Schrijf je in voor onze dagelijkse recaps van het steeds veranderende zoekmarketinglandschap.
Note: Door dit formulier in te dienen, ga je akkoord met de voorwaarden van Third Door Media. We respecteren uw privacy.

Op internetfora en contentgerelateerde Facebookgroepen breken vaak discussies los over hoe Googlebot werkt – die we hier teder GB zullen noemen – en wat het wel en niet kan zien, wat voor links het bezoekt en hoe het SEO beïnvloedt.
In dit artikel zal ik de resultaten presenteren van mijn drie maanden durende experiment.
Al bijna dagelijks, de afgelopen drie maanden, heeft GB mij bezocht als een vriend die langskomt voor een biertje.
Soms was het alleen:
: 66.249.76.136 /page1.html Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)
: 66.249.76.136 /page5.html Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)
: 66.249.76.140 /page3.html Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)
: 66.249.64.72 /page2.html Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)
: 66.249.64.72 /page6.html Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)
Soms bracht het zijn vriendjes mee:
: 64.233.172.231 /page1.html Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, zoals Gecko; Google Search Console) Chrome/41.0.2272.118 Safari/537.36
: 66.249.69.235 /image.jpg Googlebot-Image/1.0
: 66.249.76.156 /page2.html Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, zoals Gecko) Chrome/41.0.2272.96 Mobile Safari/537.36 (compatibel; Googlebot/2.1; +http://www.google.com/bot.html)
En we hadden veel plezier met het spelen van verschillende spelletjes:
Catch: Ik observeerde hoe GB ervan houdt om redirections 301 uit te voeren en afbeeldingen te crawlen, en van canonicals uit te voeren.
Hide-and-seek: Googlebot verstopte zich in de verborgen inhoud (die het, zoals zijn ouders beweren, niet tolereert en vermijdt)
Survival: Ik bereidde vallen voor en wachtte tot het ze zou springen.
Obstakels: Ik plaatste obstakels met verschillende moeilijkheidsgraden om te zien hoe mijn kleine vriend ermee om zou gaan.
Zoals je waarschijnlijk kunt zien, werd ik niet teleurgesteld. We hadden veel plezier en we werden goede vrienden. Ik geloof dat onze vriendschap een mooie toekomst heeft.
Maar laten we ter zake komen!
Ik bouwde een website met aan verdiensten gerelateerde inhoud over een interstellair reisbureau dat vluchten aanbiedt naar nog onontdekte planeten in ons melkwegstelsel en daarbuiten.
De inhoud leek veel verdiensten te hebben, terwijl het in feite een hoop onzin was.
De structuur van de experimentele website zag er als volgt uit:
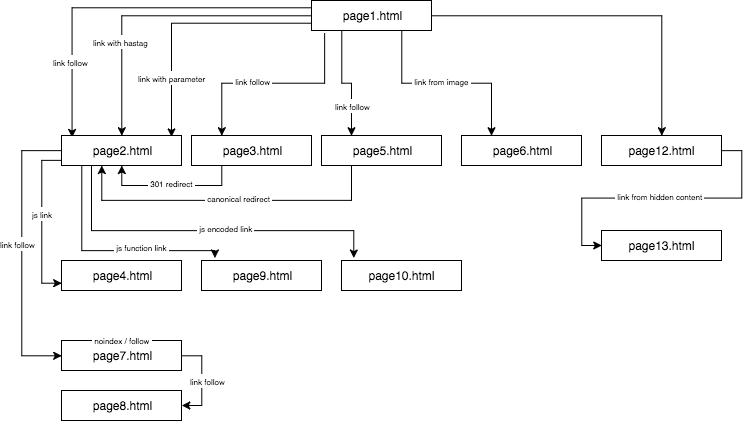
Ik zorgde voor unieke inhoud en zorgde ervoor dat elk anker/titel/alt, en ook andere coëfficiënten, globaal uniek waren (nepwoorden). Om het de lezer gemakkelijker te maken, zal ik in de beschrijving geen namen gebruiken als anchor cutroicano matestito, maar ze in plaats daarvan aanduiden als anchor1, enz.
Ik stel voor dat u de bovenstaande kaart in een apart venster openhoudt terwijl u dit artikel leest.
