V tomto příspěvku se podíváme na nejpoužívanější algoritmy strojového učení. Existuje jich obrovské množství a je snadné cítit se zmateně, když slyšíte pojmy jako „algoritmy učení založené na instancích“ a „perceptron“.
Obvykle se všechny algoritmy strojového učení dělí do skupin buď podle stylu učení, funkce, nebo podle problémů, které řeší. V tomto příspěvku najdete klasifikaci založenou na stylu učení. Zmíním se také o běžných úlohách, které tyto algoritmy pomáhají řešit.
Počet algoritmů strojového učení, které se dnes používají, je velký a nebudu se zmiňovat o 100 % z nich. Rád bych však poskytl přehled těch nejčastěji používaných.
- Algoritmy učení pod dohledem
- Klasifikační algoritmy
- Naivní Bayes
- Multinomiální Naive Bayes
- Logistická regrese
- Rozhodovací stromy
- SVM (Support Vector Machine)
- Regresní algoritmy
- Lineární regrese
- Algoritmy učení bez dozoru
- Klastrování
- K-means clustering
- K-nearest neighbor
- Snížení dimenzionality
- Učení asociačních pravidel
- Učení s posilováním
- Q-Learning
- Ensemble learning
- Bagging
- Boosting
- Náhodný les
- Stacking
- Neuronové sítě
- Závěr
Algoritmy učení pod dohledem

Pokud se v pojmech jako „učení pod dohledem“ a „učení bez dohledu“ nevyznáte, přečtěte si náš příspěvek AI vs. ML, kde je toto téma podrobně popsáno. Nyní se seznámíme s algoritmy.
Klasifikační algoritmy
Naivní Bayes

Bayesovské algoritmy jsou rodinou pravděpodobnostních klasifikátorů používaných v ML na základě použití Bayesova teorému.
Naivní Bayesův klasifikátor byl jedním z prvních algoritmů používaných pro strojové učení. Je vhodný pro binární a vícetřídní klasifikaci a umožňuje provádět předpovědi a prognózy dat na základě historických výsledků. Klasickým příkladem jsou systémy filtrování spamu, které používaly Naive Bayes až do roku 2010 a vykazovaly uspokojivé výsledky. Když však byla vynalezena Bayesova otrava, začali programátoři přemýšlet o jiných způsobech filtrování dat.
Pomocí Bayesovy věty je možné říci, jak výskyt určité události ovlivňuje pravděpodobnost jiné události.
Například tento algoritmus vypočítává pravděpodobnost, že určitý e-mail je nebo není spam, na základě typických použitých slov. Běžná slova pro spam jsou „nabídka“, „objednat nyní“ nebo „dodatečný příjem“. Pokud algoritmus zjistí tato slova, existuje vysoká pravděpodobnost, že e-mail je spam.
Naive Bayes předpokládá, že funkce jsou nezávislé. Proto se algoritmus nazývá naivní.
Multinomiální Naive Bayes
Kromě klasifikátoru Naive Bayes existují v této skupině další algoritmy. Například Multinomial Naive Bayes, který se obvykle používá pro klasifikaci dokumentů na základě četnosti určitých slov přítomných v dokumentu.
Bayesovské algoritmy se stále používají pro kategorizaci textu a detekci podvodů. Lze je také použít pro strojové vidění (například detekci obličejů), segmentaci trhu a bioinformatiku.
Logistická regrese
Ačkoli se název může zdát kontraintuitivní, logistická regrese je ve skutečnosti typem klasifikačního algoritmu.
Logistická regrese je model, který provádí předpovědi pomocí logistické funkce pro nalezení závislosti mezi výstupními a vstupními proměnnými. Společnost Statquest natočila skvělé video, kde vysvětluje rozdíl mezi lineární a logistickou regresí na příkladu obézních myší.
Rozhodovací stromy
Rozhodovací strom je jednoduchý způsob vizualizace rozhodovacího modelu ve formě stromu. Výhodou rozhodovacích stromů je jejich snadné pochopení, interpretace a vizualizace. Také nevyžadují velké úsilí na přípravu dat.
