Iratkozzon fel napi összefoglalóinkra a folyamatosan változó keresőmarketingről.
Megjegyzés: Az űrlap elküldésével Ön elfogadja a Third Door Media feltételeit. Tiszteletben tartjuk a magánéletét.

Az internetes fórumokon és a tartalommal kapcsolatos Facebook-csoportokban gyakran törnek ki viták arról, hogyan működik a Googlebot – amit itt gyengéden GB-nek fogunk hívni -, mit láthat és mit nem, milyen linkeket látogat és hogyan befolyásolja a SEO-t.
Ebben a cikkben három hónapos kísérletem eredményeit mutatom be.
Az elmúlt három hónapban szinte naponta meglátogatott a GB, mint egy barát, aki beugrik egy sörre.
Néha egyedül volt:
: 66.249.76.136 /page1.html Mozilla/5.0 (kompatibilis; Googlebot/2.1; +http://www.google.com/bot.html)
: 66.249.76.136 /page5.html Mozilla/5.0 (kompatibilis; Googlebot/2.1; +http://www.google.com/bot.html)
: 66.249.76.140 /page3.html Mozilla/5.0 (kompatibilis; Googlebot/2.1; +http://www.google.com/bot.html)
: 66.249.64.72 /page2.html Mozilla/5.0 (kompatibilis; Googlebot/2.1; +http://www.google.com/bot.html)
: 66.249.64.72 /page6.html Mozilla/5.0 (kompatibilis; Googlebot/2.1; +http://www.google.com/bot.html)
Néha hozta magával a haverjait:
: 64.233.172.231 /page1.html Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, mint Gecko; Google Search Console) Chrome/41.0.2272.118 Safari/537.36
: 66.249.69.235 /image.jpg Googlebot-Image/1.0
: 66.249.76.156 /page2.html Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, mint Gecko) Chrome/41.0.2272.96 Mobile Safari/537.36 (kompatibilis; Googlebot/2.1; +http://www.google.com/bot.html)
És nagyon jól szórakoztunk a különböző játékokkal:
Catch: Megfigyeltem, hogy a GB mennyire szereti a 301-es átirányításokat és a képek feltérképezését, valamint a kanonikumokból való futtatást.
Bújócska: A Googlebot a rejtett tartalomban bújkált (amit, ahogy a szülei állítják, nem tolerál és elkerüli)
Túlélés: Csapdákat készítettem és vártam, hogy kipattanjon belőlük.
Ebélyegek:
Amint valószínűleg láthatjátok, nem csalódtam. Rengeteget szórakoztunk, és jó barátok lettünk. Hiszem, hogy a barátságunknak fényes jövője van.
De térjünk a lényegre!
Építettem egy honlapot érdemi tartalommal egy csillagközi utazási irodáról, amely járatokat kínál galaxisunk még fel nem fedezett bolygóira és azon túlra.
A tartalom sok érdeminek tűnt, pedig valójában egy rakás ostobaság volt.
A kísérleti weboldal felépítése így nézett ki:
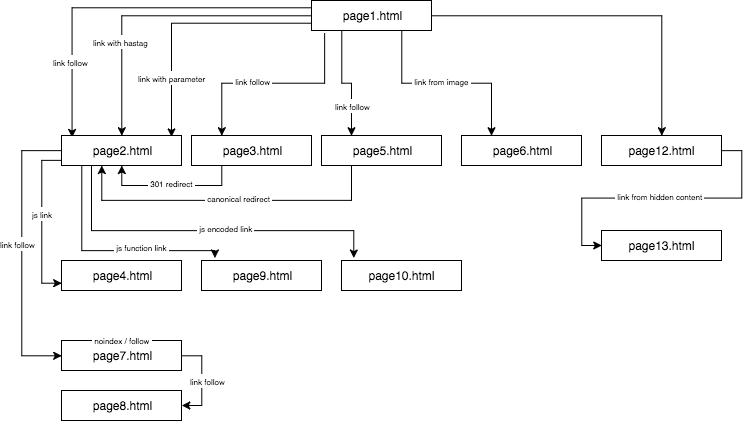
Egyedi tartalmat biztosítottam, és gondoskodtam arról, hogy minden anchor/title/alt, valamint egyéb együttható globálisan egyedi legyen (hamis szavak). Hogy megkönnyítsem az olvasó dolgát, a leírásban nem fogok olyan neveket használni, mint anchor cutroicano matestito, hanem anchor1 stb. néven hivatkozom rájuk.
