Die Menschen erstellen, teilen und speichern Daten schneller als je zuvor in der Geschichte. Wenn es um Innovationen bei der Speicherung und Übertragung dieser Daten geht, machen wir bei Facebook nicht nur Fortschritte bei der Hardware – wie größere Festplatten und schnellere Netzwerkgeräte – sondern auch bei der Software. Software hilft bei der Datenverarbeitung durch Komprimierung, bei der Informationen, wie Text, Bilder und andere Formen digitaler Daten, mit weniger Bits als das Original kodiert werden. Diese kleineren Dateien nehmen weniger Platz auf der Festplatte ein und werden schneller an andere Systeme übertragen. Das Komprimieren und Dekomprimieren von Informationen hat jedoch einen Nachteil: Zeit. Je mehr Zeit für die Komprimierung in eine kleinere Datei aufgewendet wird, desto langsamer werden die Daten verarbeitet.
Heute ist der herrschende Datenkomprimierungsstandard Deflate, der Kernalgorithmus in Zip, gzip und zlib . Seit zwei Jahrzehnten bietet er ein beeindruckendes Gleichgewicht zwischen Geschwindigkeit und Speicherplatz und wird daher in fast jedem modernen elektronischen Gerät verwendet (und nicht zufällig auch für die Übertragung jedes Bytes dieses Blogbeitrags, den Sie gerade lesen). Im Laufe der Jahre haben andere Algorithmen entweder eine bessere oder eine schnellere Komprimierung geboten, aber selten beides. Wir glauben, dass wir das geändert haben.
Wir freuen uns, Zstandard 1.0 ankündigen zu können, einen neuen Kompressionsalgorithmus und eine neue Implementierung, die auf moderne Hardware abgestimmt sind und kleinere und schnellere Komprimierungen ermöglichen. Zstandard kombiniert die jüngsten Durchbrüche bei der Komprimierung, wie Finite State Entropy, mit einem Design, bei dem die Leistung im Vordergrund steht – und optimiert dann die Implementierung für die einzigartigen Eigenschaften moderner CPUs. Das Ergebnis ist eine Verbesserung der Kompromisse, die andere Kompressionsalgorithmen eingehen, und ein breiter Anwendungsbereich mit sehr hoher Dekompressionsgeschwindigkeit. Zstandard, das ab sofort unter der BSD-Lizenz verfügbar ist, kann in nahezu jedem verlustfreien Komprimierungsszenario eingesetzt werden, auch in vielen Fällen, in denen aktuelle Algorithmen nicht anwendbar sind.
- Vergleich der Kompression
- Skalierbarkeit
- Unter der Haube
- Speicher
- Ein für die parallele Ausführung konzipiertes Format
- Branchless Design
- Finite State Entropy: Ein Wahrscheinlichkeitskompressor der nächsten Generation
- Repcode-Modellierung
- Zstandard in der Praxis
- Kleine Daten
- Wörterbücher in Aktion
- Auswahl einer Komprimierungsstufe
- Probieren Sie es aus
- More to come
Vergleich der Kompression
Es gibt drei Standardmetriken zum Vergleich von Kompressionsalgorithmen und -implementierungen:
- Kompressionsverhältnis: Die ursprüngliche Größe (Zähler) im Vergleich zur komprimierten Größe (Nenner), gemessen in einheitslosen Daten als Größenverhältnis von 1,0 oder größer.
- Komprimierungsgeschwindigkeit: Wie schnell können die Daten verkleinert werden, gemessen in MB/s der verbrauchten Eingangsdaten.
- Dekomprimierungsgeschwindigkeit: Wie schnell können die Originaldaten aus den komprimierten Daten rekonstruiert werden, gemessen in MB/s für die Rate, mit der Daten aus den komprimierten Daten erzeugt werden.
Die Art der komprimierten Daten kann sich auf diese Metriken auswirken, daher sind viele Algorithmen auf bestimmte Datentypen abgestimmt, z. B. auf englischen Text, genetische Sequenzen oder gerasterte Bilder. Zstandard ist jedoch, wie zlib, für eine allgemeine Komprimierung für eine Vielzahl von Datentypen gedacht. Um die Algorithmen darzustellen, mit denen Zstandard arbeiten soll, verwenden wir in diesem Beitrag den Silesia-Korpus, einen Datensatz mit Dateien, die die typischen, täglich verwendeten Datentypen repräsentieren.
Einige Algorithmen und Implementierungen, die heute häufig verwendet werden, sind zlib, lz4 und xz. Jeder dieser Algorithmen bietet unterschiedliche Kompromisse: lz4 zielt auf Geschwindigkeit, xz auf höhere Kompressionsraten und zlib auf ein gutes Gleichgewicht zwischen Geschwindigkeit und Größe. Die nachstehende Tabelle zeigt die groben Kompromisse zwischen der Standardkomprimierungsrate und der Geschwindigkeit der Algorithmen für den Silesia-Korpus, indem die Algorithmen mit lzbench verglichen werden, einem reinen In-Memory-Benchmark, der die Leistung der Algorithmen modellieren soll.
