Oamenii creează, partajează și stochează date într-un ritm mai rapid decât în orice alt moment din istorie. Când vine vorba de inovarea în ceea ce privește stocarea și transmiterea acestor date, la Facebook facem progrese nu numai în domeniul hardware – cum ar fi hard disk-uri mai mari și echipamente de rețea mai rapide – ci și în domeniul software. Software-ul ajută la procesarea datelor prin compresie, care codifică informațiile, cum ar fi textul, imaginile și alte forme de date digitale, folosind mai puțini biți decât originalul. Aceste fișiere mai mici ocupă mai puțin spațiu pe hard disk-uri și sunt transmise mai rapid către alte sisteme. Totuși, comprimarea și decomprimarea informațiilor are un compromis: timpul. Cu cât se petrece mai mult timp pentru a comprima într-un fișier mai mic, cu atât datele sunt mai greu de procesat.
Astăzi, standardul de compresie a datelor care domnește este Deflate, algoritmul de bază din Zip, gzip și zlib . Timp de două decenii, acesta a oferit un echilibru impresionant între viteză și spațiu și, ca urmare, este folosit în aproape toate dispozitivele electronice moderne (și, nu întâmplător, este folosit pentru a transmite fiecare octet din chiar articolul de blog pe care îl citiți). De-a lungul anilor, alți algoritmi au oferit fie o compresie mai bună, fie o compresie mai rapidă, dar rareori ambele. Noi credem că am schimbat acest lucru.
Suntem încântați să anunțăm Zstandard 1.0, un nou algoritm de compresie și o nouă implementare concepută pentru a se adapta la hardware-ul modern și pentru a comprima mai mic și mai rapid. Zstandard combină descoperirile recente în materie de compresie, cum ar fi Finite State Entropy, cu un design axat pe performanță – și apoi optimizează implementarea pentru proprietățile unice ale procesoarelor moderne. Ca urmare, îmbunătățește compromisurile făcute de alți algoritmi de compresie și are o gamă largă de aplicabilitate cu o viteză de decomprimare foarte mare. Zstandard, disponibil acum sub licența BSD, este conceput pentru a fi utilizat în aproape orice scenariu de compresie fără pierderi, inclusiv în multe cazuri în care algoritmii actuali nu sunt aplicabili.
- Compararea compresiei
- Scalabilitate
- Sub capotă
- Memorie
- Un format conceput pentru execuție paralelă
- Proiectare fără ramificații
- Finite State Entropy: Un compresor de probabilitate de ultimă generație
- Modelarea prin coduri de răspuns
- Zstandard în practică
- Date mici
- Dicționare în acțiune
- Scoaterea unui nivel de compresie
- Încercați-l
- Mai mult va urma
Compararea compresiei
Există trei metrici standard pentru compararea algoritmilor și implementărilor de compresie:
- Rata de compresie: Dimensiunea originală (numitorul) comparată cu dimensiunea comprimată (numitorul), măsurată în date fără unități ca un raport de dimensiune de 1,0 sau mai mare.
- Viteza de comprimare: Cât de repede putem face datele mai mici, măsurată în MB/s de date de intrare consumate.
- Viteza de decomprimare: Cât de repede putem reconstrui datele originale din datele comprimate, măsurată în MB/s pentru rata de producere a datelor din datele comprimate.
Tipul de date care sunt comprimate poate afecta acești parametri, astfel încât mulți algoritmi sunt reglați pentru anumite tipuri de date, cum ar fi textul în limba engleză, secvențe genetice sau imagini rasterizate. Cu toate acestea, Zstandard, ca și zlib, este destinat compresiei de uz general pentru o varietate de tipuri de date. Pentru a reprezenta algoritmii la care se așteaptă să lucreze Zstandard, în această postare vom folosi Corpusul Silesia, un set de fișiere care reprezintă tipurile de date tipice utilizate zilnic.
Câțiva algoritmi și implementări utilizate în mod obișnuit astăzi sunt zlib, lz4 și xz. Fiecare dintre acești algoritmi oferă compromisuri diferite: lz4 urmărește viteza, xz urmărește ratele de compresie mai mari, iar zlib urmărește un bun echilibru între viteză și dimensiune. Tabelul de mai jos indică compromisurile aproximative ale raportului de compresie implicit al algoritmilor și viteza pentru Corpusul Silesia prin compararea algoritmilor cu lzbench, un benchmark pur în memorie menit să modeleze performanța brută a algoritmilor.
