Aveți vizibilitate în aplicația dumneavoastră Java este crucială pentru a înțelege cum funcționează acum, cum a funcționat în trecut și pentru a crește înțelegerea modului în care ar putea funcționa în viitor. De cele mai multe ori, analiza jurnalelor este cea mai rapidă modalitate de a detecta ce nu a mers bine, făcând astfel ca logarea în Java să fie esențială pentru a asigura performanța și sănătatea aplicației dumneavoastră, precum și pentru a minimiza și reduce orice timp de nefuncționare. Faptul de a avea o soluție centralizată de logare și monitorizare ajută la reducerea timpului mediu de reparare, îmbunătățind eficiența echipei Ops sau DevOps.
Prin respectarea bunelor practici veți obține mai multă valoare din jurnalele dvs. și veți face mai ușoară utilizarea acestora. Veți putea identifica mai ușor cauza principală a erorilor și a performanțelor slabe și veți putea rezolva problemele înainte ca acestea să aibă impact asupra utilizatorilor finali. Așadar, astăzi, permiteți-mi să vă împărtășesc câteva dintre cele mai bune practici pe care ar trebui să le respectați atunci când lucrați cu aplicații Java. Să intrăm în subiect.
- Utilizați o bibliotecă de logare standard
- Select Your Appenders Wisely
- Utilizați mesaje semnificative
- Logging Java Stack Traces
- Logging Java Exceptions
- Utilizați un nivel de jurnal adecvat
- Log in JSON
- Păstrați consecvența structurii jurnalului
- Adaugați context jurnalelor dvs.
- Java Logging in Containers
- Don’t Log Too Much or Too Little
- Țineți minte audiența
- Evitați să înregistrați informații sensibile
- Utilizați o soluție de gestionare a jurnalelor pentru a centraliza & Monitorizarea jurnalelor Java
- Concluzie
- Share
Utilizați o bibliotecă de logare standard
Logarea în Java se poate face în câteva moduri diferite. Puteți utiliza o bibliotecă de logare dedicată, un API comun sau chiar să scrieți jurnalele în fișier sau direct într-un sistem de logare dedicat. Cu toate acestea, atunci când alegeți biblioteca de logare pentru sistemul dvs. gândiți-vă înainte. Lucrurile pe care trebuie să le luați în considerare și să le evaluați sunt performanța, flexibilitatea, aplicațiile pentru noile soluții de centralizare a jurnalelor și așa mai departe. Dacă vă legați direct de un singur cadru, trecerea la o bibliotecă mai nouă poate necesita o cantitate substanțială de muncă și timp. Țineți cont de acest lucru și optați pentru API-ul care vă va oferi flexibilitatea de a schimba bibliotecile de logare în viitor. La fel ca în cazul trecerii de la Log4j la Logback și la Log4j 2, atunci când folosiți API SLF4J, singurul lucru pe care trebuie să-l faceți este să schimbați dependența, nu codul.
Dacă sunteți nou în bibliotecile de logare Java, consultați ghidurile noastre pentru începători:
- Log4j Tutorial
- Logback Tutorial
- Log4j2 Tutorial
- SLF4J Tutorial
Select Your Appenders Wisely
Appenderii definesc unde vor fi livrate evenimentele de logare. Cei mai comuni apenderi sunt Console și File Appenders. Deși utile și cunoscute pe scară largă, este posibil ca acestea să nu vă satisfacă cerințele. De exemplu, este posibil să doriți să vă scrieți jurnalele într-un mod asincron sau să doriți să vă livrați jurnalele prin rețea utilizând apenderi precum cel pentru Syslog, ca acesta:
<Appenders> <Console name="Console" target="SYSTEM_OUT"> <PatternLayout pattern="%d %level %c - %m%n"/> </Console> <Syslog name="Syslog" host="logsene-syslog-receiver.sematext.com" port="514" protocol="TCP" format="RFC5424" appName="11111111-2222-3333-4444-555555555555" facility="LOCAL0" mdcId="mdc" newLine="true"/></Appenders>
Cu toate acestea, rețineți că utilizarea unor apenderi precum cel prezentat mai sus face ca pipeline-ul dvs. de jurnalizare să fie susceptibil la erori de rețea și întreruperi de comunicare. Acest lucru poate avea ca rezultat faptul că jurnalele nu sunt trimise la destinație, ceea ce poate fi inacceptabil. De asemenea, doriți să evitați ca logarea să vă afecteze sistemul dacă aplicația este proiectată într-un mod blocant. Pentru a afla mai multe, consultați postarea de pe blogul nostru Logging libraries vs Log shippers.
