Přihlaste se k odběru našich každodenních přehledů neustále se měnícího prostředí vyhledávacího marketingu.
Poznámka: Odesláním tohoto formuláře souhlasíte s podmínkami společnosti Third Door Media. Respektujeme vaše soukromí.

Na internetových fórech a v obsahových skupinách na Facebooku se často rozbíhají diskuse o tom, jak funguje Googlebot – kterému zde budeme něžně říkat GB – a co může a nemůže vidět, jaké odkazy navštěvuje a jak ovlivňuje SEO.
V tomto článku představím výsledky svého tříměsíčního experimentu.
Téměř denně mě v posledních třech měsících GB navštěvoval jako kamarád, který se stavil na pivo.
Někdy byl sám:
: 66.249.76.136 /page1.html Mozilla/5.0 (kompatibilní; Googlebot/2.1; +http://www.google.com/bot.html)
: 66.249.76.136 /page5.html Mozilla/5.0 (kompatibilní; Googlebot/2.1; +http://www.google.com/bot.html)
: 66.249.76.140 /page3.html Mozilla/5.0 (kompatibilní; Googlebot/2.1; +http://www.google.com/bot.html)
: 66.249.64.72 /page2.html Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)
: 66.249.64.72 /page6.html Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)
Občas si s sebou přivedl kamarády:
: 64.233.172.231 /page1.html Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, jako Gecko; Google Search Console) Chrome/41.0.2272.118 Safari/537.36
: 66.249.69.235 /image.jpg Googlebot-Image/1.0
: 66.249.76.156 /page2.html Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, jako Gecko) Chrome/41.0.2272.96 Mobile Safari/537.36 (kompatibilní; Googlebot/2.1; +http://www.google.com/bot.html)
A my jsme si užili spoustu zábavy při hraní různých her:
Catch: Pozoroval jsem, jak GB rád spouští přesměrování 301 a prochází obrázky a spouští je z kanonikálů.
Schovávačka: Googlebot se schovával ve skrytém obsahu (který, jak tvrdí jeho rodiče, netoleruje a vyhýbá se mu)
Přežití: Připravil jsem pasti a čekal, až je spustí.
Překážky:
Jak asi tušíte, nebyl jsem zklamán. Užili jsme si spoustu legrace a stali se z nás dobří přátelé. Věřím, že naše přátelství má před sebou zářnou budoucnost.
Ale pojďme k věci!
Vytvořil jsem webové stránky s obsahem souvisejícím se zásluhami o mezihvězdnou cestovní kancelář, která nabízí lety na dosud neobjevené planety v naší galaxii i mimo ni.
Obsah vypadal, že má spoustu zásluh, i když ve skutečnosti to byla snůška nesmyslů.
Struktura experimentálního webu vypadala takto:
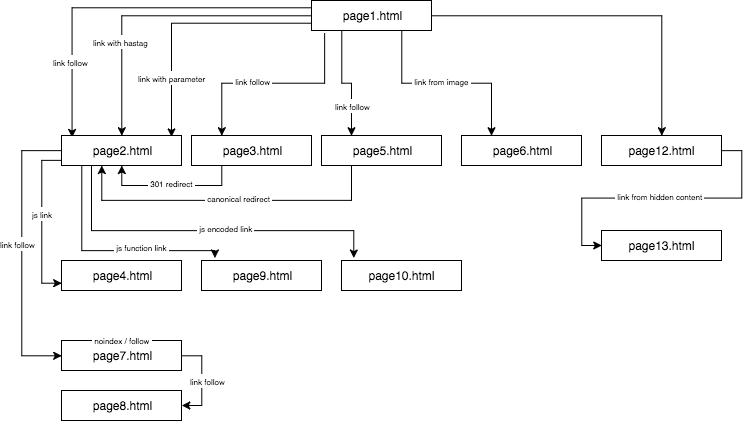
Poskytl jsem unikátní obsah a zajistil, aby každá kotva/titulek/alt i další koeficienty byly globálně unikátní (falešná slova). Abych čtenářům usnadnil práci, nebudu v popisu používat názvy jako kotva cutroicano matestito, ale budu je označovat jako kotva1 atd.
Při čtení tohoto článku doporučuji mít výše uvedenou mapu otevřenou v samostatném okně.