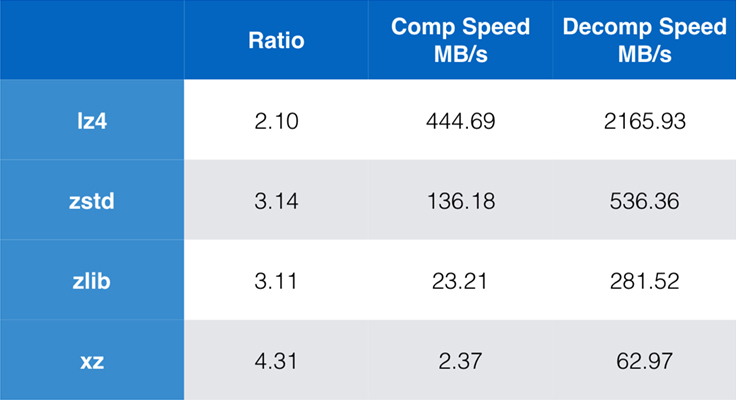
După cum s-a subliniat, există adesea compromisuri drastice între viteză și dimensiune. Cel mai rapid algoritm, lz4, are ca rezultat rapoarte de compresie mai mici; xz, care are cel mai mare raport de compresie, suferă de o viteză de compresie lentă. Cu toate acestea, Zstandard, la setarea implicită, prezintă îmbunătățiri substanțiale atât în ceea ce privește viteza de compresie, cât și în ceea ce privește viteza de decompresie, în timp ce comprimă la același raport ca și zlib.
În timp ce performanța algoritmului pur este importantă atunci când compresia este încorporată într-o aplicație mai mare, este extrem de obișnuit să se utilizeze, de asemenea, instrumente de linie de comandă pentru compresie – de exemplu, pentru comprimarea fișierelor jurnal, a pachetelor tar sau a altor date similare destinate stocării sau transferului. În aceste cazuri, performanța este deseori afectată de costuri suplimentare, cum ar fi checksumming-ul. Acest grafic arată comparația dintre instrumentele de linie de comandă gzip și zstd pe Centos 7 construit cu compilatorul implicit al sistemului.
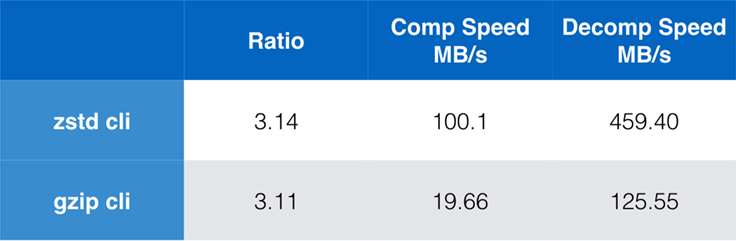
Testele au fost efectuate fiecare de 10 ori, cu timpii minimi luați, și au fost efectuate pe ramdisk pentru a evita supraîncărcarea sistemului de fișiere. Acestea au fost comenzile (care utilizează nivelurile de compresie implicite pentru ambele instrumente):
zstd -c -3 silesia.tar > silesia.tar.zst # 67,432,740 byteszstd -d -c silesia.tar.zst > /dev/nullgzip -c -6 silesia.tar > silesia.tar.gz # 68,235,522 bytesgzip -d -c silesia.tar.gz > /dev/nullScalabilitate
Dacă un algoritm este scalabil, acesta are capacitatea de a se adapta la o mare varietate de cerințe, iar Zstandard este conceput pentru a excela în peisajul actual și pentru a se adapta în viitor. Majoritatea algoritmilor au „niveluri” bazate pe compromisuri de timp/spațiu: Cu cât nivelul este mai mare, cu atât mai mare este compresia obținută cu o pierdere de viteză de compresie. Zlib oferă nouă niveluri de compresie; Zstandard oferă în prezent 22, ceea ce permite realizarea de compromisuri flexibile și granulare între viteza de compresie și ratele pentru datele viitoare. De exemplu, putem utiliza nivelul 1 dacă viteza este cea mai importantă și nivelul 22 dacă dimensiunea este cea mai importantă.
