In questo post, daremo un’occhiata agli algoritmi di apprendimento automatico più usati. C’è un’enorme varietà di essi, ed è facile sentirsi confusi quando si sentono termini come “algoritmi di apprendimento basati su istanze” e “perceptron”.
Di solito, tutti gli algoritmi di apprendimento automatico sono divisi in gruppi in base al loro stile di apprendimento, alla loro funzione o ai problemi che risolvono. In questo post, troverete una classificazione basata sullo stile di apprendimento. Menzionerò anche i compiti comuni che questi algoritmi aiutano a risolvere.
Il numero di algoritmi di apprendimento automatico che sono utilizzati oggi è grande, e non ne menzionerò il 100%. Tuttavia, vorrei fornire una panoramica di quelli più comunemente usati.
- Algoritmi di apprendimento supervisionato
- Algoritmi di classificazione
- Naive Bayes
- Multinomial Naive Bayes
- Regressione logistica
- Alberi di decisione
- SVM (Support Vector Machine)
- Algoritmi di regressione
- Regressione lineare
- Algoritmi di apprendimento non supervisionati
- Clustering
- K-means clustering
- K-nearest neighbor
- Riduzione della dimensionalità
- Apprendimento delle regole di associazione
- Apprendimento per rinforzo
- Q-Learning
- Ensemble learning
- Bagging
- Boosting
- Foresta casuale
- Stacking
- Reti neurali
- Conclusione
Algoritmi di apprendimento supervisionato

Se non hai familiarità con termini come “apprendimento supervisionato” e “apprendimento non supervisionato”, controlla il nostro post AI vs. ML dove questo argomento è trattato in dettaglio. Ora, familiarizziamo con gli algoritmi.
Algoritmi di classificazione
Naive Bayes

Gli algoritmi bayesiani sono una famiglia di classificatori probabilistici usati nel ML basati sull’applicazione del teorema di Bayes.
Il classificatore di Bayes ingenuo è stato uno dei primi algoritmi utilizzati per l’apprendimento automatico. È adatto per la classificazione binaria e multiclasse e permette di fare previsioni e dati previsionali basati su risultati storici. Un esempio classico sono i sistemi di filtraggio dello spam che hanno usato Naive Bayes fino al 2010 e hanno mostrato risultati soddisfacenti. Tuttavia, quando l’avvelenamento bayesiano è stato inventato, i programmatori hanno iniziato a pensare ad altri modi per filtrare i dati.
Utilizzando il teorema di Bayes, è possibile dire come il verificarsi di un evento influenzi la probabilità di un altro evento.
Per esempio, questo algoritmo calcola la probabilità che una certa email sia o non sia spam in base alle parole tipiche utilizzate. Parole comuni di spam sono “offerta”, “ordina ora”, o “reddito aggiuntivo”. Se l’algoritmo rileva queste parole, c’è un’alta possibilità che l’email sia spam.
Naive Bayes assume che le caratteristiche siano indipendenti. Pertanto, l’algoritmo è chiamato ingenuo.
Multinomial Naive Bayes
A parte il classificatore Naive Bayes, ci sono altri algoritmi in questo gruppo. Per esempio, Multinomial Naive Bayes, che è solitamente applicato per la classificazione dei documenti basata sulla frequenza di certe parole presenti nel documento.
Gli algoritmi bayesiani sono ancora utilizzati per la categorizzazione del testo e il rilevamento delle frodi. Possono anche essere applicati per la visione artificiale (per esempio, il rilevamento dei volti), la segmentazione del mercato e la bioinformatica.
Regressione logistica
Anche se il nome potrebbe sembrare controintuitivo, la regressione logistica è in realtà un tipo di algoritmo di classificazione.
La regressione logistica è un modello che fa previsioni usando una funzione logistica per trovare la dipendenza tra le variabili di uscita e di ingresso. Statquest ha fatto un grande video dove spiega la differenza tra la regressione lineare e la regressione logistica prendendo come esempio i topi obesi.
Alberi di decisione
Un albero di decisione è un modo semplice per visualizzare un modello decisionale sotto forma di albero. I vantaggi degli alberi decisionali sono che sono facili da capire, interpretare e visualizzare. Inoltre, richiedono poco sforzo per la preparazione dei dati.
