Ludzie tworzą, udostępniają i przechowują dane w tempie szybszym niż w jakimkolwiek innym okresie w historii. Jeśli chodzi o innowacje w zakresie przechowywania i przesyłania tych danych, w Facebooku dokonujemy postępu nie tylko w zakresie sprzętu – np. większych dysków twardych i szybszego sprzętu sieciowego – ale także oprogramowania. Oprogramowanie pomaga w przetwarzaniu danych poprzez kompresję, która koduje informacje, takie jak tekst, zdjęcia i inne formy danych cyfrowych, używając mniejszej ilości bitów niż oryginał. Takie mniejsze pliki zajmują mniej miejsca na dyskach twardych i są szybciej przesyłane do innych systemów. Kompresja i dekompresja informacji wiąże się jednak z pewnym kompromisem: czasem. Im więcej czasu poświęca się na kompresję do mniejszego pliku, tym wolniej dane są przetwarzane.
Dzisiaj królującym standardem kompresji danych jest Deflate, podstawowy algorytm w programach Zip, gzip i zlib . Przez dwie dekady zapewniał on imponującą równowagę między szybkością i przestrzenią, a w rezultacie jest używany w prawie każdym nowoczesnym urządzeniu elektronicznym (i, nieprzypadkowo, używany do przesyłania każdego bajtu tego wpisu na blogu, który właśnie czytasz). Przez lata inne algorytmy oferowały albo lepszą, albo szybszą kompresję, ale rzadko obie. Wierzymy, że udało nam się to zmienić.
Jesteśmy zachwyceni mogąc ogłosić Zstandard 1.0, nowy algorytm kompresji i implementację zaprojektowaną do skalowania z nowoczesnym sprzętem oraz kompresji mniejszych i szybszych plików. Zstandard łączy ostatnie przełomowe odkrycia w dziedzinie kompresji, takie jak Entropia skończonego stanu, z projektem opartym na wydajności – a następnie optymalizuje implementację pod kątem unikalnych właściwości nowoczesnych procesorów. W rezultacie, poprawia kompromisy dokonane przez inne algorytmy kompresji i ma szeroki zakres zastosowań przy bardzo wysokiej prędkości dekompresji. Zstandard, dostępny teraz na licencji BSD, został zaprojektowany do użycia w niemal każdym scenariuszu kompresji bezstratnej, w tym wielu, w których obecne algorytmy nie mają zastosowania.
- Porównanie kompresji
- Skalowalność
- Pod maską
- Pamięć
- Format zaprojektowany do wykonywania równoległego
- Bezgałęziowa konstrukcja
- Finite State Entropy: A next-generation probability compressor
- Modelowanie kodu powtórzonego
- Zstandard w praktyce
- Małe dane
- Słowniki w akcji
- Wybór poziomu kompresji
- Wypróbuj
- Więcej w przyszłości
Porównanie kompresji
Istnieją trzy standardowe metryki do porównywania algorytmów i implementacji kompresji:
- Współczynnik kompresji: Oryginalny rozmiar (licznik) w porównaniu z rozmiarem skompresowanym (mianownik), mierzony w danych bez jednostek jako współczynnik rozmiaru 1,0 lub większy.
- Szybkość kompresji: Jak szybko możemy zmniejszyć dane, mierzony w MB/s zużytych danych wejściowych.
- Szybkość dekompresji: Jak szybko możemy zrekonstruować oryginalne dane ze skompresowanych danych, mierzona w MB/s dla szybkości, z jaką dane są produkowane ze skompresowanych danych.
Rodzaj kompresowanych danych może mieć wpływ na te metryki, więc wiele algorytmów jest dostrojonych do konkretnych typów danych, takich jak tekst angielski, sekwencje genetyczne lub obrazy rastrowe. Jednakże, Zstandard, podobnie jak zlib, jest przeznaczony do kompresji ogólnego przeznaczenia dla różnych typów danych. Do reprezentowania algorytmów, nad którymi Zstandard ma pracować, w tym poście użyjemy korpusu Silesia, zbioru plików reprezentujących typowe typy danych używane na co dzień.
Niektóre algorytmy i implementacje powszechnie używane dzisiaj to zlib, lz4, i xz. Każdy z tych algorytmów oferuje różne kompromisy: lz4 ma na celu szybkość, xz ma na celu wyższy stopień kompresji, a zlib ma na celu dobrą równowagę między szybkością i rozmiarem. Poniższa tabela przedstawia kompromisy pomiędzy domyślnym stopniem kompresji i szybkością działania algorytmów dla korpusu Silesia poprzez porównanie algorytmów w lzbench, czysto pamięciowym benchmarku mającym na celu modelowanie wydajności algorytmów.
