În această postare, vom arunca o privire asupra celor mai utilizați algoritmi de învățare automată. Există o mare varietate a acestora și este ușor să vă simțiți confuzi atunci când auziți termeni precum „algoritmi de învățare pe bază de instanțe” și „perceptron”.
De obicei, toți algoritmii de învățare automată sunt împărțiți în grupuri bazate fie pe stilul lor de învățare, fie pe funcție, fie pe problemele pe care le rezolvă. În această postare, veți găsi o clasificare bazată pe stilul de învățare. De asemenea, voi menționa sarcinile comune pe care acești algoritmi ajută să le rezolve.
Numărul de algoritmi de învățare automată care sunt utilizați astăzi este mare și nu voi menționa 100% dintre ei. Cu toate acestea, aș dori să ofer o imagine de ansamblu a celor mai frecvent utilizați.
- Algoritmi de învățare supervizată
- Algoritmi de clasificare
- Naive Bayes
- Multinomial Naive Bayes
- Regresie logistică
- Arborii de decizie
- SVM (Support Vector Machine)
- Agoritmi de regresie
- Regresie liniară
- Agoritmi de învățare nesupravegheată
- Clustering
- K-means clustering
- K-nearest neighbor
- Reducerea dimensionalității
- Învățarea regulilor de asociere
- Învățarea prin întărire
- Q-Learning
- Învățarea prin asamblare
- Bagging
- Boosting
- Random forest
- Stacking
- Rețele neuronale
- Concluzie
Algoritmi de învățare supervizată

Dacă nu sunteți familiarizați cu termeni precum „învățare supervizată” și „învățare nesupravegheată”, consultați postul nostru AI vs. ML, unde acest subiect este abordat în detaliu. Acum, haideți să ne familiarizăm cu algoritmii.
Algoritmi de clasificare
Naive Bayes

Agoritmii Bayesieni sunt o familie de clasificatori probabilistici folosiți în ML pe baza aplicării teoremei lui Bayes.
Clasificatorul Bayes naiv a fost unul dintre primii algoritmi utilizați pentru învățarea automată. Este potrivit pentru clasificarea binară și multiclasă și permite realizarea de predicții și prognoze ale datelor pe baza rezultatelor istorice. Un exemplu clasic este reprezentat de sistemele de filtrare a spam-ului care au folosit Naive Bayes până în 2010 și au prezentat rezultate satisfăcătoare. Cu toate acestea, când a fost inventată otrăvirea Bayesiană, programatorii au început să se gândească la alte modalități de filtrare a datelor.
Utilizând teorema lui Bayes, este posibil să se spună cum apariția unui eveniment influențează probabilitatea unui alt eveniment.
De exemplu, acest algoritm calculează probabilitatea ca un anumit e-mail să fie sau să nu fie spam pe baza cuvintelor tipice folosite. Cuvintele comune de spam sunt „ofertă”, „comandă acum” sau „venit suplimentar”. Dacă algoritmul detectează aceste cuvinte, există o mare probabilitate ca e-mailul să fie spam.
Naive Bayes presupune că caracteristicile sunt independente. Prin urmare, algoritmul se numește naiv.
Multinomial Naive Bayes
În afară de clasificatorul Naive Bayes, există și alți algoritmi din acest grup. De exemplu, Multinomial Naive Bayes, care se aplică de obicei pentru clasificarea documentelor pe baza frecvenței anumitor cuvinte prezente în document.
Agoritmii Bayesieni sunt încă utilizați pentru clasificarea textelor și detectarea fraudelor. Ei pot fi, de asemenea, aplicați pentru viziune artificială (de exemplu, detectarea fețelor), segmentarea pieței și bioinformatică.
Regresie logistică
Chiar dacă numele poate părea contra-intuitiv, regresia logistică este de fapt un tip de algoritm de clasificare.
Regresia logistică este un model care face predicții folosind o funcție logistică pentru a găsi dependența dintre variabilele de ieșire și cele de intrare. Statquest a realizat un videoclip excelent în care explică diferența dintre regresia liniară și cea logistică luând ca exemplu șoarecii obezi.
Arborii de decizie
Un arbore de decizie este o modalitate simplă de a vizualiza un model decizional sub forma unui arbore. Avantajele arborilor decizionali constau în faptul că sunt ușor de înțeles, de interpretat și de vizualizat. De asemenea, ei necesită puțin efort pentru pregătirea datelor.