Utilizați mesaje semnificative
Unul dintre lucrurile cruciale atunci când vine vorba de crearea de jurnale, dar și unul dintre cele nu atât de ușoare este utilizarea de mesaje semnificative. Evenimentele din jurnalul dvs. ar trebui să includă mesaje care sunt unice pentru situația dată, să le descrie clar și să informeze persoana care le citește. Imaginați-vă că în aplicația dvs. a apărut o eroare de comunicare. Ați putea face așa:
LOGGER.warn("Communication error");
Dar ați putea, de asemenea, să creați un mesaj ca acesta:
LOGGER.warn("Error while sending documents to events Elasticsearch server, response code %d, response message %s. The message sending will be retried.", responseCode, responseMessage);
Puteți vedea cu ușurință că primul mesaj va informa persoana care citește jurnalele despre unele probleme de comunicare. Acea persoană va avea probabil contextul, numele loggerului și numărul liniei în care s-a produs avertismentul, dar asta este tot. Pentru a obține mai mult context, acea persoană ar trebui să se uite la cod, să știe la ce versiune de cod se referă eroarea și așa mai departe. Acest lucru nu este amuzant și de multe ori nu este ușor, și cu siguranță nu este ceva ce cineva dorește să facă în timp ce încearcă să rezolve o problemă de producție cât mai repede posibil.
Cel de-al doilea mesaj este mai bun. Acesta oferă informații exacte despre ce fel de eroare de comunicare s-a întâmplat, ce făcea aplicația în acel moment, ce cod de eroare a primit și care a fost răspunsul de la serverul la distanță. În cele din urmă, acesta informează, de asemenea, că trimiterea mesajului va fi reluată. Lucrul cu astfel de mesaje este cu siguranță mai ușor și mai plăcut.
În cele din urmă, gândiți-vă la dimensiunea și verbozitatea mesajului. Nu consemnați informații care sunt prea abundente. Aceste date trebuie să fie stocate undeva pentru a fi utile. Un mesaj foarte lung nu va fi o problemă, dar dacă acea linie se repetă de sute de ori într-un minut și aveți o mulțime de jurnale verboase, păstrarea mai îndelungată a acestor date poate fi problematică și, în cele din urmă, va costa, de asemenea, mai mult.
Logging Java Stack Traces
Una dintre părțile foarte importante ale logării Java sunt urmele de stivă Java. Aruncați o privire la următorul cod:
package com.sematext.blog.logging;import org.apache.logging.log4j.LogManager;import org.apache.logging.log4j.Logger;import java.io.IOException;public class Log4JExceptionNoThrowable { private static final Logger LOGGER = LogManager.getLogger(Log4JExceptionNoThrowable.class); public static void main(String args) { try { throw new IOException("This is an I/O error"); } catch (IOException ioe) { LOGGER.error("Error while executing main thread"); } }}
Codul de mai sus va duce la aruncarea unei excepții și un mesaj de jurnal care va fi tipărit în consolă cu configurația noastră implicită va arăta după cum urmează:
11:42:18.952 ERROR - Error while executing main thread
După cum puteți vedea, nu sunt prea multe informații acolo. Știm doar că a apărut o problemă, dar nu știm unde s-a întâmplat, sau care a fost problema, etc. Nu este foarte informativ.
Acum, uitați-vă la același cod cu o instrucțiune de logare ușor modificată:
package com.sematext.blog.logging;import org.apache.logging.log4j.LogManager;import org.apache.logging.log4j.Logger;import java.io.IOException;public class Log4JException { private static final Logger LOGGER = LogManager.getLogger(Log4JException.class); public static void main(String args) { try { throw new IOException("This is an I/O error"); } catch (IOException ioe) { LOGGER.error("Error while executing main thread", ioe); } }}
Cum vedeți, de data aceasta am inclus obiectul de excepție în sine în mesajul nostru de log:
LOGGER.error("Error while executing main thread", ioe);
Aceasta ar avea ca rezultat următorul jurnal de eroare în consolă cu configurația noastră implicită:
11:30:17.527 ERROR - Error while executing main threadjava.io.IOException: This is an I/O error at com.sematext.blog.logging.Log4JException.main(Log4JException.java:13)
Conține informații relevante – i.adică numele clasei, metoda în care a apărut problema și, în final, numărul liniei în care a apărut problema. Desigur, în situațiile din viața reală, urmele de stivă vor fi mai lungi, dar ar trebui să le includeți pentru a vă oferi suficiente informații pentru o depanare adecvată.
