Înscrieți-vă pentru recapitulările noastre zilnice ale peisajului în continuă schimbare al marketingului de căutare.
Nota: Prin trimiterea acestui formular, sunteți de acord cu termenii Third Door Media. Vă respectăm confidențialitatea.

Pe forumurile de internet și pe grupurile de Facebook legate de conținut, deseori izbucnesc discuții despre cum funcționează Googlebot – pe care îl vom numi cu tandrețe GB aici – și ce poate și ce nu poate vedea, ce fel de linkuri vizitează și cum influențează SEO.
În acest articol, voi prezenta rezultatele experimentului meu de trei luni.
În ultimele trei luni, aproape zilnic, GB m-a vizitat ca un prieten care trece pe la o bere.
Câteodată era singur:
: 66.249.76.136 /page1.html Mozilla/5.0 (compatibil; Googlebot/2.1; +http://www.google.com/bot.html)
: 66.249.76.136 /page5.html Mozilla/5.0 (compatibil; Googlebot/2.1; +http://www.google.com/bot.html)
: 66.249.76.140 /page3.html Mozilla/5.0 (compatibil; Googlebot/2.1; +http://www.google.com/bot.html)
: 66.249.76.140 /page3.html Mozilla/5.0 (compatibil; Googlebot/2.1; +http://www.google.com/bot.html)
.1; +http://www.google.com/bot.html)
: 66.249.64.72 /page2.html Mozilla/5.0 (compatibil; Googlebot/2.1; +http://www.google.com/bot.html)
: 66.249.64.72 /page6.html Mozilla/5.0 (compatibil; Googlebot/2.1; +http://www.google.com/bot.html)
: 66.249.64.72 /page6.html Mozilla/5.0 (compatibil; Googlebot/2.1; +http://www.google.com/bot.html)
Câteodată și-a adus și prietenii:
: 64.233.172.231 /page1.html Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko; Google Search Console) Chrome/41.0.2272.118 Safari/537.36
: 66.249.69.235 /image.jpg Googlebot-Image/1.0
: 66.249.76.156 /page2.html Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2272.96 Mobile Safari/537.36 (compatibil; Googlebot/2.1; +http://www.google.com/bot.html)
Și ne-am distrat copios jucând diferite jocuri:
Catch: Am observat cum GB iubește să ruleze redirecționări 301 și să crawleze imagini, și să ruleze din canonice.
Hide-and-seek: Googlebot se ascundea în conținutul ascuns (pe care, așa cum susțin părinții săi, nu îl tolerează și îl evită)
Supraviețuire: Am pregătit capcane și am așteptat să le declanșeze.
Obstacole: Am plasat obstacole cu diferite niveluri de dificultate pentru a vedea cum se va descurca micul meu prieten cu ele.
După cum probabil vă puteți da seama, nu am fost dezamăgit. Ne-am distrat de minune și am devenit buni prieteni. Cred că prietenia noastră are un viitor strălucit.
Dar să trecem la subiect!
Am construit un site web cu conținut legat de merite despre o agenție de turism interstelar care oferă zboruri către planete încă nedescoperite din galaxia noastră și de dincolo de ea.
Conținutul părea să aibă o mulțime de merite când de fapt era o grămadă de prostii.
Structura site-ului experimental arăta astfel:
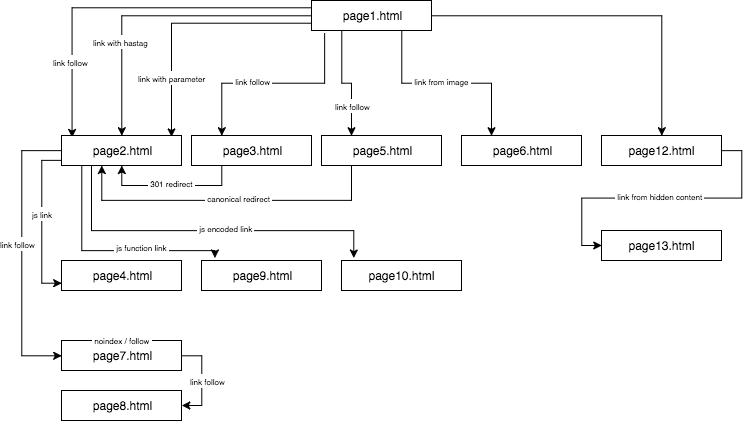
Am furnizat conținut unic și m-am asigurat că fiecare ancoră/titlu/alt, precum și alți coeficienți, erau unici la nivel global (cuvinte false). Pentru a face lucrurile mai ușoare pentru cititor, în descriere nu voi folosi nume precum anchor cutroicano matestito, ci mă voi referi la ele ca anchor1, etc.
