Iscriviti ai nostri recaps quotidiani del panorama del search marketing in continua evoluzione.
Nota: Inviando questo modulo, accetti i termini di Third Door Media. Rispettiamo la tua privacy.

Sui forum internet e sui gruppi Facebook legati ai contenuti, spesso scoppiano discussioni su come funziona Googlebot – che qui chiameremo teneramente GB – e cosa può e non può vedere, che tipo di link visita e come influenza la SEO.
In questo articolo, presenterò i risultati del mio esperimento lungo tre mesi.
Quasi ogni giorno negli ultimi tre mesi, GB mi ha fatto visita come un amico che passa per una birra.
A volte era solo:
: 66.249.76.136 /page1.html Mozilla/5.0 (compatibile; Googlebot/2.1; +http://www.google.com/bot.html)
: 66.249.76.136 /page5.html Mozilla/5.0 (compatibile; Googlebot/2.1; +http://www.google.com/bot.html)
: 66.249.76.140 /page3.html Mozilla/5.0 (compatibile; Googlebot/2.1; +http://www.google.com/bot.html)
: 66.249.64.72 /page2.html Mozilla/5.0 (compatibile; Googlebot/2.1; +http://www.google.com/bot.html)
: 66.249.64.72 /page6.html Mozilla/5.0 (compatibile; Googlebot/2.1; +http://www.google.com/bot.html)
A volte ha portato i suoi amici:
: 64.233.172.231 /page1.html Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, come Gecko; Google Search Console) Chrome/41.0.2272.118 Safari/537.36
: 66.249.69.235 /image.jpg Googlebot-Image/1.0
: 66.249.76.156 /page2.html Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, come Gecko) Chrome/41.0.2272.96 Mobile Safari/537.36 (compatibile; Googlebot/2.1; +http://www.google.com/bot.html)
E ci siamo divertiti molto a fare diversi giochi:
Catch: Ho osservato come GB ama eseguire reindirizzamenti 301 e strisciare le immagini, ed eseguire da canonicals.
Hide-and-seek: Googlebot si nascondeva nei contenuti nascosti (che, come sostengono i suoi genitori, non tollera ed evita)
Survival: Ho preparato delle trappole e ho aspettato che le facesse scattare.
Oostacoli: Ho messo degli ostacoli con vari livelli di difficoltà per vedere come il mio piccolo amico li avrebbe affrontati.
Come potete probabilmente capire, non sono rimasto deluso. Ci siamo divertiti molto e siamo diventati buoni amici. Credo che la nostra amicizia abbia un futuro luminoso.
Ma veniamo al punto!
Ho costruito un sito web con contenuti relativi ai meriti su un’agenzia di viaggi interstellari che offre voli verso pianeti ancora da scoprire nella nostra galassia e oltre.
Il contenuto sembrava avere molti meriti quando in realtà era un carico di sciocchezze.
La struttura del sito sperimentale era così:
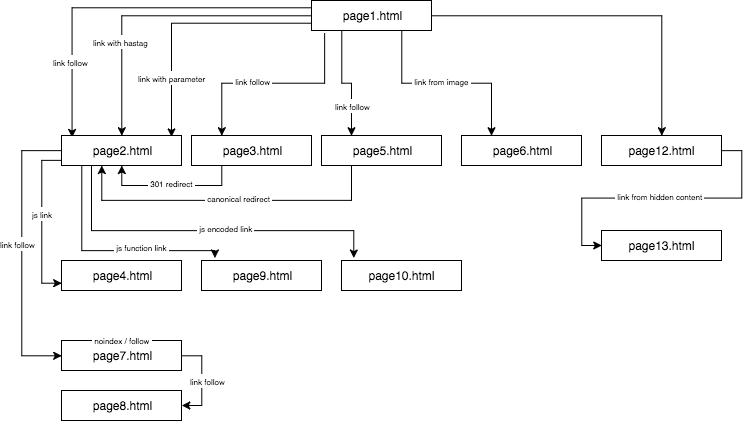
Ho fornito un contenuto unico e mi sono assicurato che ogni anchor/titolo/alt, così come altri coefficienti, fossero globalmente unici (parole false). Per rendere le cose più facili per il lettore, nella descrizione non userò nomi come anchor cutroicano matestito, ma invece li riferirò come anchor1, ecc.
