Le persone stanno creando, condividendo e memorizzando dati a un ritmo più veloce che in qualsiasi altro momento della storia. Quando si tratta di innovare l’archiviazione e la trasmissione dei dati, a Facebook stiamo facendo progressi non solo nell’hardware – come dischi rigidi più grandi e attrezzature di rete più veloci – ma anche nel software. Il software aiuta l’elaborazione dei dati attraverso la compressione, che codifica le informazioni, come testo, immagini e altre forme di dati digitali, usando meno bit dell’originale. Questi file più piccoli occupano meno spazio sui dischi rigidi e vengono trasmessi più velocemente ad altri sistemi. C’è però un compromesso nel comprimere e decomprimere le informazioni: il tempo. Più tempo viene speso per comprimere in un file più piccolo, più lento è l’elaborazione dei dati.
Oggi, lo standard di compressione dati che regna è Deflate, l’algoritmo centrale di Zip, gzip e zlib. Per due decenni, ha fornito un impressionante equilibrio tra velocità e spazio, e, come risultato, è usato in quasi tutti i moderni dispositivi elettronici (e, non a caso, usato per trasmettere ogni byte del post del blog che state leggendo). Nel corso degli anni, altri algoritmi hanno offerto o una migliore compressione o una compressione più veloce, ma raramente entrambi. Crediamo di aver cambiato questa situazione.
Siamo entusiasti di annunciare Zstandard 1.0, un nuovo algoritmo di compressione e un’implementazione progettata per scalare con l’hardware moderno e comprimere più piccoli e più velocemente. Zstandard combina recenti scoperte di compressione, come Finite State Entropy, con un design incentrato sulle prestazioni – e quindi ottimizza l’implementazione per le proprietà uniche delle CPU moderne. Come risultato, migliora i compromessi fatti da altri algoritmi di compressione e ha una vasta gamma di applicabilità con una velocità di decompressione molto alta. Zstandard, disponibile ora sotto la licenza BSD, è progettato per essere usato in quasi tutti gli scenari di compressione senza perdita, inclusi molti dove gli algoritmi attuali non sono applicabili.
- Confronto della compressione
- Scalabilità
- Sotto il cofano
- Memoria
- Un formato progettato per l’esecuzione parallela
- Design senza ramificazioni
- Finite State Entropy: Un compressore di probabilità di nuova generazione
- Modellazione del codice a barre
- Zstandard in pratica
- Piccoli dati
- Dizionari in azione
- Scegliere un livello di compressione
- Provalo
- Altro a venire
Confronto della compressione
Ci sono tre metriche standard per confrontare algoritmi di compressione e implementazioni:
- Rapporto di compressione: La dimensione originale (numeratore) rispetto alla dimensione compressa (denominatore), misurata in dati senza unità come un rapporto di dimensione di 1.0 o maggiore.
- Velocità di compressione: Quanto velocemente possiamo rendere i dati più piccoli, misurata in MB/s di dati di input consumati.
- Velocità di decompressione: quanto velocemente possiamo ricostruire i dati originali dai dati compressi, misurati in MB/s per la velocità con cui i dati vengono prodotti dai dati compressi.
Il tipo di dati compressi può influenzare queste metriche, così molti algoritmi sono sintonizzati per specifici tipi di dati, come testo inglese, sequenze genetiche o immagini rasterizzate. Tuttavia, Zstandard, come zlib, è pensato per la compressione generale per una varietà di tipi di dati. Per rappresentare gli algoritmi su cui Zstandard dovrebbe lavorare, in questo post useremo il corpus Silesia, un insieme di file che rappresentano i tipici tipi di dati usati ogni giorno.
Alcuni algoritmi e implementazioni comunemente usati oggi sono zlib, lz4 e xz. Ognuno di questi algoritmi offre diversi compromessi: lz4 punta alla velocità, xz punta a rapporti di compressione più alti, e zlib punta a un buon equilibrio tra velocità e dimensione. La tabella sottostante indica i compromessi approssimativi del rapporto di compressione predefinito degli algoritmi e della velocità per il corpus Silesia, confrontando gli algoritmi con lzbench, un benchmark in-memory puro inteso a modellare le prestazioni grezze degli algoritmi.