Mai jos este un grafic cu viteza și raportul de compresie obținute pentru toate nivelurile Zstandard și zlib. Axa x este o scară logaritmică descrescătoare în megabytes pe secundă; axa y este raportul de compresie obținut. Pentru a compara algoritmii, puteți alege o viteză pentru a vedea diferitele rapoarte pe care algoritmii le realizează la viteza respectivă. De asemenea, puteți alege un raport și să vedeți cât de rapizi sunt algoritmii atunci când ating acel nivel.
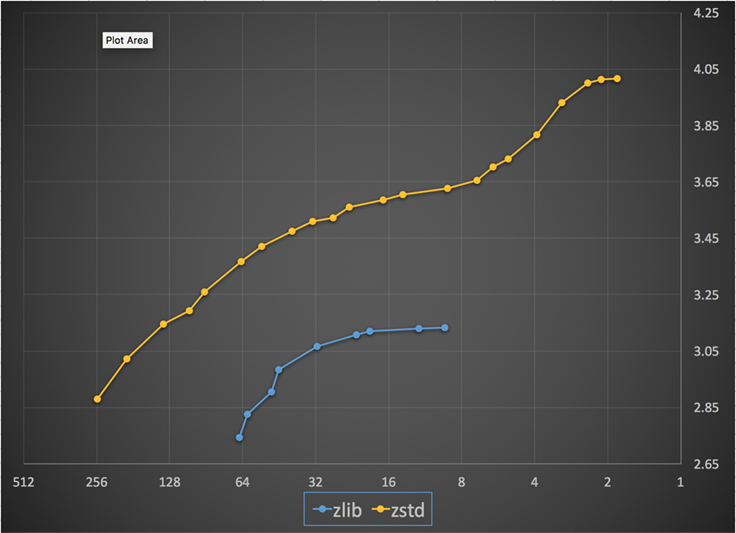
Pentru orice linie verticală (adică viteza de compresie), Zstandard obține un raport de compresie mai mare. Pentru corpus-ul Silesia, viteza de decomprimare – indiferent de raport – a fost de aproximativ 550 MB/s pentru Zstandard și 270 MB/s pentru zlib. Graficul arată o altă diferență între Zstandard și alternative: Prin utilizarea unui singur algoritm și a unei singure implementări, Zstandard permite o reglare mult mai fină pentru fiecare caz de utilizare. Acest lucru înseamnă că Zstandard poate concura cu unii dintre cei mai rapizi și mai mari algoritmi de compresie, menținând în același timp un avantaj substanțial în ceea ce privește viteza de decompresie. Aceste îmbunătățiri se traduc direct în transferuri de date mai rapide și cerințe de stocare mai mici.
Cu alte cuvinte, în comparație cu zlib, Zstandard se scalează:
- La același raport de compresie, comprimă substanțial mai repede: ~3-5x.
- La aceeași viteză de compresie, este substanțial mai mic: 10-15 procente mai mic.
- Este aproape de 2 ori mai rapid la decompresie, indiferent de raportul de compresie; cifrele de instrumente de linie de comandă arată o diferență și mai mare: mai mult de 3 ori mai rapid.
- Se scalează la rapoarte de compresie mult mai mari, menținând în același timp viteze de decompresie fulgerătoare.
Sub capotă
Zstandard îmbunătățește zlib prin combinarea mai multor inovații recente și vizând hardware-ul modern:
Memorie
Prin proiectare, zlib este limitat la o fereastră de 32 KB, ceea ce a fost o alegere sensibilă la începutul anilor ’90. Dar, mediul informatic de astăzi poate accesa mult mai multă memorie – chiar și în mediile mobile și încorporate.
Zstandard nu are o limită inerentă și poate adresa terabytes de memorie (deși o face rareori). De exemplu, cele mai mici dintre cele 22 de niveluri utilizează 1 MB sau mai puțin. Pentru compatibilitatea cu o gamă largă de sisteme de recepție, unde memoria poate fi limitată, se recomandă limitarea utilizării memoriei la 8 MB. Totuși, aceasta este o recomandare de reglare, nu o limitare a formatului de compresie.
Un format conceput pentru execuție paralelă
Unițele centrale de astăzi sunt foarte puternice și pot emite mai multe instrucțiuni pe ciclu, datorită multiplelor ALU (unități logice aritmetice) și designului din ce în ce mai avansat de execuție în afara ordinii.