Tuttavia, hanno anche un grande svantaggio. Gli alberi possono essere instabili a causa anche delle più piccole variazioni (varianza) nei dati. È anche possibile creare alberi troppo complessi che non generalizzano bene. Questo è chiamato overfitting. Bagging, boosting e regolarizzazione aiutano a combattere questo problema. Ne parleremo più avanti nel post.
Gli elementi di ogni albero decisionale sono:
- Nodo radice che pone la domanda principale. Ha le frecce che puntano verso il basso da esso ma nessuna freccia che punta ad esso. Per esempio, immaginate di costruire un albero per decidere che tipo di pasta dovreste mangiare per cena.
- Rami. Una sottosezione di un albero è chiamata un ramo o talvolta un sottoalbero.
- Nodi di decisione. Questi sono i sotto-nodi per il nodo radice che possono anche essere suddivisi in più nodi. I nodi di decisione possono essere “carbonara?” o “con i funghi?”.
- Nodi terminali. Questi nodi non si dividono. Rappresentano decisioni finali o previsioni.
Anche, è importante menzionare la divisione. Questo è il processo di dividere un nodo in sotto-nodi. Per esempio, se non siete vegetariani, la carbonara va bene. Ma se lo sei, mangia la pasta con i funghi. C’è anche un processo di rimozione dei nodi chiamato pruning.
Gli algoritmi degli alberi decisionali sono chiamati CART (Classification and Regression Trees). Gli alberi di decisione possono lavorare con dati categorici o numerici.
- Gli alberi di regressione sono usati quando le variabili hanno valore numerico.
- Gli alberi di classificazione possono essere applicati quando i dati sono categorici (classi).
Gli alberi di decisione sono abbastanza intuitivi da capire e usare. Ecco perché i diagrammi ad albero sono comunemente applicati in una vasta gamma di industrie e discipline. GreyAtom fornisce un’ampia panoramica dei diversi tipi di alberi decisionali e delle loro applicazioni pratiche.
SVM (Support Vector Machine)
Le macchine vettoriali di supporto sono un altro gruppo di algoritmi usati per compiti di classificazione e, a volte, di regressione. SVM è ottimo perché dà risultati abbastanza accurati con una potenza di calcolo minima.
L’obiettivo di SVM è di trovare un iperpiano in uno spazio N-dimensionale (dove N corrisponde al numero di caratteristiche) che classifichi distintamente i punti dati. La precisione dei risultati è direttamente correlata all’iperpiano che scegliamo. Dovremmo trovare un piano che abbia la massima distanza tra i punti dati di entrambe le classi.
Questo iperpiano è rappresentato graficamente come una linea che separa una classe dall’altra. I punti dati che cadono su lati diversi dell’iperpiano sono attribuiti a classi diverse.
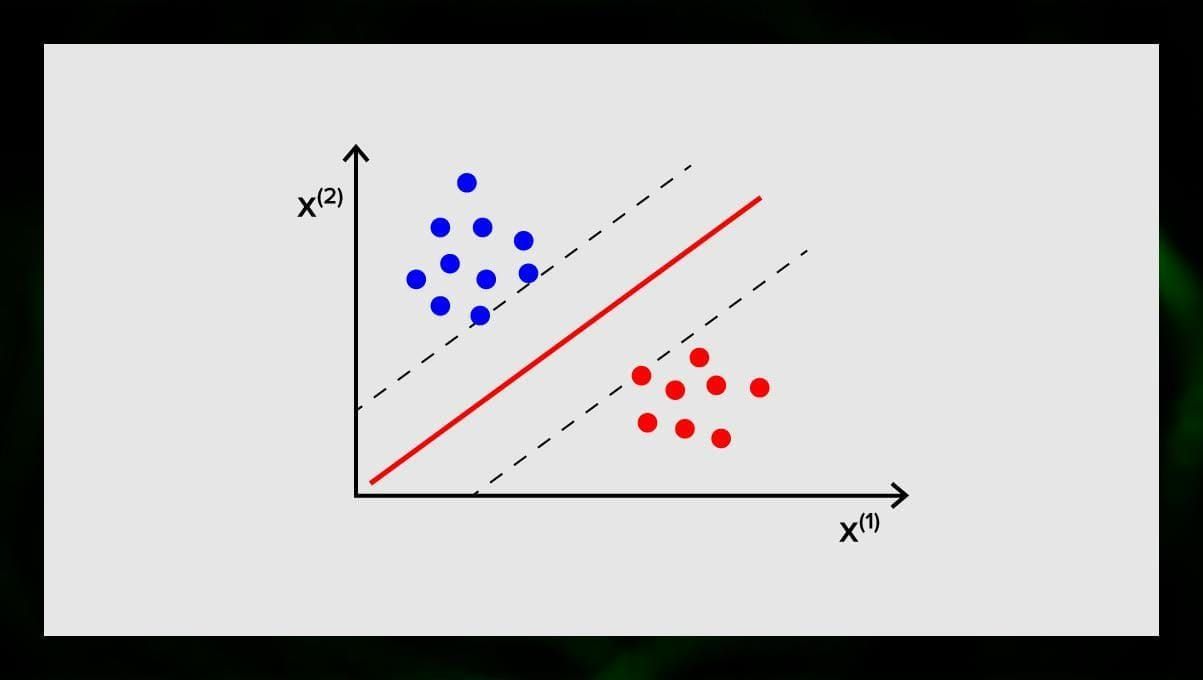
