Sign up for our daily recaps of the ever-changing search marketing landscape.
Note: Wysyłając ten formularz, zgadzasz się na warunki Third Door Media. Szanujemy Twoją prywatność.

Na forach internetowych i grupach na Facebooku związanych z contentem często wybuchają dyskusje na temat tego, jak działa Googlebot – którego będziemy tu czule nazywać GB – i co może, a czego nie może zobaczyć, jakie linki odwiedza i jak wpływa na SEO.
W tym artykule przedstawię wyniki mojego trzymiesięcznego eksperymentu.
Prawie codziennie przez ostatnie trzy miesiące GB odwiedzał mnie jak przyjaciel wpadający na piwo.
Niekiedy był sam:
: 66.249.76.136 /page1.html Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)
: 66.249.76.136 /page5.html Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)
: 66.249.76.140 /page3.html Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)
: 66.249.64.72 /page2.html Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)
: 66.249.64.72 /page6.html Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)
Czasami przyprowadzała swoich kumpli:
: 64.233.172.231 /page1.html Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko; Google Search Console) Chrome/41.0.2272.118 Safari/537.36
: 66.249.69.235 /image.jpg Googlebot-Image/1.0
: 66.249.76.156 /page2.html Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2272.96 Mobile Safari/537.36 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)
I mieliśmy mnóstwo zabawy grając w różne gry:
Łap: Zaobserwowałem jak GB uwielbia uruchamiać przekierowania 301 i crawlować obrazki, oraz uciekać od kanoniczności.
Hide-and-seek: Googlebot chował się w ukrytej treści (której, jak twierdzą jego rodzice, nie toleruje i unika)
Survival: Przygotowywałem pułapki i czekałem, aż je wyskoczy.
Obstacles: Umieściłem przeszkody o różnych poziomach trudności, aby zobaczyć, jak mój mały przyjaciel sobie z nimi poradzi.
Jak zapewne możesz powiedzieć, nie zawiodłem się. Mieliśmy mnóstwo zabawy i staliśmy się dobrymi przyjaciółmi. Wierzę, że nasza przyjaźń ma świetlaną przyszłość.
Ale przejdźmy do rzeczy!
Zbudowałem stronę internetową z treścią związaną z zasługami o międzygwiezdnym biurze podróży oferującym loty na nieodkryte jeszcze planety w naszej galaktyce i poza nią.
Treść wydawała się mieć wiele zasług, gdy w rzeczywistości była stekiem bzdur.
Struktura eksperymentalnej strony wyglądała tak:
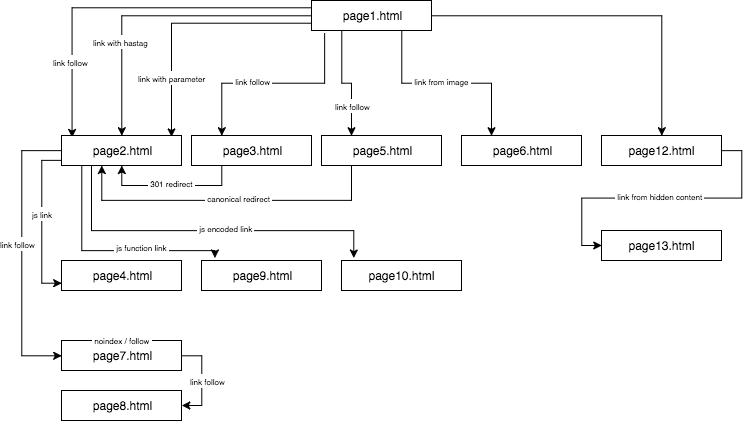
Dostarczyłem unikalną treść i upewniłem się, że każdy anchor/title/alt, jak również inne współczynniki, były globalnie unikalne (fałszywe słowa). Aby ułatwić sprawę czytelnikowi, w opisie nie będę używał nazw takich jak anchor cutroicano matestito, ale zamiast tego odniosę się do nich jako anchor1, etc.
Sugeruję, abyś zachował powyższą mapę otwartą w osobnym oknie podczas czytania tego artykułu.
- Część 1: Pierwszy link się liczy
- Link do strony z anchorem
- Link do strony z parametrem
- Link do strony z przekierowania
- Link do strony z użyciem tagu kanonicznego
- Część 2: Crawl budget
- Łącze JavaScript ze zdarzeniem onclick
- Łącze JavaScript z funkcją wewnętrzną
- Łącznik JavaScript z kodowaniem
- Część 3: Ukryta zawartość
- About The Author
Część 1: Pierwszy link się liczy
Jedną z rzeczy, które chciałem przetestować w tym eksperymencie SEO, była Reguła Liczenia Pierwszych Linków – czy można ją pominąć i jak wpływa na optymalizację.
