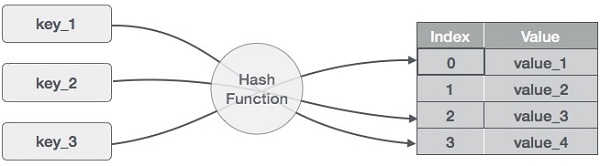
Tablica Hash jest strukturą danych, która przechowuje dane w sposób asocjacyjny. W tablicy hashowej dane są przechowywane w formacie tablicy, gdzie każda wartość danych ma swoją unikalną wartość indeksu. Dostęp do danych staje się bardzo szybki, jeśli znamy indeks pożądanych danych.
Tak więc staje się strukturą danych, w której operacje wstawiania i wyszukiwania są bardzo szybkie, niezależnie od rozmiaru danych. Hash Table wykorzystuje tablicę jako nośnik danych i używa techniki hash do generowania indeksu, gdzie element ma być wstawiony lub ma być zlokalizowany od.
Hashing
Hashing jest techniką przekształcania zakresu wartości klucza w zakres indeksów tablicy. Będziemy używać operatora modulo do uzyskania zakresu wartości kluczy. Rozważmy przykład tablicy haszującej o rozmiarze 20, w której mają być przechowywane następujące elementy. Elementy są w formacie (klucz,wartość).
- (1,20)
- (2,70)
- (42,80)
- (4,25)
- (12,44)
- (14,32)
- (17,11)
- (13,78)
- (37,98)
| Sr.No. | Key | Hash | Array Index |
|---|---|---|---|
| 1 | 1 | 1 % 20 = 1 | 1 |
| 2 | 2 | 2 % 20 = 2 | 2 |
| 3 | 42 | 42 % 20 = 2 | 2 |
| 4 | 4 | 4 % 20 = 4 | 4 |
| 5 | 12 | 12 % 20 = 12 | 12 |
| 6 | 14 | 14 % 20 = 14 | 14 |
| 7 | 17 | 17 % 20 = 17 | 17 |
| 8 | 13 | 13 % 20 = 13 | 13 |
| 9 | 37 | 37 % 20 = 17 | 17 |
Linear Probing
Jak widzimy, może się zdarzyć, że technika hashowania zostanie użyta do utworzenia już używanego indeksu tablicy. W takim przypadku możemy wyszukać następne puste miejsce w tablicy, zaglądając do następnej komórki, aż znajdziemy pustą komórkę. Technika ta nazywana jest sondowaniem liniowym.
| Sr.No. | Key | Hash | Indeks tablicy | Po sondowaniu liniowym, Indeks tablicy |
|---|---|---|---|---|
| 1 | 1 | 1 % 20 = 1 | 1 | 1 |
| 2 | 2 | 2 % 20 = 2 | 2 | 2 |
| 3 | 42 | 42 % 20 = 2 | 2 | 3 |
| 4 | 4 | 4 % 20 = 4 | 4 | 4 |
| 5 | 12 | 12 % 20 = 12 | 12 | 12 |
| 6 | 14 | 14 % 20 = 14 | 14 | 14 |
| 7 | 17 | 17 % 20 = 17 | 17 | 17 |
| 8 | 13 | 13 % 20 = 13 | 13 | 13 |
| 9 | 37 | 37 % 20 = 17 | 17 | 18 |
Podstawowe operacje
Poniżej przedstawiono podstawowe operacje podstawowe tablicy haszującej.
-
Szukaj – przeszukuje element w tablicy hash.
-
Insert – wstawia element do tablicy hash.
-
delete – usuwa element z tablicy hash.
DataItem
Definiuje element danych posiadający pewne dane i klucz, na podstawie którego ma zostać przeprowadzone wyszukiwanie w tablicy hash.
struct DataItem { int data; int key;};
Metoda haszowania
Zdefiniuj metodę haszowania, aby obliczyć kod haszujący klucza elementu danych.
int hashCode(int key){ return key % SIZE;}
Operacja wyszukiwania
Gdy element ma być wyszukany, oblicz kod haszujący przekazanego klucza i zlokalizuj element używając tego kodu haszującego jako indeksu w tablicy. Użyj sondowania liniowego, aby uzyskać element wyprzedzający, jeśli element nie zostanie znaleziony w obliczonym kodzie haszującym.
Przykład
struct DataItem *search(int key) { //get the hash int hashIndex = hashCode(key); //move in array until an empty while(hashArray != NULL) { if(hashArray->key == key) return hashArray; //go to next cell ++hashIndex; //wrap around the table hashIndex %= SIZE; } return NULL; }
Operacja wstawiania
Gdy element ma zostać wstawiony, oblicz kod haszujący przekazanego klucza i zlokalizuj indeks, używając tego kodu haszującego jako indeksu w tablicy. Użyj sondowania liniowego dla pustej lokalizacji, jeśli element zostanie znaleziony w obliczonym kodzie skrótu.
Przykład
void insert(int key,int data) { struct DataItem *item = (struct DataItem*) malloc(sizeof(struct DataItem)); item->data = data; item->key = key; //get the hash int hashIndex = hashCode(key); //move in array until an empty or deleted cell while(hashArray != NULL && hashArray->key != -1) { //go to next cell ++hashIndex; //wrap around the table hashIndex %= SIZE; } hashArray = item; }
Operacja usuwania
Gdy element ma zostać usunięty, oblicz kod skrótu przekazanego klucza i zlokalizuj indeks, używając tego kodu skrótu jako indeksu w tablicy. Użyj sondowania liniowego, aby uzyskać element naprzód, jeśli element nie zostanie znaleziony w obliczonym kodzie haszującym. Gdy zostanie znaleziony, przechowuj tam atrapę elementu, aby zachować wydajność tablicy hashowej.
Przykład
struct DataItem* delete(struct DataItem* item) { int key = item->key; //get the hash int hashIndex = hashCode(key); //move in array until an empty while(hashArray !=NULL) { if(hashArray->key == key) { struct DataItem* temp = hashArray; //assign a dummy item at deleted position hashArray = dummyItem; return temp; } //go to next cell ++hashIndex; //wrap around the table hashIndex %= SIZE; } return NULL; }
Aby dowiedzieć się o implementacji hash w języku programowania C, kliknij tutaj.
.
Dodaj komentarz