I det här inlägget ska vi ta en titt på de mest använda algoritmerna för maskininlärning. Det finns ett enormt utbud av dem och det är lätt att känna sig förvirrad när man hör termer som ”instansbaserade inlärningsalgoritmer” och ”perceptron”.
I vanliga fall delas alla maskininlärningsalgoritmer in i grupper baserat på antingen deras inlärningsstil, funktion eller de problem som de löser. I det här inlägget hittar du en klassificering baserad på inlärningsstil. Jag kommer också att nämna de vanligaste uppgifterna som dessa algoritmer hjälper till att lösa.
Antalet maskininlärningsalgoritmer som används idag är stort och jag kommer inte att nämna 100 % av dem. Jag vill dock ge en översikt över de vanligaste.
- Supervised learning algorithms
- Klassificeringsalgoritmer
- Naive Bayes
- Multinomial Naive Bayes
- Logistisk regression
- Beslutsträd
- SVM (Support Vector Machine)
- Regressionsalgoritmer
- Linjär regression
- Osuperviserade inlärningsalgoritmer
- Clustering
- K-means klustring
- K-nearest neighbor
- Dimensionalitetsreducering
- Associeringsregelinlärning
- Reinforcement learning
- Q-Learning
- Ensemble learning
- Bagging
- Boosting
- Randomskog
- Stacking
- Neurala nätverk
- Slutsats
Supervised learning algorithms

Om du inte är bekant med termer som ”supervised learning” och ”unsupervised learning”, kan du kolla in vårt inlägg om AI vs. ML där det här ämnet behandlas i detalj. Nu ska vi bekanta oss med algoritmerna.
Klassificeringsalgoritmer
Naive Bayes

Bayesianska algoritmer är en familj av sannolikhetsklassificerare som används inom ML och som bygger på tillämpning av Bayes’ teorem.
Naive Bayes klassificerare var en av de första algoritmerna som användes för maskininlärning. Den lämpar sig för binär och flerklassig klassificering och gör det möjligt att göra förutsägelser och prognoser av data baserat på historiska resultat. Ett klassiskt exempel är skräppostfiltreringssystem som använde Naive Bayes fram till 2010 och visade tillfredsställande resultat. Men när Bayes’ gifter uppfanns började programmerare tänka på andra sätt att filtrera data.
Med hjälp av Bayes’ teorem är det möjligt att säga hur förekomsten av en händelse påverkar sannolikheten för en annan händelse.
Den här algoritmen beräknar till exempel sannolikheten för att ett visst e-postmeddelande är eller inte är skräppost baserat på de typiska ord som används. Vanliga skräppostord är ”erbjudande”, ”beställ nu” eller ”extra inkomst”. Om algoritmen upptäcker dessa ord finns det en hög sannolikhet att e-postmeddelandet är skräppost.
Naive Bayes förutsätter att funktionerna är oberoende. Därför kallas algoritmen naiv.
Multinomial Naive Bayes
Avseende Naive Bayes klassificerare finns det andra algoritmer i denna grupp. Till exempel Multinomial Naive Bayes, som vanligtvis används för dokumentklassificering baserat på frekvensen av vissa ord som finns i dokumentet.
Bayesianska algoritmer används fortfarande för kategorisering av text och upptäckt av bedrägerier. De kan också tillämpas för maskinseende (till exempel ansiktsdetektering), marknadssegmentering och bioinformatik.
Logistisk regression
Även om namnet kan verka kontraintuitivt är logistisk regression faktiskt en typ av klassificeringsalgoritm.
Logistisk regression är en modell som gör förutsägelser med hjälp av en logistisk funktion för att hitta beroendet mellan utdata- och inputvariabler. Statquest har gjort en bra video där de förklarar skillnaden mellan linjär och logistisk regression med överviktiga möss som exempel.
Beslutsträd
Ett beslutsträd är ett enkelt sätt att visualisera en beslutsmodell i form av ett träd. Fördelarna med beslutsträd är att de är lätta att förstå, tolka och visualisera. Dessutom kräver de liten insats för dataförberedelse.