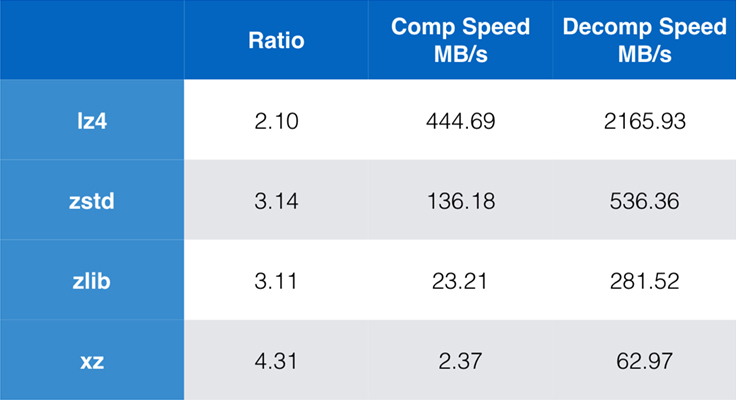
Wie bereits erwähnt, gibt es oft drastische Kompromisse zwischen Geschwindigkeit und Größe. Der schnellste Algorithmus, lz4, führt zu niedrigeren Kompressionsraten; xz, der die höchste Kompressionsrate hat, leidet unter einer langsamen Kompressionsgeschwindigkeit. Zstandard zeigt jedoch in der Standardeinstellung erhebliche Verbesserungen sowohl bei der Kompressions- als auch bei der Dekompressionsgeschwindigkeit und komprimiert dabei mit demselben Verhältnis wie zlib.
Während die Leistung des reinen Algorithmus wichtig ist, wenn die Komprimierung in eine größere Anwendung eingebettet ist, werden häufig auch Befehlszeilentools für die Komprimierung verwendet – z. B. für die Komprimierung von Protokolldateien, Tarballs oder anderen ähnlichen Daten, die für die Speicherung oder Übertragung bestimmt sind. In diesen Fällen wird die Leistung oft durch Overhead wie die Prüfsummenbildung beeinträchtigt. Dieses Diagramm zeigt den Vergleich der gzip- und zstd-Befehlszeilen-Tools auf Centos 7, das mit dem Standard-Compiler des Systems erstellt wurde.
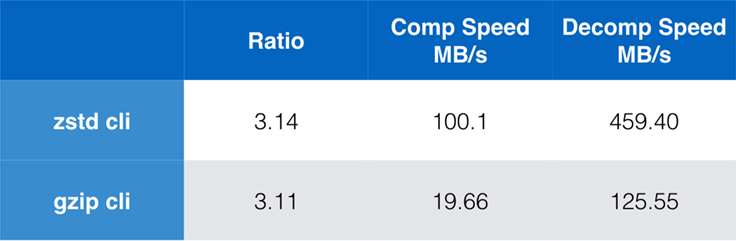
Die Tests wurden jeweils 10 Mal durchgeführt, wobei die Mindestzeiten genommen wurden, und wurden auf Ramdisk durchgeführt, um Dateisystem-Overhead zu vermeiden. Dies waren die Befehle (die die Standard-Komprimierungsstufen für beide Tools verwenden):
zstd -c -3 silesia.tar > silesia.tar.zst # 67,432,740 byteszstd -d -c silesia.tar.zst > /dev/nullgzip -c -6 silesia.tar > silesia.tar.gz # 68,235,522 bytesgzip -d -c silesia.tar.gz > /dev/nullSkalierbarkeit
Wenn ein Algorithmus skalierbar ist, hat er die Fähigkeit, sich an eine Vielzahl von Anforderungen anzupassen, und Zstandard ist so konzipiert, dass er sich in der heutigen Landschaft auszeichnet und in die Zukunft skaliert. Die meisten Algorithmen haben „Stufen“, die auf Zeit/Raum-Abwägungen basieren: Je höher die Stufe, desto stärker ist die Komprimierung bei gleichzeitigem Verlust an Komprimierungsgeschwindigkeit. Zlib bietet neun Komprimierungsstufen; Zstandard bietet derzeit 22, was flexible, granulare Kompromisse zwischen Komprimierungsgeschwindigkeit und -quoten für zukünftige Daten ermöglicht. Zum Beispiel können wir Stufe 1 verwenden, wenn die Geschwindigkeit am wichtigsten ist, und Stufe 22, wenn die Größe am wichtigsten ist.
