W tym poście przyjrzymy się najczęściej stosowanym algorytmom uczenia maszynowego. Istnieje ogromna ich różnorodność i łatwo poczuć się zdezorientowanym słysząc takie terminy jak „instance-based learning algorithms” czy „perceptron”.
Zwykle wszystkie algorytmy uczenia maszynowego są dzielone na grupy w oparciu o ich styl uczenia się, funkcję lub problemy, które rozwiązują. W tym poście znajdziesz klasyfikację opartą na stylu uczenia się. Wymienię również wspólne zadania, które te algorytmy pomagają rozwiązać.
Liczba algorytmów uczenia maszynowego, które są używane dzisiaj jest duża i nie wymienię 100% z nich. Chciałbym jednak przedstawić przegląd najczęściej używanych.
- Algorytmy uczenia nadzorowanego
- Algorytmy klasyfikacyjne
- Naiwny Bayes
- Multinomial Naive Bayes
- Regresja logistyczna
- Drzewa decyzyjne
- SVM (Support Vector Machine)
- Algorytmy regresji
- Regresja liniowa
- Algorytmy uczenia nienadzorowanego
- Klastrowanie
- K-means clustering
- K-nearest neighbor
- Redukcja wymiarowości
- Uczenie reguł asocjacyjnych
- Uczenie wzmacniające
- Q-Learning
- Ensemble learning
- Bagging
- Boosting
- Lasy losowe
- Stacking
- Sieci neuronowe
- Wnioski
Algorytmy uczenia nadzorowanego

Jeśli nie jesteś zaznajomiony z takimi terminami jak „uczenie nadzorowane” i „uczenie nienadzorowane”, sprawdź nasz post AI vs ML, gdzie ten temat został szczegółowo omówiony. Teraz zapoznajmy się z algorytmami.
Algorytmy klasyfikacyjne
Naiwny Bayes

Algorytmy bayesowskie to rodzina klasyfikatorów probabilistycznych wykorzystywanych w ML w oparciu o zastosowanie twierdzenia Bayesa.
Naiwny klasyfikator Bayesa był jednym z pierwszych algorytmów stosowanych w uczeniu maszynowym. Nadaje się on do klasyfikacji binarnej i wieloklasowej oraz pozwala na dokonywanie predykcji i prognozowanie danych na podstawie wyników historycznych. Klasycznym przykładem są systemy filtrowania spamu, które do 2010 roku wykorzystywały Naive Bayes i osiągały zadowalające wyniki. Jednak gdy wynaleziono zatrucie Bayesa, programiści zaczęli myśleć o innych sposobach filtrowania danych.
Używając twierdzenia Bayesa, można powiedzieć, jak wystąpienie zdarzenia wpływa na prawdopodobieństwo innego zdarzenia.
Na przykład ten algorytm oblicza prawdopodobieństwo, że dany e-mail jest lub nie jest spamem na podstawie typowych użytych słów. Typowe słowa spamu to „oferta”, „zamów teraz” lub „dodatkowy dochód”. Jeśli algorytm wykryje te słowa, istnieje duże prawdopodobieństwo, że wiadomość jest spamem.
Naive Bayes zakłada, że cechy są niezależne. Dlatego algorytm ten nazywany jest naiwnym.
Multinomial Naive Bayes
Oprócz klasyfikatora Naive Bayes, w tej grupie znajdują się również inne algorytmy. Na przykład Multinomial Naive Bayes, który jest zwykle stosowany do klasyfikacji dokumentów na podstawie częstotliwości występowania określonych słów w dokumencie.
Algorytmy bayesowskie są nadal używane do kategoryzacji tekstu i wykrywania oszustw. Mogą być również stosowane do wizji maszynowej (na przykład wykrywania twarzy), segmentacji rynku i bioinformatyki.
Regresja logistyczna
Nawet mimo że nazwa może wydawać się sprzeczna z intuicją, regresja logistyczna jest w rzeczywistości rodzajem algorytmu klasyfikacyjnego.
