まだ多くのことが語られます。 私たちの Twitter、Facebook、および Medium では、機械学習のエキサイティングな可能性についてのガイドと投稿を続けていきますので、お楽しみに。
コメントを残す