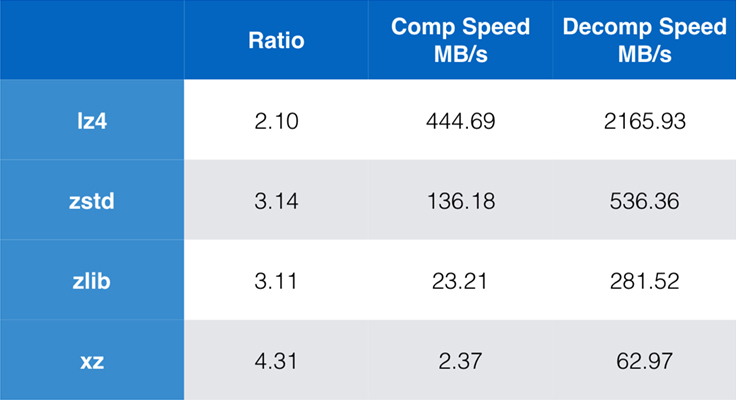
Jak widać, często występują drastyczne kompromisy pomiędzy szybkością a rozmiarem. Najszybszy algorytm, lz4, skutkuje niższymi współczynnikami kompresji; xz, który ma najwyższy współczynnik kompresji, cierpi z powodu powolnej prędkości kompresji. Jednakże Zstandard, przy domyślnych ustawieniach, wykazuje znaczną poprawę zarówno w szybkości kompresji jak i dekompresji, kompresując przy tym z takim samym współczynnikiem jak zlib.
Choć wydajność czystego algorytmu jest ważna, gdy kompresja jest wbudowana w większą aplikację, bardzo często używa się również narzędzi wiersza poleceń do kompresji – np. do kompresji plików dziennika, tarballi lub innych podobnych danych przeznaczonych do przechowywania lub transferu. W takich przypadkach na wydajność często wpływają koszty ogólne, takie jak sumy kontrolne. Ten wykres pokazuje porównanie narzędzi wiersza poleceń gzip i zstd na Centos 7 zbudowanym z domyślnym kompilatorem systemu.
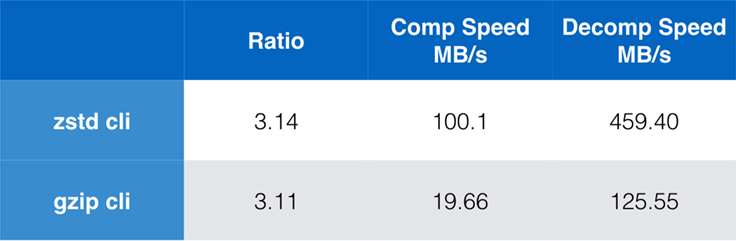
Testy były przeprowadzane 10 razy, z minimalnym czasem wziętym, i były przeprowadzane na ramdysku, aby uniknąć narzutu systemu plików. To były polecenia (które używają domyślnych poziomów kompresji dla obu narzędzi):
zstd -c -3 silesia.tar > silesia.tar.zst # 67,432,740 byteszstd -d -c silesia.tar.zst > /dev/nullgzip -c -6 silesia.tar > silesia.tar.gz # 68,235,522 bytesgzip -d -c silesia.tar.gz > /dev/nullSkalowalność
Jeśli algorytm jest skalowalny, ma możliwość dostosowania się do szerokiej gamy wymagań, a Zstandard został zaprojektowany tak, aby wyróżniać się w dzisiejszym krajobrazie i skalować się w przyszłości. Większość algorytmów ma „poziomy” oparte na kompromisach czasowo-przestrzennych: Im wyższy poziom, tym większa kompresja osiągana przy utracie szybkości kompresji. Zlib oferuje dziewięć poziomów kompresji; Zstandard obecnie oferuje 22, co pozwala na elastyczne, granularne kompromisy pomiędzy szybkością kompresji a współczynnikami dla przyszłych danych. Na przykład, możemy użyć poziomu 1, jeśli prędkość jest najważniejsza, a poziomu 22, jeśli najważniejszy jest rozmiar.
