Ein Einblick in Ihre Java-Anwendung ist entscheidend, um zu verstehen, wie sie jetzt funktioniert, wie sie in der Vergangenheit funktioniert hat und wie sie in der Zukunft funktionieren könnte. In den meisten Fällen ist die Analyse von Protokollen der schnellste Weg, um herauszufinden, was schief gelaufen ist. Daher ist die Protokollierung in Java von entscheidender Bedeutung für die Sicherstellung der Leistung und des Zustands Ihrer Anwendung sowie für die Minimierung und Reduzierung von Ausfallzeiten. Eine zentralisierte Protokollierungs- und Überwachungslösung trägt dazu bei, die Mean Time To Repair zu verkürzen, indem sie die Effektivität Ihres Ops- oder DevOps-Teams verbessert.
Wenn Sie sich an bewährte Verfahren halten, können Sie Ihre Protokolle besser nutzen und ihre Verwendung vereinfachen. Sie werden in der Lage sein, die Ursache von Fehlern und schlechter Leistung leichter zu ermitteln und Probleme zu lösen, bevor sie sich auf die Endbenutzer auswirken. Deshalb möchte ich Ihnen heute einige der besten Praktiken vorstellen, auf die Sie bei der Arbeit mit Java-Anwendungen schwören sollten. Legen wir los.
- Verwenden Sie eine Standardprotokollierungsbibliothek
- Wählen Sie Ihre Appenders mit Bedacht aus
- Verwenden Sie aussagekräftige Nachrichten
- Protokollierung von Java-Stack-Traces
- Protokollierung von Java-Ausnahmen
- Geeignete Protokollierungsebene verwenden
- Protokollierung in JSON
- Konsistente Log-Struktur
- Add Context to Your Logs
- Java-Protokollierung in Containern
- Don’t Log Too Much or Too Little
- Behalten Sie das Publikum im Auge
- Vermeiden Sie die Protokollierung sensibler Informationen
- Verwenden Sie eine Log-Management-Lösung zur zentralen & Überwachung von Java-Logs
- Fazit
- Aktien
Verwenden Sie eine Standardprotokollierungsbibliothek
Die Protokollierung in Java kann auf verschiedene Weise erfolgen. Sie können eine spezielle Protokollierungsbibliothek, eine gemeinsame API oder sogar nur Protokolle in eine Datei oder direkt in ein spezielles Protokollierungssystem schreiben. Bei der Auswahl der Protokollierungsbibliothek für Ihr System sollten Sie jedoch vorausschauend denken. Zu berücksichtigen und zu bewerten sind Leistung, Flexibilität, Appenders für neue Lösungen zur Zentralisierung von Protokollen und so weiter. Wenn Sie sich direkt an ein einziges Framework binden, kann die Umstellung auf eine neuere Bibliothek einen erheblichen Arbeits- und Zeitaufwand bedeuten. Behalten Sie das im Hinterkopf und entscheiden Sie sich für die API, die Ihnen die Flexibilität bietet, die Protokollierungsbibliotheken in Zukunft zu wechseln. Genau wie bei der Umstellung von Log4j auf Logback und auf Log4j 2 müssen Sie bei der Verwendung der SLF4J-API nur die Abhängigkeit ändern, nicht den Code.
Wenn Sie neu im Bereich der Java-Protokollierungsbibliotheken sind, sehen Sie sich unsere Anleitungen für Anfänger an:
- Log4j-Tutorial
- Logback-Tutorial
- Log4j2-Tutorial
- SLF4J-Tutorial
Wählen Sie Ihre Appenders mit Bedacht aus
Appenders definieren, wohin Ihre Protokollereignisse geliefert werden. Die gebräuchlichsten Appender sind der Konsolen- und der Datei-Appender. Obwohl sie nützlich und weithin bekannt sind, erfüllen sie möglicherweise nicht Ihre Anforderungen. Vielleicht möchten Sie Ihre Protokolle asynchron schreiben oder Sie möchten Ihre Protokolle über das Netzwerk versenden, indem Sie Appender wie den für Syslog verwenden, z.B. so:
<Appenders> <Console name="Console" target="SYSTEM_OUT"> <PatternLayout pattern="%d %level %c - %m%n"/> </Console> <Syslog name="Syslog" host="logsene-syslog-receiver.sematext.com" port="514" protocol="TCP" format="RFC5424" appName="11111111-2222-3333-4444-555555555555" facility="LOCAL0" mdcId="mdc" newLine="true"/></Appenders>
Denken Sie jedoch daran, dass die Verwendung von Appendern wie dem oben gezeigten Ihre Protokollierungspipeline anfällig für Netzwerkfehler und Kommunikationsunterbrechungen macht. Dies kann dazu führen, dass Protokolle nicht an ihren Bestimmungsort übermittelt werden, was möglicherweise nicht akzeptabel ist. Sie möchten auch vermeiden, dass die Protokollierung Ihr System beeinträchtigt, wenn der Appender auf eine blockierende Weise konzipiert ist. Weitere Informationen finden Sie in unserem Blogbeitrag Logging-Bibliotheken vs. Log-Shipper.
