Posiadanie wglądu w swoją aplikację Java jest kluczowe dla zrozumienia, jak działa ona teraz, jak działała w przeszłości i zwiększenia zrozumienia tego, jak może działać w przyszłości. Częściej niż nie, analiza logów jest najszybszym sposobem na wykrycie tego, co poszło nie tak, co czyni logowanie w Javie krytycznym dla zapewnienia wydajności i zdrowia aplikacji, a także minimalizuje i redukuje wszelkie przestoje. Posiadanie scentralizowanego logowania i monitorowania rozwiązania pomaga zmniejszyć Mean Time To Repair poprzez poprawę efektywności swojego zespołu Ops lub DevOps.
Podążając za dobrymi praktykami, otrzymasz więcej wartości z dzienników i ułatwisz ich wykorzystanie. Będziesz w stanie łatwiej wskazać pierwotną przyczynę błędów i słabej wydajności oraz rozwiązać problemy, zanim wpłyną one na użytkowników końcowych. Tak więc dzisiaj, pozwól mi podzielić się kilkoma najlepszymi praktykami, które powinieneś stosować podczas pracy z aplikacjami Java.
- Użyj standardowej biblioteki logowania
- Wybierz mądrze swoje apendyksy
- Use Meaningful Messages
- Logowanie śladów stosu Java
- Logowanie wyjątków Javy
- Używaj odpowiedniego poziomu logów
- Log in JSON
- Keep the Log Structure Consistent
- Add Context to Your Logs
- Java Logging in Containers
- Don’t Log Too Much or Too Little
- Keep the Audience in Mind
- Unikaj logowania wrażliwych informacji
- Use a Log Management Solution to Centralize & Monitor Java Logs
- Konkluzja
- Udział
Użyj standardowej biblioteki logowania
Logowanie w Javie może być wykonane na kilka różnych sposobów. Można użyć dedykowanej biblioteki logowania, wspólnego API, a nawet po prostu zapisywać logi do pliku lub bezpośrednio do dedykowanego systemu logowania. Jednak przy wyborze biblioteki logowania dla swojego systemu należy myśleć perspektywicznie. Rzeczy, które należy rozważyć i ocenić to wydajność, elastyczność, appendery dla nowych rozwiązań centralizacji logów, i tak dalej. Jeśli przywiązujesz się bezpośrednio do jednego frameworka, przejście na nowszą bibliotekę może wymagać znacznego nakładu pracy i czasu. Miej to na uwadze i wybierz API, które da Ci elastyczność w zamianie bibliotek logowania w przyszłości. Podobnie jak w przypadku przejścia z Log4j na Logback i na Log4j 2, podczas korzystania z SLF4J API jedyną rzeczą, którą musisz zrobić, jest zmiana zależności, a nie kodu.
Jeśli jesteś nowy w bibliotekach logowania Java, sprawdź nasze przewodniki dla początkujących:
- Log4j Tutorial
- Logback Tutorial
- Log4j2 Tutorial
- SLF4J Tutorial
Wybierz mądrze swoje apendyksy
Apendyksy określają, gdzie będą dostarczane zdarzenia dziennika. Najbardziej powszechne apendyksy to Console i File Appenders. Chociaż są one użyteczne i powszechnie znane, mogą nie spełniać twoich wymagań. Na przykład, możesz chcieć pisać swoje logi w sposób asynchroniczny lub możesz chcieć wysyłać logi przez sieć używając apenderów takich jak ten dla Syslog, jak poniżej:
<Appenders> <Console name="Console" target="SYSTEM_OUT"> <PatternLayout pattern="%d %level %c - %m%n"/> </Console> <Syslog name="Syslog" host="logsene-syslog-receiver.sematext.com" port="514" protocol="TCP" format="RFC5424" appName="11111111-2222-3333-4444-555555555555" facility="LOCAL0" mdcId="mdc" newLine="true"/></Appenders>
Należy jednak pamiętać, że używanie apenderów takich jak ten pokazany powyżej sprawia, że Twój potok logowania jest podatny na błędy sieciowe i zakłócenia komunikacji. Może to spowodować, że logi nie zostaną wysłane do miejsca przeznaczenia, co może być niedopuszczalne. Chcesz również uniknąć wpływu logowania na system, jeśli appender jest zaprojektowany w sposób blokujący. Aby dowiedzieć się więcej sprawdź nasz wpis na blogu Logging libraries vs Log shippers.