Poniżej znajduje się wykres prędkości i współczynnika kompresji uzyskanych dla wszystkich poziomów Zstandard i zlib. Oś x to malejąca skala logarytmiczna w megabajtach na sekundę; oś y to osiągnięty współczynnik kompresji. Aby porównać algorytmy, możesz wybrać prędkość, aby zobaczyć różne współczynniki, jakie algorytmy osiągają przy tej prędkości. Podobnie, można wybrać współczynnik i zobaczyć, jak szybkie są algorytmy, gdy osiągają ten poziom.
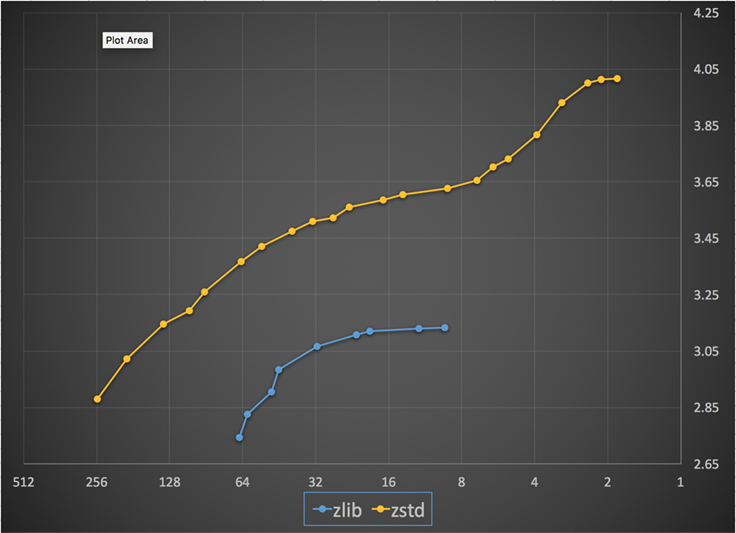
Dla każdej pionowej linii (tj. prędkości kompresji), Zstandard osiąga wyższy współczynnik kompresji. Dla korpusu Silesia prędkość dekompresji – niezależnie od współczynnika – wynosiła około 550 MB/s dla Zstandard i 270 MB/s dla zlib. Wykres pokazuje jeszcze jedną różnicę pomiędzy Zstandardem a alternatywnymi rozwiązaniami: Dzięki zastosowaniu jednego algorytmu i implementacji, Zstandard pozwala na znacznie dokładniejsze dostrojenie do każdego przypadku użycia. Oznacza to, że Zstandard może konkurować z niektórymi najszybszymi i najbardziej zaawansowanymi algorytmami kompresji, zachowując jednocześnie znaczną przewagę w szybkości dekompresji. Te ulepszenia przekładają się bezpośrednio na szybszy transfer danych i mniejsze wymagania w zakresie przechowywania.
Innymi słowy, w porównaniu z zlib, Zstandard skaluje się:
- Przy tym samym współczynniku kompresji, kompresuje znacznie szybciej: ~3-5x.
- Przy tej samej prędkości kompresji jest znacząco mniejszy: 10-15 procent mniejszy.
- Jest prawie 2x szybszy przy dekompresji, niezależnie od współczynnika kompresji; liczby narzędzi linii poleceń pokazują jeszcze większą różnicę: ponad 3x szybciej.
- Skaluje się do znacznie wyższych współczynników kompresji, zachowując błyskawiczne prędkości dekompresji.
Pod maską
Zstandard ulepsza zlib poprzez połączenie kilku ostatnich innowacji i ukierunkowanie na nowoczesny sprzęt:
Pamięć
Zgodnie z projektem, zlib jest ograniczony do okna 32 KB, co było rozsądnym wyborem we wczesnych latach ’90. Jednak dzisiejsze środowisko komputerowe może mieć dostęp do znacznie większej ilości pamięci – nawet w środowiskach mobilnych i wbudowanych.
Zstandard nie ma nieodłącznego ograniczenia i może adresować terabajty pamięci (choć rzadko to robi). Na przykład, niższe z 22 poziomów używają 1 MB lub mniej. Dla kompatybilności z szeroką gamą systemów odbiorczych, gdzie pamięć może być ograniczona, zalecane jest ograniczenie użycia pamięci do 8 MB. Jest to jednak zalecenie dotyczące dostrajania, a nie ograniczenie formatu kompresji.
Format zaprojektowany do wykonywania równoległego
Dzisiejsze procesory są bardzo wydajne i mogą wydawać kilka instrukcji na cykl, dzięki wielu jednostkom ALU (arytmetyczne jednostki logiczne) i coraz bardziej zaawansowanym projektom wykonywania poza kolejnością.