Cu toate acestea, ei au și un mare dezavantaj. Arborii pot fi instabili din cauza chiar și a celor mai mici variații (varianță) din date. De asemenea, este posibil să se creeze arbori prea complecși care nu generalizează bine. Acest lucru se numește supraadaptare. Bagging, boosting și regularizarea ajută la combaterea acestei probleme. Vom vorbi despre ele mai târziu în post.
Elementele fiecărui arbore de decizie sunt:
- Nodul rădăcină care pune întrebarea principală. Acesta are săgețile îndreptate în jos de la el, dar nu are săgeți îndreptate spre el. De exemplu, imaginați-vă că construiți un arbore pentru a decide ce fel de paste ar trebui să mâncați la cină.
- Noduri. O subsecțiune a unui arbore se numește ramură sau, uneori, subarbore.
- Noduri de decizie. Acestea sunt subnodurile pentru nodul rădăcină care pot fi, de asemenea, divizate în mai multe noduri. Nodurile de decizie pot fi „carbonara?” sau „cu ciuperci?”.
- Noduri de frunze sau noduri terminale. Aceste noduri nu se divizează. Ele reprezintă decizii sau predicții finale.
De asemenea, este important să menționăm divizarea. Acesta este procesul de divizare a unui nod în subnoduri. De exemplu, dacă nu ești vegetarian, carbonara este în regulă. Dar dacă sunteți, mâncați paste cu ciuperci. Există, de asemenea, un proces de eliminare a nodurilor numit pruning.
Argitmii de arbori de decizie sunt denumiți CART (Classification and Regression Trees). Arborii de decizie pot lucra cu date categorice sau numerice.
- Arborii de regresie sunt utilizați atunci când variabilele au valoare numerică.
- Arborii de clasificare pot fi aplicați atunci când datele sunt categorice (clase).
Arborii de decizie sunt destul de intuitivi pentru a fi înțeleși și utilizați. Acesta este motivul pentru care diagramele arborescente sunt aplicate în mod obișnuit într-o gamă largă de industrii și discipline. GreyAtom oferă o prezentare generală a diferitelor tipuri de arbori de decizie și a aplicațiilor practice ale acestora.
SVM (Support Vector Machine)
Mașinile vectoriale de suport sunt un alt grup de algoritmi utilizați pentru sarcini de clasificare și, uneori, de regresie. SVM este grozav pentru că oferă rezultate destul de precise cu o putere de calcul minimă.
Obiectivul SVM este de a găsi un hiperplan într-un spațiu N-dimensional (unde N corespunde cu numărul de caracteristici) care clasifică distinct punctele de date. Acuratețea rezultatelor este direct corelată cu hiperplanul pe care îl alegem. Ar trebui să găsim un plan care are distanța maximă între punctele de date din ambele clase.
Acest hiperplan este reprezentat grafic ca o linie care separă o clasă de alta. Punctele de date care se află pe părți diferite ale hiperplanului sunt atribuite unor clase diferite.