Reguła Liczenia Pierwszych Linków mówi, że na danej stronie bot Google widzi tylko pierwszy link do podstrony. Jeśli na jednej stronie znajdują się dwa linki do tej samej podstrony, to zgodnie z tą regułą drugi z nich zostanie zignorowany. Bot Google będzie ignorował anchor w drugim i w każdym kolejnym linku podczas obliczania rankingu strony.
Jest to problem szeroko nadzorowany przez wielu specjalistów, ale obecny szczególnie w sklepach internetowych, gdzie menu nawigacyjne znacząco zniekształca strukturę strony.
W większości sklepów mamy statyczne (widoczne w źródle strony) rozwijane menu, które daje np. cztery linki do głównych kategorii i 25 ukrytych linków do podkategorii. Podczas mapowania struktury strony, GB widzi wszystkie linki (na każdej stronie z menu), co powoduje, że podczas mapowania wszystkie strony mają jednakową wagę, a ich moc (juice) rozkłada się równomiernie, co wygląda mniej więcej tak:
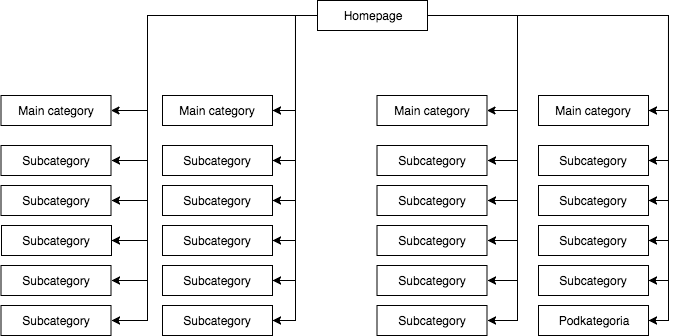
Najczęstsza, ale moim zdaniem błędna struktura strony.
Powyższego przykładu nie można nazwać prawidłową strukturą, ponieważ wszystkie kategorie są podlinkowane ze wszystkich stron, na których jest menu. Dlatego zarówno strona główna, jak i wszystkie kategorie i podkategorie mają jednakową liczbę linków przychodzących, a moc całego serwisu internetowego przepływa przez nie z jednakową siłą. Stąd moc strony głównej (która zwykle jest źródłem większości mocy ze względu na liczbę linków przychodzących) jest dzielona na 24 kategorie i podkategorie, a więc każda z nich otrzymuje tylko 4 procent mocy strony głównej.
Jak powinna wyglądać struktura:

Jeśli potrzebujesz szybko przetestować strukturę swojej strony i crawlować ją tak, jak robi to Google, Screaming Frog jest pomocnym narzędziem.
W tym przykładzie moc strony głównej jest podzielona na cztery, a każda z kategorii otrzymuje 25 procent mocy strony głównej i rozdziela jej część do podkategorii. Takie rozwiązanie daje też większe szanse na linkowanie wewnętrzne. Przykładowo, gdy napiszesz artykuł na blogu sklepu i będziesz chciał podlinkować do jednej z podkategorii, GB zauważy link podczas crawlowania strony. W pierwszym przypadku nie zrobi tego ze względu na zasadę First Link Counts Rule. Jeśli link do podkategorii był w menu strony, to ten w artykule zostanie zignorowany.
Zacząłem ten eksperyment SEO od następujących działań:
- Po pierwsze, na stronie1.html, umieściłem link do podstrony page2.html jako klasyczny link dofollow z anchorem: anchor1.
- Następnie, w tekście na tej samej stronie, umieściłem lekko zmodyfikowane odnośniki, aby sprawdzić, czy GB będzie chciało je crawlować.
W tym celu przetestowałem następujące rozwiązania:
- Do strony głównej serwisu przypisałem jeden link zewnętrzny dofollow dla frazy z anchorem URL (czyli wszelkie zewnętrzne linkowanie strony głównej i podstron dla danych fraz nie wchodziło w grę) – przyspieszyło to indeksowanie serwisu.