Regresja logistyczna to model, który dokonuje przewidywań przy użyciu funkcji logistycznej w celu znalezienia zależności między zmiennymi wyjściowymi i wejściowymi. Statquest przygotował świetny film, w którym wyjaśnia różnicę między regresją liniową a logistyczną, biorąc za przykład otyłe myszy.
Drzewa decyzyjne
Drzewo decyzyjne to prosty sposób na wizualizację modelu decyzyjnego w postaci drzewa. Zaletami drzew decyzyjnych jest to, że są one łatwe do zrozumienia, interpretacji i wizualizacji. Wymagają również niewielkiego wysiłku przy przygotowaniu danych.
Jednakże, mają również dużą wadę. Drzewa mogą być niestabilne z powodu nawet najmniejszych zmian (wariancji) w danych. Możliwe jest również tworzenie zbyt skomplikowanych drzew, które nie generalizują dobrze. Nazywa się to przepasowaniem (overfitting). Woreczkowanie, boosting i regularizacja pomagają zwalczyć ten problem. Będziemy o nich mówić w dalszej części wpisu.
Elementy każdego drzewa decyzyjnego to:
- Węzeł główny, który zadaje główne pytanie. Ma on strzałki skierowane w dół od niego, ale nie ma strzałek skierowanych do niego. Na przykład wyobraź sobie, że budujesz drzewo do podjęcia decyzji, jaki rodzaj makaronu powinieneś zjeść na obiad.
- Gałęzie. Podsekcja drzewa nazywana jest gałęzią lub czasami poddrzewem.
- Węzły decyzyjne. Są to węzły podrzędne dla węzła głównego, które mogą być również podzielone na więcej węzłów. Twoje węzły decyzji mogą być „carbonara?” lub „z grzybami?”.
- Węzły liści lub węzły końcowe. Te węzły nie dzielą się. Reprezentują one ostateczne decyzje lub przewidywania.
Ważne jest również wspomnieć o dzieleniu. Jest to proces dzielenia węzła na węzły podrzędne. Na przykład, jeśli nie jesteś wegetarianinem, carbonara jest w porządku. Ale jeśli jesteś, zjedz makaron z grzybami. Istnieje również proces usuwania węzłów zwany przycinaniem.
Algorytmy drzew decyzyjnych są określane jako CART (Classification and Regression Trees). Drzewa decyzyjne mogą pracować z danymi kategorycznymi lub numerycznymi.
- Drzewa regresyjne są stosowane, gdy zmienne mają wartość numeryczną.
- Drzewa klasyfikacyjne mogą być stosowane, gdy dane są kategoryczne (klasy).
Drzewa decyzyjne są dość intuicyjne w zrozumieniu i użyciu. Dlatego też diagramy drzew są powszechnie stosowane w wielu branżach i dyscyplinach. GreyAtom zapewnia szeroki przegląd różnych typów drzew decyzyjnych i ich praktycznych zastosowań.
SVM (Support Vector Machine)
Support vector machines to kolejna grupa algorytmów używanych do zadań klasyfikacji i, czasami, regresji. SVM jest świetny, ponieważ daje dość dokładne wyniki przy minimalnej mocy obliczeniowej.
Celem SVM jest znalezienie hiperpłaszczyzny w N-wymiarowej przestrzeni (gdzie N odpowiada liczbie cech), która wyraźnie klasyfikuje punkty danych. Dokładność wyników jest bezpośrednio skorelowana z hiperpłaszczyzną, którą wybierzemy. Powinniśmy znaleźć płaszczyznę, która ma maksymalną odległość między punktami danych obu klas.
Ta hiperpłaszczyzna jest graficznie reprezentowana jako linia, która oddziela jedną klasę od drugiej. Punkty danych, które leżą po różnych stronach hiperpłaszczyzny są przypisywane do różnych klas.