Unten sehen Sie ein Diagramm der Kompressionsgeschwindigkeit und des Kompressionsverhältnisses, die für alle Stufen von Zstandard und zlib erreicht wurden. Die x-Achse ist eine abnehmende logarithmische Skala in Megabytes pro Sekunde; die y-Achse ist das erreichte Kompressionsverhältnis. Um die Algorithmen zu vergleichen, können Sie eine Geschwindigkeit auswählen, um die verschiedenen Verhältnisse zu sehen, die die Algorithmen bei dieser Geschwindigkeit erreichen. Ebenso können Sie einen Wert wählen und sehen, wie schnell die Algorithmen sind, wenn sie diesen Wert erreichen.
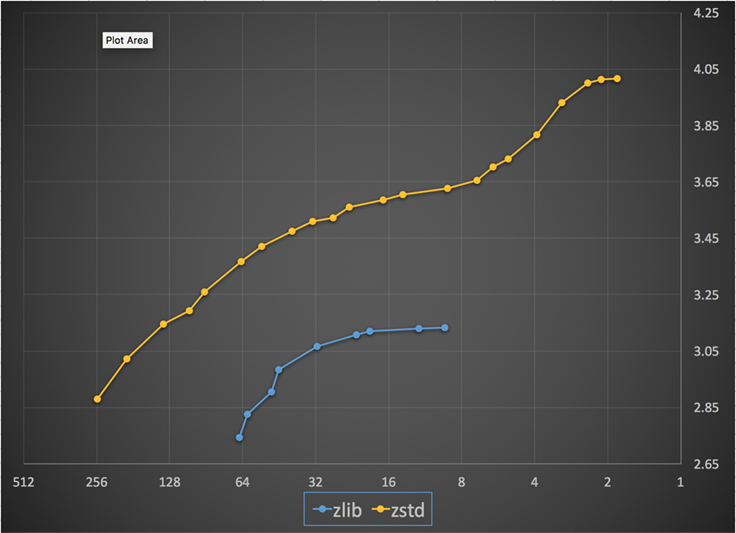
Für jede vertikale Linie (d.h. Kompressionsgeschwindigkeit) erreicht Zstandard eine höhere Kompressionsrate. Für das Silesia-Korpus betrug die Dekomprimierungsgeschwindigkeit – unabhängig von der Ratio – etwa 550 MB/s für Zstandard und 270 MB/s für zlib. Die Grafik zeigt einen weiteren Unterschied zwischen Zstandard und den Alternativen: Durch die Verwendung eines einzigen Algorithmus und einer einzigen Implementierung ermöglicht Zstandard eine viel feinere Abstimmung für jeden Anwendungsfall. Das bedeutet, dass Zstandard mit einigen der schnellsten und stärksten Komprimierungsalgorithmen konkurrieren kann und gleichzeitig einen erheblichen Geschwindigkeitsvorteil bei der Dekomprimierung aufweist. Diese Verbesserungen schlagen sich direkt in einer schnelleren Datenübertragung und geringeren Speicheranforderungen nieder.
Mit anderen Worten, im Vergleich zu zlib skaliert Zstandard:
- Bei gleichem Kompressionsverhältnis komprimiert es wesentlich schneller: ~3-5x.
- Bei gleicher Kompressionsgeschwindigkeit ist er wesentlich kleiner: 10-15 Prozent kleiner.
- Beim Dekomprimieren ist er fast 2x schneller, unabhängig von der Kompressionsrate; die Zahlen der Kommandozeilentools zeigen einen noch größeren Unterschied: mehr als 3x schneller.
- Es skaliert zu viel höheren Kompressionsverhältnissen, während es blitzschnelle Dekompressionsgeschwindigkeiten beibehält.
Unter der Haube
Zstandard verbessert zlib, indem es mehrere aktuelle Innovationen kombiniert und auf moderne Hardware abzielt:
Speicher
Durch das Design ist zlib auf ein 32 KB-Fenster beschränkt, was in den frühen 90er Jahren eine vernünftige Wahl war. Heutige Computerumgebungen können jedoch auf viel mehr Speicher zugreifen – sogar in mobilen und eingebetteten Umgebungen.
Zstandard hat keine inhärente Begrenzung und kann Terabytes an Speicher adressieren (auch wenn es selten geschieht). Die untere der 22 Stufen benötigt beispielsweise 1 MB oder weniger. Um die Kompatibilität mit einer Vielzahl von Empfangssystemen zu gewährleisten, bei denen der Speicher begrenzt sein kann, wird empfohlen, die Speichernutzung auf 8 MB zu begrenzen. Dies ist jedoch eine Tuning-Empfehlung und keine Einschränkung des Komprimierungsformats.
Ein für die parallele Ausführung konzipiertes Format
Die heutigen CPUs sind sehr leistungsfähig und können dank mehrerer ALUs (arithmetische Logikeinheiten) und eines zunehmend fortschrittlichen Out-of-Order-Ausführungsdesigns mehrere Befehle pro Zyklus ausführen.
Im Wesentlichen bedeutet dies, dass wenn:
a = b1 + b2
c = d1 + d2
dann sowohl a als auch c parallel berechnet werden.