- Czekałem, aż strona2.html zacznie się rankingować na frazę z pierwszego linku dofollow (anchor1) pochodzącego ze strony1.html. Ta fałszywa fraza, ani żadna inna, którą testowałem nie mogła znaleźć się na stronie docelowej. Założyłem, że skoro inne linki zadziałają, to strona2.html również znajdzie się w wynikach wyszukiwania dla innych fraz z innych linków. Trwało to około 45 dni. I wtedy udało mi się wysnuć pierwszy ważny wniosek.
Nawet strona, na której słowo kluczowe nie występuje ani w treści, ani w meta title, ale jest powiązane z badanym anchorem, może bez problemu uplasować się w wynikach wyszukiwania wyżej niż strona, która zawiera to słowo, ale nie jest powiązana ze słowem kluczowym.
Co więcej, strona główna (page1.html), która zawierała badaną frazę, była najsilniejszą stroną w serwisie (linkowana z 78 proc. podstron), a mimo to plasowała się niżej na badaną frazę niż podstrona (page2.html) podlinkowana na badaną frazę.
Poniżej przedstawiam cztery rodzaje testowanych przeze mnie linków, z których wszystkie pojawiają się po pierwszym linku dofollow prowadzącym do strony2.html.
Link do strony z anchorem
< a href=”page2.html#testhash” >anchor2< /a >
Pierwszym z dodatkowych linków przychodzących w kodzie za linkiem dofollow był link z anchorem (hashtagiem). Chciałem sprawdzić, czy GB przejdzie przez ten link i zaindeksuje również stronę2.html pod frazą anchor2, pomimo tego, że link prowadzi do tej strony (strona2.html), ale adres URL został zmieniony na strona2.html#testhash uses anchor2.
Niestety GB nigdy nie chciało zapamiętać tego połączenia i nie skierowało mocy na podstronę strona2.html dla tej frazy. W efekcie w wynikach wyszukiwania dla frazy anchor2 w dniu pisania tego artykułu znajduje się tylko podstrona page1.html, gdzie słowo to znajduje się w anchorze linku. Googlując frazę testhash, nasza domena również nie plasuje się w rankingu.
Link do strony z parametrem
page2.html?parameter=1
Początkowo GB zainteresował ten śmieszny fragment adresu URL zaraz po znaku zapytania oraz anchor wewnątrz linku anchor3.
Zaintrygowany GB próbował dociec, co mam na myśli. Pomyślało: „Czy to jest zagadka?”. Aby uniknąć indeksowania zduplikowanej treści pod innymi adresami URL, kanoniczna strona2.html wskazywała na samą siebie. W sumie logi zarejestrowały 8 crawli pod tym adresem, ale wnioski były raczej smutne:
- Po 2 tygodniach częstotliwość odwiedzin GB znacznie spadła, aż w końcu odeszła i już nigdy nie crawlowała tego linku.
- Strona2.html nie została zaindeksowana pod frazą anchor3, podobnie jak parametr z URL parametr1. Według Search Console link ten nie istnieje (nie jest liczony wśród linków przychodzących), ale jednocześnie fraza anchor3 jest wymieniona jako fraza zakotwiczona.
Link do strony z przekierowania
Chciałem zmusić GB do większego crawlowania mojej strony, co skutkowało tym, że GB co kilka dni wpisywał link dofollow z anchorem anchor4 na stronie1.html prowadzący do strony3.html, która przekierowywała kodem 301 na stronę2.html. Niestety, podobnie jak w przypadku strony z parametrem, po 45 dniach strona2.html nie była jeszcze rankingowa w wynikach wyszukiwania dla frazy z anchorem4, która pojawiła się w linku przekierowującym na stronie1.html.
Jednakże w Google Search Console, w sekcji Anchor Texts, anchor4 jest widoczny i zaindeksowany. Może to wskazywać, że po pewnym czasie przekierowanie zacznie działać zgodnie z oczekiwaniami, a więc strona2.html uplasuje się w wynikach wyszukiwania dla anchor4, mimo że jest drugim linkiem do tej samej strony docelowej w ramach tej samej witryny.
Link do strony z użyciem tagu kanonicznego
Na stronie1.html umieściłem odwołanie do strony5.html (follow link) z anchorem anchor5. Jednocześnie na stronie5.html znajdowała się unikalna treść, a w jej głowie znacznik kanoniczny do strony2.html.
< link rel=”canonical” href=”https://example.com/page2.html” />
Test ten dał następujące wyniki:
- Link dla frazy anchor5 kierujący do strony5.html przekierowujący kanonicznie do strony2.html nie został przeniesiony na stronę docelową (tak jak w pozostałych przypadkach).