Si consiglia di tenere la mappa di cui sopra aperta in una finestra separata mentre si legge questo articolo.
- Parte 1: Il primo link conta
- Link a un sito web con un’ancora
- Link a un sito web con un parametro
- Link a un sito web da un reindirizzamento
- Link a una pagina usando il tag canonical
- Parte 2: Crawl budget
- Link JavaScript con un evento onclick
- Link JavaScript con una funzione interna
- JavaScript link con codifica
- Parte 3: Contenuto nascosto
- A proposito dell’autore
Parte 1: Il primo link conta
Una delle cose che volevo testare in questo esperimento SEO era la regola del primo link che conta – se può essere omesso e come influenza l’ottimizzazione.
La regola del primo link conta dice che su una pagina, Google Bot vede solo il primo link a una sottopagina. Se avete due link alla stessa sottopagina su una pagina, il secondo sarà ignorato, secondo questa regola. Google Bot ignorerà l’ancora nel secondo e in ogni link consecutivo durante il calcolo del rango della pagina.
È un problema ampiamente sorvegliato da molti specialisti, ma presente soprattutto nei negozi online, dove i menu di navigazione distorcono significativamente la struttura del sito.
Nella maggior parte dei negozi, abbiamo un menu a discesa statico (visibile nel sorgente della pagina), che dà, per esempio, quattro link alle categorie principali e 25 link nascosti alle sottocategorie. Durante la mappatura della struttura di una pagina, GB vede tutti i link (su ogni pagina con un menu), il che fa sì che tutte le pagine abbiano la stessa importanza durante la mappatura e che il loro potere (juice) sia distribuito in modo uniforme, che assomiglia più o meno a questo:
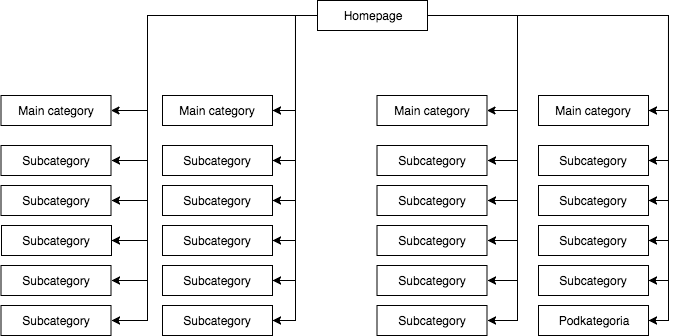
La struttura di pagina più comune ma, secondo me, sbagliata.
L’esempio precedente non può essere definito una struttura corretta perché tutte le categorie sono collegate da tutti i siti dove c’è un menu. Pertanto, sia la home page che tutte le categorie e sottocategorie hanno un numero uguale di link in entrata, e la potenza dell’intero servizio web scorre attraverso di loro con uguale forza. Quindi, la potenza della home page (che di solito è la fonte della maggior parte della potenza a causa del numero di link in entrata) viene divisa in 24 categorie e sottocategorie, quindi ognuna di esse riceve solo il 4% della potenza della homepage.
Come dovrebbe apparire la struttura:

Se avete bisogno di testare velocemente la struttura della vostra pagina e strisciarla come fa Google, Screaming Frog è uno strumento utile.
In questo esempio, la potenza della homepage è divisa in quattro e ciascuna delle categorie riceve il 25% della potenza della homepage e ne distribuisce una parte alle sottocategorie. Questa soluzione fornisce anche una migliore possibilità di collegamento interno. Per esempio, quando si scrive un articolo sul blog del negozio e si vuole collegare a una delle sottocategorie, GB noterà il link durante la scansione del sito web. Nel primo caso, non lo farà a causa della regola First Link Counts. Se il link a una sottocategoria era nel menu del sito, allora quello nell’articolo sarà ignorato.
Ho iniziato questo esperimento SEO con le seguenti azioni:
- Prima, nella pagina1.html, ho incluso un link a una sottopagina page2.html come un classico link dofollow con un’ancora: anchor1.
- Poi, nel testo della stessa pagina, ho incluso riferimenti leggermente modificati per verificare se GB sarebbe stato desideroso di scansionarli.