Use Meaningful Messages
Jedną z kluczowych rzeczy jeśli chodzi o tworzenie logów, a jednocześnie jedną z nie tak łatwych jest używanie znaczących wiadomości. Twoje zdarzenia w logach powinny zawierać wiadomości, które są unikalne dla danej sytuacji, jasno je opisywać i informować osobę je czytającą. Wyobraź sobie, że w Twojej aplikacji wystąpił błąd komunikacji. Mógłbyś to zrobić w ten sposób:
LOGGER.warn("Communication error");
Ale mógłbyś również stworzyć komunikat w ten sposób:
LOGGER.warn("Error while sending documents to events Elasticsearch server, response code %d, response message %s. The message sending will be retried.", responseCode, responseMessage);
Łatwo zauważyć, że pierwszy komunikat będzie informował osobę przeglądającą logi o problemach z komunikacją. Osoba ta prawdopodobnie będzie miała kontekst, nazwę loggera oraz numer linii, w której wystąpiło ostrzeżenie, ale to wszystko. Aby uzyskać więcej kontekstu, osoba ta musiałaby spojrzeć na kod, wiedzieć, z którą wersją kodu związany jest błąd, i tak dalej. To nie jest zabawne i często nie jest łatwe, a na pewno nie jest to coś, co chce się robić podczas próby rozwiązania problemu produkcyjnego tak szybko, jak to możliwe.
Druga wiadomość jest lepsza. Dostarcza dokładnych informacji o tym, jaki rodzaj błędu komunikacji wystąpił, co aplikacja robiła w tym czasie, jaki kod błędu otrzymała i jaka była odpowiedź ze zdalnego serwera. Na koniec informuje również, że wysłanie wiadomości zostanie ponowione. Praca z takimi komunikatami jest zdecydowanie łatwiejsza i przyjemniejsza.
Na koniec zastanów się nad rozmiarem i dosłownością komunikatu. Nie zapisuj w dzienniku informacji, które są zbyt obszerne. Te dane muszą być gdzieś przechowywane, aby mogły być użyteczne. Jedna bardzo długa wiadomość nie będzie problemem, ale jeśli ta linia powtarza się setki razy w ciągu minuty i masz wiele pełnych logów, dłuższe przechowywanie takich danych może być problematyczne, a na koniec dnia będzie również kosztować więcej.
Logowanie śladów stosu Java
Jedną z bardzo ważnych części logowania Java są ślady stosu Java. Spójrz na następujący kod:
package com.sematext.blog.logging;import org.apache.logging.log4j.LogManager;import org.apache.logging.log4j.Logger;import java.io.IOException;public class Log4JExceptionNoThrowable { private static final Logger LOGGER = LogManager.getLogger(Log4JExceptionNoThrowable.class); public static void main(String args) { try { throw new IOException("This is an I/O error"); } catch (IOException ioe) { LOGGER.error("Error while executing main thread"); } }}
Powyższy kod spowoduje rzucenie wyjątku, a komunikat dziennika, który zostanie wydrukowany na konsolę z naszą domyślną konfiguracją będzie wyglądał następująco:
11:42:18.952 ERROR - Error while executing main thread
Jak widać nie ma tam zbyt wielu informacji. Wiemy tylko, że wystąpił problem, ale nie wiemy gdzie to się stało, ani na czym polegał problem itp. Nie jest to zbyt pouczające.
Teraz spójrz na ten sam kod z nieco zmodyfikowaną deklaracją logowania:
package com.sematext.blog.logging;import org.apache.logging.log4j.LogManager;import org.apache.logging.log4j.Logger;import java.io.IOException;public class Log4JException { private static final Logger LOGGER = LogManager.getLogger(Log4JException.class); public static void main(String args) { try { throw new IOException("This is an I/O error"); } catch (IOException ioe) { LOGGER.error("Error while executing main thread", ioe); } }}
Jak widzisz, tym razem zawarliśmy sam obiekt wyjątku w naszym komunikacie dziennika:
LOGGER.error("Error while executing main thread", ioe);
To spowodowałoby następujący dziennik błędów w konsoli z naszą domyślną konfiguracją:
11:30:17.527 ERROR - Error while executing main threadjava.io.IOException: This is an I/O error at com.sematext.blog.logging.Log4JException.main(Log4JException.java:13)
Zawiera on istotne informacje – tj.tj. nazwę klasy, metodę, w której wystąpił problem, a także numer linii, w której wystąpił problem. Oczywiście, w rzeczywistych sytuacjach, ślady stosu będą dłuższe, ale powinieneś je zawrzeć, aby dać ci wystarczająco dużo informacji do prawidłowego debugowania.