- Deel 1: First link counts
- Link naar een website met een anker
- Link naar een website met een parameter
- Link naar een website vanuit een omleiding
- Link naar een pagina met behulp van canonical tag
- Deel 2: Crawlbudget
- JavaScript-link met een onclick-event
- Javascript-link met een interne functie
- JavaScript link met codering
- Deel 3: Verborgen inhoud
- Over de auteur
Deel 1: First link counts
Een van de dingen die ik in dit SEO-experiment wilde testen, was de First Link Counts Rule – of deze kan worden weggelaten en hoe deze de optimalisatie beïnvloedt.
De First Link Counts Rule zegt dat op een pagina, Google Bot alleen de eerste link naar een subpagina ziet. Als je twee links naar dezelfde subpagina op een pagina hebt, zal de tweede worden genegeerd, volgens deze regel. Google Bot zal het anker in de tweede en in elke opeenvolgende link negeren bij het berekenen van de rang van de pagina.
Het is een probleem dat door veel specialisten wordt overzien, maar dat vooral voorkomt in online winkels, waar navigatiemenu’s de structuur van de website aanzienlijk verstoren.
In de meeste winkels hebben we een statisch (zichtbaar in de bron van de pagina) uitklapmenu, dat bijvoorbeeld vier links naar hoofdcategorieën geeft en 25 verborgen links naar subcategorieën. Tijdens het in kaart brengen van de structuur van een pagina ziet GB alle links (op elke pagina met een menu), waardoor alle pagina’s tijdens het in kaart brengen even belangrijk zijn en hun kracht (sap) gelijkmatig wordt verdeeld, wat er ongeveer zo uitziet:
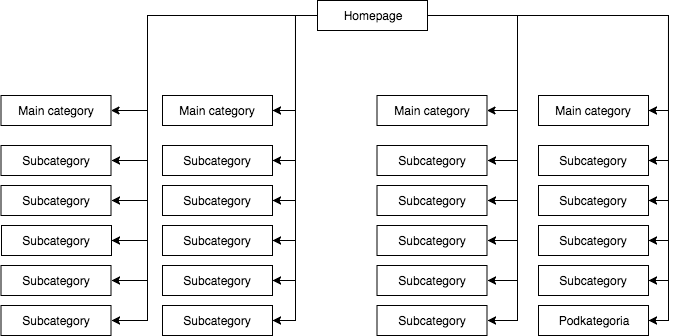
De meest voorkomende, maar naar mijn mening, verkeerde paginastructuur.
Het bovenstaande voorbeeld kan geen juiste structuur worden genoemd, omdat alle categorieën zijn gelinkt vanaf alle sites waar een menu is. Daarom hebben zowel de homepage als alle categorieën en subcategorieën een gelijk aantal inkomende links, en stroomt de kracht van de hele webdienst met gelijke kracht door hen heen. Vandaar dat de kracht van de homepage (die gewoonlijk de bron is van de meeste kracht vanwege het aantal inkomende links) wordt verdeeld over 24 categorieën en subcategorieën, zodat elk van hen slechts 4 procent ontvangt van de kracht van de homepage.
Hoe de structuur eruit zou moeten zien:

Als u de structuur van uw pagina snel wilt testen en crawlen zoals Google dat doet, is Screaming Frog een handig hulpmiddel.
In dit voorbeeld wordt de kracht van de homepage in vieren gedeeld en krijgt elk van de categorieën 25 procent van de kracht van de homepage en verdeelt een deel daarvan over de subcategorieën. Deze oplossing biedt ook een betere kans op interne linking. Wanneer u bijvoorbeeld een artikel schrijft op de blog van de winkel en een link wilt plaatsen naar een van de subcategorieën, zal GB de link opmerken tijdens het crawlen van de website. In het eerste geval zal het dat niet doen vanwege de First Link Counts Rule. Als de link naar een subcategorie in het menu van de website stond, dan wordt die in het artikel genegeerd.
Ik begon dit SEO-experiment met de volgende acties:
- Eerst, op de pagina1.html, nam ik een link op naar een subpagina pagina2.html als een klassieke dofollow link met een anker: anchor1.
- Volgende, in de tekst op dezelfde pagina, nam ik licht gewijzigde verwijzingen op om te controleren of GB zou staan te popelen om ze te crawlen.
Daartoe testte ik de volgende oplossingen:
- Op de homepage van de webdienst wees ik één externe dofollow-link toe voor een frase met een URL-anker (zodat elke externe koppeling van de homepage en de subpagina’s voor gegeven frases uitgesloten was) – dit versnelde de indexering van de dienst.
