A Java-alkalmazásod átláthatósága elengedhetetlen ahhoz, hogy megértsd, hogyan működik most, hogyan működött valamikor a múltban, és hogy jobban megértsd, hogyan fog működni a jövőben. Leggyakrabban a naplók elemzése a leggyorsabb módja annak, hogy felderítsük, mi romlott el, így a naplózás Java-ban kritikus fontosságú az alkalmazás teljesítményének és egészségének biztosítása, valamint az esetleges leállások minimalizálása és csökkentése szempontjából. Egy központosított naplózási és felügyeleti megoldás segít csökkenteni a javításra fordított átlagos időt az Ops vagy DevOps csapat hatékonyságának javításával.
A jó gyakorlatok követésével több értéket nyerhet a naplófájlokból, és könnyebben használhatja azokat. Könnyebben meg tudja majd határozni a hibák és a gyenge teljesítmény gyökerét, és könnyebben megoldja a problémákat, mielőtt azok hatással lennének a végfelhasználókra. Ezért ma hadd osszunk meg néhányat a legjobb gyakorlatok közül, amelyekre érdemes esküdnie, amikor Java-alkalmazásokkal dolgozik. Vágjunk bele.
- Szokásos naplózási könyvtár használata
- Bölcsen válassza ki az appendereit
- Használjon értelmes üzeneteket
- Java Stack Traces naplózása
- Java kivételek naplózása
- A megfelelő naplózási szint használata
- Log in JSON
- Keep the Log Structure Consistent
- Adjunk kontextust a naplókhoz
- Java naplózás konténerekben
- Ne naplózz túl sokat vagy túl keveset
- Figyeljen a közönségre
- Kerüljük az érzékeny információk naplózását
- Használjon naplókezelő megoldást a & Java naplók központi felügyeletére
- Következtetés
- Share
Szokásos naplózási könyvtár használata
A naplózás Java-ban többféleképpen is elvégezhető. Használhatunk egy dedikált naplózási könyvtárat, egy közös API-t, vagy akár csak naplókat írhatunk fájlba vagy közvetlenül egy dedikált naplózási rendszerbe. A naplózási könyvtár kiválasztásakor azonban gondolkodjunk előre. A mérlegelendő és értékelendő dolgok a teljesítmény, a rugalmasság, az új naplóközpontosítási megoldásokhoz szükséges appendumok és így tovább. Ha közvetlenül egy keretrendszerhez köti magát, az újabb könyvtárra való váltás jelentős mennyiségű munkát és időt vehet igénybe. Tartsa ezt szem előtt, és válassza azt az API-t, amely rugalmasságot biztosít ahhoz, hogy a jövőben naplókönyvtárakat váltson. Akárcsak a Log4j-ről Logbackre és Log4j 2-re való váltásnál, az SLF4J API használatakor is csak a függőséget kell megváltoztatni, a kódot nem.
Ha még nem ismeri a Java naplózási könyvtárakat, olvassa el kezdőknek szóló útmutatónkat:
- Log4j Tutorial
- Logback Tutorial
- Log4j2 Tutorial
- SLF4J Tutorial
Bölcsen válassza ki az appendereit
Az appenderek határozzák meg, hogy a napló eseményei hova kerülnek. A leggyakoribb appenderek a konzol és a fájl appenderek. Bár hasznosak és széles körben ismertek, előfordulhat, hogy nem felelnek meg az Ön igényeinek. Előfordulhat például, hogy a naplóit aszinkron módon szeretné írni, vagy a Sysloghoz hasonló appenderek segítségével szeretné a hálózaton keresztül szállítani a naplóit, például így:
<Appenders> <Console name="Console" target="SYSTEM_OUT"> <PatternLayout pattern="%d %level %c - %m%n"/> </Console> <Syslog name="Syslog" host="logsene-syslog-receiver.sematext.com" port="514" protocol="TCP" format="RFC5424" appName="11111111-2222-3333-4444-555555555555" facility="LOCAL0" mdcId="mdc" newLine="true"/></Appenders>
Ne feledje azonban, hogy a fentihez hasonló appenderek használata érzékennyé teszi a naplózási csővezetéket a hálózati hibákra és kommunikációs zavarokra. Ez azt eredményezheti, hogy a naplók nem jutnak el a rendeltetési helyükre, ami nem feltétlenül elfogadható. Azt is el akarja kerülni, hogy a naplózás befolyásolja a rendszerét, ha az appendert blokkoló módon tervezték. Ha többet szeretne megtudni, olvassa el a Naplókönyvtárak vs. naplószállítók blogbejegyzésünket.
