Människor skapar, delar och lagrar data snabbare än någonsin tidigare. När det gäller innovation när det gäller lagring och överföring av dessa data gör vi på Facebook framsteg inte bara när det gäller hårdvara – t.ex. större hårddiskar och snabbare nätverksutrustning – utan även när det gäller mjukvara. Mjukvara hjälper till med databehandling genom komprimering, som kodar information, t.ex. text, bilder och andra former av digitala data, med hjälp av färre bitar än originalet. Dessa mindre filer tar mindre plats på hårddiskarna och överförs snabbare till andra system. Det finns dock en motprestation för att komprimera och dekomprimera information: tid. Ju mer tid som går åt till att komprimera till en mindre fil, desto långsammare är det att bearbeta data.
I dag är den regerande datakomprimeringsstandarden Deflate, kärnalgoritmen i Zip, gzip och zlib . I två decennier har den gett en imponerande balans mellan snabbhet och utrymme, och som ett resultat av detta används den i nästan alla moderna elektroniska apparater (och, inte av en slump, används den för att överföra varje byte av just det blogginlägg du läser). Under årens lopp har andra algoritmer erbjudit antingen bättre komprimering eller snabbare komprimering, men sällan både och. Vi tror att vi har ändrat detta.
Vi är glada att kunna presentera Zstandard 1.0, en ny komprimeringsalgoritm och implementering som är utformad för att kunna skalas med modern hårdvara och komprimera mindre och snabbare. Zstandard kombinerar nyligen genomförda komprimeringsgenombrott, som Finite State Entropy, med en design som fokuserar på prestanda – och optimerar sedan implementationen för de unika egenskaperna hos moderna CPU:er. Resultatet är att den förbättrar de kompromisser som andra komprimeringsalgoritmer gör och har ett brett användningsområde med mycket hög dekomprimeringshastighet. Zstandard, som nu finns tillgänglig under BSD-licensen, är utformad för att kunna användas i nästan alla scenarier för förlustfri komprimering, inklusive många där nuvarande algoritmer inte är tillämpbara.
- Genom att jämföra komprimering
- Skalbarhet
- Under huven
- Historia
- Ett format som är utformat för parallell exekvering
- Branchless design
- Finite State Entropy: En nästa generations sannolikhetskompressor
- Repkodmodellering
- Zstandard i praktiken
- Små data
- Wordböcker i praktiken
- Välja en komprimeringsnivå
- Try it out
- Mer kommer att komma
Genom att jämföra komprimering
Det finns tre standardmått för att jämföra komprimeringsalgoritmer och implementeringar:
- Komprimeringsförhållande: Den ursprungliga storleken (täljare) jämfört med den komprimerade storleken (nämnare), mätt i enhetslösa data som ett storleksförhållande på 1,0 eller mer.
- Komprimeringshastighet: Hur snabbt vi kan göra data mindre, mätt i MB/s av förbrukade indata.
- Dekomprimeringshastighet: Hur snabbt vi kan rekonstruera originaldata från de komprimerade data, mätt i MB/s för hastigheten med vilken data produceras från komprimerade data.
Typen av data som komprimeras kan påverka dessa mätvärden, så många algoritmer är avstämda för specifika datatyper, till exempel engelsk text, genetiska sekvenser eller rasteriserade bilder. Zstandard, liksom zlib, är dock avsedd för allmän komprimering för en mängd olika datatyper. För att representera de algoritmer som Zstandard förväntas arbeta med kommer vi i det här inlägget att använda Silesia corpus, en datamängd med filer som representerar de typiska datatyper som används varje dag.
Några algoritmer och implementeringar som ofta används idag är zlib, lz4 och xz. Var och en av dessa algoritmer erbjuder olika kompromisser: lz4 syftar till snabbhet, xz syftar till högre kompressionsförhållanden och zlib syftar till en bra balans mellan snabbhet och storlek. Tabellen nedan visar de grova kompromisserna mellan algoritmernas standardkompressionsförhållande och hastighet för Silesia-korpusen genom att jämföra algoritmerna per lzbench, ett rent in-memory-benchmark som är tänkt att modellera algoritmens råa prestanda.
