Melde dich für unsere täglichen Zusammenfassungen der sich ständig verändernden Suchmaschinenmarketing-Landschaft an.
Hinweis: Mit dem Absenden dieses Formulars erklärst du dich mit den Bedingungen von Third Door Media einverstanden. Wir respektieren Ihre Privatsphäre.

In Internetforen und in inhaltsbezogenen Facebook-Gruppen wird oft darüber diskutiert, wie der Googlebot – den wir hier liebevoll GB nennen – arbeitet, was er sehen kann und was nicht, welche Links er besucht und wie er SEO beeinflusst.
In diesem Artikel werde ich die Ergebnisse meines dreimonatigen Experiments vorstellen.
In den letzten drei Monaten hat mich GB fast täglich besucht wie ein Freund, der auf ein Bier vorbeikommt.
Manchmal war es allein:
: 66.249.76.136 /page1.html Mozilla/5.0 (kompatibel; Googlebot/2.1; +http://www.google.com/bot.html)
: 66.249.76.136 /page5.html Mozilla/5.0 (kompatibel; Googlebot/2.1; +http://www.google.com/bot.html)
: 66.249.76.140 /page3.html Mozilla/5.0 (kompatibel; Googlebot/2.1; +http://www.google.com/bot.html)
: 66.249.64.72 /page2.html Mozilla/5.0 (kompatibel; Googlebot/2.1; +http://www.google.com/bot.html)
: 66.249.64.72 /page6.html Mozilla/5.0 (kompatibel; Googlebot/2.1; +http://www.google.com/bot.html)
Manchmal hat es seine Kumpels mitgebracht:
: 64.233.172.231 /page1.html Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, wie Gecko; Google Search Console) Chrome/41.0.2272.118 Safari/537.36
: 66.249.69.235 /image.jpg Googlebot-Image/1.0
: 66.249.76.156 /page2.html Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, wie Gecko) Chrome/41.0.2272.96 Mobile Safari/537.36 (kompatibel; Googlebot/2.1; +http://www.google.com/bot.html)
Und wir hatten viel Spaß bei verschiedenen Spielen:
Fangen: Ich beobachtete, wie GB es liebt, 301-Weiterleitungen auszuführen, Bilder zu crawlen und von Canonicals auszulaufen.
Verstecken und Suchen: Googlebot versteckte sich im versteckten Inhalt (den er, wie seine Eltern behaupten, nicht toleriert und vermeidet)
Überleben: Ich bereitete Fallen vor und wartete darauf, dass er sie aufstellt.
Hindernisse: Ich habe Hindernisse mit verschiedenen Schwierigkeitsgraden aufgestellt, um zu sehen, wie mein kleiner Freund mit ihnen zurechtkommen würde.
Wie ihr wahrscheinlich sehen könnt, wurde ich nicht enttäuscht. Wir hatten jede Menge Spaß und sind gute Freunde geworden. Ich glaube, unsere Freundschaft hat eine glänzende Zukunft.
Aber kommen wir zum Punkt!
Ich habe eine Website mit leistungsbezogenen Inhalten über ein interstellares Reisebüro erstellt, das Flüge zu noch unentdeckten Planeten in unserer Galaxie und darüber hinaus anbietet.
Der Inhalt schien viele Vorzüge zu haben, obwohl er in Wirklichkeit eine Menge Unsinn war.