W istocie oznacza to, że jeśli:
a = b1 + b2
c = d1 + d2
to zarówno a jak i c będą obliczane równolegle.
Jest to możliwe tylko wtedy, gdy nie ma między nimi żadnej relacji. Dlatego w tym przykładzie:
a = b1 + b2
c = d1 + a
c musi poczekać, aż a zostanie obliczony jako pierwszy, a dopiero potem rozpocznie się obliczanie c.
Oznacza to, że aby wykorzystać możliwości nowoczesnego procesora, należy zaprojektować przepływ operacji z niewielką ilością lub bez zależności od danych.
Osiąga się to w Zstandard poprzez rozdzielenie danych na wiele równoległych strumieni. Dekoder Huffmana nowej generacji, Huff0, jest w stanie dekodować wiele symboli równolegle przy użyciu jednego rdzenia. Taki zysk kumuluje się z wielowątkowością, która wykorzystuje wiele rdzeni.
Bezgałęziowa konstrukcja
Nowe procesory są bardziej wydajne i osiągają bardzo wysokie częstotliwości, ale jest to możliwe tylko dzięki podejściu wieloetapowemu, w którym instrukcja jest dzielona na potok złożony z wielu kroków. W każdym cyklu zegara, procesor jest w stanie wydać wynik wielu operacji, w zależności od dostępnych jednostek ALU. Im więcej ALU jest używanych, tym więcej pracy wykonuje procesor, a co za tym idzie, tym szybciej zachodzi kompresja. Utrzymanie ALU zasilanych pracą jest kluczowe dla wydajności nowoczesnego procesora.
Okazuje się to trudne. Rozważmy następującą prostą sytuację:
if (condition) doSomething() else doSomethingElse()Kiedy się na to natknie, CPU nie wie, co zrobić, ponieważ zależy to od wartości condition. Ostrożny procesor poczekałby na wynik condition przed rozpoczęciem pracy nad którąkolwiek z gałęzi, co byłoby niezwykle marnotrawne.
Dzisiejsze procesory uprawiają hazard. Robią to inteligentnie, dzięki predyktorowi rozgałęzień, który mówi im w istocie najbardziej prawdopodobny wynik oceny condition. Gdy zakład jest słuszny, potok pozostaje pełny i instrukcje są wydawane bez przerwy. Kiedy zakład jest błędny (błędne przewidywanie), procesor musi zatrzymać wszystkie operacje rozpoczęte spekulacyjnie, wrócić do gałęzi i obrać inny kierunek. Nazywa się to pipeline flush i jest niezwykle kosztowne w nowoczesnych procesorach.
Dwadzieścia pięć lat temu pipeline flush nie stanowiło problemu. Dziś jest to tak ważne, że konieczne jest projektowanie formatów kompatybilnych z algorytmami bez rozgałęzień. Jako przykład spójrzmy na aktualizację strumienia bitowego:
/* classic version */while (nbBitsUsed >= 8) { /* each while test is a branch */ accumulator <<= 8; accumulator += *byte++; nbBitsUsed -= 8;} /*>/* branch-less version */nbBytesUsed = nbBitsUsed >> 3;nbBitsUsed &= 7;ptr += nbBytesUsed;accumulator = read64(ptr);Jak widać, wersja bez rozgałęzień ma przewidywalne obciążenie pracą, bez żadnego warunku. Procesor zawsze będzie wykonywał tę samą pracę, a ta praca nigdy nie jest wyrzucana z powodu błędnego przewidywania. W przeciwieństwie do tego, wersja klasyczna wykonuje mniej pracy, gdy (nbBitsUsed < 8). Ale sam test nie jest darmowy i za każdym razem, gdy test jest błędnie odgadnięty, powoduje to pełne przepłukanie potoku, co kosztuje więcej niż praca wykonana przez wersję bez rozgałęzień.
Jak można się domyślić, ten efekt uboczny ma wpływ na sposób pakowania, odczytu i dekodowania danych. Zstandard został stworzony, aby być przyjaznym dla algorytmów bezgałęziowych, szczególnie w krytycznych pętlach.
Finite State Entropy: A next-generation probability compressor
W kompresji dane są najpierw przekształcane w zbiór symboli (etap modelowania), a następnie te symbole są kodowane przy użyciu minimalnej liczby bitów. Ten drugi etap nazywany jest etapem entropii, na pamiątkę Claude’a Shannona, który dokładnie oblicza limit kompresji zbioru symboli z danym prawdopodobieństwem (nazywany „limitem Shannona”). Celem jest zbliżenie się do tego limitu przy jednoczesnym wykorzystaniu jak najmniejszej ilości zasobów procesora.