Pentru a afla mai multe despre cum să gestionați urmele de stivă Java cu Logstash, consultați Handling Multiline Stack Traces with Logstash sau uitați-vă la Logagent, care poate face acest lucru pentru dumneavoastră din start.
Logging Java Exceptions
Când vă ocupați de excepțiile Java și de urme de stivă nu ar trebui să vă gândiți doar la întreaga urmă de stivă, la liniile în care a apărut problema și așa mai departe. Ar trebui să vă gândiți, de asemenea, la modul în care să nu vă ocupați de excepții.
Evitați să ignorați în tăcere excepțiile. Nu doriți să ignorați ceva important. De exemplu, nu faceți acest lucru:
try { throw new IOException("This is an I/O error");} catch (IOException ioe) {}
De asemenea, nu înregistrați pur și simplu o excepție și nu o aruncați mai departe. Asta înseamnă că tocmai ați împins problema în sus pe stiva de execuție. Evitați și astfel de lucruri:
try { throw new IOException("This is an I/O error");} catch (IOException ioe) { LOGGER.error("I/O error occurred during request processing", ioe); throw ioe;}
Dacă doriți să aflați mai multe despre excepții, citiți ghidul nostru despre manipularea excepțiilor Java, în care acoperim totul, de la ce sunt acestea până la cum să le prindeți și să le rezolvați.
Utilizați un nivel de jurnal adecvat
Când scrieți codul aplicației, gândiți-vă de două ori la un anumit mesaj de jurnal. Nu orice informație este la fel de importantă și nu orice situație neașteptată este o eroare sau un mesaj critic. De asemenea, utilizați nivelurile de logare în mod consecvent – informațiile de un tip similar ar trebui să fie la un nivel de gravitate similar.
Atât fațada SLF4J, cât și fiecare cadru de logare Java pe care îl veți utiliza oferă metode care pot fi utilizate pentru a furniza un nivel de logare adecvat. De exemplu:
LOGGER.error("I/O error occurred during request processing", ioe);
Log in JSON
Dacă plănuim să înregistrăm și să privim datele manual într-un fișier sau pe ieșirea standard, atunci înregistrarea planificată va fi mai mult decât bună. Este mai ușor de utilizat – suntem obișnuiți cu ea. Dar acest lucru este viabil doar pentru aplicații foarte mici și chiar și atunci se sugerează să folosiți ceva care vă va permite să corelați datele metrice cu jurnalele. Efectuarea unor astfel de operațiuni într-o fereastră de terminal nu este amuzantă și, uneori, pur și simplu nu este posibil. Dacă doriți să stocați jurnalele în sistemul de gestionare și centralizare a jurnalelor, ar trebui să le înregistrați în JSON. Acest lucru se datorează faptului că parsarea nu este gratuită – de obicei înseamnă utilizarea expresiilor regulate. Bineînțeles, puteți plăti acest preț în log shipper, dar de ce să faceți asta dacă puteți înregistra cu ușurință în JSON. Înregistrarea în JSON înseamnă, de asemenea, gestionarea ușoară a urmelor de stivă, deci încă un avantaj. Ei bine, puteți, de asemenea, să vă conectați pur și simplu la o destinație compatibilă cu Syslog, dar aceasta este o altă poveste.
