Az emberek gyorsabban hoznak létre, osztanak meg és tárolnak adatokat, mint bármikor máskor a történelem során. Amikor az adatok tárolásának és továbbításának innovációjáról van szó, a Facebooknál nemcsak a hardverek – például nagyobb merevlemezek és gyorsabb hálózati eszközök -, hanem a szoftverek terén is fejlesztéseket hajtunk végre. A szoftverek az adatfeldolgozást tömörítéssel segítik, amely az információt, például szöveget, képeket és a digitális adatok más formáit az eredetinél kevesebb bit felhasználásával kódolja. Ezek a kisebb fájlok kevesebb helyet foglalnak a merevlemezeken, és gyorsabban továbbíthatók más rendszerekbe. Az információk tömörítésének és dekompressziójának azonban van egy kompromisszuma: az idő. Minél több időt tölt a kisebb fájlba tömörítéssel, annál lassabb az adatok feldolgozása.
A mai uralkodó adattömörítési szabvány a Deflate, a Zip, a gzip és a zlib algoritmusok központi algoritmusa. Két évtizede lenyűgöző egyensúlyt biztosít a sebesség és a tárhely között, és ennek eredményeként szinte minden modern elektronikus eszközön ezt használják (és nem véletlenül éppen az Ön által olvasott blogbejegyzés minden egyes bájtjának továbbítására). Az évek során más algoritmusok vagy jobb tömörítést vagy gyorsabb tömörítést kínáltak, de ritkán mindkettőt. Úgy gondoljuk, hogy ezen változtattunk.
Örömmel jelentjük be a Zstandard 1.0-t, egy új tömörítési algoritmust és implementációt, amelyet úgy terveztünk, hogy a modern hardverekkel skálázható legyen, és kisebb és gyorsabb tömörítést tegyen lehetővé. A Zstandard ötvözi a legújabb tömörítési áttöréseket, mint például a véges állapotú entrópia, a teljesítményt előtérbe helyező tervezéssel – majd a modern CPU-k egyedi tulajdonságaihoz optimalizálja a megvalósítást. Ennek eredményeképpen javítja a más tömörítési algoritmusok által kötött kompromisszumokat, és széles körű alkalmazhatósággal rendelkezik, nagyon nagy dekompressziós sebességgel. A mostantól BSD licenc alatt elérhető Zstandardot úgy tervezték, hogy szinte minden veszteségmentes tömörítési forgatókönyvben használható legyen, köztük sok olyanban, ahol a jelenlegi algoritmusok nem alkalmazhatók.
- Tömörítés összehasonlítása
- Skálázhatóság
- A motorháztető alatt
- Memória
- Párhuzamos végrehajtásra tervezett formátum
- Branchless design
- Finite State Entropy: A következő generációs valószínűségi tömörítő
- Repkódmodellezés
- Zstandard a gyakorlatban
- Kis adatok
- Szótárak működésben
- Tömörítési szint kiválasztása
- Próbálja ki
- Még több lesz
Tömörítés összehasonlítása
A tömörítési algoritmusok és implementációk összehasonlítására három szabványos mérőszám létezik:
- Tömörítési arány: Az eredeti méret (számláló) a tömörített mérethez (nevező) képest, egységnyi adatban mérve 1,0 vagy annál nagyobb méretarány.
- Tömörítési sebesség: Milyen gyorsan tudjuk az adatot kisebbé tenni, a felhasznált bemeneti adat MB/s-ban mérve.
- Tömörítési sebesség: Milyen gyorsan tudjuk rekonstruálni az eredeti adatokat a tömörített adatokból, MB/s-ban mérve a tömörített adatokból előállított adatok sebességét.
A tömörítendő adatok típusa befolyásolhatja ezeket a metrikákat, ezért sok algoritmust bizonyos típusú adatokra hangolnak, például angol szövegre, genetikai szekvenciákra vagy raszterizált képekre. A Zstandard azonban, akárcsak a zlib, általános célú tömörítésre készült, különböző adattípusok számára. A Zstandardtól elvárt algoritmusok bemutatására ebben a bejegyzésben a Silesia korpuszt fogjuk használni, egy olyan fájlokból álló adathalmazt, amely a mindennap használt tipikus adattípusokat reprezentálja.
A manapság általánosan használt algoritmusok és implementációk közé tartozik a zlib, az lz4 és az xz. Mindegyik algoritmus különböző kompromisszumokat kínál: az lz4 a sebességre, az xz a nagyobb tömörítési arányra, a zlib pedig a sebesség és a méret jó egyensúlyára törekszik. Az alábbi táblázat az algoritmusok alapértelmezett tömörítési arányának és sebességének durva kompromisszumait mutatja a sziléziai korpusz esetében az algoritmusok lzbench-hez, egy tisztán memórián belüli benchmarkhoz viszonyítva, amely az algoritmusok nyers teljesítményének modellezésére szolgál.
