Hash Tableはデータを連想的に格納するデータ構造である。 ハッシュテーブルでは、データは配列形式で保存され、各データ値にはそれぞれ固有のインデックス値がある。 したがって、データのサイズに関係なく、挿入と検索操作が非常に高速なデータ構造になる。
Hashing
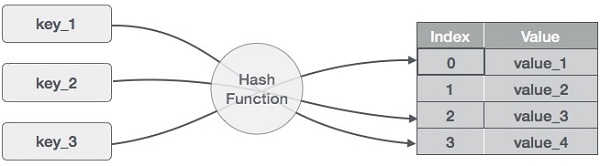
Hashing は、キー値の範囲を配列のインデックスの範囲に変換する技術である。 ここでは、キー値の範囲を得るためにモジュロ演算子を使用することにします。 サイズ20のハッシュテーブルの例で、次のような項目が格納されることを考える。 項目は(key,value)の形式である。
- (1,20)
- (2,70)
- (42,80)
- (4,25)
- (12.0)
- (12.0)
- (42.0)
- (42.0)
- (42.0)44)
- (14,32)
- (17,11)
- (13,78)
- (37,98)
| Sr.No. | Key | Hash | 配列インデックス |
|---|---|---|---|
| 1 | 1 % 20 = 1 | 1 | |
| 2 | 2 % 20 = 2 | 2 | 2 |
| 3 | 42 | 42 % 20 = 2 | 2 |
| 4 | 4 | 4 % 20 = 4 | 4 |
| 5 | 12 | 12 % 20 = 12 | 12 |
| 6 | 14 | 14 % 20 = 14 | 14 |
| 7 | 17 | 17 % 20 = 17 | 17 |
| 8 | 13 | 13 % 20 = 13 | 13 |
| 9 | 37 | 17 |
Linear Probing
ご覧のようになります。 ハッシュ化技術によって,すでに使用されている配列のインデックスが作成されることがあります. このような場合、空のセルを見つけるまで次のセルを調べることで、配列の次の空の場所を検索することができます。 この手法をリニアプロービングと呼びます。
| Sr.No. | Key | Hash | Array Index | After Linear Probing.のようになる。 配列インデックス |
|---|---|---|---|---|
| 1 | 1 % 20 = 1 | 1 | ||
| 2 | 2 | 2 % 20 = 2 | 2 | 2 |
| 3 | 42 | 42 % 20 = 2 | 2 | 3 |
| 4 | 4 | 4 % 20 = 4 | 4 | 4 |
| 5 | 12 | 12 % 20 = 12 | 12 | 12 |
| 6 | 14 | 14 % 20 = 14 | 14 | 14 |
| 7 | 17 | 17 % 20 = 17 | 17 | 17 |
| 8 | 13 | 13 % 20 = 13 | 13 | |
| 9 | 37 | 37 % 20 = 17 | 17 | 18 |
Basic Operations
以下はハッシュテーブルの基本操作である。
-
Search – ハッシュテーブルの要素を検索します。
-
Insert – ハッシュテーブルに要素を挿入します。
-
delete – ハッシュテーブルから要素を削除します。
DataItem
いくつかのデータとキーを持つデータ項目を定義し、それに基づいてハッシュテーブルで検索を行います。
struct DataItem { int data; int key;};
Hash Method
データ項目のキーのハッシュコードを計算するハッシュメソッドを定義する。
int hashCode(int key){ return key % SIZE;}
Search Operation
要素を検索したいときは、渡されたキーのハッシュコードを計算し、配列内のインデックスとしてそのハッシュコードで要素を探す。
例
struct DataItem *search(int key) { //get the hash int hashIndex = hashCode(key); //move in array until an empty while(hashArray != NULL) { if(hashArray->key == key) return hashArray; //go to next cell ++hashIndex; //wrap around the table hashIndex %= SIZE; } return NULL; }
挿入操作
要素が挿入されるたびに、渡されたキーのハッシュコードを計算し、そのハッシュコードを配列のインデックスとしてそのインデックスを探す。
例
void insert(int key,int data) { struct DataItem *item = (struct DataItem*) malloc(sizeof(struct DataItem)); item->data = data; item->key = key; //get the hash int hashIndex = hashCode(key); //move in array until an empty or deleted cell while(hashArray != NULL && hashArray->key != -1) { //go to next cell ++hashIndex; //wrap around the table hashIndex %= SIZE; } hashArray = item; }
削除操作
要素を削除するときはいつでも、渡されたキーのハッシュコードを計算し、そのハッシュコードを配列のインデックスとしてインデックスの位置を特定する。 計算されたハッシュコードで要素が見つからなければ、線形探査で先の要素を取得する。 見つかったらそこにダミーのアイテムを格納して、ハッシュテーブルの性能を維持する。
例
struct DataItem* delete(struct DataItem* item) { int key = item->key; //get the hash int hashIndex = hashCode(key); //move in array until an empty while(hashArray !=NULL) { if(hashArray->key == key) { struct DataItem* temp = hashArray; //assign a dummy item at deleted position hashArray = dummyItem; return temp; } //go to next cell ++hashIndex; //wrap around the table hashIndex %= SIZE; } return NULL; }
C言語でのハッシュ実装について知りたい方はこちら
コメントを残す