Suger că vă sugerez să țineți harta de mai sus deschisă într-o fereastră separată în timp ce citiți acest articol.
- Partea 1: Primul link contează
- Link către un site web cu o ancoră
- Link către un site web cu un parametru
- Legătură către un site web dintr-o redirecționare
- Legătură către o pagină folosind eticheta canonică
- Partea 2: Bugetul de crawlare
- Legătură JavaScript cu un eveniment onclick
- Legătură JavaScript cu o funcție internă
- Legătura JavaScript cu codarea
- Partea 3: Conținutul ascuns
- Despre autor
Partea 1: Primul link contează
Unul dintre lucrurile pe care am vrut să le testez în acest experiment SEO a fost regula First Link Counts – dacă poate fi omisă și cum influențează ea optimizarea.
Regula First Link Counts spune că pe o pagină, Google Bot vede doar primul link către o subpagină. Dacă pe o pagină aveți două linkuri către aceeași subpagină, cel de-al doilea va fi ignorat, conform acestei reguli. Google Bot va ignora ancora din al doilea și din fiecare link consecutiv atunci când va calcula rangul paginii.
Este o problemă supervizată pe scară largă de mulți specialiști, dar care este prezentă mai ales în magazinele online, unde meniurile de navigare distorsionează semnificativ structura site-ului.
În majoritatea magazinelor, avem un meniu derulant static (vizibil în sursa paginii), care oferă, de exemplu, patru link-uri către categoriile principale și 25 de link-uri ascunse către subcategorii. În timpul cartografierii structurii unei pagini, GB vede toate legăturile (pe fiecare pagină cu meniu), ceea ce face ca toate paginile să aibă aceeași importanță în timpul cartografierii, iar puterea (juice) lor să fie distribuită în mod egal, ceea ce arată aproximativ așa:
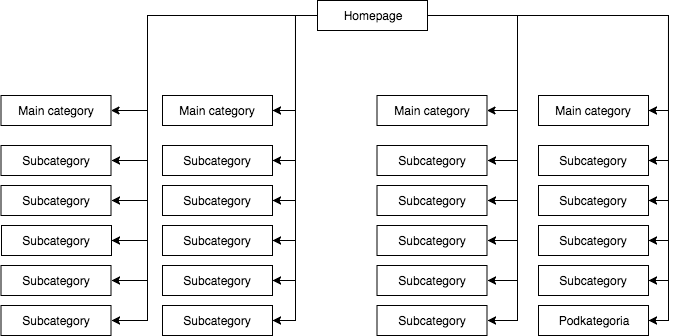
Cea mai frecventă, dar, în opinia mea, cea mai greșită structură a paginii.
Exemplul de mai sus nu poate fi numit o structură corectă, deoarece toate categoriile sunt legate de toate site-urile unde există un meniu. Prin urmare, atât pagina principală, cât și toate categoriile și subcategoriile au un număr egal de legături de intrare, iar puterea întregului serviciu web curge prin ele cu aceeași forță. Prin urmare, puterea paginii de pornire (care este, de obicei, sursa celei mai mari părți a puterii datorită numărului de linkuri primite) este împărțită în 24 de categorii și subcategorii, astfel încât fiecare dintre ele primește doar 4 % din puterea paginii de pornire.
Cum ar trebui să arate structura:

Dacă aveți nevoie să testați rapid structura paginii dvs. și să o parcurgeți așa cum o face Google, Screaming Frog este un instrument util.
În acest exemplu, puterea paginii de start este împărțită în patru, iar fiecare dintre categorii primește 25 la sută din puterea paginii de start și distribuie o parte din ea către subcategorii. Această soluție oferă, de asemenea, o șansă mai bună de realizare a legăturilor interne. De exemplu, atunci când scrieți un articol pe blogul magazinului și doriți să creați un link către una dintre subcategorii, GB va observa link-ul în timpul parcurgerii site-ului. În primul caz, nu o va face din cauza regulii First Link Counts. Dacă link-ul către o subcategorie era în meniul site-ului, atunci cel din articol va fi ignorat.
Am început acest experiment SEO cu următoarele acțiuni:
- Primul, pe pagina1.html, am inclus o legătură către o subpagină pagina2.html ca o legătură dofollow clasică cu o ancoră: anchor1.
- În continuare, în textul de pe aceeași pagină, am inclus referințe ușor modificate pentru a verifica dacă GB va fi dornic să le crawleze.