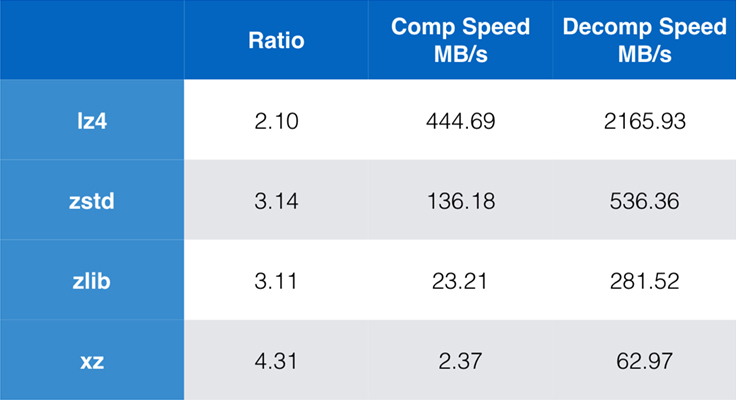
Amint vázoltuk, a sebesség és a méret között gyakran drasztikus kompromisszumok vannak. A leggyorsabb algoritmus, az lz4 alacsonyabb tömörítési arányt eredményez; az xz, amely a legmagasabb tömörítési aránnyal rendelkezik, lassú tömörítési sebességgel szenved. A Zstandard azonban az alapértelmezett beállítások mellett jelentős javulást mutat mind a tömörítési, mind a dekompressziós sebességben, miközben ugyanolyan arányban tömörít, mint a zlib.
Míg a tiszta algoritmus teljesítménye fontos, amikor a tömörítés egy nagyobb alkalmazásba van beágyazva, rendkívül gyakori, hogy parancssori eszközöket is használunk tömörítésre – mondjuk naplófájlok, tarballok vagy más hasonló, tárolásra vagy továbbításra szánt adatok tömörítésére. Ezekben az esetekben a teljesítményt gyakran befolyásolja a többletköltség, például az ellenőrző összegzés. Ez a diagram a gzip és a zstd parancssori eszközök összehasonlítását mutatja a rendszer alapértelmezett fordítójával épített Centos 7 rendszeren.
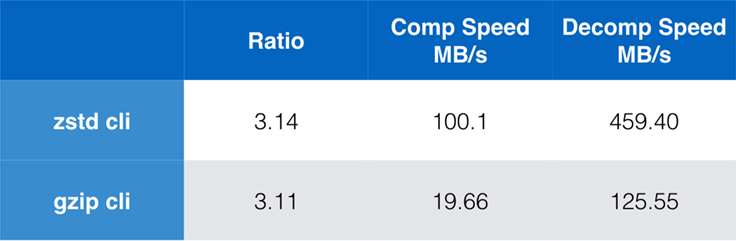
A teszteket egyenként tízszer végeztük el, a minimális időkkel, és ramdisken végeztük a fájlrendszeri túlterhelés elkerülése érdekében. Ezek voltak a parancsok (amelyek mindkét eszköz alapértelmezett tömörítési szintjét használják):
zstd -c -3 silesia.tar > silesia.tar.zst # 67,432,740 byteszstd -d -c silesia.tar.zst > /dev/nullgzip -c -6 silesia.tar > silesia.tar.gz # 68,235,522 bytesgzip -d -c silesia.tar.gz > /dev/nullSkálázhatóság
Ha egy algoritmus skálázható, akkor képes alkalmazkodni a legkülönbözőbb követelményekhez, és a Zstandardot úgy tervezték, hogy kitűnjön a mai környezetben és a jövőben is skálázható legyen. A legtöbb algoritmusnak vannak “szintjei”, amelyek az idő/tér kompromisszumokon alapulnak: Minél magasabb a szint, annál nagyobb az elért tömörítés a tömörítési sebesség csökkenése mellett. A Zlib kilenc tömörítési szintet kínál; a Zstandard jelenleg 22-t, ami rugalmas, szemcsés kompromisszumokat tesz lehetővé a tömörítési sebesség és a jövőbeli adatok arányai között. Például használhatjuk az 1-es szintet, ha a sebesség a legfontosabb, és a 22-es szintet, ha a méret a legfontosabb.