Mají však také velkou nevýhodu. Stromy mohou být nestabilní kvůli i těm nejmenším odchylkám (variance) v datech. Je také možné vytvořit příliš složité stromy, které se nedají dobře zobecnit. Tomu se říká overfitting. Proti tomuto problému pomáhají bojovat metody Bagging, Boosting a regularizace. Budeme o nich hovořit později v tomto příspěvku.
Prvky každého rozhodovacího stromu jsou:
- Kořenový uzel, který klade hlavní otázku. Směřují z něj šipky dolů, ale žádné šipky k němu nesměřují. Představte si například, že sestavujete strom pro rozhodování o tom, jaký druh těstovin si dáte k večeři.
- Větve. Podsekce stromu se nazývá větev nebo někdy podstrom.
- Rozhodovací uzly. Jsou to dílčí uzly pro kořenový uzel, které se také mohou dělit na více uzlů. Vaše rozhodovací uzly mohou být „carbonara?“ nebo „s houbami?“.
- Listy nebo koncové uzly. Tyto uzly se nedělí. Představují konečná rozhodnutí nebo předpovědi.
Také je důležité zmínit rozdělení. Jedná se o proces rozdělení uzlu na dílčí uzly. Například pokud nejste vegetarián, carbonara je v pořádku. Ale pokud jste, jezte těstoviny s houbami. Existuje také proces odstraňování uzlů, který se nazývá prořezávání.
Algoritmy rozhodovacích stromů se označují jako CART (Classification and Regression Trees). Rozhodovací stromy mohou pracovat s kategorickými nebo číselnými daty.
- Regresní stromy se používají, když mají proměnné číselnou hodnotu.
- Klasifikační stromy lze použít, když jsou data kategorická (třídy).
Rozhodovací stromy jsou poměrně intuitivní na pochopení a použití. Proto se stromové diagramy běžně používají v široké škále průmyslových odvětví a oborů. GreyAtom poskytuje široký přehled různých typů rozhodovacích stromů a jejich praktických aplikací.
SVM (Support Vector Machine)
Podpůrné vektorové stroje jsou další skupinou algoritmů používaných pro klasifikační a někdy i regresní úlohy. SVM je skvělý, protože poskytuje poměrně přesné výsledky s minimálním výpočetním výkonem.
Cílem SVM je najít hyperplochu v N-rozměrném prostoru (kde N odpovídá počtu rysů), která zřetelně klasifikuje datové body. Přesnost výsledků přímo souvisí s hyperplochou, kterou zvolíme. Měli bychom najít rovinu, která má maximální vzdálenost mezi datovými body obou tříd.
Tato hyperrovina je graficky znázorněna jako přímka, která odděluje jednu třídu od druhé. Datové body, které leží na různých stranách hyperplochy, jsou přiřazeny k různým třídám.
