In diesem Beitrag werden wir einen Blick auf die am häufigsten verwendeten Algorithmen des maschinellen Lernens werfen. Es gibt eine riesige Auswahl an Algorithmen, und man ist leicht verwirrt, wenn man Begriffe wie „instanzbasierte Lernalgorithmen“ und „Perzeptron“ hört.
In der Regel werden alle maschinellen Lernalgorithmen in Gruppen eingeteilt, die entweder auf ihrem Lernstil, ihrer Funktion oder den Problemen, die sie lösen, basieren. In diesem Beitrag finden Sie eine Klassifizierung auf der Grundlage des Lernstils. Ich werde auch die gemeinsamen Aufgaben erwähnen, die diese Algorithmen zu lösen helfen.
Die Zahl der heute verwendeten Algorithmen für maschinelles Lernen ist groß, und ich werde nicht 100% von ihnen erwähnen. Ich möchte jedoch einen Überblick über die am häufigsten verwendeten Algorithmen geben.
- Überwachte Lernalgorithmen
- Klassifizierungsalgorithmen
- Naive Bayes
- Multinomial Naive Bayes
- Logistische Regression
- Entscheidungsbäume
- SVM (Support Vector Machine)
- Regressionsalgorithmen
- Lineare Regression
- Unüberwachte Lernalgorithmen
- Clustering
- K-means clustering
- K-nearest neighbor
- Dimensionalitätsreduktion
- Assoziationsregel-Lernen
- Verstärkungslernen
- Q-Learning
- Ensemble-Lernen
- Bagging
- Boosting
- Random forest
- Stacking
- Neuronale Netze
- Abschluss
Überwachte Lernalgorithmen

Wenn Sie mit Begriffen wie „überwachtes Lernen“ und „unüberwachtes Lernen“ nicht vertraut sind, lesen Sie unseren Beitrag KI vs. ML, in dem dieses Thema ausführlich behandelt wird. Machen wir uns nun mit den Algorithmen vertraut.
Klassifizierungsalgorithmen
Naive Bayes

Bayes’sche Algorithmen sind eine Familie von probabilistischen Klassifizierern, die in ML auf der Anwendung des Bayes’schen Theorems basieren.
Der Naive-Bayes-Klassifikator war einer der ersten Algorithmen, die für das maschinelle Lernen verwendet wurden. Er eignet sich für binäre und Multiklassenklassifizierung und ermöglicht Vorhersagen und Prognosen auf der Grundlage historischer Ergebnisse. Ein klassisches Beispiel sind Systeme zur Spam-Filterung, die bis 2010 Naive Bayes verwendeten und zufriedenstellende Ergebnisse zeigten. Als jedoch die Bayes’sche Vergiftung erfunden wurde, begannen die Programmierer, über andere Möglichkeiten der Datenfilterung nachzudenken.
Mit Hilfe des Bayes’schen Theorems lässt sich feststellen, wie sich das Auftreten eines Ereignisses auf die Wahrscheinlichkeit eines anderen Ereignisses auswirkt.
Dieser Algorithmus berechnet zum Beispiel die Wahrscheinlichkeit, dass eine bestimmte E-Mail Spam ist oder nicht, anhand der verwendeten typischen Wörter. Übliche Spam-Wörter sind „Angebot“, „Jetzt bestellen“ oder „Zusatzeinkommen“. Wenn der Algorithmus diese Wörter erkennt, ist die Wahrscheinlichkeit hoch, dass es sich bei der E-Mail um Spam handelt.
Naive Bayes geht davon aus, dass die Merkmale unabhängig sind. Daher wird der Algorithmus als naiv bezeichnet.
Multinomial Naive Bayes
Neben dem Naive Bayes Klassifikator gibt es weitere Algorithmen in dieser Gruppe. Zum Beispiel Multinomial Naive Bayes, der normalerweise für die Klassifizierung von Dokumenten auf der Grundlage der Häufigkeit bestimmter Wörter im Dokument verwendet wird.
Bayes’sche Algorithmen werden immer noch für die Textkategorisierung und Betrugserkennung verwendet. Sie können auch für das maschinelle Sehen (z. B. Gesichtserkennung), die Marktsegmentierung und die Bioinformatik verwendet werden.
Logistische Regression
Auch wenn der Name kontraintuitiv erscheinen mag, ist die logistische Regression eigentlich eine Art Klassifizierungsalgorithmus.
Die logistische Regression ist ein Modell, das Vorhersagen unter Verwendung einer logistischen Funktion macht, um die Abhängigkeit zwischen den Ausgangs- und Eingangsvariablen zu ermitteln. Statquest hat ein großartiges Video erstellt, in dem der Unterschied zwischen linearer und logistischer Regression am Beispiel fettleibiger Mäuse erklärt wird.