Az alábbiakban a Zstandard és a zlib összes szintjén elért tömörítési sebességet és arányt ábrázoljuk. Az x-tengely egy csökkenő logaritmikus skála megabájt/másodpercben; az y-tengely az elért tömörítési arány. Az algoritmusok összehasonlításához kiválaszthat egy sebességet, és láthatja az algoritmusok által az adott sebességnél elért különböző arányokat. Hasonlóképpen, kiválaszthat egy arányt, és láthatja, hogy az algoritmusok milyen gyorsak, amikor elérik ezt a szintet.
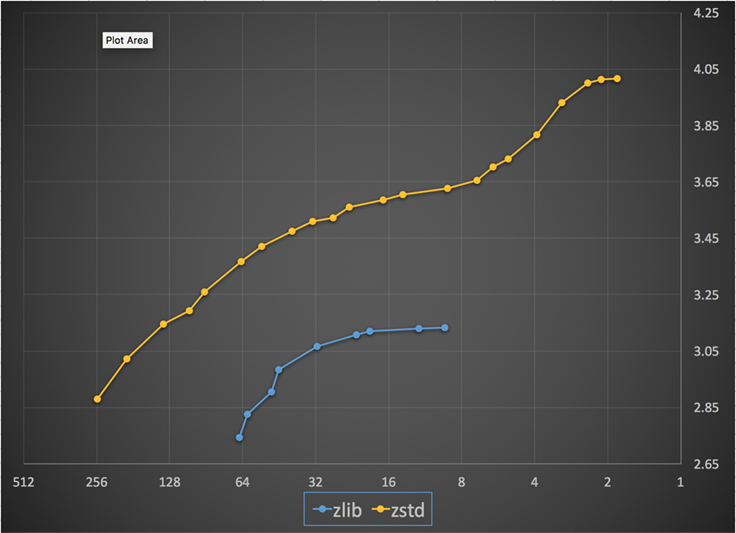
Minden függőleges vonal (azaz tömörítési sebesség) esetén a Zstandard nagyobb tömörítési arányt ér el. A sziléziai korpusz esetében a dekompressziós sebesség – az aránytól függetlenül – körülbelül 550 MB/s volt a Zstandard és 270 MB/s a zlib esetében. A diagram egy másik különbséget is mutat a Zstandard és az alternatívák között: Azáltal, hogy a Zstandard egyetlen algoritmust és megvalósítást használ, sokkal finomabb hangolást tesz lehetővé az egyes felhasználási esetekre. Ez azt jelenti, hogy a Zstandard képes felvenni a versenyt a leggyorsabb és legmagasabb tömörítési algoritmusokkal, miközben jelentős előnye van a dekompressziós sebességben. Ezek a fejlesztések közvetlenül gyorsabb adatátvitelre és kisebb tárolási igényre fordíthatók.
Más szóval, a zlib-hez képest a Zstandard skálázódik:
- Egyazon tömörítési arány mellett lényegesen gyorsabban tömörít: ~3-5x.
- Egyforma tömörítési sebesség mellett lényegesen kisebb: 10-15 százalékkal kisebb.
- A tömörítési aránytól függetlenül majdnem 2x gyorsabb a dekompresszióban; a parancssori eszköz számok még nagyobb különbséget mutatnak: több mint 3x gyorsabb.
- Sokkal nagyobb tömörítési arányokhoz skálázódik, miközben fenntartja a villámgyors dekompressziós sebességet.
A motorháztető alatt
A zstandard több újdonság kombinálásával és a modern hardverek megcélzásával javítja a zlib-et:
Memória
A zlib eleve 32 KB-os ablakra korlátozódik, ami a 90-es évek elején ésszerű választás volt. A mai számítástechnikai környezet azonban sokkal több memóriát képes elérni – még a mobil és beágyazott környezetekben is.
A zstandardnak nincs eredendő korlátja, és terabájtnyi memóriát is képes megszólítani (bár ezt ritkán teszi). A 22 szint közül az alsó például 1 MB-ot vagy annál kevesebbet használ. A fogadó rendszerek széles körével való kompatibilitás érdekében, ahol a memória korlátozott lehet, ajánlott a memóriahasználatot 8 MB-ra korlátozni. Ez azonban csak hangolási ajánlás, nem pedig a tömörítési formátum korlátozása.
Párhuzamos végrehajtásra tervezett formátum
A mai CPU-k nagyon erősek, és több utasítást képesek kiadni ciklusonként, köszönhetően a több ALU-nak (aritmetikai logikai egység) és az egyre fejlettebb, sorrenden kívüli végrehajtás kialakításának.