În acest scop, am testat următoarele soluții:
- Pentru pagina de start a serviciului web, am atribuit o singură legătură externă dofollow pentru o frază cu o ancoră URL (astfel încât orice legătură externă a paginii de start și a subpaginilor pentru frazele date era exclusă) – aceasta a accelerat indexarea serviciului.
- Am așteptat ca pagina2.html să înceapă să se claseze pentru o frază de la prima legătură dofollow (anchor1) venită de la pagina1.html. Această frază falsă, sau oricare alta pe care am testat-o, nu a putut fi găsită pe pagina țintă. Am presupus că, dacă și alte linkuri ar funcționa, atunci pagina2.html s-ar clasa în rezultatele căutării și pentru alte fraze provenite din alte linkuri. A durat în jur de 45 de zile. Și atunci am reușit să fac prima concluzie importantă.
Chiar și un site web, unde un cuvânt cheie nu se află nici în conținut, nici în metatitlu, dar este legat cu o ancoră cercetată, poate cu ușurință să se claseze în rezultatele de căutare mai sus decât un site web care conține acest cuvânt, dar nu este legat de un cuvânt cheie.
În plus, pagina de start (pagina1.html), care conținea fraza cercetată, era cea mai puternică pagină din serviciul web (legată de 78% din subpagini) și, cu toate acestea, s-a clasat mai jos la fraza cercetată decât subpagina (pagina2.html) legată de fraza cercetată.
Mai jos, prezint patru tipuri de legături pe care le-am testat, toate venind după prima legătură dofollow care duce la pagina2.html.
Link către un site web cu o ancoră
< a href=”page2.html#testhash” >anchor2< /a >
Prima dintre legăturile suplimentare care vine în codul din spatele linkului dofollow a fost un link cu o ancoră (un hashtag). Am vrut să văd dacă GB va trece prin această legătură și va indexa și pagina2.html sub sintagma anchor2, în ciuda faptului că legătura duce la acea pagină (pagina2.html), dar URL-ul fiind schimbat în pagina2.html#testhash folosește anchor2.
Din păcate, GB nu a vrut să-și amintească niciodată de această legătură și nu a direcționat puterea către subpagina pagina2.html pentru acea sintagmă. Ca urmare, în rezultatele căutării pentru sintagma anchor2 în ziua scrierii acestui articol, există doar subpagina page1.html, unde se găsește cuvântul în ancora link-ului. În timpul căutării pe Google a frazei testhash, nici domeniul nostru nu se află în clasament.
Link către un site web cu un parametru
page2.html?parameter=1
Inițial, GB a fost interesat de această parte amuzantă a URL-ului imediat după semnul de interogare și de ancora din interiorul linkului anchor3.
Intrigat, GB a încercat să își dea seama la ce mă refer. S-a gândit: „Este o ghicitoare?”. Pentru a evita indexarea conținutului duplicat de sub celelalte URL-uri, pagina canonică page2.html era îndreptată spre ea însăși. În total, jurnalele au înregistrat 8 crawlere pe această adresă, dar concluziile au fost mai degrabă triste:
- După 2 săptămâni, frecvența vizitelor lui GB a scăzut semnificativ, până când, în cele din urmă, a plecat și nu a mai crawlat niciodată acel link.
- Pagina2.html nu a fost indexată sub fraza anchor3, și nici parametrul cu URL-ul parameter1. Conform Search Console, această legătură nu există (nu este contabilizată printre legăturile primite), dar, în același timp, fraza anchor3 este listată ca frază ancorată.
Legătură către un site web dintr-o redirecționare
Am vrut să forțez GB să-mi crawleze mai mult site-ul web, ceea ce a dus la faptul că GB, la fiecare câteva zile, introducea legătura dofollow cu ancoră anchor4 pe pagina1.html care duce la pagina3.html, care se redirecționează cu un cod 301 către pagina2.html. Din nefericire, ca și în cazul paginii cu parametru, după 45 de zile pagina2.html nu era încă poziționată în rezultatele de căutare pentru fraza anchor4 care apărea în link-ul redirecționat pe pagina1.html.
Cu toate acestea, în Google Search Console, în secțiunea Anchor Texts, anchor4 este vizibilă și indexată. Acest lucru ar putea indica faptul că, după o perioadă de timp, redirecționarea va începe să funcționeze conform așteptărilor, astfel încât pagina2.html se va clasa în rezultatele căutării pentru anchor4, în ciuda faptului că este a doua legătură către aceeași pagină țintă din cadrul aceluiași site web.