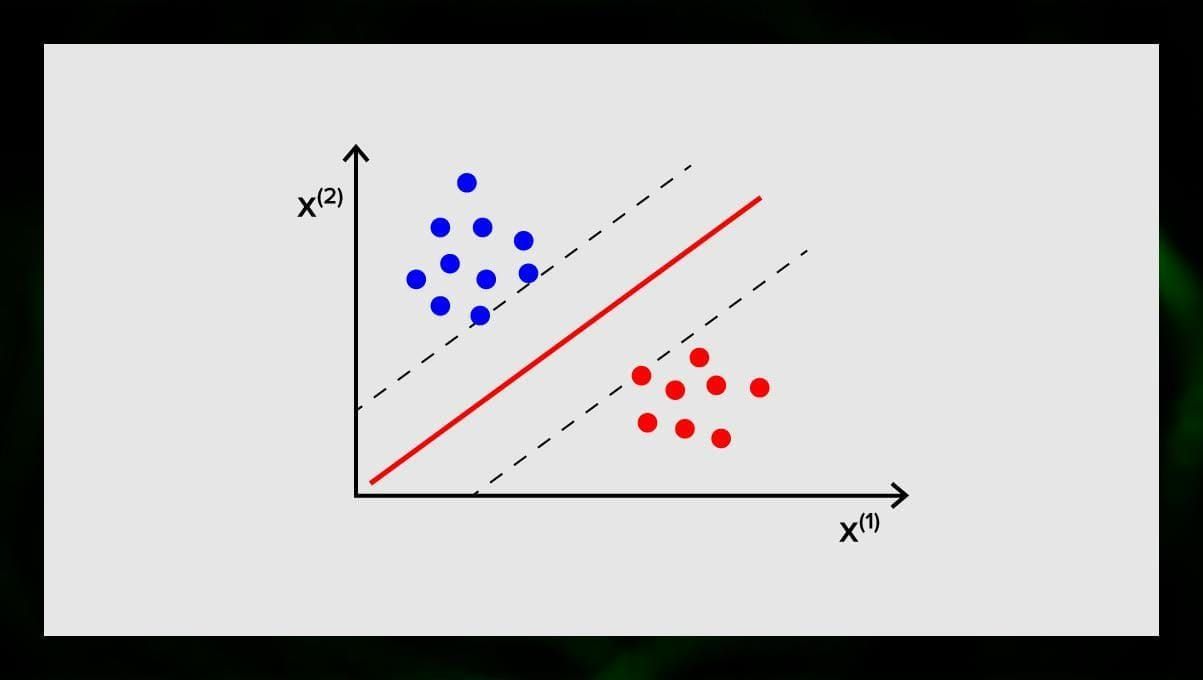
Zauważ, że wymiar hiperpłaszczyzny zależy od liczby cech. Jeżeli liczba cech wejściowych wynosi 2, to hiperpłaszczyzna jest tylko linią. Jeżeli liczba cech wejściowych wynosi 3, to hiperpłaszczyzna staje się dwuwymiarową płaszczyzną. Trudno jest narysować model na wykresie, gdy liczba cech jest większa niż 3. Tak więc w tym przypadku będziesz używał typów Kernel, aby przekształcić go w przestrzeń trójwymiarową.
Dlaczego nazywa się to maszyną wektorów podporowych? Wektory wsparcia to punkty danych najbliższe hiperpłaszczyźnie. Wpływają one bezpośrednio na położenie i orientację hiperpłaszczyzny i pozwalają nam zmaksymalizować margines klasyfikatora. Usunięcie wektorów wsparcia spowoduje zmianę położenia hiperpłaszczyzny. Są to punkty, które pomagają nam zbudować naszą SVM.
SVM są obecnie aktywnie wykorzystywane w diagnostyce medycznej do wyszukiwania anomalii, w systemach kontroli jakości powietrza, do analizy finansowej i przewidywań na giełdzie oraz kontroli błędów maszyn w przemyśle.
Algorytmy regresji
Algorytmy regresji są przydatne w analityce, na przykład gdy próbujesz przewidzieć koszty papierów wartościowych lub sprzedaży danego produktu w określonym czasie.
Regresja liniowa
Regresja liniowa próbuje modelować związek między zmiennymi poprzez dopasowanie równania liniowego do obserwowanych danych.