Verwenden Sie aussagekräftige Nachrichten
Einer der wichtigsten Punkte bei der Erstellung von Protokollen, aber auch einer der nicht ganz einfachsten, ist die Verwendung aussagekräftiger Nachrichten. Ihre Log-Ereignisse sollten Meldungen enthalten, die für die jeweilige Situation einzigartig sind, sie klar beschreiben und die Person, die sie liest, informieren. Stellen Sie sich vor, in Ihrer Anwendung ist ein Kommunikationsfehler aufgetreten. Sie könnten es so machen:
LOGGER.warn("Communication error");
Aber Sie könnten auch eine Meldung wie diese erstellen:
LOGGER.warn("Error while sending documents to events Elasticsearch server, response code %d, response message %s. The message sending will be retried.", responseCode, responseMessage);
Sie können leicht erkennen, dass die erste Meldung die Person, die die Protokolle betrachtet, über einige Kommunikationsprobleme informiert. Diese Person wird wahrscheinlich den Kontext, den Namen des Loggers und die Zeilennummer, in der die Warnung auftrat, erfahren, aber das ist auch schon alles. Um mehr Kontext zu erhalten, müsste die Person sich den Code ansehen, wissen, auf welche Version des Codes sich der Fehler bezieht, und so weiter. Das macht keinen Spaß und ist oft nicht einfach, und sicherlich nichts, was man tun möchte, wenn man versucht, ein Produktionsproblem so schnell wie möglich zu beheben.
Die zweite Meldung ist besser. Sie liefert genaue Informationen darüber, welche Art von Kommunikationsfehler aufgetreten ist, was die Anwendung zu diesem Zeitpunkt getan hat, welchen Fehlercode sie erhalten hat und wie die Antwort des Remote-Servers lautete. Schließlich informiert sie auch darüber, dass das Senden der Nachricht erneut versucht wird. Die Arbeit mit solchen Nachrichten ist auf jeden Fall einfacher und angenehmer.
Schließlich sollten Sie sich Gedanken über den Umfang und die Ausführlichkeit der Nachricht machen. Loggen Sie keine zu ausführlichen Informationen. Diese Daten müssen irgendwo gespeichert werden, um nützlich zu sein. Eine sehr lange Nachricht ist kein Problem, aber wenn sich diese Zeile in einer Minute hunderte Male wiederholt und Sie viele ausführliche Protokolle haben, kann eine längere Aufbewahrung solcher Daten problematisch sein und kostet letztendlich auch mehr.
Protokollierung von Java-Stack-Traces
Einer der sehr wichtigen Teile der Java-Protokollierung sind die Java-Stack-Traces. Schauen Sie sich den folgenden Code an:
package com.sematext.blog.logging;import org.apache.logging.log4j.LogManager;import org.apache.logging.log4j.Logger;import java.io.IOException;public class Log4JExceptionNoThrowable { private static final Logger LOGGER = LogManager.getLogger(Log4JExceptionNoThrowable.class); public static void main(String args) { try { throw new IOException("This is an I/O error"); } catch (IOException ioe) { LOGGER.error("Error while executing main thread"); } }}
Der obige Code führt dazu, dass eine Ausnahme ausgelöst wird, und eine Protokollmeldung, die mit unserer Standardkonfiguration auf der Konsole ausgegeben wird, sieht wie folgt aus:
11:42:18.952 ERROR - Error while executing main thread
Wie Sie sehen können, gibt es nicht viele Informationen. Wir wissen nur, dass das Problem aufgetreten ist, aber wir wissen nicht, wo es aufgetreten ist, oder was das Problem war, usw. Nicht sehr informativ.