În majoritatea cazurilor, pentru a activa logarea în JSON în cadrul de logare Java este suficient să includeți configurația corespunzătoare. De exemplu, să presupunem că avem următorul mesaj de jurnal inclus în codul nostru:
LOGGER.info("This is a log message that will be logged in JSON!");
Pentru a configura Log4J 2 pentru a scrie mesaje de jurnal în JSON, vom include următoarea configurație:
<?xml version="1.0" encoding="UTF-8"?><Configuration status="WARN"> <Appenders> <Console name="Console" target="SYSTEM_OUT"> <JSONLayout compact="true" eventEol="true"> </JSONLayout> </Console> </Appenders> <Loggers> <Root level="info"> <AppenderRef ref="Console"/> </Root> </Loggers></Configuration>
Rezultatul ar arăta după cum urmează:
{"instant":{"epochSecond":1596030628,"nanoOfSecond":695758000},"thread":"main","level":"INFO","loggerName":"com.sematext.blog.logging.Log4J2JSON","message":"This is a log message that will be logged in JSON!","endOfBatch":false,"loggerFqcn":"org.apache.logging.slf4j.Log4jLogger","threadId":1,"threadPriority":5}
Păstrați consecvența structurii jurnalului
Structura evenimentelor de jurnal trebuie să fie consecventă. Acest lucru nu este valabil doar în cadrul unei singure aplicații sau al unui set de microservicii, ci ar trebui să fie aplicat în întreaga dumneavoastră stivă de aplicații. Cu evenimente de jurnal structurate în mod similar, va fi mai ușor să le examinați, să le comparați, să le corelați sau pur și simplu să le stocați într-un magazin de date dedicat. Este mai ușor să vă uitați în datele care provin de la sistemele dvs. atunci când știți că acestea au câmpuri comune, cum ar fi severitatea și numele de gazdă, astfel încât să puteți tăia cu ușurință datele pe baza acestor informații. Pentru inspirație, aruncați o privire la Sematext Common Schema, chiar dacă nu sunteți un utilizator Sematext.
Desigur, păstrarea structurii nu este întotdeauna posibilă, deoarece stiva dvs. completă este formată din servere dezvoltate extern, baze de date, motoare de căutare, cozi etc., fiecare dintre acestea având propriul set de jurnale și formate de jurnal. Cu toate acestea, pentru a vă păstra sănătatea mintală a dvs. și a echipei dvs. minimizați numărul de structuri diferite ale mesajelor de jurnal pe care le puteți controla.
O modalitate de a păstra o structură comună este de a folosi același model pentru jurnalele dvs., cel puțin pentru cele care folosesc același cadru de logare. De exemplu, dacă aplicațiile și microserviciile dvs. folosesc Log4J 2, ați putea folosi un model ca acesta:
<PatternLayout> <Pattern>%d %p %c{35}:%L - %m%n</Pattern></PatternLayout>
Prin utilizarea unui singur model sau a unui set foarte limitat de modele, puteți fi siguri că numărul de formate de jurnal va rămâne mic și controlabil.
Adaugați context jurnalelor dvs.
Contextul informației este important, iar pentru noi, dezvoltatorii și DevOps, un mesaj de jurnal este o informație. Priviți următoarea intrare de jurnal:
An error occurred!
Știm că a apărut o eroare undeva în aplicație. Nu știm unde s-a întâmplat, nu știm ce fel de eroare a fost, știm doar când s-a întâmplat. Acum, uitați-vă la un mesaj cu ceva mai multe informații contextuale:
com.sematext.blog.logging.ParsingErrorExample - A parsing error occurred for user with id 1234!
Aceeași înregistrare de jurnal, dar cu mult mai multe informații contextuale. Știm firul în care s-a întâmplat, știm la ce clasă a fost generată eroarea. Am modificat mesajul, de asemenea, pentru a include utilizatorul pentru care s-a produs eroarea, astfel încât să ne putem întoarce la utilizator, dacă este necesar. De asemenea, am putea include informații suplimentare, cum ar fi contextele de diagnosticare. Gândiți-vă la ceea ce aveți nevoie și includeți-le.
Pentru a include informații de context nu trebuie să faceți prea multe atunci când vine vorba de codul care este responsabil pentru generarea mesajului de jurnal. De exemplu, PatternLayout din Log4J 2 vă oferă tot ceea ce aveți nevoie pentru a include informațiile de context. Puteți opta pentru un model foarte simplu ca acesta:
<PatternLayout pattern="%d{HH:mm:ss.SSS} %-5level - %msg%n"/>
Acesta va avea ca rezultat un mesaj de jurnal asemănător cu cel de mai jos:
17:13:08.059 INFO - This is the first INFO level log message!