Są zmienne objaśniające i zmienne zależne. Zmienne zależne to rzeczy, które chcemy wyjaśnić lub przewidzieć. Objaśniające, jak wynika z nazwy, coś wyjaśniają. Jeśli chcesz zbudować regresję liniową, zakładasz, że istnieje liniowa zależność między zmiennymi zależnymi i niezależnymi. Na przykład, istnieje korelacja między metrami kwadratowymi domu i jego ceną lub gęstością zaludnienia i miejscami na kebab w okolicy.
Po przyjęciu tego założenia, musisz następnie dowiedzieć się, jaka jest konkretna relacja liniowa. Będziesz musiał znaleźć równanie regresji liniowej dla zestawu danych. Ostatnim krokiem jest obliczenie reszty.
Uwaga: Gdy regresja rysuje linię prostą, nazywa się liniową, gdy jest krzywą – wielomianową.
Algorytmy uczenia nienadzorowanego

Teraz porozmawiajmy o algorytmach, które są w stanie znaleźć ukryte wzorce w nieoznakowanych danych.
Klastrowanie
Klastrowanie oznacza, że dzielimy dane wejściowe na grupy według stopnia ich podobieństwa do siebie. Klasteryzacja jest zazwyczaj jednym z kroków do budowy bardziej złożonego algorytmu. Prościej jest badać każdą grupę osobno i budować model w oparciu o ich cechy, niż pracować ze wszystkim naraz. Ta sama technika jest stale wykorzystywana w marketingu i sprzedaży do rozbicia wszystkich potencjalnych klientów na grupy.
Bardzo popularnymi algorytmami klasteryzacji są k-means clustering i k-nearest neighbor.
K-means clustering
K-means clustering dzieli zbiór elementów przestrzeni wektorowej na predefiniowaną liczbę klastrów k. Nieprawidłowa liczba klastrów unieważni jednak cały proces, dlatego ważne jest, aby próbować ze zmienną liczbą klastrów. Główna idea algorytmu k-średnich polega na tym, że dane są losowo dzielone na klastry, a następnie iteracyjnie przeliczany jest środek każdego klastra uzyskany w poprzednim kroku. Następnie wektory są ponownie dzielone na klastry. Algorytm zatrzymuje się, gdy w pewnym momencie nie ma zmian w klastrach po iteracji.
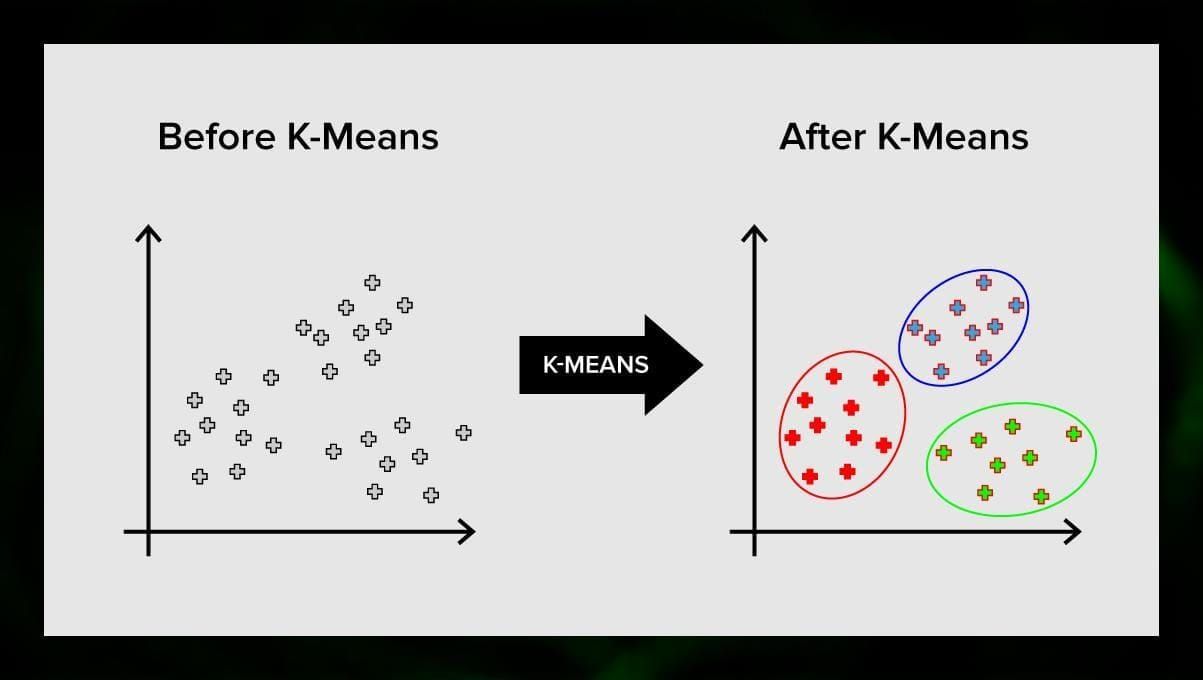
Metoda ta może być stosowana do rozwiązywania problemów, gdy klastry są odrębne lub mogą być łatwo oddzielone od siebie, bez nakładających się danych.