Használjon értelmes üzeneteket
A naplók létrehozásakor az egyik legfontosabb dolog, ugyanakkor az egyik nem is olyan egyszerű dolog az értelmes üzenetek használata. A naplóeseményeknek olyan üzeneteket kell tartalmazniuk, amelyek egyediek az adott helyzetben, egyértelműen leírják azokat, és tájékoztatják az azokat olvasó személyt. Képzelje el, hogy kommunikációs hiba történt az alkalmazásában. Ezt így is megtehetnéd:
LOGGER.warn("Communication error");
De létrehozhatnál egy ilyen üzenetet is:
LOGGER.warn("Error while sending documents to events Elasticsearch server, response code %d, response message %s. The message sending will be retried.", responseCode, responseMessage);
Egyszerűen láthatod, hogy az első üzenet tájékoztatja a naplót nézegető személyt valamilyen kommunikációs problémáról. Ez a személy valószínűleg megkapja a kontextust, a naplózó nevét és a sorszámot, ahol a figyelmeztetés történt, de ez minden. Ahhoz, hogy több kontextust kapjon, meg kell néznie a kódot, tudnia kell, hogy a hiba a kód melyik verziójához kapcsolódik, és így tovább. Ez nem szórakoztató és gyakran nem könnyű, és biztosan nem olyasvalami, amit az ember a lehető leggyorsabban szeretne csinálni, miközben egy termelési hiba elhárításával próbálkozik.
A második üzenet jobb. Pontos információt ad arról, hogy milyen kommunikációs hiba történt, mit csinált az alkalmazás abban az időben, milyen hibakódot kapott, és mi volt a távoli kiszolgáló válasza. Végül arról is tájékoztat, hogy az üzenet elküldését újra meg kell próbálni. Az ilyen üzenetekkel való munka határozottan könnyebb és kellemesebb.
Végül gondoljunk az üzenet méretére és szóbeliségére. Ne naplózzon túlságosan terjedelmes információkat. Ezeket az adatokat valahol tárolni kell ahhoz, hogy hasznosak legyenek. Egyetlen nagyon hosszú üzenet nem jelent problémát, de ha ez a sor egy perc alatt több százszor ismétlődik, és rengeteg szószátyár naplófájlunk van, az ilyen adatok hosszabb megőrzése problémás lehet, és végső soron többe is kerül.
Java Stack Traces naplózása
A Java naplózás egyik nagyon fontos része a Java stack traces. Nézzük meg a következő kódot:
package com.sematext.blog.logging;import org.apache.logging.log4j.LogManager;import org.apache.logging.log4j.Logger;import java.io.IOException;public class Log4JExceptionNoThrowable { private static final Logger LOGGER = LogManager.getLogger(Log4JExceptionNoThrowable.class); public static void main(String args) { try { throw new IOException("This is an I/O error"); } catch (IOException ioe) { LOGGER.error("Error while executing main thread"); } }}
A fenti kód hatására egy kivételt dobunk, és az alapértelmezett konfigurációnkkal a konzolra kiírt naplóüzenet a következőképpen néz ki:
11:42:18.952 ERROR - Error while executing main thread
Amint láthatjuk, nem sok információ van benne. Csak azt tudjuk, hogy a probléma bekövetkezett, de nem tudjuk, hogy hol történt, vagy mi volt a probléma, stb. Nem túl informatív.
Most nézzük meg ugyanazt a kódot egy kissé módosított naplózási utasítással:
package com.sematext.blog.logging;import org.apache.logging.log4j.LogManager;import org.apache.logging.log4j.Logger;import java.io.IOException;public class Log4JException { private static final Logger LOGGER = LogManager.getLogger(Log4JException.class); public static void main(String args) { try { throw new IOException("This is an I/O error"); } catch (IOException ioe) { LOGGER.error("Error while executing main thread", ioe); } }}
Mint láthatod, ezúttal magát a kivételobjektumot is belevettük a naplóüzenetbe:
LOGGER.error("Error while executing main thread", ioe);
Ez a következő hibanaplót eredményezné a konzolon az alapértelmezett konfigurációnkkal:
11:30:17.527 ERROR - Error while executing main threadjava.io.IOException: This is an I/O error at com.sematext.blog.logging.Log4JException.main(Log4JException.java:13)
Ez tartalmazza a lényeges információkat – i.azaz az osztály nevét, a metódust, ahol a probléma előfordult, és végül a sorszámot, ahol a probléma történt. Természetesen a valós életben a stack traces hosszabbak lesznek, de érdemes őket is felvenni, hogy elegendő információt adjanak a megfelelő hibakereséshez.