Dies ist nur möglich, wenn es keine Beziehung zwischen ihnen gibt. Daher muss in diesem Beispiel:
a = b1 + b2
c = d1 + a
c zuerst auf die Berechnung von a warten, und erst dann beginnt die Berechnung von c.
Das bedeutet, dass man, um die Vorteile einer modernen CPU zu nutzen, einen Ablauf von Operationen mit wenigen oder gar keinen Datenabhängigkeiten entwerfen muss.
Dies wird mit Zstandard erreicht, indem die Daten in mehrere parallele Ströme aufgeteilt werden. Ein Huffman-Decoder der neuen Generation, Huff0, ist in der Lage, mehrere Symbole parallel mit einem einzigen Kern zu dekodieren. Dieser Gewinn ist kumulativ mit Multi-Threading, bei dem mehrere Kerne verwendet werden.
Branchless Design
Neue CPUs sind leistungsfähiger und erreichen sehr hohe Frequenzen, aber dies ist nur dank eines mehrstufigen Ansatzes möglich, bei dem ein Befehl in eine Pipeline mit mehreren Schritten aufgeteilt wird. Bei jedem Taktzyklus kann die CPU das Ergebnis mehrerer Operationen ausgeben, je nach den verfügbaren ALUs. Je mehr ALUs verwendet werden, desto mehr Arbeit hat die CPU, und desto schneller erfolgt die Komprimierung. Die ALUs mit Arbeit zu versorgen, ist entscheidend für die Leistung moderner CPUs.
Das erweist sich als schwierig. Betrachten wir die folgende einfache Situation:
if (condition) doSomething() else doSomethingElse()Wenn sie auf diese Situation stößt, weiß die CPU nicht, was sie tun soll, da sie vom Wert von condition abhängt. Eine vorsichtige CPU würde das Ergebnis von condition abwarten, bevor sie an einem der beiden Zweige arbeitet, was extrem verschwenderisch wäre.
Heutige CPUs spielen. Sie tun dies auf intelligente Weise, dank eines Verzweigungsprädiktors, der ihnen im Wesentlichen das wahrscheinlichste Ergebnis der Auswertung von condition mitteilt. Wenn die Wette richtig ist, bleibt die Pipeline voll und es werden kontinuierlich Befehle ausgegeben. Wenn die Wette falsch ist (eine Fehlprognose), muss die CPU alle spekulativ gestarteten Operationen stoppen, zur Verzweigung zurückkehren und die andere Richtung einschlagen. Dies wird als Pipeline-Flush bezeichnet und ist bei modernen CPUs extrem kostspielig.
Vor fünfundzwanzig Jahren war der Pipeline-Flush kein Thema. Heute ist es so wichtig, dass es unerlässlich ist, Formate zu entwickeln, die mit verzweigungslosen Algorithmen kompatibel sind. Betrachten wir als Beispiel eine Bitstrom-Aktualisierung:
/* classic version */while (nbBitsUsed >= 8) { /* each while test is a branch */ accumulator <<= 8; accumulator += *byte++; nbBitsUsed -= 8;} /*>/* branch-less version */nbBytesUsed = nbBitsUsed >> 3;nbBitsUsed &= 7;ptr += nbBytesUsed;accumulator = read64(ptr);Wie Sie sehen können, hat die verzweigungslose Version eine vorhersehbare Arbeitslast, ohne jede Bedingung. Die CPU wird immer die gleiche Arbeit verrichten, und diese Arbeit wird niemals aufgrund einer falschen Vorhersage weggeworfen. Im Gegensatz dazu macht die klassische Version weniger Arbeit, wenn (nbBitsUsed < 8). Aber der Test selbst ist nicht kostenlos, und jedes Mal, wenn der Test falsch erraten wird, führt dies zu einem vollständigen Flush der Pipeline, was mehr kostet als die Arbeit, die von der verzweigungslosen Version geleistet wird.
Wie Sie sich denken können, hat dieser Nebeneffekt Auswirkungen auf die Art und Weise, wie Daten gepackt, gelesen und dekodiert werden. Zstandard wurde entwickelt, um verzweigungslose Algorithmen zu unterstützen, insbesondere innerhalb kritischer Schleifen.
Finite State Entropy: Ein Wahrscheinlichkeitskompressor der nächsten Generation
Bei der Komprimierung werden die Daten zunächst in eine Reihe von Symbolen umgewandelt (die Modellierungsphase), und dann werden diese Symbole mit einer minimalen Anzahl von Bits kodiert. Diese zweite Stufe wird in Anlehnung an Claude Shannon als Entropie-Stufe bezeichnet, die die Kompressionsgrenze einer Menge von Symbolen mit bestimmten Wahrscheinlichkeiten genau berechnet (die so genannte „Shannon-Grenze“). Das Ziel ist es, sich dieser Grenze zu nähern und dabei so wenig CPU-Ressourcen wie möglich zu verbrauchen.