Nota che la dimensione dell’iperpiano dipende dal numero di caratteristiche. Se il numero di caratteristiche di input è 2, allora l’iperpiano è solo una linea. Se il numero di caratteristiche di input è 3, allora l’iperpiano diventa un piano bidimensionale. Diventa difficile disegnare su un grafico un modello quando il numero di caratteristiche supera 3. Quindi, in questo caso, userai i tipi di kernel per trasformarlo in uno spazio tridimensionale.
Perché si chiama Support Vector Machine? I vettori di supporto sono i punti di dati più vicini all’iperpiano. Essi influenzano direttamente la posizione e l’orientamento dell’iperpiano e ci permettono di massimizzare il margine del classificatore. Cancellare i vettori di supporto cambierà la posizione dell’iperpiano. Questi sono i punti che ci aiutano a costruire il nostro SVM.
SVM sono ora attivamente utilizzati nella diagnosi medica per trovare anomalie, nei sistemi di controllo della qualità dell’aria, per l’analisi finanziaria e le previsioni sul mercato azionario, e il controllo dei guasti delle macchine nell’industria.
Algoritmi di regressione
Gli algoritmi di regressione sono utili nell’analisi, per esempio, quando si cerca di prevedere i costi dei titoli o le vendite di un particolare prodotto in un determinato momento.
Regressione lineare
La regressione lineare cerca di modellare la relazione tra le variabili adattando un’equazione lineare ai dati osservati.
Ci sono variabili esplicative e variabili dipendenti. Le variabili dipendenti sono cose che vogliamo spiegare o prevedere. Quelle esplicative, come segue per il nome, spiegano qualcosa. Se volete costruire una regressione lineare, assumete che ci sia una relazione lineare tra le vostre variabili dipendenti e indipendenti. Per esempio, c’è una correlazione tra i metri quadrati di una casa e il suo prezzo o la densità della popolazione e i posti di kebab nella zona.
Una volta fatta questa assunzione, è necessario capire la relazione lineare specifica. Dovrete trovare un’equazione di regressione lineare per una serie di dati. L’ultimo passo è calcolare il residuo.
Nota: Quando la regressione disegna una linea retta, si chiama lineare, quando è una curva – polinomiale.
Algoritmi di apprendimento non supervisionati

Ora parliamo degli algoritmi che sono in grado di trovare modelli nascosti nei dati senza etichetta.
Clustering
Clustering significa che stiamo dividendo gli input in gruppi in base al grado di somiglianza tra loro. Il clustering è di solito uno dei passi per costruire un algoritmo più complesso. È più semplice studiare ogni gruppo separatamente e costruire un modello basato sulle loro caratteristiche, piuttosto che lavorare con tutto in una volta. La stessa tecnica è costantemente usata nel marketing e nelle vendite per dividere tutti i potenziali clienti in gruppi.