A cikk olvasása közben javaslom, hogy a fenti térképet tartsa nyitva egy külön ablakban.
- 1. rész: Az első linkek száma
- Hivatkozás egy weboldalra horgonnyal
- Link egy weboldalra paraméterrel
- Link egy weboldalra egy átirányításból
- Link egy oldalra kanonikus tag használatával
- 2. rész: Crawl költségvetés
- JavaScript-link onclick-eseménnyel
- Javascript link belső funkcióval
- JavaScript link kódolással
- 3. rész: Rejtett tartalom
- A szerzőről
1. rész: Az első linkek száma
Az egyik dolog, amit ebben a SEO-kísérletben tesztelni akartam, az Első linkek száma szabály volt – hogy elhagyható-e, és hogyan befolyásolja az optimalizálást.
Az Első linkek száma szabály szerint egy oldalon a Google Bot csak az aloldalra mutató első linket látja. Ha egy oldalon két link mutat ugyanarra az aloldalra, akkor a második linket e szabály szerint figyelmen kívül hagyja. A Google Bot az oldal rangjának kiszámításakor figyelmen kívül hagyja a második és minden további link horgonyát.
Ezt a problémát sok szakember széles körben felügyeli, de különösen az online boltokban van jelen, ahol a navigációs menük jelentősen torzítják a weboldal szerkezetét.
A legtöbb boltban van egy statikus (az oldal forrásában látható) legördülő menü, amely például négy linket ad a fő kategóriákra és 25 rejtett linket az alkategóriákra. Az oldal szerkezetének feltérképezése során a GB látja az összes linket (minden egyes menüvel rendelkező oldalon), ami azt eredményezi, hogy a feltérképezés során minden oldal egyforma fontosságú, és erejük (juice) egyenletesen oszlik el, ami nagyjából így néz ki:
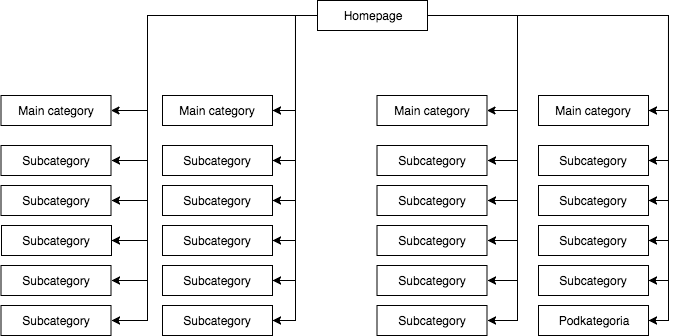
A leggyakoribb, de véleményem szerint rossz oldalszerkezet.
A fenti példa nem nevezhető megfelelő szerkezetnek, mert minden oldalról, ahol van menü, az összes kategória linkelve van. Ezért mind a kezdőlap, mind az összes kategória és alkategória azonos számú bejövő linkkel rendelkezik, és az egész webszolgáltatás ereje azonos erővel áramlik rajtuk keresztül. Ezért a kezdőlap ereje (amely a bejövő linkek száma miatt általában a legtöbb erő forrása) 24 kategóriában és alkategóriában oszlik meg, így mindegyikük a kezdőlap erejének csak 4 százalékát kapja.