- Strona5.html została zaindeksowana pomimo znacznika kanonicznego.
- Strona5.html nie uplasowała się w wynikach wyszukiwania dla anchor5.
- Strona5.html uplasowała się na frazy użyte w tekście strony, co wskazywało na to, że GB całkowicie zignorowało znaczniki kanoniczne.
Zaryzykowałbym twierdzenie, że użycie rel=canonical w celu uniemożliwienia indeksowania niektórych treści (np. podczas filtrowania) po prostu nie mogło zadziałać.
Część 2: Crawl budget
Podczas projektowania strategii SEO chciałem sprawić, aby GB tańczyło do mojej melodii, a nie odwrotnie. W tym celu zweryfikowałem procesy SEO na poziomie logów serwera (logi dostępu i logi błędów), co dało mi ogromną przewagę. Dzięki temu znałem każdy ruch GB i jego reakcję na zmiany, które wprowadzałem (przebudowa strony, wywrócenie systemu linkowania wewnętrznego, sposób wyświetlania informacji) w ramach kampanii SEO.
Jednym z moich zadań w ramach kampanii SEO była przebudowa strony w taki sposób, aby GB odwiedzał tylko te adresy, które będzie w stanie zaindeksować i które chcemy, aby zaindeksował. W skrócie: w indeksie Google powinny znajdować się tylko te strony, które są dla nas ważne z punktu widzenia SEO. Z drugiej strony GB powinno indeksować tylko te strony, które chcemy, aby były indeksowane przez Google, co nie dla wszystkich jest oczywiste, np. gdy sklep internetowy wprowadza filtrowanie po kolorach, rozmiarach i cenach, a odbywa się to poprzez manipulację parametrami URL, np.:
example.com/women/shoes/?color=red&size=40&price=200-250
Może się okazać, że rozwiązanie pozwalające GB na crawlowanie dynamicznych adresów URL powoduje, że zamiast na crawlowanie strony, GB poświęca czas na ich przeszukiwanie (i ewentualnie indeksowanie).
example.com/women/shoes/
Takie dynamicznie tworzone adresy URL są nie tylko bezużyteczne, ale potencjalnie szkodliwe dla SEO, ponieważ mogą zostać pomylone z cienką treścią, co spowoduje spadek pozycji strony w rankingu.
W ramach tego eksperymentu chciałem również sprawdzić kilka metod strukturyzacji bez użycia rel=”nofollow”, blokowania GB w pliku robots.txt czy umieszczania części kodu HTML w niewidocznych dla bota ramkach (zablokowane iframe).
Testowałem trzy rodzaje linków JavaScript.
Łącze JavaScript ze zdarzeniem onclick
Proste łącze skonstruowane w oparciu o JavaScript
< a href=”javascript:void(0)” onclick=”window.location.href =’page4.html'” >anchor6< /a >
GB bez problemu przeszedł na podstronę page4.html i zaindeksował całą stronę. Podstrona nie plasuje się w wynikach wyszukiwania dla frazy anchor6, a frazy tej nie można znaleźć w sekcji Anchor Texts w Google Search Console. Wniosek jest taki, że link nie przekazał soku.
Podsumowując:
- Klasyczny link JavaScript pozwala Google na indeksowanie witryny i indeksowanie stron, na które trafia.
- Nie przekazuje soku – jest neutralny.
Łącze JavaScript z funkcją wewnętrzną
Postanowiłem podnieść grę, ale ku mojemu zdziwieniu GB pokonało przeszkodę w niecałe 2 godziny od publikacji łącza.
< a href=”javascript:void(0)” class=”js-link” data-url=”page9.html” >anchor7< /a >
Do obsługi tego linku wykorzystałem funkcję zewnętrzną, której celem było odczytanie adresu URL z danych i przekierowanie – tylko przekierowanie użytkownika, na co liczyłem – na docelową stronę9.html. Podobnie jak we wcześniejszym przypadku, strona9.html została w pełni zindeksowana.
Co ciekawe, pomimo braku innych linków przychodzących, strona9.html była trzecią najczęściej odwiedzaną stroną przez GB w całym serwisie internetowym, zaraz po stronach page1.html i page2.html.
Wcześniej stosowałem tę metodę do strukturyzacji serwisów internetowych. Jednak, jak widać, już nie działa. W SEO nic nie żyje wiecznie, z wyjątkiem Yellow Pages.