În esență, înseamnă că dacă:
a = b1 + b2
c = d1 + d2
atunci atât a cât și c vor fi calculate în paralel.
Acest lucru este posibil numai dacă nu există nicio relație între ele. Prin urmare, în acest exemplu:
a = b1 + b2
c = d1 + a
c trebuie să aștepte ca a să fie calculat mai întâi, și numai după aceea va începe calculul lui c.
Înseamnă că, pentru a profita de CPU-ul modern, trebuie proiectat un flux de operații cu puține sau nici o dependență de date.
Acest lucru se realizează cu Zstandard prin separarea datelor în mai multe fluxuri paralele. Un decodor Huffman de nouă generație, Huff0, este capabil să decodifice mai multe simboluri în paralel cu un singur nucleu. Un astfel de câștig este cumulativ cu multi-threading, care utilizează mai multe nuclee.
Proiectare fără ramificații
Noi procesoare sunt mai puternice și ating frecvențe foarte ridicate, dar acest lucru este posibil numai datorită unei abordări în mai multe etape, în care o instrucțiune este împărțită într-un pipeline cu mai multe etape. La fiecare ciclu de ceas, procesorul este capabil să emită rezultatul mai multor operații, în funcție de ALU-urile disponibile. Cu cât sunt utilizate mai multe ALU-uri, cu atât mai multă muncă depune CPU-ul și, prin urmare, cu atât mai repede are loc compresia. Menținerea ALU-urilor alimentate cu muncă este crucială pentru performanța CPU-urilor moderne.
Acest lucru se dovedește a fi dificil. Luați în considerare următoarea situație simplă:
if (condition) doSomething() else doSomethingElse()Când întâlnește această situație, CPU nu știe ce să facă, deoarece depinde de valoarea lui condition. Un CPU precaut ar aștepta rezultatul lui condition înainte de a lucra la oricare dintre ramuri, ceea ce ar fi extrem de risipitor.
CPU-urile de astăzi pariază. Ele o fac în mod inteligent, datorită unui predictor de ramură, care le spune în esență rezultatul cel mai probabil al evaluării lui condition. Atunci când pariul este corect, pipeline-ul rămâne plin și instrucțiunile sunt emise continuu. Când pariul este greșit (o predicție greșită), CPU trebuie să oprească toate operațiile începute speculativ, să se întoarcă la ramură și să o ia în cealaltă direcție. Acest lucru se numește „pipeline flush” și este extrem de costisitor în procesoarele moderne.
Cu 25 de ani în urmă, pipeline flush-ul era o non-problemă. Astăzi, este atât de importantă încât este esențial să se proiecteze formate compatibile cu algoritmii branchless. Ca exemplu, să ne uităm la o actualizare a fluxului de biți:
/* classic version */while (nbBitsUsed >= 8) { /* each while test is a branch */ accumulator <<= 8; accumulator += *byte++; nbBitsUsed -= 8;} /*>/* branch-less version */nbBytesUsed = nbBitsUsed >> 3;nbBitsUsed &= 7;ptr += nbBytesUsed;accumulator = read64(ptr); După cum puteți vedea, versiunea branchless are o sarcină de lucru previzibilă, fără nicio condiție. Unitatea centrală de procesare va face întotdeauna aceeași muncă, iar această muncă nu este niciodată aruncată la gunoi din cauza unei previziuni greșite. În schimb, versiunea clasică face mai puțină muncă atunci când (nbBitsUsed < 8). Dar testul în sine nu este gratuit și, ori de câte ori testul este ghicit incorect, are ca rezultat o spălare completă a pipeline-ului, care costă mai mult decât munca efectuată de versiunea branchless.
După cum puteți ghici, acest efect secundar are impact asupra modului în care datele sunt împachetate, citite și decodate. Zstandard a fost creat pentru a fi prietenos cu algoritmii branchless, în special în cadrul buclelor critice.
Finite State Entropy: Un compresor de probabilitate de ultimă generație
În compresie, datele sunt mai întâi transformate într-un set de simboluri (etapa de modelare), iar apoi aceste simboluri sunt codificate folosind un număr minim de biți. Această a doua etapă se numește etapa de entropie, în memoria lui Claude Shannon, care calculează cu exactitate limita de compresie a unui set de simboluri cu probabilități date (numită „limita Shannon”). Scopul este de a se apropia de această limită în timp ce se utilizează cât mai puține resurse CPU.