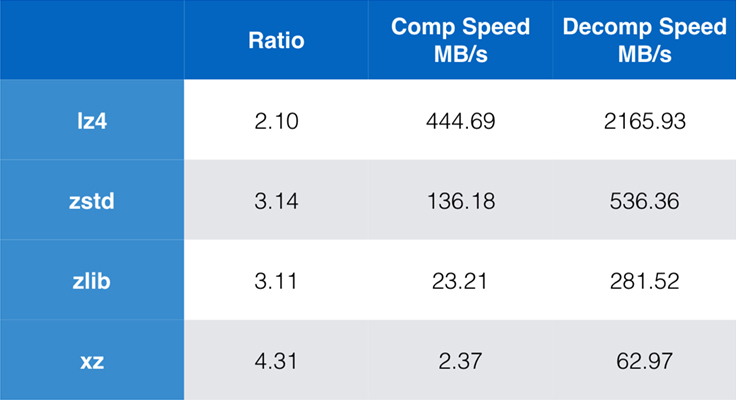
Som framgår är det ofta drastiska kompromisser mellan hastighet och storlek. Den snabbaste algoritmen, lz4, resulterar i lägre kompressionskvoter; xz, som har den högsta kompressionskvoten, lider av en långsam kompressionshastighet. Zstandard, med standardinställningen, visar dock avsevärda förbättringar i både komprimeringshastighet och dekomprimeringshastighet, samtidigt som den komprimerar med samma komprimeringsförhållande som zlib.
Som ren algoritmprestanda är viktig när komprimering är inbäddad i ett större program, är det extremt vanligt att även använda kommandoradsverktyg för komprimering – till exempel för att komprimera loggfiler, tarballs eller andra liknande data som är avsedda för lagring eller överföring. I dessa fall påverkas prestandan ofta av overhead, t.ex. kontrollsummatisering. Det här diagrammet visar en jämförelse mellan kommandoradsverktygen gzip och zstd på Centos 7 som byggts med systemets standardkompilator.
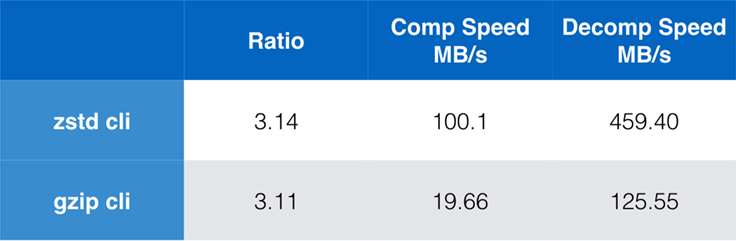
Testerna utfördes var och en 10 gånger, med minsta möjliga tider, och utfördes på ramdisk för att undvika överbelastning av filsystemet. Dessa var kommandona (som använder standardkomprimeringsnivåerna för båda verktygen):
zstd -c -3 silesia.tar > silesia.tar.zst # 67,432,740 byteszstd -d -c silesia.tar.zst > /dev/nullgzip -c -6 silesia.tar > silesia.tar.gz # 68,235,522 bytesgzip -d -c silesia.tar.gz > /dev/nullSkalbarhet
Om en algoritm är skalbar har den förmågan att anpassa sig till en mängd olika krav, och Zstandard är utformad för att utmärka sig i dagens landskap och för att kunna skalas in i framtiden. De flesta algoritmer har ”nivåer” baserade på avvägningar mellan tid och utrymme: Ju högre nivå, desto större komprimering uppnås med förlust av komprimeringshastighet. Zlib erbjuder nio komprimeringsnivåer; Zstandard erbjuder för närvarande 22, vilket möjliggör flexibla, granulära avvägningar mellan komprimeringshastighet och förhållandena för framtida data. Vi kan till exempel använda nivå 1 om hastigheten är viktigast och nivå 22 om storleken är viktigast.