Ha többet szeretne megtudni arról, hogyan kezelje a Java stack traces-t a Logstash-szel, lásd: Handling Multiline Stack Traces with Logstash, vagy nézze meg a Logagent-et, amely ezt már alapból képes elvégezni Ön helyett.
Java kivételek naplózása
A Java kivételek és stack traces kezelésénél nem csak a teljes stack trace-re kell gondolni, hanem azokra a sorokra, ahol a probléma megjelent, és így tovább. Arra is gondolnia kell, hogyan ne foglalkozzon a kivételekkel.
Kerülje el a kivételek csendes figyelmen kívül hagyását. Nem akarsz figyelmen kívül hagyni valami fontosat. Például ne tegye ezt:
try { throw new IOException("This is an I/O error");} catch (IOException ioe) {}
Egy kivételt ne csak naplózzon, és ne dobja tovább. Ez azt jelenti, hogy csak feljebb toltad a problémát a végrehajtási veremben. Kerüld az ehhez hasonló dolgokat is:
try { throw new IOException("This is an I/O error");} catch (IOException ioe) { LOGGER.error("I/O error occurred during request processing", ioe); throw ioe;}
Ha többet szeretnél megtudni a kivételekről, olvasd el a Java kivételek kezeléséről szóló útmutatónkat, amelyben mindent tárgyalunk a kivételek mibenlététől kezdve azon át, hogy hogyan lehet elkapni és kijavítani őket.
A megfelelő naplózási szint használata
Az alkalmazáskódod írásakor gondold át kétszer is az adott naplóüzenetet. Nem minden információ egyformán fontos, és nem minden váratlan helyzet hiba vagy kritikus üzenet. Emellett következetesen használja a naplózási szinteket – a hasonló típusú információknak hasonló súlyossági szinten kell lenniük.
A SLF4J facade és minden egyes Java naplózási keretrendszer, amelyet használni fog, olyan módszereket biztosít, amelyekkel megadhatja a megfelelő naplózási szintet. Például:
LOGGER.error("I/O error occurred during request processing", ioe);
Log in JSON
Ha azt tervezzük, hogy naplózzuk és manuálisan megnézzük az adatokat egy fájlban vagy a standard kimeneten, akkor a tervezett naplózás több mint jó lesz. Ez sokkal felhasználóbarátabb – már megszoktuk. De ez csak nagyon kis alkalmazásoknál életképes, és még akkor is javasolt valami olyat használni, ami lehetővé teszi a metrikai adatok korrelálását a naplókkal. Az ilyen műveletek elvégzése egy terminálablakban nem szórakoztató, és néha egyszerűen nem lehetséges. Ha a naplókat a naplókezelő és központosító rendszerben szeretné tárolni, akkor JSON-ban kell naplózni. Ez azért van, mert a tagolás nem jár ingyen – ez általában a reguláris kifejezések használatát jelenti. Természetesen ezt az árat a naplószállítóban is kifizetheted, de miért tennéd, ha egyszerűen naplózhatsz JSON-ban is. A JSON-ban történő naplózás a stack traces egyszerű kezelését is jelenti, tehát még egy előny. Nos, egyszerűen naplózhatsz egy Syslog kompatibilis célállomásra is, de ez már egy másik történet.