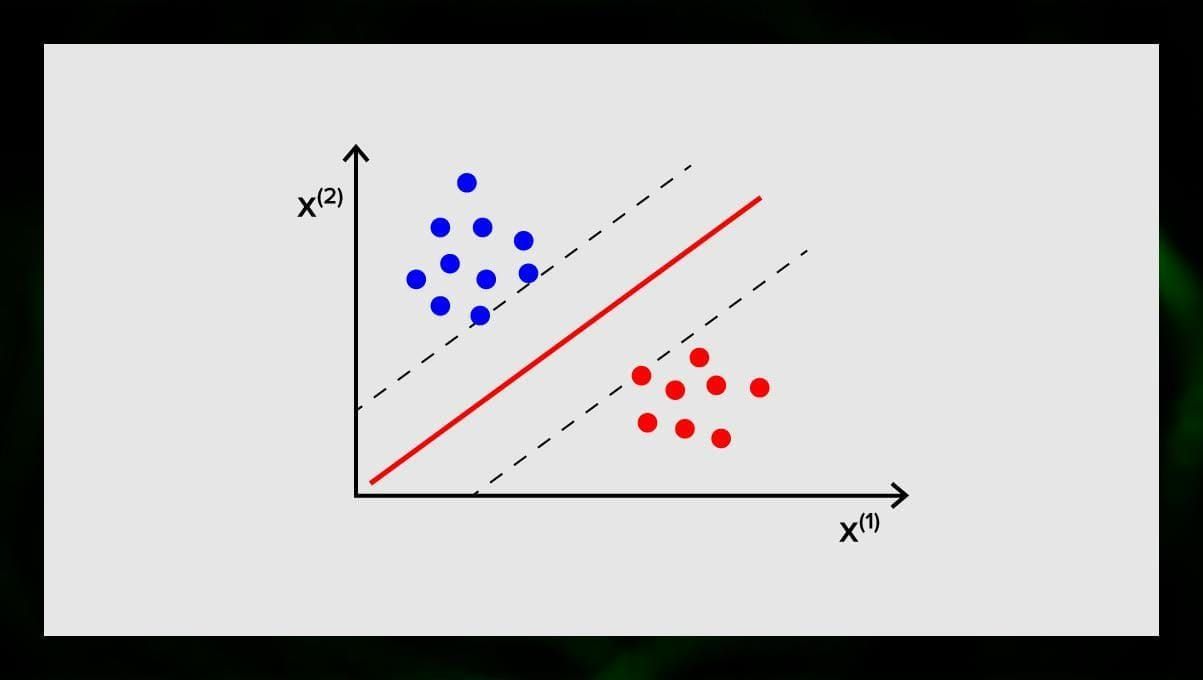
Rețineți că dimensiunea hiperplanului depinde de numărul de caracteristici. Dacă numărul de caracteristici de intrare este 2, atunci hiperplanul este doar o linie. Dacă numărul de caracteristici de intrare este 3, atunci hiperplanul devine un plan bidimensional. Devine dificil să se deseneze pe un grafic un model atunci când numărul de caracteristici depășește 3. Deci, în acest caz, veți folosi tipurile Kernel pentru a-l transforma într-un spațiu tridimensional.
De ce se numește Support Vector Machine? Vectorii suport sunt punctele de date cele mai apropiate de hiperplan. Aceștia influențează direct poziția și orientarea hiperplanului și ne permit să maximizăm marja clasificatorului. Ștergerea vectorilor suport va schimba poziția hiperplanului. Acestea sunt punctele care ne ajută să construim SVM.
SVM sunt acum utilizate în mod activ în diagnosticul medical pentru a găsi anomalii, în sistemele de control al calității aerului, pentru analize financiare și predicții pe piața bursieră, precum și pentru controlul defecțiunilor mașinilor în industrie.
Agoritmi de regresie
Agoritmii de regresie sunt utili în analiză, de exemplu, atunci când încercați să preziceți costurile pentru valori mobiliare sau vânzările pentru un anumit produs la un anumit moment.
Regresie liniară
Regresia liniară încearcă să modeleze relația dintre variabile prin ajustarea unei ecuații liniare la datele observate.
Există variabile explicative și variabile dependente. Variabilele dependente sunt lucruri pe care dorim să le explicăm sau să le prognozăm. Cele explicative, așa cum rezultă pentru nume, explică ceva. Dacă doriți să construiți o regresie liniară, presupuneți că există o relație liniară între variabilele dependente și cele independente. De exemplu, există o corelație între metrii pătrați ai unei case și prețul acesteia sau densitatea populației și a localurilor de kebab din zonă.
După ce faceți această presupunere, trebuie apoi să vă dați seama care este relația liniară specifică. Va trebui să găsiți o ecuație de regresie liniară pentru un set de date. Ultimul pas este să calculați rezidualul.
Nota: Când regresia trasează o linie dreaptă, se numește liniară, când este o curbă – polinomială.
Agoritmi de învățare nesupravegheată

Acum să vorbim despre algoritmii care sunt capabili să găsească modele ascunse în date neetichetate.
Clustering
Clustering înseamnă că împărțim intrările în grupuri în funcție de gradul de similaritate între ele. Clusterizarea este, de obicei, una dintre etapele de construire a unui algoritm mai complex. Este mai simplu să studiezi fiecare grup în parte și să construiești un model pe baza caracteristicilor lor, decât să lucrezi cu totul deodată. Aceeași tehnică este folosită în mod constant în marketing și vânzări pentru a împărți toți potențialii clienți în grupuri.