Schauen Sie sich nun denselben Code mit einer leicht geänderten Protokollierungsanweisung an:
package com.sematext.blog.logging;import org.apache.logging.log4j.LogManager;import org.apache.logging.log4j.Logger;import java.io.IOException;public class Log4JException { private static final Logger LOGGER = LogManager.getLogger(Log4JException.class); public static void main(String args) { try { throw new IOException("This is an I/O error"); } catch (IOException ioe) { LOGGER.error("Error while executing main thread", ioe); } }}
Wie Sie sehen, haben wir dieses Mal das Ausnahmeobjekt selbst in unsere Protokollmeldung aufgenommen:
LOGGER.error("Error while executing main thread", ioe);
Das würde mit unserer Standardkonfiguration zu folgendem Fehlerprotokoll in der Konsole führen:
11:30:17.527 ERROR - Error while executing main threadjava.io.IOException: This is an I/O error at com.sematext.blog.logging.Log4JException.main(Log4JException.java:13)
Es enthält relevante Informationen – d. h.d. h. den Namen der Klasse, die Methode, in der das Problem aufgetreten ist, und schließlich die Zeilennummer, in der das Problem aufgetreten ist. In realen Situationen werden die Stack Traces natürlich länger sein, aber Sie sollten sie einbeziehen, um genügend Informationen für ein korrektes Debugging zu erhalten.
Um mehr darüber zu erfahren, wie man Java-Stack Traces mit Logstash handhabt, lesen Sie bitte den Abschnitt Handhabung von mehrzeiligen Stack Traces mit Logstash oder schauen Sie sich Logagent an, das diese Aufgabe von Haus aus übernehmen kann.
Protokollierung von Java-Ausnahmen
Beim Umgang mit Java-Ausnahmen und Stack Traces sollten Sie nicht nur an den gesamten Stack Trace denken, an die Zeilen, in denen das Problem auftrat, und so weiter. Man sollte auch darüber nachdenken, wie man nicht mit Ausnahmen umgeht.
Vermeiden Sie es, Ausnahmen stillschweigend zu ignorieren. Sie wollen ja nicht etwas Wichtiges ignorieren. Tun Sie zum Beispiel Folgendes nicht:
try { throw new IOException("This is an I/O error");} catch (IOException ioe) {}
Auch protokollieren Sie nicht einfach eine Ausnahme und werfen sie weiter. Das bedeutet, dass Sie das Problem auf dem Ausführungsstapel nach oben geschoben haben. Vermeiden Sie auch solche Dinge:
try { throw new IOException("This is an I/O error");} catch (IOException ioe) { LOGGER.error("I/O error occurred during request processing", ioe); throw ioe;}
Wenn Sie mehr über Ausnahmen erfahren möchten, lesen Sie unseren Leitfaden über die Behandlung von Java-Ausnahmen, in dem wir alles behandeln, von dem, was sie sind, bis hin zu dem, wie man sie abfängt und behebt.
Geeignete Protokollierungsebene verwenden
Wenn Sie Ihren Anwendungscode schreiben, denken Sie zweimal über eine bestimmte Protokollmeldung nach. Nicht jede Information ist gleich wichtig und nicht jede unerwartete Situation ist ein Fehler oder eine kritische Meldung. Verwenden Sie außerdem die Protokollierungsebenen konsistent – Informationen eines ähnlichen Typs sollten auf einer ähnlichen Schwereebene liegen.
Beide SLF4J-Fassaden und jedes Java-Protokollierungs-Framework, das Sie verwenden werden, bieten Methoden, die verwendet werden können, um eine geeignete Protokollierungsebene bereitzustellen. Zum Beispiel:
LOGGER.error("I/O error occurred during request processing", ioe);
Protokollierung in JSON
Wenn wir planen, zu protokollieren und die Daten manuell in einer Datei oder der Standardausgabe zu betrachten, dann ist die geplante Protokollierung mehr als in Ordnung. Es ist benutzerfreundlicher – wir sind daran gewöhnt. Aber das ist nur für sehr kleine Anwendungen praktikabel, und selbst dann ist es ratsam, etwas zu verwenden, das es Ihnen ermöglicht, die Metrikdaten mit den Protokollen zu korrelieren. Es macht keinen Spaß, solche Operationen in einem Terminalfenster durchzuführen, und manchmal ist es einfach nicht möglich. Wenn Sie Protokolle im System zur Verwaltung und Zentralisierung von Protokollen speichern möchten, sollten Sie in JSON protokollieren. Denn das Parsen ist nicht umsonst – es bedeutet in der Regel die Verwendung regulärer Ausdrücke. Natürlich können Sie diesen Preis im Log-Shipper zahlen, aber warum sollten Sie das tun, wenn Sie einfach in JSON protokollieren können. Logging in JSON bedeutet auch eine einfache Handhabung von Stack Traces, also ein weiterer Vorteil. Nun, Sie können auch einfach an ein Syslog-kompatibles Ziel protokollieren, aber das ist eine andere Geschichte.