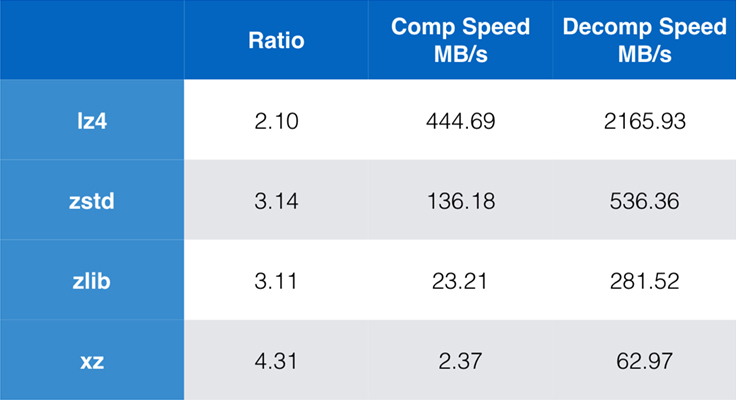
Come sottolineato, ci sono spesso compromessi drastici tra velocità e dimensione. L’algoritmo più veloce, lz4, risulta in rapporti di compressione più bassi; xz, che ha il rapporto di compressione più alto, soffre di una velocità di compressione lenta. Tuttavia, Zstandard, con l’impostazione predefinita, mostra miglioramenti sostanziali sia nella velocità di compressione che di decompressione, mentre comprime con lo stesso rapporto di zlib.
Mentre le prestazioni dell’algoritmo puro sono importanti quando la compressione è incorporata in un’applicazione più grande, è estremamente comune usare anche strumenti a riga di comando per la compressione – per esempio, per comprimere file di log, tarball, o altri dati simili destinati all’archiviazione o al trasferimento. In questi casi, le prestazioni sono spesso influenzate dall’overhead, come il checksumming. Questo grafico mostra il confronto tra gli strumenti a riga di comando gzip e zstd su Centos 7 costruito con il compilatore predefinito del sistema.
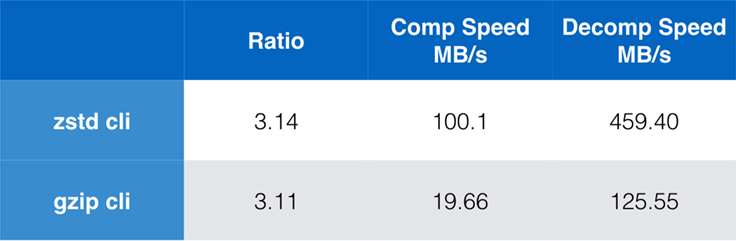
I test sono stati condotti 10 volte ciascuno, con i tempi minimi presi, e sono stati condotti su ramdisk per evitare l’overhead del filesystem. Questi erano i comandi (che usano i livelli di compressione predefiniti per entrambi gli strumenti):
zstd -c -3 silesia.tar > silesia.tar.zst # 67,432,740 byteszstd -d -c silesia.tar.zst > /dev/nullgzip -c -6 silesia.tar > silesia.tar.gz # 68,235,522 bytesgzip -d -c silesia.tar.gz > /dev/nullScalabilità
Se un algoritmo è scalabile, ha la capacità di adattarsi a un’ampia varietà di requisiti, e Zstandard è progettato per eccellere nel panorama attuale e per scalare nel futuro. La maggior parte degli algoritmi ha dei “livelli” basati su compromessi tempo/spazio: Più alto è il livello, maggiore è la compressione ottenuta con una perdita di velocità di compressione. Zlib offre nove livelli di compressione; Zstandard attualmente ne offre 22, il che permette compromessi flessibili e granulari tra velocità di compressione e rapporti per i dati futuri. Per esempio, possiamo usare il livello 1 se la velocità è più importante e il livello 22 se la dimensione è più importante.