Aby dowiedzieć się więcej o tym, jak obsługiwać ślady stosu Java z Logstash zobacz Handling Multiline Stack Traces with Logstash lub spójrz na Logagent, który może to zrobić dla ciebie po wyjęciu z pudełka.
Logowanie wyjątków Javy
Przy pracy z wyjątkami Javy i śladami stosu nie powinieneś myśleć tylko o całym śladzie stosu, liniach, w których pojawił się problem i tak dalej. Powinieneś również pomyśleć o tym, jak nie radzić sobie z wyjątkami.
Unikaj cichego ignorowania wyjątków. Nie chcesz zignorować czegoś ważnego. Na przykład, nie rób tego:
try { throw new IOException("This is an I/O error");} catch (IOException ioe) {}
Nie rejestruj też po prostu wyjątku i nie rzucaj go dalej. Oznacza to, że właśnie popchnąłeś problem w górę stosu wykonawczego. Unikaj również takich rzeczy:
try { throw new IOException("This is an I/O error");} catch (IOException ioe) { LOGGER.error("I/O error occurred during request processing", ioe); throw ioe;}
Jeśli chcesz dowiedzieć się więcej o wyjątkach, przeczytaj nasz przewodnik po obsłudze wyjątków w Javie, w którym omówimy wszystko, od tego, czym są, do tego, jak je łapać i naprawiać.
Używaj odpowiedniego poziomu logów
Podczas pisania kodu aplikacji zastanów się dwa razy nad danym komunikatem w logu. Nie każdy bit informacji jest tak samo ważny i nie każda nieoczekiwana sytuacja jest błędem lub komunikatem krytycznym. Należy również konsekwentnie stosować poziomy logowania – informacje podobnego typu powinny znajdować się na podobnym poziomie nasilenia.
Zarówno fasada SLF4J, jak i każdy framework logowania Javy, którego będziesz używać, dostarczają metod, które można wykorzystać do zapewnienia odpowiedniego poziomu logowania. Na przykład:
LOGGER.error("I/O error occurred during request processing", ioe);
Log in JSON
Jeśli planujemy logować i przeglądać dane ręcznie w pliku lub na standardowym wyjściu to planowane logowanie będzie bardziej niż w porządku. Jest to bardziej przyjazne dla użytkownika – jesteśmy do tego przyzwyczajeni. Ale to jest wykonalne tylko dla bardzo małych aplikacji i nawet wtedy sugerowane jest użycie czegoś, co pozwoli na korelację danych metrycznych z logami. Wykonywanie takich operacji w oknie terminala nie jest przyjemne, a czasami po prostu nie jest możliwe. Jeśli chcesz przechowywać logi w systemie zarządzania i centralizacji logów, powinieneś logować się w JSON. A to dlatego, że parsowanie nie jest za darmo – zazwyczaj oznacza to użycie wyrażeń regularnych. Oczywiście można zapłacić tę cenę w log shipperze, ale po co to robić, skoro można łatwo logować w JSON. Logowanie w JSON oznacza również łatwą obsługę śladów stosu, a więc jeszcze jedną zaletę. Cóż, można też po prostu logować się do miejsca docelowego zgodnego z Syslog, ale to już inna historia.