Die Struktur der experimentellen Website sah folgendermaßen aus:
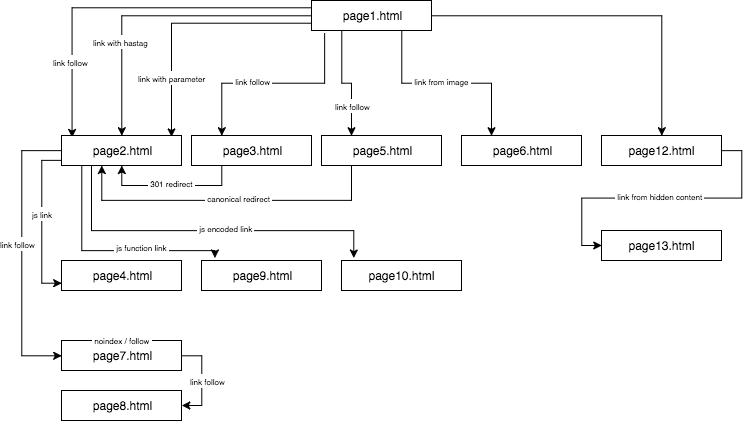
Ich stellte einzigartige Inhalte bereit und sorgte dafür, dass jeder Anker/Titel/Alt sowie andere Koeffizienten global einzigartig waren (gefälschte Wörter). Um es für den Leser einfacher zu machen, werde ich in der Beschreibung keine Namen wie anchor cutroicano matestito verwenden, sondern sie als anchor1 usw. bezeichnen.
Ich schlage vor, dass Sie die obige Karte in einem separaten Fenster geöffnet lassen, während Sie diesen Artikel lesen.
- Teil 1: Der erste Link zählt
- Link zu einer Website mit einem Anker
- Link zu einer Website mit einem Parameter
- Link zu einer Website aus einer Weiterleitung
- Link zu einer Seite mit kanonischem Tag
- Teil 2: Crawl-Budget
- JavaScript-Link mit einem onclick-Ereignis
- Javascript-Link mit interner Funktion
- JavaScript-Link mit Kodierung
- Teil 3: Versteckte Inhalte
- Über den Autor
Teil 1: Der erste Link zählt
Eines der Dinge, die ich in diesem SEO-Experiment testen wollte, war die First Link Counts Rule – ob sie weggelassen werden kann und wie sie die Optimierung beeinflusst.
Die First Link Counts Rule besagt, dass der Google Bot auf einer Seite nur den ersten Link zu einer Unterseite sieht. Wenn Sie zwei Links zur gleichen Unterseite auf einer Seite haben, wird der zweite Link nach dieser Regel ignoriert. Der Google Bot ignoriert den Anker im zweiten und in jedem weiteren Link bei der Berechnung des Rangs der Seite.
Es handelt sich um ein Problem, das von vielen Fachleuten beobachtet wird, das aber vor allem in Online-Shops auftritt, wo Navigationsmenüs die Struktur der Website erheblich verzerren.
In den meisten Shops haben wir ein statisches (im Quelltext der Seite sichtbares) Dropdown-Menü, das beispielsweise vier Links zu Hauptkategorien und 25 versteckte Links zu Unterkategorien enthält. Während des Mappings der Struktur einer Seite sieht GB alle Links (auf jeder Seite mit einem Menü), was dazu führt, dass alle Seiten während des Mappings gleich wichtig sind und ihre Kraft (juice) gleichmäßig verteilt wird, was ungefähr so aussieht:
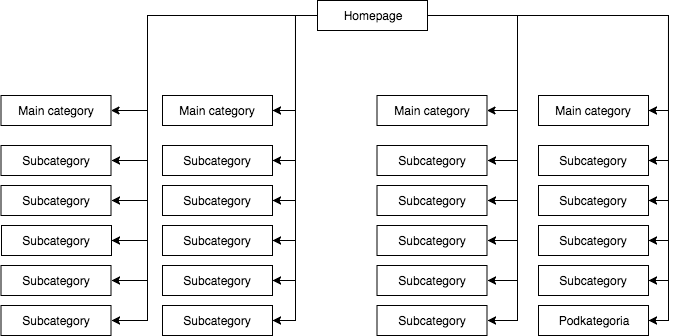
Die häufigste, aber meiner Meinung nach falsche Seitenstruktur.
Das obige Beispiel kann nicht als richtige Struktur bezeichnet werden, da alle Kategorien von allen Seiten verlinkt sind, auf denen es ein Menü gibt. Daher haben sowohl die Startseite als auch alle Kategorien und Unterkategorien die gleiche Anzahl an eingehenden Links, und die Kraft des gesamten Webangebots fließt mit gleicher Stärke durch sie hindurch. Daher wird die Kraft der Startseite (die normalerweise aufgrund der Anzahl der eingehenden Links die Quelle der meisten Kraft ist) auf 24 Kategorien und Unterkategorien aufgeteilt, so dass jede von ihnen nur 4 Prozent der Kraft der Startseite erhält.