- Ik wachtte tot pagina2.html begon te ranken voor een frase van de eerste dofollow link (anchor1) afkomstig van pagina1.html. Deze nep zin, of een andere die ik getest kon niet worden gevonden op de doelpagina. Ik nam aan dat als andere links zouden werken, pagina2.html ook zou ranken in de zoekresultaten voor andere zinnen van andere links. Het duurde ongeveer 45 dagen. En toen kon ik de eerste belangrijke conclusie trekken.
Ook een website, waar een trefwoord noch in de inhoud, noch in de meta titel voorkomt, maar wel gekoppeld is met een onderzocht anker, kan gemakkelijk hoger in de zoekresultaten ranken dan een website die dit woord wel bevat, maar niet gekoppeld is aan een trefwoord.
Bovendien was de homepage (page1.html), die de onderzochte woordgroep bevatte, de sterkste pagina in de webdienst (gelinkt aan 78 procent van de subpagina’s) en toch scoorde deze lager op de onderzochte woordgroep dan de subpagina (page2.html) gekoppeld aan de onderzochte woordgroep.
Hieronder presenteer ik vier soorten links die ik heb getest, die allemaal na de eerste dofollow-link komen die naar pagina2.html leidt.
Link naar een website met een anker
< a href=”page2.html#testhash” >anchor2< /a >
De eerste van de extra links die in de code achter de dofollow-link kwam, was een link met een anker (een hashtag). Ik wilde zien of GB door de link heen zou gaan en ook pagina2.html zou indexeren onder de frase anchor2, ondanks het feit dat de link naar die pagina leidt (pagina2.html) maar de URL wordt gewijzigd in pagina2.html#testhash gebruikt anchor2.
Helaas wilde GB die koppeling niet onthouden en leidde het de kracht niet naar de subpagina pagina2.html voor die frase. Als resultaat, in de zoekresultaten voor de frase anchor2 op de dag van het schrijven van dit artikel, is er alleen de subpagina pagina1.html, waar het woord kan worden gevonden in het anker van de link. Bij het Googlen op de frase testhash, komt ons domein ook niet voor.
Link naar een website met een parameter
page2.html?parameter=1
In eerste instantie was GB geïnteresseerd in dit grappige deel van de URL net na het queryteken en het anker binnen de link anchor3.
Geïntrigeerd probeerde GB erachter te komen wat ik bedoelde. Het dacht, “Is het een raadsel?” Om de dubbele inhoud onder de andere URL’s niet te indexeren, wees de canonieke pagina2.html naar zichzelf. De logs registreerden in totaal 8 crawls op dit adres, maar de conclusies waren nogal treurig:
- Na 2 weken nam de frequentie van GB’s bezoeken significant af totdat het uiteindelijk vertrok en nooit meer die link crawled.
- pagina2.html werd niet geïndexeerd onder de frase anchor3, noch was de parameter met de URL parameter1. Volgens Search Console bestaat deze link niet (hij wordt niet meegeteld bij de inkomende links), maar tegelijkertijd wordt de frase anchor3 wel vermeld als een verankerde frase.
Link naar een website vanuit een omleiding
Ik wilde GB dwingen mijn website meer te crawlen, wat ertoe leidde dat GB om de paar dagen de dofollow-link met een anker4 op pagina1.html invoerde die leidt naar pagina3.html, die met een 301-code doorverwijst naar pagina2.html. Helaas, net als in het geval van de pagina met een parameter, kwam na 45 dagen pagina2.html nog niet voor in de zoekresultaten voor de anchor4-zin die in de doorverwijzende link op pagina1.html stond.
Hoewel, in Google Search Console, in de sectie Anchor Teksten, is anchor4 zichtbaar en geïndexeerd. Dit zou erop kunnen wijzen dat de omleiding na verloop van tijd begint te werken zoals verwacht, zodat pagina2.html in de zoekresultaten zal ranken voor anchor4, ondanks dat het de tweede link is naar dezelfde doelpagina binnen dezelfde website.
Link naar een pagina met behulp van canonical tag
Op pagina1.html heb ik een verwijzing geplaatst naar pagina5.html (follow link) met een anker anchor5. Tegelijkertijd stond er op pagina5.html unieke inhoud, en in de kop daarvan stond een canonieke tag naar pagina2.html.