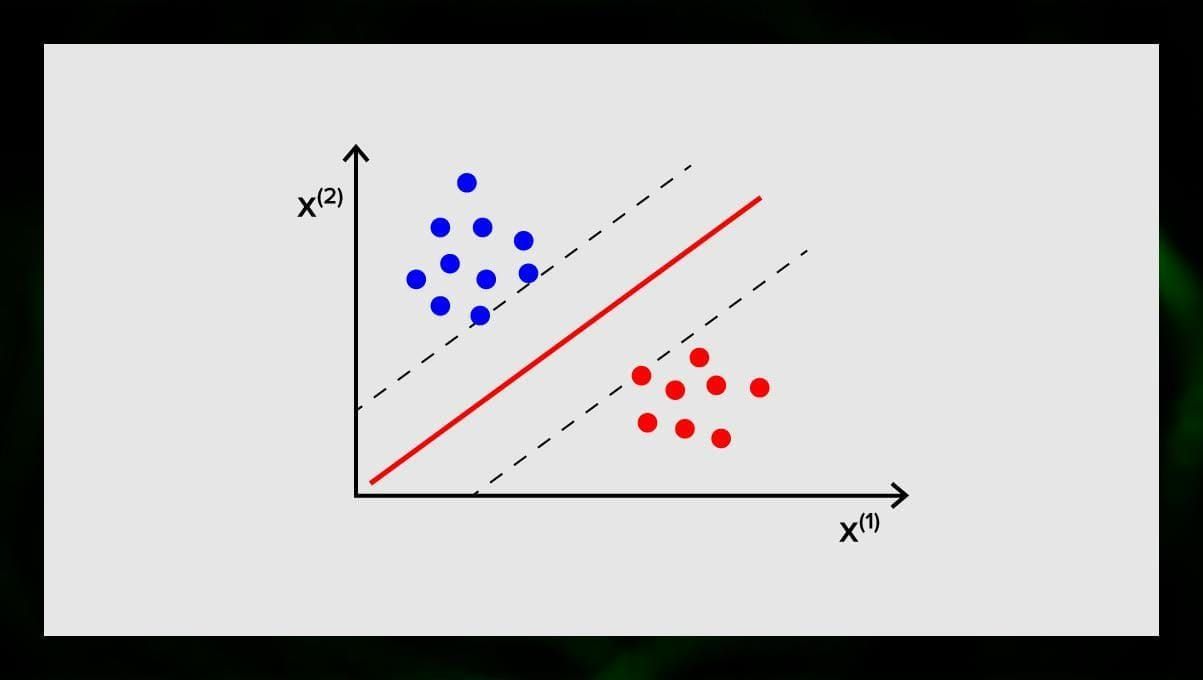
Všimněte si, že rozměr hyperplochy závisí na počtu rysů. Pokud je počet vstupních rysů 2, pak je hyperplocha pouze přímka. Pokud je počet vstupních prvků 3, pak se hyperplocha stane dvourozměrnou rovinou. Když počet rysů přesáhne 3, je obtížné nakreslit do grafu model. V tomto případě tedy použijete typy jádra, abyste jej transformovali do trojrozměrného prostoru.
Proč se tomu říká stroj s podpůrnými vektory? Podpůrné vektory jsou datové body nejblíže hyperrovině. Přímo ovlivňují polohu a orientaci hyperplochy a umožňují nám maximalizovat marži klasifikátoru. Odstraněním podpůrných vektorů se změní poloha hyperplochy. Jsou to body, které nám pomáhají sestavit SVM.
SVM se nyní aktivně používají v lékařské diagnostice k vyhledávání anomálií, v systémech kontroly kvality ovzduší, pro finanční analýzu a předpovědi na burze a pro kontrolu poruch strojů v průmyslu.
Regresní algoritmy
Regresní algoritmy jsou užitečné v analytice, například když se snažíte předpovědět náklady na cenné papíry nebo prodej určitého výrobku v určitém čase.
Lineární regrese
Lineární regrese se pokouší modelovat vztah mezi proměnnými dosazením lineární rovnice na pozorovaná data.
Existují vysvětlující a závislé proměnné. Závislé proměnné jsou věci, které chceme vysvětlit nebo předpovědět. Vysvětlující, jak vyplývá z názvu, něco vysvětlují. Pokud chcete sestavit lineární regresi, předpokládáte, že mezi závislými a nezávislými proměnnými existuje lineární vztah. Například existuje závislost mezi metry čtverečními domu a jeho cenou nebo mezi hustotou obyvatelstva a místy s kebabem v dané oblasti.
Jakmile tento předpoklad vyslovíte, musíte dále zjistit konkrétní lineární vztah. Budete muset najít rovnici lineární regrese pro soubor dat. Posledním krokem je výpočet rezidua.
Poznámka: Když regrese kreslí přímku, nazývá se lineární, když je to křivka – polynomická.
Algoritmy učení bez dozoru

Povíme si nyní o algoritmech, které jsou schopny najít skryté vzory v neoznačených datech.
Klastrování
Klastrování znamená, že vstupy rozdělujeme do skupin podle míry jejich vzájemné podobnosti. Shlukování je obvykle jedním z kroků k vytvoření složitějšího algoritmu. Je jednodušší studovat každou skupinu zvlášť a na základě jejich vlastností sestavit model, než pracovat se vším najednou. Stejná technika se neustále používá v marketingu a prodeji k rozdělení všech potenciálních klientů do skupin.