Hogyan kellene kinéznie a struktúrának:

Ha gyorsan tesztelned kell az oldalad struktúráját, és úgy kell feltérképezned, ahogy a Google teszi, a Screaming Frog egy hasznos eszköz.
Ebben a példában a kezdőlap ereje négyfelé oszlik, és mindegyik kategória megkapja a kezdőlap erejének 25 százalékát, és ennek egy részét szétosztja az alkategóriák között. Ez a megoldás a belső linkelésnek is nagyobb esélyt ad. Ha például az üzlet blogján írunk egy cikket, és az egyik alkategóriára szeretnénk linkelni, a GB észreveszi a linket a weboldal kúszása közben. Az első esetben ezt nem fogja megtenni az Első link számít szabály miatt. Ha az egyik alkategóriára mutató link a weboldal menüjében volt, akkor a cikkben lévő linket figyelmen kívül hagyja.
Ezt a SEO-kísérletet a következő műveletekkel kezdtem:
- Először az oldalon1.html oldalon egy page2.html aloldalra mutató hivatkozást építettem be klasszikus dofollow hivatkozásként, anchor:anchor1 horgonnyal.
- Ezután ugyanezen oldal szövegében kissé módosított hivatkozásokat építettem be, hogy ellenőrizzem, hogy a GB szívesen feltérképezi-e azokat.
Ezért a következő megoldásokat teszteltem:
- A webszolgáltatás kezdőlapjához egy URL horgonnyal ellátott kifejezéshez egy külső dofollow linket rendeltem (így a kezdőlap és az adott kifejezésekhez tartozó aloldalak bármilyen külső hivatkozásáról szó sem lehetett) – ez felgyorsította a szolgáltatás indexelését.
- Vártam, hogy a page2.html oldal a page1.html oldalról érkező első dofollow link (anchor1) alapján kezdjen el rangsorolni egy kifejezésre. Ez a hamis kifejezés, vagy bármely más, általam tesztelt kifejezés nem volt megtalálható a céloldalon. Feltételeztem, hogy ha más linkek is működnek, akkor a page2.html más linkekből származó más kifejezésekre is rangsorolni fog a keresési eredményekben. Ez körülbelül 45 napig tartott. És akkor tudtam levonni az első fontos következtetést.
Még egy olyan weboldal, ahol egy kulcsszó sem a tartalomban, sem a meta címben nem szerepel, de egy kutatott horgonnyal kapcsolódik, könnyen előrébb tud rangsorolni a keresési eredményekben, mint egy olyan weboldal, amely tartalmazza ezt a szót, de nem kapcsolódik hozzá kulcsszó.
Mégis a főoldal (page1.html), amely tartalmazta a kutatott kifejezést, a legerősebb oldal volt a webszolgáltatásban (az aloldalak 78 százalékáról linkelt), és mégis rosszabbul rangsorolt a kutatott kifejezésre, mint az aloldal (page2.html), amely a kutatott kifejezéshez kapcsolódott.
A következőkben négyféle, általam tesztelt linket mutatok be, amelyek mindegyike a page2.html oldalra vezető első dofollow link után következik.
Hivatkozás egy weboldalra horgonnyal
< a href=”page2.html#testhash” >anchor2< /a >
A dofollow link mögött a kódban érkező további linkek közül az első egy horgonnyal (hashtaggel) rendelkező link volt. Kíváncsi voltam, hogy a GB átmegy-e a hivatkozáson, és indexeli-e a page2.html-t is az anchor2 kifejezés alatt, annak ellenére, hogy a link ugyan arra az oldalra (page2.html) vezet, de az URL-t page2.html#testhash használ anchor2-t.
A GB sajnos nem akarta megjegyezni ezt a kapcsolatot, és nem irányította a hatalmat a page2.html aloldalra az adott kifejezéshez. Ennek eredményeképpen a cikk írásának napján az anchor2 kifejezésre a keresési eredményekben csak az page1.html aloldal szerepel, ahol a szó a link horgonyában található. A teszthash kifejezésre való guglizás során a mi domainünk sem szerepel a rangsorban.