Ein sehr verbreiteter Algorithmus ist die Huffman-Kodierung, die in Deflate verwendet wird. Er liefert den bestmöglichen Präfixcode, wobei davon ausgegangen wird, dass jedes Symbol mit einer natürlichen Anzahl von Bits beschrieben wird (1 Bit, 2 Bits …). Dies funktioniert in der Praxis sehr gut, aber die Begrenzung der natürlichen Zahlen bedeutet, dass es unmöglich ist, hohe Kompressionsraten zu erreichen, da ein Symbol notwendigerweise mindestens 1 Bit verbraucht.
Eine bessere Methode ist die sogenannte arithmetische Kodierung, die beliebig nahe an die Shannon-Grenze -log2(P) herankommen kann und daher Bruchteile von Bits pro Symbol verbraucht. Dies führt zu einem besseren Komprimierungsverhältnis, wenn die Wahrscheinlichkeiten hoch sind, verbraucht aber auch mehr CPU-Leistung. In der Praxis haben selbst optimierte arithmetische Kodierer mit der Geschwindigkeit zu kämpfen, insbesondere bei der Dekomprimierung, die Divisionen mit einem vorhersehbaren Ergebnis (z. B. kein Fließkomma) erfordert und sich als langsam erweist.
Die Finite State Entropie basiert auf einer neuen Theorie namens ANS (Asymmetric Numeral System) von Jarek Duda. Finite State Entropy ist eine Variante, bei der viele Kodierungsschritte in Tabellen vorberechnet werden, was zu einem Entropie-Codec führt, der so präzise ist wie die arithmetische Kodierung und nur Additionen, Tabellennachschlageoperationen und Verschiebungen verwendet, was in etwa dem Komplexitätsgrad von Huffman entspricht. Außerdem verringert sich die Latenzzeit für den Zugriff auf das nächste Symbol, da es unmittelbar aus dem Zustandswert abrufbar ist, während bei Huffman eine vorherige Bitstromdekodierung erforderlich ist. Es würde den Rahmen dieses Beitrags sprengen, die Funktionsweise zu erklären, aber wenn Sie daran interessiert sind, gibt es eine Reihe von Artikeln, in denen die Funktionsweise detailliert beschrieben wird.
Repcode-Modellierung
Repcode-Modellierung komprimiert effizient strukturierte Daten, die Sequenzen mit nahezu gleichem Inhalt aufweisen, die sich nur um ein oder wenige Bytes unterscheiden. Diese Methode ist nicht neu, wurde aber erst nach der Veröffentlichung von Deflate eingesetzt und existiert daher nicht in zlib/gzip.
Die Effizienz der Repcode-Modellierung hängt stark von der Art der zu komprimierenden Daten ab und reicht von einer ein- bis zu einer zweistelligen Kompressionsverbesserung. Diese kombinierten Verbesserungen führen zu einer besseren und schnelleren Komprimierung, die in der Zstandard-Bibliothek angeboten wird.
Zstandard in der Praxis
Wie bereits erwähnt, gibt es mehrere typische Anwendungsfälle für Komprimierung. Damit ein Algorithmus überzeugend ist, muss er entweder außerordentlich gut in einem bestimmten Anwendungsfall sein, wie z.B. der Komprimierung von menschenlesbarem Text, oder sehr gut in vielen verschiedenen Anwendungsfällen. Zstandard wählt den letzteren Ansatz. Eine Möglichkeit, über Anwendungsfälle nachzudenken, ist die Frage, wie oft ein bestimmtes Stück Daten dekomprimiert werden kann. Zstandard hat in all diesen Fällen Vorteile.
Viele Male. Bei Daten, die viele Male verarbeitet werden, sind die Dekomprimierungsgeschwindigkeit und die Möglichkeit, eine sehr hohe Kompressionsrate zu wählen, ohne die Dekomprimierungsgeschwindigkeit zu beeinträchtigen, von Vorteil. Die Speicherung des sozialen Graphen auf Facebook zum Beispiel wird wiederholt gelesen, wenn Sie und Ihre Freunde mit der Website interagieren. Außerhalb von Facebook gehören zu den Beispielen, bei denen Daten viele Male dekomprimiert werden müssen, Dateien, die von einem Server heruntergeladen werden, wie der Quellcode des Linux-Kernels oder die auf Servern installierten RPMs, das von einer Webseite verwendete JavaScript und CSS oder die Ausführung Tausender von MapReduces über Daten in einem Data Warehouse.