Velmi běžné shlukovací algoritmy jsou k-means clustering a k-nejbližší soused.
K-means clustering
K-means clustering rozdělí množinu prvků vektorového prostoru do předem definovaného počtu shluků k. Nesprávný počet shluků však celý proces znehodnotí, proto je důležité vyzkoušet jej s různým počtem shluků. Hlavní myšlenka algoritmu k-means spočívá v tom, že data jsou náhodně rozdělena do shluků a poté je iterativně přepočítán střed každého shluku získaný v předchozím kroku. Poté se vektory opět rozdělí do shluků. Algoritmus se zastaví, když v určitém bodě po iteraci nedojde ke změně shluků.
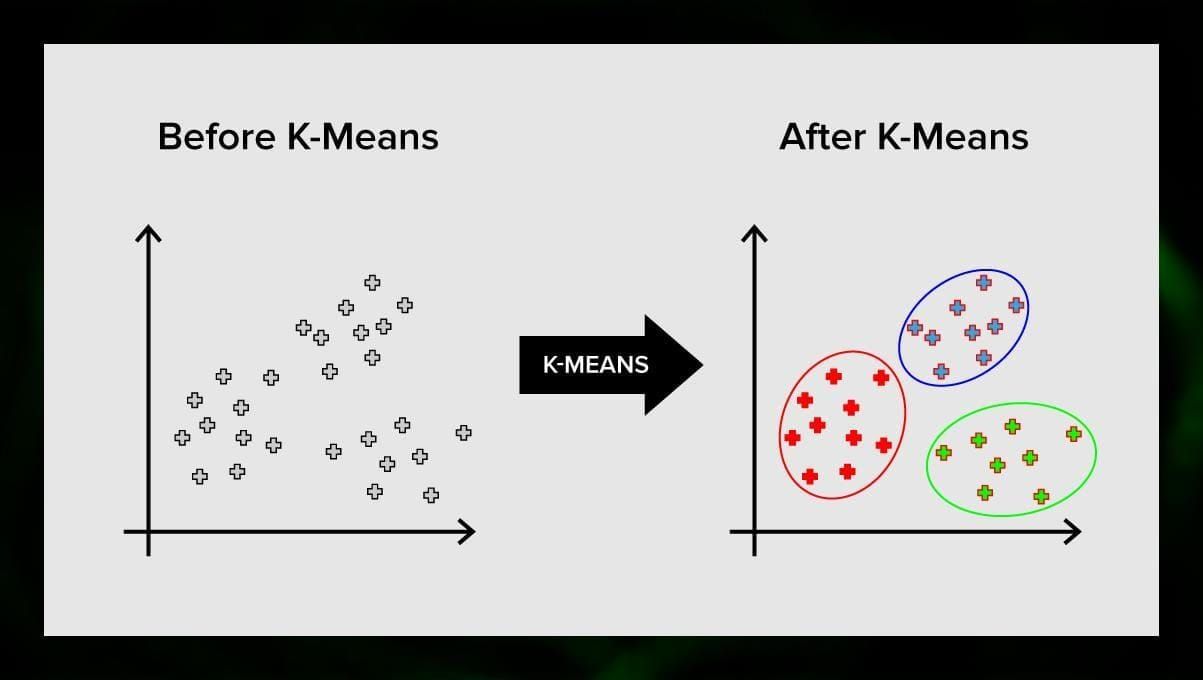
Tuto metodu lze použít k řešení problémů, kdy jsou shluky odlišné nebo je lze od sebe snadno oddělit, přičemž se data nepřekrývají.
K-nearest neighbor
kNN znamená k-nejbližší soused. Jedná se o jeden z nejjednodušších klasifikačních algoritmů, který se někdy používá v regresních úlohách.
Pro trénování klasifikátoru je třeba mít k dispozici sadu dat s předem definovanými třídami. Třídění se provádí ručně za účasti odborníků ve studované oblasti. Pomocí tohoto algoritmu je možné pracovat s více třídami nebo vyjasnit situace, kdy vstupy patří do více než jedné třídy.
Metoda vychází z předpokladu, že podobné značky odpovídají blízkým objektům v prostoru atributových vektorů.
