Lidé vytvářejí, sdílejí a ukládají data rychleji než kdykoli v historii. Pokud jde o inovace v oblasti ukládání a přenosu těchto dat, děláme ve společnosti Facebook pokroky nejen v oblasti hardwaru – jako jsou větší pevné disky a rychlejší síťová zařízení – ale také v oblasti softwaru. Software pomáhá se zpracováním dat prostřednictvím komprese, která kóduje informace, jako je text, obrázky a další formy digitálních dat, s použitím menšího počtu bitů než originál. Tyto menší soubory zabírají méně místa na pevných discích a jsou rychleji přenášeny do jiných systémů. Komprimace a dekomprimace informací má však svou protihodnotu: čas. Čím více času se stráví komprimací do menšího souboru, tím pomaleji se data zpracovávají.
Dnes kralujícím standardem komprese dat je Deflate, základní algoritmus uvnitř Zip, gzip a zlib . Již dvě desetiletí poskytuje působivou rovnováhu mezi rychlostí a prostorem, a proto se používá v téměř každém moderním elektronickém zařízení (a nikoli náhodou se používá k přenosu každého bajtu právě tohoto příspěvku na blogu, který právě čtete). V průběhu let nabízely jiné algoritmy buď lepší, nebo rychlejší kompresi, ale málokdy obojí. Věříme, že jsme to změnili.
S potěšením oznamujeme Zstandard 1.0, nový kompresní algoritmus a implementaci navrženou tak, aby se dala škálovat s moderním hardwarem a komprimovala menší a rychlejší data. Zstandard kombinuje nedávné průlomové objevy v oblasti komprese, jako je Finite State Entropy, s návrhem zaměřeným na výkon – a poté optimalizuje implementaci pro jedinečné vlastnosti moderních procesorů. Díky tomu vylepšuje kompromisy jiných kompresních algoritmů a má široký rozsah použitelnosti s velmi vysokou rychlostí dekomprese. Zstandard, který je nyní k dispozici pod licencí BSD, je navržen tak, aby jej bylo možné použít téměř v každém scénáři bezeztrátové komprese, včetně mnoha případů, kdy současné algoritmy nejsou použitelné.
- Srovnání komprese
- Škálovatelnost
- Pod kapotou
- Paměť
- Formát určený pro paralelní provádění
- Bezkanálový návrh
- Konečná stavová entropie: Při kompresi jsou data nejprve transformována na sadu symbolů (fáze modelování) a poté jsou tyto symboly zakódovány pomocí minimálního počtu bitů. Tato druhá fáze se nazývá fáze entropie, na památku Clauda Shannona, která přesně vypočítá limit komprese množiny symbolů s danými pravděpodobnostmi (tzv. „Shannonův limit“). Cílem je přiblížit se tomuto limitu při použití co nejmenšího počtu prostředků procesoru.
- Repcode modeling
- Zstandard v praxi
- Malá data
- Slovníky v akci
- Výběr úrovně komprese
- Vyzkoušejte to
- Další budoucnost
Srovnání komprese
Existují tři standardní metriky pro srovnání kompresních algoritmů a implementací:
- Kompresní poměr:
- Rychlost komprese: Jak rychle dokážeme zmenšit data, měřeno v MB/s spotřebovaných vstupních dat.
- Rychlost dekomprese: Jak rychle můžeme rekonstruovat původní data z komprimovaných dat, měřeno v MB/s pro rychlost, s jakou jsou data vytvářena z komprimovaných dat.
Typ komprimovaných dat může tyto metriky ovlivnit, takže mnoho algoritmů je vyladěno pro konkrétní typy dat, například anglický text, genetické sekvence nebo rastrované obrázky. Zstandard je však stejně jako zlib určen k univerzální kompresi pro různé typy dat. Pro reprezentaci algoritmů, na kterých by měl Zstandard pracovat, použijeme v tomto příspěvku korpus Silesia, datovou sadu souborů, které reprezentují typické typy dat používané každý den.