In den meisten Fällen reicht es aus, die richtige Konfiguration einzubinden, um die Protokollierung in JSON in Ihrem Java-Logging-Framework zu aktivieren. Nehmen wir zum Beispiel an, dass wir die folgende Log-Meldung in unserem Code haben:
LOGGER.info("This is a log message that will be logged in JSON!");
Um Log4J 2 so zu konfigurieren, dass es Log-Meldungen in JSON schreibt, würden wir die folgende Konfiguration einfügen:
<?xml version="1.0" encoding="UTF-8"?><Configuration status="WARN"> <Appenders> <Console name="Console" target="SYSTEM_OUT"> <JSONLayout compact="true" eventEol="true"> </JSONLayout> </Console> </Appenders> <Loggers> <Root level="info"> <AppenderRef ref="Console"/> </Root> </Loggers></Configuration>
Das Ergebnis würde wie folgt aussehen:
{"instant":{"epochSecond":1596030628,"nanoOfSecond":695758000},"thread":"main","level":"INFO","loggerName":"com.sematext.blog.logging.Log4J2JSON","message":"This is a log message that will be logged in JSON!","endOfBatch":false,"loggerFqcn":"org.apache.logging.slf4j.Log4jLogger","threadId":1,"threadPriority":5}
Konsistente Log-Struktur
Die Struktur Ihrer Log-Events sollte konsistent sein. Dies gilt nicht nur innerhalb einer einzelnen Anwendung oder eines Satzes von Microservices, sondern sollte auf den gesamten Anwendungsstapel angewendet werden. Mit ähnlich strukturierten Protokollereignissen ist es einfacher, sie zu untersuchen, zu vergleichen, zu korrelieren oder einfach in einem speziellen Datenspeicher zu speichern. Es ist einfacher, die von Ihren Systemen stammenden Daten zu untersuchen, wenn Sie wissen, dass sie gemeinsame Felder wie Schweregrad und Hostname haben, so dass Sie die Daten auf der Grundlage dieser Informationen leicht aufschlüsseln können. Lassen Sie sich von Sematext Common Schema inspirieren, auch wenn Sie kein Sematext-Benutzer sind.
Natürlich ist es nicht immer möglich, die Struktur beizubehalten, da Ihr kompletter Stack aus extern entwickelten Servern, Datenbanken, Suchmaschinen, Warteschlangen usw. besteht, von denen jeder seinen eigenen Satz von Protokollen und Protokollformaten hat. Um jedoch die Vernunft von Ihnen und Ihrem Team zu bewahren, sollten Sie die Anzahl der verschiedenen Protokollmeldungsstrukturen, die Sie kontrollieren können, minimieren.
Eine Möglichkeit, eine gemeinsame Struktur beizubehalten, besteht darin, dass Sie das gleiche Muster für Ihre Protokolle verwenden, zumindest für diejenigen, die das gleiche Protokollierungs-Framework verwenden. Wenn Ihre Anwendungen und Microservices beispielsweise Log4J 2 verwenden, könnten Sie ein Muster wie dieses verwenden:
<PatternLayout> <Pattern>%d %p %c{35}:%L - %m%n</Pattern></PatternLayout>
Durch die Verwendung eines einzigen oder eines sehr begrenzten Satzes von Mustern können Sie sicher sein, dass die Anzahl der Protokollformate klein und überschaubar bleibt.
Add Context to Your Logs
Information context is important and for us developers and DevOps a log message is information. Sehen Sie sich den folgenden Protokolleintrag an:
An error occurred!
Wir wissen, dass irgendwo in der Anwendung ein Fehler aufgetreten ist. Wir wissen nicht, wo er aufgetreten ist, wir wissen nicht, um welche Art von Fehler es sich handelt, wir wissen nur, wann er aufgetreten ist. Betrachten wir nun eine Meldung mit etwas mehr Kontextinformationen:
com.sematext.blog.logging.ParsingErrorExample - A parsing error occurred for user with id 1234!
Derselbe Protokolleintrag, aber mit viel mehr Kontextinformationen. Wir kennen den Thread, in dem der Fehler aufgetreten ist, und wir wissen, in welcher Klasse der Fehler erzeugt wurde. Wir haben auch die Meldung geändert, um den Benutzer, bei dem der Fehler aufgetreten ist, mit einzubeziehen, so dass wir uns bei Bedarf an den Benutzer wenden können. Wir könnten auch zusätzliche Informationen wie Diagnosekontexte einfügen. Überlegen Sie, was Sie brauchen, und fügen Sie es ein.
Um Kontextinformationen einzufügen, müssen Sie nicht viel tun, wenn es um den Code geht, der für die Erzeugung der Protokollmeldung verantwortlich ist. Das PatternLayout in Log4J 2 zum Beispiel gibt Ihnen alles, was Sie brauchen, um die Kontextinformationen einzubinden. Sie können ein sehr einfaches Muster wie dieses verwenden:
<PatternLayout pattern="%d{HH:mm:ss.SSS} %-5level - %msg%n"/>
Das führt zu einer Protokollmeldung, die der folgenden ähnelt:
17:13:08.059 INFO - This is the first INFO level log message!