Legătură către o pagină folosind eticheta canonică
Pe pagina1.html, am plasat o referință la pagina5.html (follow link) cu o ancoră anchor5. În același timp, pe pagina5.html a existat un conținut unic, iar în capul acestuia a fost plasată o etichetă canonică către pagina2.html.
< link rel=”canonical” href=”https://example.com/page2.html” />
Acest test a dat următoarele rezultate:
- Linkul pentru fraza anchor5 care direcționează către pagina5.html redirecționează canonic către pagina2.html nu a fost transferată către pagina țintă (la fel ca în celelalte cazuri).
- pagina5.html a fost indexată în ciuda tag-ului canonic.
- pagina5.html nu s-a clasat în rezultatele căutării pentru anchor5.
- pagina5.html s-a clasat în funcție de frazele folosite în textul paginii, ceea ce indică faptul că GB a ignorat în totalitate etichetele canonice.
Am îndrăzni să afirm că utilizarea rel=canonical pentru a împiedica indexarea unui anumit conținut (de exemplu, în timpul filtrării) pur și simplu nu ar putea funcționa.
Partea 2: Bugetul de crawlare
În timp ce concepeam o strategie SEO, am vrut să îl fac pe GB să danseze pe melodia mea și nu invers. În acest scop, am verificat procesele SEO la nivelul logurilor serverului (loguri de acces și loguri de erori), ceea ce mi-a oferit un avantaj uriaș. Datorită acestui fapt, cunoșteam fiecare mișcare a lui GB și modul în care acesta reacționa la schimbările pe care le introduceam (restructurarea site-ului web, răsturnarea sistemului de linkuri interne, modul de afișare a informațiilor) în cadrul campaniei SEO.
Una dintre sarcinile mele în timpul campaniei SEO a fost să reconstruiesc un site web în așa fel încât GB să viziteze doar acele URL-uri pe care ar putea să le indexeze și pe care noi doream să le indexeze. Pe scurt: în indexul Google ar trebui să existe doar paginile care sunt importante pentru noi din punct de vedere SEO. Pe de altă parte, GB ar trebui să crawleze doar site-urile pe care dorim să fie indexate de Google, ceea ce nu este evident pentru toată lumea, de exemplu, atunci când un magazin online implementează filtrarea după culori, mărimi și prețuri, iar acest lucru se face prin manipularea parametrilor URL, de ex.:
exemplu.com/femeile/încălțăminte/?color=red&size=40&price=200-250
Se poate dovedi că o soluție care îi permite lui GB să parcurgă URL-uri dinamice face ca acesta să dedice timp pentru a le parcurge (și eventual indexa) în loc să parcurgă pagina.
example.com/women/shoes/
Aceste URL-uri create dinamic nu sunt doar inutile, ci și potențial dăunătoare pentru SEO, deoarece pot fi confundate cu un conținut subțire, ceea ce va duce la scăderea clasamentului site-ului.
În cadrul acestui experiment am vrut să verific și câteva metode de structurare fără a folosi rel=”nofollow”, blocarea GB în fișierul robots.txt sau plasarea unei părți din codul HTML în cadre invizibile pentru bot (iframe blocat).
Am testat trei tipuri de link-uri JavaScript.
Legătură JavaScript cu un eveniment onclick
Un simplu link construit pe JavaScript
< a href=”javascript:void(0)” onclick=”window.location.href =’page4.html'” >anchor6< /a >
GB a trecut cu ușurință la subpagina page4.html și a indexat întreaga pagină. Subpagina nu se clasează în rezultatele căutării pentru fraza anchor6, iar această frază nu poate fi găsită în secțiunea Anchor Texts din Google Search Console. Concluzia este că linkul nu a transferat juice.
Pentru a rezuma:
- Un link clasic JavaScript permite Google să parcurgă site-ul web și să indexeze paginile pe care le întâlnește.
- Nu transferă juice – este neutru.
Legătură JavaScript cu o funcție internă
Am decis să ridic jocul, dar, spre surprinderea mea, GB a depășit obstacolul în mai puțin de 2 ore de la publicarea linkului.
< a href=”javascript:void(0)” class=”js-link” data-url=”page9.html” >anchor7< /a >
Pentru a opera acest link, am folosit o funcție externă, care avea ca scop citirea URL-ului din date și redirecționarea – doar redirecționarea unui utilizator, așa cum speram eu – către pagina țintă page9.html. Ca și în cazul anterior, pagina9.html fusese complet indexată.