- Část 1. Založení mapy:
- Odkaz na webovou stránku s kotvou
- Odkaz na webovou stránku s parametrem
- Odkaz na web z přesměrování
- Odkaz na stránku pomocí kanonické značky
- Část 2: Rozpočet procházení
- Jáveskriptový odkaz s událostí onclick
- Javascriptový odkaz s interní funkcí
- JavaScriptový odkaz s kódováním
- Část 3: Skrytý obsah
- O autorovi
Část 1. Založení mapy:
Pravidlo prvního odkazu se počítá
Jednou z věcí, kterou jsem chtěl v tomto SEO experimentu otestovat, bylo pravidlo prvního odkazu se počítá – zda ho lze vynechat a jak ovlivňuje optimalizaci.
Pravidlo prvního odkazu se počítá říká, že na stránce vidí bot Google pouze první odkaz na podstránku. Pokud máte na jedné stránce dva odkazy na stejnou podstránku, druhý odkaz bude podle tohoto pravidla ignorován. Bot Google bude při výpočtu pozice stránky ignorovat kotvu v druhém a v každém dalším odkazu.
Jedná se o problém, na který široce dohlíží mnoho odborníků, ale který se vyskytuje zejména v internetových obchodech, kde navigační menu výrazně narušuje strukturu webu.
Ve většině obchodů máme statické (ve zdroji stránky viditelné) rozbalovací menu, které dává například čtyři odkazy na hlavní kategorie a 25 skrytých odkazů na podkategorie. Při mapování struktury stránky vidí GB všechny odkazy (na každé stránce s menu), což má za následek, že všechny stránky mají při mapování stejnou důležitost a jejich síla (šťáva) je rovnoměrně rozložena, což vypadá zhruba takto:
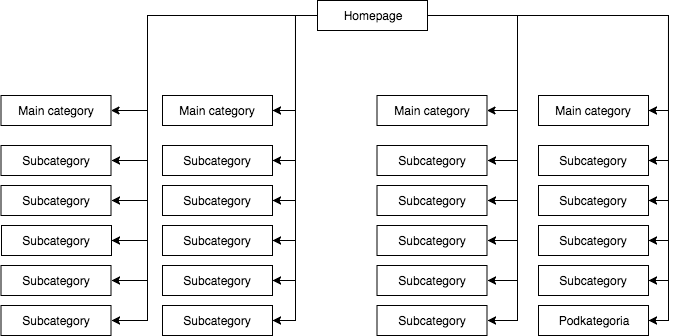
Nejčastější, ale podle mého názoru nesprávná struktura stránek.
Výše uvedený příklad nelze nazvat správnou strukturou, protože všechny kategorie jsou propojeny ze všech stránek, kde je menu. Proto mají jak domovská stránka, tak všechny kategorie a podkategorie stejný počet příchozích odkazů a výkon celé webové služby jimi proudí se stejnou silou. Proto se síla domovské stránky (která je obvykle zdrojem většiny síly vzhledem k počtu příchozích odkazů) rozděluje do 24 kategorií a podkategorií, takže každá z nich dostává pouze 4 % síly domovské stránky.
Jak by měla vypadat struktura:

Pokud potřebujete rychle otestovat strukturu své stránky a procházet ji podobně jako Google, pomůže vám nástroj Screaming Frog.
V tomto příkladu je výkon domovské stránky rozdělen na čtyři a každá z kategorií získává 25 procent výkonu domovské stránky a část rozděluje do podkategorií. Toto řešení také poskytuje větší šanci na interní propojení. Například když napíšete článek na blogu obchodu a budete chtít odkázat na jednu z podkategorií, GB si odkazu všimne při procházení webu. V prvním případě to neudělá kvůli pravidlu První odkaz se počítá. Pokud by byl odkaz na podkategorii v menu webu, pak ten v článku bude ignorován.
Tento SEO experiment jsem začal následujícími akcemi:
- Nejprve na stránce1.html jsem zařadil odkaz na podstránku page2.html jako klasický dofollow odkaz s kotvou: anchor1.
- Dále jsem do textu na téže stránce zařadil mírně upravené odkazy, abych ověřil, zda je GB bude chtít procházet.