Nedan visas ett diagram över den komprimeringshastighet och det kompressionsförhållande som uppnåtts för alla nivåer av Zstandard och zlib. X-axeln är en avtagande logaritmisk skala i megabyte per sekund, y-axeln är det uppnådda kompressionsförhållandet. För att jämföra algoritmerna kan du välja en hastighet för att se de olika förhållandena som algoritmerna uppnår vid den hastigheten. På samma sätt kan du välja ett förhållande och se hur snabba algoritmerna är när de uppnår den nivån.
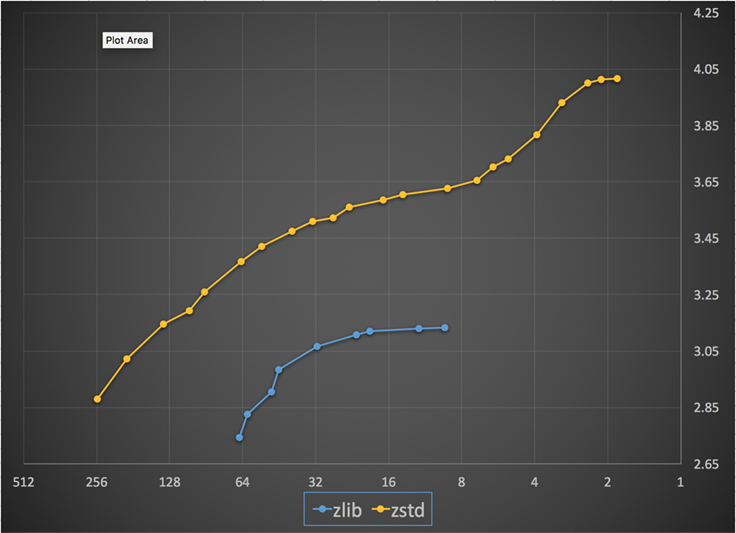
För varje vertikal linje (dvs. komprimeringshastighet) uppnår Zstandard ett högre kompressionsförhållande. För Silesia-korpusen var dekomprimeringshastigheten – oavsett kvot – ungefär 550 MB/s för Zstandard och 270 MB/s för zlib. Diagrammet visar en annan skillnad mellan Zstandard och alternativen: Genom att Zstandard använder en algoritm och ett genomförande kan man göra mycket finare inställningar för varje användningsfall. Detta innebär att Zstandard kan konkurrera med några av de snabbaste och högsta komprimeringsalgoritmerna samtidigt som den behåller en betydande fördel i fråga om dekomprimeringshastighet. Dessa förbättringar översätts direkt till snabbare dataöverföring och mindre lagringsbehov.
Med andra ord, jämfört med zlib, skalar Zstandard:
- Vid samma kompressionsförhållande komprimerar den betydligt snabbare:
- Vid samma komprimeringshastighet är den betydligt mindre: 10-15 procent mindre.
- Den är nästan 2 gånger snabbare vid dekomprimering, oavsett komprimeringsförhållande; siffrorna för kommandoradsverktyget visar en ännu större skillnad: mer än 3 gånger snabbare.
- Den skalar till mycket högre kompressionsförhållanden, samtidigt som den upprätthåller blixtsnabba dekomprimeringshastigheter.
Under huven
Zstandard förbättrar zlib genom att kombinera flera nyligen genomförda innovationer och rikta in sig på modern maskinvara:
Historia
Den är utformad så att zlib är begränsat till ett fönster på 32 KB, vilket var ett förnuftigt val i början av 90-talet. Men dagens datormiljö har tillgång till mycket mer minne – även i mobila och inbyggda miljöer.
Zstandard har ingen inneboende begränsning och kan adressera terabyte av minne (även om den sällan gör det). Till exempel använder den lägsta av de 22 nivåerna 1 MB eller mindre. För kompatibilitet med ett brett utbud av mottagarsystem, där minnet kan vara begränsat, rekommenderas att begränsa minnesanvändningen till 8 MB. Detta är dock en rekommendation för inställning, inte en begränsning av komprimeringsformatet.