Entscheidungsbäume
Ein Entscheidungsbaum ist eine einfache Möglichkeit, ein Entscheidungsmodell in Form eines Baums zu visualisieren. Die Vorteile von Entscheidungsbäumen sind, dass sie leicht zu verstehen, zu interpretieren und zu visualisieren sind. Außerdem erfordern sie wenig Aufwand bei der Datenaufbereitung.
Sie haben aber auch einen großen Nachteil. Die Bäume können durch kleinste Abweichungen (Varianz) in den Daten instabil werden. Es ist auch möglich, überkomplexe Bäume zu erstellen, die nicht gut verallgemeinern. Dies wird als Overfitting bezeichnet. Bagging, Boosting und Regularisierung helfen bei der Bekämpfung dieses Problems. Wir werden später in diesem Beitrag auf sie eingehen.
Die Elemente eines jeden Entscheidungsbaums sind:
- Wurzelknoten, der die Hauptfrage stellt. Er hat Pfeile, die von ihm nach unten zeigen, aber keine Pfeile, die auf ihn zeigen. Stellen Sie sich zum Beispiel vor, Sie bauen einen Baum, um zu entscheiden, welche Art von Nudeln Sie zum Abendessen essen sollen.
- Verzweigungen. Ein Teilbereich eines Baumes wird als Zweig oder manchmal auch als Unterbaum bezeichnet.
- Entscheidungsknoten. Dies sind die Unterknoten des Wurzelknotens, die sich auch in weitere Knoten aufteilen können. Ihre Entscheidungsknoten können sein „Carbonara?“ oder „mit Pilzen?“.
- Blätter oder Endknoten. Diese Knoten werden nicht aufgeteilt. Sie stellen endgültige Entscheidungen oder Vorhersagen dar.
Es ist auch wichtig, das Splitting zu erwähnen. Dies ist der Prozess der Aufteilung eines Knotens in Unterknoten. Wenn du zum Beispiel kein Vegetarier bist, ist Carbonara okay. Wenn Sie aber Vegetarier sind, essen Sie Nudeln mit Pilzen. Es gibt auch einen Prozess der Knotenentfernung, der Pruning genannt wird.
Entscheidungsbaumalgorithmen werden als CART (Classification and Regression Trees) bezeichnet. Entscheidungsbäume können mit kategorischen oder numerischen Daten arbeiten.
- Regressionsbäume werden verwendet, wenn die Variablen numerische Werte haben.
- Klassifikationsbäume können angewendet werden, wenn die Daten kategorisch sind (Klassen).
Entscheidungsbäume sind recht intuitiv zu verstehen und zu verwenden. Aus diesem Grund werden Baumdiagramme in vielen Branchen und Disziplinen häufig eingesetzt. GreyAtom bietet einen umfassenden Überblick über verschiedene Arten von Entscheidungsbäumen und ihre praktischen Anwendungen.
SVM (Support Vector Machine)
Support Vector Machines sind eine weitere Gruppe von Algorithmen, die für Klassifizierungs- und manchmal auch für Regressionsaufgaben verwendet werden. SVM eignet sich hervorragend, weil sie mit minimaler Rechenleistung recht genaue Ergebnisse liefert.
Das Ziel der SVM besteht darin, in einem N-dimensionalen Raum (wobei N der Anzahl der Merkmale entspricht) eine Hyperebene zu finden, die die Datenpunkte eindeutig klassifiziert. Die Genauigkeit der Ergebnisse steht in direktem Zusammenhang mit der von uns gewählten Hyperebene. Es sollte eine Ebene gefunden werden, die den größten Abstand zwischen den Datenpunkten beider Klassen aufweist.
Diese Hyperebene wird grafisch als eine Linie dargestellt, die eine Klasse von der anderen trennt. Datenpunkte, die auf verschiedene Seiten der Hyperebene fallen, werden verschiedenen Klassen zugeordnet.