W większości przypadków, aby włączyć logowanie w JSON w swoim frameworku logowania Java, wystarczy włączyć odpowiednią konfigurację. Na przykład, załóżmy, że mamy następujący komunikat dziennika zawarty w naszym kodzie:
LOGGER.info("This is a log message that will be logged in JSON!");
Aby skonfigurować Log4J 2 do zapisywania komunikatów dziennika w JSON, załączylibyśmy następującą konfigurację:
<?xml version="1.0" encoding="UTF-8"?><Configuration status="WARN"> <Appenders> <Console name="Console" target="SYSTEM_OUT"> <JSONLayout compact="true" eventEol="true"> </JSONLayout> </Console> </Appenders> <Loggers> <Root level="info"> <AppenderRef ref="Console"/> </Root> </Loggers></Configuration>
Wynik wyglądałby następująco:
{"instant":{"epochSecond":1596030628,"nanoOfSecond":695758000},"thread":"main","level":"INFO","loggerName":"com.sematext.blog.logging.Log4J2JSON","message":"This is a log message that will be logged in JSON!","endOfBatch":false,"loggerFqcn":"org.apache.logging.slf4j.Log4jLogger","threadId":1,"threadPriority":5}
Keep the Log Structure Consistent
Struktura twoich zdarzeń dziennika powinna być spójna. Nie jest to prawdą tylko w obrębie jednej aplikacji lub zestawu mikroserwisów, ale powinno być stosowane w całym stosie aplikacji. Dzięki podobnej strukturze logów łatwiej będzie je przeglądać, porównywać, korelować lub po prostu przechowywać w dedykowanym magazynie danych. Łatwiej jest spojrzeć na dane pochodzące z systemów, gdy wiesz, że mają one wspólne pola, takie jak powaga i nazwa hosta, więc możesz łatwo kroić dane na podstawie tych informacji. Dla inspiracji, spójrz na Sematext Common Schema, nawet jeśli nie jesteś użytkownikiem Sematext.
Oczywiście, utrzymanie struktury nie zawsze jest możliwe, ponieważ twój pełny stos składa się z zewnętrznie opracowanych serwerów, baz danych, wyszukiwarek, kolejek itp. Każdy z nich ma swój własny zestaw logów i formatów logów. Aby jednak zachować zdrowy rozsądek swój i swojego zespołu, należy zminimalizować liczbę różnych struktur komunikatów dziennika, które można kontrolować.
Jednym ze sposobów na utrzymanie wspólnej struktury jest użycie tego samego wzorca dla logów, przynajmniej tych, które używają tego samego frameworka logowania. Na przykład, jeśli twoje aplikacje i mikroserwisy używają Log4J 2, możesz użyć wzorca takiego jak ten:
<PatternLayout> <Pattern>%d %p %c{35}:%L - %m%n</Pattern></PatternLayout>
Używając jednego lub bardzo ograniczonego zestawu wzorców, możesz być pewien, że liczba formatów dzienników pozostanie mała i możliwa do zarządzania.
Add Context to Your Logs
Kontekst informacji jest ważny, a dla nas, deweloperów i DevOps, wiadomość dziennika jest informacją. Spójrz na następujący wpis w dzienniku:
An error occurred!
Wiemy, że gdzieś w aplikacji pojawił się błąd. Nie wiemy gdzie to się stało, nie wiemy jaki to był błąd, wiemy tylko kiedy to się stało. Teraz spójrzmy na komunikat z nieco większą ilością informacji kontekstowych:
com.sematext.blog.logging.ParsingErrorExample - A parsing error occurred for user with id 1234!
Ten sam rekord dziennika, ale dużo więcej informacji kontekstowych. Wiemy, w którym wątku się to stało, wiemy, w jakiej klasie został wygenerowany błąd. Zmodyfikowaliśmy również komunikat, aby zawierał informację o użytkowniku, dla którego błąd wystąpił, dzięki czemu możemy do niego wrócić w razie potrzeby. Moglibyśmy również dołączyć dodatkowe informacje, takie jak konteksty diagnostyczne. Zastanów się, czego potrzebujesz i dołącz to.
Aby dołączyć informacje o kontekście, nie musisz robić wiele, jeśli chodzi o kod odpowiedzialny za generowanie komunikatu dziennika. Na przykład, PatternLayout w Log4J 2 daje ci wszystko, czego potrzebujesz, aby dołączyć informacje o kontekście. Możesz użyć bardzo prostego wzorca, takiego jak ten:
<PatternLayout pattern="%d{HH:mm:ss.SSS} %-5level - %msg%n"/>
, który spowoduje wyświetlenie komunikatu dziennika podobnego do poniższego:
17:13:08.059 INFO - This is the first INFO level log message!
Ale możesz również dołączyć wzorzec, który będzie zawierał znacznie więcej informacji:
<PatternLayout pattern="%d{HH:mm:ss.SSS} %c %l %-5level - %msg%n"/>
To spowoduje wyświetlenie komunikatu dziennika podobnego do tego:
17:24:01.710 com.sematext.blog.logging.Log4j2 com.sematext.blog.logging.Log4j2.main(Log4j2.java:12) INFO - This is the first INFO level log message!