Di seguito c’è un grafico della velocità di compressione e del rapporto raggiunto per tutti i livelli di Zstandard e zlib. L’asse x è una scala logaritmica decrescente in megabyte al secondo; l’asse y è il rapporto di compressione raggiunto. Per confrontare gli algoritmi, puoi scegliere una velocità per vedere i vari rapporti che gli algoritmi raggiungono a quella velocità. Allo stesso modo, puoi scegliere un rapporto e vedere quanto sono veloci gli algoritmi quando raggiungono quel livello.
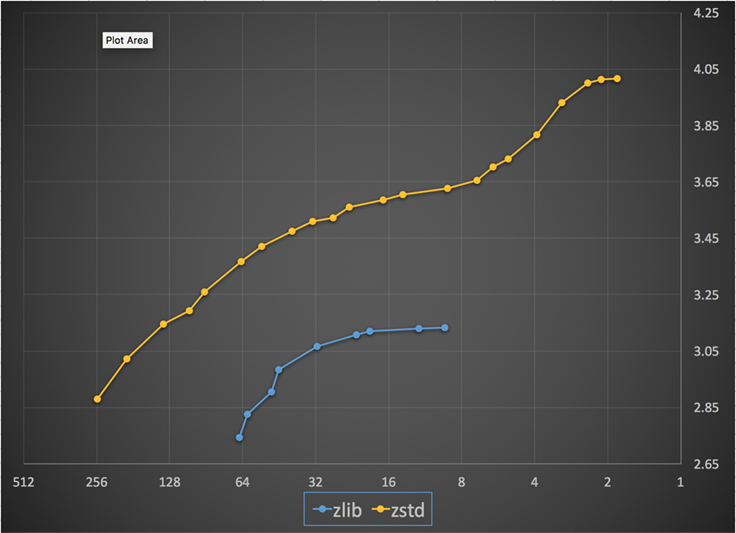
Per qualsiasi linea verticale (cioè, velocità di compressione), Zstandard raggiunge un rapporto di compressione più alto. Per il corpus Silesia, la velocità di decompressione – indipendentemente dal rapporto – era di circa 550 MB/s per Zstandard e 270 MB/s per zlib. Il grafico mostra un’altra differenza tra Zstandard e le alternative: Usando un algoritmo e un’implementazione, Zstandard permette una regolazione molto più fine per ogni caso d’uso. Questo significa che Zstandard può competere con alcuni degli algoritmi di compressione più veloci e più alti, mantenendo un sostanziale vantaggio di velocità di decompressione. Questi miglioramenti si traducono direttamente in un trasferimento di dati più veloce e in minori requisiti di archiviazione.
In altre parole, rispetto a zlib, Zstandard scala:
- Allo stesso rapporto di compressione, comprime sostanzialmente più velocemente: ~3-5x.
- Alla stessa velocità di compressione, è sostanzialmente più piccolo: 10-15 per cento più piccolo.
- È quasi 2x più veloce nella decompressione, indipendentemente dal rapporto di compressione; i numeri della linea di comando mostrano una differenza ancora maggiore: più di 3x più veloce.
- Si adatta a rapporti di compressione molto più alti, pur mantenendo velocità di decompressione fulminee.
Sotto il cofano
Zstandard migliora zlib combinando diverse innovazioni recenti e puntando all’hardware moderno:
Memoria
Da progetto, zlib è limitato a una finestra di 32 KB, che era una scelta ragionevole nei primi anni ’90. Ma, l’ambiente informatico di oggi può accedere a molta più memoria – anche in ambienti mobili ed embedded.
Zstandard non ha limiti intrinseci e può indirizzare terabyte di memoria (anche se raramente lo fa). Per esempio, il più basso dei 22 livelli usa 1 MB o meno. Per la compatibilità con una vasta gamma di sistemi di ricezione, dove la memoria può essere limitata, si raccomanda di limitare l’uso della memoria a 8 MB. Questa è una raccomandazione di sintonizzazione, tuttavia, non una limitazione del formato di compressione.