Einmal. Für Daten, die nur einmal komprimiert werden, insbesondere für die Übertragung über ein Netzwerk, ist die Kompression ein flüchtiger Moment im Datenfluss. Je weniger Overhead auf dem Server anfällt, desto mehr Anfragen kann der Server pro Sekunde bearbeiten. Der geringere Overhead auf dem Client bedeutet, dass die Daten schneller verarbeitet werden können. Dies ist in der Regel bei Client/Server-Situationen der Fall, bei denen die Daten für den Client einzigartig sind, wie z. B. bei einer benutzerdefinierten Webserver-Antwort – z. B. die Daten, die zum Rendern verwendet werden, wenn Sie eine Nachricht von einem Freund über Messenger erhalten. Das Ergebnis ist, dass Ihr mobiles Gerät Seiten schneller lädt, weniger Akku verbraucht und weniger von Ihrem Datentarif in Anspruch nimmt. Zstandard eignet sich insbesondere für mobile Szenarien viel besser als andere Algorithmen, da er mit kleinen Datenmengen umgehen kann.
Wahrscheinlich nie. Obwohl es scheinbar kontraintuitiv ist, ist es oft der Fall, dass ein Teil der Daten – wie Backups oder Protokolldateien – nie dekomprimiert wird, aber bei Bedarf gelesen werden kann. Für diese Art von Daten muss die Komprimierung in der Regel schnell sein, die Daten klein machen (mit einem der Situation angemessenen Zeit-/Platzverhältnis) und vielleicht eine Prüfsumme speichern, aber ansonsten unsichtbar sein. In den seltenen Fällen, in denen die Daten dekomprimiert werden müssen, soll die Komprimierung den operativen Anwendungsfall nicht verlangsamen. Eine schnelle Dekomprimierung ist vorteilhaft, da oft nur ein kleiner Teil der Daten (z.B. eine bestimmte Datei im Backup oder eine Nachricht in einer Protokolldatei) schnell gefunden werden muss.
In all diesen Fällen bietet Zstandard die Möglichkeit, um ein Vielfaches schneller zu komprimieren und zu dekomprimieren als gzip, wobei die komprimierten Daten kleiner sind.
Kleine Daten
Es gibt noch einen weiteren Anwendungsfall für die Komprimierung, der weniger Beachtung findet, aber sehr wichtig sein kann: kleine Daten. Dabei handelt es sich um Anwendungsmuster, bei denen Daten in kleinen Mengen erzeugt und verbraucht werden, z. B. JSON-Nachrichten zwischen einem Webserver und einem Browser (typischerweise Hunderte von Bytes) oder Datenseiten in einer Datenbank (einige Kilobytes).
Datenbanken stellen einen interessanten Anwendungsfall dar. Systeme wie MySQL, PostgreSQL und MongoDB speichern alle Daten für den Echtzeitzugriff. Die jüngsten Hardwarevorteile, insbesondere die Verbreitung von Flash-Geräten (SSD), haben das Gleichgewicht zwischen Größe und Durchsatz grundlegend verändert – wir leben jetzt in einer Welt, in der die IOPs (IO-Operationen pro Sekunde) recht hoch sind, aber die Kapazität unserer Speichergeräte geringer ist als zu der Zeit, als Festplatten das Rechenzentrum beherrschten.
Außerdem hat Flash eine interessante Eigenschaft in Bezug auf die Schreibbeständigkeit – nach Tausenden von Schreibvorgängen auf denselben Abschnitt des Geräts kann dieser Abschnitt keine Schreibvorgänge mehr annehmen, was oft dazu führt, dass das Gerät außer Betrieb genommen wird. Daher ist es naheliegend, nach Möglichkeiten zu suchen, die Menge der geschriebenen Daten zu reduzieren, da dies mehr Daten pro Server bedeuten kann und das Gerät langsamer ausbrennt. Die Datenkomprimierung ist eine Strategie hierfür, und Datenbanken werden häufig auch auf Leistung optimiert, d.h. Lese- und Schreibleistung sind gleichermaßen wichtig.
Die Verwendung der Datenkomprimierung bei Datenbanken ist jedoch mit einem Problem verbunden. Datenbanken greifen gerne zufällig auf Daten zu, während die meisten typischen Anwendungsfälle für die Komprimierung eine ganze Datei in linearer Reihenfolge lesen. Dies ist ein Problem, da die Datenkomprimierung im Wesentlichen durch die Vorhersage der Zukunft auf der Grundlage der Vergangenheit funktioniert – die Algorithmen sehen sich Ihre Daten nacheinander an und sagen voraus, was sie in der Zukunft sehen könnten. Je genauer die Vorhersagen sind, desto kleiner können die Daten werden.
Bei der Komprimierung kleiner Daten, wie z. B. Seiten in einer Datenbank oder winzige JSON-Dokumente, die an Ihr mobiles Gerät gesendet werden, gibt es einfach nicht viel „Vergangenheit“, die für die Vorhersage der Zukunft genutzt werden kann. Komprimierungsalgorithmen haben versucht, dieses Problem durch die Verwendung von gemeinsam genutzten Wörterbüchern zu lösen, um einen effektiven Frühstart zu ermöglichen. Dies geschieht durch die gemeinsame Nutzung eines statischen Satzes „vergangener“ Daten als Ausgangspunkt für die Komprimierung.