Pro tento účel jsem vyzkoušel následující řešení:
- Na domovskou stránku webové služby jsem přiřadil jeden externí dofollow odkaz pro frázi s kotvou URL (takže jakékoliv externí propojení domovské stránky a podstránek pro dané fráze nepřipadalo v úvahu) – urychlilo to indexaci služby.
- Čekal jsem, až se stránka2.html začne řadit pro frázi z prvního dofollow odkazu (anchor1) pocházejícího ze stránky1.html. Tuto falešnou frázi ani žádnou jinou, kterou jsem testoval, nebylo možné na cílové stránce najít. Předpokládal jsem, že pokud budou ostatní odkazy fungovat, pak se stránka2.html bude ve výsledcích vyhledávání umisťovat i na další fráze z jiných odkazů. Trvalo to přibližně 45 dní. A pak jsem mohl učinit první důležitý závěr:
I stránka, kde se klíčové slovo nenachází ani v obsahu, ani v meta title, ale je propojena zkoumanou kotvou, se může snadno umístit ve výsledcích vyhledávání výše než stránka, která toto slovo obsahuje, ale není propojena s klíčovým slovem.
Navíc domovská stránka (page1.html), která obsahovala zkoumanou frázi, byla nejsilnější stránkou webové služby (odkazovala ze 78 procent podstránek), a přesto se na zkoumanou frázi umístila níže než podstránka (page2.html) odkazovaná na zkoumanou frázi.
Níže uvádím čtyři typy odkazů, které jsem testoval a které všechny následují po prvním dofollow odkazu vedoucím na stránku2.html.
Odkaz na webovou stránku s kotvou
< a href=“page2.html#testhash“ >kotva2< /a >
Prvním z dalších odkazů přicházejících v kódu za odkazem dofollow byl odkaz s kotvou (hashtag). Chtěl jsem vyzkoušet, zda GB projde odkazem a zaindexuje také stránku page2.html pod frází anchor2, přestože odkaz vede na tuto stránku (page2.html), ale URL změněné na page2.html#testhash používá anchor2.
Naneštěstí si GB toto spojení nikdy nechtěl zapamatovat a pro tuto frázi nepřesměroval výkon na podstránku page2.html. Výsledkem je, že ve výsledcích vyhledávání pro frázi anchor2 je v den psaní tohoto článku pouze podstránka page1.html, kde se toto slovo nachází v kotvě odkazu. Při vyhledávání fráze testhash v Googlu se naše doména také neumisťuje.
Odkaz na webovou stránku s parametrem
page2.html?parameter=1
Zpočátku GB zaujala tato legrační část adresy URL hned za značkou dotazu a kotva uvnitř odkazu anchor3.
Zajímavé, GB se snažil zjistit, co tím myslím. Napadlo ho: „Je to hádanka?“. Aby se zabránilo indexování duplicitního obsahu pod ostatními adresami URL, ukazovala kanonická stránka2.html sama na sebe. Protokoly celkem zaznamenaly 8 procházení této adresy, ale závěry byly spíše smutné:
- Po dvou týdnech se frekvence návštěv GB výrazně snížila, až nakonec odešla a tento odkaz už nikdy neprolezla.
- stránka2.html nebyla indexována pod frází anchor3, ani parametr s URL parametr1. Podle Search Console tento odkaz neexistuje (není započítán mezi příchozí odkazy), ale zároveň je fráze anchor3 uvedena jako ukotvená fráze.
Odkaz na web z přesměrování
Chtěl jsem donutit GB, aby můj web více procházel, což vedlo k tomu, že GB každých pár dní zadával odkaz dofollow s kotvou anchor4 na stránce1.html vedoucí na stránku3.html, která přesměrovává kódem 301 na stránku2.html. Bohužel stejně jako v případě stránky s parametrem se po 45 dnech stránka2.html ještě neumístila ve výsledcích vyhledávání na frázi s kotvou4, která se objevila v přesměrovaném odkazu na stránce1.html.
V Google Search Console v sekci Anchor Texts je však kotva4 viditelná a indexovaná. To by mohlo naznačovat, že po nějaké době začne přesměrování fungovat podle očekávání, takže stránka2.html se bude ve výsledcích vyhledávání řadit na kotvu4, přestože se jedná o druhý odkaz na stejnou cílovou stránku v rámci stejného webu.