Ez lényegében azt jelenti, hogy ha:
a = b1 + b2
c = d1 + d2
akkor mind a a, mind a c számítás párhuzamosan történik.
Ez csak akkor lehetséges, ha nincs köztük kapcsolat. Ezért ebben a példában:
a = b1 + b2
c = d1 + a
c meg kell várni, hogy előbb a a számítása megtörténjen, és csak ezután kezdődik a c számítása.
Ez azt jelenti, hogy a modern CPU előnyeinek kihasználásához olyan műveletfolyamot kell tervezni, amelyben kevés vagy semmilyen adatfüggőség nincs.
Ez a Zstandarddal úgy érhető el, hogy az adatokat több párhuzamos folyamra osztjuk. Egy új generációs Huffman-dekóder, a Huff0, képes több szimbólum párhuzamos dekódolására egyetlen maggal. Ez a nyereség halmozódik a multi-threadinggel, amely több magot használ.
Branchless design
Az új CPU-k nagyobb teljesítményűek és nagyon magas frekvenciákat érnek el, de ez csak a többlépcsős megközelítésnek köszönhető, ahol egy utasítás több lépésből álló pipeline-ra van felosztva. A CPU minden egyes órajelciklusban több művelet eredményét képes kiadni, a rendelkezésre álló ALU-k függvényében. Minél több ALU-t használnak, annál több munkát végez a CPU, és ennélfogva annál gyorsabban történik a tömörítés. Az ALU-k munkával való ellátása kulcsfontosságú a modern CPU teljesítménye szempontjából.
Ez nehéznek bizonyul. Tekintsük a következő egyszerű helyzetet:
if (condition) doSomething() else doSomethingElse()Amikor ezzel találkozik, a CPU nem tudja, mit tegyen, mivel a condition értékétől függ. Egy óvatos CPU megvárná a condition eredményét, mielőtt bármelyik ágon dolgozna, ami rendkívül pazarló lenne.
A mai CPU-k hazardíroznak. Ezt intelligensen teszik, hála az elágazás-előrejelzőnek, amely lényegében megmondja nekik a condition kiértékelésének legvalószínűbb eredményét. Ha a fogadás helyes, a csővezeték tele marad, és az utasítások folyamatosan kerülnek kiadásra. Ha a fogadás rossz (téves előrejelzés), a CPU-nak le kell állítania minden spekulatívan megkezdett műveletet, vissza kell térnie az elágazáshoz, és a másik irányba kell haladnia. Ezt nevezzük pipeline flush-nek, és a modern CPU-kban rendkívül költséges.
Huszonöt évvel ezelőtt a pipeline flush nem volt probléma. Ma már annyira fontos, hogy elengedhetetlen az elágazás nélküli algoritmusokkal kompatibilis formátumok tervezése. Példaként nézzünk meg egy bitfolyam-frissítést:
/* classic version */while (nbBitsUsed >= 8) { /* each while test is a branch */ accumulator <<= 8; accumulator += *byte++; nbBitsUsed -= 8;} /*>/* branch-less version */nbBytesUsed = nbBitsUsed >> 3;nbBitsUsed &= 7;ptr += nbBytesUsed;accumulator = read64(ptr); Amint láthatjuk, az elágazás nélküli változatnak kiszámítható a munkaterhelése, minden feltétel nélkül. A CPU mindig ugyanazt a munkát végzi, és ez a munka soha nem vész el egy rossz előrejelzés miatt. Ezzel szemben a klasszikus változat kevesebb munkát végez, ha (nbBitsUsed < 8). De maga a teszt nem ingyenes, és valahányszor a tesztet rosszul találják ki, az egy teljes pipeline flush-t eredményez, ami többe kerül, mint az elágazás nélküli változat által végzett munka.
Amint sejthető, ez a mellékhatás hatással van az adatok csomagolására, olvasására és dekódolására. A Zstandard úgy lett létrehozva, hogy barátságos legyen az elágazásmentes algoritmusokkal, különösen a kritikus ciklusokon belül.
Finite State Entropy: A következő generációs valószínűségi tömörítő
A tömörítés során az adatokat először szimbólumok halmazává alakítjuk (a modellezési szakasz), majd ezeket a szimbólumokat minimális számú bit felhasználásával kódoljuk. Ezt a második szakaszt Claude Shannon emlékére entrópia-szakasznak nevezik, amely pontosan kiszámítja egy adott valószínűségű szimbólumhalmaz tömörítési határát (az úgynevezett “Shannon-határ”). A cél az, hogy a lehető legkevesebb CPU-erőforrás felhasználásával megközelítsük ezt a határt.