Link egy weboldalra paraméterrel
page2.html?parameter=1
A GB-t kezdetben az URL-nek ez a vicces része érdekelte, közvetlenül a kérdőjel után és a horgony az anchor3 linken belül.
Kíváncsi volt, GB megpróbálta kitalálni, mire gondolok. Arra gondolt, hogy “ez egy rejtvény?”. Hogy elkerülje a duplikált tartalom indexelését a többi URL alatt, a kanonikus page2.html önmagára mutatott. A naplók összesen 8 lánctalálatot regisztráltak ezen a címen, de a következtetések meglehetősen szomorúak voltak:
- 2 hét elteltével a GB látogatásainak gyakorisága jelentősen csökkent, míg végül elment, és soha többé nem lánctalálta ezt a linket.
- A page2.html nem indexelődött az anchor3 kifejezés alatt, ahogy az URL parameter1 paramétere sem. A Search Console szerint ez a link nem létezik (nem számít a bejövő linkek között), ugyanakkor az anchor3 kifejezés horgonyzott kifejezésként szerepel.
Link egy weboldalra egy átirányításból
A GB-t arra akartam kényszeríteni, hogy többet kússzon a weboldalamra, aminek eredményeként a GB néhány naponta beírta a dofollow linket anchor4 horgonnyal a page1.html oldalon, amely a page3.html oldalra vezet, amely 301-es kóddal átirányít a page2.html oldalra. Sajnos, ahogy a paraméteres oldal esetében is, 45 nap után a page2.html még nem szerepelt a keresési eredményekben a page1.html átirányított linkben megjelenő anchor4 kifejezésre.
Mégis a Google Search Console-ban, az Anchor Texts részben az anchor4 látható és indexelt. Ez azt jelezheti, hogy egy idő után az átirányítás az elvárt módon kezd működni, így az oldal2.html annak ellenére szerepel a keresési eredményekben az anchor4-re, hogy ugyanazon a weboldalon belül a második link ugyanarra a céloldalra.
Link egy oldalra kanonikus tag használatával
Az oldal1.html oldalon elhelyeztem egy hivatkozást az oldal5.html-re (követő link) anchor anchor5 horgonnyal. Ugyanakkor az oldal5.html oldalon egyedi tartalom volt, és a fejében volt egy kanonikus tag az oldal2.html-re.
< link rel=”canonical” href=”https://example.com/page2.html” />
Ez a teszt a következő eredményeket adta:
- Az anchor5 kifejezéshez tartozó link az oldal5.html oldalra irányított, és kanonikusan átirányított az oldal2-re.html nem került át a céloldalra (csakúgy, mint a többi esetben).
- Az oldal5.html a kanonikus tag ellenére indexelve lett.
- Az oldal5.html nem szerepelt a keresési eredményekben az anchor5.html az oldal szövegében használt kifejezések alapján rangsorolt, ami azt jelezte, hogy a GB teljesen figyelmen kívül hagyta a kanonikus címkéket.
Megkockáztatom, hogy a rel=canonical használata bizonyos tartalmak indexelésének megakadályozására (pl. szűrés közben) egyszerűen nem működhet.
2. rész: Crawl költségvetés
A SEO stratégia tervezése során a GB-t az én dallamomra akartam rávenni, és nem fordítva. Ennek érdekében a SEO-folyamatokat a szervernaplók (hozzáférési naplók és hibanaplók) szintjén ellenőriztem, ami hatalmas előnyt jelentett számomra. Ennek köszönhetően ismertem GB minden mozdulatát, és tudtam, hogyan reagált az általam a SEO-kampány keretében bevezetett változtatásokra (a weboldal átalakítása, a belső linkrendszer felforgatása, az információk megjelenítésének módja).