Bardzo popularnym algorytmem jest kodowanie Huffmana, używane w Deflate. Daje on najlepszy możliwy kod prefiksowy, zakładając, że każdy symbol jest opisany naturalną liczbą bitów (1 bit, 2 bity …). Działa to świetnie w praktyce, ale limit liczb naturalnych oznacza, że niemożliwe jest osiągnięcie wysokiego współczynnika kompresji, ponieważ symbol z konieczności zużywa co najmniej 1 bit.
Lepszą metodą jest kodowanie arytmetyczne, które może arbitralnie zbliżyć się do limitu Shannona -log2(P), a więc zużywając ułamkowe bity na symbol. Przekłada się to na lepszy współczynnik kompresji, gdy prawdopodobieństwo jest wysokie, ale zużywa też więcej mocy procesora. W praktyce nawet zoptymalizowane kodery arytmetyczne walczą o szybkość, szczególnie po stronie dekompresji, która wymaga dzielenia z przewidywalnym wynikiem (np. nie zmiennoprzecinkowym) i która okazuje się wolna.
Finite State Entropy jest oparta na nowej teorii zwanej ANS (Asymmetric Numeral System) autorstwa Jarka Dudy. Finite State Entropy jest wariantem, który prekompiluje wiele kroków kodowania w tablicach, dając w rezultacie kodek entropii tak precyzyjny jak kodowanie arytmetyczne, używając tylko dodawania, przeszukiwania tabel i przesunięć, co jest mniej więcej na tym samym poziomie złożoności co Huffman. Zmniejsza on również opóźnienie w dostępie do następnego symbolu, ponieważ jest on natychmiast dostępny z wartości stanu, podczas gdy Huffman wymaga wcześniejszej operacji dekodowania strumienia bitów. Wyjaśnienie jej działania wykracza poza zakres tego wpisu, ale jeśli jesteś zainteresowany, istnieje seria artykułów szczegółowo opisujących jej działanie.
Modelowanie kodu powtórzonego
Modelowanie kodu powtórzonego skutecznie kompresuje dane strukturalne, które charakteryzują się sekwencjami o prawie identycznej zawartości, różniącymi się tylko jednym lub kilkoma bajtami. Ta metoda nie jest nowa, ale została po raz pierwszy użyta po opublikowaniu Deflate, więc nie istnieje w zlib/gzip.
Wydajność modelowania repcode w dużym stopniu zależy od typu kompresowanych danych, waha się od jedno- do dwucyfrowej poprawy kompresji. Te połączone ulepszenia składają się na lepsze i szybsze doświadczenie kompresji, oferowane w ramach biblioteki Zstandard.
Zstandard w praktyce
Jak wspomniano wcześniej, istnieje kilka typowych przypadków użycia kompresji. Aby algorytm był przekonujący, musi być albo wyjątkowo dobry w jednym konkretnym przypadku, takim jak kompresja tekstu czytanego przez człowieka, albo bardzo dobry w wielu różnych przypadkach. Zstandard przyjmuje to drugie podejście. Jednym ze sposobów myślenia o przypadkach użycia jest to, ile razy konkretny fragment danych może zostać zdekompresowany. Zstandard ma zalety we wszystkich tych przypadkach.
Wiele razy. W przypadku danych przetwarzanych wielokrotnie, szybkość dekompresji i możliwość wybrania bardzo wysokiego stopnia kompresji bez uszczerbku dla szybkości dekompresji jest korzystna. Na przykład zapis grafu społecznościowego w serwisie Facebook jest wielokrotnie odczytywany w miarę interakcji użytkownika i jego znajomych z witryną. Poza Facebookiem przykłady sytuacji, w których dane muszą być wielokrotnie dekompresowane, obejmują pliki pobierane z serwera, takie jak kod źródłowy jądra systemu Linux lub pakiety RPM zainstalowane na serwerach, JavaScript i CSS używane na stronie internetowej lub tysiące operacji MapReduces na danych w hurtowni danych.