K-nearest neighbor
kNN oznacza k-nearest neighbor. Jest to jeden z najprostszych algorytmów klasyfikacyjnych wykorzystywany czasami w zadaniach regresji.
Aby wytrenować klasyfikator, należy dysponować zbiorem danych z predefiniowanymi klasami. Oznaczanie odbywa się ręcznie z udziałem specjalistów z badanej dziedziny. Za pomocą tego algorytmu możliwa jest praca z wieloma klasami lub wyjaśnienie sytuacji, w których dane wejściowe należą do więcej niż jednej klasy.
Metoda opiera się na założeniu, że podobne etykiety odpowiadają bliskim obiektom w przestrzeni wektorów atrybutów.
Nowoczesne systemy oprogramowania wykorzystują kNNN do wizualnego rozpoznawania wzorców, na przykład do skanowania i wykrywania ukrytych paczek na dnie koszyka przy kasie (na przykład AmazonGo). Algorytmy kNN analizują wszystkie dane i zauważają nietypowe wzorce, które wskazują na podejrzaną aktywność.
Redukcja wymiarowości
Analiza składowych głównych (PCA) jest ważną techniką, którą należy zrozumieć, aby skutecznie rozwiązywać problemy związane z ML.
Wyobraź sobie, że masz wiele zmiennych do rozważenia. Na przykład musisz sklasyfikować miasta w trzy grupy: dobre do życia, złe do życia i takie sobie. Jak wiele zmiennych musisz wziąć pod uwagę? Prawdopodobnie bardzo dużo. Czy rozumiesz zależności między nimi? Nie bardzo. Więc jak możesz wziąć wszystkie zmienne, które zebrałeś i skupić się tylko na kilku z nich, które są najważniejsze?
W kategoriach technicznych, chcesz „zmniejszyć wymiar swojej przestrzeni cech”. Zmniejszając wymiar swojej przestrzeni cech, udaje ci się uzyskać mniej zależności między zmiennymi do rozważenia i istnieje mniejsze prawdopodobieństwo, że przepasujesz swój model.
Istnieje wiele sposobów na osiągnięcie redukcji wymiarowości, ale większość z tych technik należy do jednej z dwóch klas:
- Eliminacja cech;
- Ekstrakcja cech.
Eliminacja cech oznacza, że zmniejszasz liczbę cech poprzez wyeliminowanie niektórych z nich. Zaletą tej metody jest to, że jest prosta i zachowuje interpretowalność zmiennych. Jako wadę, chociaż, otrzymujesz zero informacji od zmiennych, które zdecydowałeś się usunąć.
Eksploracja cech pozwala uniknąć tego problemu. Celem przy zastosowaniu tej metody jest wyodrębnienie zestawu cech z danego zbioru danych. Ekstrakcja cech ma na celu zredukowanie liczby cech w zbiorze danych poprzez stworzenie nowych cech na podstawie istniejących (a następnie odrzucenie oryginalnych cech). Nowy zredukowany zbiór cech musi być stworzony w taki sposób, aby był w stanie podsumować większość informacji zawartych w oryginalnym zbiorze cech.
Pierwotna analiza składowych jest algorytmem ekstrakcji cech. łączy ona zmienne wejściowe w określony sposób, a następnie możliwe jest porzucenie „najmniej ważnych” zmiennych przy jednoczesnym zachowaniu najbardziej wartościowych części wszystkich zmiennych.