A legtöbb esetben a JSON-ban történő naplózás engedélyezéséhez a Java naplózási keretrendszeredben elég a megfelelő konfigurációt felvenni. Tegyük fel például, hogy a következő naplóüzenet szerepel a kódunkban:
LOGGER.info("This is a log message that will be logged in JSON!");
A Log4J 2 konfigurálásához, hogy a naplóüzeneteket JSON-ban írja, a következő konfigurációt kell felvennünk:
<?xml version="1.0" encoding="UTF-8"?><Configuration status="WARN"> <Appenders> <Console name="Console" target="SYSTEM_OUT"> <JSONLayout compact="true" eventEol="true"> </JSONLayout> </Console> </Appenders> <Loggers> <Root level="info"> <AppenderRef ref="Console"/> </Root> </Loggers></Configuration>
Az eredmény így nézne ki:
{"instant":{"epochSecond":1596030628,"nanoOfSecond":695758000},"thread":"main","level":"INFO","loggerName":"com.sematext.blog.logging.Log4J2JSON","message":"This is a log message that will be logged in JSON!","endOfBatch":false,"loggerFqcn":"org.apache.logging.slf4j.Log4jLogger","threadId":1,"threadPriority":5}
Keep the Log Structure Consistent
A napló eseményeinek szerkezetének konzisztensnek kell lennie. Ez nem csak egyetlen alkalmazáson vagy mikroszolgáltatások halmazán belül igaz, hanem az egész alkalmazáshalmazon belül alkalmazni kell. Hasonlóan strukturált naplóeseményekkel könnyebb lesz megvizsgálni, összehasonlítani, korrelálni vagy egyszerűen csak egy dedikált adattárolóban tárolni őket. Könnyebb belenézni a rendszereiből érkező adatokba, ha tudja, hogy olyan közös mezőkkel rendelkeznek, mint a súlyosság és a hostnév, így könnyen felszeletelheti és feldarabolhatja az adatokat ezen információk alapján. Inspirációként tekintse meg a Sematext Common Schema-t még akkor is, ha nem Sematext-felhasználó.
A struktúra megtartása természetesen nem mindig lehetséges, mivel a teljes verem külső fejlesztésű szerverekből, adatbázisokból, keresőmotorokból, várólistákból stb. áll, amelyek mindegyike saját naplókkal és naplóformátumokkal rendelkezik. Azonban a saját és a csapata épelméjűségének megőrzése érdekében minimalizálja a különböző naplóüzenet-struktúrák számát, amelyeket ellenőrizhet.
A közös struktúra megtartásának egyik módja, hogy ugyanazt a mintát használja a naplói számára, legalábbis azok számára, amelyek ugyanazt a naplózási keretrendszert használják. Ha például az alkalmazásai és mikroszolgáltatásai a Log4J 2-t használják, használhat egy ilyen mintát:
<PatternLayout> <Pattern>%d %p %c{35}:%L - %m%n</Pattern></PatternLayout>
Egyetlen vagy nagyon korlátozott számú minta használatával biztos lehet benne, hogy a naplóformátumok száma kicsi és kezelhető marad.
Adjunk kontextust a naplókhoz
Az információs kontextus fontos, és számunkra, fejlesztők és DevOps-ok számára a naplóüzenet információ. Nézzük meg a következő naplóbejegyzést:
An error occurred!
Tudjuk, hogy egy hiba jelent meg valahol az alkalmazásban. Nem tudjuk, hogy hol történt, nem tudjuk, hogy milyen hiba volt, csak azt tudjuk, hogy mikor történt. Most nézzünk meg egy üzenetet, amely valamivel több kontextuális információval rendelkezik:
com.sematext.blog.logging.ParsingErrorExample - A parsing error occurred for user with id 1234!
Ez ugyanaz a naplóbejegyzés, de sokkal több kontextuális információval. Tudjuk, hogy melyik szálon történt, tudjuk, hogy milyen osztályon generálódott a hiba. Módosítottuk az üzenetet is, hogy tartalmazza a felhasználót, akinél a hiba történt, így szükség esetén visszatérhetünk a felhasználóhoz. További információkat is megadhatunk, például diagnosztikai kontextusokat. Gondolja át, mire van szüksége, és vegye fel.
A kontextusinformációk felvételéhez nem kell sokat tennie, ha a naplóüzenet generálásáért felelős kódról van szó. A Log4J 2-ben található PatternLayout például mindent megad, amire a kontextusinformációk felvételéhez szüksége van. Használhat egy ilyen nagyon egyszerű mintát:
<PatternLayout pattern="%d{HH:mm:ss.SSS} %-5level - %msg%n"/>
Ez a következőhöz hasonló naplóüzenetet eredményez:
17:13:08.059 INFO - This is the first INFO level log message!