Un algoritm foarte comun este codificarea Huffman, utilizat în cadrul Deflate. Acesta oferă cel mai bun cod prefix posibil, presupunând că fiecare simbol este descris cu un număr natural de biți (1 bit, 2 biți …). Acest lucru funcționează foarte bine în practică, dar limita numerelor naturale înseamnă că este imposibil să se ajungă la rapoarte de compresie ridicate, deoarece un simbol consumă în mod necesar cel puțin 1 bit.
O metodă mai bună se numește codificare aritmetică, care se poate apropia în mod arbitrar de limita Shannon -log2(P), consumând astfel biți fracționari pe simbol. Aceasta se traduce printr-un raport de compresie mai bun atunci când probabilitățile sunt mari, dar consumă, de asemenea, mai multă putere CPU. În practică, chiar și codificatorii aritmetici optimizați se luptă pentru viteză, în special pe partea de decompresie, care necesită diviziuni cu un rezultat previzibil (de exemplu, nu în virgulă mobilă) și care se dovedește a fi lent.
Finite State Entropy se bazează pe o nouă teorie numită ANS (Asymmetric Numeral System) de Jarek Duda. Finite State Entropy este o variantă care precalculează mulți pași de codificare în tabele, rezultând un codec de entropie la fel de precis ca și codificarea aritmetică, folosind doar adunări, căutări în tabele și deplasări, ceea ce reprezintă aproximativ același nivel de complexitate ca și Huffman. De asemenea, reduce latența de accesare a simbolului următor, deoarece acesta este accesibil imediat din valoarea de stare, în timp ce Huffman necesită o operațiune prealabilă de decodare a fluxului de biți. Explicarea modului în care funcționează nu intră în sfera de aplicare a acestei postări, dar, dacă sunteți interesat, există o serie de articole care detaliază funcționarea sa internă.
Modelarea prin coduri de răspuns
Modelarea prin coduri de răspuns comprimă eficient datele structurate, care prezintă secvențe de conținut aproape echivalent, care diferă doar prin unul sau câțiva octeți. Această metodă nu este nouă, dar a fost folosită pentru prima dată după publicarea Deflate, deci nu există în cadrul zlib/gzip.
Eficiența modelării repcode depinde foarte mult de tipul de date care se comprimă, variind de la o îmbunătățire a compresiei cu o singură cifră până la două cifre. Aceste îmbunătățiri combinate se adaugă la o experiență de compresie mai bună și mai rapidă, oferită în cadrul bibliotecii Zstandard.
Zstandard în practică
După cum am menționat anterior, există mai multe cazuri tipice de utilizare a compresiei. Pentru ca un algoritm să fie convingător, acesta trebuie fie să fie extraordinar de bun într-un caz de utilizare specific, cum ar fi comprimarea textului lizibil pentru oameni, fie foarte bun în mai multe cazuri de utilizare diverse. Zstandard adoptă cea din urmă abordare. Un mod de a ne gândi la cazurile de utilizare este de câte ori poate fi decomprimată o anumită bucată de date. Zstandard are avantaje în toate aceste cazuri.
Multe ori. Pentru datele procesate de multe ori, viteza de decomprimare și capacitatea de a opta pentru un raport de compresie foarte mare fără a compromite viteza de decomprimare este avantajoasă. Stocarea graficului social de pe Facebook, de exemplu, este citită în mod repetat pe măsură ce dvs. și prietenii dvs. interacționați cu site-ul. În afara Facebook, exemple de cazuri în care datele trebuie decomprimate de mai multe ori includ fișiere descărcate de pe un server, cum ar fi codul sursă al kernelului Linux sau RPM-urile instalate pe servere, JavaScript și CSS utilizate de o pagină web sau rularea a mii de MapReduces peste datele dintr-un depozit de date.