Un formato progettato per l’esecuzione parallela
Le CPU di oggi sono molto potenti e possono emettere diverse istruzioni per ciclo, grazie alle ALU multiple (unità logiche aritmetiche) e a un design di esecuzione fuori ordine sempre più avanzato.
In sostanza, significa che se:
a = b1 + b2
c = d1 + d2
allora sia a che c saranno calcolati in parallelo.
Questo è possibile solo se non c’è relazione tra loro. Quindi, in questo esempio:
a = b1 + b2
c = d1 + a
c deve aspettare che a sia calcolato per primo, e solo allora inizierà il calcolo di c.
Significa che, per trarre vantaggio dalla moderna CPU, si deve progettare un flusso di operazioni con poche o nessuna dipendenza di dati.
Questo si ottiene con Zstandard separando i dati in più flussi paralleli. Un decodificatore Huffman di nuova generazione, Huff0, è in grado di decodificare più simboli in parallelo con un singolo core. Tale guadagno è cumulativo con il multi-threading, che utilizza più core.
Design senza ramificazioni
Le nuove CPU sono più potenti e raggiungono frequenze molto alte, ma questo è possibile solo grazie a un approccio multistadio, dove un’istruzione è suddivisa in una pipeline di più passi. Ad ogni ciclo di clock, la CPU è in grado di emettere il risultato di più operazioni, a seconda delle ALU disponibili. Più ALU vengono utilizzate, più lavoro sta facendo la CPU, e quindi più velocemente avviene la compressione. Mantenere le ALU alimentate con il lavoro è cruciale per le prestazioni della CPU moderna.
Questo risulta essere difficile. Considerate la seguente semplice situazione:
if (condition) doSomething() else doSomethingElse()Quando incontra questo, la CPU non sa cosa fare, poiché dipende dal valore di condition. Una CPU prudente aspetterebbe il risultato di condition prima di lavorare su entrambi i rami, il che sarebbe estremamente dispendioso.
Le CPU di oggi scommettono. Lo fanno in modo intelligente, grazie a un predittore di ramo, che dice loro in sostanza il risultato più probabile della valutazione di condition. Quando la scommessa è giusta, la pipeline rimane piena e le istruzioni vengono emesse continuamente. Quando la scommessa è sbagliata (una previsione errata), la CPU deve fermare tutte le operazioni iniziate speculativamente, tornare al ramo e prendere l’altra direzione. Questo si chiama pipeline flush, ed è estremamente costoso nelle CPU moderne.
Venticinque anni fa, il pipeline flush era un non problema. Oggi è così importante che è essenziale progettare formati compatibili con algoritmi branchless. Come esempio, guardiamo un aggiornamento bit-stream:
/* classic version */while (nbBitsUsed >= 8) { /* each while test is a branch */ accumulator <<= 8; accumulator += *byte++; nbBitsUsed -= 8;} /*>/* branch-less version */nbBytesUsed = nbBitsUsed >> 3;nbBitsUsed &= 7;ptr += nbBytesUsed;accumulator = read64(ptr);Come potete vedere, la versione branchless ha un carico di lavoro prevedibile, senza alcuna condizione. La CPU farà sempre lo stesso lavoro, e quel lavoro non viene mai buttato via a causa di un’errata previsione. Al contrario, la versione classica fa meno lavoro quando (nbBitsUsed < 8). Ma il test in sé non è libero, e ogni volta che il test viene indovinato in modo errato, risulta in un lavaggio completo della pipeline, che costa più del lavoro fatto dalla versione senza rami.
Come potete immaginare, questo effetto collaterale ha un impatto sul modo in cui i dati vengono impacchettati, letti e decodificati. Zstandard è stato creato per essere amichevole con gli algoritmi senza diramazioni, specialmente all’interno dei cicli critici.