Algoritmii de clusterizare foarte comuni sunt clusterizarea k-means și k-nearest neighbor.
K-means clustering
K-means clustering împarte setul de elemente ale spațiului vectorial într-un număr predefinit de clustere k. Un număr incorect de clustere va invalida însă întregul proces, așa că este important să se încerce cu un număr variabil de clustere. Ideea principală a algoritmului k-means este că datele sunt împărțite aleatoriu în clustere, iar apoi, centrul fiecărui cluster obținut în etapa anterioară este recalculat iterativ. Apoi, vectorii sunt împărțiți din nou în clustere. Algoritmul se oprește atunci când la un moment dat nu există nicio schimbare în clustere după o iterație.
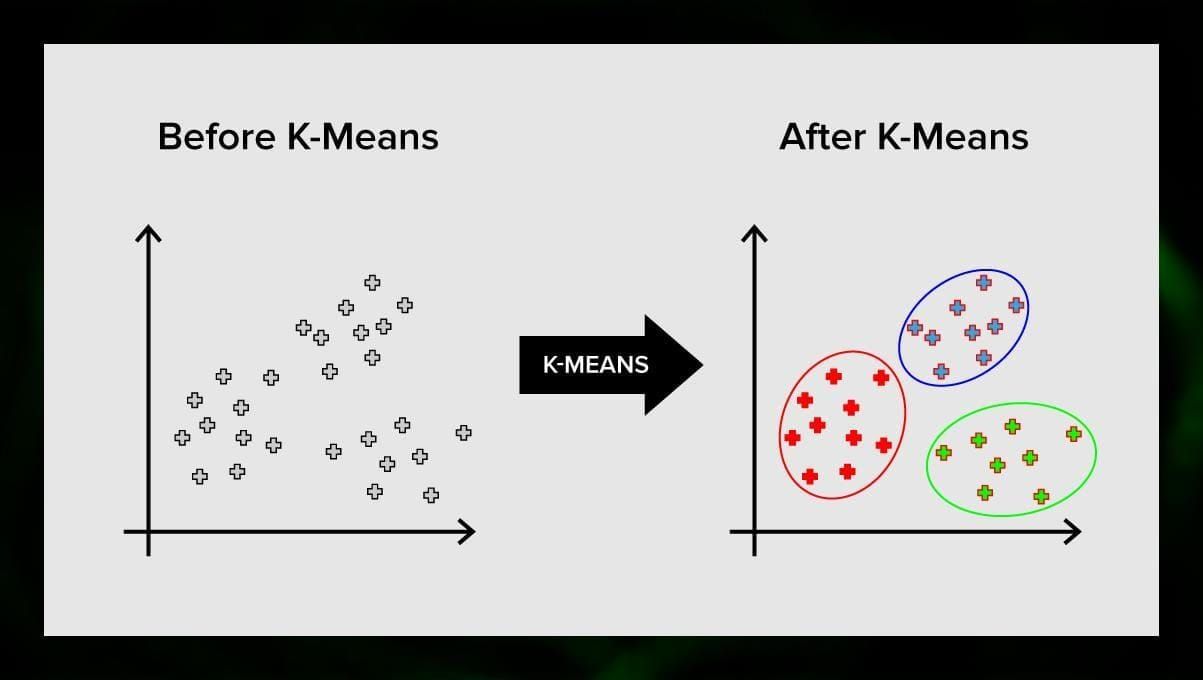
Această metodă poate fi aplicată pentru a rezolva probleme atunci când clusterele sunt distincte sau pot fi separate ușor unele de altele, fără suprapunere de date.
K-nearest neighbor
kNN înseamnă k-nearest neighbor. Acesta este unul dintre cei mai simpli algoritmi de clasificare, folosit uneori în sarcinile de regresie.
Pentru a antrena clasificatorul, trebuie să aveți un set de date cu clase predefinite. Clasificarea se face manual, implicând specialiști în domeniul studiat. Folosind acest algoritm, este posibil să se lucreze cu clase multiple sau să se clarifice situațiile în care intrările aparțin mai multor clase.
Metoda se bazează pe ipoteza că etichetele similare corespund unor obiecte apropiate în spațiul vectorial al atributelor.