Zstandard baut auf diesem Ansatz mit hochoptimierten Algorithmen und APIs für die Wörterbuchkomprimierung auf. Darüber hinaus enthält Zstandard Werkzeuge (zstd --train) zur einfachen Erstellung von Wörterbüchern für benutzerdefinierte Anwendungen und Vorkehrungen für die Registrierung von Standardwörterbüchern zur gemeinsamen Nutzung mit größeren Gemeinschaften. Während die Komprimierung je nach Datenmuster variiert, kann die Komprimierung kleiner Daten zwischen 2 und 5 Mal besser sein als die Komprimierung ohne Wörterbücher.
Wörterbücher in Aktion
Während es schwierig sein kann, mit einem Wörterbuch im Kontext einer laufenden Datenbank zu spielen (es erfordert schließlich erhebliche Änderungen an der Datenbank), können Sie Wörterbücher in Aktion mit anderen Arten von kleinen Daten sehen. JSON, die lingua franca der kleinen Daten in der modernen Welt, besteht in der Regel aus kleinen, sich wiederholenden Datensätzen. Es gibt unzählige öffentliche Datensätze; für diese Demonstration verwenden wir den „Benutzer“-Datensatz von GitHub, der über HTTP verfügbar ist. Hier ist ein Beispieleintrag aus diesem Datensatz:
{ "login": "octocat", "id": 1, "avatar_url": "https://github.com/images/error/octocat_happy.gif", "gravatar_id": "", "url": "https://api.github.com/users/octocat", "html_url": "https://github.com/octocat", "followers_url": "https://api.github.com/users/octocat/followers", "following_url": "https://api.github.com/users/octocat/following{/other_user}", "gists_url": "https://api.github.com/users/octocat/gists{/gist_id}", "starred_url": "https://api.github.com/users/octocat/starred{/owner}{/repo}", "subscriptions_url": "https://api.github.com/users/octocat/subscriptions", "organizations_url": "https://api.github.com/users/octocat/orgs", "repos_url": "https://api.github.com/users/octocat/repos", "events_url": "https://api.github.com/users/octocat/events{/privacy}", "received_events_url": "https://api.github.com/users/octocat/received_events", "type": "User", "site_admin": false }Wie Sie sehen können, gibt es hier eine ganze Menge Wiederholungen – wir können diese gut komprimieren! Aber jeder Benutzer ist etwas weniger als 1 KB groß, und die meisten Komprimierungsalgorithmen brauchen mehr Daten, um sich zu bewähren. Ein Satz von 1.000 Benutzern benötigt etwa 850 KB, um unkomprimiert gespeichert zu werden. Wendet man nun gzip oder zstd auf jede einzelne Datei an, verringert sich dieser Wert auf knapp über 300 KB – nicht schlecht! Wenn wir jedoch ein einmaliges, gemeinsam genutztes Wörterbuch mit zstd erstellen, sinkt die Größe auf 122 KB – und das ursprüngliche Komprimierungsverhältnis von 2,8x auf 6,9. Dies ist eine erhebliche Verbesserung, die mit zstd sofort verfügbar ist:
$ zstd --train -o ../json.zdict -r .sorting 982 files of total size 0 MB ...finding patterns ...statistics ...Save dictionary of size 65599 into file ../json.zdict$ du -h --apparent-size .846K .$ zstd --rm -D ../json.zdict -r .$ du -h --apparent-size .122K .Auswahl einer Komprimierungsstufe
Wie oben gezeigt, bietet Zstandard eine beträchtliche Anzahl von Stufen. Diese Anpassungsmöglichkeiten sind leistungsstark, führen aber zu schwierigen Entscheidungen. Der beste Weg, eine Entscheidung zu treffen, besteht darin, Ihre Daten zu prüfen und zu messen und zu entscheiden, welche Kompromisse Sie eingehen wollen. Bei Facebook halten wir die Standardstufe 3 für viele Anwendungsfälle für geeignet, aber von Zeit zu Zeit passen wir sie leicht an, je nachdem, wo unser Engpass liegt (oft versuchen wir, eine Netzwerkverbindung oder eine Festplattenspindel zu sättigen); manchmal ist uns die gespeicherte Größe wichtiger und wir verwenden eine höhere Stufe.
Um die auf Ihre Bedürfnisse am besten zugeschnittenen Ergebnisse zu erzielen, müssen Sie sowohl die von Ihnen verwendete Hardware als auch die Daten, die Ihnen wichtig sind, berücksichtigen – es gibt keine festen und schnellen Vorschriften, die ohne Kontext gemacht werden können. Im Zweifelsfall sollten Sie jedoch entweder bei der Standardstufe 3 oder bei einer Stufe zwischen 6 und 9 bleiben, um einen guten Kompromiss zwischen Geschwindigkeit und Speicherplatz zu erzielen; Stufe 20+ sollten Sie für Fälle aufsparen, in denen Ihnen wirklich nur die Größe und nicht die Kompressionsgeschwindigkeit wichtig ist.