Finite State Entropy: Un compressore di probabilità di nuova generazione
Nella compressione, i dati vengono prima trasformati in un insieme di simboli (lo stadio di modellazione), e poi questi simboli vengono codificati usando un numero minimo di bit. Questo secondo stadio è chiamato stadio dell’entropia, in memoria di Claude Shannon, che calcola con precisione il limite di compressione di un insieme di simboli con determinate probabilità (chiamato “limite di Shannon”). L’obiettivo è quello di avvicinarsi a questo limite utilizzando il minor numero possibile di risorse della CPU.
Un algoritmo molto comune è la codifica Huffman, in uso in Deflate. Fornisce il miglior codice di prefisso possibile, assumendo che ogni simbolo sia descritto con un numero naturale di bit (1 bit, 2 bit …). Questo funziona benissimo in pratica, ma il limite dei numeri naturali significa che è impossibile raggiungere alti rapporti di compressione, perché un simbolo consuma necessariamente almeno 1 bit.
Un metodo migliore è chiamato codifica aritmetica, che può avvicinarsi arbitrariamente al limite di Shannon -log2(P), consumando quindi frazioni di bit per simbolo. Si traduce in un migliore rapporto di compressione quando le probabilità sono alte, ma utilizza anche più potenza della CPU. In pratica, anche i codificatori aritmetici ottimizzati lottano per la velocità, specialmente sul lato della decompressione, che richiede divisioni con un risultato prevedibile (ad esempio, non una virgola mobile) e che si rivela essere lento.
Finite State Entropy è basato su una nuova teoria chiamata ANS (Asymmetric Numeral System) di Jarek Duda. Finite State Entropy è una variante che precomputa molti passi di codifica in tabelle, risultando in un codec di entropia preciso come la codifica aritmetica, usando solo aggiunte, lookup di tabelle e spostamenti, che è circa lo stesso livello di complessità di Huffman. Riduce anche la latenza per accedere al simbolo successivo, poiché è immediatamente accessibile dal valore di stato, mentre Huffman richiede una precedente operazione di decodifica del bit-stream. Spiegare come funziona è al di fuori dello scopo di questo post, ma se siete interessati, c’è una serie di articoli che dettagliano il suo funzionamento interno.
Modellazione del codice a barre
La modellazione del codice a barre comprime in modo efficiente i dati strutturati, che presentano sequenze di contenuto quasi equivalente, che differiscono solo di uno o pochi byte. Questo metodo non è nuovo, ma è stato usato per la prima volta dopo la pubblicazione di Deflate, quindi non esiste all’interno di zlib/gzip.
L’efficienza del repcode modeling dipende fortemente dal tipo di dati da comprimere, variando ovunque da un miglioramento di compressione a due cifre. Questi miglioramenti combinati si sommano ad un’esperienza di compressione migliore e più veloce, offerta all’interno della libreria Zstandard.
Zstandard in pratica
Come detto prima, ci sono diversi casi d’uso tipici della compressione. Affinché un algoritmo sia convincente, deve essere straordinariamente buono in un caso d’uso specifico, come la compressione di testo leggibile dall’uomo, o molto buono in molti casi d’uso diversi. Zstandard adotta il secondo approccio. Un modo di pensare ai casi d’uso è quante volte uno specifico pezzo di dati potrebbe essere decompresso. Zstandard ha vantaggi in tutti questi casi.
Molte volte. Per i dati trattati molte volte, la velocità di decompressione e la possibilità di optare per un rapporto di compressione molto alto senza compromettere la velocità di decompressione è vantaggiosa. La memorizzazione del grafico sociale su Facebook, per esempio, viene letta ripetutamente mentre voi e i vostri amici interagite con il sito. Al di fuori di Facebook, esempi di quando i dati devono essere decompressi molte volte includono i file scaricati da un server, come il codice sorgente del kernel Linux o gli RPM installati sui server, il JavaScript e il CSS utilizzati da una pagina web, o l’esecuzione di migliaia di MapReduce sui dati in un data warehouse.