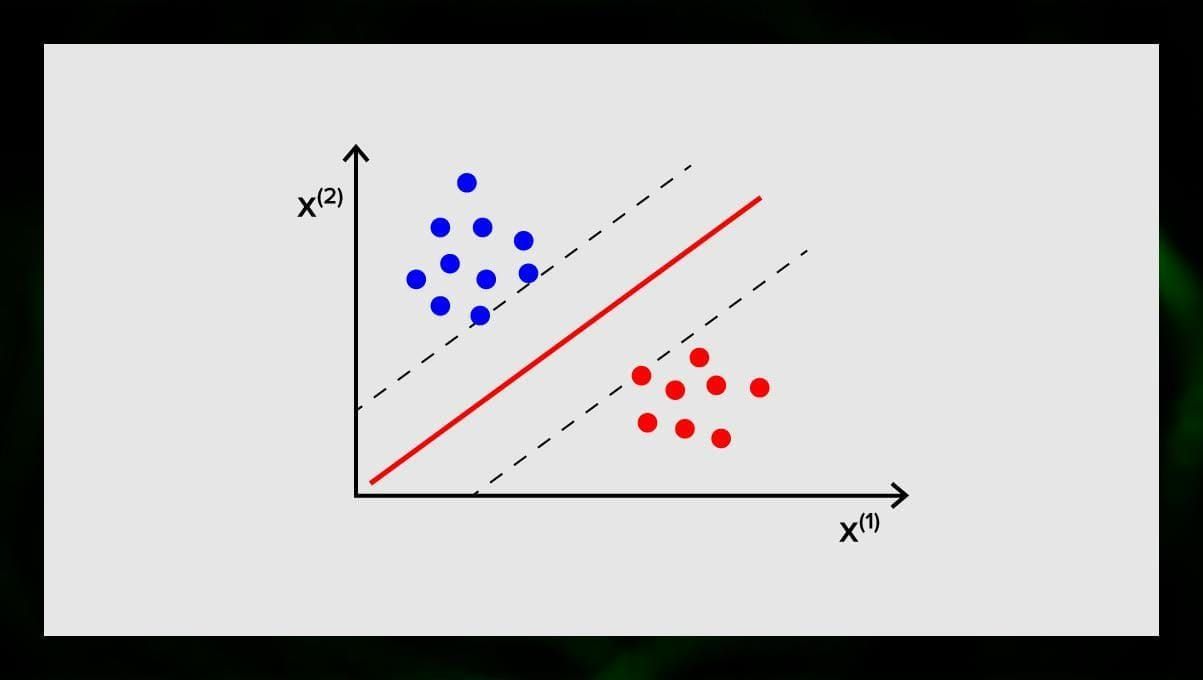
Beachten Sie, dass die Dimension der Hyperebene von der Anzahl der Merkmale abhängt. Wenn die Anzahl der Eingangsmerkmale 2 beträgt, dann ist die Hyperebene nur eine Linie. Wenn die Anzahl der Eingangsmerkmale 3 beträgt, wird die Hyperebene zu einer zweidimensionalen Ebene. Es wird schwierig, ein Modell auf einem Graphen zu zeichnen, wenn die Anzahl der Merkmale 3 übersteigt. In diesem Fall werden Sie also Kernel-Typen verwenden, um es in einen 3-dimensionalen Raum zu transformieren.
Warum nennt man dies eine Support Vector Machine? Stützvektoren sind Datenpunkte, die der Hyperebene am nächsten liegen. Sie haben einen direkten Einfluss auf die Position und die Ausrichtung der Hyperebene und ermöglichen es uns, den Spielraum des Klassifikators zu maximieren. Durch das Löschen der Stützvektoren wird die Position der Hyperebene verändert. Dies sind die Punkte, die uns beim Aufbau unserer SVM helfen.
SVM werden heute aktiv in der medizinischen Diagnose zum Auffinden von Anomalien, in Systemen zur Kontrolle der Luftqualität, für Finanzanalysen und Vorhersagen an der Börse sowie zur Fehlerkontrolle von Maschinen in der Industrie eingesetzt.
Regressionsalgorithmen
Regressionsalgorithmen sind in der Analytik nützlich, z.B. wenn man versucht, die Kosten für Wertpapiere oder den Umsatz für ein bestimmtes Produkt zu einem bestimmten Zeitpunkt vorherzusagen.
Lineare Regression
Die lineare Regression versucht, die Beziehung zwischen Variablen zu modellieren, indem eine lineare Gleichung an die beobachteten Daten angepasst wird.
Es gibt erklärende und abhängige Variablen. Abhängige Variablen sind Dinge, die wir erklären oder vorhersagen wollen. Die erklärenden, wie es aus dem Namen folgt, erklären etwas. Wenn Sie eine lineare Regression erstellen wollen, nehmen Sie an, dass eine lineare Beziehung zwischen den abhängigen und unabhängigen Variablen besteht. Zum Beispiel gibt es eine Korrelation zwischen den Quadratmetern eines Hauses und seinem Preis oder der Dichte der Bevölkerung und der Dönerläden in der Gegend.
Wenn Sie diese Annahme getroffen haben, müssen Sie als Nächstes die spezifische lineare Beziehung herausfinden. Sie müssen eine lineare Regressionsgleichung für einen Satz von Daten finden. Der letzte Schritt ist die Berechnung des Residuums.
Anmerkung: Wenn die Regression eine gerade Linie zeichnet, nennt man sie linear, wenn sie eine Kurve ist – polynomial.
Unüberwachte Lernalgorithmen

Nun lassen Sie uns über Algorithmen sprechen, die in der Lage sind, versteckte Muster in unmarkierten Daten zu finden.