Egy nagyon elterjedt algoritmus a Huffman-kódolás, amelyet a Deflate-en belül használnak. Ez adja a lehető legjobb prefix kódot, feltételezve, hogy minden szimbólumot természetes számú bitekkel írunk le (1 bit, 2 bit …). Ez a gyakorlatban nagyszerűen működik, de a természetes számok korlátja miatt lehetetlen nagy tömörítési arányokat elérni, mert egy szimbólum szükségszerűen legalább 1 bitet fogyaszt.
Egy jobb módszer az úgynevezett aritmetikai kódolás, amely tetszőlegesen közelítheti a Shannon-határt -log2(P), tehát szimbólumonként tört biteket fogyaszt. Nagy valószínűségek esetén jobb tömörítési arányt eredményez, de több CPU-teljesítményt is fogyaszt. A gyakorlatban még az optimalizált aritmetikai kódolók is küzdenek a sebességért, különösen a dekompressziós oldalon, amely kiszámítható eredményű (pl. nem lebegőpontos) osztásokat igényel, és amely lassúnak bizonyul.
A véges állapotú entrópia Jarek Duda új elméletén, az ANS-en (Asymmetric Numeral System) alapul. A Finite State Entropy egy olyan változat, amely sok kódolási lépést előre kiszámít a táblázatokba, ami egy olyan pontos entrópia kódolót eredményez, mint az aritmetikai kódolás, csak összeadásokat, táblázatkeresést és eltolásokat használ, ami körülbelül ugyanolyan komplexitású, mint a Huffman. Emellett csökkenti a következő szimbólum elérésének késleltetését, mivel az azonnal elérhető az állapotértékből, míg a Huffman egy előzetes bitfolyam-dekódolási műveletet igényel. Működésének magyarázata nem tartozik ennek a bejegyzésnek a tárgykörébe, de ha érdekli, van egy cikksorozat, amely részletezi a belső működését.
Repkódmodellezés
A repkódmodellezés hatékonyan tömöríti a strukturált adatokat, amelyek közel azonos tartalmú, mindössze egy vagy néhány bájtnyi eltéréssel rendelkező sorozatokkal rendelkeznek. Ez a módszer nem új, de először a Deflate megjelenése után alkalmazták, így a zlib/gzip-ben nem létezik.
A repkódmodellezés hatékonysága nagymértékben függ a tömörítendő adatok típusától, a tömörítési javulás egy- és kétszámjegyű nagyságrendű lehet. Ezek a kombinált fejlesztések a Zstandard könyvtáron belül kínált jobb és gyorsabb tömörítési élményt eredményeznek.
Zstandard a gyakorlatban
Mint már említettük, a tömörítésnek számos tipikus felhasználási esete van. Ahhoz, hogy egy algoritmus meggyőző legyen, vagy rendkívül jónak kell lennie egy adott felhasználási esetben, például az ember által olvasható szöveg tömörítésében, vagy nagyon jónak kell lennie sokféle felhasználási esetben. A Zstandard az utóbbi megközelítést alkalmazza. A felhasználási esetek egyik módja az, hogy egy adott adatot hányszor lehet visszatömöríteni. A Zstandard minden ilyen esetben előnyökkel rendelkezik.
Sokszor. A sokszor feldolgozott adatok esetében előnyös a dekompressziós sebesség és az a képesség, hogy nagyon magas tömörítési arányt választhatunk a dekompressziós sebesség veszélyeztetése nélkül. A Facebook közösségi gráfjának tárolása például többször is beolvasásra kerül, ahogy Ön és barátai interakcióba lépnek az oldallal. A Facebookon kívül a szerverről letöltött fájlok, például a Linux kernel forráskódja vagy a szerverekre telepített RPM-ek, egy weboldal által használt JavaScript és CSS, vagy egy adattárházban lévő adatokon több ezer MapReduce futtatása is példák arra, amikor az adatokat sokszor kell dekompresszálni.
Csak egyszer. A csak egyszer tömörített adatok esetében, különösen a hálózaton keresztüli továbbításhoz, a tömörítés egy múló pillanat az adatáramlásban. A szerverre nehezedő kisebb többletköltség azt jelenti, hogy a szerver több kérést tud kezelni másodpercenként. A kliensen jelentkező kisebb többletköltség azt jelenti, hogy az adatokra gyorsabban lehet reagálni. Ez jellemzően olyan ügyfél-kiszolgáló helyzetekben merül fel, ahol az adatok az ügyfél számára egyediek, például egy webkiszolgáló egyedi válasza – mondjuk az adatok rendereléséhez használt adatok, amikor üzenetet kap egy barátjától a Messengeren. A végeredmény az, hogy a mobilkészülék gyorsabban tölti be az oldalakat, kevesebb akkumulátort használ, és kevesebbet fogyaszt az adatkeretből. A Zstandard különösen azért illik sokkal jobban a mobilos forgatókönyvekhez, mint más algoritmusok, mert így kezeli a kis adatokat.