Ett format som är utformat för parallell exekvering
Högre tidens CPU:er är mycket kraftfulla och kan utfärda flera instruktioner per cykel, tack vare flera ALU:er (aritmetiska logiska enheter) och en alltmer avancerad design för exekvering utanför ordningen.
I huvudsak innebär det att om:
a = b1 + b2
c = d1 + d2
då kommer både a och c att beräknas parallellt.
Detta är endast möjligt om det inte finns något samband mellan dem. I det här exemplet:
a = b1 + b2
c = d1 + a
c måste därför vänta på att a beräknas först, och först därefter kommer c beräkningen att påbörjas.
Det innebär att man, för att dra nytta av den moderna CPU:n, måste utforma ett flödet av operationer med få eller inga databeroenden.
Det här uppnås med Zstandard genom att data separeras i flera parallella strömmar. En ny generation Huffman-dekoder, Huff0, kan avkoda flera symboler parallellt med en enda kärna. En sådan vinst är kumulativ med multi-threading, som använder flera kärnor.
Branchless design
Nya CPU:er är kraftfullare och når mycket höga frekvenser, men detta är endast möjligt tack vare en flerstegsmetod, där en instruktion delas upp i en pipeline med flera steg. Vid varje klockcykel kan CPU:n utfärda resultatet av flera operationer, beroende på tillgängliga ALU:er. Ju fler ALU:er som används, desto mer arbete utför CPU:n och desto snabbare sker komprimeringen. Att hålla ALU:erna matade med arbete är avgörande för modern CPU-prestanda.
Detta visar sig vara svårt. Tänk på följande enkla situation:
if (condition) doSomething() else doSomethingElse()När den stöter på detta vet inte CPU:n vad den ska göra, eftersom den är beroende av värdet på condition. En försiktig CPU skulle vänta på resultatet av condition innan den arbetar på någon av grenarna, vilket skulle vara extremt slösaktigt.
Dagens CPU:er spelar. De gör det på ett intelligent sätt, tack vare en grenförutsägare, som i huvudsak talar om det mest sannolika resultatet av att utvärdera condition. När satsningen är riktig förblir pipeline full och instruktioner utfärdas kontinuerligt. När satsningen är felaktig (en felaktig förutsägelse) måste processorn avbryta alla operationer som påbörjats spekulativt, återvända till förgreningen och gå åt andra hållet. Detta kallas pipeline flush och är extremt kostsamt i moderna CPU:er.
För 25 år sedan var pipeline flush en icke-fråga. I dag är det så viktigt att det är nödvändigt att utforma format som är kompatibla med grenlösa algoritmer. Som exempel kan vi titta på en bitströmsuppdatering:
/* classic version */while (nbBitsUsed >= 8) { /* each while test is a branch */ accumulator <<= 8; accumulator += *byte++; nbBitsUsed -= 8;} /*>/* branch-less version */nbBytesUsed = nbBitsUsed >> 3;nbBitsUsed &= 7;ptr += nbBytesUsed;accumulator = read64(ptr);Som du kan se har den grenlösa versionen en förutsägbar arbetsbelastning, utan något villkor. CPU:n kommer alltid att göra samma arbete, och det arbetet kastas aldrig bort på grund av en felaktig förutsägelse. Den klassiska versionen gör däremot mindre arbete när (nbBitsUsed < 8). Men själva testet är inte gratis, och när testet gissas felaktigt resulterar det i en fullständig pipelineflush, vilket kostar mer än det arbete som utförs av den grenlösa versionen.
Som du kan gissa har denna bieffekt effekter på hur data packas, läses och avkodas. Zstandard har skapats för att vara vänlig mot grenlösa algoritmer, särskilt inom kritiska slingor.
Finite State Entropy: En nästa generations sannolikhetskompressor
I komprimering omvandlas data först till en uppsättning symboler (modelleringssteget), och sedan kodas dessa symboler med hjälp av ett minimalt antal bitar. Detta andra steg kallas entropisteget, till minne av Claude Shannon, som exakt beräknar komprimeringsgränsen för en uppsättning symboler med givna sannolikheter (kallad ”Shannon-gränsen”). Målet är att komma nära denna gräns och samtidigt använda så få CPU-resurser som möjligt.