De olyan mintát is felvehet, amely sokkal több információt tartalmaz:
<PatternLayout pattern="%d{HH:mm:ss.SSS} %c %l %-5level - %msg%n"/>
Ez egy ehhez hasonló naplóüzenetet eredményez:
17:24:01.710 com.sematext.blog.logging.Log4j2 com.sematext.blog.logging.Log4j2.main(Log4j2.java:12) INFO - This is the first INFO level log message!
Java naplózás konténerekben
Gondolj arra, hogy milyen környezetben fog futni az alkalmazásod. Más a naplózási konfiguráció, ha a Java kódodat VM-ben vagy csupasz metál gépen futtatod, más, ha konténeres környezetben futtatod, és természetesen más, ha Java vagy Kotlin kódodat Android eszközön futtatod.
A naplózás beállításához konténeres környezetben ki kell választanod a kívánt megközelítést. Használhatja a biztosított naplózási vezérlők egyikét – mint például a journald, logagent, Syslog vagy JSON fájl. Ehhez ne feledd, hogy az alkalmazásodnak nem a konténer efemer tárolójába kell írnia a naplófájlt, hanem a szabványos kimenetre. Ezt könnyen megteheted a naplózási keretrendszered konfigurálásával, hogy a naplót a konzolra írja. A Log4J 2 esetében például csak a következő appenderkonfigurációt kell használnod:
<Appenders> <Console name="Console" target="SYSTEM_OUT"> <PatternLayout pattern="%d{HH:mm:ss.SSS} - %m %n"/> </Console></Appenders>
A naplózási vezérlőket teljesen elhagyhatod, és a naplókat közvetlenül a központi naplózási megoldásodba, például a Sematext felhőnkbe küldheted:
<Appenders> <Console name="Console" target="SYSTEM_OUT"> <PatternLayout pattern="%d %level %c - %m%n"/> </Console> <Syslog name="Syslog" host="logsene-syslog-receiver.sematext.com" port="514" protocol="TCP" format="RFC5424" appName="11111111-2222-3333-4444-555555555555" facility="LOCAL0" mdcId="mdc" newLine="true"/></Appenders>
Ne naplózz túl sokat vagy túl keveset
Fejlesztőként hajlamosak vagyunk azt gondolni, hogy minden fontos lehet – hajlamosak vagyunk algoritmusunk vagy üzleti kódunk minden lépését fontosnak jelölni. Másrészt néha ennek az ellenkezőjét tesszük – nem adunk hozzá naplózást ott, ahol kellene, vagy csak a FATAL és ERROR naplózási szinteket naplózzuk. Mindkét megközelítés nem fog túl jól működni. Amikor megírjuk a kódunkat és naplózást adunk hozzá, gondoljuk át, mi lesz fontos ahhoz, hogy lássuk, hogy az alkalmazás megfelelően működik-e, és mi lesz fontos ahhoz, hogy diagnosztizálni tudjuk az alkalmazás hibás állapotát és kijavítsuk azt. Ezt használd vezérfonalként annak eldöntéséhez, hogy mit és hol kell naplózni. Tartsa szem előtt, hogy a túl sok napló hozzáadása információs fáradtsághoz vezet, az elégtelen információ pedig a hibaelhárítás képtelenségét eredményezi.
Figyeljen a közönségre
A legtöbb esetben nem ön lesz az egyetlen személy, aki a naplókat nézi. Mindig tartsd észben, hogy. Több szereplő is nézheti a naplókat.
A fejlesztő nézheti a naplókat hibaelhárítás vagy hibakeresés közben. Az ilyen emberek számára a naplók részletesek, technikai jellegűek lehetnek, és nagyon mély információkat tartalmazhatnak a rendszer működésével kapcsolatban. Az ilyen személynek hozzáférése lesz a kódhoz is, vagy akár ismeri is a kódot, és ezt feltételezhetjük.
Aztán ott van a DevOps. Számukra a naplóeseményekre a hibaelhárításhoz lesz szükség, és a diagnosztikában hasznos információkat kell tartalmazniuk. Feltételezheti a rendszer, az architektúra, a komponensek és a komponensek konfigurációjának ismeretét, de a platform kódjának ismeretét nem szabad feltételeznie.
Végezetül, az alkalmazásnaplókat maguk a felhasználók is olvashatják. Ilyen esetben a naplóknak eléggé leírónak kell lenniük ahhoz, hogy segítsenek a probléma megoldásában, ha ez egyáltalán lehetséges, vagy elegendő információt adjanak a felhasználót segítő támogató csapat számára. A Sematext monitorozásra való használata például egy monitorozó ügynök telepítésével és futtatásával jár. Ha egy nagyon korlátozó tűzfal mögött van, és az ügynök nem tud metrikákat küldeni a Sematextnek, akkor célzottan naplózza a hibákat, amelyeket maguk a Sematext-felhasználók is megnézhetnek.