Java Logging in Containers
Pomyśl o środowisku, w którym będzie działać twoja aplikacja. Istnieje różnica w konfiguracji logowania, gdy uruchamiasz swój kod Java w maszynie wirtualnej lub na maszynie bare-metal, jest inna, gdy uruchamiasz go w środowisku kontenerowym, i oczywiście jest inna, gdy uruchamiasz swój kod Java lub Kotlin na urządzeniu z systemem Android.
Aby skonfigurować logowanie w środowisku kontenerowym, musisz wybrać podejście, które chcesz zastosować. Możesz użyć jednego z dostarczonych sterowników logowania – takich jak journald, logagent, Syslog lub plik JSON. Aby to zrobić, pamiętaj, że Twoja aplikacja nie powinna zapisywać pliku logu do efemerycznego magazynu kontenera, ale na standardowe wyjście. Można to łatwo zrobić konfigurując swój framework logowania, aby zapisywał log do konsoli. Na przykład, z Log4J 2 wystarczy użyć następującej konfiguracji appendera:
<Appenders> <Console name="Console" target="SYSTEM_OUT"> <PatternLayout pattern="%d{HH:mm:ss.SSS} - %m %n"/> </Console></Appenders>
Można również całkowicie pominąć sterowniki logowania i wysyłać logi bezpośrednio do scentralizowanego rozwiązania logów, takiego jak nasza Sematext Cloud:
<Appenders> <Console name="Console" target="SYSTEM_OUT"> <PatternLayout pattern="%d %level %c - %m%n"/> </Console> <Syslog name="Syslog" host="logsene-syslog-receiver.sematext.com" port="514" protocol="TCP" format="RFC5424" appName="11111111-2222-3333-4444-555555555555" facility="LOCAL0" mdcId="mdc" newLine="true"/></Appenders>
Don’t Log Too Much or Too Little
Jako programiści mamy tendencję do myślenia, że wszystko może być ważne – mamy tendencję do oznaczania każdego kroku naszego algorytmu lub kodu biznesowego jako ważnego. Z drugiej strony, czasami postępujemy odwrotnie – nie dodajemy logowania tam, gdzie powinniśmy lub logujemy tylko poziomy logów FATAL i ERROR. Oba podejścia nie przyniosą dobrych rezultatów. Pisząc swój kod i dodając logowanie, zastanów się, co będzie ważne, aby zobaczyć, czy aplikacja działa poprawnie, a co będzie ważne, aby móc zdiagnozować zły stan aplikacji i go naprawić. Użyj tego jako swojego przewodnika, aby zdecydować co i gdzie logować. Należy pamiętać, że dodanie zbyt wielu logów skończy się zmęczeniem informacyjnym, a brak wystarczającej ilości informacji spowoduje niezdolność do rozwiązywania problemów.
Keep the Audience in Mind
W większości przypadków, nie będziesz jedyną osobą przeglądającą logi. Zawsze o tym pamiętaj. Istnieje wiele podmiotów, które mogą przeglądać dzienniki.
Deweloper może przeglądać dzienniki w celu rozwiązywania problemów lub podczas sesji debugowania. Dla takich osób dzienniki mogą być szczegółowe, techniczne i zawierać bardzo głębokie informacje związane z tym, jak działa system. Taka osoba będzie miała również dostęp do kodu lub nawet będzie znała kod i można założyć, że.
Wtedy są DevOps. Dla nich zdarzenia logów będą potrzebne do rozwiązywania problemów i powinny zawierać informacje pomocne w diagnostyce. Możesz założyć znajomość systemu, jego architektury, komponentów i konfiguracji komponentów, ale nie powinieneś zakładać znajomości kodu platformy.
Na koniec, logi Twojej aplikacji mogą być czytane przez samych użytkowników. W takim przypadku logi powinny być wystarczająco opisowe, aby pomóc naprawić problem, jeśli jest to w ogóle możliwe, lub dać wystarczająco dużo informacji zespołowi wsparcia pomagającemu użytkownikowi. Na przykład, użycie Sematext do monitorowania wymaga zainstalowania i uruchomienia agenta monitorującego. Jeśli znajdujesz się za bardzo restrykcyjnym firewallem i agent nie może wysyłać metryk do Sematext, loguje on błędy, które użytkownicy Sematext mogą sprawdzić.