Tylko raz. W przypadku danych skompresowanych tylko raz, zwłaszcza w celu transmisji przez sieć, kompresja jest ulotnym momentem w przepływie danych. Mniejszy narzut na serwer oznacza, że serwer może obsłużyć więcej żądań na sekundę. Mniejszy narzut na klienta oznacza, że dane mogą być przetwarzane szybciej. Zazwyczaj pojawia się to w sytuacjach klient/serwer, gdzie dane są unikalne dla klienta, takie jak odpowiedź serwera WWW, która jest niestandardowa – powiedzmy, dane używane do renderowania, gdy otrzymasz notatkę od znajomego na Messengerze. W rezultacie urządzenie mobilne ładuje strony szybciej, zużywa mniej baterii i zużywa mniejszą ilość danych. Zstandard w szczególności pasuje do scenariuszy mobilnych znacznie lepiej niż inne algorytmy ze względu na sposób, w jaki obsługuje małe dane.
Prawdopodobnie nigdy. Choć wydaje się to sprzeczne z intuicją, często zdarza się, że część danych – takich jak kopie zapasowe lub pliki dziennika – nigdy nie zostanie zdekompresowana, ale może być odczytana w razie potrzeby. Dla tego typu danych, kompresja zazwyczaj musi być szybka, czynić dane małymi (z kompromisem czas/przestrzeń odpowiednim do sytuacji) i być może przechowywać sumę kontrolną, ale poza tym być niewidoczna. W rzadkich przypadkach, gdy zachodzi potrzeba dekompresji, nie chcesz, aby kompresja spowolniła operacyjny przypadek użycia. Szybka dekompresja jest korzystna, ponieważ często jest to mała część danych (np. określony plik w kopii zapasowej lub wiadomość w pliku dziennika), która musi być szybko odnaleziona.
W tych wszystkich przypadkach, Zstandard daje możliwość kompresji i dekompresji wielokrotnie szybciej niż gzip, przy czym skompresowane dane są mniejsze.
Małe dane
Jest jeszcze jeden przypadek użycia kompresji, któremu poświęca się mniej uwagi, ale który może być bardzo ważny: małe dane. Są to wzorce użycia, w których dane są produkowane i konsumowane w małych ilościach, takich jak wiadomości JSON między serwerem internetowym a przeglądarką (typowo setki bajtów) lub strony danych w bazie danych (kilka kilobajtów).
Bazy danych zapewniają interesujący przypadek użycia. Systemy takie jak MySQL, PostgreSQL i MongoDB przechowują dane przeznaczone do dostępu w czasie rzeczywistym. Ostatnie zalety sprzętu, w szczególności związane z rozpowszechnieniem urządzeń flash (SSD), zasadniczo zmieniły równowagę między rozmiarem a przepustowością – żyjemy teraz w świecie, w którym IOP (operacje wejścia-wyjścia na sekundę) są dość wysokie, ale pojemność naszych urządzeń pamięci masowej jest mniejsza niż w czasach, gdy w centrach danych królowały dyski twarde.
Dodatkowo, pamięć flash ma interesującą właściwość dotyczącą wytrzymałości na zapis – po tysiącach zapisów w tej samej sekcji urządzenia, sekcja ta nie może już przyjmować zapisów, co często prowadzi do wycofania urządzenia z użytku. Naturalne jest więc poszukiwanie sposobów na zmniejszenie ilości zapisywanych danych, gdyż może to oznaczać więcej danych na serwer i wolniejsze wypalanie się urządzenia. Kompresja danych jest strategią do tego celu, a bazy danych są również często optymalizowane pod kątem wydajności, co oznacza, że wydajność odczytu i zapisu jest równie ważna.
Jest jednak pewna komplikacja w używaniu kompresji danych z bazami danych. Bazy danych lubią losowy dostęp do danych, podczas gdy większość typowych przypadków użycia kompresji czyta cały plik w porządku liniowym. Jest to problem, ponieważ kompresja danych zasadniczo działa poprzez przewidywanie przyszłości w oparciu o przeszłość – algorytmy patrzą na dane sekwencyjnie i przewidują, co mogą zobaczyć w przyszłości. Im dokładniejsze przewidywania, tym mniejsze mogą być dane.
Gdy kompresujesz małe dane, takie jak strony w bazie danych lub małe dokumenty JSON wysyłane do urządzenia mobilnego, po prostu nie ma zbyt wiele „przeszłości” do wykorzystania w celu przewidywania przyszłości. Algorytmy kompresji próbowały rozwiązać ten problem, używając wstępnie współdzielonych słowników, aby efektywnie rozpocząć pracę. Odbywa się to poprzez wstępne współdzielenie statycznego zestawu danych „z przeszłości” jako materiału siewnego dla kompresji.
