A Hashtábla olyan adatszerkezet, amely asszociatív módon tárolja az adatokat. A hash-táblában az adatokat tömb formátumban tároljuk, ahol minden adatértéknek saját egyedi indexértéke van. Az adatok elérése nagyon gyors lesz, ha ismerjük a kívánt adat indexét.
Így olyan adatszerkezetté válik, amelyben a beszúrási és keresési műveletek az adatok méretétől függetlenül nagyon gyorsak. A Hash-tábla egy tömböt használ tárolóeszközként, és hash-technikát alkalmaz egy index létrehozására, ahonnan egy elemet be kell illeszteni vagy meg kell keresni.
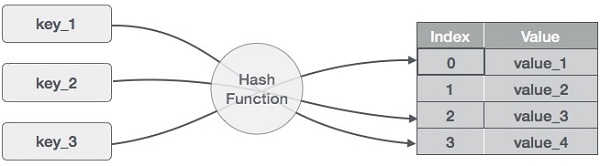
Hashing
A hash-technika egy olyan technika, amellyel egy kulcsértéktartományt egy tömb indextartományává alakítunk át. A modulo operátort fogjuk használni a kulcsértékek tartományának kinyeréséhez. Vegyünk egy példát egy 20-as méretű hash-táblára, és a következő elemeket kell tárolni. Az elemek (kulcs,érték) formátumban vannak.
- (1,20)
- (2,70)
- (42,80)
- (4,25)
- (12,44)
- (14,32)
- (17,11)
- (13,78)
- (37,98)
| Sr.No. | Key | Hash | Array Index | |
|---|---|---|---|---|
| 1 | 1 | 1 % 20 = 1 | 1 | |
| 2 | 2 | 2 | 2 % 20 = 2 | 2 |
| 3 | 42 | 42 % 20 = 2 | 2 | |
| 4 | 4 | 4 % 20 = 4 | 4 | |
| 5 | 12 | 12 % 20 = 12 | 12 | |
| 6 | 14 | 14 % 20 = 14 | 14 | |
| 7 | 17 | 17 % 20 = 17 | 17 | |
| 8 | 13 | 13 % 20 = 13 | 13 | |
| 9 | 37 | 37 % 20 = 17 | 17 |
Lineáris szondázás
Amint látjuk, előfordulhat, hogy a hashing technikát a tömb már használt indexének létrehozására használjuk. Ilyen esetben a tömb következő üres helyét úgy kereshetjük meg, hogy a következő cellában keresünk, amíg üres cellát nem találunk. Ezt a technikát lineáris keresésnek nevezzük.
| Sr.sz. | Key | Hash | Array Index | A lineáris szondázás után, Array Index | |
|---|---|---|---|---|---|
| 1 | 1 | 1 % 20 = 1 | 1 | 1 | 1 |
| 2 | 2 | 2 % 20 = 2 | 2 | 2 | |
| 3 | 42 | 42 % 20 = 2 | 2 | 3 | |
| 4 | 4 | 4 % 20 = 4 | 4 | 4 | |
| 5 | 12 | 12 % 20 = 12 | 12 | 12 | |
| 6 | 14 | 14 % 20 = 14 | 14 | 14 | |
| 7 | 17 | 17 % 20 = 17 | 17 | 17 | |
| 8 | 13 | 13 % 20 = 13 | 13 | 13 | |
| 9 | 37 | 37 % 20 = 17 | 17 | 18 |
Basic Operations
A következők a hash tábla alapvető elsődleges műveletei.
-
Keresés – elemet keres a hash-táblában.
-
Beillesztés – elemet illeszt be a hash-táblába.
-
Leállítás – elemet töröl a hash-táblából.
DataItem
Meghatároz egy bizonyos adatokkal és kulcsokkal rendelkező adatelemet, amely alapján a keresést egy hash-táblában kell elvégezni.
struct DataItem { int data; int key;};
Hash Method
Definiáljunk egy hash-módszert az adatelem kulcsának hash-kódjának kiszámításához.
int hashCode(int key){ return key % SIZE;}
Keresési művelet
Amikor egy elemet kell keresni, számítsuk ki az átadott kulcs hash-kódját, és keressük meg az elemet a hash-kódot indexként használva a tömbben. Ha az elemet nem találjuk a kiszámított hash-kóddal, lineáris kereséssel előrébb jutunk az elemhez.
Példa
struct DataItem *search(int key) { //get the hash int hashIndex = hashCode(key); //move in array until an empty while(hashArray != NULL) { if(hashArray->key == key) return hashArray; //go to next cell ++hashIndex; //wrap around the table hashIndex %= SIZE; } return NULL; }
Beillesztési művelet
Amikor egy elemet be kell illeszteni, számítsuk ki az átadott kulcs hash-kódját, és keressük meg az indexet a hash-kódot indexként használva a tömbben. Használjon lineáris keresést az üres helyre, ha a kiszámított hash-kódnál talál egy elemet.
Példa
void insert(int key,int data) { struct DataItem *item = (struct DataItem*) malloc(sizeof(struct DataItem)); item->data = data; item->key = key; //get the hash int hashIndex = hashCode(key); //move in array until an empty or deleted cell while(hashArray != NULL && hashArray->key != -1) { //go to next cell ++hashIndex; //wrap around the table hashIndex %= SIZE; } hashArray = item; }
Törlési művelet
Amikor egy elemet törölni kell, számítsa ki az átadott kulcs hash-kódját, és keresse meg az indexet a hash-kódot indexként használva a tömbben. Ha a kiszámított hash-kódnál nem találunk elemet, lineáris szondázással szerezzük meg az elemet előre. Ha megtaláltuk, tároljunk ott egy dummy elemet, hogy a hash-tábla teljesítménye megmaradjon.
Példa
struct DataItem* delete(struct DataItem* item) { int key = item->key; //get the hash int hashIndex = hashCode(key); //move in array until an empty while(hashArray !=NULL) { if(hashArray->key == key) { struct DataItem* temp = hashArray; //assign a dummy item at deleted position hashArray = dummyItem; return temp; } //go to next cell ++hashIndex; //wrap around the table hashIndex %= SIZE; } return NULL; }
A hash megvalósításáról C programozási nyelven itt olvashat.
Vélemény, hozzászólás?