Clustering
Clustering bedeutet, dass wir die Eingaben entsprechend dem Grad ihrer Ähnlichkeit in Gruppen einteilen. Clustering ist in der Regel einer der Schritte zum Aufbau eines komplexeren Algorithmus. Es ist einfacher, jede Gruppe einzeln zu untersuchen und ein Modell auf der Grundlage ihrer Merkmale zu erstellen, als alles auf einmal zu bearbeiten. Die gleiche Technik wird ständig in Marketing und Vertrieb eingesetzt, um alle potenziellen Kunden in Gruppen einzuteilen.
Sehr verbreitete Clustering-Algorithmen sind k-means clustering und k-nearest neighbor.
K-means clustering
K-means clustering unterteilt die Menge der Elemente des Vektorraums in eine vordefinierte Anzahl von Clustern k. Eine falsche Anzahl von Clustern macht jedoch den gesamten Prozess ungültig, daher ist es wichtig, ihn mit einer unterschiedlichen Anzahl von Clustern zu testen. Der Grundgedanke des k-means-Algorithmus besteht darin, dass die Daten nach dem Zufallsprinzip in Cluster eingeteilt werden und anschließend das Zentrum jedes Clusters, das im vorherigen Schritt ermittelt wurde, iterativ neu berechnet wird. Dann werden die Vektoren erneut in Cluster unterteilt. Der Algorithmus stoppt, wenn sich die Cluster nach einer Iteration nicht mehr verändern.
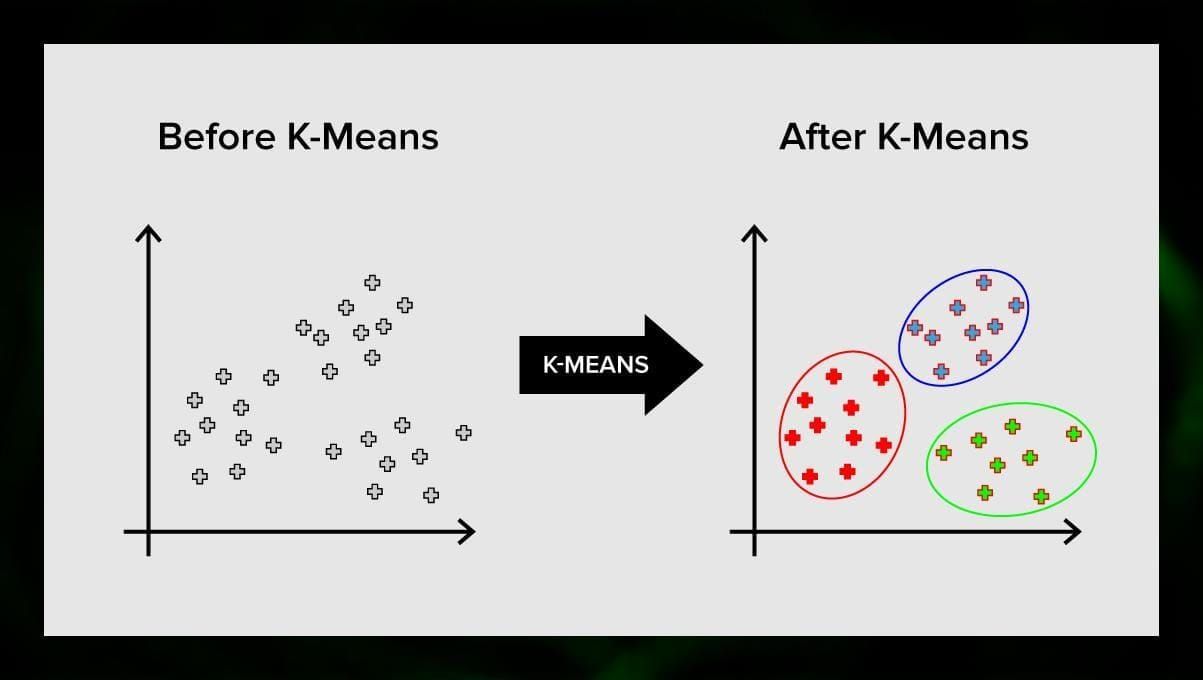
Diese Methode kann zur Lösung von Problemen eingesetzt werden, bei denen die Cluster eindeutig sind oder leicht voneinander getrennt werden können, ohne dass sich die Daten überschneiden.
K-nearest neighbor
kNN steht für k-nearest neighbor. Dies ist einer der einfachsten Klassifizierungsalgorithmen, der manchmal bei Regressionsaufgaben verwendet wird.
Um den Klassifikator zu trainieren, benötigt man einen Datensatz mit vordefinierten Klassen. Die Markierung erfolgt manuell unter Einbeziehung von Spezialisten auf dem untersuchten Gebiet. Mit diesem Algorithmus ist es möglich, mit mehreren Klassen zu arbeiten oder die Situationen zu klären, in denen Eingaben zu mehr als einer Klasse gehören.