Jednym z możliwych zastosowań PCA jest sytuacja, gdy obrazy w zbiorze danych są zbyt duże. Zredukowana reprezentacja cech pomaga szybko uporać się z zadaniami takimi jak dopasowywanie i wyszukiwanie obrazów.
Uczenie reguł asocjacyjnych
Apriori jest jednym z najpopularniejszych algorytmów wyszukiwania reguł asocjacyjnych. Jest on w stanie przetwarzać duże ilości danych w stosunkowo niewielkim czasie.
Sęk w tym, że bazy danych wielu projektów są dziś bardzo duże, sięgają gigabajtów i terabajtów. I będą nadal rosły. Dlatego potrzebny jest efektywny, skalowalny algorytm do znajdowania reguł asocjacyjnych w krótkim czasie. Apriori jest jednym z takich algorytmów.
Aby móc zastosować ten algorytm, należy przygotować dane, konwertując je wszystkie do postaci binarnej i zmieniając ich strukturę danych.
Zwykle operuje się tym algorytmem na bazie danych zawierającej dużą liczbę transakcji, na przykład na bazie danych zawierającej informacje o wszystkich artykułach, które klienci kupili w supermarkecie.
Uczenie wzmacniające

Uczenie wzmacniające jest jedną z metod uczenia maszynowego, która pomaga nauczyć maszynę, jak wchodzić w interakcje z pewnym środowiskiem. W tym przypadku, środowisko (na przykład w grze wideo) służy jako nauczyciel. Dostarcza ono informacji zwrotnych do decyzji podejmowanych przez komputer. Na podstawie tej nagrody maszyna uczy się obierać najlepszy kierunek działania. Przypomina to sposób, w jaki dzieci uczą się, aby nie dotykać gorącej patelni – poprzez próby i odczuwanie bólu.
Rozkładając ten proces na czynniki pierwsze, obejmuje on następujące proste kroki:
- Komputer obserwuje środowisko;
- Wybiera pewną strategię;
- Działa zgodnie z tą strategią;
- Otrzymuje nagrodę lub karę;
- Uczy się na podstawie tego doświadczenia i udoskonala strategię;
- Powtarza to aż do znalezienia optymalnej strategii.
Q-Learning
Istnieje kilka algorytmów, które mogą być użyte do Reinforcement learning. Jednym z najbardziej popularnych jest Q-learning.
Q-learning jest bezmodelowym algorytmem uczenia wzmacniającego. Q-learning opiera się na wynagrodzeniu otrzymywanym od otoczenia. Agent tworzy funkcję użyteczności Q, która następnie daje mu możliwość wyboru strategii zachowania, oraz uwzględnia doświadczenia z poprzednich interakcji ze środowiskiem.
Jedną z zalet uczenia Q jest możliwość porównania oczekiwanej użyteczności dostępnych działań bez tworzenia modeli środowiska.
Ensemble learning

Ensemble learning jest metodą rozwiązywania problemu poprzez budowanie wielu modeli ML i łączenie ich. Uczenie grupowe jest głównie używane do poprawy wydajności modeli klasyfikacji, predykcji i aproksymacji funkcji. Inne zastosowania uczenia zespołowego obejmują sprawdzanie decyzji podejmowanych przez model, wybór optymalnych cech do budowy modeli, uczenie przyrostowe oraz uczenie niestacjonarne.
Poniżej przedstawiono niektóre z częściej stosowanych algorytmów uczenia zespołowego.
Bagging
Bagging oznacza agregację bootstrapową. Jest to jeden z najwcześniejszych algorytmów grupujących, o zaskakująco dobrej wydajności. Aby zagwarantować różnorodność klasyfikatorów, używasz bootstrapowanych replik danych treningowych. Oznacza to, że różne podzbiory danych treningowych są losowane – z zastąpieniem – z zestawu danych treningowych. Każdy podzbiór danych treningowych jest wykorzystywany do trenowania innego klasyfikatora tego samego typu. Następnie, poszczególne klasyfikatory mogą być łączone. Aby to zrobić, należy podjąć zwykłą większość głosów na ich decyzje. Klasa, która została przypisana przez większość klasyfikatorów, jest decyzją ensemble.