Dar puteți, de asemenea, să includeți un model care va include mult mai multe informații:
<PatternLayout pattern="%d{HH:mm:ss.SSS} %c %l %-5level - %msg%n"/>
Acesta va avea ca rezultat un mesaj de jurnal ca acesta:
17:24:01.710 com.sematext.blog.logging.Log4j2 com.sematext.blog.logging.Log4j2.main(Log4j2.java:12) INFO - This is the first INFO level log message!
Java Logging in Containers
Gândiți-vă la mediul în care va rula aplicația dvs. Există o diferență în configurația de logare atunci când vă rulați codul Java într-un VM sau pe o mașină bare-metal, este diferită atunci când îl rulați într-un mediu containerizat și, bineînțeles, este diferită atunci când vă rulați codul Java sau Kotlin pe un dispozitiv Android.
Pentru a configura logarea într-un mediu containerizat trebuie să alegeți abordarea pe care doriți să o adoptați. Puteți utiliza unul dintre driverele de logare furnizate – cum ar fi journald, logagent, Syslog sau fișierul JSON. Pentru a face acest lucru, amintiți-vă că aplicația dvs. nu ar trebui să scrie fișierul jurnal în memoria efemeră a containerului, ci pe ieșirea standard. Acest lucru poate fi realizat cu ușurință prin configurarea cadrului de logare pentru a scrie jurnalul în consolă. De exemplu, cu Log4J 2 ar trebui doar să folosiți următoarea configurație de aplicație:
<Appenders> <Console name="Console" target="SYSTEM_OUT"> <PatternLayout pattern="%d{HH:mm:ss.SSS} - %m %n"/> </Console></Appenders>
Puteți, de asemenea, să omiteți complet driverele de logare și să expediați jurnalele direct către soluția dvs. de logare centralizată, cum ar fi Sematext Cloud al nostru:
<Appenders> <Console name="Console" target="SYSTEM_OUT"> <PatternLayout pattern="%d %level %c - %m%n"/> </Console> <Syslog name="Syslog" host="logsene-syslog-receiver.sematext.com" port="514" protocol="TCP" format="RFC5424" appName="11111111-2222-3333-4444-555555555555" facility="LOCAL0" mdcId="mdc" newLine="true"/></Appenders>
Don’t Log Too Much or Too Little
Ca dezvoltatori avem tendința de a crede că totul ar putea fi important – avem tendința de a marca fiecare pas al algoritmului nostru sau al codului de afaceri ca fiind important. Pe de altă parte, uneori facem opusul – nu adăugăm logare acolo unde ar trebui sau înregistrăm doar nivelurile de logare FATAL și ERROR. Ambele abordări nu se vor descurca foarte bine. Atunci când vă scrieți codul și adăugați jurnalizare, gândiți-vă la ceea ce va fi important pentru a vedea dacă aplicația funcționează corect și la ceea ce va fi important pentru a putea diagnostica o stare greșită a aplicației și pentru a o remedia. Folosiți acest lucru ca lumină călăuzitoare pentru a decide ce și unde să înregistrați. Rețineți că dacă adăugați prea multe jurnale veți ajunge la oboseală informațională, iar dacă nu aveți suficiente informații, veți ajunge la incapacitatea de depanare.
Țineți minte audiența
În cele mai multe cazuri, nu veți fi singura persoană care se uită la jurnale. Amintiți-vă întotdeauna că. Există mai mulți actori care se pot uita la jurnale.
Dezvoltatorul poate să se uite la jurnale pentru depanare sau în timpul sesiunilor de depanare. Pentru astfel de persoane, jurnalele pot fi detaliate, tehnice și pot include informații foarte profunde legate de modul în care funcționează sistemul. O astfel de persoană va avea, de asemenea, acces la cod sau chiar va cunoaște codul și vă puteți asuma acest lucru.
Apoi există DevOps. Pentru aceștia, evenimentele din jurnal vor fi necesare pentru depanare și ar trebui să includă informații utile în diagnosticare. Vă puteți asuma cunoașterea sistemului, a arhitecturii sale, a componentelor sale și a configurației componentelor, dar nu ar trebui să vă asumați cunoștințele despre codul platformei.