Wie die Struktur aussehen sollte:

Wenn Sie die Struktur Ihrer Seite schnell testen und sie wie Google crawlen wollen, ist Screaming Frog ein hilfreiches Tool.
In diesem Beispiel wird die Kraft der Homepage in vier geteilt und jede der Kategorien erhält 25 Prozent der Kraft der Homepage und verteilt einen Teil davon auf die Unterkategorien. Diese Lösung bietet auch eine bessere Möglichkeit der internen Verlinkung. Wenn Sie zum Beispiel einen Artikel im Blog des Shops schreiben und auf eine der Unterkategorien verlinken wollen, wird GB den Link beim Crawlen der Website bemerken. Im ersten Fall wird es dies aufgrund der First Link Counts Rule nicht tun. Wenn der Link zu einer Unterkategorie im Menü der Website war, wird der Link im Artikel ignoriert.
Ich habe dieses SEO-Experiment mit den folgenden Aktionen begonnen:
- Erst habe ich auf der Seite1.html einen Link zu einer Unterseite page2.html als klassischen dofollow-Link mit einem Anker: anchor1.
- Als Nächstes fügte ich in den Text auf derselben Seite leicht veränderte Verweise ein, um zu prüfen, ob GB sie gerne crawlen würde.
Zu diesem Zweck testete ich die folgenden Lösungen:
- Der Homepage des Webdienstes wies ich einen externen dofollow-Link für eine Phrase mit einem URL-Anker zu (so dass eine externe Verlinkung der Homepage und der Unterseiten für bestimmte Phrasen nicht in Frage kam) – dies beschleunigte die Indexierung des Dienstes.
- Ich wartete darauf, dass Seite2.html für eine Phrase des ersten dofollow-Links (Anker1) von Seite1.html zu ranken begann. Dieser gefälschte Ausdruck oder ein anderer, den ich getestet habe, konnte auf der Zielseite nicht gefunden werden. Ich ging davon aus, dass, wenn andere Links funktionieren würden, auch Seite2.html in den Suchergebnissen für andere Phrasen von anderen Links ranken würde. Es dauerte etwa 45 Tage. Und dann konnte ich die erste wichtige Schlussfolgerung ziehen.
Auch eine Website, auf der ein Schlüsselwort weder im Inhalt noch im Meta-Titel vorkommt, aber mit einem recherchierten Anker verlinkt ist, kann in den Suchergebnissen problemlos höher ranken als eine Website, die dieses Wort enthält, aber nicht mit einem Schlüsselwort verlinkt ist.
Darüber hinaus war die Homepage (page1.html), die den recherchierten Begriff enthielt, die stärkste Seite des Webdienstes (verlinkt von 78 Prozent der Unterseiten) und dennoch rangierte sie für den recherchierten Begriff niedriger als die Unterseite (page2.html), die mit der recherchierten Phrase verlinkt war.
Nachfolgend stelle ich vier Arten von Links vor, die ich getestet habe und die alle nach dem ersten dofollow-Link kommen, der zu page2.html führt.
Link zu einer Website mit einem Anker
< a href=“page2.html#testhash“ >Anker2< /a >
Der erste der zusätzlichen Links, die im Code hinter dem dofollow-Link kommen, war ein Link mit einem Anker (einem Hashtag). Ich wollte sehen, ob GB den Link durchgehen und auch page2.html unter der Phrase anchor2 indexieren würde, obwohl der Link zu dieser Seite (page2.html) führt, aber die URL in page2.html#testhash uses anchor2 geändert wird.
Leider wollte sich GB diese Verbindung nicht merken und leitete die Macht nicht auf die Unterseite page2.html für diese Phrase. Infolgedessen findet sich in den Suchergebnissen für den Ausdruck anchor2 am Tag der Abfassung dieses Artikels nur die Unterseite page1.html, auf der das Wort im Anker des Links zu finden ist. Beim Googeln der Phrase testhash rangiert unsere Domain ebenfalls nicht.