< link rel=”canonieke” href=”https://example.com/page2.html” />
Deze test gaf de volgende resultaten:
- De link voor de anchor5-zin die naar pagina5.html leidt en canoniek verwijst naar pagina2.html werd niet doorgestuurd naar de doelpagina (net als in de andere gevallen).
- pagina5.html werd geïndexeerd ondanks de canonieke tag.
- pagina5.html rangschikte niet in de zoekresultaten voor anchor5.
- pagina5.html rankt op de zinnen die in de tekst van de pagina worden gebruikt, wat aangeeft dat GB de canonieke tags volledig negeert.
Ik durf te beweren dat het gebruik van rel=canonieke om de indexering van sommige inhoud te voorkomen (bijv. tijdens het filteren) gewoon niet kan werken.
Deel 2: Crawlbudget
Tijdens het ontwerpen van een SEO-strategie wilde ik GB naar mijn pijpen laten dansen en niet andersom. Om dit doel te bereiken, controleerde ik de SEO processen op het niveau van de server logs (toegangslogs en error logs), wat mij een enorm voordeel opleverde. Dankzij dat, kende ik elke beweging van GB en hoe het reageerde op de veranderingen die ik introduceerde (website herstructurering, het omdraaien van het interne linking systeem, de manier van het weergeven van informatie) binnen de SEO campagne.
Een van mijn taken tijdens de SEO campagne was het herbouwen van een website op een manier dat GB alleen die URL’s zou bezoeken die het in staat zou zijn om te indexeren en die we wilden dat het zou indexeren. In een notendop: er zouden alleen de pagina’s die voor ons belangrijk zijn vanuit het oogpunt van SEO in de index van Google moeten staan. Aan de andere kant zou GB alleen de websites moeten crawlen waarvan we willen dat ze door Google worden geïndexeerd, wat niet voor iedereen vanzelfsprekend is, bijvoorbeeld wanneer een online winkel filtering implementeert op kleuren, maten en prijzen, en dit wordt gedaan door de URL parameters te manipuleren, bijv.:
voorbeeld.com/vrouwen/schoenen/?color=red&size=40&price=200-250
Het kan blijken dat een oplossing waarmee GB dynamische URL’s kan crawlen, ervoor zorgt dat GB tijd besteedt aan het doorzoeken (en eventueel indexeren) daarvan in plaats van aan het crawlen van de pagina.
voorbeeld.com/women/shoes/
Dergelijke dynamisch aangemaakte URL’s zijn niet alleen nutteloos, maar mogelijk ook schadelijk voor SEO, omdat ze kunnen worden aangezien voor dunne inhoud, wat zal resulteren in een daling van de website rankings.
In dit experiment wilde ik ook enkele methodes van structureren controleren zonder rel=”nofollow” te gebruiken, GB te blokkeren in het robots.txt bestand of een deel van de HTML code in frames te plaatsen die onzichtbaar zijn voor de bot (geblokkeerde iframe).
Ik testte drie soorten JavaScript links.
JavaScript-link met een onclick-event
Een eenvoudige link geconstrueerd op JavaScript
< a href=”javascript:void(0)” onclick=”window.location.href =’page4.html'” >anchor6< /a >
GB gaat gemakkelijk door naar de subpagina page4.html en indexeert de hele pagina. De subpagina komt niet voor in de zoekresultaten voor de anchor6 frase, en deze frase kan niet worden gevonden in de sectie Anchor Texts in Google Search Console. De conclusie is dat de link het sap niet heeft overgebracht.
Om samen te vatten:
- Een klassieke JavaScript-link staat Google toe de website te crawlen en de pagina’s te indexeren waarop het komt.
- Het brengt geen sap over – het is neutraal.
Javascript-link met een interne functie
Ik besloot het spel te verhogen, maar tot mijn verbazing overwon GB het obstakel in minder dan 2 uur na de publicatie van de link.
< a href=”javascript:void(0)” class=”js-link” data-url=”page9.html” >anchor7< /a >
Om deze link te bedienen, gebruikte ik een externe functie, die tot doel had de URL uit de gegevens te lezen en de doorverwijzing – alleen de doorverwijzing van een gebruiker, zoals ik hoopte – naar het doel page9.html. Net als in het eerdere geval was pagina9.html volledig geïndexeerd.
Wat interessant is, is dat ondanks het ontbreken van andere inkomende links, pagina9.html de derde meest bezochte pagina was door GB in de hele webdienst, vlak na pagina1.html en pagina2.html.