În cele din urmă, jurnalele aplicației dvs. pot fi citite chiar de către utilizatorii dvs. Într-un astfel de caz, jurnalele ar trebui să fie suficient de descriptive pentru a ajuta la remedierea problemei, dacă acest lucru este posibil, sau pentru a oferi suficiente informații echipei de asistență care îl ajută pe utilizator. De exemplu, utilizarea Sematext pentru monitorizare implică instalarea și rularea unui agent de monitorizare. Dacă vă aflați în spatele unui firewall foarte restrictiv și agentul nu poate expedia metrice către Sematext, acesta înregistrează erorile vizate pe care utilizatorii Sematext înșiși le pot examina, de asemenea.
Am putea merge mai departe și să identificăm și mai mulți actori care ar putea să se uite în jurnale, dar această listă scurtă ar trebui să vă dea o idee despre ceea ce ar trebui să aveți în vedere atunci când vă scrieți mesajele de jurnal.
Evitați să înregistrați informații sensibile
Informațiile sensibile nu ar trebui să fie prezente în jurnale sau ar trebui să fie mascate. Parolele, numerele cărților de credit, numerele de securitate socială, token-urile de acces și așa mai departe – toate acestea pot fi periculoase dacă sunt scurse sau accesate de cei care nu ar trebui să le vadă. Există două lucruri pe care ar trebui să le luați în considerare.
Gândiți-vă dacă informațiile sensibile sunt cu adevărat esențiale pentru rezolvarea problemelor. Poate că, în loc de numărul cardului de credit, este suficient să păstrați informațiile despre identificatorul tranzacției și data tranzacției? Poate că nu este necesar să păstrați numărul de securitate socială în jurnale atunci când puteți stoca cu ușurință identificatorul utilizatorului. Gândiți-vă la astfel de situații, gândiți-vă la datele pe care le stocați și scrieți datele sensibile doar atunci când este cu adevărat necesar.
Al doilea lucru este expedierea jurnalelor cu informații sensibile către un serviciu de jurnale găzduit. Există foarte puține excepții în care nu trebuie urmat următorul sfat. Dacă jurnalele dvs. au și trebuie să aibă stocate informații sensibile, mascați-le sau eliminați-le înainte de a le trimite la depozitul centralizat de jurnale. Cei mai populari expeditori de jurnale, cum ar fi Logagent al nostru, includ o funcționalitate care permite eliminarea sau mascarea datelor sensibile.
În cele din urmă, mascarea informațiilor sensibile se poate face în cadrul de logare în sine. Să vedem cum se poate face prin extinderea Log4j 2. Codul nostru care produce evenimente de log arată după cum urmează (exemplul complet poate fi găsit pe Sematext Github):
public class Log4J2Masking { private static Logger LOGGER = LoggerFactory.getLogger(Log4J2Masking.class); private static final Marker SENSITIVE_DATA_MARKER = MarkerFactory.getMarker("SENSITIVE_DATA_MARKER"); public static void main(String args) { LOGGER.info("This is a log message without sensitive data"); LOGGER.info(SENSITIVE_DATA_MARKER, "This is a a log message with credit card number 1234-4444-3333-1111 in it"); }}
Dacă ar fi să rulați întregul exemplu de pe Github, rezultatul ar fi următorul:
21:20:42.099 - This is a log message without sensitive data21:20:42.101 - This is a a log message with credit card number ****-****-****-**** in it
Vezi că numărul cărții de credit a fost mascat. Acest lucru a fost realizat deoarece am adăugat un Convertor personalizat care verifică dacă Markerul dat este trecut de-a lungul evenimentului de jurnal și încearcă să înlocuiască un model definit. Implementarea unui astfel de convertor arată după cum urmează:
@Plugin(name = "sample_logging_mask", category = "Converter")@ConverterKeys("sc")public class LoggingConverter extends LogEventPatternConverter { private static Pattern PATTERN = Pattern.compile("\b({4})-({4})-({4})-({4})\b"); public LoggingConverter(String options) { super("sc", "sc"); } public static LoggingConverter newInstance(final String options) { return new LoggingConverter(options); } @Override public void format(LogEvent event, StringBuilder toAppendTo) { String message = event.getMessage().getFormattedMessage(); String maskedMessage = message; if (event.getMarker() != null && "SENSITIVE_DATA_MARKER".compareToIgnoreCase(event.getMarker().getName()) == 0) { Matcher matcher = PATTERN.matcher(message); if (matcher.find()) { maskedMessage = matcher.replaceAll("****-****-****-****"); } } toAppendTo.append(maskedMessage); }}
Este foarte simplu și ar putea fi scris într-un mod mai optimizat și ar trebui, de asemenea, să gestioneze toate formatele posibile de numere de cărți de credit, dar este suficient pentru acest scop.