Doar o dată. Pentru datele comprimate doar o singură dată, în special pentru transmiterea într-o rețea, compresia este un moment trecător în fluxul de date. Cu cât este mai puțin încărcat pe server, înseamnă că acesta poate gestiona mai multe cereri pe secundă. Mai puțină suprasolicitare pentru client înseamnă că se poate acționa mai rapid asupra datelor. De obicei, acest lucru apare în situații client/server în care datele sunt unice pentru client, cum ar fi un răspuns personalizat al serverului web – de exemplu, datele utilizate pentru a reda atunci când primiți o notă de la un prieten pe Messenger. Rezultatul net este că dispozitivul dvs. mobil încarcă paginile mai repede, utilizează mai puțină baterie și consumă mai puțin din planul dvs. de date. Zstandard, în special, se potrivește scenariilor mobile mult mai bine decât alți algoritmi, datorită modului în care tratează datele mici.
Poate niciodată. Deși aparent contraintuitiv, se întâmplă adesea ca o bucată de date – cum ar fi copiile de rezervă sau fișierele jurnal – să nu fie niciodată decomprimată, dar să poată fi citită dacă este necesar. Pentru acest tip de date, compresia trebuie, de obicei, să fie rapidă, să facă datele mici (cu un compromis timp/spațiu adecvat situației) și, poate, să stocheze o sumă de control, dar, în rest, să fie invizibilă. În rarele ocazii în care este necesar să fie decomprimată, nu doriți ca comprimarea să încetinească cazul de utilizare operațională. Descompactarea rapidă este benefică pentru că deseori este vorba de o mică parte a datelor (cum ar fi un anumit fișier din copia de rezervă sau un mesaj dintr-un fișier jurnal) care trebuie găsit rapid.
În toate aceste cazuri, Zstandard aduce capacitatea de a comprima și decomprima de multe ori mai repede decât gzip, datele comprimate rezultate fiind mai mici.
Date mici
Există un alt caz de utilizare a compresiei care primește mai puțină atenție, dar care poate fi destul de important: datele mici. Acestea sunt modele de utilizare în care datele sunt produse și consumate în cantități mici, cum ar fi mesajele JSON între un server web și browser (de obicei sute de octeți) sau pagini de date într-o bază de date (câteva kiloocteți).
Bazele de date oferă un caz de utilizare interesant. Sisteme precum MySQL, PostgreSQL și MongoDB stochează toate datele destinate accesului în timp real. Avantajele hardware recente, în special în jurul proliferării dispozitivelor flash (SSD), au schimbat în mod fundamental echilibrul dintre dimensiune și debit – acum trăim într-o lume în care IOP-urile (operațiuni IO pe secundă) sunt destul de ridicate, dar capacitatea dispozitivelor noastre de stocare este mai mică decât era atunci când hard disk-urile dominau centrul de date.
În plus, flash-ul are o proprietate interesantă în ceea ce privește rezistența la scriere – după mii de scrieri în aceeași secțiune a dispozitivului, acea secțiune nu mai poate accepta scrieri, ceea ce duce adesea la scoaterea din uz a dispozitivului. Prin urmare, este firesc să se caute modalități de reducere a cantității de date care se scriu, deoarece aceasta poate însemna mai multe date pe server și arderea dispozitivului într-un ritm mai lent. Compresia datelor este o strategie în acest sens, iar bazele de date sunt, de asemenea, adesea optimizate pentru performanță, ceea ce înseamnă că performanța la citire și la scriere sunt la fel de importante.
Există însă o complicație pentru utilizarea compresiei de date cu bazele de date. Bazelor de date le place să acceseze datele în mod aleatoriu, în timp ce majoritatea cazurilor tipice de utilizare a compresiei citesc un întreg fișier în ordine liniară. Aceasta este o problemă deoarece compresia datelor funcționează, în esență, prin prezicerea viitorului pe baza trecutului – algoritmii se uită la datele dvs. în mod secvențial și prezic ce ar putea vedea în viitor. Cu cât predicțiile sunt mai precise, cu atât mai mici pot fi datele.
Când comprimați date mici, cum ar fi paginile dintr-o bază de date sau documente JSON minuscule care sunt trimise către dispozitivul dvs. mobil, pur și simplu nu există prea mult „trecut” pe care să îl folosiți pentru a prezice viitorul. Algoritmii de compresie au încercat să abordeze acest aspect prin utilizarea dicționarelor preîmpărtășite pentru a porni efectiv. Acest lucru se face prin preîmpărtășirea unui set static de date „trecute” ca sămânță pentru compresie.