Zstandard opiera się na tym podejściu z wysoce zoptymalizowanymi algorytmami i interfejsami API dla kompresji słowników. Dodatkowo, Zstandard zawiera narzędzia (zstd --train) do łatwego tworzenia słowników dla niestandardowych aplikacji i przepisy dotyczące rejestrowania standardowych słowników w celu udostępnienia ich większym społecznościom. Podczas gdy kompresja różni się w zależności od próbek danych, kompresja małych danych może być od 2x do 5x lepsza niż kompresja bez słowników.
Słowniki w akcji
Choć zabawa ze słownikiem w kontekście działającej bazy danych może być trudna (wymaga przecież znacznych modyfikacji bazy danych), można zobaczyć słowniki w akcji z innymi typami małych danych. JSON, lingua franca małych danych we współczesnym świecie, ma tendencję do bycia małymi, powtarzającymi się rekordami. Dostępne są niezliczone publiczne zbiory danych; na potrzeby tej demonstracji użyjemy zbioru danych „user” z GitHuba, dostępnego przez HTTP. Oto przykładowy wpis z tego zestawu danych:
{ "login": "octocat", "id": 1, "avatar_url": "https://github.com/images/error/octocat_happy.gif", "gravatar_id": "", "url": "https://api.github.com/users/octocat", "html_url": "https://github.com/octocat", "followers_url": "https://api.github.com/users/octocat/followers", "following_url": "https://api.github.com/users/octocat/following{/other_user}", "gists_url": "https://api.github.com/users/octocat/gists{/gist_id}", "starred_url": "https://api.github.com/users/octocat/starred{/owner}{/repo}", "subscriptions_url": "https://api.github.com/users/octocat/subscriptions", "organizations_url": "https://api.github.com/users/octocat/orgs", "repos_url": "https://api.github.com/users/octocat/repos", "events_url": "https://api.github.com/users/octocat/events{/privacy}", "received_events_url": "https://api.github.com/users/octocat/received_events", "type": "User", "site_admin": false } Jak widać, jest tu sporo powtórzeń – możemy je ładnie skompresować! Ale każdy użytkownik to trochę poniżej 1 KB, a większość algorytmów kompresji naprawdę potrzebuje więcej danych, aby rozprostować nogi. Zestaw 1000 użytkowników zajmuje w przybliżeniu 850 KB do przechowywania nieskompresowanego. Naiwne zastosowanie gzip lub zstd indywidualnie do każdego pliku zmniejsza tę liczbę do nieco ponad 300 KB; nieźle! Ale jeśli utworzymy jednorazowy, wstępnie współdzielony słownik z zstd, rozmiar spadnie do 122 KB – zwiększając oryginalny współczynnik kompresji z 2,8x do 6,9. Jest to znacząca poprawa, dostępna out-of-box z zstd:
$ zstd --train -o ../json.zdict -r .sorting 982 files of total size 0 MB ...finding patterns ...statistics ...Save dictionary of size 65599 into file ../json.zdict$ du -h --apparent-size .846K .$ zstd --rm -D ../json.zdict -r .$ du -h --apparent-size .122K .Wybór poziomu kompresji
Jak pokazano powyżej, Zstandard zapewnia znaczną liczbę poziomów. To dostosowanie jest potężne, ale prowadzi do trudnych wyborów. Najlepszym sposobem na podjęcie decyzji jest przejrzenie danych i dokonanie pomiarów, a następnie określenie kompromisów. W Facebooku uważamy, że domyślny poziom 3 jest odpowiedni dla wielu przypadków użycia, ale od czasu do czasu dostosujemy go nieznacznie w zależności od tego, co jest naszym wąskim gardłem (często próbujemy nasycić połączenie sieciowe lub wrzeciono dysku); innym razem bardziej zależy nam na przechowywanym rozmiarze i użyjemy wyższego poziomu.
W ostatecznym rozrachunku, aby uzyskać wyniki najbardziej dostosowane do Twoich potrzeb, musisz wziąć pod uwagę zarówno sprzęt, którego używasz, jak i dane, na których Ci zależy – nie ma twardych i szybkich recept, które można wykonać bez kontekstu. Jeśli jednak masz wątpliwości, trzymaj się domyślnego poziomu 3 lub czegoś z zakresu od 6 do 9, aby uzyskać dobry kompromis między szybkością a przestrzenią; zachowaj poziom 20+ dla przypadków, w których naprawdę zależy Ci tylko na rozmiarze, a nie na szybkości kompresji.