Hursomhelst har de också en stor nackdel. Träden kan bli instabila på grund av även de minsta variationer (varians) i data. Det är också möjligt att skapa alltför komplexa träd som inte generaliserar bra. Detta kallas överanpassning. Bagging, boosting och regularisering hjälper till att bekämpa detta problem. Vi kommer att prata om dem senare i inlägget.
Elementen i varje beslutsträd är:
- Root node som ställer huvudfrågan. Den har pilarna som pekar ner från den men inga pilar som pekar till den. Tänk dig till exempel att du bygger ett träd för att bestämma vilken sorts pasta du ska ha till middag.
- Brancher. En del av ett träd kallas för en gren eller ibland för ett underträd.
- Beslutningsnoder. Detta är undernoder till rotnoden som också kan delas upp i fler noder. Dina beslutsnoder kan vara ”carbonara?” eller ”med svamp?”.
- Blad eller terminalnoder. Dessa noder delas inte. De representerar slutliga beslut eller förutsägelser.
Det är också viktigt att nämna delning. Detta är processen att dela upp en nod i undernoder. Om du till exempel inte är vegetarian är carbonara okej. Men om du är det ska du äta pasta med svamp. Det finns också en process för att ta bort noder som kallas beskärning.
Det finns algoritmer för beslutsträd som kallas CART (Classification and Regression Trees). Beslutsträd kan arbeta med kategoriska eller numeriska data.
- Regressionsträd används när variablerna har numeriska värden.
- Klassificeringsträd kan tillämpas när data är kategoriska (klasser).
Det är ganska intuitivt att förstå och använda beslutsträd. Det är därför som träddiagram är vanligt förekommande inom ett brett spektrum av branscher och discipliner. GreyAtom ger en bred översikt över olika typer av beslutsträd och deras praktiska tillämpningar.
SVM (Support Vector Machine)
Stödvektormaskiner är en annan grupp algoritmer som används för klassificering och, ibland, regressionsuppgifter. SVM är bra eftersom den ger ganska exakta resultat med minimal beräkningskraft.
Målet med SVM är att hitta ett hyperplan i ett N-dimensionellt utrymme (där N motsvarar antalet funktioner) som tydligt klassificerar datapunkterna. Resultatens noggrannhet korrelerar direkt med den hyperplan som vi väljer. Vi bör hitta ett plan som har det största avståndet mellan datapunkter i båda klasserna.
Detta hyperplan representeras grafiskt som en linje som skiljer en klass från en annan. Datapunkter som faller på olika sidor av hyperplanet tillskrivs olika klasser.
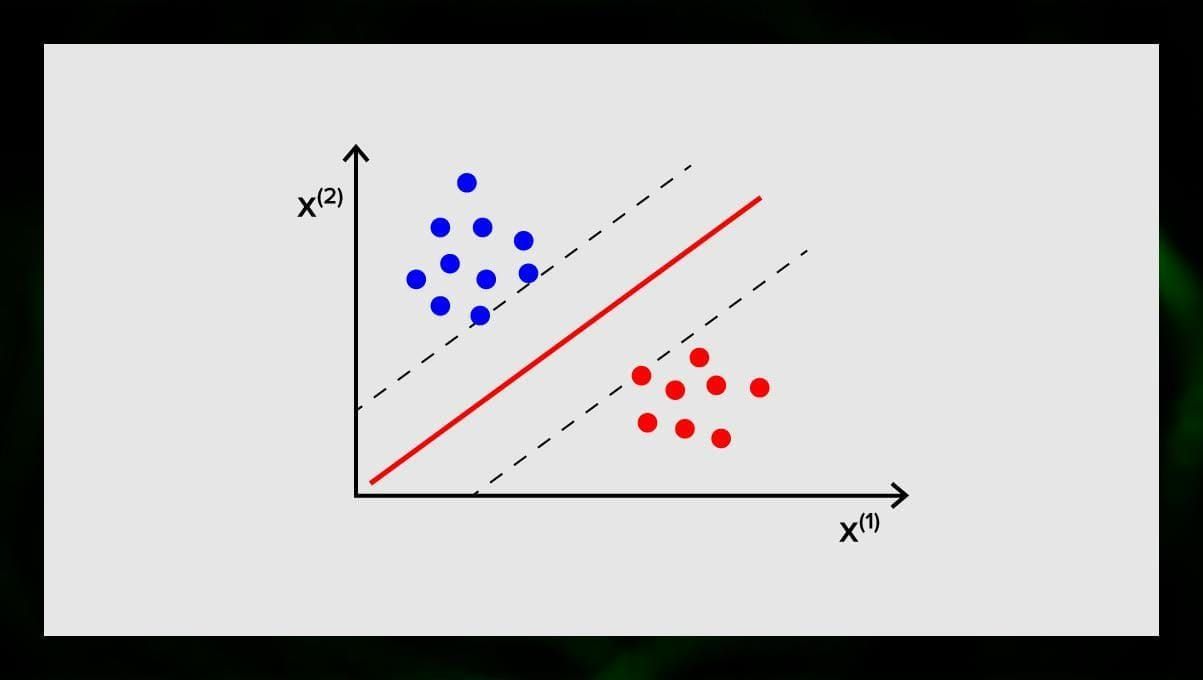