Solo una volta. Per i dati compressi solo una volta, specialmente per la trasmissione su una rete, la compressione è un momento fugace nel flusso di dati. Il minor overhead sul server significa che il server può gestire più richieste al secondo. Il minor overhead sul client significa che i dati possono essere gestiti più rapidamente. Tipicamente questo viene fuori con situazioni client/server in cui i dati sono unici per il client, come una risposta del server web che è personalizzata – ad esempio, i dati utilizzati per il rendering quando si riceve una nota da un amico su Messenger. Il risultato netto è che il vostro dispositivo mobile carica le pagine più velocemente, usa meno batteria e consuma meno del vostro piano dati. Zstandard in particolare si adatta agli scenari mobili molto meglio di altri algoritmi a causa di come gestisce i dati piccoli.
Possibilmente mai. Anche se apparentemente controintuitivo, è spesso il caso che un pezzo di dati – come i backup o i file di log – non sarà mai decompresso ma può essere letto se necessario. Per questo tipo di dati, la compressione in genere deve essere veloce, rendere i dati piccoli (con un compromesso tempo/spazio adatto alla situazione), e forse memorizzare un checksum, ma altrimenti essere invisibile. Nella rara occasione in cui è necessario decomprimere, non si vuole che la compressione rallenti il caso d’uso operativo. La decompressione veloce è vantaggiosa perché spesso è una piccola parte dei dati (come un file specifico nel backup o un messaggio in un file di log) che deve essere trovata velocemente.
In tutti questi casi, Zstandard porta l’abilità di comprimere e decomprimere molte volte più velocemente di gzip, con i dati compressi risultanti che sono più piccoli.
Piccoli dati
C’è un altro caso d’uso della compressione che riceve meno attenzione ma può essere abbastanza importante: piccoli dati. Questi sono modelli d’uso in cui i dati sono prodotti e consumati in piccole quantità, come i messaggi JSON tra un server web e un browser (tipicamente centinaia di byte) o pagine di dati in un database (pochi kilobyte).
I database forniscono un caso d’uso interessante. Sistemi come MySQL, PostgreSQL e MongoDB memorizzano tutti dati destinati all’accesso in tempo reale. I recenti vantaggi dell’hardware, in particolare intorno alla proliferazione dei dispositivi flash (SSD), hanno cambiato fondamentalmente l’equilibrio tra dimensioni e throughput – ora viviamo in un mondo in cui le IOP (operazioni IO al secondo) sono piuttosto alte, ma la capacità dei nostri dispositivi di archiviazione è inferiore a quando i dischi rigidi dominavano il data center.
Inoltre, flash ha una proprietà interessante per quanto riguarda la resistenza alla scrittura – dopo migliaia di scritture sulla stessa sezione del dispositivo, quella sezione non può più accettare scritture, spesso portando alla rimozione del dispositivo dal servizio. Quindi è naturale cercare modi per ridurre la quantità di dati che vengono scritti perché può significare più dati per server e bruciare il dispositivo ad un ritmo più lento. La compressione dei dati è una strategia per questo, e anche i database sono spesso ottimizzati per le prestazioni, il che significa che le prestazioni di lettura e scrittura sono ugualmente importanti.
C’è però una complicazione nell’uso della compressione dei dati con i database. Ai database piace accedere ai dati in modo casuale, mentre la maggior parte dei casi d’uso tipici per la compressione leggono un intero file in ordine lineare. Questo è un problema perché la compressione dei dati funziona essenzialmente prevedendo il futuro sulla base del passato – gli algoritmi guardano i tuoi dati in modo sequenziale e predicono ciò che potrebbe vedere in futuro. Più accurate sono le previsioni, più piccoli possono essere i dati.
Quando si comprimono piccoli dati, come le pagine di un database o piccoli documenti JSON inviati al dispositivo mobile, semplicemente non c’è molto “passato” da usare per prevedere il futuro. Gli algoritmi di compressione hanno tentato di affrontare questo problema utilizzando dizionari pre-condivisi per un’efficace partenza rapida. Questo viene fatto pre-condividendo un insieme statico di dati “passati” come seme per la compressione.