Ik had deze methode al eerder gebruikt voor het structureren van webdiensten. Echter, zoals we kunnen zien, werkt het niet meer. In SEO leeft niets voor altijd, behalve de Gouden Gids.
JavaScript link met codering
Toch wilde ik niet opgeven en ik besloot dat er een manier moest zijn om de deur effectief in GB’s gezicht te sluiten. Dus bouwde ik een eenvoudige functie, codeerde de gegevens met een base64 algoritme, en de verwijzing zag er als volgt uit:
< a href=”javascript:void(0)” class=”js-link” data-url=”cGFnZTEwLmh0bWw=” >anchor8< /a >
GB was dus niet in staat om een JavaScript-code te produceren die zowel de inhoud van een data-URL-attribuut zou decoderen als zou redirecten. En daar was het! We hebben een manier om een web service te structureren zonder rel=nonfollows te gebruiken om te voorkomen dat bots gaan crawlen waar ze maar willen! Op deze manier verspillen we ons crawl-budget niet, wat vooral belangrijk is in het geval van grote webdiensten, en GB danst eindelijk naar onze pijpen. Of de functie nu op dezelfde pagina in het hoofdgedeelte of in een extern JS-bestand is ingevoerd, er is geen bewijs van een bot, noch in de serverlogs noch in Search Console.
Deel 3: Verborgen inhoud
In de laatste test wilde ik nagaan of de inhoud in bijvoorbeeld verborgen tabbladen door GB in aanmerking zou worden genomen en geïndexeerd, of dat Google zo’n pagina rendert en de verborgen tekst negeert, zoals sommige specialisten beweren.
Ik wilde deze bewering ofwel bevestigen ofwel verwerpen. Om dat te doen, plaatste ik een muur van tekst met meer dan 2000 tekens op pagina12.html en verborg een blok tekst met ongeveer 20 procent van de tekst (400 tekens) in Cascading Style Sheets en ik voegde de toon meer knop toe. Binnen de verborgen tekst was er een link naar pagina13.html met een anker anker9.
Er is geen twijfel over mogelijk dat een bot een pagina kan renderen. We kunnen het waarnemen in zowel Google Search Console als Google Insight Speed. Niettemin bleek uit mijn tests dat een blok tekst dat werd weergegeven nadat op de knop Meer weergeven was geklikt, volledig werd geïndexeerd. De zinnen verborgen in de tekst werden gerangschikt in de zoekresultaten en GB volgde de links verborgen in de tekst. Bovendien waren de ankers van de links uit een verborgen blok tekst zichtbaar in Google Search Console in de sectie Anchor Text en begon pagina13.html ook te ranken in de zoekresultaten voor het trefwoord anchor9.
Dit is van cruciaal belang voor online winkels, waar inhoud vaak in verborgen tabbladen wordt geplaatst. Nu zijn we er zeker van dat GB de inhoud in verborgen tabbladen ziet, ze indexeert, en het sap van de links die daar verborgen zijn overbrengt.
De belangrijkste conclusie die ik uit dit experiment trek, is dat ik geen directe manier heb gevonden om de First Link Counts Rule te omzeilen door aangepaste links te gebruiken (links met parameter, 301 redirects, canonicals, ankerlinks). Tegelijkertijd is het wel mogelijk om de structuur van een website op te bouwen met behulp van Javascript links, waardoor we vrij zijn van de beperkingen van de First Link Counts Rule. Bovendien, Google Bot kan zien en indexeren inhoud verborgen in bladwijzers en het volgt de links verborgen in hen.
Schrijf u in voor onze dagelijkse recaps van de steeds veranderende search marketing landscape.
Note: Door het indienen van dit formulier, gaat u akkoord met Third Door Media’s voorwaarden. Wij respecteren uw privacy.
Over de auteur

“Accepteer niet ‘gewoon’ hoge kwaliteit. Dat kan iedereen. Als de hemel de limiet is, zoek dan een hogere hemel.” Max Cyrek is CEO van Cyrek Digital, een digitale marketing consultant en SEO evangelist. Doorheen zijn carrière heeft Max, samen met zijn team van meer dan 30, met honderden bedrijven gewerkt om hen te helpen slagen. Hij werkt al bijna tien jaar in digitale marketing en heeft zich gespecialiseerd in technische SEO, het managen van succesvolle marketingprojecten.
Geef een antwoord