Probieren Sie es aus
Zstandard ist sowohl ein Kommandozeilenprogramm (zstd) als auch eine Bibliothek. Es ist in hochgradig portierbarem C geschrieben, wodurch es für praktisch jede heute verwendete Plattform geeignet ist – seien es die Server, auf denen Ihr Unternehmen läuft, Ihr Laptop oder sogar das Telefon in Ihrer Tasche. Sie können es aus unserem Github-Repository herunterladen, mit einem einfachen make install kompilieren und es wie gzip verwenden:
$ zstd access.logaccess.log : 8.07% (6695078 => 540336 bytes, access.log.zst)Wie zu erwarten, können Sie es als Teil einer Befehlspipeline verwenden, zum Beispiel, um Ihre kritische MySQL-Datenbank zu sichern:
$ mysqldump --single-transaction --opt pokemon | zstd -q -o /srv/backups/mysqldump.sql.zstDer tar-Befehl unterstützt verschiedene Komprimierungsimplementierungen out-of-box, so dass Sie nach der Installation von Zstandard sofort mit Tarballs arbeiten können, die mit Zstandard komprimiert wurden. Hier ist ein einfaches Beispiel, das die Verwendung mit tar und den Geschwindigkeitsunterschied zu gzip zeigt:
$ time tar -I zstd -cf linux-4.6.4.tar.zst linux-4.6.4tar -I zstd -cf linux-4.6.4.tar.zst linux-4.6.4 3.15s user 0.50s system 107% cpu 3.396 total$ time tar -zcf linux-4.6.4.tar.gz linux-4.6.4tar -zcf linux-4.6.4.tar.gz linux-4.6.4 13.74s user 0.43s system 102% cpu 13.784 totalNeben der Verwendung auf der Kommandozeile gibt es die APIs, die in den Header-Dateien im Repository dokumentiert sind (beginnen Sie hier für einen Überblick über die APIs). Wir enthalten auch eine zlib-kompatible Wrapper-API (libWrapper) zur einfacheren Integration mit Tools, die bereits über zlib-Schnittstellen verfügen. Schließlich enthalten wir eine Reihe von Beispielen, sowohl für die grundlegende Verwendung als auch für fortgeschrittene Anwendungen wie Wörterbücher und Streaming, ebenfalls im GitHub-Repository.
More to come
Während wir 1.0 erreicht haben und Zstandard als bereit für jede Art von Produktionseinsatz betrachten, sind wir noch nicht fertig. In zukünftigen Versionen:
- Multi-Thread-Kommandozeilen-Kompression für noch schnelleren Durchsatz bei großen Datensätzen, ähnlich dem pigz-Tool für zlib.
- Neue Kompressionsstufen, in beide Richtungen, die eine noch schnellere Kompression und höhere Raten ermöglichen.
- Ein von der Community gepflegter Satz vordefinierter Komprimierungswörterbücher für gängige Datensätze wie JSON, HTML und gängige Netzwerkprotokolle.
Wir möchten uns bei allen bedanken, die mit ihrem Code und ihrem Feedback dazu beigetragen haben, dass wir 1.0 erreichen konnten. Dies ist erst der Anfang. Wir wissen, dass wir Ihre Hilfe brauchen, damit Zstandard sein Potenzial voll ausschöpfen kann. Wie bereits erwähnt, können Sie Zstandard noch heute ausprobieren, indem Sie den Quellcode oder vorgefertigte Binärdateien von unserem GitHub-Projekt herunterladen oder, für Mac-Nutzer, über Homebrew (brew install zstd) installieren. Wir würden uns über Feedback und interessante Anwendungsfälle freuen, ebenso wie über zusätzliche Sprachbindungen und Hilfe bei der Integration in Ihre bevorzugten Open-Source-Projekte.
Fußnoten
- Während die verlustfreie Datenkompression im Mittelpunkt dieses Beitrags steht, gibt es ein verwandtes, aber sehr unterschiedliches Feld der verlustbehafteten Datenkompression, die hauptsächlich für Bilder, Audio und Video verwendet wird.
- Deflate, zlib, gzip – drei Namen, die miteinander verbunden sind. Deflate ist der Algorithmus, der von den Implementierungen von zlib und gzip verwendet wird. Zlib ist eine Bibliothek, die Deflate bereitstellt, und gzip ist ein Befehlszeilenwerkzeug, das zlib zur Deflatierung von Daten sowie zur Prüfsummenbildung verwendet. Diese Prüfsummenbildung kann einen erheblichen Overhead verursachen.
- Alle Benchmarks wurden auf einem Intel E5-2678 v3 mit 2,5 GHz auf einer Centos 7-Maschine durchgeführt. Die Kommandozeilen-Tools (
zstdundgzip) wurden mit dem System GCC, 4.8.5, erstellt. Die von lzbench durchgeführten Algorithmus-Benchmarks wurden mit GCC 6.
erstellt.
Schreibe einen Kommentar