Odkaz na stránku pomocí kanonické značky
Na stránku1.html jsem umístil odkaz na stránku5.html (následný odkaz) s kotvou anchor5. Zároveň se na stránce5.html nacházel unikátní obsah a v jeho hlavičce byla značka canonical na stránku2.html.
< odkaz rel=“canonical“ href=“https://example.com/page2.html“ />
Tento test dal následující výsledky:
- Odkaz pro frázi anchor5 směřující na stránku5.html přesměroval kanonicky na stránku2.html nebyl přenesen na cílovou stránku (stejně jako v ostatních případech).
- stránka5.html byla indexována i přes kanonickou značku.
- stránka5.html se ve výsledcích vyhledávání pro kotvu5 neumístila.
- stránka5.html se umístila na fráze použité v textu stránky, což naznačovalo, že GB zcela ignoroval kanonické značky.
Dovolil bych si tvrdit, že použití rel=canonical k zabránění indexování některého obsahu (např. při filtrování) prostě nemůže fungovat.
Část 2: Rozpočet procházení
Při navrhování strategie SEO jsem chtěl, aby GB tančil podle mých not a ne naopak. Za tímto účelem jsem ověřoval procesy SEO na úrovni logů serveru (logy přístupů a logy chyb), což mi poskytlo obrovskou výhodu. Díky tomu jsem znal každý pohyb GB a věděl jsem, jak reaguje na změny, které jsem v rámci kampaně SEO zavedl (restrukturalizace webu, převrácení systému vnitřních odkazů vzhůru nohama, způsob zobrazování informací).
Jedním z mých úkolů během kampaně SEO bylo přestavět web tak, aby GB navštěvoval pouze ty adresy URL, které bude schopen indexovat a které jsme chtěli, aby indexoval. Stručně řečeno: v indexu Googlu by měly být pouze stránky, které jsou pro nás důležité z hlediska SEO. Na druhou stranu by GB měl procházet jen ty stránky, které chceme, aby Google indexoval, což není každému jasné, například když internetový obchod zavede filtrování podle barev, velikostí a cen, a to pomocí manipulace s parametry URL, např:
example.com/women/shoes/?color=red&size=40&price=200-250
Může se ukázat, že řešení, které umožňuje GB procházet dynamické adresy URL, způsobuje, že místo procházení stránky věnuje čas jejich prohledávání (a případně indexování).
example.com/women/shoes/
Takto dynamicky vytvořené adresy URL jsou nejen zbytečné, ale potenciálně škodlivé pro SEO, protože mohou být mylně považovány za tenký obsah, což bude mít za následek pokles pozic webu.
V rámci tohoto experimentu jsem chtěl také ověřit některé metody strukturování bez použití rel=“nofollow“, blokování GB v souboru robots.txt nebo umístění části kódu HTML do rámců, které jsou pro bota neviditelné (blokovaný iframe).
Testoval jsem tři druhy odkazů v JavaScriptu.
Jáveskriptový odkaz s událostí onclick
Jednoduchý odkaz postavený na JavaScriptu
< a href=“javascript:void(0)“ onclick=“window.location.href =’page4.html'“ >anchor6< /a >
GB snadno přešel na podstránku page4.html a indexoval celou stránku. Podstránka se ve výsledcích vyhledávání pro frázi anchor6 neumisťuje a tuto frázi nelze nalézt ani v sekci Anchor Texts v konzole Google Search Console. Závěr je, že odkaz nepřenesl šťávu.
Shrneme-li to:
- Klasický odkaz v JavaScriptu umožňuje Googlu procházet web a indexovat stránky, na které narazí.
- Nepřenáší šťávu – je neutrální.
Javascriptový odkaz s interní funkcí
Rozhodl jsem se zvýšit hru, ale k mému překvapení GB překonal překážku za necelé 2 hodiny po zveřejnění odkazu.
< a href=“javascript:void(0)“ class=“js-link“ data-url=“page9.html“ >anchor7< /a >
Pro provoz tohoto odkazu jsem použil externí funkci, která byla zaměřena na načtení URL z dat a přesměrování – pouze přesměrování uživatele, jak jsem doufal – na cílovou stránku9.html. Stejně jako v předchozím případě byla stránka9.html plně indexována.
Zajímavé je, že i přes absenci jiných příchozích odkazů byla stránka9.html třetí nejnavštěvovanější stránkou GB v celé webové službě, hned po stránce1.html a stránce2.html.