Înainte de a trece la explicarea codului, aș dori să vă arăt și fișierul de configurare log4j2.xml pentru acest exemplu:
<?xml version="1.0" encoding="UTF-8"?><Configuration status="WARN" packages="com.sematext.blog.logging"> <Appenders> <Console name="Console" target="SYSTEM_OUT"> <PatternLayout pattern="%d{HH:mm:ss.SSS} - %sc %n"/> </Console> </Appenders> <Loggers> <Root level="info"> <AppenderRef ref="Console"/> </Root> </Loggers></Configuration>
După cum puteți vedea, am adăugat atributul packages în configurația noastră pentru a-i spune framework-ului unde să caute convertorul nostru. Apoi am folosit modelul %sc pentru a furniza mesajul de jurnal. Facem asta pentru că nu putem suprascrie modelul implicit %m. Odată ce Log4j2 găsește modelul %sc, va folosi convertorul nostru, care ia mesajul formatat al evenimentului de jurnal și folosește un regex simplu pentru a înlocui datele, dacă acestea au fost găsite. Simplu ca bună ziua.
Un lucru care trebuie observat aici este faptul că folosim funcționalitatea Marker. Potrivirea regex este costisitoare și nu dorim să facem acest lucru pentru fiecare mesaj de jurnal. De aceea, marcăm evenimentele de jurnal care trebuie procesate cu Markerul creat, astfel încât doar cele marcate să fie verificate.
Utilizați o soluție de gestionare a jurnalelor pentru a centraliza & Monitorizarea jurnalelor Java
Cu complexitatea aplicațiilor, volumul jurnalelor dvs. va crește și el. Este posibil să scăpați cu înregistrarea într-un fișier și să folosiți jurnalele numai atunci când este necesară depanarea, dar atunci când volumul de date crește, devine rapid dificil și lent să depanați în acest mod Când se întâmplă acest lucru, luați în considerare utilizarea unei soluții de gestionare a jurnalelor pentru a centraliza și monitoriza jurnalele dvs. Puteți opta pentru o soluție internă bazată pe software open-source, cum ar fi Elastic Stack, sau puteți utiliza unul dintre instrumentele de gestionare a jurnalelor disponibile pe piață, cum ar fi Sematext Logs.
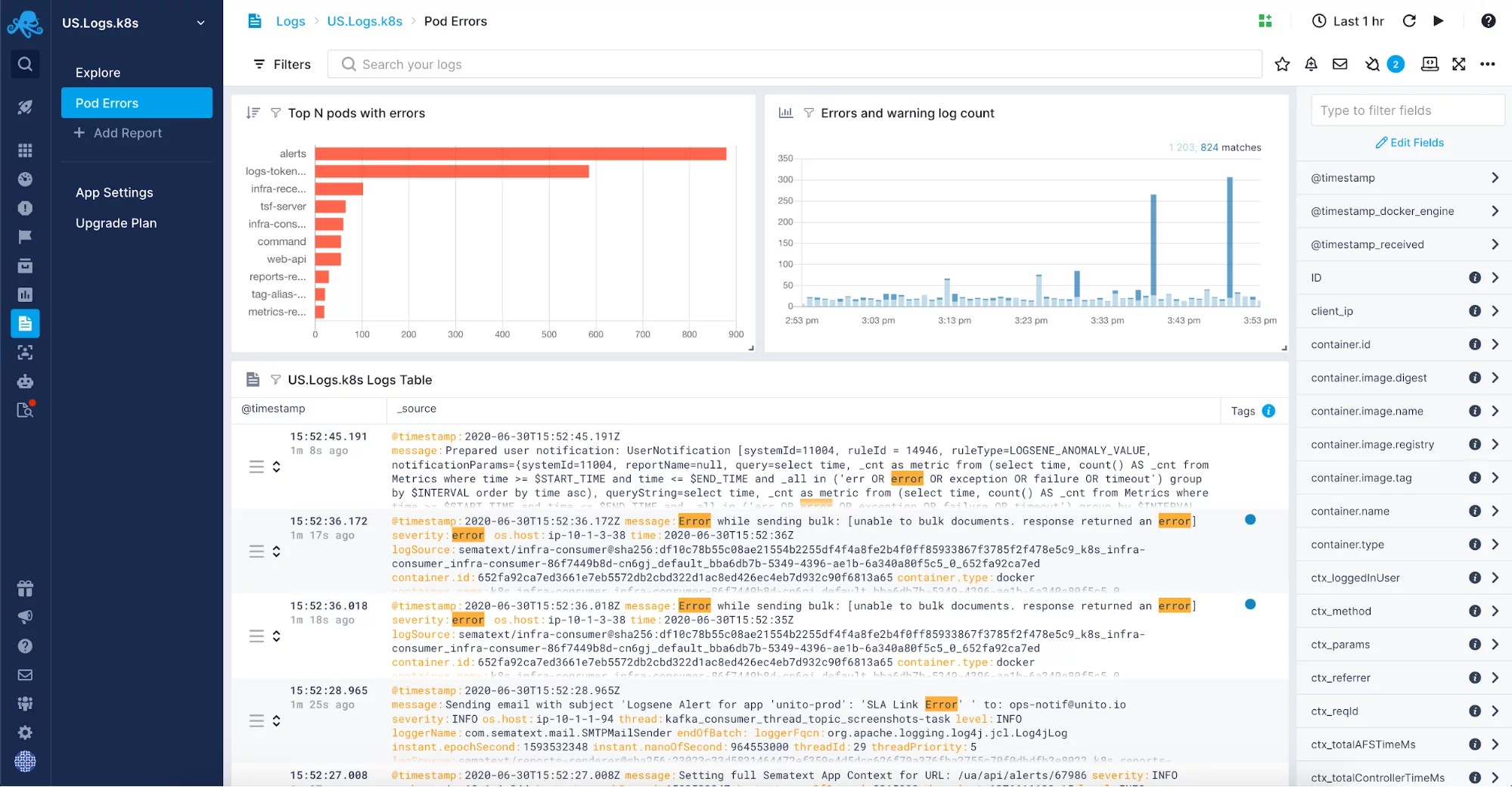