Boosting
Ta grupa algorytmów ensemble jest podobna do bagging. Boosting również używa różnych klasyfikatorów do ponownego próbkowania danych, a następnie wybiera optymalną wersję przez głosowanie większościowe. W boostingu iteracyjnie trenuje się słabe klasyfikatory, aby złożyć je w silny klasyfikator. Kiedy klasyfikatory są dodawane, zazwyczaj przypisywane są im pewne wagi, które opisują dokładność ich przewidywań. Po dodaniu słabego klasyfikatora do zespołu, wagi są ponownie obliczane. Błędnie sklasyfikowane wejścia zyskują większą wagę, a poprawnie sklasyfikowane instancje tracą wagę. W ten sposób system koncentruje się bardziej na przykładach, w których uzyskano błędną klasyfikację.
Lasy losowe
Lasy losowe lub losowe lasy decyzyjne to metoda uczenia zespołowego do klasyfikacji, regresji i innych zadań. Aby zbudować las losowy, należy wytrenować wiele drzew decyzyjnych na losowych próbkach danych szkoleniowych. Wyjściem lasu losowego jest najczęstszy wynik wśród poszczególnych drzew. Losowe lasy decyzyjne skutecznie zwalczają przepełnienie dzięki _losowej _naturze algorytmu.
Stacking
Stacking jest techniką uczenia zespołowego, która łączy wiele modeli klasyfikacji lub regresji poprzez meta-klasyfikator lub meta-regresor. Modele poziomu bazowego są trenowane w oparciu o kompletny zestaw treningowy, a następnie meta-model jest trenowany na wyjściach modeli poziomu bazowego jako cechach.
Sieci neuronowe
Sieć neuronowa jest sekwencją neuronów połączonych synapsami, która przypomina strukturę ludzkiego mózgu. Jednak ludzki mózg jest jeszcze bardziej złożona.
Co jest wspaniałe o sieci neuronowych jest to, że mogą one być używane do w zasadzie każdego zadania z filtrowania spamu do widzenia komputerowego. Jednak są one zazwyczaj stosowane do tłumaczenia maszynowego, wykrywania anomalii i zarządzania ryzykiem, rozpoznawania mowy i generowania języka, rozpoznawania twarzy i więcej.