A tal fine, ho testato le seguenti soluzioni:
- Alla homepage del servizio web, ho assegnato un link esterno dofollow per una frase con un’ancora URL (quindi qualsiasi collegamento esterno della homepage e delle sottopagine per determinate frasi era fuori questione) – ha accelerato l’indicizzazione del servizio.
- Ho aspettato che la pagina2.html cominciasse a classificarsi per una frase dal primo link dofollow (anchor1) proveniente dalla pagina1.html. Questa frase falsa, o qualsiasi altra che ho testato non poteva essere trovata sulla pagina di destinazione. Ho supposto che se altri link avrebbero funzionato, allora anche la pagina2.html si sarebbe classificata nei risultati di ricerca per altre frasi da altri link. Ci sono voluti circa 45 giorni. E poi sono stato in grado di fare la prima importante conclusione.
Anche un sito web, dove una parola chiave non è né nel contenuto, né nel meta titolo, ma è collegato con un ancoraggio ricercato, può facilmente classificarsi nei risultati di ricerca più in alto di un sito web che contiene questa parola ma non è collegato a una parola chiave.
Inoltre, la homepage (page1.html), che conteneva la frase ricercata, era la pagina più forte del servizio web (collegata dal 78% delle sottopagine) e tuttavia, si è classificata più in basso sulla frase ricercata rispetto alla sottopagina (page2.html) collegata alla frase ricercata.
Di seguito, presento quattro tipi di link che ho testato, tutti dopo il primo link dofollow che porta alla pagina2.html.
Link a un sito web con un’ancora
< a href=”page2.html#testhash” >anchor2< /a >
Il primo dei link aggiuntivi che arrivano nel codice dietro il link dofollow era un link con un’ancora (un hashtag). Volevo vedere se GB sarebbe passato attraverso il link e avrebbe indicizzato anche la pagina2.html sotto la frase anchor2, nonostante il fatto che il link porta a quella pagina (pagina2.html) ma l’URL essendo cambiato in pagina2.html#testhash usa anchor2.
Purtroppo, GB non ha mai voluto ricordare quel collegamento e non ha diretto la potenza alla sottopagina pagina2.html per quella frase. Di conseguenza, nei risultati di ricerca per la frase anchor2 il giorno della stesura di questo articolo, c’è solo la sottopagina page1.html, dove la parola si trova nell’ancora del link. Cercando su Google la frase testhash, il nostro dominio non è nemmeno classificato.
Link a un sito web con un parametro
page2.html?parameter=1
Inizialmente, GB era interessato a questa parte divertente dell’URL subito dopo il marchio di query e l’ancora all’interno del link anchor3.
Intrigato, GB cercava di capire cosa intendessi. Ha pensato: “È un indovinello?”. Per evitare di indicizzare il contenuto duplicato sotto gli altri URL, il canonico page2.html puntava su se stesso. I logs hanno registrato complessivamente 8 crawls su questo indirizzo, ma le conclusioni sono state piuttosto tristi:
- Dopo 2 settimane, la frequenza delle visite di GB è diminuita significativamente fino a quando alla fine se n’è andato e non ha più strisciato quel link.
- pagina2.html non è stata indicizzata sotto la frase anchor3, né il parametro con il parametro URL1. Secondo Search Console, questo link non esiste (non viene contato tra i link in entrata), ma allo stesso tempo, la frase anchor3 è elencata come frase ancorata.
Link a un sito web da un reindirizzamento
Ho voluto forzare GB a scansionare di più il mio sito web, il che ha portato GB, ogni paio di giorni, a inserire il link dofollow con un anchor4 su page1.html che porta a page3.html, che reindirizza con un codice 301 a page2.html. Purtroppo, come nel caso della pagina con un parametro, dopo 45 giorni la pagina2.html non era ancora posizionata nei risultati di ricerca per la frase anchor4 che appariva nel link reindirizzato sulla pagina1.html.
Tuttavia, in Google Search Console, nella sezione Anchor Texts, anchor4 è visibile e indicizzato. Questo potrebbe indicare che, dopo un po’, il reindirizzamento inizierà a funzionare come previsto, in modo che la pagina2.html si classificherà nei risultati di ricerca per anchor4 nonostante sia il secondo link alla stessa pagina di destinazione all’interno dello stesso sito web.