Możemy pójść dalej i zidentyfikować jeszcze więcej podmiotów, które mogą zaglądać do dzienników, ale ta krótka lista powinna dać ci wgląd w to, o czym powinieneś pomyśleć pisząc swoje komunikaty dziennika.
Unikaj logowania wrażliwych informacji
Wrażliwe informacje nie powinny być obecne w dziennikach lub powinny być zamaskowane. Hasła, numery kart kredytowych, numery ubezpieczenia społecznego, tokeny dostępu i tak dalej – wszystkie te informacje mogą być niebezpieczne, jeśli wyciekną lub uzyskają do nich dostęp osoby, które nie powinny ich widzieć. Są dwie rzeczy, które powinieneś rozważyć.
Przemyśl, czy wrażliwe informacje są naprawdę niezbędne do rozwiązywania problemów. Może zamiast numeru karty kredytowej wystarczy zachować informacje o identyfikatorze transakcji i dacie transakcji? Może nie jest konieczne przechowywanie w logach numeru ubezpieczenia społecznego, skoro można łatwo przechowywać identyfikator użytkownika? Pomyśl o takich sytuacjach, pomyśl o danych, które przechowujesz, i zapisuj wrażliwe dane tylko wtedy, gdy jest to naprawdę konieczne.
Drugą rzeczą jest wysyłanie logów z wrażliwymi informacjami do hostowanej usługi logów. Istnieje bardzo niewiele wyjątków, w których poniższa rada nie powinna być przestrzegana. Jeśli Twoje logi mają i muszą mieć zapisane wrażliwe informacje, zamaskuj je lub usuń przed wysłaniem ich do scentralizowanego magazynu logów. Większość popularnych dostawców logów, takich jak nasz własny Logagent, zawiera funkcjonalność, która pozwala na usunięcie lub zamaskowanie wrażliwych danych.
Wreszcie, maskowanie wrażliwych informacji może być wykonane w samym szkielecie logowania. Przyjrzyjmy się, jak można to zrobić poprzez rozszerzenie Log4j 2. Nasz kod, który produkuje zdarzenia dziennika wygląda następująco (pełny przykład można znaleźć na Sematext Github):
public class Log4J2Masking { private static Logger LOGGER = LoggerFactory.getLogger(Log4J2Masking.class); private static final Marker SENSITIVE_DATA_MARKER = MarkerFactory.getMarker("SENSITIVE_DATA_MARKER"); public static void main(String args) { LOGGER.info("This is a log message without sensitive data"); LOGGER.info(SENSITIVE_DATA_MARKER, "This is a a log message with credit card number 1234-4444-3333-1111 in it"); }}
Jeśli miałbyś uruchomić cały przykład z Githuba, dane wyjściowe byłyby następujące:
21:20:42.099 - This is a log message without sensitive data21:20:42.101 - This is a a log message with credit card number ****-****-****-**** in it
Widzisz, że numer karty kredytowej został zamaskowany. Stało się tak, ponieważ dodaliśmy niestandardowy Converter, który sprawdza czy dany Marker jest przekazywany wzdłuż zdarzenia logu i próbuje zastąpić zdefiniowany wzorzec. Implementacja takiego konwertera wygląda następująco:
@Plugin(name = "sample_logging_mask", category = "Converter")@ConverterKeys("sc")public class LoggingConverter extends LogEventPatternConverter { private static Pattern PATTERN = Pattern.compile("\b({4})-({4})-({4})-({4})\b"); public LoggingConverter(String options) { super("sc", "sc"); } public static LoggingConverter newInstance(final String options) { return new LoggingConverter(options); } @Override public void format(LogEvent event, StringBuilder toAppendTo) { String message = event.getMessage().getFormattedMessage(); String maskedMessage = message; if (event.getMarker() != null && "SENSITIVE_DATA_MARKER".compareToIgnoreCase(event.getMarker().getName()) == 0) { Matcher matcher = PATTERN.matcher(message); if (matcher.find()) { maskedMessage = matcher.replaceAll("****-****-****-****"); } } toAppendTo.append(maskedMessage); }}
Jest to bardzo proste i mogłoby być napisane w bardziej zoptymalizowany sposób, a także powinno obsługiwać wszystkie możliwe formaty numerów kart kredytowych, ale do tego celu w zupełności wystarczy.