Sistemele software moderne folosesc kNN pentru recunoașterea modelelor vizuale, de exemplu, pentru a scana și detecta pachetele ascunse în partea de jos a coșului de cumpărături la check-out (de exemplu, AmazonGo). K-nearest neighbor este, de asemenea, utilizat în domeniul bancar pentru a detecta tipare în utilizarea cardurilor de credit. algoritmii kNN analizează toate datele și detectează tipare neobișnuite care indică o activitate suspectă.
Reducerea dimensionalității
Analiza componentelor principale (PCA) este o tehnică importantă de înțeles pentru a rezolva eficient problemele legate de ML.
Imaginați-vă că aveți o mulțime de variabile de luat în considerare. De exemplu, trebuie să grupați orașele în trei grupe: bune pentru a trăi, rele pentru a trăi și așa și așa. Câte variabile trebuie să luați în considerare? Probabil, foarte multe. Înțelegeți relațiile dintre ele? Nu prea. Deci, cum puteți lua toate variabilele pe care le-ați colectat și să vă concentrați doar asupra câtorva dintre ele care sunt cele mai importante?
În termeni tehnici, doriți să „reduceți dimensiunea spațiului caracteristic”. Prin reducerea dimensiunii spațiului dvs. de caracteristici, reușiți să obțineți mai puține relații între variabile de luat în considerare și este mai puțin probabil să vă supraadaptați modelul.
Există multe modalități de a realiza reducerea dimensionalității, dar majoritatea acestor tehnici se încadrează într-una din cele două clase:
- Eliminarea caracteristicilor;
- Extragerea caracteristicilor.
Eliminarea caracteristicilor înseamnă că reduceți numărul de caracteristici prin eliminarea unora dintre ele. Avantajele acestei metode sunt că este simplă și menține interpretabilitatea variabilelor dumneavoastră. Ca un dezavantaj, deși, obțineți zero informații de la variabilele pe care ați decis să le eliminați.
Extragerea caracteristicilor evită această problemă. Scopul atunci când se aplică această metodă este de a extrage un set de caracteristici din setul de date dat. Extracția caracteristicilor are ca scop reducerea numărului de caracteristici dintr-un set de date prin crearea de noi caracteristici pe baza celor existente (și apoi renunțarea la caracteristicile originale). Noul set redus de caracteristici trebuie creat astfel încât să fie capabil să rezume majoritatea informațiilor conținute în setul original de caracteristici.
Analiza componentelor principale este un algoritm de extragere a caracteristicilor. combină variabilele de intrare într-un mod specific, iar apoi este posibil să se renunțe la variabilele „mai puțin importante”, păstrând în același timp cele mai valoroase părți ale tuturor variabilelor.
Una dintre posibilele utilizări ale PCA este atunci când imaginile din setul de date sunt prea mari. O reprezentare redusă a caracteristicilor ajută la abordarea rapidă a unor sarcini cum ar fi potrivirea și regăsirea imaginilor.
Învățarea regulilor de asociere
Apriori este unul dintre cei mai populari algoritmi de căutare a regulilor de asociere. Acesta este capabil să proceseze cantități mari de date într-o perioadă relativ mică de timp.
Ceea ce se întâmplă este că bazele de date ale multor proiecte de astăzi sunt foarte mari, ajungând la gigabytes și terabytes. Și vor continua să crească. Prin urmare, este nevoie de un algoritm eficient și scalabil pentru a găsi reguli asociative într-un timp scurt. Apriori este unul dintre acești algoritmi.
Pentru a putea aplica algoritmul, este necesar să se pregătească datele, convertindu-le pe toate în formă binară și modificând structura lor de date.
De obicei, se operează acest algoritm pe o bază de date care conține un număr mare de tranzacții, de exemplu, pe o bază de date care conține informații despre toate articolele pe care clienții le-au cumpărat la un supermarket.
Învățarea prin întărire

Învățarea prin întărire este una dintre metodele de învățare automată care ajută la învățarea mașinii cum să interacționeze cu un anumit mediu. În acest caz, mediul (de exemplu, într-un joc video) servește drept profesor. Acesta oferă feedback la deciziile luate de calculator. Pe baza acestei recompense, mașina învață să ia cea mai bună decizie. Aceasta amintește de modul în care copiii învață să nu atingă o tigaie fierbinte – prin încercări și prin durere.