Mezi dnes běžně používané algoritmy a jejich implementace patří zlib, lz4 a xz. Každý z těchto algoritmů nabízí různé kompromisy: lz4 usiluje o rychlost, xz o vyšší kompresní poměr a zlib o dobrou rovnováhu rychlosti a velikosti. Následující tabulka ukazuje hrubé kompromisy výchozího kompresního poměru a rychlosti algoritmů pro korpus Silesia porovnáním algoritmů na lzbench, čistě in-memory benchmark určený k modelování hrubého výkonu algoritmů.
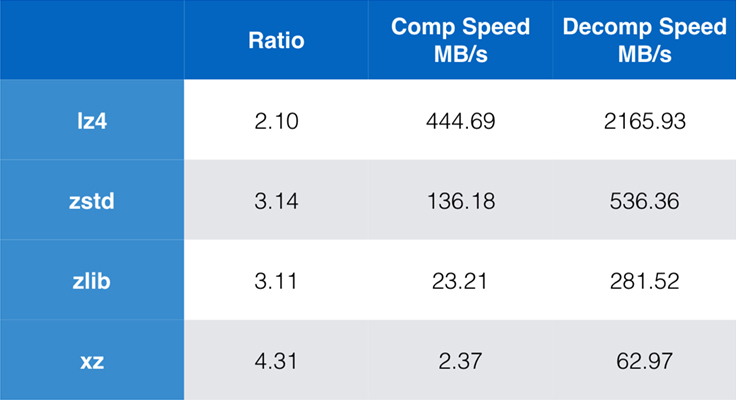
Jak bylo nastíněno, často dochází k drastickým kompromisům mezi rychlostí a velikostí. Nejrychlejší algoritmus lz4 má za následek nižší kompresní poměr; xz, který má nejvyšší kompresní poměr, trpí nízkou rychlostí komprese. Zstandard však při výchozím nastavení vykazuje podstatné zlepšení rychlosti komprese i dekomprese, přičemž komprimuje ve stejném poměru jako zlib.
Přestože je čistý výkon algoritmu důležitý, pokud je komprese začleněna do větší aplikace, je velmi časté, že se ke kompresi používají také nástroje příkazového řádku – například pro kompresi souborů protokolu, tarballů nebo jiných podobných dat určených k ukládání nebo přenosu. V těchto případech je výkon často ovlivněn režií, například kontrolním součtem. Tento graf ukazuje srovnání nástrojů příkazového řádku gzip a zstd v systému Centos 7 sestaveném s výchozím kompilátorem systému.
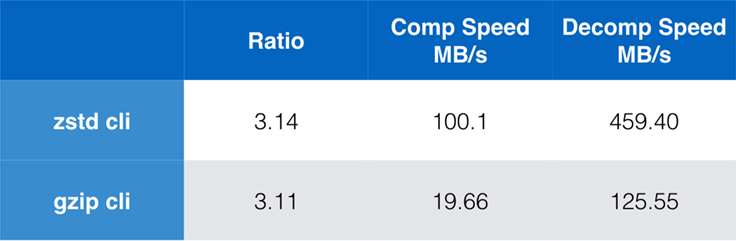
Testy byly provedeny vždy desetkrát, přičemž časy byly minimální, a byly provedeny na ramdisku, aby se zabránilo zatížení souborového systému. Jednalo se o tyto příkazy (které používají výchozí úrovně komprese pro oba nástroje):
zstd -c -3 silesia.tar > silesia.tar.zst # 67,432,740 byteszstd -d -c silesia.tar.zst > /dev/nullgzip -c -6 silesia.tar > silesia.tar.gz # 68,235,522 bytesgzip -d -c silesia.tar.gz > /dev/nullŠkálovatelnost
Je-li algoritmus škálovatelný, má schopnost přizpůsobit se nejrůznějším požadavkům a Zstandard je navržen tak, aby vynikal v dnešním prostředí a škáloval i do budoucna. Většina algoritmů má „úrovně“ založené na kompromisu mezi časem a prostorem: Čím vyšší úroveň, tím větší komprese se dosáhne při ztrátě rychlosti komprese. Zlib nabízí devět úrovní komprese; Zstandard jich v současnosti nabízí 22, což umožňuje flexibilní, granulární kompromisy mezi rychlostí komprese a poměry pro budoucí data. Například můžeme použít úroveň 1, pokud je nejdůležitější rychlost, a úroveň 22, pokud je nejdůležitější velikost.