Link zu einer Website mit einem Parameter
page2.html?parameter=1
Anfänglich interessierte sich GB für diesen komischen Teil der URL direkt nach dem Abfragezeichen und dem Anker innerhalb des anchor3-Links.
Intrigiert versuchte GB herauszufinden, was ich meinte. Es dachte: „Ist das ein Rätsel?“ Um die Indizierung des doppelten Inhalts unter den anderen URLs zu vermeiden, zeigte die kanonische Seite2.html auf sich selbst. In den Protokollen wurden insgesamt 8 Crawls zu dieser Adresse registriert, aber die Schlussfolgerungen waren eher traurig:
- Nach zwei Wochen nahm die Häufigkeit der Besuche von GB deutlich ab, bis es sich schließlich verabschiedete und diesen Link nie wieder crawlte.
- Seite2.html wurde weder unter der Phrase anchor3 indexiert, noch wurde der Parameter mit der URL parameter1. Laut Search Console existiert dieser Link nicht (er wird nicht zu den eingehenden Links gezählt), aber gleichzeitig wird die Phrase anchor3 als verankerte Phrase aufgeführt.
Link zu einer Website aus einer Weiterleitung
Ich wollte GB zwingen, meine Website mehr zu crawlen, was dazu führte, dass GB alle paar Tage den dofollow-Link mit einem Anker anchor4 auf page1.html eingab, der zu page3.html führte, die mit einem 301-Code zu page2.html weiterleitet. Leider war die Seite2.html nach 45 Tagen, genau wie die Seite mit dem Parameter, noch nicht in den Suchergebnissen für die Phrase anchor4 enthalten, die in dem weitergeleiteten Link auf Seite1.html auftauchte.
In der Google Search Console ist anchor4 jedoch im Abschnitt Anchor Texts sichtbar und indexiert. Dies könnte darauf hindeuten, dass die Umleitung nach einer Weile wie erwartet zu funktionieren beginnt, so dass Seite2.html in den Suchergebnissen für Anker4 rangiert, obwohl es sich um den zweiten Link auf dieselbe Zielseite innerhalb derselben Website handelt.
Link zu einer Seite mit kanonischem Tag
Auf Seite1.html habe ich einen Verweis auf Seite5.html (Follow-Link) mit einem Anker Anker5 gesetzt. Gleichzeitig gab es auf Seite5.html einen eindeutigen Inhalt, und in dessen Kopf befand sich ein kanonisches Tag zu Seite2.html.
< link rel=“canonical“ href=“https://example.com/page2.html“ />
Dieser Test ergab folgende Ergebnisse:
- Der Link für die Phrase anchor5, der auf page5.html verweist und kanonisch auf page2.html wurde nicht auf die Zielseite übertragen (genau wie in den anderen Fällen).
- Seite5.html wurde trotz des kanonischen Tags indexiert.
- Seite5.html rangierte nicht in den Suchergebnissen für Anker5.
- Seite5.html rangierte bei den im Text der Seite verwendeten Phrasen, was darauf hindeutet, dass GB die kanonischen Tags völlig ignorierte.
Ich wage zu behaupten, dass die Verwendung von rel=canonical zur Verhinderung der Indexierung einiger Inhalte (z. B. beim Filtern) einfach nicht funktionieren kann.
Teil 2: Crawl-Budget
Bei der Entwicklung einer SEO-Strategie wollte ich GB dazu bringen, nach meiner Pfeife zu tanzen und nicht umgekehrt. Zu diesem Zweck überprüfte ich die SEO-Prozesse auf der Ebene der Server-Logs (Zugriffslogs und Fehlerlogs), was mir einen großen Vorteil verschaffte. Dadurch kannte ich jede Bewegung von GB und wusste, wie es auf die Änderungen reagierte, die ich im Rahmen der SEO-Kampagne einführte (Umstrukturierung der Website, Umstellung des Systems der internen Verlinkung, Darstellung der Informationen).