Sie können aber auch ein Muster verwenden, das weitaus mehr Informationen enthält:
<PatternLayout pattern="%d{HH:mm:ss.SSS} %c %l %-5level - %msg%n"/>
Das führt zu einer Protokollmeldung wie der folgenden:
17:24:01.710 com.sematext.blog.logging.Log4j2 com.sematext.blog.logging.Log4j2.main(Log4j2.java:12) INFO - This is the first INFO level log message!
Java-Protokollierung in Containern
Denken Sie an die Umgebung, in der Ihre Anwendung ausgeführt werden soll. Es gibt einen Unterschied in der Protokollierungskonfiguration, wenn Sie Ihren Java-Code in einer VM oder auf einer Bare-Metal-Maschine ausführen, es ist anders, wenn Sie ihn in einer containerisierten Umgebung ausführen, und natürlich ist es anders, wenn Sie Ihren Java- oder Kotlin-Code auf einem Android-Gerät ausführen.
Um die Protokollierung in einer containerisierten Umgebung einzurichten, müssen Sie den Ansatz wählen, den Sie wählen möchten. Sie können einen der bereitgestellten Logging-Treiber verwenden – wie journald, logagent, Syslog oder JSON-Datei. Dabei ist zu beachten, dass Ihre Anwendung die Protokolldatei nicht in den ephemeren Speicher des Containers, sondern in die Standardausgabe schreiben sollte. Das lässt sich leicht bewerkstelligen, indem Sie Ihr Logging-Framework so konfigurieren, dass das Protokoll auf die Konsole geschrieben wird. Mit Log4J 2 würden Sie zum Beispiel einfach die folgende Appender-Konfiguration verwenden:
<Appenders> <Console name="Console" target="SYSTEM_OUT"> <PatternLayout pattern="%d{HH:mm:ss.SSS} - %m %n"/> </Console></Appenders>
Sie können die Logging-Treiber auch ganz weglassen und die Logs direkt an Ihre zentralisierte Logs-Lösung wie unsere Sematext Cloud senden:
<Appenders> <Console name="Console" target="SYSTEM_OUT"> <PatternLayout pattern="%d %level %c - %m%n"/> </Console> <Syslog name="Syslog" host="logsene-syslog-receiver.sematext.com" port="514" protocol="TCP" format="RFC5424" appName="11111111-2222-3333-4444-555555555555" facility="LOCAL0" mdcId="mdc" newLine="true"/></Appenders>
Don’t Log Too Much or Too Little
Als Entwickler neigen wir dazu, alles für wichtig zu halten – wir neigen dazu, jeden Schritt unseres Algorithmus oder Geschäftscodes als wichtig zu markieren. Andererseits tun wir manchmal das Gegenteil – wir fügen keine Protokollierung hinzu, wo wir sollten, oder wir protokollieren nur FATAL- und ERROR-Protokollstufen. Beide Ansätze sind nicht sehr erfolgreich. Wenn Sie Ihren Code schreiben und die Protokollierung hinzufügen, denken Sie darüber nach, was wichtig ist, um zu sehen, ob die Anwendung richtig funktioniert, und was wichtig ist, um einen falschen Anwendungszustand zu diagnostizieren und zu beheben. Lassen Sie sich davon leiten, um zu entscheiden, was und wo protokolliert werden soll. Denken Sie daran, dass das Hinzufügen von zu vielen Protokollen zu Informationsmüdigkeit führt und dass ein Mangel an Informationen dazu führt, dass Sie nicht in der Lage sind, Fehler zu beheben.
Behalten Sie das Publikum im Auge
In den meisten Fällen werden Sie nicht die einzige Person sein, die sich die Protokolle ansieht. Denken Sie immer daran. Es gibt mehrere Akteure, die sich die Protokolle ansehen können.
Der Entwickler kann sich die Protokolle zur Fehlersuche oder während der Debugging-Sitzungen ansehen. Für diese Personen können die Protokolle detailliert und technisch sein und sehr tiefe Informationen darüber enthalten, wie das System läuft. Eine solche Person hat auch Zugriff auf den Code oder kennt ihn sogar, wovon Sie ausgehen können.
Dann gibt es DevOps. Für sie werden die Log-Ereignisse für die Fehlersuche benötigt und sollten Informationen enthalten, die bei der Diagnose hilfreich sind. Sie können das Wissen über das System, seine Architektur, seine Komponenten und die Konfiguration der Komponenten voraussetzen, aber Sie sollten nicht das Wissen über den Code der Plattform voraussetzen.