Wypróbuj
Zstandard jest zarówno narzędziem wiersza poleceń (zstd), jak i biblioteką. Jest napisany w wysoce przenośnym języku C, co czyni go odpowiednim dla praktycznie każdej używanej obecnie platformy – czy to serwerów, na których działa Twoja firma, laptopa, czy nawet telefonu w Twojej kieszeni. Możesz go pobrać z naszego repozytorium na githubie, skompilować za pomocą prostego make install i zacząć go używać tak, jak używałbyś gzip:
$ zstd access.logaccess.log : 8.07% (6695078 => 540336 bytes, access.log.zst)Jak można się spodziewać, możesz go używać jako części potoku poleceń, na przykład do tworzenia kopii zapasowej krytycznej bazy danych MySQL:
$ mysqldump --single-transaction --opt pokemon | zstd -q -o /srv/backups/mysqldump.sql.zstPolecenie tar obsługuje różne implementacje kompresji out-of-box, więc po zainstalowaniu Zstandard możesz od razu pracować z tarballami skompresowanymi za pomocą Zstandard. Oto prosty przykład, który pokazuje użycie tar i różnicę prędkości w porównaniu z gzip:
$ time tar -I zstd -cf linux-4.6.4.tar.zst linux-4.6.4tar -I zstd -cf linux-4.6.4.tar.zst linux-4.6.4 3.15s user 0.50s system 107% cpu 3.396 total$ time tar -zcf linux-4.6.4.tar.gz linux-4.6.4tar -zcf linux-4.6.4.tar.gz linux-4.6.4 13.74s user 0.43s system 102% cpu 13.784 totalPoza użyciem w linii poleceń, istnieją interfejsy API, udokumentowane w plikach nagłówkowych w repozytorium (zacznij tutaj, aby zapoznać się z interfejsami API). Dołączamy także API wrappera kompatybilnego z zlibem (libWrapper) dla łatwiejszej integracji z narzędziami, które już mają interfejsy zlibowe. Wreszcie, dołączamy wiele przykładów, zarówno podstawowego użycia, jak i bardziej zaawansowanych, takich jak słowniki i strumieniowanie, również w repozytorium GitHub.
Więcej w przyszłości
Pomimo że osiągnęliśmy 1.0 i uważamy Zstandard za gotowy do każdego rodzaju produkcyjnego użycia, nie skończyliśmy. W przyszłych wersjach:
- Wielowątkowa kompresja w wierszu poleceń dla jeszcze większej przepustowości dużych zbiorów danych, podobna do narzędzia pigz dla zlib.
- Nowe poziomy kompresji, w obu kierunkach, pozwalające na jeszcze szybszą kompresję i wyższe współczynniki.
- Zarządzany przez społeczność predefiniowany zestaw słowników kompresji dla typowych zbiorów danych, takich jak JSON, HTML i typowe protokoły sieciowe.
Chcielibyśmy podziękować wszystkim współtwórcom, zarówno kodu, jak i opinii, którzy pomogli nam dotrzeć do wersji 1.0. To jest dopiero początek. Wiemy, że aby Zstandard mógł sprostać swojemu potencjałowi, potrzebujemy Twojej pomocy. Jak wspomniano powyżej, możesz wypróbować Zstandard już dziś, pobierając źródło lub wstępnie zbudowane binarki z naszego projektu na GitHubie, lub, dla użytkowników Maca, instalując poprzez homebrew (brew install zstd). Będziemy wdzięczni za wszelkie opinie i ciekawe przypadki użycia, jak również za dodatkowe wiązania językowe i pomoc w integracji z Twoimi ulubionymi projektami open source.
Przypisy
- Choć bezstratna kompresja danych jest głównym tematem tego wpisu, istnieje pokrewna, ale bardzo odmienna dziedzina stratnej kompresji danych, używana głównie do obrazów, audio i wideo.
- Deflate, zlib, gzip – trzy nazwy splecione ze sobą. Deflate jest algorytmem używanym przez implementacje zlib i gzip. Zlib jest biblioteką udostępniającą Deflate, a gzip jest narzędziem wiersza poleceń, które używa zlib do deflacji danych, jak również do sum kontrolnych. To sumowanie kontrolne może mieć znaczny narzut.
- Wszystkie testy zostały przeprowadzone na procesorze Intel E5-2678 v3 pracującym z częstotliwością 2,5 GHz na maszynie Centos 7. Narzędzia wiersza poleceń (
zstdigzip) zostały zbudowane przy użyciu systemu GCC, 4.8.5. Benchmarki algorytmów wykonywane przez lzbench zostały zbudowane przy użyciu GCC 6.
.
Dodaj komentarz