Link a una pagina usando il tag canonical
Sulla pagina1.html, ho messo un riferimento alla pagina5.html (follow link) con un anchor anchor5. Allo stesso tempo, nella pagina5.html c’era un contenuto unico, e nella sua testa, c’era un tag canonico a pagina2.html.
< link rel=”canonical” href=”https://example.com/page2.html” />
Questo test ha dato i seguenti risultati:
- Il link per la frase anchor5 diretto a pagina5.html che reindirizza canonicamente a pagina2.html non è stato trasferito alla pagina di destinazione (come negli altri casi).
- pagina5.html è stato indicizzato nonostante il tag canonico.
- pagina5.html non si è classificato nei risultati di ricerca per anchor5.
- pagina5.html si classificava sulle frasi usate nel testo della pagina, il che indicava che GB ignorava totalmente i tag canonical.
Si azzarderebbe a sostenere che l’uso di rel=canonical per impedire l’indicizzazione di alcuni contenuti (ad esempio durante il filtraggio) semplicemente non potrebbe funzionare.
Parte 2: Crawl budget
Mentre progettavo una strategia SEO, volevo far ballare GB al mio ritmo e non il contrario. A questo scopo, ho verificato i processi SEO a livello dei log del server (log di accesso e log di errore) che mi hanno fornito un enorme vantaggio. Grazie a ciò, conoscevo ogni movimento di GB e come reagiva ai cambiamenti che introducevo (ristrutturazione del sito, capovolgimento del sistema di linking interno, modo di visualizzare le informazioni) nell’ambito della campagna SEO.
Uno dei miei compiti durante la campagna SEO era quello di ricostruire un sito web in modo da far visitare a GB solo gli URL che sarebbe stato in grado di indicizzare e che noi volevamo che indicizzasse. In poche parole: nell’indice di Google dovrebbero esserci solo le pagine che sono importanti per noi dal punto di vista del SEO. D’altra parte, GB dovrebbe scansionare solo i siti web che vogliamo siano indicizzati da Google, il che non è ovvio per tutti, per esempio, quando un negozio online implementa il filtraggio per colori, dimensioni e prezzi, e lo fa manipolando i parametri URL, per esempio:
esempio.com/women/shoes/?color=red&size=40&price=200-250
Può risultare che una soluzione che permette a GB di scansionare gli URL dinamici gli fa dedicare del tempo per perlustrare (ed eventualmente indicizzare) invece di scansionare la pagina.
esempio.com/women/shoes/
Questi URL creati dinamicamente non solo sono inutili, ma potenzialmente dannosi per il SEO perché possono essere scambiati per contenuto sottile, il che si tradurrà in un calo del ranking del sito.
In questo esperimento ho anche voluto verificare alcuni metodi di strutturazione senza usare rel=”nofollow”, bloccando GB nel file robots.txt o mettendo parte del codice HTML in frame che sono invisibili per il bot (iframe bloccato).
Ho testato tre tipi di link JavaScript.
Link JavaScript con un evento onclick
Un semplice link costruito su JavaScript
< a href=”javascript:void(0)” onclick=”window.location.href =’page4.html'” >anchor6< /a >
GB passa facilmente alla sottopagina page4.html e indicizza l’intera pagina. La sottopagina non si classifica nei risultati di ricerca per la frase anchor6, e questa frase non può essere trovata nella sezione Anchor Texts in Google Search Console. La conclusione è che il link non ha trasferito il succo.
Per riassumere:
- Un classico link JavaScript permette a Google di scansionare il sito e indicizzare le pagine che incontra.
- Non trasferisce il succo – è neutrale.
Link JavaScript con una funzione interna
Ho deciso di alzare il tiro ma, con mia sorpresa, GB ha superato l’ostacolo in meno di 2 ore dalla pubblicazione del link.
< a href=”javascript:void(0)” class=”js-link” data-url=”page9.html” >anchor7< /a >
Per far funzionare questo link, ho usato una funzione esterna, che aveva lo scopo di leggere l’URL dai dati e il reindirizzamento – solo il reindirizzamento di un utente, come speravo – al target page9.html. Come nel caso precedente, la pagina9.html era stata completamente indicizzata.