A SEO-kampány során az egyik feladatom az volt, hogy úgy építsem át a weboldalt, hogy GB csak azokat az URL-eket látogassa meg, amelyeket indexelni tud, és amelyeket indexelni szeretnénk. Dióhéjban: csak a számunkra SEO szempontból fontos oldalak legyenek a Google indexében. Másrészt a GB-nek csak azokat a weboldalakat kellene feltérképeznie, amelyeket szeretnénk, hogy a Google indexeljen, ami nem mindenki számára nyilvánvaló, például amikor egy webáruház szín, méret és ár szerinti szűrést valósít meg, és ez az URL paraméterek manipulálásával történik, pl.:
example.com/women/shoes/?color=red&size=40&price=200-250
Kiderülhet, hogy egy olyan megoldás, amely lehetővé teszi a GB számára a dinamikus URL-ek feltérképezését, az oldal feltérképezése helyett a feltérképezésre (és esetleg indexelésére) fordít időt.
example.com/women/shoes/
Az ilyen dinamikusan létrehozott URL-ek nem csak haszontalanok, hanem potenciálisan károsak a SEO szempontjából, mivel összetéveszthetik őket vékony tartalomnak, ami a webhely rangsorának csökkenését eredményezi.
Ezzel a kísérlettel a rel=”nofollow” használata, a GB blokkolása a robots.txt fájlban vagy a HTML-kód egy részének a bot számára láthatatlan keretekbe helyezése (blokkolt iframe) nélküli strukturálási módszereket is ellenőrizni akartam.
Háromféle JavaScript linket teszteltem.
JavaScript-link onclick-eseménnyel
Egy egyszerű JavaScriptre épülő link
< a href=”javascript:void(0)” onclick=”window.location.href =’page4.html'” >anchor6< /a >
GB könnyen továbblépett a page4.html aloldalra és indexelte az egész oldalt. Az aloldal nem szerepel a keresési eredményekben az anchor6 kifejezésre, és ez a kifejezés nem található a Google Search Console horgonyszövegek részében. A következtetés az, hogy a link nem adta át a juice-t.
Összefoglalva:
- A klasszikus JavaScript link lehetővé teszi a Google számára, hogy feltérképezze a webhelyet és indexelje az oldalakat, amelyekre rátalál.
- Nem ad át juice-t – semleges.
Javascript link belső funkcióval
Úgy döntöttem, hogy felemelem a játékot, de meglepetésemre a GB kevesebb mint 2 órával a link közzététele után leküzdötte az akadályt.
< a href=”javascript:void(0)” class=”js-link” data-url=”page9.html” >anchor7< /a >
A link működtetéséhez egy külső függvényt használtam, amelynek célja az volt, hogy az adatokból kiolvassa az URL-t és az átirányítást – reményeim szerint csak a felhasználó átirányítását – a céloldal9.html-re. A korábbi esethez hasonlóan a page9.html teljes mértékben indexelve volt.
Az érdekes az, hogy más bejövő linkek hiánya ellenére a page9.html volt a harmadik leggyakrabban látogatott oldal a GB által az egész webszolgáltatásban, közvetlenül a page1.html és a page2.html után.
Ezt a módszert már korábban is használtam webszolgáltatások strukturálásához. Azonban, mint láthatjuk, ez már nem működik. A SEO-ban semmi sem él örökké, leszámítva a sárga oldalakat.
JavaScript link kódolással
Mégsem adtam fel, és úgy döntöttem, hogy kell lennie egy módnak arra, hogy hatékonyan becsukjam az ajtót GB előtt. Így hát felépítettem egy egyszerű függvényt, az adatokat base64 algoritmussal kódoltam, és a hivatkozás így nézett ki:
< a href=”javascript:void(0)” class=”js-link” data-url=”cGFnZTEwLmh0bWw=” >anchor8< /a >
Az eredmény az lett, hogy GB nem tudott olyan JavaScript-kódot előállítani, amely egyszerre dekódolja a data-URL attribútum tartalmát és az átirányítást. És már meg is volt! Megvan a módja annak, hogyan strukturáljunk egy webszolgáltatást rel=nonfollows használata nélkül, hogy megakadályozzuk a botokat abban, hogy oda kússzanak, ahová akarnak! Így nem pazaroljuk a crawl-budgetünket, ami különösen nagy webszolgáltatások esetében fontos, és a GB végre a mi dallamunkra táncol. Akár ugyanazon az oldalon a head részben, akár egy külső JS fájlban vezettük be a funkciót, sem a szervernaplókban, sem a Search Console-ban nincs nyoma botnak.