Mehetnénk tovább, és még több szereplőt azonosíthatnánk, akik belenézhetnek a naplókba, de ez a rövid lista bepillantást enged abba, hogy mire érdemes gondolni a naplóüzenetek írásakor.
Kerüljük az érzékeny információk naplózását
Az érzékeny információknak nem szabad jelen lenniük a naplókban, vagy azokat el kell takarni. Jelszavak, hitelkártyaszámok, társadalombiztosítási számok, hozzáférési tokenek és így tovább – mindezek veszélyesek lehetnek, ha kiszivárognak, vagy ha olyanok férnek hozzá, akiknek nem kellene ezt látniuk. Két dolgot kellene figyelembe vennie:
Gondolja át, hogy az érzékeny információk valóban elengedhetetlenek-e a hibaelhárításhoz. Esetleg a hitelkártyaszám helyett elég, ha a tranzakció azonosítójára és a tranzakció dátumára vonatkozó információkat tárolja? Talán nem szükséges a társadalombiztosítási számot a naplókban tartani, ha a felhasználói azonosítót könnyen tárolhatja. Gondolja át az ilyen helyzeteket, gondolja át, hogy milyen adatokat tárol, és csak akkor írjon ki érzékeny adatokat, ha valóban szükséges.
A második dolog az érzékeny információkat tartalmazó naplók szállítása egy hosztolt naplószolgáltatáshoz. Nagyon kevés olyan kivétel van, ahol az alábbi tanácsot nem kell követni. Ha a naplóiban érzékeny adatokat tárolnak, és szükségük is van rá, maszkolja vagy távolítsa el azokat, mielőtt elküldi őket a központi naplótárolóba. A legtöbb népszerű naplószállító, például a mi Logagentünk, tartalmaz olyan funkciókat, amelyek lehetővé teszik az érzékeny adatok eltávolítását vagy maszkolását.
Az érzékeny információk maszkolása végül magában a naplózási keretrendszerben is elvégezhető. Nézzük meg, hogyan lehet ezt a Log4j 2 bővítésével megvalósítani. A naplóeseményeket előállító kódunk a következőképpen néz ki (a teljes példa megtalálható a Sematext Githubon):
public class Log4J2Masking { private static Logger LOGGER = LoggerFactory.getLogger(Log4J2Masking.class); private static final Marker SENSITIVE_DATA_MARKER = MarkerFactory.getMarker("SENSITIVE_DATA_MARKER"); public static void main(String args) { LOGGER.info("This is a log message without sensitive data"); LOGGER.info(SENSITIVE_DATA_MARKER, "This is a a log message with credit card number 1234-4444-3333-1111 in it"); }}
Ha a teljes példát a Githubról futtatnánk, a kimenet a következő lenne:
21:20:42.099 - This is a log message without sensitive data21:20:42.101 - This is a a log message with credit card number ****-****-****-**** in it
Látható, hogy a hitelkártyaszámot maszkoltuk. Ez azért történt, mert hozzáadtunk egy egyéni konvertert, amely ellenőrzi, hogy az adott Marker át van-e adva a naplóesemény mentén, és megpróbál egy meghatározott mintát helyettesíteni. Az ilyen konverter megvalósítása a következőképpen néz ki:
@Plugin(name = "sample_logging_mask", category = "Converter")@ConverterKeys("sc")public class LoggingConverter extends LogEventPatternConverter { private static Pattern PATTERN = Pattern.compile("\b({4})-({4})-({4})-({4})\b"); public LoggingConverter(String options) { super("sc", "sc"); } public static LoggingConverter newInstance(final String options) { return new LoggingConverter(options); } @Override public void format(LogEvent event, StringBuilder toAppendTo) { String message = event.getMessage().getFormattedMessage(); String maskedMessage = message; if (event.getMarker() != null && "SENSITIVE_DATA_MARKER".compareToIgnoreCase(event.getMarker().getName()) == 0) { Matcher matcher = PATTERN.matcher(message); if (matcher.find()) { maskedMessage = matcher.replaceAll("****-****-****-****"); } } toAppendTo.append(maskedMessage); }}
Ez nagyon egyszerű, és lehetne optimalizáltabban is megírni, és az összes lehetséges hitelkártyaszám formátumot is kezelni kellene, de erre a célra elegendő.