Bemärk att hyperplanets dimension beror på antalet funktioner. Om antalet inmatningsfunktioner är 2 är hyperplanet bara en linje. Om antalet ingående funktioner är 3 blir hyperplanet ett tvådimensionellt plan. Det blir svårt att rita upp en modell på en graf när antalet funktioner överstiger 3. Så i det här fallet kommer du att använda kärntyper för att omvandla den till ett 3-dimensionellt utrymme.
Varför kallas detta för en stödvektormaskin? Stödvektorer är datapunkter som ligger närmast hyperplanet. De påverkar direkt hyperplanets position och orientering och gör att vi kan maximera marginalen för klassificeraren. Om stödvektorerna raderas kommer hyperplanets position att ändras. Det är dessa punkter som hjälper oss att bygga vår SVM.
SVM används nu aktivt inom medicinsk diagnostik för att hitta anomalier, i system för kontroll av luftkvalitet, för finansiell analys och förutsägelser på aktiemarknaden och för felkontroll av maskiner inom industrin.
Regressionsalgoritmer
Regressionsalgoritmer är användbara inom analys, till exempel när man försöker förutsäga kostnaderna för värdepapper eller försäljningen av en viss produkt vid en viss tidpunkt.
Linjär regression
Linjär regression försöker modellera förhållandet mellan variabler genom att anpassa en linjär ekvation till de observerade uppgifterna.
Det finns förklarande och beroende variabler. Beroende variabler är saker som vi vill förklara eller förutsäga. De förklarande, som det följer av namnet, förklarar något. Om du vill bygga en linjär regression antar du att det finns ett linjärt samband mellan dina beroende och oberoende variabler. Det finns till exempel ett samband mellan kvadratmeterna på ett hus och dess pris eller tätheten av befolkning och kebabställen i området.
När du har gjort detta antagande måste du härnäst räkna ut det specifika linjära sambandet. Du måste hitta en linjär regressionsekvation för en uppsättning data. Det sista steget är att beräkna restvärdet.
Notera: När regressionen drar en rak linje kallas den linjär, när den är en kurva – polynomial.
Osuperviserade inlärningsalgoritmer

Nu ska vi prata om algoritmer som kan hitta dolda mönster i omärkta data.
Clustering
Clustering innebär att vi delar upp indata i grupper enligt graden av deras likhet med varandra. Klusterbildning är vanligtvis ett av stegen för att bygga en mer komplex algoritm. Det är enklare att studera varje grupp för sig och bygga en modell utifrån deras egenskaper, än att arbeta med allt på en gång. Samma teknik används ständigt inom marknadsföring och försäljning för att dela in alla potentiella kunder i grupper.
Väldigt vanliga klusteralgoritmer är k-means clustering och k-nearest neighbor.