Moderní softwarové systémy používají kNN pro vizuální rozpoznávání vzorů, například ke skenování a odhalování skrytých balíčků na dně košíku při odbavení (například AmazonGo). K-nejbližší soused se také používá v bankovnictví k odhalování vzorů při používání kreditních karet. kNN algoritmy analyzují všechna data a odhalují neobvyklé vzory, které naznačují podezřelou aktivitu.
Snížení dimenzionality
Analýza hlavních komponent (PCA) je důležitou technikou, kterou je třeba pochopit, aby bylo možné efektivně řešit problémy související s ML.
Představte si, že máte mnoho proměnných, které je třeba zvážit. Například potřebujete shlukovat města do tří skupin: dobrá pro život, špatná pro život a tak nějak. Kolik proměnných musíte vzít v úvahu? Pravděpodobně hodně. Rozumíte vztahům mezi nimi? Ani ne. Jak tedy můžete vzít všechny proměnné, které jste shromáždili, a zaměřit se pouze na několik z nich, které jsou nejdůležitější?“
Technickým termínem chcete „zmenšit rozměr prostoru příznaků“. Snížením dimenze prostoru příznaků se vám podaří získat méně vztahů mezi proměnnými, které je třeba brát v úvahu, a je méně pravděpodobné, že váš model bude příliš přizpůsobený.
Existuje mnoho způsobů, jak dosáhnout snížení dimenzionality, ale většina těchto technik spadá do jedné ze dvou tříd:
- Eliminace příznaků;
- Extrakce příznaků.
Eliminace příznaků znamená, že snížíte počet příznaků tím, že některé z nich vyřadíte. Výhodou této metody je, že je jednoduchá a zachovává interpretovatelnost vašich proměnných. Jako nevýhodu však lze označit to, že z proměnných, které jste se rozhodli vyřadit, získáte nulovou informaci.
Extrakce rysů se tomuto problému vyhýbá. Cílem při použití této metody je extrahovat sadu rysů z daného souboru dat. Extrakce rysů má za cíl snížit počet rysů v datové sadě vytvořením nových rysů na základě stávajících (a následným vyřazením původních rysů). Nová redukovaná množina rysů musí být vytvořena tak, aby byla schopna shrnout většinu informací obsažených v původní množině rysů.
Analýza hlavních komponent je algoritmus pro extrakci rysů. kombinuje vstupní proměnné určitým způsobem, a pak je možné vypustit „nejméně důležité“ proměnné a přitom zachovat nejcennější části všech proměnných.
Jedním z možných použití PCA je situace, kdy jsou obrazy v datovém souboru příliš velké. Redukovaná reprezentace příznaků pomáhá rychle řešit úlohy, jako je porovnávání a vyhledávání obrázků.
Učení asociačních pravidel
Apriori je jedním z nejpopulárnějších algoritmů pro vyhledávání asociačních pravidel. Je schopen zpracovat velké množství dat za relativně krátkou dobu.
Jde o to, že databáze mnoha projektů jsou dnes velmi rozsáhlé, dosahují gigabajtů a terabajtů. A budou se dále zvětšovat. Proto člověk potřebuje efektivní, škálovatelný algoritmus pro nalezení asociativních pravidel v krátkém čase. Jedním z těchto algoritmů je Apriori.
Aby bylo možné algoritmus použít, je nutné data připravit, převést je všechna do binární podoby a změnit jejich datovou strukturu.
Obvykle se tento algoritmus provozuje na databázi obsahující velké množství transakcí, například na databázi, která obsahuje informace o všech položkách, které zákazníci koupili v supermarketu.
Učení s posilováním

Učení s posilováním je jednou z metod strojového učení, která pomáhá naučit stroj, jak komunikovat s určitým prostředím. V tomto případě slouží prostředí (například ve videohře) jako učitel. Poskytuje zpětnou vazbu na rozhodnutí učiněná počítačem. Na základě této odměny se stroj naučí zvolit nejlepší postup. Připomíná to způsob, jakým se děti učí nedotýkat se horké pánve – zkoušením a pociťováním bolesti.