Descoperind acest proces, el implică acești pași simpli:
- Computerul observă mediul;
- Alege o anumită strategie;
- Actuează în conformitate cu această strategie;
- Reține fie o recompensă, fie o penalizare;
- Învață din această experiență și rafinează strategia;
- Repetă până când este găsită strategia optimă.
Q-Learning
Există câțiva algoritmi care pot fi folosiți pentru învățarea prin întărire. Unul dintre cei mai comuni este Q-Learning.
Q-Learning este un algoritm de învățare prin întărire fără model. Q-learning se bazează pe remunerația primită din partea mediului. Agentul formează o funcție de utilitate Q, care ulterior îi oferă posibilitatea de a alege o strategie de comportament și ia în considerare experiența interacțiunilor anterioare cu mediul.
Unul dintre avantajele învățării Q este că este capabil să compare utilitatea așteptată a acțiunilor disponibile fără a forma modele de mediu.
Învățarea prin asamblare

Învățarea prin asamblare este metoda de rezolvare a unei probleme prin construirea mai multor modele ML și combinarea acestora. Învățarea în ansamblu este utilizată în principal pentru a îmbunătăți performanța modelelor de clasificare, predicție și aproximare a funcțiilor. Alte aplicații ale învățării de ansamblu includ verificarea deciziei luate de model, selectarea caracteristicilor optime pentru construirea modelelor, învățarea incrementală și învățarea nestaționară.
În continuare sunt prezentați unii dintre cei mai comuni algoritmi de învățare de ansamblu.
Bagging
Bagging înseamnă agregare bootstrap. Este unul dintre cei mai timpurii algoritmi de ansamblu, cu o performanță surprinzător de bună. Pentru a garanta diversitatea clasificatorilor, se utilizează replici bootstrap ale datelor de instruire. Aceasta înseamnă că diferite subseturi de date de instruire sunt extrase aleatoriu – cu înlocuire – din setul de date de instruire. Fiecare subset de date de instruire este utilizat pentru a instrui un clasificator diferit de același tip. Apoi, clasificatorii individuali pot fi combinați. Pentru a face acest lucru, trebuie să se ia un vot majoritar simplu al deciziilor lor. Clasa care a fost atribuită de majoritatea clasificatorilor este decizia ansamblului.
Boosting
Acest grup de algoritmi de ansamblu este similar cu bagging. Boosting utilizează, de asemenea, o varietate de clasificatori pentru a reeșantiona datele, iar apoi alege versiunea optimă prin vot majoritar. În boosting, se antrenează iterativ clasificatorii slabi pentru a-i asambla într-un clasificator puternic. Atunci când clasificatorii sunt adăugați, li se atribuie, de obicei, niște ponderi, care descriu acuratețea predicțiilor lor. După ce un clasificator slab este adăugat în ansamblu, ponderile sunt recalculate. Intrările clasificate incorect câștigă mai multă greutate, iar instanțele clasificate corect pierd din greutate. Astfel, sistemul se concentrează mai mult pe exemplele în care a fost obținută o clasificare eronată.
Random forest
Random forests sau random decision forests sunt o metodă de învățare în ansamblu pentru clasificare, regresie și alte sarcini. Pentru a construi o pădure aleatorie, trebuie să antrenați o multitudine de arbori de decizie pe eșantioane aleatorii de date de instruire. Rezultatul pădurii aleatoare este cel mai frecvent rezultat dintre arborii individuali. Pădurile de decizie aleatoare combat cu succes supraadaptarea datorită naturii _aleatoare_ a algoritmului.
Stacking
Stacking este o tehnică de învățare de ansamblu care combină mai multe modele de clasificare sau regresie prin intermediul unui metaclasificator sau al unui metaregresor. Modelele de nivel de bază sunt antrenate pe baza unui set complet de instruire, apoi meta-modelul este antrenat pe ieșirile modelelor de nivel de bază ca caracteristici.
Rețele neuronale
O rețea neuronală este o secvență de neuroni conectați prin sinapse, care amintește de structura creierului uman. Cu toate acestea, creierul uman este chiar mai complex.