En mycket vanlig algoritm är Huffman-kodning, som används i Deflate. Den ger bästa möjliga prefixkod, om man antar att varje symbol beskrivs med ett naturligt antal bitar (1 bit, 2 bitar …). Detta fungerar utmärkt i praktiken, men gränsen för naturliga tal innebär att det är omöjligt att nå höga kompressionsförhållanden, eftersom en symbol nödvändigtvis förbrukar minst 1 bit.
En bättre metod kallas aritmetisk kodning, som kan komma godtyckligt nära Shannon-gränsen -log2(P), och därmed förbruka bråkdelar av bitar per symbol. Det ger ett bättre kompressionsförhållande när sannolikheterna är höga, men det använder också mer processorkraft. I praktiken kämpar även optimerade aritmetiska kodare med hastigheten, särskilt på dekompressionssidan, som kräver divisioner med ett förutsägbart resultat (t.ex. inte ett flyttal) och som visar sig vara långsamma.
Finite State Entropy bygger på en ny teori som kallas ANS (Asymmetric Numeral System) av Jarek Duda. Finite State Entropy är en variant som förberäknar många kodningssteg i tabeller, vilket resulterar i en entropikodning som är lika exakt som aritmetisk kodning och som endast använder sig av additioner, tabellsökningar och förskjutningar, vilket är ungefär samma komplexitetsnivå som Huffman. Det minskar också väntetiden för att få tillgång till nästa symbol, eftersom den är omedelbart tillgänglig från tillståndsvärdet, medan Huffman kräver en föregående avkodning av bitströmmen. Att förklara hur den fungerar ligger utanför ramen för det här inlägget, men om du är intresserad finns det en serie artiklar som beskriver dess inre arbete.
Repkodmodellering
Repkodmodellering komprimerar effektivt strukturerade data, som har sekvenser med nästan likvärdigt innehåll, som bara skiljer sig åt med en eller ett par bytes. Denna metod är inte ny men användes först efter att Deflate publicerades, så den finns inte i zlib/gzip.
Effektiviteten hos repcode modeling beror i hög grad på vilken typ av data som komprimeras och varierar från en enkel till en tvåsiffrig komprimeringsförbättring. Dessa kombinerade förbättringar ger sammantaget en bättre och snabbare komprimeringsupplevelse som erbjuds inom Zstandard-biblioteket.
Zstandard i praktiken
Som tidigare nämnts finns det flera typiska användningsområden för komprimering. För att en algoritm ska vara övertygande måste den antingen vara utomordentligt bra på ett specifikt användningsfall, t.ex. komprimering av människoläsbar text, eller mycket bra på många olika användningsfall. Zstandard använder sig av det sistnämnda tillvägagångssättet. Ett sätt att tänka på användningsområden är hur många gånger en viss data kan dekomprimeras. Zstandard har fördelar i alla dessa fall.
Många gånger. För data som behandlas många gånger är dekomprimeringshastighet och möjligheten att välja ett mycket högt kompressionsförhållande utan att kompromissa med dekomprimeringshastigheten fördelaktigt. Lagringen av den sociala grafen på Facebook, till exempel, läses upprepade gånger när du och dina vänner interagerar med webbplatsen. Utanför Facebook är exempel på när data behöver dekomprimeras många gånger filer som laddas ner från en server, t.ex. källkoden till Linuxkärnan eller RPM som installeras på servrar, JavaScript och CSS som används på en webbsida, eller att köra tusentals MapReduces över data i ett datalager.