Pokud tento proces rozdělíme, zahrnuje tyto jednoduché kroky:
- Počítač pozoruje prostředí;
- Vybere nějakou strategii;
- Postupuje podle této strategie;
- Získá buď odměnu, nebo trest;
- Učí se z této zkušenosti a zdokonaluje strategii;
- Pakuje se, dokud nenajde optimální strategii.
Q-Learning
Existuje několik algoritmů, které lze použít pro Reinforcement learning. Jedním z nejběžnějších je Q-learning.
Q-learning je algoritmus posilování učení bez modelu. Q-learning je založen na odměně získané z prostředí. Agent si vytvoří funkci užitku Q, která mu následně dává možnost zvolit strategii chování a zohlednit zkušenosti z předchozích interakcí s prostředím.
Jednou z výhod Q-learningu je, že dokáže porovnávat očekávanou užitečnost dostupných akcí bez vytváření modelů prostředí.
Ensemble learning

Ensemble learning je metoda řešení problému sestavením více ML modelů a jejich kombinací. Ensemble learning se používá především ke zlepšení výkonnosti klasifikačních, predikčních a aproximačních modelů funkcí. Mezi další aplikace ansámblového učení patří kontrola rozhodnutí učiněných modelem, výběr optimálních funkcí pro sestavení modelů, inkrementální učení a nestacionární učení.
Níže jsou uvedeny některé z nejběžnějších algoritmů ansámblového učení.
Bagging
Bagging znamená bootstrap agregaci. Jedná se o jeden z prvních ansámblových algoritmů s překvapivě dobrým výkonem. K zaručení různorodosti klasifikátorů se používají bootstrapované repliky trénovacích dat. To znamená, že z trénovacího souboru dat jsou náhodně – s náhradou – vybírány různé podmnožiny trénovacích dat. Každá podmnožina trénovacích dat se použije k trénování jiného klasifikátoru stejného typu. Poté lze jednotlivé klasifikátory kombinovat. K tomu je třeba provést prosté většinové hlasování jejich rozhodnutí. Třída, kterou přiřadila většina klasifikátorů, je rozhodnutím souboru.
Boosting
Tato skupina algoritmů souboru je podobná baggingu. Boosting také používá různé klasifikátory k opakovanému vzorkování dat a poté vybírá optimální verzi většinovým hlasováním. Při boostingu se iterativně trénují slabé klasifikátory, aby se z nich sestavil silný klasifikátor. Při skládání klasifikátorů jsou jim obvykle přiřazeny určité váhy, které popisují přesnost jejich předpovědí. Po přidání slabého klasifikátoru do souboru se váhy přepočítají. Nesprávně klasifikované vstupy získají větší váhu a správně klasifikované případy váhu ztratí. Systém se tedy více soustředí na příklady, u kterých byla získána chybná klasifikace.
Náhodný les
Náhodné lesy neboli náhodné rozhodovací lesy jsou ansámblovou metodou učení pro klasifikaci, regresi a další úlohy. K sestavení náhodného lesa je třeba natrénovat množství rozhodovacích stromů na náhodných vzorcích trénovacích dat. Výstupem náhodného lesa je nejčastější výsledek mezi jednotlivými stromy. Náhodné rozhodovací lesy úspěšně bojují proti overfittingu díky _náhodné _přírodě algoritmu.
Stacking
Stacking je technika učení souboru, která kombinuje více klasifikačních nebo regresních modelů prostřednictvím meta-klasifikátoru nebo meta-regresoru. Modely základní úrovně jsou trénovány na základě kompletní trénovací množiny, poté je metamodel trénován na výstupech modelů základní úrovně jako rysy.
Neuronové sítě
Neuronová síť je sled neuronů propojených synapsemi, který připomíná strukturu lidského mozku. Lidský mozek je však ještě složitější.
Na neuronových sítích je skvělé to, že je lze použít v podstatě pro jakoukoli úlohu od filtrování spamu po počítačové vidění. Obvykle se však používají pro strojový překlad, detekci anomálií a řízení rizik, rozpoznávání řeči a generování jazyka, rozpoznávání obličejů a další.