Ceea ce este interesant este că, în ciuda lipsei altor linkuri de intrare, pagina9.html a fost a treia cea mai frecvent vizitată pagină de către GB din întregul serviciu web, imediat după pagina1.html și pagina2.html.
Am mai folosit această metodă pentru structurarea serviciilor web. Cu toate acestea, după cum putem vedea, nu mai funcționează. În SEO nimic nu trăiește veșnic, în afară de Pagini Aurii.
Legătura JavaScript cu codarea
Cu toate acestea, nu am vrut să renunț și am decis că trebuie să existe o modalitate de a închide efectiv ușa în nasul lui GB. Așadar, am construit o funcție simplă, codificând datele cu un algoritm base64, iar referința arăta astfel:
< a href=”javascript:void(0)” class=”js-link” data-url=”cGFnZTEwLmh0bWw=” >anchor8< /a >
Ca urmare, GB a fost incapabil să producă un cod JavaScript care să decodifice atât conținutul unui atribut data-URL, cât și să redirecționeze. Și iată că a fost! Avem o modalitate de a structura un serviciu web fără să folosim rel=nonfollows pentru a împiedica roboții să crawleze pe unde vor ei! În acest fel, nu ne irosim bugetul de crawl-budget, ceea ce este deosebit de important în cazul serviciilor web mari, iar GB dansează în cele din urmă pe melodia noastră. Indiferent dacă funcția a fost introdusă pe aceeași pagină în secțiunea head sau într-un fișier JS extern, nu există nicio dovadă a unui bot nici în jurnalele serverului, nici în Search Console.
Partea 3: Conținutul ascuns
În testul final, am vrut să verific dacă conținutul din, de exemplu, filele ascunse ar fi luat în considerare și indexat de GB sau dacă Google a redat o astfel de pagină și a ignorat textul ascuns, așa cum au susținut unii specialiști.
Am vrut să confirm sau să resping această afirmație. Pentru a face acest lucru, am plasat un zid de text cu peste 2000 de semne pe pagina12.html și am ascuns un bloc de text cu aproximativ 20 la sută din text (400 de semne) în Cascading Style Sheets și am adăugat butonul show more. În cadrul textului ascuns a existat un link către pagina13.html cu o ancoră anchor9.
Nu există nicio îndoială că un robot poate reda o pagină. Putem observa acest lucru atât în Google Search Console, cât și în Google Insight Speed. Cu toate acestea, testele mele au arătat că un bloc de text afișat după ce am făcut clic pe butonul „Show more” a fost complet indexat. Frazele ascunse în text se clasau în rezultatele căutării, iar GB urmărea linkurile ascunse în text. Mai mult, ancorele linkurilor dintr-un bloc de text ascuns erau vizibile în Google Search Console în secțiunea Anchor Text, iar pagina13.html a început, de asemenea, să se claseze în rezultatele căutării pentru cuvântul cheie anchor9.
Acest lucru este crucial pentru magazinele online, unde conținutul este adesea plasat în file ascunse. Acum suntem siguri că GB vede conținutul din filele ascunse, le indexează și transferă juice-ul din link-urile care sunt ascunse acolo.
Cea mai importantă concluzie pe care o trag din acest experiment este că nu am găsit o modalitate directă de a ocoli regula First Link Counts Rule prin utilizarea link-urilor modificate (link-uri cu parametru, redirecționări 301, canonice, link-uri ancoră). În același timp, este posibil să construim structura unui site web folosind link-uri Javascript, datorită cărora suntem liberi de restricțiile Regulei First Link Counts. Mai mult decât atât, Google Bot poate vedea și indexa conținutul ascuns în bookmark-uri și urmărește link-urile ascunse în acestea.
Înscrieți-vă pentru a primi recenziile noastre zilnice despre peisajul în continuă schimbare al marketingului de căutare.
Nota: Prin trimiterea acestui formular, sunteți de acord cu termenii Third Door Media. Vă respectăm intimitatea.
Despre autor

„Nu acceptați „doar” o calitate înaltă. Oricine poate face asta. Dacă cerul este limita, găsiți un cer mai înalt.” Max Cyrek este CEO al Cyrek Digital, consultant în marketing digital și evanghelist SEO. De-a lungul carierei sale, Max, împreună cu echipa sa de peste 30 de persoane, a lucrat cu sute de companii pe care le-a ajutat să aibă succes. Lucrează în marketingul digital de aproape zece ani și s-a specializat în SEO tehnic, gestionând proiecte de marketing de succes.
.
Lasă un răspuns