Das Verfahren basiert auf der Annahme, dass ähnliche Bezeichnungen nahe beieinander liegenden Objekten im Attributvektorraum entsprechen.
Moderne Softwaresysteme verwenden kNN für die visuelle Mustererkennung, zum Beispiel zum Scannen und Erkennen von versteckten Paketen am Ende des Einkaufswagens an der Kasse (zum Beispiel AmazonGo). kNN-Algorithmen analysieren alle Daten und erkennen ungewöhnliche Muster, die auf verdächtige Aktivitäten hindeuten.
Dimensionalitätsreduktion
Die Hauptkomponentenanalyse (PCA) ist eine wichtige Technik, die man verstehen muss, um ML-bezogene Probleme effektiv zu lösen.
Stellen Sie sich vor, Sie müssen eine Menge Variablen berücksichtigen. Zum Beispiel müssen Sie Städte in drei Gruppen einteilen: gut zum Leben, schlecht zum Leben und so gut wie. Wie viele Variablen müssen Sie dabei berücksichtigen? Wahrscheinlich eine ganze Menge. Verstehen Sie die Beziehungen zwischen ihnen? Nicht wirklich. Wie können Sie also alle gesammelten Variablen nehmen und sich auf einige wenige konzentrieren, die am wichtigsten sind?
In der Fachsprache heißt das, dass Sie „die Dimension Ihres Merkmalsraums reduzieren“ wollen. Durch die Verringerung der Dimension des Merkmalsraums können Sie weniger Beziehungen zwischen den Variablen berücksichtigen, und es ist weniger wahrscheinlich, dass Ihr Modell übermäßig angepasst wird.
Es gibt viele Möglichkeiten, die Dimensionalität zu verringern, aber die meisten dieser Techniken fallen in eine von zwei Klassen:
- Merkmalseliminierung;
- Merkmalsextraktion.
Merkmalseliminierung bedeutet, dass Sie die Anzahl der Merkmale verringern, indem Sie einige von ihnen eliminieren. Die Vorteile dieser Methode sind, dass sie einfach ist und die Interpretierbarkeit der Variablen beibehält. Der Nachteil ist jedoch, dass die Variablen, die Sie weggelassen haben, keinerlei Informationen liefern.
Dieses Problem wird durch die Merkmalsextraktion vermieden. Das Ziel bei der Anwendung dieser Methode ist es, eine Reihe von Merkmalen aus dem gegebenen Datensatz zu extrahieren. Die Merkmalsextraktion zielt darauf ab, die Anzahl der Merkmale in einem Datensatz zu reduzieren, indem neue Merkmale auf der Grundlage der vorhandenen Merkmale erstellt werden (und die ursprünglichen Merkmale dann verworfen werden). Der neue reduzierte Satz von Merkmalen muss so erstellt werden, dass er in der Lage ist, die meisten der im ursprünglichen Satz von Merkmalen enthaltenen Informationen zusammenzufassen.
Die Hauptkomponentenanalyse ist ein Algorithmus für die Merkmalsextraktion. Sie kombiniert die Eingabevariablen auf eine bestimmte Weise, und dann ist es möglich, die „unwichtigsten“ Variablen wegzulassen, während die wertvollsten Teile aller Variablen erhalten bleiben.
Eine der möglichen Anwendungen der PCA ist, wenn die Bilder im Datensatz zu groß sind. Eine reduzierte Merkmalsdarstellung hilft, Aufgaben wie Bildabgleich und -abfrage schnell zu bewältigen.
Assoziationsregel-Lernen
Apriori ist einer der beliebtesten Algorithmen zur Suche nach Assoziationsregeln. Er ist in der Lage, große Datenmengen in relativ kurzer Zeit zu verarbeiten.
Das Problem ist, dass die Datenbanken vieler Projekte heute sehr groß sind und Gigabytes und Terabytes erreichen. Und sie werden weiter wachsen. Daher braucht man einen effektiven, skalierbaren Algorithmus, um in kurzer Zeit assoziative Regeln zu finden. Apriori ist einer dieser Algorithmen.
Um den Algorithmus anwenden zu können, muss man die Daten vorbereiten, indem man sie alle in die binäre Form konvertiert und ihre Datenstruktur ändert.
Gemeinsam wendet man diesen Algorithmus auf eine Datenbank an, die eine große Anzahl von Transaktionen enthält, zum Beispiel auf eine Datenbank, die Informationen über alle Artikel enthält, die Kunden in einem Supermarkt gekauft haben.