Neuronová síť se skládá z neuronů neboli uzlů. Každý z těchto neuronů přijímá data, zpracovává je a poté je předává jinému neuronu.
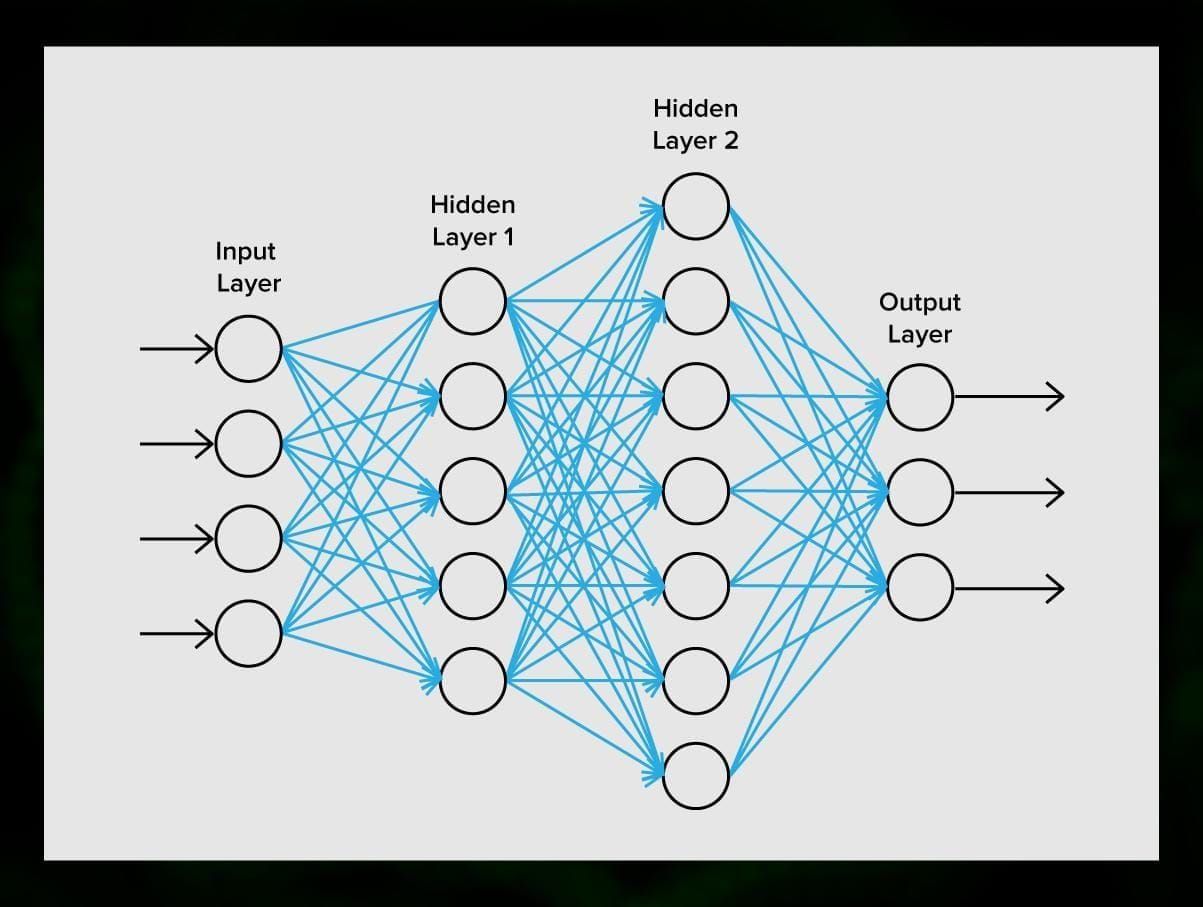
Každý neuron zpracovává signály stejným způsobem. Jak ale potom získáme jiný výsledek? Za to jsou zodpovědné synapse, které neurony vzájemně propojují. Každý neuron může mít mnoho synapsí, které signál zeslabují nebo zesilují. Také neurony jsou schopny v průběhu času měnit své vlastnosti. Volbou správných parametrů synapsí budeme schopni získat správné výsledky převodu vstupní informace na výstupu.