Quello che è interessante è che, nonostante la mancanza di altri link in entrata, la pagina9.html era la terza pagina più visitata da GB nell’intero servizio web, subito dopo la pagina1.html e la pagina2.html.
Ho già usato questo metodo per strutturare servizi web. Tuttavia, come possiamo vedere, non funziona più. Nel SEO nulla vive per sempre, a parte le Pagine Gialle.
JavaScript link con codifica
Ancora, non mi sarei arreso e decisi che doveva esserci un modo per chiudere efficacemente la porta in faccia a GB. Così, ho costruito una semplice funzione, codificando i dati con un algoritmo base64, e il riferimento era così:
< a href=”javascript:void(0)” class=”js-link” data-url=”cGFnZTEwLmh0bWw=” >anchor8< /a >
Come risultato, GB non era in grado di produrre un codice JavaScript che potesse sia decodificare il contenuto di un attributo data-URL che reindirizzare. Ed ecco fatto! Abbiamo un modo per strutturare un servizio web senza usare rel=nonfollows per impedire ai bot di strisciare dove vogliono! In questo modo, non sprechiamo il nostro crawl-budget, che è particolarmente importante nel caso di grandi servizi web, e GB finalmente balla al nostro ritmo. Sia che la funzione sia stata introdotta nella stessa pagina nella sezione head o in un file JS esterno, non ci sono prove di un bot né nei log del server né in Search Console.
Parte 3: Contenuto nascosto
Nel test finale, ho voluto verificare se il contenuto, per esempio, delle schede nascoste sarebbe stato considerato e indicizzato da GB o se Google ha reso una tale pagina e ignorato il testo nascosto, come alcuni specialisti hanno sostenuto.
Volevo confermare o respingere questa affermazione. Per farlo, ho messo un muro di testo con oltre 2000 segni su page12.html e ho nascosto un blocco di testo con circa il 20% del testo (400 segni) in Cascading Style Sheets e ho aggiunto il pulsante mostra di più. All’interno del testo nascosto c’era un link alla pagina13.html con un’ancora9.
Non c’è dubbio che un bot può rendere una pagina. Possiamo osservarlo sia in Google Search Console che in Google Insight Speed. Tuttavia, i miei test hanno rivelato che un blocco di testo visualizzato dopo aver fatto clic sul pulsante mostra di più è stato completamente indicizzato. Le frasi nascoste nel testo erano classificate nei risultati di ricerca e GB seguiva i link nascosti nel testo. Inoltre, le ancore dei link da un blocco di testo nascosto erano visibili in Google Search Console nella sezione Anchor Text e anche la pagina13.html ha iniziato a classificarsi nei risultati di ricerca per la parola chiave anchor9.
Questo è fondamentale per i negozi online, dove il contenuto è spesso inserito in schede nascoste. Ora siamo sicuri che GB vede il contenuto nelle schede nascoste, le indicizza e trasferisce il succo dai link che vi sono nascosti.
La conclusione più importante che sto traendo da questo esperimento è che non ho trovato un modo diretto per aggirare la regola First Link Counts usando link modificati (link con parametro, redirect 301, canonicals, anchor link). Allo stesso tempo, è possibile costruire la struttura di un sito web utilizzando link Javascript, grazie ai quali siamo liberi dalle restrizioni della First Link Counts Rule. Inoltre, Google Bot può vedere e indicizzare il contenuto nascosto nei segnalibri e segue i link nascosti in essi.
Iscriviti ai nostri recaps quotidiani del panorama del search marketing in continua evoluzione.
Nota: Inviando questo modulo, accetti i termini di Third Door Media. Rispettiamo la tua privacy.
A proposito dell’autore

“Non accettare ‘solo’ l’alta qualità. Chiunque può farlo. Se il cielo è il limite, trovate un cielo più alto”. Max Cyrek è CEO di Cyrek Digital, un consulente di marketing digitale e SEO evangelist. Nel corso della sua carriera, Max, insieme al suo team di oltre 30 persone, ha lavorato con centinaia di aziende aiutandole ad avere successo. Lavora nel marketing digitale da quasi dieci anni e si è specializzato in SEO tecnico, gestendo progetti di marketing di successo.
Lascia un commento