Verstärkungslernen

Verstärkendes Lernen ist eine der Methoden des maschinellen Lernens, die dazu dient, der Maschine beizubringen, wie sie mit einer bestimmten Umgebung interagieren soll. In diesem Fall dient die Umgebung (z. B. in einem Videospiel) als Lehrmeister. Sie gibt Rückmeldung zu den vom Computer getroffenen Entscheidungen. Auf der Grundlage dieser Belohnung lernt die Maschine, wie sie sich am besten verhält. Das erinnert an die Art und Weise, wie Kinder lernen, eine heiße Bratpfanne nicht zu berühren – durch Ausprobieren und Schmerzempfinden.
Dieser Prozess umfasst folgende einfache Schritte:
- Der Computer beobachtet die Umgebung;
- wählt eine Strategie;
- handelt entsprechend dieser Strategie;
- erhält entweder eine Belohnung oder eine Bestrafung;
- lernt aus dieser Erfahrung und verfeinert die Strategie;
- wiederholt, bis die optimale Strategie gefunden ist.
Q-Learning
Es gibt eine Reihe von Algorithmen, die für Reinforcement Learning verwendet werden können. Einer der gebräuchlichsten ist Q-Learning.
Q-Learning ist ein modellfreier Reinforcement-Learning-Algorithmus. Q-Learning basiert auf der von der Umwelt erhaltenen Vergütung. Der Agent bildet eine Nutzenfunktion Q, die ihm anschließend die Möglichkeit gibt, eine Verhaltensstrategie zu wählen und dabei die Erfahrungen aus früheren Interaktionen mit der Umwelt zu berücksichtigen.
Einer der Vorteile des Q-Lernens ist, dass es in der Lage ist, den erwarteten Nutzen der verfügbaren Aktionen zu vergleichen, ohne Umweltmodelle zu bilden.
Ensemble-Lernen

Ensemble-Lernen ist die Methode zur Lösung eines Problems durch die Erstellung mehrerer ML-Modelle und deren Kombination. Ensemble-Lernen wird in erster Linie eingesetzt, um die Leistung von Klassifizierungs-, Vorhersage- und Funktionsannäherungsmodellen zu verbessern. Andere Anwendungen des Ensemble-Lernens umfassen die Überprüfung der vom Modell getroffenen Entscheidungen, die Auswahl optimaler Merkmale für die Erstellung von Modellen, inkrementelles Lernen und nicht-stationäres Lernen.
Im Folgenden werden einige der gebräuchlichsten Ensemble-Lernalgorithmen vorgestellt.
Bagging
Bagging steht für Bootstrap-Aggregation. Es ist einer der frühesten Ensemble-Algorithmen mit einer erstaunlich guten Leistung. Um die Vielfalt der Klassifikatoren zu gewährleisten, verwendet man Bootstrap-Replikate der Trainingsdaten. Das bedeutet, dass aus dem Trainingsdatensatz nach dem Zufallsprinzip – mit Ersetzung – verschiedene Teilmengen gezogen werden. Jeder Trainingsdatensatz wird verwendet, um einen anderen Klassifikator desselben Typs zu trainieren. Anschließend können die einzelnen Klassifikatoren kombiniert werden. Dazu müssen Sie eine einfache Mehrheitsabstimmung über ihre Entscheidungen durchführen. Die Klasse, die von der Mehrheit der Klassifizierer zugewiesen wurde, ist die Ensemble-Entscheidung.
Boosting
Diese Gruppe von Ensemble-Algorithmen ist dem Bagging ähnlich. Auch beim Boosting wird eine Vielzahl von Klassifikatoren verwendet, um die Daten erneut zu samplen, und dann wird die optimale Version durch Mehrheitsabstimmung ausgewählt. Beim Boosting werden iterativ schwache Klassifikatoren trainiert, um sie zu einem starken Klassifikator zusammenzufügen. Wenn die Klassifikatoren hinzugefügt werden, werden ihnen in der Regel einige Gewichte zugewiesen, die die Genauigkeit ihrer Vorhersagen beschreiben. Nachdem ein schwacher Klassifikator zum Ensemble hinzugefügt wurde, werden die Gewichte neu berechnet. Falsch klassifizierte Eingaben erhalten mehr Gewicht, und richtig klassifizierte Instanzen verlieren an Gewicht. Auf diese Weise konzentriert sich das System stärker auf Beispiele, bei denen eine falsche Klassifizierung vorgenommen wurde.
Random forest
Random forests oder random decision forests sind eine Ensemble-Lernmethode für Klassifizierung, Regression und andere Aufgaben. Um einen Random Forest zu erstellen, müssen Sie eine Vielzahl von Entscheidungsbäumen auf Zufallsstichproben von Trainingsdaten trainieren. Die Ausgabe des Random Forest ist das häufigste Ergebnis der einzelnen Bäume. Zufällige Entscheidungswälder bekämpfen erfolgreich die Überanpassung aufgrund der _zufälligen _Natur des Algorithmus.