Enbart en gång. För data som komprimeras en enda gång, särskilt för överföring via ett nätverk, är komprimeringen ett flyktigt ögonblick i dataflödet. Ju mindre överbelastning den har på servern, desto mer kan servern hantera fler förfrågningar per sekund. Mindre överbelastning för klienten innebär att uppgifterna kan behandlas snabbare. Vanligtvis uppstår detta i klient/server-situationer där uppgifterna är unika för klienten, t.ex. ett webbserversvar som är anpassat – t.ex. de uppgifter som används för att återge när du får en anteckning från en vän på Messenger. Nettoresultatet är att din mobila enhet laddar sidor snabbare, använder mindre batteri och förbrukar mindre av din dataplan. Särskilt Zstandard passar mobilscenarierna mycket bättre än andra algoritmer på grund av hur den hanterar små data.
Möjligen aldrig. Även om det verkar kontraintuitivt är det ofta så att en datamängd – t.ex. säkerhetskopior eller loggfiler – aldrig kommer att dekomprimeras men kan läsas vid behov. För denna typ av data måste komprimeringen vanligtvis vara snabb, göra datan liten (med en tid/utrymme-avvägning som är lämplig för situationen) och kanske lagra en kontrollsumma, men i övrigt vara osynlig. Vid det sällsynta tillfället att data behöver dekomprimeras vill man inte att komprimeringen ska sakta ner det operativa användningsfallet. Snabb dekomprimering är fördelaktigt eftersom det ofta är en liten del av data (t.ex. en specifik fil i säkerhetskopian eller ett meddelande i en loggfil) som behöver hittas snabbt.
I alla dessa fall ger Zstandard möjlighet att komprimera och dekomprimera många gånger snabbare än gzip, och de resulterande komprimerade data är mindre.
Små data
Det finns ett annat användningsområde för komprimering som får mindre uppmärksamhet, men som kan vara ganska viktigt: små data. Detta är användningsmönster där data produceras och konsumeras i små mängder, t.ex. JSON-meddelanden mellan en webbserver och en webbläsare (vanligtvis hundratals byte) eller sidor med data i en databas (några kilobyte).
Databaser är ett intressant användningsområde. System som MySQL, PostgreSQL och MongoDB lagrar alla data som är avsedda för åtkomst i realtid. De senaste hårdvarufördelarna, särskilt när det gäller spridningen av flash-enheter (SSD-enheter), har i grunden förändrat balansen mellan storlek och genomströmning – vi lever nu i en värld där IOP:er (IO-operationer per sekund) är ganska höga, men kapaciteten hos våra lagringsenheter är lägre än när hårddiskar styrde datacentret.
Flash har dessutom en intressant egenskap när det gäller skrivtålighet – efter tusentals skrivningar till samma sektion av enheten kan den sektionen inte längre acceptera skrivningar, vilket ofta leder till att enheten tas ur bruk. Därför är det naturligt att söka efter sätt att minska mängden data som skrivs eftersom det kan innebära mer data per server och att enheten bränns ut i långsammare takt. Datakomprimering är en strategi för detta, och databaser är också ofta optimerade för prestanda, vilket innebär att läs- och skrivprestanda är lika viktiga.
Det finns dock en komplikation för att använda datakomprimering med databaser. Databaser gillar att få slumpmässig åtkomst till data, medan de flesta typiska användningsfall för komprimering läser en hel fil i linjär ordning. Detta är ett problem eftersom datakomprimering i huvudsak fungerar genom att förutsäga framtiden utifrån det förflutna – algoritmerna tittar på dina data sekventiellt och förutsäger vad de kan se i framtiden. Ju mer exakta förutsägelserna är, desto mindre kan datan göras.
När du komprimerar små data, t.ex. sidor i en databas eller små JSON-dokument som skickas till din mobila enhet, finns det helt enkelt inte mycket ”förflutet” att använda för att förutsäga framtiden. Komprimeringsalgoritmer har försökt lösa detta genom att använda fördelade ordböcker för att effektivt starta upp. Detta görs genom att man i förväg delar en statisk uppsättning ”tidigare” data som ett frö för komprimeringen.