Ceea ce este grozav la rețelele neuronale este că acestea pot fi folosite practic pentru orice sarcină, de la filtrarea spam-ului la viziunea computerizată. Cu toate acestea, ele sunt aplicate în mod normal pentru traducere automată, detectarea anomaliilor și gestionarea riscurilor, recunoașterea vorbirii și generarea de limbaj, recunoașterea fețelor și multe altele.
O rețea neuronală este formată din neuroni, sau noduri. Fiecare dintre acești neuroni primește date, le procesează și apoi le transferă către un alt neuron.
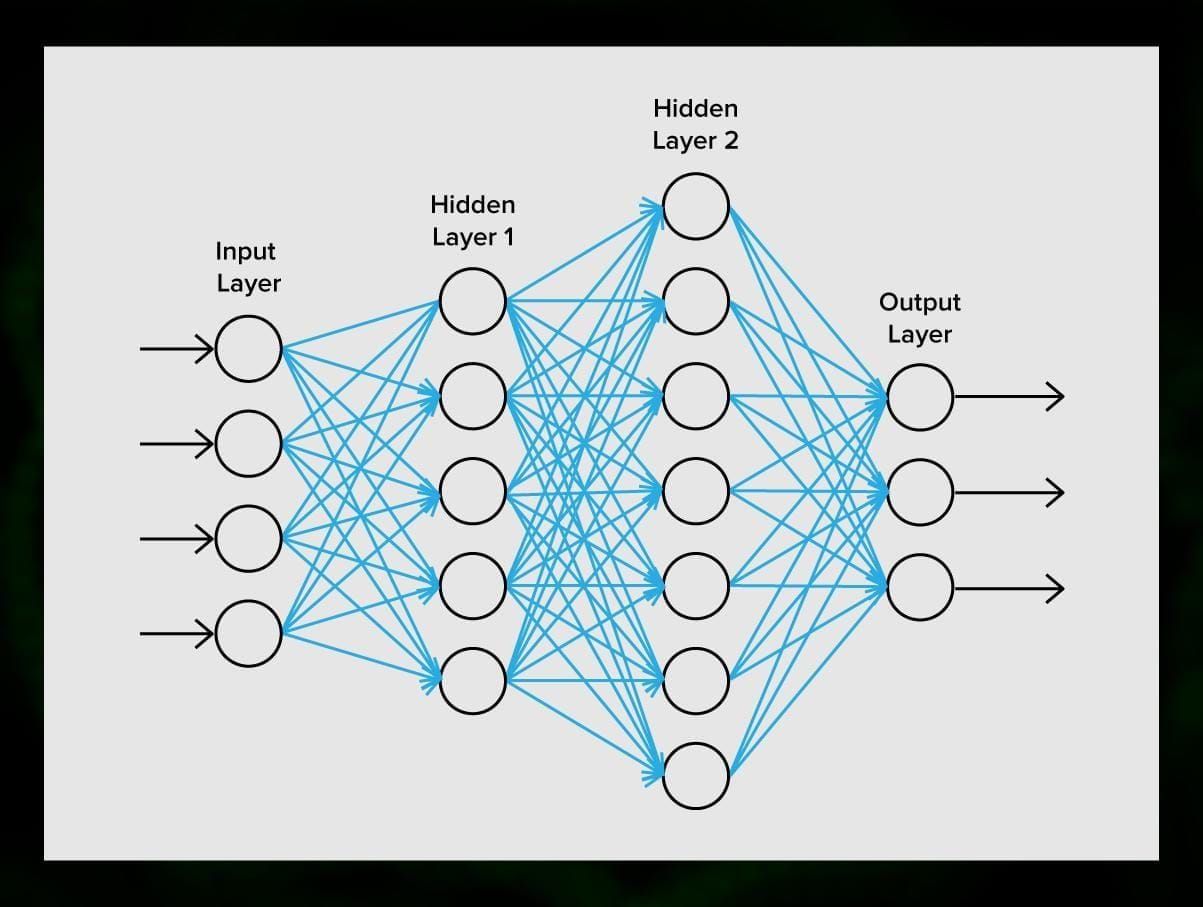
Care neuron procesează semnalele în același mod. Dar cum obținem atunci un rezultat diferit? Sinapsele care conectează neuronii între ei sunt responsabile de acest lucru. Fiecare neuron este capabil să aibă mai multe sinapse care atenuează sau amplifică semnalul. De asemenea, neuronii sunt capabili să își schimbe caracteristicile în timp. Prin alegerea parametrilor corecți ai sinapselor, vom putea obține rezultatele corecte ale conversiei informației de intrare la ieșire.