Stacking
Stacking ist eine Ensemble-Lerntechnik, die mehrere Klassifizierungs- oder Regressionsmodelle über einen Meta-Klassifikator oder einen Meta-Regressor kombiniert. Die Basismodelle werden auf der Grundlage eines vollständigen Trainingssatzes trainiert, dann wird das Metamodell auf den Ausgaben der Basismodelle als Merkmale trainiert.
Neuronale Netze
Ein neuronales Netz ist eine Folge von Neuronen, die durch Synapsen verbunden sind, was an die Struktur des menschlichen Gehirns erinnert. Das menschliche Gehirn ist jedoch noch komplexer.
Das Tolle an neuronalen Netzen ist, dass sie für praktisch jede Aufgabe eingesetzt werden können, von der Spam-Filterung bis zum Computer-Vision. Normalerweise werden sie jedoch für die maschinelle Übersetzung, die Erkennung von Anomalien und das Risikomanagement, die Spracherkennung und Spracherzeugung, die Gesichtserkennung und vieles mehr eingesetzt.
Ein neuronales Netz besteht aus Neuronen oder Knotenpunkten. Jedes dieser Neuronen empfängt Daten, verarbeitet sie und gibt sie dann an ein anderes Neuron weiter.
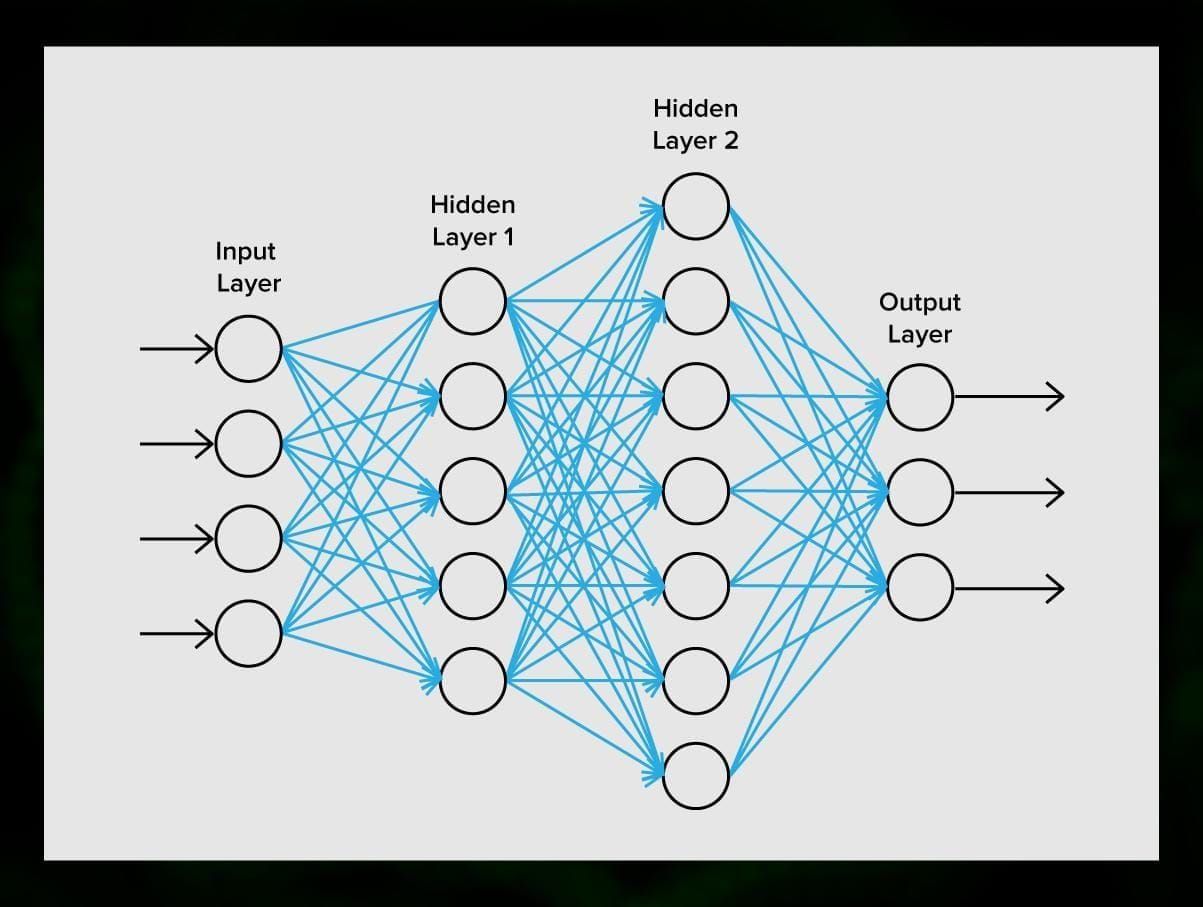
Jedes Neuron verarbeitet die Signale auf die gleiche Weise. Aber wie kommt man dann zu einem anderen Ergebnis? Verantwortlich dafür sind die Synapsen, die die Neuronen miteinander verbinden. Jedes Neuron kann viele Synapsen haben, die das Signal abschwächen oder verstärken. Außerdem können die Neuronen ihre Eigenschaften im Laufe der Zeit verändern. Durch die Wahl der richtigen Synapsenparameter können wir die richtigen Ergebnisse der Umwandlung der Eingangsinformationen am Ausgang erzielen.