Zstandard si basa su questo approccio con algoritmi altamente ottimizzati e API per la compressione dei dizionari. Inoltre, Zstandard include strumenti (zstd --train) per creare facilmente dizionari per applicazioni personalizzate e disposizioni per registrare dizionari standard da condividere con comunità più ampie. Mentre la compressione varia in base ai campioni di dati, la compressione di piccoli dati può variare ovunque da 2x a 5x meglio della compressione senza dizionari.
Dizionari in azione
Mentre può essere difficile giocare con un dizionario nel contesto di un database in esecuzione (richiede modifiche significative al database, dopo tutto), si possono vedere dizionari in azione con altri tipi di piccoli dati. JSON, la lingua franca dei piccoli dati nel mondo moderno, tende ad essere piccoli record ripetitivi. Ci sono innumerevoli set di dati pubblici disponibili; per lo scopo di questa dimostrazione, useremo il set di dati “utente” di GitHub, disponibile via HTTP. Ecco un esempio di voce da questo set di dati:
{ "login": "octocat", "id": 1, "avatar_url": "https://github.com/images/error/octocat_happy.gif", "gravatar_id": "", "url": "https://api.github.com/users/octocat", "html_url": "https://github.com/octocat", "followers_url": "https://api.github.com/users/octocat/followers", "following_url": "https://api.github.com/users/octocat/following{/other_user}", "gists_url": "https://api.github.com/users/octocat/gists{/gist_id}", "starred_url": "https://api.github.com/users/octocat/starred{/owner}{/repo}", "subscriptions_url": "https://api.github.com/users/octocat/subscriptions", "organizations_url": "https://api.github.com/users/octocat/orgs", "repos_url": "https://api.github.com/users/octocat/repos", "events_url": "https://api.github.com/users/octocat/events{/privacy}", "received_events_url": "https://api.github.com/users/octocat/received_events", "type": "User", "site_admin": false } Come potete vedere, c’è un bel po’ di ripetizione qui – possiamo comprimerli bene! Ma ogni utente è un po’ meno di 1 KB, e la maggior parte degli algoritmi di compressione ha davvero bisogno di più dati per poter allungare le gambe. Un insieme di 1.000 utenti richiede circa 850 KB per essere memorizzato non compresso. Applicando ingenuamente gzip o zstd individualmente ad ogni file si riduce a poco più di 300 KB; non male! Ma se creiamo un dizionario unico e pre-condiviso, con zstd la dimensione scende a 122 KB – portando il rapporto di compressione originale da 2,8x a 6,9. Questo è un miglioramento significativo, disponibile out-of-box con zstd:
$ zstd --train -o ../json.zdict -r .sorting 982 files of total size 0 MB ...finding patterns ...statistics ...Save dictionary of size 65599 into file ../json.zdict$ du -h --apparent-size .846K .$ zstd --rm -D ../json.zdict -r .$ du -h --apparent-size .122K .Scegliere un livello di compressione
Come mostrato sopra, Zstandard fornisce un numero sostanziale di livelli. Questa personalizzazione è potente ma porta a scelte difficili. Il modo migliore per decidere è quello di rivedere i tuoi dati e misurare, decidendo quali compromessi vuoi fare. A Facebook, troviamo il livello predefinito 3 adatto a molti casi d’uso, ma di tanto in tanto, lo regoleremo leggermente a seconda di quale sia il nostro collo di bottiglia (spesso stiamo cercando di saturare una connessione di rete o un mandrino del disco); altre volte, ci interessa di più la dimensione memorizzata e useremo un livello più alto.
In definitiva, per i risultati più adatti alle vostre esigenze, dovrete considerare sia l’hardware che usate sia i dati che vi interessano – non ci sono prescrizioni dure e veloci che possono essere fatte senza contesto. In caso di dubbio, comunque, attenetevi al livello predefinito di 3 o a qualcosa tra 6 e 9 per un buon compromesso tra velocità e spazio; conservate il livello 20+ per i casi in cui vi interessa veramente solo la dimensione e non la velocità di compressione.