Tento způsob jsem již dříve použil pro strukturování webových služeb. Jak je však vidět, již nefunguje. V SEO nic nežije věčně, kromě Zlatých stránek.
JavaScriptový odkaz s kódováním
Přesto jsem se nevzdával a rozhodl jsem se, že musí existovat způsob, jak GB účinně zavřít dveře před nosem. Sestavil jsem tedy jednoduchou funkci, zakódoval data pomocí algoritmu base64 a odkaz vypadal takto:
< a href=“javascript:void(0)“ class=“js-link“ data-url=“cGFnZTEwLmh0bWw=“ >anchor8< /a >
Výsledkem bylo, že GB nebyl schopen vytvořit kód JavaScriptu, který by dekódoval obsah atributu data-URL a zároveň přesměroval. A bylo to! Máme způsob, jak strukturovat webovou službu bez použití rel=nonfollows, abychom zabránili robotům prolézat, kam se jim zlíbí! Tímto způsobem neplýtváme rozpočtem na crawlování, což je důležité zejména v případě velkých webových služeb, a GB konečně tančí podle naší noty. Ať už byla funkce zavedena na téže stránce v sekci head nebo v externím souboru JS, v protokolech serveru ani v Search Console není žádný důkaz o přítomnosti bota.
Část 3: Skrytý obsah
V posledním testu jsem chtěl ověřit, zda obsah například ve skrytých záložkách bude brán v úvahu a indexován GB, nebo zda Google takovou stránku vykreslí a skrytý text ignoruje, jak tvrdí někteří odborníci.
Chtěl jsem toto tvrzení buď potvrdit, nebo zamítnout. Za tímto účelem jsem na stránku12.html umístil zeď textu s více než 2000 znaky a blok textu s asi 20 procenty textu (400 znaků) jsem skryl v kaskádových stylech a přidal jsem tlačítko zobrazit více. Uvnitř skrytého textu byl odkaz na stránku13.html s kotvou anchor9.
Není pochyb o tom, že bot může stránku vykreslit. Můžeme to pozorovat v konzole Google Search Console i v aplikaci Google Insight Speed. Nicméně mé testy odhalily, že blok textu zobrazený po kliknutí na tlačítko zobrazit více byl plně indexován. Fráze skryté v textu se řadily mezi výsledky vyhledávání a GB sledoval odkazy skryté v textu. Kromě toho byly kotvy odkazů ze skrytého bloku textu viditelné v konzole Google Search Console v části Anchor Text a stránka13.html se také začala řadit ve výsledcích vyhledávání na klíčové slovo anchor9.
To je zásadní pro internetové obchody, kde je obsah často umístěn ve skrytých záložkách. Nyní máme jistotu, že GB vidí obsah ve skrytých záložkách, indexuje je a přenáší šťávu z odkazů, které jsou tam skryté.
Nejdůležitější závěr, který z tohoto experimentu vyvozuji, je, že jsem nenašel přímý způsob, jak obejít pravidlo First Link Counts pomocí upravených odkazů (odkazy s parametrem, přesměrování 301, kanonické odkazy, kotevní odkazy). Zároveň je možné vytvořit strukturu webu pomocí Javascriptových odkazů, díky nimž se zbavíme omezení Pravidla pro počty prvních odkazů. Navíc Google Bot vidí a indexuje obsah skrytý v záložkách a sleduje odkazy v nich ukryté.
Přihlaste se k odběru našich každodenních přehledů neustále se měnícího prostředí vyhledávacího marketingu.
Poznámka: Odesláním tohoto formuláře souhlasíte s podmínkami společnosti Third Door Media. Respektujeme vaše soukromí.
O autorovi

„Nepřijímejte „jen“ vysokou kvalitu. To dokáže každý. Pokud je obloha limitem, najděte si vyšší oblohu“. Max Cyrek je generálním ředitelem společnosti Cyrek Digital, konzultantem v oblasti digitálního marketingu a evangelistou SEO. Během své kariéry Max spolu se svým více než třicetičlenným týmem spolupracoval se stovkami firem, kterým pomáhal uspět. V oblasti digitálního marketingu působí již téměř deset let a specializuje se na technické SEO, přičemž řídí úspěšné marketingové projekty.
Napsat komentář