Algoritmi di clustering molto comuni sono il clustering k-means e il k-nearest neighbor.
K-means clustering
K-means clustering divide l’insieme degli elementi dello spazio vettoriale in un numero predefinito di cluster k. Un numero sbagliato di cluster invaliderà l’intero processo, quindi è importante provare con un numero variabile di cluster. L’idea principale dell’algoritmo k-means è che i dati vengono divisi casualmente in cluster, e dopo, il centro di ogni cluster ottenuto nel passo precedente viene iterativamente ricalcolato. Poi, i vettori sono divisi di nuovo in cluster. L’algoritmo si ferma quando ad un certo punto non ci sono cambiamenti nei cluster dopo un’iterazione.
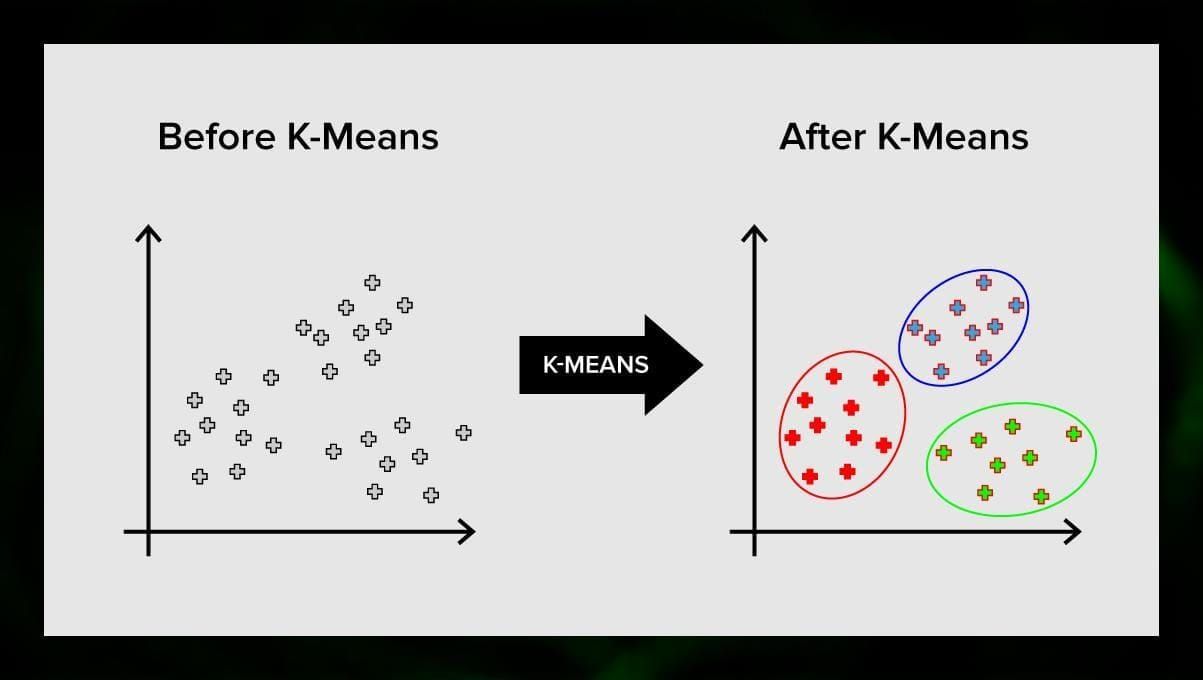
Questo metodo può essere applicato per risolvere problemi quando i cluster sono distinti o possono essere separati facilmente l’uno dall’altro, senza dati sovrapposti.
K-nearest neighbor
kNN sta per k-nearest neighbor. Si tratta di uno degli algoritmi di classificazione più semplici, talvolta utilizzato in compiti di regressione.
Per addestrare il classificatore, è necessario avere un insieme di dati con classi predefinite. La classificazione viene fatta manualmente coinvolgendo specialisti nell’area studiata. Utilizzando questo algoritmo, è possibile lavorare con più classi o chiarire le situazioni in cui gli input appartengono a più di una classe.
Il metodo si basa sul presupposto che etichette simili corrispondono a oggetti vicini nello spazio vettoriale degli attributi.