Níže je graf rychlosti a poměru komprese dosažené pro všechny úrovně Zstandard a zlib. Na ose x je klesající logaritmická stupnice v megabajtech za sekundu; na ose y je dosažený kompresní poměr. Chcete-li porovnat algoritmy, můžete si vybrat rychlost a zobrazit různé poměry, kterých algoritmy při této rychlosti dosahují. Stejně tak můžete zvolit poměr a zobrazit, jak rychlé jsou algoritmy při dosažení této úrovně.
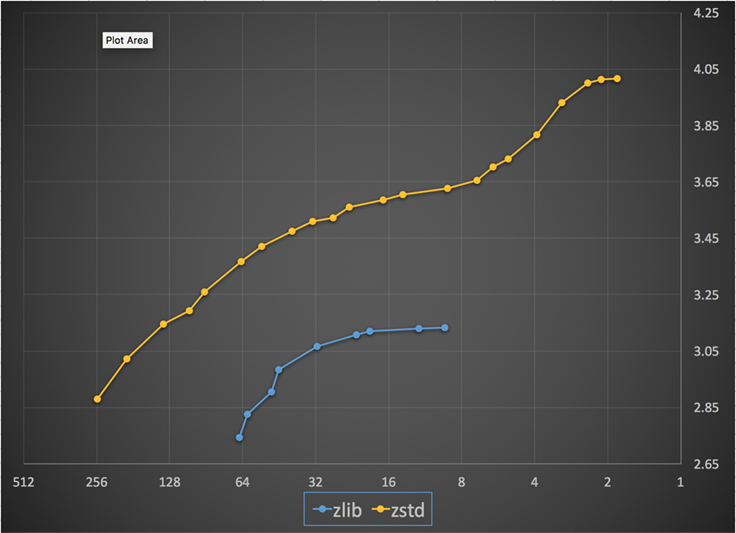
Pro jakoukoli svislou čáru (tj. rychlost komprese) dosahuje Zstandard vyššího kompresního poměru. Pro korpus Silesia byla rychlost dekomprese – bez ohledu na poměr – přibližně 550 MB/s pro Zstandard a 270 MB/s pro zlib. Graf ukazuje další rozdíl mezi standardem Zstandard a alternativami: Díky použití jednoho algoritmu a implementace umožňuje standard Z mnohem jemnější ladění pro každý případ použití. To znamená, že Zstandard může konkurovat některým z nejrychlejších a nejkvalitnějších kompresních algoritmů a zároveň si zachovat značnou výhodu v rychlosti dekomprese. Tato zlepšení se přímo promítají do rychlejšího přenosu dat a menších nároků na úložiště.
Jinými slovy, ve srovnání s zlib se Zstandard škáluje:
- Při stejném kompresním poměru komprimuje podstatně rychleji:
- Při stejné rychlosti komprese je podstatně menší: o 10-15 procent menší.
- Při dekompresi je téměř 2x rychlejší bez ohledu na kompresní poměr; čísla nástrojů příkazového řádku ukazují ještě větší rozdíl: více než 3x rychlejší.
- Škáluje na mnohem vyšší kompresní poměry při zachování bleskové rychlosti dekomprese.
Pod kapotou
Zstandard vylepšuje zlib kombinací několika nedávných inovací a zaměřením na moderní hardware:
Paměť
Podle návrhu je zlib omezen na okno 32 KB, což byla na počátku 90. let rozumná volba. Dnešní počítačové prostředí však může přistupovat k mnohem větší paměti – dokonce i v mobilních a vestavěných prostředích.
Zstandard nemá žádné vrozené omezení a může adresovat terabajty paměti (i když to dělá jen zřídka). Například nižší z 22 úrovní využívá 1 MB nebo méně. Pro kompatibilitu s širokou škálou přijímacích systémů, kde může být paměť omezena, se doporučuje omezit využití paměti na 8 MB. Jedná se však o doporučení pro ladění, nikoli o omezení kompresního formátu.