Zanim przejdziemy do wyjaśnienia kodu, chciałbym również pokazać plik konfiguracyjny log4j2.xml dla tego przykładu:
<?xml version="1.0" encoding="UTF-8"?><Configuration status="WARN" packages="com.sematext.blog.logging"> <Appenders> <Console name="Console" target="SYSTEM_OUT"> <PatternLayout pattern="%d{HH:mm:ss.SSS} - %sc %n"/> </Console> </Appenders> <Loggers> <Root level="info"> <AppenderRef ref="Console"/> </Root> </Loggers></Configuration>
Jak widać, dodaliśmy atrybut packages w naszej konfiguracji, aby powiedzieć frameworkowi, gdzie ma szukać naszego konwertera. Następnie użyliśmy wzorca %sc, aby dostarczyć wiadomość do logu. Robimy to, ponieważ nie możemy nadpisać domyślnego wzorca %m. Kiedy Log4j2 znajdzie nasz wzorzec %sc, użyje naszego konwertera, który pobierze sformatowaną wiadomość zdarzenia logu i użyje prostego regexa i zastąpi dane, jeśli zostały znalezione. Tak proste jak to.
Jedną rzeczą, którą należy zauważyć tutaj jest to, że używamy funkcjonalności Marker. Dopasowywanie Regex jest kosztowne i nie chcemy tego robić dla każdej wiadomości dziennika. Dlatego oznaczamy zdarzenia dziennika, które powinny być przetwarzane za pomocą utworzonego Markera, więc tylko te oznaczone są sprawdzane.
Use a Log Management Solution to Centralize & Monitor Java Logs
Wraz ze złożonością aplikacji, objętość twoich dzienników również będzie rosła. Możesz uciec z logowania do pliku i używać dzienników tylko wtedy, gdy potrzebne jest rozwiązywanie problemów, ale gdy ilość danych rośnie, szybko staje się trudne i powolne do rozwiązywania problemów w ten sposób Kiedy tak się dzieje, rozważ użycie rozwiązania do zarządzania dziennikami do centralizacji i monitorowania dzienników. Możesz wybrać rozwiązanie wewnętrzne oparte na oprogramowaniu open-source, takie jak Elastic Stack lub użyć jednego z narzędzi do zarządzania logami dostępnych na rynku, takich jak Sematext Logs.
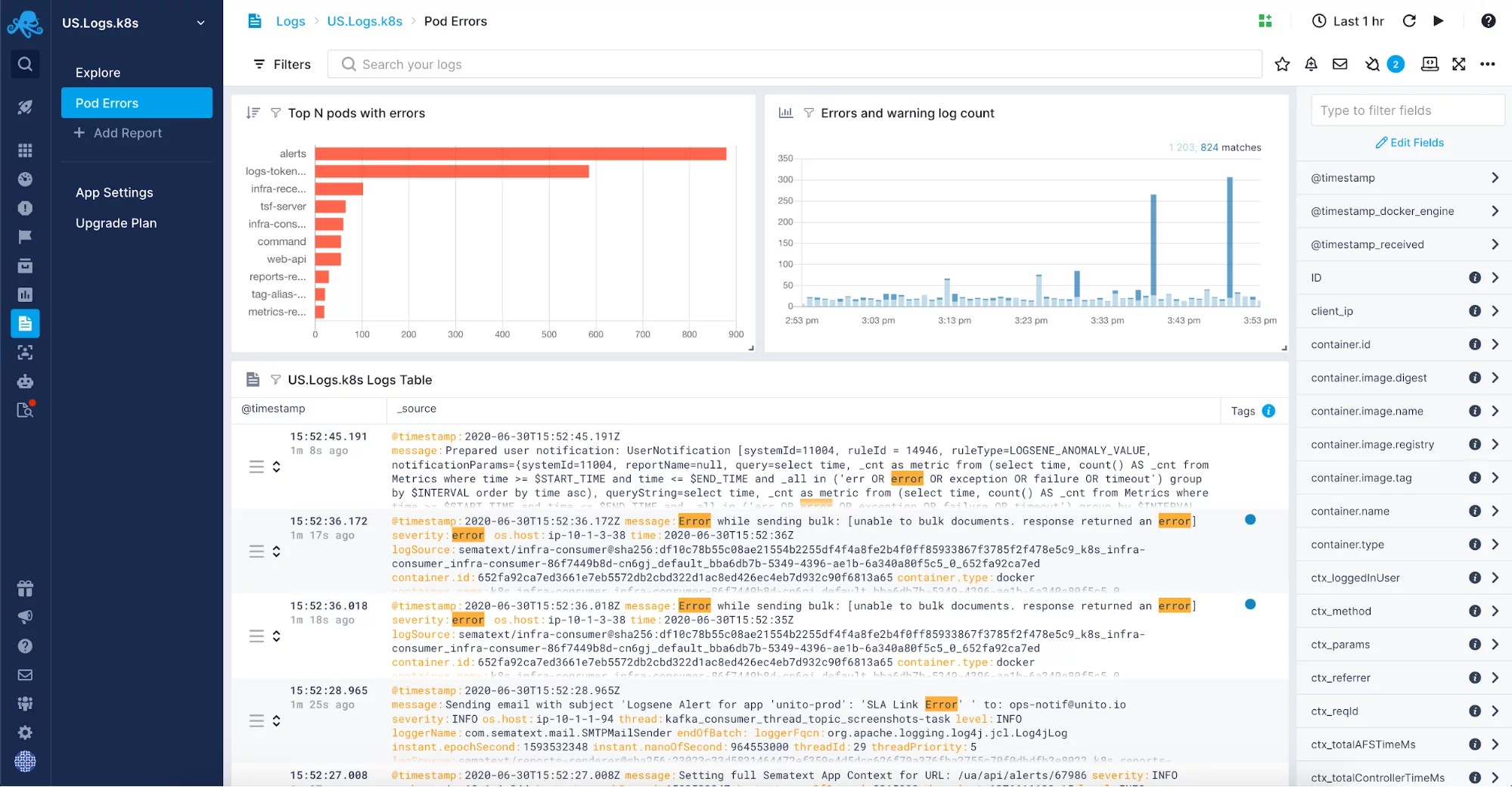
