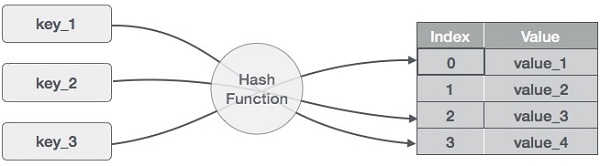
Hash Table is een datastructuur die gegevens op een associatieve manier opslaat. In een hash-tabel worden gegevens opgeslagen in een array-formaat, waarbij elke gegevenswaarde zijn eigen unieke indexwaarde heeft. Toegang tot gegevens wordt zeer snel als we de index van de gewenste gegevens kennen.
Dus wordt het een gegevensstructuur waarin invoeg- en zoekoperaties zeer snel zijn, ongeacht de grootte van de gegevens. Hash Table gebruikt een array als opslagmedium en gebruikt de hash-techniek om een index te genereren waar een element moet worden ingevoegd of van moet worden gelokaliseerd.
Hashing
Hashing is een techniek om een reeks sleutelwaarden om te zetten in een reeks indexen van een array. We gaan de modulo operator gebruiken om een bereik van sleutelwaarden te krijgen. Beschouw een voorbeeld van een hashtabel van grootte 20, en de volgende items moeten worden opgeslagen. De items zijn in het formaat (sleutel,waarde).
- (1,20)
- (2,70)
- (42,80)
- (4,25)
- (12,44)
- (14,32)
- (17,11)
- (13,78)
- (37,98)
| Sr.No. | Key | Hash | Array Index |
|---|---|---|---|
| 1 | 1 | 1 % 20 = 1 | 1 |
| 2 | 2 % 20 = 2 | 2 | |
| 3 | 42 | 42 % 20 = 2 | 2 |
| 4 | 4 | 4 % 20 = 4 | 4 |
| 5 | 12 | 12 % 20 = 12 | 12 |
| 6 | 14 | 14 % 20 = 14 | 14 |
| 7 | 17 | 17 % 20 = 17 | 17 |
| 8 | 13 | 13 % 20 = 13 | 13 |
| 9 | 37 | 37 % 20 = 17 | 17 |
Linear Probing
Zoals we kunnen zien, kan het gebeuren dat de hashing techniek wordt gebruikt om een reeds gebruikte index van de array te maken. In zo’n geval kunnen we de volgende lege plaats in de array zoeken door in de volgende cel te kijken tot we een lege cel vinden. Deze techniek heet linear probing.
| Sr.nr. | Key | Hash | Array Index | Na Linear Probing, Array Index |
|---|---|---|---|---|
| 1 | 1 | 1 % 20 = 1 | 1 | 1 |
| 2 | 2 | 2 % 20 = 2 | 2 | 2 |
| 3 | 42 | 42 % 20 = 2 | 2 | 3 |
| 4 | 4 | 4 % 20 = 4 | 4 | 4 |
| 5 | 12 | 12 % 20 = 12 | 12 | 12 |
| 6 | 14 | 14 % 20 = 14 | 14 | 14 |
| 7 | 17 | 17 % 20 = 17 | 17 | 17 |
| 8 | 13 | 13 % 20 = 13 | 13 | 13 |
| 9 | 37 | 37 % 20 = 17 | 17 | 18 |
Basisbewerkingen
Volgende zijn de basis primaire bewerkingen van een hashtabel.
-
Zoeken – Zoekt een element in een hashtabel.
-
Invoegen – Voegt een element in een hashtabel in.
-
Verwijderen – Verwijdert een element uit een hashtabel.
DataItem
Definieer een data-item met een aantal gegevens en een sleutel, op basis waarvan in een hashtabel moet worden gezocht.
struct DataItem { int data; int key;};
Hash Method
Definieer een hashing methode om de hash code van de sleutel van het data item te berekenen.
int hashCode(int key){ return key % SIZE;}
Search Operation
Wanneer een element moet worden doorzocht, bereken dan de hash code van de doorgegeven sleutel en lokaliseer het element met behulp van die hash code als index in de array. Gebruik lineaire sondering om het element eerder te krijgen als het element niet wordt gevonden bij de berekende hash code.
Voorbeeld
struct DataItem *search(int key) { //get the hash int hashIndex = hashCode(key); //move in array until an empty while(hashArray != NULL) { if(hashArray->key == key) return hashArray; //go to next cell ++hashIndex; //wrap around the table hashIndex %= SIZE; } return NULL; }
Insert Operation
Wanneer een element moet worden ingevoegd, bereken dan de hash code van de doorgegeven sleutel en zoek de index met behulp van die hash code als index in de array. Gebruik lineaire sondering voor een lege plaats, als een element wordt gevonden bij de berekende hash code.
Example
void insert(int key,int data) { struct DataItem *item = (struct DataItem*) malloc(sizeof(struct DataItem)); item->data = data; item->key = key; //get the hash int hashIndex = hashCode(key); //move in array until an empty or deleted cell while(hashArray != NULL && hashArray->key != -1) { //go to next cell ++hashIndex; //wrap around the table hashIndex %= SIZE; } hashArray = item; }
Delete Operation
Wanneer een element moet worden verwijderd, bereken dan de hash code van de doorgegeven sleutel en zoek de index met behulp van die hash code als een index in de array. Gebruik lineaire probing om het element vooruit te krijgen als een element niet gevonden wordt bij de berekende hash code. Wanneer het gevonden is, sla daar dan een dummy element op om de prestatie van de hash tabel intact te houden.
Example
struct DataItem* delete(struct DataItem* item) { int key = item->key; //get the hash int hashIndex = hashCode(key); //move in array until an empty while(hashArray !=NULL) { if(hashArray->key == key) { struct DataItem* temp = hashArray; //assign a dummy item at deleted position hashArray = dummyItem; return temp; } //go to next cell ++hashIndex; //wrap around the table hashIndex %= SIZE; } return NULL; }
Om meer te weten over hash implementatie in C programmeertaal, klik hier.
Geef een antwoord