I moderni sistemi software utilizzano kNN per il riconoscimento visivo dei pattern, ad esempio, per scansionare e rilevare i pacchetti nascosti in fondo al carrello alla cassa (ad esempio, AmazonGo). Gli algoritmi kNN analizzano tutti i dati e individuano modelli insoliti che indicano attività sospette.
Riduzione della dimensionalità
L’analisi dei componenti principali (PCA) è una tecnica importante da comprendere per risolvere efficacemente i problemi legati al ML.
Immagina di avere molte variabili da considerare. Per esempio, avete bisogno di raggruppare le città in tre gruppi: buone per vivere, cattive per vivere e così così. Quante variabili dovete considerare? Probabilmente molte. Capite le relazioni tra di esse? Non proprio. Allora come puoi prendere tutte le variabili che hai raccolto e concentrarti solo su alcune di esse che sono le più importanti?
In termini tecnici, vuoi “ridurre la dimensione del tuo spazio delle caratteristiche”. Riducendo la dimensione del vostro spazio delle caratteristiche, riuscite ad avere meno relazioni tra le variabili da considerare e avete meno probabilità di sovradimensionare il vostro modello.
Ci sono molti modi per ottenere la riduzione della dimensionalità, ma la maggior parte di queste tecniche rientrano in una delle due classi:
- Eliminazione delle caratteristiche;
- Estrazione delle caratteristiche.
L’eliminazione delle caratteristiche significa che si riduce il numero delle caratteristiche eliminandone alcune. I vantaggi di questo metodo sono che è semplice e mantiene l’interpretabilità delle vostre variabili. Come svantaggio, però, si ottengono zero informazioni dalle variabili che si è deciso di eliminare.
L’estrazione delle caratteristiche evita questo problema. L’obiettivo quando si applica questo metodo è quello di estrarre un insieme di caratteristiche dal set di dati dato. L’estrazione delle caratteristiche mira a ridurre il numero di caratteristiche in un set di dati creando nuove caratteristiche basate su quelle esistenti (e quindi scartando le caratteristiche originali). Il nuovo set ridotto di caratteristiche deve essere creato in modo che sia in grado di riassumere la maggior parte delle informazioni contenute nel set originale di caratteristiche.
L’analisi delle componenti principali è un algoritmo per l’estrazione delle caratteristiche. combina le variabili di input in un modo specifico, e quindi è possibile eliminare le variabili “meno importanti” pur mantenendo le parti più preziose di tutte le variabili.
Uno dei possibili usi della PCA è quando le immagini nel dataset sono troppo grandi. Una rappresentazione ridotta delle caratteristiche aiuta ad affrontare rapidamente compiti come la corrispondenza e il recupero delle immagini.
Apprendimento delle regole di associazione
Apriori è uno degli algoritmi di ricerca delle regole di associazione più popolari. È in grado di elaborare grandi quantità di dati in un periodo di tempo relativamente piccolo.
Il fatto è che i database di molti progetti oggi sono molto grandi, raggiungendo gigabyte e terabyte. E continueranno a crescere. Pertanto, si ha bisogno di un algoritmo efficace e scalabile per trovare regole associative in un breve lasso di tempo. Apriori è uno di questi algoritmi.
Per poter applicare l’algoritmo, è necessario preparare i dati, convertendoli tutti in forma binaria e modificandone la struttura dei dati.
Di solito, si opera questo algoritmo su un database contenente un gran numero di transazioni, per esempio, su un database che contiene informazioni su tutti gli articoli che i clienti hanno acquistato in un supermercato.
Apprendimento per rinforzo

L’apprendimento per rinforzo è uno dei metodi di apprendimento automatico che aiuta a insegnare alla macchina come interagire con un certo ambiente. In questo caso, l’ambiente (per esempio, in un videogioco) funge da insegnante. Fornisce un feedback alle decisioni prese dal computer. Sulla base di questa ricompensa, la macchina impara a prendere la migliore linea d’azione. Ricorda il modo in cui i bambini imparano a non toccare una padella calda – attraverso la prova e la sensazione di dolore.