Formát určený pro paralelní provádění
Dnešní procesory jsou velmi výkonné a díky vícenásobným ALU (aritmeticko-logickým jednotkám) a stále pokročilejšímu návrhu provádění mimo pořadí mohou vydávat několik instrukcí za cyklus.
V podstatě to znamená, že pokud:
a = b1 + b2
c = d1 + d2
tak budou a i c počítány paralelně.
To je možné pouze v případě, že mezi nimi není žádný vztah. Proto v tomto příkladu:
a = b1 + b2
c = d1 + a
c musí počkat, až se nejprve vypočítá a, a teprve potom se začne počítat c.
To znamená, že pro využití výhod moderního procesoru je třeba navrhnout tok operací s malou nebo žádnou datovou závislostí.
Toho se v Zstandardu dosáhne rozdělením dat do více paralelních proudů. Nová generace Huffmanova dekodéru, Huff0, je schopna dekódovat více symbolů paralelně pomocí jediného jádra. Takový zisk se kumuluje s vícevláknovým zpracováním, které využívá více jader.
Nové procesory jsou výkonnější a dosahují velmi vysokých frekvencí, ale to je možné jen díky vícestupňovému přístupu, kdy je instrukce rozdělena do pipeline o více krocích. V každém taktu je procesor schopen vydat výsledek více operací v závislosti na dostupných ALU. Čím více ALU se používá, tím více práce CPU vykonává, a tudíž tím rychleji dochází ke kompresi. Pro výkon moderního procesoru je rozhodující, aby byly jednotky ALU zásobovány prací.
Ukazuje se, že to je obtížné. Uvažujme následující jednoduchou situaci:
if (condition) doSomething() else doSomethingElse()Když na ni procesor narazí, neví, co má dělat, protože závisí na hodnotě condition. Opatrný procesor by počkal na výsledek condition, než by začal pracovat na kterékoli větvi, což by bylo nesmírně nehospodárné.
Dnešní procesory hazardují. Činí tak inteligentně díky prediktoru větví, který jim v podstatě říká nejpravděpodobnější výsledek vyhodnocení condition. Když je sázka správná, zůstává pipeline plná a instrukce jsou vydávány průběžně. Když je sázka špatná (chybná předpověď), procesor musí zastavit všechny spekulativně zahájené operace, vrátit se k větvení a vydat se jiným směrem. Tomu se říká propláchnutí pipeline a v moderních procesorech je to nesmírně nákladné.
Před pětadvaceti lety bylo propláchnutí pipeline bezproblémové. Dnes je tak důležité, že je nezbytné navrhovat formáty kompatibilní s bezvětvovými algoritmy. Jako příklad se podívejme na aktualizaci bitového proudu:
/* classic version */while (nbBitsUsed >= 8) { /* each while test is a branch */ accumulator <<= 8; accumulator += *byte++; nbBitsUsed -= 8;} /*>/* branch-less version */nbBytesUsed = nbBitsUsed >> 3;nbBitsUsed &= 7;ptr += nbBytesUsed;accumulator = read64(ptr);Jak vidíte, bezvětvová verze má předvídatelné zatížení, bez jakékoliv podmínky. Procesor bude vždy vykonávat stejnou práci a tato práce není nikdy zahozena kvůli chybné předpovědi. Naproti tomu klasická verze vykoná méně práce, když (nbBitsUsed < 8). Samotný test však není zadarmo a kdykoli je test odhadnut špatně, má to za následek propláchnutí celé pipeline, což stojí více než práce vykonaná bezvětvovou verzí.
Jak asi tušíte, tento vedlejší efekt má dopady na způsob balení, čtení a dekódování dat. Zstandard byl vytvořen tak, aby byl přátelský k bezvětvovým algoritmům, zejména v rámci kritických smyček.
Konečná stavová entropie: Při kompresi jsou data nejprve transformována na sadu symbolů (fáze modelování) a poté jsou tyto symboly zakódovány pomocí minimálního počtu bitů. Tato druhá fáze se nazývá fáze entropie, na památku Clauda Shannona, která přesně vypočítá limit komprese množiny symbolů s danými pravděpodobnostmi (tzv. „Shannonův limit“). Cílem je přiblížit se tomuto limitu při použití co nejmenšího počtu prostředků procesoru.