O soluție de centralizare a jurnalelor complet gestionată vă va oferi libertatea de a nu mai fi nevoit să gestionați încă o parte, de obicei destul de complexă, a infrastructurii dumneavoastră. În schimb, veți putea să vă concentrați asupra aplicației dvs. și va trebui să configurați doar expedierea de jurnale. Este posibil să doriți să includeți jurnale precum jurnalele de colectare a gunoiului JVM în soluția dvs. de jurnal gestionat. După ce le activați pentru aplicațiile și sistemele dvs. care lucrează pe JVM, veți dori să agregați jurnalele într-un singur loc pentru corelarea și analiza jurnalelor și pentru a vă ajuta să reglați colectarea gunoiului în instanțele JVM. Astfel de jurnale corelate cu metricele sunt o sursă neprețuită de informații pentru depanarea problemelor legate de garbage collection.
Dacă sunteți interesat să vedeți cum Sematext Logs se compară cu soluții similare, accesați articolul nostru despre cel mai bun software de gestionare a jurnalelor sau articolul de pe blog în care analizăm unele dintre cele mai bune instrumente de analiză a jurnalelor, dar vă recomandăm să folosiți versiunea de încercare gratuită de 14 zile pentru a explora pe deplin caracteristicile sale. Încercați-l și vedeți cu ochii voștri!
Concluzie
Incorporarea fiecărei bune practici s-ar putea să nu fie ușor de implementat imediat, în special pentru aplicațiile care sunt deja live și funcționează în producție. Dar dacă vă acordați timp și implementați sugestiile una după alta, veți începe să observați o creștere a utilității jurnalelor dumneavoastră. Pentru mai multe sfaturi despre cum să profitați la maximum de jurnalele dumneavoastră, vă recomandăm să parcurgeți și celălalt articol al nostru despre cele mai bune practici de logare, în care explicăm și intrările și ieșirile pe care ar trebui să le urmați indiferent de tipul de aplicație cu care lucrați. Și nu uitați că la Sematext ajutăm organizațiile cu configurările de logare prin oferirea de consultanță în logare, așa că, dacă aveți probleme, contactați-ne și vom fi bucuroși să vă ajutăm.
.
Lasă un răspuns