Mielőtt belevágnánk a kódmagyarázatba, szeretném megmutatni a log4j2.xml konfigurációs fájlt is ehhez a példához:
<?xml version="1.0" encoding="UTF-8"?><Configuration status="WARN" packages="com.sematext.blog.logging"> <Appenders> <Console name="Console" target="SYSTEM_OUT"> <PatternLayout pattern="%d{HH:mm:ss.SSS} - %sc %n"/> </Console> </Appenders> <Loggers> <Root level="info"> <AppenderRef ref="Console"/> </Root> </Loggers></Configuration>
Mint látható, a konfigurációnkban hozzáadtuk a packages attribútumot, hogy megmondjuk a keretrendszernek, hol keresse a konverterünket. Ezután a %sc mintát használtuk a naplóüzenet megadásához. Ezt azért tesszük, mert nem tudjuk felülírni az alapértelmezett %m mintát. Amint a Log4j2 megtalálja a %sc mintánkat, használni fogja a konverterünket, amely a napló esemény formázott üzenetét veszi, és egy egyszerű regexet használ, és kicseréli az adatokat, ha megtalálta. Ennyire egyszerű.
Egy dolog, amit itt észre kell vennünk, hogy a Marker funkciót használjuk. A regex-illesztés drága, és nem akarjuk ezt minden naplóüzenetnél elvégezni. Ezért a létrehozott Markerrel jelöljük a feldolgozandó naplóeseményeket, így csak a megjelöltek kerülnek ellenőrzésre.
Használjon naplókezelő megoldást a & Java naplók központi felügyeletére
Az alkalmazások összetettségével a naplók mennyisége is nőni fog. Megúszhatja azzal, hogy egy fájlba naplóz, és csak akkor használja a naplókat, amikor hibaelhárításra van szükség, de amikor az adatmennyiség növekszik, gyorsan nehézkessé és lassúvá válik a hibaelhárítás ilyen módon Amikor ez történik, fontolja meg egy naplókezelési megoldás használatát a naplóinak központosítására és felügyeletére. Választhat egy nyílt forráskódú szoftveren alapuló házon belüli megoldást, mint például az Elastic Stack, vagy használhatja a piacon elérhető naplókezelő eszközök egyikét, például a Sematext Logs-t.