Valószínűleg soha. Bár látszólag ellentmondásos, gyakran előfordul, hogy egy adat – például biztonsági mentések vagy naplófájlok – soha nem lesz dekompresszálva, de szükség esetén olvasható. Az ilyen típusú adatok esetében a tömörítésnek jellemzően gyorsnak kell lennie, kicsivé kell tennie az adatokat (a helyzetnek megfelelő idő/tér kompromisszummal), és esetleg ellenőrző összeget kell tárolnia, de egyébként láthatatlannak kell lennie. Abban a ritka esetben, amikor mégis dekompresszióra van szükség, nem szeretné, ha a tömörítés lassítaná az operatív felhasználási esetet. A gyors dekompresszió azért előnyös, mert gyakran az adatok egy kis része (például egy adott fájl a biztonsági mentésben vagy egy üzenet egy naplófájlban) az, amit gyorsan meg kell találni.
A Zstandard mindezen esetekben a gzip-nél sokszor gyorsabb tömörítést és dekompressziót tesz lehetővé, miközben az így kapott tömörített adatok kisebbek.
Kis adatok
A tömörítésnek van egy másik felhasználási esete is, amely kevesebb figyelmet kap, de nagyon fontos lehet: a kis adatok. Ezek olyan felhasználási esetek, ahol az adatok kis mennyiségben keletkeznek és fogynak, mint például a webkiszolgáló és a böngésző közötti JSON-üzenetek (jellemzően több száz bájt) vagy egy adatbázisban lévő oldalak adatai (néhány kilobájt).
Az adatbázisok érdekes felhasználási esetet biztosítanak. Az olyan rendszerek, mint a MySQL, a PostgreSQL és a MongoDB mind valós idejű hozzáférésre szánt adatokat tárolnak. A közelmúlt hardverelőnyei, különösen a flash (SSD) eszközök elterjedése körül, alapvetően megváltoztatták a méret és az áteresztőképesség közötti egyensúlyt – ma már olyan világban élünk, ahol az IOP (IO műveletek másodpercenként) meglehetősen magas, de a tárolóeszközeink kapacitása alacsonyabb, mint amikor a merevlemezek uralták az adatközpontokat.
A flashnek ráadásul van egy érdekes tulajdonsága az írásállóság tekintetében – az eszköz ugyanazon szakaszára történő több ezer írás után az a szakasz nem képes többé írást fogadni, ami gyakran az eszköz használaton kívül helyezéséhez vezet. Ezért természetes, hogy keressük a módját az írandó adatmennyiség csökkentésének, mert ez szerverenként több adatot jelenthet, és lassabban égeti ki az eszközt. Az adattömörítés erre egy stratégia, és az adatbázisokat is gyakran teljesítményre optimalizálják, vagyis az olvasási és írási teljesítmény egyaránt fontos.
Az adattömörítésnek az adatbázisoknál való alkalmazásánál azonban van egy bonyodalom. Az adatbázisok szeretnek véletlenszerűen hozzáférni az adatokhoz, míg a tömörítés legjellemzőbb felhasználási eseteiben a teljes fájlt lineáris sorrendben olvassák be. Ez azért probléma, mert az adattömörítés lényegében úgy működik, hogy a múlt alapján megjósolja a jövőt – az algoritmusok szekvenciálisan nézik az adatokat, és megjósolják, hogy mit láthatnak a jövőben. Minél pontosabbak a jóslatok, annál kisebbé tudja tenni az adatokat.
Ha kis méretű adatokat tömörítünk, például egy adatbázisban lévő oldalakat vagy a mobileszközre küldött apró JSON-dokumentumokat, egyszerűen nincs sok “múlt”, amelyet felhasználhatunk a jövő előrejelzéséhez. A tömörítő algoritmusok ezt úgy próbálták kezelni, hogy előre megosztott szótárakat használtak a hatékony ugrásszerű indításhoz. Ez úgy történik, hogy a tömörítés magjaként egy statikus “múltbeli” adathalmazt osztanak meg előzetesen.