Velmi rozšířeným algoritmem je Huffmanovo kódování, používané v rámci Deflate. Poskytuje nejlepší možný prefixový kód za předpokladu, že každý symbol je popsán přirozeným počtem bitů (1 bit, 2 bity …). V praxi to funguje skvěle, ale omezení přirozených čísel znamená, že není možné dosáhnout vysokých kompresních poměrů, protože symbol nutně spotřebuje alespoň 1 bit.
Lepší metoda se nazývá aritmetické kódování, které se může libovolně blížit Shannonově hranici -log2(P), a tedy spotřebovává zlomkové bity na symbol. To se projevuje lepším kompresním poměrem při vysoké pravděpodobnosti, ale také spotřebovává více výkonu procesoru. V praxi i optimalizované aritmetické kodéry bojují o rychlost, zejména na straně dekomprese, která vyžaduje dělení s předvídatelným výsledkem (např. ne s plovoucí desetinnou čárkou) a která se ukazuje jako pomalá.
Finite State Entropy je založena na nové teorii nazvané ANS (Asymmetric Numeral System) od Jarka Dudy. Finite State Entropy je varianta, která předpočítává mnoho kroků kódování do tabulek, čímž vzniká entropický kodek stejně přesný jako aritmetické kódování, který používá pouze sčítání, vyhledávání v tabulkách a posuny, což je přibližně stejná úroveň složitosti jako Huffman. Snižuje také latenci přístupu k dalšímu symbolu, protože je okamžitě přístupný ze stavové hodnoty, zatímco Huffman vyžaduje předchozí operaci dekódování bitového proudu. Vysvětlení jeho fungování přesahuje rámec tohoto příspěvku, ale pokud vás to zajímá, existuje řada článků, které podrobně popisují jeho vnitřní fungování.
Repcode modeling
Repcode modeling účinně komprimuje strukturovaná data, jejichž součástí jsou sekvence s téměř rovnocenným obsahem, které se liší pouze o jeden nebo několik bajtů. Tato metoda není nová, ale poprvé byla použita až po zveřejnění Deflate, takže v rámci zlib/gzip neexistuje.
Účinnost modelování repcode velmi závisí na typu komprimovaných dat a pohybuje se od jedno- až po dvouciferné zlepšení komprese. Tato kombinovaná zlepšení dávají dohromady lepší a rychlejší kompresi, kterou nabízí knihovna Zstandard.
Zstandard v praxi
Jak již bylo zmíněno, existuje několik typických případů použití komprese. Aby byl algoritmus přesvědčivý, musí být buď mimořádně dobrý v jednom konkrétním případě použití, jako je komprese lidsky čitelného textu, nebo velmi dobrý v mnoha různých případech použití. Zstandard používá druhý přístup. Jedním ze způsobů, jak uvažovat o případech použití, je kolikrát může být určitý kus dat dekomprimován. Zstandard má výhody ve všech těchto případech.
Mnohokrát. U mnohokrát zpracovávaných dat je výhodná rychlost dekomprese a možnost zvolit velmi vysoký kompresní poměr, aniž by byla ohrožena rychlost dekomprese. Například úložiště sociálního grafu na Facebooku se opakovaně načítá, jak vy a vaši přátelé komunikujete s webem. Mimo Facebook jsou příkladem toho, kdy je třeba data dekomprimovat mnohokrát, soubory stažené ze serveru, například zdrojový kód jádra Linuxu nebo soubory RPM nainstalované na serverech, JavaScript a CSS používané webovou stránkou nebo spouštění tisíců MapReduces nad daty v datovém skladu.
Jen jednou. U dat komprimovaných jen jednou, zejména pro přenos po síti, je komprese prchavým okamžikem v toku dat. Menší režie serveru znamená, že server může zpracovat více požadavků za sekundu. Menší režie na straně klienta znamená, že data mohou být zpracována rychleji. Obvykle to přichází v úvahu v situacích klient/server, kdy jsou data pro klienta jedinečná, jako je odpověď webového serveru, která je vlastní – například data použitá k vykreslení, když obdržíte poznámku od přítele na Messengeru. Výsledkem je, že mobilní zařízení načítá stránky rychleji, spotřebovává méně baterie a využívá méně datového tarifu. Zejména Zstandard se hodí pro mobilní scénáře mnohem lépe než jiné algoritmy, protože zpracovává malá data.