Zstandard se bazează pe această abordare cu algoritmi și API-uri foarte optimizate pentru compresia dicționarelor. În plus, Zstandard include instrumente (zstd --train) pentru a realiza cu ușurință dicționare pentru aplicații personalizate și prevederi pentru înregistrarea dicționarelor standard pentru partajarea cu comunități mai mari. În timp ce compresia variază în funcție de eșantioanele de date, compresia datelor de mici dimensiuni poate fi de la 2x până la 5x mai bună decât compresia fără dicționare.
Dicționare în acțiune
În timp ce poate fi greu să te joci cu un dicționar în contextul unei baze de date care rulează (necesită modificări semnificative ale bazei de date, până la urmă), poți vedea dicționare în acțiune cu alte tipuri de date de mici dimensiuni. JSON, lingua franca a datelor mici în lumea modernă, tinde să fie înregistrări mici și repetitive. Există nenumărate seturi de date publice disponibile; în scopul acestei demonstrații, vom folosi setul de date „user” de pe GitHub, disponibil prin HTTP. Iată un exemplu de intrare din acest set de date:
{ "login": "octocat", "id": 1, "avatar_url": "https://github.com/images/error/octocat_happy.gif", "gravatar_id": "", "url": "https://api.github.com/users/octocat", "html_url": "https://github.com/octocat", "followers_url": "https://api.github.com/users/octocat/followers", "following_url": "https://api.github.com/users/octocat/following{/other_user}", "gists_url": "https://api.github.com/users/octocat/gists{/gist_id}", "starred_url": "https://api.github.com/users/octocat/starred{/owner}{/repo}", "subscriptions_url": "https://api.github.com/users/octocat/subscriptions", "organizations_url": "https://api.github.com/users/octocat/orgs", "repos_url": "https://api.github.com/users/octocat/repos", "events_url": "https://api.github.com/users/octocat/events{/privacy}", "received_events_url": "https://api.github.com/users/octocat/received_events", "type": "User", "site_admin": false } După cum puteți vedea, există destul de multe repetiții aici – le putem comprima frumos! Dar fiecare utilizator este puțin sub 1 KB, iar majoritatea algoritmilor de compresie chiar au nevoie de mai multe date pentru a-și întinde picioarele. Un set de 1.000 de utilizatori necesită aproximativ 850 KB pentru a fi stocat necomprimat. Aplicând în mod naiv fie gzip, fie zstd în mod individual la fiecare fișier, se reduce la puțin peste 300 KB; nu este rău! Dar dacă creăm un dicționar unic, pre-împărțit, cu zstd, dimensiunea scade la 122 KB – ducând raportul de compresie inițial de la 2,8x la 6,9. Aceasta este o îmbunătățire semnificativă, disponibilă out-of-box cu zstd:
$ zstd --train -o ../json.zdict -r .sorting 982 files of total size 0 MB ...finding patterns ...statistics ...Save dictionary of size 65599 into file ../json.zdict$ du -h --apparent-size .846K .$ zstd --rm -D ../json.zdict -r .$ du -h --apparent-size .122K .Scoaterea unui nivel de compresie
După cum s-a arătat mai sus, Zstandard oferă un număr substanțial de niveluri. Această personalizare este puternică, dar conduce la alegeri dificile. Cel mai bun mod de a decide este să vă revizuiți datele și să măsurați, hotărând ce compromisuri doriți să faceți. La Facebook, considerăm că nivelul implicit 3 este potrivit pentru multe cazuri de utilizare, dar, din când în când, îl vom ajusta ușor în funcție de care este gâtul nostru de îmbulzeală (de multe ori încercăm să saturăm o conexiune de rețea sau un fus de disc); alteori, ne pasă mai mult de dimensiunea stocată și vom folosi un nivel mai mare.
În cele din urmă, pentru a obține rezultatele cele mai adaptate nevoilor dumneavoastră, va trebui să luați în considerare atât hardware-ul pe care îl utilizați, cât și datele de care vă pasă – nu există prescripții ferme și rapide care pot fi făcute fără context. Totuși, atunci când aveți dubii, rămâneți fie la nivelul implicit de 3, fie la ceva din intervalul 6-9 pentru un compromis plăcut între viteză și spațiu; păstrați nivelul 20+ pentru cazurile în care vă interesează cu adevărat doar dimensiunea și nu viteza de compresie.