Scomponendo questo processo, comporta questi semplici passi:
- Il computer osserva l’ambiente;
- Sceglie una strategia;
- Agisce secondo questa strategia;
- Riceve una ricompensa o una penalità;
- Impara da questa esperienza e perfeziona la strategia;
- Ripete fino a trovare la strategia ottimale.
Q-Learning
Ci sono un paio di algoritmi che possono essere usati per il Reinforcement learning. Uno dei più comuni è il Q-learning.
Q-learning è un algoritmo di apprendimento di rinforzo senza modello. Il Q-learning si basa sulla remunerazione ricevuta dall’ambiente. L’agente forma una funzione di utilità Q, che successivamente gli dà la possibilità di scegliere una strategia di comportamento, e tiene conto dell’esperienza delle precedenti interazioni con l’ambiente.
Uno dei vantaggi del Q-learning è che è in grado di confrontare l’utilità attesa delle azioni disponibili senza formare modelli ambientali.
Ensemble learning

Ensemble learning è il metodo per risolvere un problema costruendo più modelli ML e combinandoli. L’apprendimento d’insieme è usato principalmente per migliorare le prestazioni dei modelli di classificazione, predizione e approssimazione delle funzioni. Altre applicazioni dell’apprendimento d’insieme includono il controllo della decisione presa dal modello, la selezione delle caratteristiche ottimali per la costruzione dei modelli, l’apprendimento incrementale e l’apprendimento non stazionario.
Di seguito sono riportati alcuni degli algoritmi di apprendimento d’insieme più comuni.
Bagging
Bagging sta per bootstrap aggregating. È uno dei primi algoritmi di ensemble, con una performance sorprendentemente buona. Per garantire la diversità dei classificatori, si usano repliche bootstrap dei dati di allenamento. Ciò significa che diversi sottoinsiemi di dati di formazione sono estratti casualmente – con sostituzione – dal set di dati di formazione. Ogni sottoinsieme di dati di allenamento viene usato per addestrare un diverso classificatore dello stesso tipo. Poi, i singoli classificatori possono essere combinati. Per fare questo, è necessario prendere un semplice voto di maggioranza delle loro decisioni. La classe che è stata assegnata dalla maggioranza dei classificatori è la decisione dell’ensemble.
Boosting
Questo gruppo di algoritmi di ensemble è simile al bagging. Anche il boosting usa una varietà di classificatori per ricampionare i dati, e poi sceglie la versione ottimale con il voto di maggioranza. Nel boosting, si addestrano iterativamente i classificatori deboli per assemblarli in un classificatore forte. Quando i classificatori vengono aggiunti, di solito vengono loro attribuiti dei pesi, che descrivono l’accuratezza delle loro previsioni. Dopo che un classificatore debole viene aggiunto all’insieme, i pesi vengono ricalcolati. Gli input classificati in modo errato guadagnano più peso, e le istanze classificate correttamente perdono peso. Così, il sistema si concentra maggiormente sugli esempi in cui è stata ottenuta una classificazione errata.
Foresta casuale
Le foreste casuali o foreste decisionali casuali sono un metodo di apprendimento in ensemble per la classificazione, la regressione e altri compiti. Per costruire una foresta casuale, è necessario addestrare una moltitudine di alberi decisionali su campioni casuali di dati di allenamento. L’output della foresta casuale è il risultato più frequente tra i singoli alberi. Le foreste decisionali casuali combattono con successo l’overfitting a causa della natura casuale dell’algoritmo.
Stacking
Stacking è una tecnica di apprendimento di ensemble che combina modelli multipli di classificazione o regressione attraverso un meta-classificatore o un meta-regressore. I modelli di livello base sono addestrati sulla base di un set di allenamento completo, poi il meta-modello è addestrato sulle uscite dei modelli di livello base come caratteristiche.
Reti neurali
Una rete neurale è una sequenza di neuroni collegati da sinapsi, che ricorda la struttura del cervello umano. Tuttavia, il cervello umano è ancora più complesso.
Il bello delle reti neurali è che possono essere utilizzate per qualsiasi compito, dal filtraggio dello spam alla visione artificiale. Tuttavia, sono normalmente applicate per la traduzione automatica, il rilevamento di anomalie e la gestione del rischio, il riconoscimento del parlato e la generazione di linguaggio, il riconoscimento dei volti e altro ancora.