Zstandard bygger på detta tillvägagångssätt med högoptimerade algoritmer och API:er för komprimering av ordböcker. Dessutom innehåller Zstandard verktyg (zstd --train) för att enkelt göra ordböcker för anpassade tillämpningar och bestämmelser för att registrera standardordböcker för att dela dem med större grupper. Även om komprimeringen varierar beroende på dataproverna kan komprimeringen av små data vara allt från 2x till 5x bättre än komprimering utan ordböcker.
Wordböcker i praktiken
Som det kan vara svårt att leka med en ordbok i samband med en löpande databas (det kräver trots allt betydande ändringar i databasen), kan du se ordböcker i praktiken med andra typer av små data. JSON, den moderna världens lingua franca för små data, tenderar att vara små, repetitiva poster. Det finns otaliga offentliga datamängder tillgängliga; för den här demonstrationen kommer vi att använda datamängden ”user” från GitHub, som är tillgänglig via HTTP. Här är en exempelpost från denna datamängd:
{ "login": "octocat", "id": 1, "avatar_url": "https://github.com/images/error/octocat_happy.gif", "gravatar_id": "", "url": "https://api.github.com/users/octocat", "html_url": "https://github.com/octocat", "followers_url": "https://api.github.com/users/octocat/followers", "following_url": "https://api.github.com/users/octocat/following{/other_user}", "gists_url": "https://api.github.com/users/octocat/gists{/gist_id}", "starred_url": "https://api.github.com/users/octocat/starred{/owner}{/repo}", "subscriptions_url": "https://api.github.com/users/octocat/subscriptions", "organizations_url": "https://api.github.com/users/octocat/orgs", "repos_url": "https://api.github.com/users/octocat/repos", "events_url": "https://api.github.com/users/octocat/events{/privacy}", "received_events_url": "https://api.github.com/users/octocat/received_events", "type": "User", "site_admin": false }Som du kan se finns det en hel del upprepningar här – vi kan komprimera dessa fint! Men varje användare är lite mindre än 1 KB, och de flesta komprimeringsalgoritmer behöver verkligen mer data för att kunna sträcka på benen. En uppsättning med 1 000 användare tar ungefär 850 KB att lagra okomprimerat. Att naivt tillämpa antingen gzip eller zstd individuellt på varje fil minskar detta till drygt 300 KB; inte illa! Men om vi skapar en engångsordbok med zstd som är för-delad, sjunker storleken till 122 KB – vilket innebär att det ursprungliga komprimeringsförhållandet går från 2,8x till 6,9. Detta är en betydande förbättring, som är tillgänglig out-of-box med zstd:
$ zstd --train -o ../json.zdict -r .sorting 982 files of total size 0 MB ...finding patterns ...statistics ...Save dictionary of size 65599 into file ../json.zdict$ du -h --apparent-size .846K .$ zstd --rm -D ../json.zdict -r .$ du -h --apparent-size .122K .Välja en komprimeringsnivå
Som framgår ovan tillhandahåller Zstandard ett betydande antal nivåer. Denna anpassning är kraftfull men leder till svåra val. Det bästa sättet att bestämma är att granska dina data och mäta och bestämma vilka kompromisser du vill göra. På Facebook anser vi att standardnivån 3 är lämplig för många användningsfall, men från tid till annan justerar vi den något beroende på vad vår flaskhals är (ofta försöker vi mätta en nätverksanslutning eller en diskspindel); andra gånger bryr vi oss mer om den lagrade storleken och använder då en högre nivå.
För att få de resultat som är mest skräddarsydda för dina behov måste du slutligen ta hänsyn till både den maskinvara du använder och de data du bryr dig om – det finns inga hårda och snabba föreskrifter som kan göras utan sammanhang. När du är tveksam bör du dock antingen hålla dig till standardnivån 3 eller något i intervallet 6 till 9 för att få en bra kompromiss mellan hastighet och utrymme; spara nivå 20+ för fall där du verkligen bara bryr dig om storleken och inte om komprimeringshastigheten.