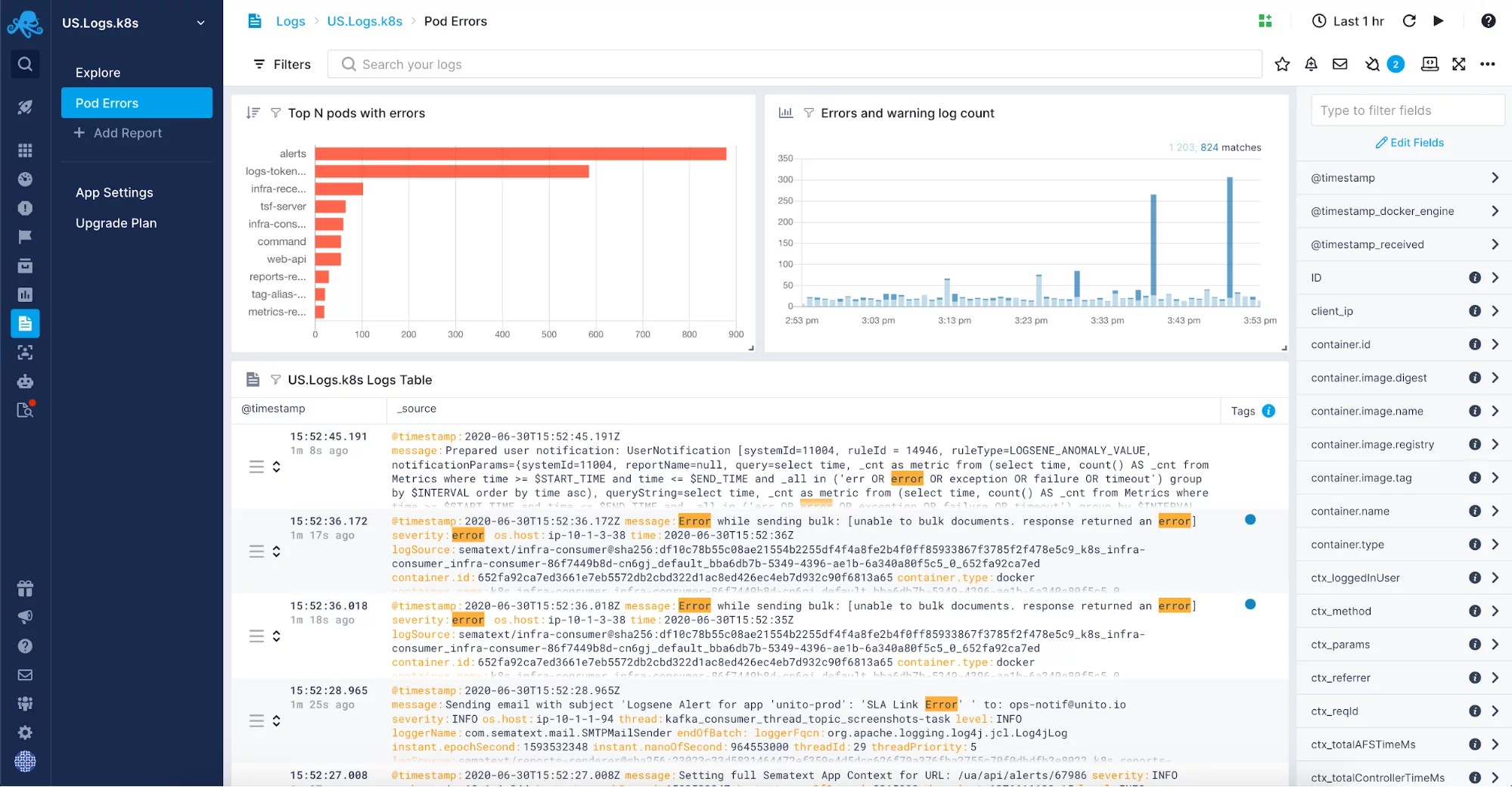
A teljesen menedzselt naplóközpontosítási megoldás megadja a szabadságot, hogy nem kell az infrastruktúra egy újabb, általában meglehetősen összetett részét kezelni. Ehelyett az alkalmazására összpontosíthat, és csak a naplószállítást kell beállítania. Lehet, hogy az olyan naplófájlokat, mint a JVM szemétgyűjtési naplók, is be szeretné vonni a kezelt naplómegoldásába. Miután bekapcsolta őket a JVM-en dolgozó alkalmazásai és rendszerei számára, a naplókat egyetlen helyen szeretné majd összesíteni a naplók korrelációja, a naplóelemzés és a JVM-példányok szemétgyűjtésének hangolása érdekében. Az ilyen, metrikákkal korrelált naplók felbecsülhetetlen értékű információforrást jelentenek a szemétgyűjtéssel kapcsolatos problémák elhárításához.
Ha érdekli, hogyan áll a Sematext Logs a hasonló megoldásokkal szemben, látogasson el a legjobb naplókezelő szoftverekről szóló cikkünkhöz vagy a blogbejegyzéshez, amelyben áttekintjük a legjobb naplóelemző eszközöket, de javasoljuk, hogy használja a 14 napos ingyenes próbaverziót a funkciók teljes körű felfedezéséhez. Próbálja ki, és győződjön meg róla a saját szemével!
Következtetés
Az egyes jó gyakorlatok beépítése nem biztos, hogy azonnal könnyen megvalósítható, különösen a már élesben és termelésben működő alkalmazások esetében. De ha időt szánsz rá, és egymás után vezeted be a javaslatokat, látni fogod a naplóid hasznosságának növekedését. További tippekért, hogyan hozhatod ki a legtöbbet a naplóidból, javasoljuk, hogy nézd át a másik cikkünket is a naplózás legjobb gyakorlatairól, ahol elmagyarázzuk, hogy mit és hogyan kell követned, függetlenül attól, hogy milyen típusú alkalmazással dolgozol. És ne feledje, hogy a Sematextnél naplózási tanácsadással segítünk a szervezeteknek a naplózási beállításokban, így ha gondjai vannak, forduljon hozzánk, és mi szívesen segítünk.
Vélemény, hozzászólás?