Una rete neurale è composta da neuroni, o nodi. Ognuno di questi neuroni riceve dati, li elabora e poi li trasferisce ad un altro neurone.
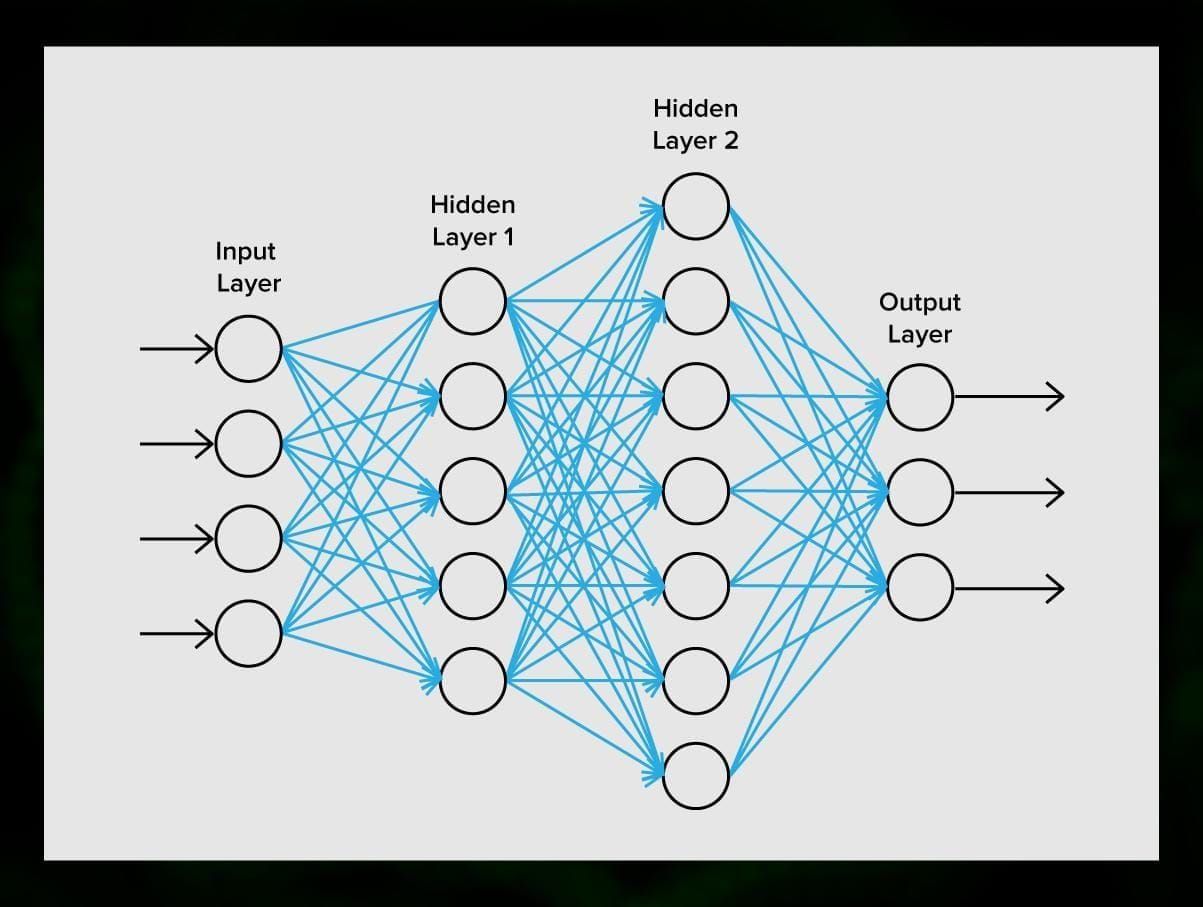
Ogni neurone elabora i segnali allo stesso modo. Ma come possiamo ottenere un risultato diverso? Le sinapsi che collegano i neuroni tra loro ne sono responsabili. Ogni neurone è in grado di avere molte sinapsi che attenuano o amplificano il segnale. Inoltre, i neuroni sono in grado di cambiare le loro caratteristiche nel tempo. Scegliendo i parametri corretti delle sinapsi, saremo in grado di ottenere i risultati corretti della conversione delle informazioni in ingresso all’uscita.