A Zstandard erre a megközelítésre épül a szótártömörítés rendkívül optimalizált algoritmusaival és API-jaival. Ezen kívül a Zstandard tartalmaz olyan eszközöket (zstd --train), amelyekkel könnyedén készíthetünk szótárakat egyéni alkalmazásokhoz, valamint rendelkezéseket a szabványos szótárak regisztrálására a nagyobb közösségekkel való megosztás céljából. Bár a tömörítés az adatminták alapján változik, a kis adatok tömörítése 2x-5x jobb lehet, mint a szótárak nélküli tömörítés.
Szótárak működésben
Míg egy szótárral nehéz lehet játszani egy futó adatbázis kontextusában (elvégre jelentős módosításokat igényel az adatbázisban), a szótárak működésben más típusú kis adatokkal láthatók. A JSON, a kis adatok lingua francája a modern világban, általában kis, ismétlődő rekordok. Számtalan nyilvános adatkészlet áll rendelkezésre; a bemutatóhoz a GitHubról származó, HTTP-n keresztül elérhető “user” adatkészletet fogjuk használni. Íme egy minta bejegyzés ebből az adathalmazból:
{ "login": "octocat", "id": 1, "avatar_url": "https://github.com/images/error/octocat_happy.gif", "gravatar_id": "", "url": "https://api.github.com/users/octocat", "html_url": "https://github.com/octocat", "followers_url": "https://api.github.com/users/octocat/followers", "following_url": "https://api.github.com/users/octocat/following{/other_user}", "gists_url": "https://api.github.com/users/octocat/gists{/gist_id}", "starred_url": "https://api.github.com/users/octocat/starred{/owner}{/repo}", "subscriptions_url": "https://api.github.com/users/octocat/subscriptions", "organizations_url": "https://api.github.com/users/octocat/orgs", "repos_url": "https://api.github.com/users/octocat/repos", "events_url": "https://api.github.com/users/octocat/events{/privacy}", "received_events_url": "https://api.github.com/users/octocat/received_events", "type": "User", "site_admin": false } Amint látja, itt elég sok az ismétlődés – ezeket szépen tömöríthetjük! De minden egyes felhasználó egy kicsit kevesebb, mint 1 KB, és a legtöbb tömörítő algoritmusnak valóban több adatra van szüksége, hogy kinyújthassa a lábát. Egy 1000 felhasználóból álló készlet tömörítetlen tárolása nagyjából 850 KB-ot vesz igénybe. A gzip vagy zstd egyenkénti alkalmazása minden egyes fájlra naiv módon alig több mint 300 KB-ra csökkenti ezt a mennyiséget; nem rossz! De ha egyszeri, előre megosztott szótárat hozunk létre, a zstd segítségével a méret 122 KB-ra csökken – így az eredeti tömörítési arány 2,8x-ról 6,9-re nő. Ez egy jelentős javulás, ami a zstd-val out-of-box elérhető:
$ zstd --train -o ../json.zdict -r .sorting 982 files of total size 0 MB ...finding patterns ...statistics ...Save dictionary of size 65599 into file ../json.zdict$ du -h --apparent-size .846K .$ zstd --rm -D ../json.zdict -r .$ du -h --apparent-size .122K .Tömörítési szint kiválasztása
Amint fentebb látható, a Zstandard jelentős számú szintet biztosít. Ez a testreszabhatóság erőteljes, de nehéz döntésekhez vezet. A döntés legjobb módja az adatok áttekintése és a mérés, valamint annak eldöntése, hogy milyen kompromisszumokat szeretne kötni. A Facebooknál sok felhasználási esetre megfelelőnek találjuk az alapértelmezett 3. szintet, de időről időre ezt kissé módosítjuk attól függően, hogy mi a szűk keresztmetszetünk (gyakran megpróbáljuk telíteni a hálózati kapcsolatot vagy a lemezorsót); máskor viszont jobban érdekel minket a tárolt méret, és magasabb szintet használunk.
Az Ön igényeihez leginkább illeszkedő eredményekhez végső soron mind az Ön által használt hardvert, mind a fontos adatokat figyelembe kell vennie – nincsenek olyan kemény és gyors előírások, amelyeket kontextus nélkül meg lehet adni. Ha azonban kétségei vannak, maradjon az alapértelmezett 3-as szintnél, vagy maradjon a 6 és 9 közötti tartományban, ha a sebesség és a tárhely közötti jó kompromisszumot szeretné elérni; a 20+ szintet tartsa meg azokra az esetekre, amikor valóban csak a méret érdekli, és nem a tömörítési sebesség.