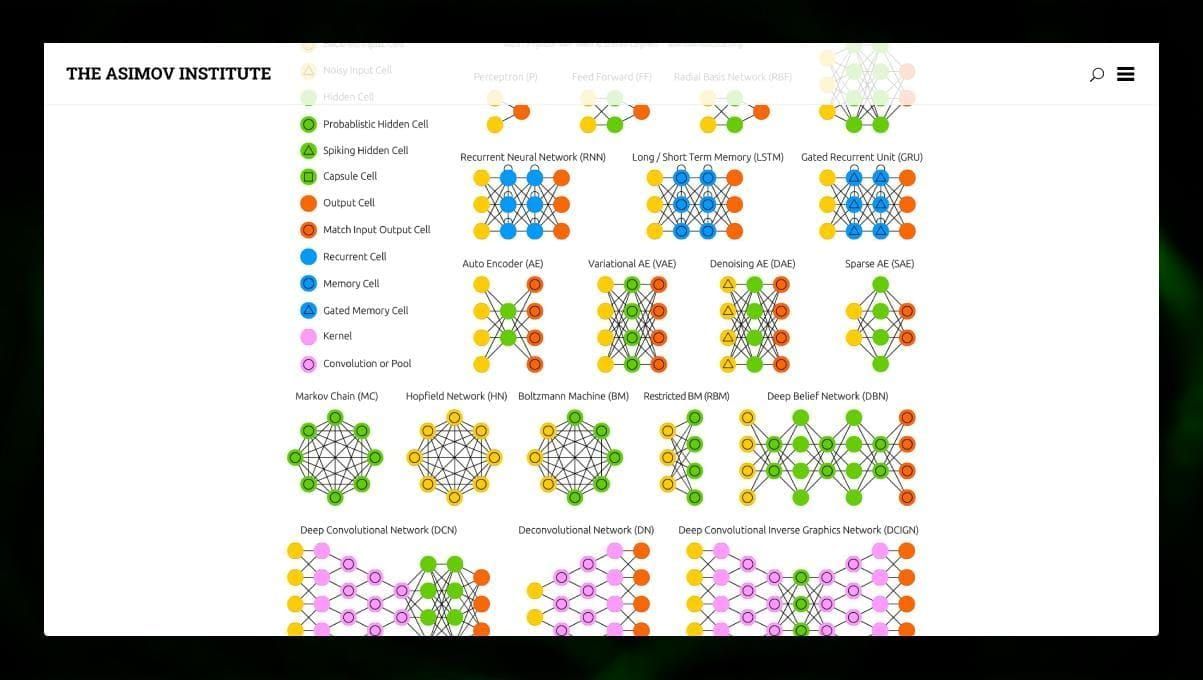
Es gibt viele verschiedene Arten von NN:
- Feedforward neuronale Netze (FF oder FFNN) und Perceptrons § sind sehr einfach, es gibt keine Schleifen oder Zyklen im Netz. In der Praxis werden solche Netze selten verwendet, aber sie werden oft mit anderen Typen kombiniert, um neue Netze zu erhalten.
- Ein Hopfield-Netz (HN) ist ein vollständig verbundenes neuronales Netz mit einer symmetrischen Matrix von Verbindungen. Ein solches Netz wird oft als assoziatives Speichernetz bezeichnet. Wie eine Person, die eine Hälfte des Tisches sieht, sich die zweite Hälfte vorstellen kann, so stellt dieses Netz, wenn es eine verrauschte Tabelle erhält, die vollständige Tabelle wieder her.
- Neuronale Netze mit Faltung (CNN) und tiefe neuronale Netze mit Faltung (DCNN) unterscheiden sich stark von anderen Arten von Netzen. Sie werden in der Regel für Bildverarbeitungs-, Audio- oder videobezogene Aufgaben verwendet. Eine typische Anwendung von CNN ist die Klassifizierung von Bildern.
Viele verschiedene Arten von neuronalen Netzen sind interessant zu beobachten. Das ist im NN-Zoo möglich.
Abschluss
Dieser Beitrag gibt einen breiten Überblick über verschiedene ML-Algorithmen, aber es gibt noch viel zu sagen. Bleiben Sie auf Twitter, Facebook und Medium dran, um weitere Leitfäden und Beiträge über die spannenden Möglichkeiten des maschinellen Lernens zu erhalten.
Schreibe einen Kommentar