Schließlich können Ihre Anwendungsprotokolle von Ihren Benutzern selbst gelesen werden. In einem solchen Fall sollten die Protokolle aussagekräftig genug sein, um das Problem zu beheben, wenn das überhaupt möglich ist, oder um dem Support-Team, das dem Benutzer hilft, genügend Informationen zu liefern. Die Verwendung von Sematext zur Überwachung erfordert zum Beispiel die Installation und den Betrieb eines Überwachungsagenten. Wenn Sie sich hinter einer sehr restriktiven Firewall befinden und der Agent keine Metriken an Sematext übermitteln kann, protokolliert er gezielt Fehler, die sich Sematext-Benutzer auch selbst ansehen können.
Wir könnten noch weiter gehen und noch mehr Akteure identifizieren, die in die Protokolle schauen könnten, aber diese kurze Liste sollte Ihnen einen Einblick geben, woran Sie denken sollten, wenn Sie Ihre Protokollnachrichten schreiben.
Vermeiden Sie die Protokollierung sensibler Informationen
Sensible Informationen sollten nicht in den Protokollen enthalten sein oder sollten maskiert werden. Kennwörter, Kreditkartennummern, Sozialversicherungsnummern, Zugangskennungen usw. – all das kann gefährlich sein, wenn es durchsickert oder von Personen eingesehen wird, die es nicht sehen sollten. Es gibt zwei Dinge, die Sie bedenken sollten.
Überlegen Sie, ob die sensiblen Informationen für die Fehlerbehebung wirklich notwendig sind. Vielleicht reicht es aus, anstelle der Kreditkartennummer die Informationen über die Transaktionskennung und das Datum der Transaktion zu speichern? Vielleicht ist es nicht notwendig, die Sozialversicherungsnummer in den Protokollen aufzubewahren, wenn man die Benutzerkennung problemlos speichern kann. Denken Sie über solche Situationen nach, denken Sie über die Daten nach, die Sie speichern, und schreiben Sie sensible Daten nur, wenn es wirklich notwendig ist.
Der zweite Punkt ist der Versand von Protokollen mit sensiblen Informationen an einen gehosteten Protokolldienst. Es gibt nur sehr wenige Ausnahmen, in denen die folgenden Ratschläge nicht befolgt werden sollten. Wenn in Ihren Protokollen sensible Informationen gespeichert sind und gespeichert werden müssen, maskieren oder entfernen Sie diese, bevor Sie sie an Ihren zentralen Protokollspeicher senden. Die meisten populären Log-Shipper, wie unser eigener Logagent, enthalten Funktionen, die das Entfernen oder Maskieren sensibler Daten ermöglichen.
Schließlich kann die Maskierung sensibler Informationen im Logging-Framework selbst vorgenommen werden. Schauen wir uns an, wie dies durch die Erweiterung von Log4j 2 geschehen kann. Unser Code, der Log-Ereignisse erzeugt, sieht wie folgt aus (das vollständige Beispiel finden Sie auf Sematext Github):
public class Log4J2Masking { private static Logger LOGGER = LoggerFactory.getLogger(Log4J2Masking.class); private static final Marker SENSITIVE_DATA_MARKER = MarkerFactory.getMarker("SENSITIVE_DATA_MARKER"); public static void main(String args) { LOGGER.info("This is a log message without sensitive data"); LOGGER.info(SENSITIVE_DATA_MARKER, "This is a a log message with credit card number 1234-4444-3333-1111 in it"); }}
Wenn Sie das gesamte Beispiel von Github ausführen würden, sähe die Ausgabe wie folgt aus:
21:20:42.099 - This is a log message without sensitive data21:20:42.101 - This is a a log message with credit card number ****-****-****-**** in it
Sie können sehen, dass die Kreditkartennummer maskiert wurde. Dies wurde erreicht, weil wir einen benutzerdefinierten Konverter hinzugefügt haben, der prüft, ob der angegebene Marker im Log-Ereignis übergeben wird und versucht, ein definiertes Muster zu ersetzen. Die Implementierung eines solchen Konverters sieht wie folgt aus:
@Plugin(name = "sample_logging_mask", category = "Converter")@ConverterKeys("sc")public class LoggingConverter extends LogEventPatternConverter { private static Pattern PATTERN = Pattern.compile("\b({4})-({4})-({4})-({4})\b"); public LoggingConverter(String options) { super("sc", "sc"); } public static LoggingConverter newInstance(final String options) { return new LoggingConverter(options); } @Override public void format(LogEvent event, StringBuilder toAppendTo) { String message = event.getMessage().getFormattedMessage(); String maskedMessage = message; if (event.getMarker() != null && "SENSITIVE_DATA_MARKER".compareToIgnoreCase(event.getMarker().getName()) == 0) { Matcher matcher = PATTERN.matcher(message); if (matcher.find()) { maskedMessage = matcher.replaceAll("****-****-****-****"); } } toAppendTo.append(maskedMessage); }}
Sie ist sehr einfach und könnte optimierter geschrieben werden und sollte auch alle möglichen Kreditkartennummernformate verarbeiten können, aber für diesen Zweck ist sie ausreichend.