Próbálja ki
A Zstandard egy parancssori eszköz (zstd) és egy könyvtár is. Rendkívül hordozható C nyelven íródott, így gyakorlatilag minden manapság használt platformon használható – legyen szó a vállalkozásodat működtető szerverekről, a laptopodról vagy akár a zsebedben lévő telefonról. Előveheted a github tárolónkból, lefordíthatod egy egyszerű make install segítségével, és elkezdheted használni, ahogyan a gzip-t használnád:
$ zstd access.logaccess.log : 8.07% (6695078 => 540336 bytes, access.log.zst)Amint az várható volt, használhatod egy parancssorozat részeként, például a kritikus MySQL adatbázisod biztonsági mentéséhez:
$ mysqldump --single-transaction --opt pokemon | zstd -q -o /srv/backups/mysqldump.sql.zstA tar parancs támogatja a különböző tömörítési implementációkat out-of-box, így amint telepíted a Zstandardot, azonnal dolgozhatsz a Zstandarddal tömörített tarballal. Itt egy egyszerű példa, amely bemutatja a tar használatát és a sebességkülönbséget a gzip-hez képest:
$ time tar -I zstd -cf linux-4.6.4.tar.zst linux-4.6.4tar -I zstd -cf linux-4.6.4.tar.zst linux-4.6.4 3.15s user 0.50s system 107% cpu 3.396 total$ time tar -zcf linux-4.6.4.tar.gz linux-4.6.4tar -zcf linux-4.6.4.tar.gz linux-4.6.4 13.74s user 0.43s system 102% cpu 13.784 totalA parancssori használaton túl ott vannak az API-k, amelyek a tárolóban található fejlécfájlokban vannak dokumentálva (az API-k áttekintéséhez kezdd itt). Tartalmazunk egy zlib-kompatibilis wrapper API-t is (libWrapper) a könnyebb integráció érdekében olyan eszközökkel, amelyek már rendelkeznek zlib interfésszel. Végül számos példát is mellékelünk, mind az alapvető használatra, mind a fejlettebb használatra, mint például a szótárak és a streaming, szintén a GitHub-tárban.
Még több lesz
Bár elértük az 1.0-ás verziót, és a Zstandardot késznek tartjuk mindenféle termelési felhasználásra, még nem végeztünk. Jövőbeli verziókban érkezik:
- Multi-threaded parancssori tömörítés a még gyorsabb átviteli sebességért a nagy adathalmazokon, hasonlóan a pigz eszközhöz a zlib-hez.
- Új tömörítési szintek, mindkét irányban, ami még gyorsabb tömörítést és nagyobb arányokat tesz lehetővé.
- Egy közösség által karbantartott, előre definiált tömörítési szótárkészlet olyan gyakori adathalmazokhoz, mint a JSON, a HTML és a gyakori hálózati protokollok.
Mindenkinek szeretnénk köszönetet mondani, aki hozzájárult mind a kódhoz, mind a visszajelzésekhez, és segített minket az 1.0-hoz. Ez még csak a kezdet. Tudjuk, hogy ahhoz, hogy a Zstandard kiélhesse a benne rejlő lehetőségeket, szükségünk van a segítségére. Ahogy fentebb említettük, a Zstandardt még ma kipróbálhatod, ha letöltöd a GitHub projektünkből a forrást vagy az előre elkészített binárisokat, vagy Mac felhasználók számára a homebrew (brew install zstd) segítségével telepíted. Örülnénk minden visszajelzésnek és érdekes felhasználási esetnek, valamint további nyelvi kötéseknek és segítségnek a kedvenc nyílt forráskódú projektjeidbe való integrálásában.
Lábjegyzetek
- Míg e bejegyzés középpontjában a veszteségmentes adattömörítés áll, létezik egy kapcsolódó, de nagyon eltérő terület, a veszteséges adattömörítés, amelyet elsősorban képek, hang és videó esetén használnak.
- Deflate, zlib, gzip – három név összefonódott. A Deflate a zlib és gzip implementációk által használt algoritmus. A zlib egy Deflate-et biztosító könyvtár, a gzip pedig egy parancssori eszköz, amely a zlib-et használja az adatok deflatálására, valamint az ellenőrző összegzésre. Ez az ellenőrző összegzés jelentős többletköltséggel járhat.
- Minden benchmarkot egy 2,5 GHz-en futó Intel E5-2678 v3 processzoron végeztünk egy Centos 7-es gépen. A parancssori eszközök (
zstdésgzip) a 4.8.5-ös GCC rendszerrel készültek. Az lzbench által végzett algoritmus benchmarkok a GCC 6.
programmal készültek.
Vélemény, hozzászólás?