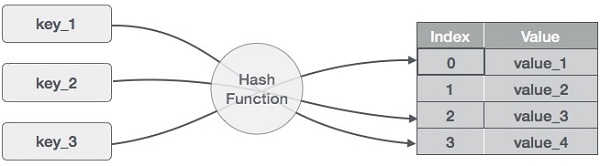
La tabella hash è una struttura di dati che memorizza dati in maniera associativa. In una tabella hash, i dati sono memorizzati in un formato di array, dove ogni valore di dati ha il suo valore di indice unico. L’accesso ai dati diventa molto veloce se conosciamo l’indice dei dati desiderati.
Quindi, diventa una struttura di dati in cui le operazioni di inserimento e ricerca sono molto veloci indipendentemente dalla dimensione dei dati. Hash Table usa una matrice come supporto di memorizzazione e utilizza la tecnica dell’hash per generare un indice in cui un elemento deve essere inserito o da cui deve essere localizzato.
Hashing
Hashing è una tecnica per convertire una serie di valori chiave in una serie di indici di una matrice. Useremo l’operatore modulo per ottenere un intervallo di valori chiave. Consideriamo un esempio di tabella hash di dimensione 20, e i seguenti elementi devono essere memorizzati. Gli elementi sono nel formato (chiave, valore).
- (1,20)
- (2,70)
- (42,80)
- (4,25)
- (12,44)
- (14,32)
- (17,11)
- (13,78)
- (37,98)
| Sr.No. | Key | Hash | Array Index | |
|---|---|---|---|---|
| 1 | 1 | 1 % 20 = 1 | 1 | |
| 2 | 2 | 2 | 2 % 20 = 2 | 2 |
| 3 | 42 | 42 % 20 = 2 | 2 | |
| 4 | 4 | 4 % 20 = 4 | 4 | |
| 5 | 12 | 12 % 20 = 12 | 12 | |
| 6 | 14 | 14 % 20 = 14 | 14 | |
| 7 | 17 | 17 % 20 = 17 | 17 | |
| 8 | 13 | 13 % 20 = 13 | 13 | |
| 9 | 37 | 37 % 20 = 17 | 17 |
Linear Probing
Come possiamo vedere, può succedere che la tecnica di hashing sia usata per creare un indice già usato dell’array. In tal caso, possiamo cercare la prossima posizione vuota nell’array guardando nella cella successiva fino a trovare una cella vuota. Questa tecnica è chiamata linear probing.
| Sr.No. | Key | Hash | Indice della matrice | Dopo il Linear Probing, Indice Array | |
|---|---|---|---|---|---|
| 1 | 1 | 1 % 20 = 1 | 1 | 1 | 1 |
| 2 | 2 | 2 % 20 = 2 | 2 | 2 | |
| 3 | 42 | 42 % 20 = 2 | 2 | 3 | |
| 4 | 4 | 4 % 20 = 4 | 4 | 4 | |
| 5 | 12 | 12 % 20 = 12 | 12 | 12 | |
| 6 | 14 | 14 % 20 = 14 | 14 | 14 | |
| 7 | 17 | 17 % 20 = 17 | 17 | 17 | |
| 8 | 13 | 13 % 20 = 13 | 13 | 13 | |
| 9 | 37 | 37 % 20 = 17 | 17 | 18 |
Operazioni di base
Sono le operazioni principali di base di una tabella hash.
-
Cerca – Cerca un elemento in una tabella hash.
-
Inserisci – inserisce un elemento in una tabella hash.
-
delete – Cancella un elemento da una tabella hash.
DataItem
Definisce un elemento di dati con alcuni dati e una chiave, in base ai quali la ricerca deve essere condotta in una tabella hash.
struct DataItem { int data; int key;};
Metodo hash
Definire un metodo hash per calcolare il codice hash della chiave dell’elemento di dati.
int hashCode(int key){ return key % SIZE;}
Operazione di ricerca
Quando un elemento deve essere cercato, calcolare il codice hash della chiave passata e localizzare l’elemento usando quel codice hash come indice nell’array. Usa il linear probing per ottenere l’elemento in anticipo se l’elemento non si trova al codice hash calcolato.
Esempio
struct DataItem *search(int key) { //get the hash int hashIndex = hashCode(key); //move in array until an empty while(hashArray != NULL) { if(hashArray->key == key) return hashArray; //go to next cell ++hashIndex; //wrap around the table hashIndex %= SIZE; } return NULL; }
Operazione di inserimento
Quando un elemento deve essere inserito, calcola il codice hash della chiave passata e individua l’indice usando quel codice hash come indice nell’array. Usa il linear probing per la posizione vuota, se un elemento viene trovato al codice hash calcolato.
Esempio
void insert(int key,int data) { struct DataItem *item = (struct DataItem*) malloc(sizeof(struct DataItem)); item->data = data; item->key = key; //get the hash int hashIndex = hashCode(key); //move in array until an empty or deleted cell while(hashArray != NULL && hashArray->key != -1) { //go to next cell ++hashIndex; //wrap around the table hashIndex %= SIZE; } hashArray = item; }
Operazione di cancellazione
Quando un elemento deve essere cancellato, calcola il codice hash della chiave passata e individua l’indice usando quel codice hash come indice nell’array. Usate il linear probing per ottenere l’elemento in anticipo se un elemento non viene trovato al codice hash calcolato. Quando viene trovato, memorizza lì un elemento fittizio per mantenere intatte le prestazioni della tabella hash.
Esempio
struct DataItem* delete(struct DataItem* item) { int key = item->key; //get the hash int hashIndex = hashCode(key); //move in array until an empty while(hashArray !=NULL) { if(hashArray->key == key) { struct DataItem* temp = hashArray; //assign a dummy item at deleted position hashArray = dummyItem; return temp; } //go to next cell ++hashIndex; //wrap around the table hashIndex %= SIZE; } return NULL; }
Per conoscere l’implementazione dell’hash nel linguaggio di programmazione C, clicca qui.
Lascia un commento