Sieć neuronowa składa się z neuronów lub węzłów. Każdy z tych neuronów odbiera dane, przetwarza je, a następnie przekazuje do innego neuronu.
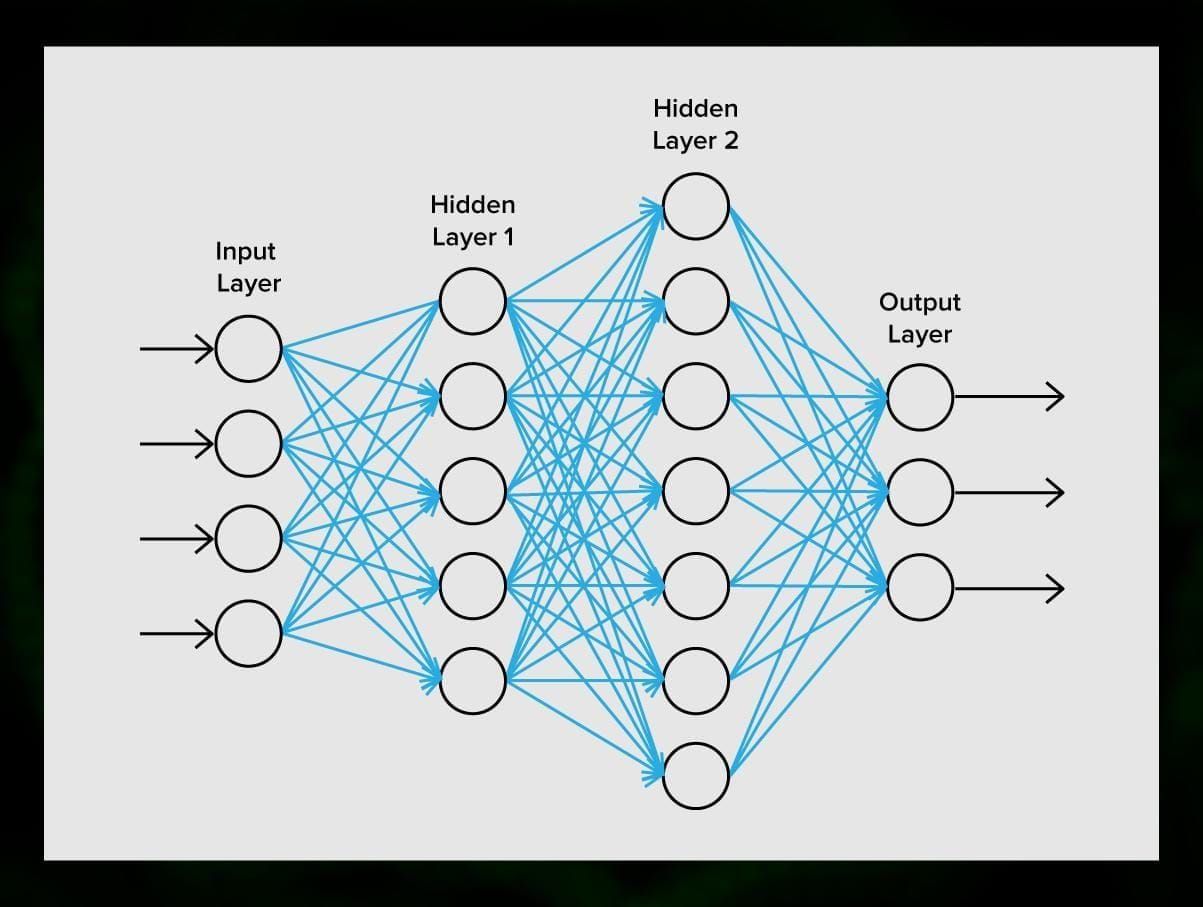
Każdy neuron przetwarza sygnały w ten sam sposób. Ale jak w takim razie otrzymujemy inny wynik? Odpowiedzialne są za to synapsy, które łączą neurony ze sobą. Każdy neuron jest w stanie posiadać wiele synaps, które tłumią lub wzmacniają sygnał. Ponadto, neurony są w stanie zmieniać swoje właściwości w czasie. Dobierając odpowiednie parametry synaps, będziemy w stanie uzyskać prawidłowe wyniki przekształcenia informacji wejściowej na wyjściu.
Istnieje wiele różnych typów NN:
- Sieci neuronowe typu FP (FF lub FFNN) i perceptrony § są bardzo proste, nie ma w nich pętli ani cykli. W praktyce takie sieci są rzadko stosowane, ale często łączy się je z innymi typami w celu uzyskania nowych sieci.
- Sieć Hopfielda (HN) jest w pełni połączoną siecią neuronową o symetrycznej macierzy połączeń. Taka sieć jest często nazywana siecią pamięci asocjacyjnej. Podobnie jak osoba, która widząc jedną połowę stołu, potrafi wyobrazić sobie drugą, sieć ta, otrzymując zaszumioną tabelę, przywraca ją do stanu pełnego.
- Konwolucyjne sieci neuronowe (CNN) i głębokie konwolucyjne sieci neuronowe (DCNN) znacznie różnią się od innych typów sieci. Są one zwykle używane do przetwarzania obrazów, audio lub zadań związanych z wideo. Typowym sposobem zastosowania CNN jest klasyfikowanie obrazów.
Wiele różnych typów sieci neuronowych jest interesujących do obserwowania. Można to zrobić w zoo NN.
Wnioski
Ten post jest szerokim przeglądem różnych algorytmów ML, ale wciąż jest wiele do powiedzenia. Bądź na bieżąco z naszym Twitterem, Facebookiem i Medium, aby uzyskać więcej poradników i postów na temat ekscytujących możliwości uczenia maszynowego.
.
Dodaj komentarz