Možná nikdy. Ačkoli je to zdánlivě neintuitivní, často se stává, že část dat – například zálohy nebo soubory protokolu – nebude nikdy dekomprimována, ale v případě potřeby ji lze přečíst. Pro tento typ dat je obvykle nutné, aby komprese byla rychlá, data byla malá (s kompromisem mezi časem a prostorem vhodným pro danou situaci) a možná ukládala kontrolní součet, ale jinak byla neviditelná. Ve vzácných případech, kdy je třeba data dekomprimovat, nechcete, aby komprese zpomalovala provozní případ použití. Rychlá dekomprese je výhodná, protože se často jedná o malou část dat (například konkrétní soubor v záloze nebo zprávu v souboru protokolu), kterou je třeba rychle najít.
Ve všech těchto případech přináší standard Z možnost komprimovat a dekomprimovat mnohonásobně rychleji než gzip, přičemž výsledná komprimovaná data jsou menší.
Malá data
Existuje ještě jeden případ použití komprese, kterému se věnuje méně pozornosti, ale může být docela důležitý: malá data. Jedná se o modely použití, kdy jsou data vytvářena a spotřebovávána v malém množství, například zprávy JSON mezi webovým serverem a prohlížečem (typicky stovky bajtů) nebo stránky dat v databázi (několik kilobajtů).
Databáze představují zajímavý případ použití. Systémy jako MySQL, PostgreSQL a MongoDB ukládají data určená pro přístup v reálném čase. Nedávné hardwarové výhody, zejména v souvislosti s rozšířením zařízení typu flash (SSD), zásadně změnily rovnováhu mezi velikostí a propustností – nyní žijeme ve světě, kde jsou IOP (IO operace za sekundu) poměrně vysoké, ale kapacita našich úložných zařízení je nižší než v době, kdy datovým centrům vládly pevné disky.
Zařízení typu flash má navíc zajímavou vlastnost týkající se odolnosti proti zápisu – po tisících zápisů do stejné části zařízení již tato část nemůže přijímat zápisy, což často vede k vyřazení zařízení z provozu. Proto je přirozené hledat způsoby, jak snížit množství zapisovaných dat, protože to může znamenat více dat na server a pomalejší vypalování zařízení. Jednou z těchto strategií je komprese dat a databáze jsou také často optimalizovány na výkon, což znamená, že výkon při čtení a zápisu je stejně důležitý.
Používání komprese dat u databází však přináší komplikace. Databáze rády přistupují k datům náhodně, zatímco většina typických případů použití komprese čte celý soubor v lineárním pořadí. To je problém, protože komprese dat v podstatě funguje tak, že předpovídá budoucnost na základě minulosti – algoritmy se na data dívají postupně a předpovídají, co by mohly vidět v budoucnosti. Čím přesnější jsou předpovědi, tím menší mohou být data.
Pokud komprimujete malá data, jako jsou stránky v databázi nebo malé dokumenty JSON odesílané do mobilního zařízení, jednoduše není mnoho „minulosti“, kterou by bylo možné použít k předpovědi budoucnosti. Kompresní algoritmy se to pokoušely řešit pomocí předem sdílených slovníků, které umožňují efektivní start. Toho se dosáhne předběžným sdílením statické sady „minulých“ dat jako semínka pro kompresi.
Zstandard staví na tomto přístupu s vysoce optimalizovanými algoritmy a rozhraním API pro kompresi slovníků. Kromě toho Zstandard obsahuje nástroje (zstd --train) pro snadnou tvorbu slovníků pro vlastní aplikace a ustanovení pro registraci standardních slovníků pro sdílení s většími komunitami. Ačkoli se komprese liší v závislosti na vzorcích dat, komprese malých dat se může pohybovat v rozmezí 2x až 5x lepší než komprese bez slovníků.