Există mai multe tipuri diferite de NN:
- Rețele neuronale de tip feedforward (FF sau FFNN) și perceptronii § sunt foarte directe, nu există bucle sau cicluri în rețea. În practică, astfel de rețele sunt rareori utilizate, dar ele sunt adesea combinate cu alte tipuri pentru a obține altele noi.
- O rețea Hopfield (HN) este o rețea neuronală complet conectată cu o matrice simetrică de legături. O astfel de rețea este adesea numită rețea cu memorie asociativă. La fel ca o persoană care, văzând o jumătate de tabel, își poate imagina a doua jumătate, această rețea, primind un tabel zgomotos, îl restabilește în întregime.
- Rețelele neuronale convoluționale (CNN) și rețelele neuronale convoluționale profunde (DCNN) sunt foarte diferite de alte tipuri de rețele. Ele sunt utilizate de obicei pentru sarcini legate de procesarea imaginilor, audio sau video. O modalitate tipică de aplicare a CNN este clasificarea imaginilor.
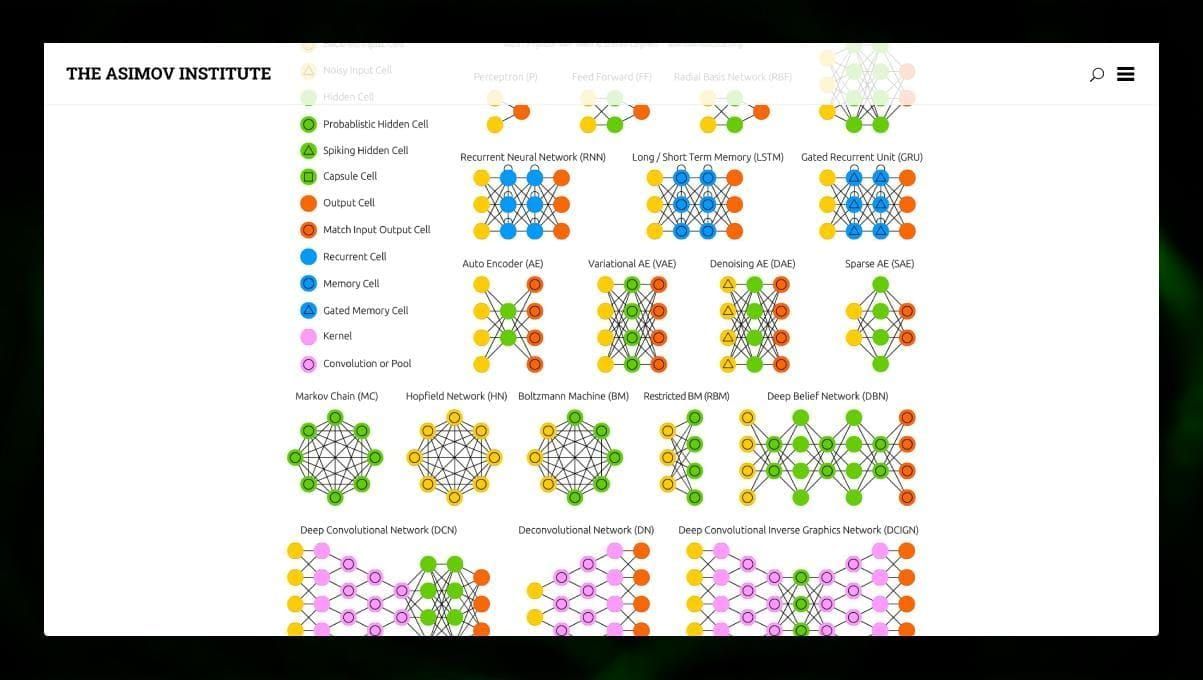
Multe tipuri diferite de rețele neuronale sunt interesante de observat. Este posibil să faceți acest lucru în grădina zoologică NN.
Concluzie
Acest post este o prezentare generală a diferiților algoritmi ML, dar mai sunt încă multe de spus. Rămâneți conectați la Twitter, Facebook și Medium pentru mai multe ghiduri și postări despre posibilitățile interesante ale învățării automate.
.
Lasă un răspuns