Eine meiner Aufgaben während der SEO-Kampagne bestand darin, eine Website so umzubauen, dass GB nur die URLs aufruft, die es indizieren kann und die wir indizieren wollen. Kurz gesagt: Es sollten nur die Seiten im Google-Index stehen, die aus SEO-Sicht für uns wichtig sind. Auf der anderen Seite sollte GB nur die Webseiten crawlen, die wir von Google indexiert haben wollen, was nicht für jeden offensichtlich ist, z.B. wenn ein Online-Shop eine Filterung nach Farben, Größen und Preisen implementiert, und dies durch Manipulation der URL-Parameter geschieht, z.B.:
example.com/women/shoes/?color=red&size=40&price=200-250
Es könnte sich herausstellen, dass eine Lösung, die es GB erlaubt, dynamische URLs zu crawlen, dazu führt, dass es Zeit darauf verwendet, diese zu durchsuchen (und möglicherweise zu indizieren), anstatt die Seite zu crawlen.
Beispiel.com/Frauen/Schuhe/
Solche dynamisch erstellten URLs sind nicht nur nutzlos, sondern potenziell schädlich für die Suchmaschinenoptimierung, da sie fälschlicherweise für dünne Inhalte gehalten werden können, was zu einem Rückgang der Website-Rankings führt.
Im Rahmen dieses Experiments wollte ich auch einige Methoden der Strukturierung prüfen, ohne rel=“nofollow“ zu verwenden, GB in der robots.txt-Datei zu blockieren oder einen Teil des HTML-Codes in Frames zu platzieren, die für den Bot unsichtbar sind (blockierter iframe).
Ich habe drei Arten von JavaScript-Links getestet.
JavaScript-Link mit einem onclick-Ereignis
Ein einfacher Link, der auf JavaScript aufgebaut ist
< a href=“javascript:void(0)“ onclick=“window.location.href =’page4.html'“ >anchor6< /a >
GB gelangte problemlos auf die Unterseite page4.html und indexierte die gesamte Seite. Die Unterseite rangiert in den Suchergebnissen nicht für den Ausdruck „anchor6“, und dieser Ausdruck ist im Abschnitt „Anchor Texts“ in der Google Search Console nicht zu finden. Die Schlussfolgerung ist, dass der Link den Saft nicht übertragen hat.
Zusammenfassend:
- Ein klassischer JavaScript-Link ermöglicht es Google, die Website zu crawlen und die Seiten, auf die er stößt, zu indizieren.
- Er überträgt keinen Saft – er ist neutral.
Javascript-Link mit interner Funktion
Ich beschloss, das Spiel zu erhöhen, aber zu meiner Überraschung überwand GB das Hindernis in weniger als 2 Stunden nach der Veröffentlichung des Links.
< a href=“javascript:void(0)“ class=“js-link“ data-url=“page9.html“ >anchor7< /a >
Um diesen Link zu bedienen, verwendete ich eine externe Funktion, die darauf abzielte, die URL aus den Daten auszulesen und die Umleitung – nur die Umleitung eines Benutzers, wie ich hoffte – zum Ziel page9.html. Wie im früheren Fall war page9.html vollständig indiziert.
Interessant ist, dass trotz des Fehlens anderer eingehender Links page9.html die von GB am dritthäufigsten besuchte Seite des gesamten Webdienstes war, gleich nach page1.html und page2.html.
Ich hatte diese Methode schon früher zur Strukturierung von Webdiensten verwendet. Aber wie wir sehen, funktioniert sie nicht mehr. In der SEO lebt nichts ewig, abgesehen von den Gelben Seiten.