Slovníky v akci
Ačkoli může být obtížné hrát si se slovníkem v kontextu běžící databáze (přece jen vyžaduje značné úpravy databáze), můžete slovníky vidět v akci s jinými typy malých dat. JSON, lingua franca malých dat v moderním světě, bývají malé, opakující se záznamy. K dispozici je nespočet veřejných datových sad; pro účely této ukázky použijeme datovou sadu „user“ ze služby GitHub, která je dostupná prostřednictvím protokolu HTTP. Zde je ukázkový záznam z této datové sady:
{ "login": "octocat", "id": 1, "avatar_url": "https://github.com/images/error/octocat_happy.gif", "gravatar_id": "", "url": "https://api.github.com/users/octocat", "html_url": "https://github.com/octocat", "followers_url": "https://api.github.com/users/octocat/followers", "following_url": "https://api.github.com/users/octocat/following{/other_user}", "gists_url": "https://api.github.com/users/octocat/gists{/gist_id}", "starred_url": "https://api.github.com/users/octocat/starred{/owner}{/repo}", "subscriptions_url": "https://api.github.com/users/octocat/subscriptions", "organizations_url": "https://api.github.com/users/octocat/orgs", "repos_url": "https://api.github.com/users/octocat/repos", "events_url": "https://api.github.com/users/octocat/events{/privacy}", "received_events_url": "https://api.github.com/users/octocat/received_events", "type": "User", "site_admin": false }Jak vidíte, je zde poměrně dost opakování – můžeme je pěkně zkomprimovat! Každý uživatel má však o něco méně než 1 KB a většina kompresních algoritmů opravdu potřebuje více dat, aby se protáhla. Sada 1 000 uživatelů zabere v nekomprimovaném stavu zhruba 850 KB. Naivní aplikace gzip nebo zstd na každý soubor zvlášť to sníží na něco málo přes 300 KB; to není špatné! Pokud však vytvoříme jednorázový, předem sdílený slovník s zstd, velikost klesne na 122 KB – čímž se původní kompresní poměr zvýší z 2,8× na 6,9×. To je výrazné zlepšení, které je k dispozici hned po vybalení s zstd:
$ zstd --train -o ../json.zdict -r .sorting 982 files of total size 0 MB ...finding patterns ...statistics ...Save dictionary of size 65599 into file ../json.zdict$ du -h --apparent-size .846K .$ zstd --rm -D ../json.zdict -r .$ du -h --apparent-size .122K .Výběr úrovně komprese
Jak bylo ukázáno výše, Zstandard poskytuje značný počet úrovní. Toto přizpůsobení je výkonné, ale vede k náročným volbám. Nejlepším způsobem, jak se rozhodnout, je zkontrolovat data a měření a rozhodnout se, jaké kompromisy chcete učinit. Ve společnosti Facebook považujeme výchozí úroveň 3 za vhodnou pro mnoho případů použití, ale čas od času ji mírně upravíme v závislosti na tom, co je naším úzkým místem (často se snažíme nasytit síťové připojení nebo diskové vřeteno); jindy nám více záleží na uložené velikosti a použijeme vyšší úroveň.
Koneckonců, aby byly výsledky co nejvíce přizpůsobeny vašim potřebám, budete muset zvážit jak hardware, který používáte, tak data, na kterých vám záleží – neexistují žádné tvrdé a pevné předpisy, které by bylo možné učinit bez kontextu. V případě pochybností však buď zůstaňte u výchozí úrovně 3, nebo u něčeho z rozsahu 6 až 9, abyste dosáhli příjemného kompromisu mezi rychlostí a prostorem; úroveň 20+ si nechte pro případy, kdy vám skutečně záleží pouze na velikosti a ne na rychlosti komprese.