3. rész: Rejtett tartalom
Az utolsó tesztben azt akartam ellenőrizni, hogy a GB figyelembe veszi és indexeli-e a tartalmat például a rejtett fülekben, vagy a Google megjelenít egy ilyen oldalt, és figyelmen kívül hagyja a rejtett szöveget, ahogy azt egyes szakemberek állítják.
Ezt az állítást szerettem volna vagy megerősíteni, vagy elutasítani. Ehhez egy több mint 2000 jelet tartalmazó szövegfalat helyeztem el a page12.html oldalon, és Cascading Style Sheetsben elrejtettem egy szövegblokkot, amely a szöveg körülbelül 20 százalékát (400 jelet) tartalmazza, és hozzáadtam a show more gombot. Az elrejtett szövegen belül volt egy link a page13.html oldalra egy anchor9 horgonnyal.
Kétségtelen, hogy egy bot képes megjeleníteni egy oldalt. Ezt mind a Google Search Console-ban, mind a Google Insight Speed-ben megfigyelhetjük. Ennek ellenére a tesztjeim azt mutatták, hogy a show more gombra kattintás után megjelenő szövegblokkot teljes mértékben indexelték. A szövegben elrejtett kifejezések a keresési eredmények között rangsoroltak, és a GB követte a szövegben elrejtett linkeket. Ráadásul a Google Search Console-ban a rejtett szövegblokkban lévő linkek horgonyai láthatóak voltak az Anchor Text részben, és a page13.html is elkezdett rangsorolni a keresési eredményekben az anchor9 kulcsszóra.
Ez kulcsfontosságú az online boltok esetében, ahol a tartalom gyakran rejtett fülekbe kerül. Most már biztosak vagyunk benne, hogy a GB látja a rejtett fülekben lévő tartalmakat, indexeli azokat, és átadja az ott elrejtett linkek juice-ját.
A legfontosabb következtetés, amit ebből a kísérletből levonok, hogy nem találtam közvetlen módot arra, hogy módosított linkek (paraméteres linkek, 301-es átirányítások, kanonikusok, horgonyvonalak) használatával megkerüljük az Első link számít szabályt. Ugyanakkor lehetséges egy weboldal szerkezetét Javascript linkek segítségével felépíteni, aminek köszönhetően megszabadulunk az Első Link Számok Szabály korlátozásaitól. Ráadásul a Google Bot látja és indexeli a könyvjelzőkben elrejtett tartalmakat, és követi az azokban elrejtett linkeket.
Iratkozzon fel napi összefoglalóinkra a keresőmarketing folyamatosan változó világáról.
Megjegyzés: Az űrlap elküldésével Ön elfogadja a Third Door Media feltételeit. Tiszteletben tartjuk a magánéletét.
A szerzőről

“Ne fogadja el “csak” a magas minőséget. Azt bárki meg tudja csinálni. Ha az ég a határ, keress egy magasabb égtájat.” Max Cyrek a Cyrek Digital vezérigazgatója, digitális marketing tanácsadó és SEO evangelista. Pályafutása során Max több mint 30 fős csapatával együtt több száz céggel dolgozott együtt, segítve őket a sikerben. Közel tíz éve dolgozik a digitális marketing területén, és a technikai SEO-ra specializálódott, sikeres marketingprojekteket irányít.
Vélemény, hozzászólás?