Łącznik JavaScript z kodowaniem
Nie poddawałem się jednak i uznałem, że musi istnieć sposób na skuteczne zamknięcie GB drzwi przed nosem. Skonstruowałem więc prostą funkcję, kodując dane algorytmem base64, a odnośnik wyglądał tak:
< a href=”javascript:void(0)” class=”js-link” data-url=”cGFnZTEwLmh0bWw=” >anchor8< /a >
W rezultacie GB nie był w stanie wyprodukować kodu JavaScript, który zarówno dekodowałby zawartość atrybutu data-URL, jak i przekierowywał. I tak się stało! Mamy sposób na ustrukturyzowanie serwisu internetowego bez użycia rel=nonfollows, aby uniemożliwić botom indeksowanie się gdziekolwiek zechcą! Dzięki temu nie marnujemy naszego crawl-budżetu, co jest szczególnie ważne w przypadku dużych serwisów, a GB w końcu tańczy do naszej melodii. Niezależnie od tego, czy funkcja została wprowadzona na tej samej stronie w sekcji head, czy w zewnętrznym pliku JS, nie ma żadnych dowodów na obecność bota ani w logach serwera, ani w Search Console.
Część 3: Ukryta zawartość
W ostatnim teście chciałem sprawdzić, czy zawartość np. w ukrytych zakładkach zostanie uwzględniona i zaindeksowana przez GB, czy też Google wyrenderuje taką stronę i zignoruje ukryty tekst, jak twierdzą niektórzy specjaliści.
Chciałem albo potwierdzić, albo odrzucić to twierdzenie. W tym celu na stronie 12.html umieściłem ścianę tekstu z ponad 2000 znaków, a blok tekstu z około 20 procentami tekstu (400 znaków) ukryłem w Kaskadowych Arkuszach Stylów i dodałem przycisk pokaż więcej. Wewnątrz ukrytego tekstu znajdował się link do strony13.html z anchorem anchor9.
Nie ma wątpliwości, że bot może renderować stronę. Możemy to zaobserwować zarówno w Google Search Console jak i Google Insight Speed. Niemniej jednak moje testy wykazały, że blok tekstu wyświetlany po kliknięciu w przycisk pokaż więcej został w pełni zaindeksowany. Frazy ukryte w tekście znajdowały się w wynikach wyszukiwania, a GB podążało za linkami ukrytymi w tekście. Co więcej, anchory linków z ukrytego bloku tekstu były widoczne w Google Search Console w sekcji Anchor Text, a strona13.html również zaczęła plasować się w wynikach wyszukiwania dla słowa kluczowego anchor9.
Jest to kluczowe dla sklepów internetowych, gdzie treści często umieszczane są w ukrytych zakładkach. Teraz mamy pewność, że GB widzi treści w ukrytych zakładkach, indeksuje je i przekazuje sok z ukrytych tam linków.
Najważniejszym wnioskiem, jaki wyciągam z tego eksperymentu jest to, że nie znalazłem bezpośredniego sposobu na ominięcie reguły First Link Counts Rule poprzez stosowanie zmodyfikowanych linków (linki z parametrem, przekierowania 301, kanoniczne, anchor linki). Jednocześnie możliwe jest budowanie struktury strony z wykorzystaniem linków Javascript, dzięki czemu jesteśmy wolni od ograniczeń wynikających z reguły First Link Counts Rule. Co więcej, Google Bot widzi i indeksuje treści ukryte w zakładkach i śledzi ukryte w nich linki.
Zapisz się, aby otrzymywać nasze codzienne podsumowania stale zmieniającego się krajobrazu marketingu wyszukiwania.
Uwaga: Przesyłając ten formularz, zgadzasz się na warunki Third Door Media. Szanujemy Twoją prywatność.
About The Author

„Nie akceptuj 'tylko’ wysokiej jakości. Każdy może to zrobić. Jeśli niebo jest limitem, znajdź wyższe niebo.” Max Cyrek jest CEO Cyrek Digital, konsultantem marketingu cyfrowego i ewangelistą SEO. W ciągu swojej kariery Max, wraz ze swoim ponad 30-osobowym zespołem, pracował z setkami firm pomagając im odnieść sukces. Pracuje w marketingu cyfrowym od prawie dziesięciu lat i specjalizuje się w technicznym SEO, zarządzając udanymi projektami marketingowymi.
.
Dodaj komentarz