W pełni zarządzane rozwiązanie do centralizacji logów da Ci swobodę, ponieważ nie będziesz musiał zarządzać kolejną, zwykle dość złożoną, częścią infrastruktury. Zamiast tego będziesz mógł skupić się na swojej aplikacji i będziesz musiał skonfigurować tylko wysyłkę logów. Możesz chcieć włączyć logi takie jak logi odśmiecania JVM do swojego rozwiązania logów zarządzanych. Po włączeniu ich dla swoich aplikacji i systemów pracujących na JVM będziesz chciał agregować logi w jednym miejscu w celu korelacji logów, analizy logów i aby pomóc Ci dostroić zbieranie śmieci w instancjach JVM. Takie dzienniki skorelowane z metrykami są nieocenionym źródłem informacji do rozwiązywania problemów związanych z odśmiecaniem.
Jeśli jesteś zainteresowany, aby zobaczyć, jak Sematext Logs radzi sobie z podobnymi rozwiązaniami, przejdź do naszego artykułu o najlepszym oprogramowaniu do zarządzania dziennikami lub do wpisu na blogu, w którym przeglądamy niektóre z najlepszych narzędzi do analizy dzienników, ale zalecamy skorzystanie z 14-dniowej bezpłatnej wersji próbnej, aby w pełni poznać jego funkcje. Wypróbuj je i przekonaj się sam!
Konkluzja
Wprowadzenie każdej dobrej praktyki może nie być łatwe do wdrożenia od razu, zwłaszcza w przypadku aplikacji, które są już na żywo i działają w produkcji. Jeśli jednak poświęcisz trochę czasu i wprowadzisz te sugestie jedna po drugiej, zaczniesz zauważać wzrost użyteczności swoich logów. Aby uzyskać więcej wskazówek na temat tego, jak w pełni wykorzystać swoje logi, polecamy również zapoznać się z naszym innym artykułem na temat najlepszych praktyk logowania, w którym wyjaśniamy tajniki i zasady, których należy przestrzegać niezależnie od typu aplikacji, z którą pracujesz. Pamiętaj, że w Sematext pomagamy organizacjom w konfiguracji logów, oferując doradztwo w tym zakresie, więc jeśli masz problemy, skontaktuj się z nami, a my z przyjemnością pomożemy.
Udział
.
Dodaj komentarz