Ci sono molti tipi diversi di NN:
- Le reti neurali feedforward (FF o FFNN) e i perceptrons § sono molto semplici, non ci sono loop o cicli nella rete. In pratica, tali reti sono raramente utilizzate, ma sono spesso combinate con altri tipi per ottenerne di nuove.
- Una rete Hopfield (HN) è una rete neurale completamente connessa con una matrice simmetrica di collegamenti. Tale rete è spesso chiamata rete di memoria associativa. Proprio come una persona che vedendo una metà del tavolo, può immaginare la seconda metà, questa rete, ricevendo una tabella rumorosa, la ripristina al completo.
- Le reti neurali rivoluzionarie (CNN) e le reti neurali convoluzionali profonde (DCNN) sono molto diverse dagli altri tipi di reti. Di solito vengono utilizzate per l’elaborazione delle immagini, l’audio o i compiti legati ai video. Un modo tipico di applicare CNN è classificare le immagini.
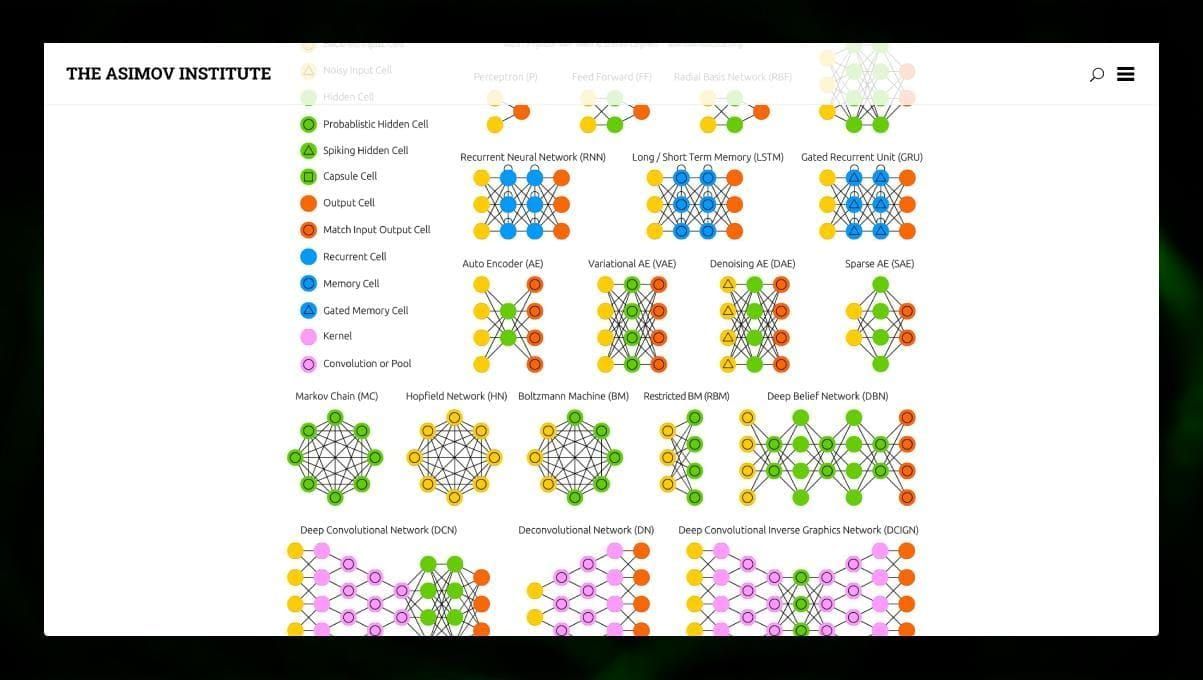
Molti tipi diversi di reti neurali sono interessanti da osservare. E’ possibile farlo nello zoo delle NN.
Conclusione
Questo post è un’ampia panoramica dei diversi algoritmi ML, ma c’è ancora molto da dire. Restate sintonizzati sui nostri Twitter, Facebook e Medium per altre guide e post sulle eccitanti possibilità del machine learning.
Lascia un commento