Încercați-l
Zstandard este atât un instrument în linie de comandă (zstd), cât și o bibliotecă. Este scris în C extrem de portabil, ceea ce îl face potrivit pentru practic toate platformele folosite astăzi – fie că este vorba de serverele pe care funcționează afacerea dvs., de laptopul dvs. sau chiar de telefonul din buzunar. Îl puteți lua din depozitul nostru github, îl puteți compila cu un simplu make install și puteți începe să îl folosiți așa cum ați folosi gzip:
$ zstd access.logaccess.log : 8.07% (6695078 => 540336 bytes, access.log.zst)Așa cum v-ați putea aștepta, îl puteți folosi ca parte a unui pipeline de comenzi, de exemplu, pentru a face o copie de rezervă a bazei de date critice MySQL:
$ mysqldump --single-transaction --opt pokemon | zstd -q -o /srv/backups/mysqldump.sql.zstComanda tar suportă diferite implementări de compresie out-of-box, astfel încât, odată ce ați instalat Zstandard, puteți lucra imediat cu tarball-uri comprimate cu Zstandard. Iată un exemplu simplu care o arată în utilizare cu tar și diferența de viteză în comparație cu gzip:
$ time tar -I zstd -cf linux-4.6.4.tar.zst linux-4.6.4tar -I zstd -cf linux-4.6.4.tar.zst linux-4.6.4 3.15s user 0.50s system 107% cpu 3.396 total$ time tar -zcf linux-4.6.4.tar.gz linux-4.6.4tar -zcf linux-4.6.4.tar.gz linux-4.6.4 13.74s user 0.43s system 102% cpu 13.784 totalÎn afară de utilizarea în linie de comandă, există API-urile, documentate în fișierele de antet din depozit (începeți aici pentru o prezentare generală a API-urilor). De asemenea, includem o API de înfășurare compatibilă cu zlib (libWrapper) pentru o integrare mai ușoară cu instrumentele care au deja interfețe zlib. În cele din urmă, includem o serie de exemple, atât de utilizare de bază, cât și de utilizare mai avansată, cum ar fi dicționarele și streamingul, de asemenea în depozitul GitHub.
Mai mult va urma
Chiar dacă am ajuns la 1.0 și considerăm că Zstandard este gata pentru orice tip de utilizare în producție, nu am terminat. Urmează în versiunile viitoare:
- Comprimare în linie de comandă cu mai multe fire, pentru un randament și mai rapid pe seturi mari de date, similar instrumentului pigz pentru zlib.
- Noi niveluri de compresie, în ambele direcții, care permit o compresie și mai rapidă și rapoarte mai mari.
- Un set de dicționare de compresie predefinite, întreținute de comunitate, pentru seturi de date comune, cum ar fi JSON, HTML și protocoale de rețea comune.
Am dori să mulțumim tuturor contributorilor, atât de cod cât și de feedback, care ne-au ajutat să ajungem la 1.0. Acesta este doar începutul. Știm că, pentru ca Zstandard să se ridice la înălțimea potențialului său, avem nevoie de ajutorul dumneavoastră. Așa cum am menționat mai sus, puteți încerca Zstandard astăzi prin preluarea sursei sau a binarelor pre-construite din proiectul nostru GitHub sau, pentru utilizatorii Mac, prin instalarea prin homebrew (brew install zstd). Ne-ar plăcea să primim orice feedback și cazuri de utilizare interesante pe care le aveți, precum și legături de limbaj suplimentare și ajutor pentru a-l integra cu proiectele open source preferate.
Note de subsol
- În timp ce compresia de date fără pierderi este punctul central al acestei postări, există un domeniu înrudit, dar foarte diferit, al compresiei de date cu pierderi, utilizat în principal pentru imagini, audio și video.
- Deflate, zlib, gzip – trei nume întrepătrunse. Deflate este algoritmul folosit de implementările zlib și gzip. Zlib este o bibliotecă care furnizează Deflate, iar gzip este un instrument de linie de comandă care folosește zlib pentru Deflating date, precum și pentru checksumming. Această însumare de control poate avea o suprasolicitare semnificativă.
- Toate testele de referință au fost efectuate pe un Intel E5-2678 v3 care rulează la 2,5 GHz pe o mașină Centos 7. Instrumentele de linie de comandă (
zstdșigzip) au fost construite cu sistemul GCC, 4.8.5. Testele de referință ale algoritmilor efectuate de lzbench au fost construite cu GCC 6.
.
Lasă un răspuns