Bevor ich mich in die Code-Erklärung stürze, möchte ich Ihnen auch die Konfigurationsdatei log4j2.xml für dieses Beispiel zeigen:
<?xml version="1.0" encoding="UTF-8"?><Configuration status="WARN" packages="com.sematext.blog.logging"> <Appenders> <Console name="Console" target="SYSTEM_OUT"> <PatternLayout pattern="%d{HH:mm:ss.SSS} - %sc %n"/> </Console> </Appenders> <Loggers> <Root level="info"> <AppenderRef ref="Console"/> </Root> </Loggers></Configuration>
Wie Sie sehen können, haben wir das Attribut packages in unserer Konfiguration hinzugefügt, um dem Framework mitzuteilen, wo es nach unserem Konverter suchen soll. Dann haben wir das %sc-Muster verwendet, um die Protokollnachricht bereitzustellen. Wir tun das, weil wir das Standardmuster %m nicht überschreiben können. Sobald Log4j2 unser %sc-Muster findet, wird es unseren Konverter verwenden, der die formatierte Nachricht des Log-Ereignisses nimmt und einen einfachen Regex verwendet und die Daten ersetzt, wenn er gefunden wurde. So einfach ist das.
Eine Sache, die hier zu beachten ist, ist, dass wir die Marker-Funktionalität verwenden. Der Regex-Abgleich ist teuer, und wir wollen ihn nicht für jede Protokollmeldung durchführen. Deshalb markieren wir die Log-Ereignisse, die verarbeitet werden sollen, mit dem erstellten Marker, so dass nur die markierten überprüft werden.
Verwenden Sie eine Log-Management-Lösung zur zentralen & Überwachung von Java-Logs
Mit der Komplexität der Anwendungen wird auch das Volumen Ihrer Logs wachsen. Wenn die Datenmenge jedoch wächst, wird die Fehlersuche auf diese Weise schnell schwierig und langsam. In diesem Fall sollten Sie den Einsatz einer Protokollverwaltungslösung in Betracht ziehen, um Ihre Protokolle zu zentralisieren und zu überwachen. Sie können sich entweder für eine Inhouse-Lösung entscheiden, die auf Open-Source-Software wie Elastic Stack basiert, oder eines der auf dem Markt erhältlichen Log-Management-Tools wie Sematext Logs verwenden.
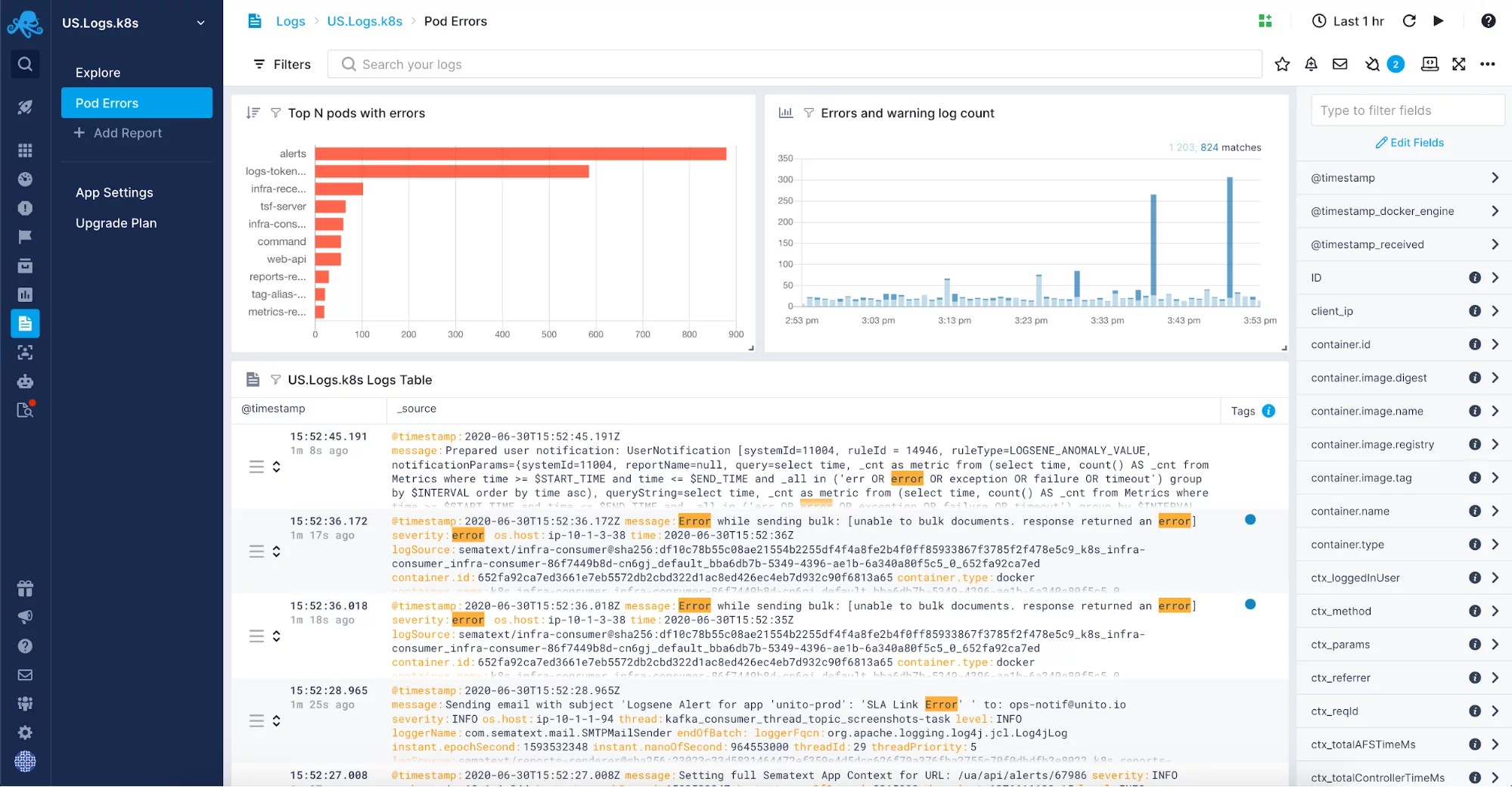