Vyzkoušejte to
Zstandard je nástroj příkazového řádku (zstd) i knihovna. Je napsán ve vysoce přenosném jazyce C, takže je vhodný prakticky pro všechny dnes používané platformy – ať už jde o servery, na kterých běží vaše firma, váš notebook, nebo dokonce telefon ve vaší kapse. Můžete si jej stáhnout z našeho repozitáře github, zkompilovat pomocí jednoduchého příkazu make install a začít jej používat stejně jako gzip:
$ zstd access.logaccess.log : 8.07% (6695078 => 540336 bytes, access.log.zst)Jak se dalo očekávat, můžete jej použít jako součást příkazové řady, například k zálohování kritické databáze MySQL:
$ mysqldump --single-transaction --opt pokemon | zstd -q -o /srv/backups/mysqldump.sql.zstPříkaz tar podporuje různé implementace komprese out-of-box, takže po instalaci Zstandardu můžete okamžitě pracovat s tarbally komprimovanými pomocí Zstandardu. Zde je jednoduchý příklad, který ukazuje jeho použití s tar a rozdíl v rychlosti ve srovnání s gzip:
$ time tar -I zstd -cf linux-4.6.4.tar.zst linux-4.6.4tar -I zstd -cf linux-4.6.4.tar.zst linux-4.6.4 3.15s user 0.50s system 107% cpu 3.396 total$ time tar -zcf linux-4.6.4.tar.gz linux-4.6.4tar -zcf linux-4.6.4.tar.gz linux-4.6.4 13.74s user 0.43s system 102% cpu 13.784 totalKromě použití v příkazovém řádku existují rozhraní API, zdokumentovaná v hlavičkových souborech v úložišti (pro přehled rozhraní API začněte zde). Zahrnujeme také rozhraní API kompatibilní s rozhraním zlib wrapper (libWrapper) pro snadnější integraci s nástroji, které již mají rozhraní zlib. A konečně, v repozitáři GitHub uvádíme řadu příkladů, jak základního, tak pokročilejšího použití, jako jsou slovníky a streamování, rovněž v repozitáři GitHub.
Další budoucnost
Ačkoli jsme dosáhli verze 1.0 a považujeme Zstandard za připravený pro všechny druhy produkčního použití, ještě jsme neskončili. V budoucích verzích přijde:
- Vícevláknová komprese z příkazového řádku pro ještě rychlejší propustnost velkých souborů dat, podobně jako nástroj pigz pro zlib.
- Nové úrovně komprese, a to v obou směrech, umožňující ještě rychlejší kompresi a vyšší poměry.
- Komunitou spravovaná předdefinovaná sada kompresních slovníků pro běžné datové sady, jako je JSON, HTML a běžné síťové protokoly.
Rádi bychom poděkovali všem přispěvatelům, a to jak kódu, tak zpětné vazby, kteří nám pomohli dostat se k verzi 1.0. To je teprve začátek. Víme, že k tomu, aby Zstandard naplnil svůj potenciál, potřebujeme vaši pomoc. Jak bylo uvedeno výše, Zstandard si můžete vyzkoušet ještě dnes, a to tak, že si z našeho projektu GitHub stáhnete zdrojové kódy nebo předpřipravené binární soubory, případně pro uživatele počítačů Mac nainstalujete pomocí homebrew (brew install zstd). Budeme rádi za jakoukoli zpětnou vazbu a zajímavé případy použití, které máte, stejně jako za další jazykové vazby a pomoc s integrací s vašimi oblíbenými open source projekty.
Poznámky pod čarou
- Ačkoli se tento příspěvek zaměřuje na bezeztrátovou kompresi dat, existuje příbuzná, ale velmi odlišná oblast ztrátové komprese dat, která se používá především pro obrázky, zvuk a video.
- Deflate, zlib, gzip – tři propletená jména. Deflate je algoritmus, který používají implementace zlib a gzip. Zlib je knihovna poskytující Deflate a gzip je nástroj příkazového řádku, který používá zlib pro Deflate dat a také pro kontrolní součty. Toto kontrolní sčítání může mít značnou režii.
- Všechny benchmarky byly provedeny na počítači Intel E5-2678 v3 běžícím na frekvenci 2,5 GHz na počítači se systémem Centos 7. Nástroje příkazového řádku (
zstdagzip) byly sestaveny se systémem GCC, 4.8.5. V tomto případě se jednalo o nástroje, které byly vytvořeny na bázi příkazového řádku. Algoritmické benchmarky prováděné nástrojem lzbench byly sestaveny s GCC 6.
.
Napsat komentář