JavaScript-Link mit Kodierung
Doch ich wollte nicht aufgeben und beschloss, dass es einen Weg geben musste, GB die Tür vor der Nase zuzuschlagen. Also konstruierte ich eine einfache Funktion, kodierte die Daten mit einem base64-Algorithmus, und der Verweis sah wie folgt aus:
< a href=“javascript:void(0)“ class=“js-link“ data-url=“cGFnZTEwLmh0bWw=“ >anchor8< /a >
Damit war GB nicht in der Lage, einen JavaScript-Code zu erzeugen, der sowohl den Inhalt eines data-URL-Attributs entschlüsselt als auch eine Weiterleitung ermöglicht. Und da war es! Wir haben eine Möglichkeit, einen Webdienst zu strukturieren, ohne rel=nonfollows zu verwenden, um zu verhindern, dass Bots nach Belieben crawlen können! Auf diese Weise verschwenden wir nicht unser Crawl-Budget, was besonders bei großen Webdiensten wichtig ist, und GB tanzt endlich nach unserer Pfeife. Egal, ob die Funktion auf der gleichen Seite im Head-Bereich oder in einer externen JS-Datei eingeführt wurde, es gibt weder in den Server-Logs noch in der Search Console Hinweise auf einen Bot.
Teil 3: Versteckte Inhalte
Im letzten Test wollte ich prüfen, ob der Inhalt in z.B. versteckten Tabs von GB berücksichtigt und indexiert wird oder ob Google eine solche Seite rendert und den versteckten Text ignoriert, wie einige Spezialisten behaupten.
Ich wollte diese Behauptung entweder bestätigen oder verwerfen. Dazu habe ich auf Seite12.html eine Textwand mit über 2000 Zeichen platziert und einen Textblock mit etwa 20 Prozent des Textes (400 Zeichen) in Cascading Style Sheets versteckt und die Schaltfläche „Mehr anzeigen“ hinzugefügt. Innerhalb des versteckten Textes befand sich ein Link zu Seite13.html mit dem Anker anchor9.
Es besteht kein Zweifel, dass ein Bot eine Seite rendern kann. Wir können dies sowohl in Google Search Console als auch in Google Insight Speed beobachten. Meine Tests ergaben jedoch, dass ein Textblock, der nach dem Klicken auf die Schaltfläche „Mehr anzeigen“ angezeigt wurde, vollständig indexiert wurde. Die im Text versteckten Phrasen wurden in den Suchergebnissen angezeigt, und GB folgte den im Text versteckten Links. Außerdem waren die Anker der Links aus einem versteckten Textblock in der Google Search Console im Abschnitt Ankertext sichtbar, und die Seite 13.html begann ebenfalls, in den Suchergebnissen für das Schlüsselwort anchor9 zu ranken.
Dies ist entscheidend für Online-Shops, deren Inhalte oft in versteckten Tabs platziert werden. Jetzt sind wir sicher, dass GB die Inhalte in versteckten Tabs sieht, sie indiziert und den Saft der dort versteckten Links überträgt.
Die wichtigste Schlussfolgerung, die ich aus diesem Experiment ziehe, ist, dass ich keinen direkten Weg gefunden habe, die First Link Counts Rule durch die Verwendung modifizierter Links (Links mit Parameter, 301 Redirects, Canonicals, Ankerlinks) zu umgehen. Gleichzeitig ist es möglich, die Struktur einer Website mit Javascript-Links aufzubauen, wodurch wir von den Einschränkungen der First Link Counts Rule befreit sind. Außerdem kann der Google Bot die in Lesezeichen versteckten Inhalte sehen und indizieren und er folgt den darin versteckten Links.
Abonnieren Sie unsere täglichen Zusammenfassungen der sich ständig verändernden Suchmaschinenmarketing-Landschaft.
Hinweis: Mit dem Absenden dieses Formulars erklären Sie sich mit den Bedingungen von Third Door Media einverstanden. Wir respektieren Ihre Privatsphäre.
Über den Autor

„Akzeptieren Sie nicht ’nur‘ hohe Qualität. Das kann jeder machen. Wenn der Himmel die Grenze ist, finden Sie einen höheren Himmel.“ Max Cyrek ist CEO von Cyrek Digital, einem Berater für digitales Marketing und SEO-Evangelist. Im Laufe seiner Karriere hat Max zusammen mit seinem über 30-köpfigen Team mit Hunderten von Unternehmen zusammengearbeitet und ihnen zum Erfolg verholfen. Er ist seit fast zehn Jahren im digitalen Marketing tätig und hat sich auf technisches SEO spezialisiert und leitet erfolgreiche Marketingprojekte.
Schreibe einen Kommentar