Eine vollständig verwaltete Lösung zur Zentralisierung von Logs gibt Ihnen die Freiheit, nicht noch einen weiteren, in der Regel recht komplexen Teil Ihrer Infrastruktur verwalten zu müssen. Stattdessen können Sie sich auf Ihre Anwendung konzentrieren und müssen nur den Versand der Protokolle einrichten. Möglicherweise möchten Sie Protokolle wie JVM Garbage Collection Logs in Ihre verwaltete Protokolllösung einbeziehen. Nachdem Sie diese für Ihre Anwendungen und Systeme, die auf der JVM arbeiten, aktiviert haben, möchten Sie die Protokolle an einem einzigen Ort für die Protokollkorrelation, die Protokollanalyse und die Optimierung der Garbage Collection in den JVM-Instanzen zusammenfassen. Solche mit Metriken korrelierten Logs sind eine unschätzbare Informationsquelle für die Fehlersuche bei Problemen im Zusammenhang mit der Garbage Collection.
Wenn Sie wissen möchten, wie Sematext Logs im Vergleich zu ähnlichen Lösungen abschneidet, lesen Sie unseren Artikel über die beste Log-Management-Software oder den Blog-Beitrag, in dem wir einige der besten Log-Analyse-Tools vorstellen. Probieren Sie es aus und überzeugen Sie sich selbst!
Fazit
Es ist vielleicht nicht einfach, alle bewährten Verfahren sofort zu implementieren, vor allem bei Anwendungen, die bereits in Betrieb sind und in der Produktion arbeiten. Wenn Sie sich jedoch die Zeit nehmen und die Vorschläge nach und nach umsetzen, werden Sie feststellen, dass die Nützlichkeit Ihrer Protokolle zunimmt. Für weitere Tipps, wie Sie das meiste aus Ihren Logs herausholen können, empfehlen wir Ihnen auch unseren anderen Artikel über Best Practices für die Protokollierung, in dem wir die Besonderheiten erklären, die Sie unabhängig von der Art der Anwendung, mit der Sie arbeiten, beachten sollten. Und denken Sie daran, dass wir bei Sematext Unternehmen bei der Einrichtung ihrer Logging-Systeme helfen, indem wir Logging-Consulting anbieten. Sprechen Sie uns an, wenn Sie Probleme haben, und wir helfen Ihnen gerne weiter.
Schreibe einen Kommentar