Provalo
Zstandard è sia uno strumento a riga di comando (zstd)che una libreria. È scritto in C altamente portabile, il che lo rende adatto praticamente ad ogni piattaforma usata oggi – che si tratti dei server che gestiscono il tuo business, del tuo portatile o anche del telefono che hai in tasca. Puoi prenderlo dal nostro repository github, compilarlo con un semplice make install, e iniziare a usarlo come useresti gzip:
$ zstd access.logaccess.log : 8.07% (6695078 => 540336 bytes, access.log.zst)Come potresti aspettarti, puoi usarlo come parte di una pipeline di comandi, per esempio, per fare il backup del tuo database MySQL critico:
$ mysqldump --single-transaction --opt pokemon | zstd -q -o /srv/backups/mysqldump.sql.zstIl comando tar supporta diverse implementazioni di compressione out-of-box, quindi una volta installato Zstandard, puoi immediatamente lavorare con tarball compressi con Zstandard. Ecco un semplice esempio che lo mostra in uso con tar e la differenza di velocità rispetto a gzip:
$ time tar -I zstd -cf linux-4.6.4.tar.zst linux-4.6.4tar -I zstd -cf linux-4.6.4.tar.zst linux-4.6.4 3.15s user 0.50s system 107% cpu 3.396 total$ time tar -zcf linux-4.6.4.tar.gz linux-4.6.4tar -zcf linux-4.6.4.tar.gz linux-4.6.4 13.74s user 0.43s system 102% cpu 13.784 totalOltre all’uso della linea di comando, ci sono le API, documentate nei file header nel repository (inizia qui per una panoramica delle API). Includiamo anche un’API wrapper compatibile con zlib (libWrapper) per una più facile integrazione con strumenti che hanno già interfacce zlib. Infine, includiamo una serie di esempi, sia di uso base che di uso più avanzato come i dizionari e lo streaming, anch’essi nel repository GitHub.
Altro a venire
Mentre abbiamo raggiunto la 1.0 e consideriamo Zstandard pronto per ogni tipo di uso in produzione, non abbiamo finito. In arrivo nelle versioni future:
- Compressione multi-thread a riga di comando per un throughput ancora più veloce su grandi insiemi di dati, simile allo strumento pigz per zlib.
- Nuovi livelli di compressione, in entrambe le direzioni, che permettono una compressione ancora più veloce e rapporti più alti.
- Un insieme predefinito dalla comunità di dizionari di compressione per insiemi di dati comuni come JSON, HTML e protocolli di rete comuni.
Vorremmo ringraziare tutti i collaboratori, sia di codice che di feedback, che ci hanno aiutato ad arrivare alla 1.0. Questo è solo l’inizio. Sappiamo che affinché Zstandard sia all’altezza del suo potenziale, abbiamo bisogno del vostro aiuto. Come detto sopra, potete provare Zstandard oggi stesso prendendo il sorgente o i binari pre-costruiti dal nostro progetto GitHub, o, per gli utenti Mac, installandolo tramite homebrew (brew install zstd). Ci piacerebbe avere qualsiasi feedback e casi d’uso interessanti che avete, così come binding di linguaggio aggiuntivi e aiuto per integrarlo con i vostri progetti open source preferiti.
Note a piè di pagina
- Mentre la compressione dati senza perdita è l’obiettivo di questo post, esiste un campo correlato ma molto diverso della compressione dati con perdita, usato principalmente per immagini, audio e video.
- Deflate, zlib, gzip – tre nomi intrecciati. Deflate è l’algoritmo usato dalle implementazioni di zlib e gzip. Zlib è una libreria che fornisce Deflate, e gzip è uno strumento a riga di comando che usa zlib per deflazionare i dati e per il checksumming. Questo checksumming può avere un significativo overhead.
- Tutti i benchmark sono stati eseguiti su un Intel E5-2678 v3 che gira a 2,5 GHz su una macchina Centos 7. Gli strumenti a riga di comando (
zstdegzip) sono stati costruiti con il sistema GCC, 4.8.5. I benchmark degli algoritmi eseguiti da lzbench sono stati costruiti con GCC 6.
.
Lascia un commento