Try it out
Zstandard är både ett kommandoradsverktyg (zstd) och ett bibliotek. Det är skrivet i mycket portabel C, vilket gör det lämpligt för praktiskt taget alla plattformar som används idag – oavsett om det är servrarna som driver ditt företag, din bärbara dator eller till och med telefonen i din ficka. Du kan hämta det från vårt github-förråd, kompilera det med ett enkelt make install och börja använda det som du skulle använda gzip:
$ zstd access.logaccess.log : 8.07% (6695078 => 540336 bytes, access.log.zst)Som du kanske förväntar dig kan du använda det som en del av en kommandopipeline, till exempel för att säkerhetskopiera din kritiska MySQL-databas:
$ mysqldump --single-transaction --opt pokemon | zstd -q -o /srv/backups/mysqldump.sql.zstKommandot tar har stöd för olika komprimeringsimplementationer out-of-box, så när du väl har installerat Zstandard kan du genast arbeta med tarbullar komprimerade med Zstandard. Här är ett enkelt exempel som visar hur det används med tar och hastighetsskillnaden jämfört med gzip:
$ time tar -I zstd -cf linux-4.6.4.tar.zst linux-4.6.4tar -I zstd -cf linux-4.6.4.tar.zst linux-4.6.4 3.15s user 0.50s system 107% cpu 3.396 total$ time tar -zcf linux-4.6.4.tar.gz linux-4.6.4tar -zcf linux-4.6.4.tar.gz linux-4.6.4 13.74s user 0.43s system 102% cpu 13.784 totalBortom kommandoradsanvändning finns API:erna, som är dokumenterade i headerfilerna i repositoriet (börja här för en översikt över API:erna). Vi inkluderar också ett zlib-kompatibelt wrapper-API (libWrapper) för enklare integration med verktyg som redan har zlib-gränssnitt. Slutligen inkluderar vi ett antal exempel, både på grundläggande användning och på mer avancerad användning som t.ex. ordböcker och streaming, som också finns i GitHub-repositoriet.
Mer kommer att komma
Men även om vi har nått 1.0 och anser att Zstandard är redo för alla typer av produktionsanvändning är vi inte färdiga. Kommer i framtida versioner:
- Multitrådad komprimering på kommandoraden för ännu snabbare genomströmning på stora datamängder, i likhet med pigz-verktyget för zlib.
- Nya komprimeringsnivåer, i båda riktningarna, vilket möjliggör ännu snabbare komprimering och högre komprimeringsgrad.
- En gemenskapsunderhållen fördefinierad uppsättning kompressionsordböcker för vanliga datamängder som JSON, HTML och vanliga nätverksprotokoll.
Vi vill tacka alla bidragsgivare, både av kod och feedback, som hjälpt oss att nå fram till 1.0. Detta är bara början. Vi vet att för att Zstandard ska kunna leva upp till sin potential behöver vi din hjälp. Som nämnts ovan kan du prova Zstandard idag genom att hämta källkoden eller förbyggda binärer från vårt GitHub-projekt, eller, för Mac-användare, installera via homebrew (brew install zstd). Vi vill gärna ha feedback och intressanta användningsfall som du har, liksom ytterligare språkbindningar och hjälp med att integrera det med dina favoritprojekt med öppen källkod.
Fotnoter
- Men även om förlustfri datakomprimering är fokus för det här inlägget, finns det ett relaterat men mycket annorlunda område för förlustfylld datakomprimering, som främst används för bilder, ljud och video.
- Deflate, zlib, gzip – tre namn som är sammanflätade. Deflate är den algoritm som används av zlib- och gzip-implementationerna. Zlib är ett bibliotek som tillhandahåller Deflate, och gzip är ett kommandoradsverktyg som använder zlib för deflatering av data samt kontrollsummatisering. Denna kontrollsummatisering kan ha betydande overhead.
- Alla riktmärken utfördes på en Intel E5-2678 v3 som körs på 2,5 GHz på en Centos 7-maskin. Kommandoradsverktygen (
zstdochgzip) byggdes med systemet GCC, 4.8.5. Algoritmbänkmärken som utfördes av lzbench byggdes med GCC 6.
.
Lämna ett svar