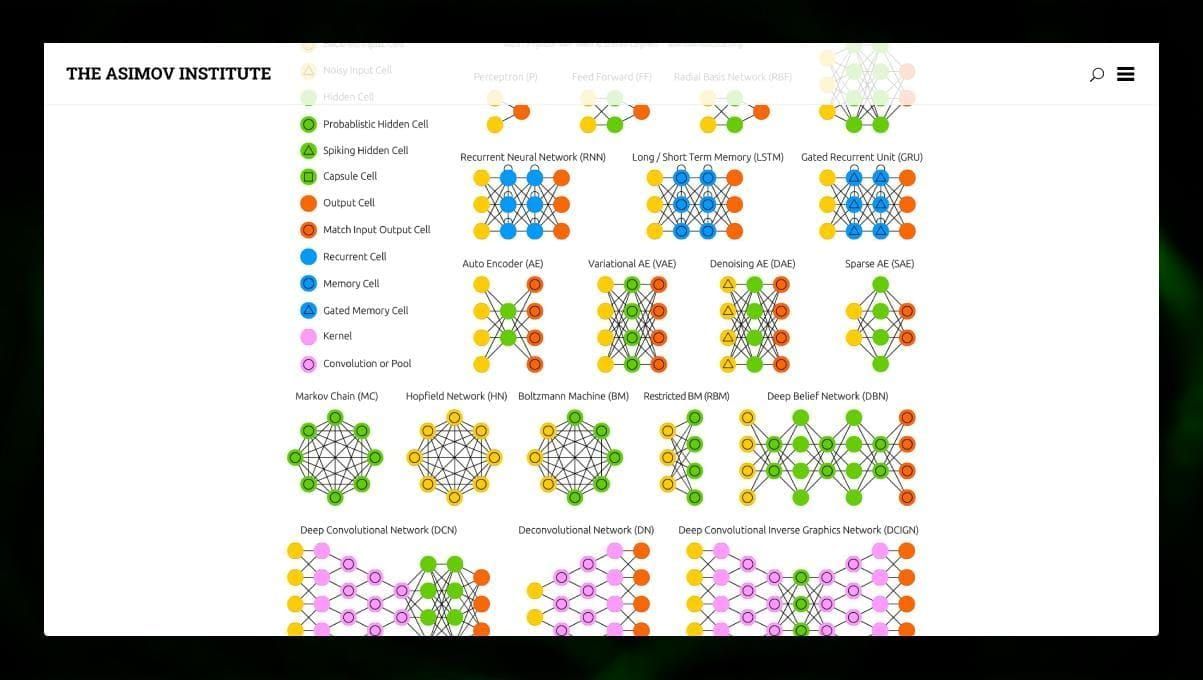
Existuje mnoho různých typů NN:
- Neuronové sítě dopředné (FF nebo FFNN) a perceptrony § jsou velmi přímočaré, v síti nejsou žádné smyčky nebo cykly. V praxi se tyto sítě používají jen zřídka, ale často se kombinují s jinými typy, aby se získaly nové.
- Hopfieldova síť (HN) je plně propojená neuronová síť se symetrickou maticí vazeb. Taková síť se často nazývá síť s asociativní pamětí. Stejně jako člověk, který vidí jednu polovinu tabulky, si dokáže představit druhou polovinu, tak i tato síť, když dostane zašuměnou tabulku, ji obnoví do plné podoby.
- Konvoluční neuronové sítě (CNN) a hluboké konvoluční neuronové sítě (DCNN) se od ostatních typů sítí velmi liší. Obvykle se používají pro úlohy související se zpracováním obrazu, zvuku nebo videa. Typickým způsobem použití CNN je klasifikace obrázků.
Zajímavé je pozorovat mnoho různých typů neuronových sítí. To je možné provést v zoologické zahradě NN.
Závěr
Tento příspěvek představuje široký přehled různých algoritmů ML, ale stále je k němu co říci. Sledujte náš Twitter, Facebook a Medium, kde najdete další průvodce a příspěvky o zajímavých možnostech strojového učení.
Napsat komentář