K-means klustring
K-means klustring delar upp mängden element i vektorrummet i ett fördefinierat antal kluster k. Ett felaktigt antal kluster ogiltigförklarar dock hela processen, så det är viktigt att prova med varierande antal kluster. Huvudidén med k-means-algoritmen är att data slumpmässigt delas in i kluster, och efter det beräknas centrum för varje kluster som erhållits i det föregående steget iterativt på nytt. Därefter delas vektorerna in i kluster igen. Algoritmen stannar när det vid en viss punkt inte sker någon förändring av kluster efter en iteration.
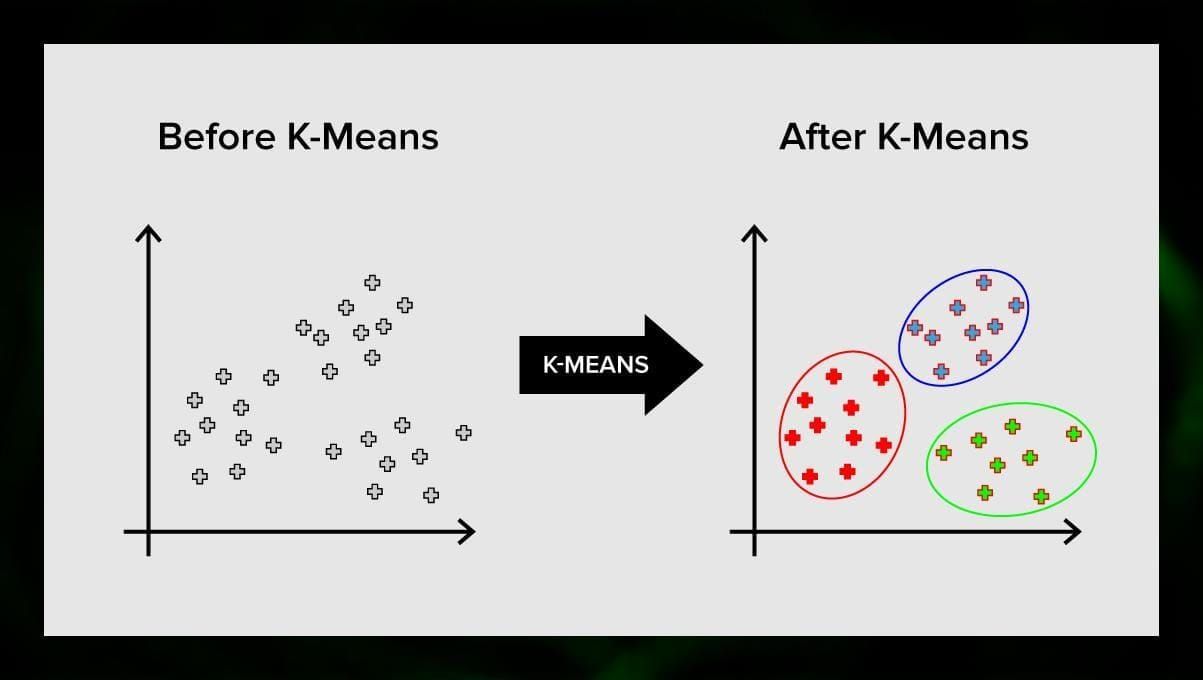
Denna metod kan tillämpas för att lösa problem när kluster är distinkta eller lätt kan separeras från varandra utan att data överlappar varandra.
K-nearest neighbor
kNN står för k-nearest neighbor. Detta är en av de enklaste klassificeringsalgoritmerna som ibland används i regressionsuppgifter.
För att träna klassificeraren måste du ha en uppsättning data med fördefinierade klasser. Markeringen görs manuellt med hjälp av specialister inom det studerade området. Med hjälp av denna algoritm är det möjligt att arbeta med flera klasser eller reda ut situationer där indata tillhör mer än en klass.
Metoden bygger på antagandet att liknande etiketter motsvarar nära objekt i attributvektorrummet.
Moderna mjukvarusystem använder kNN för visuell mönsterigenkänning, t.ex. för att skanna och upptäcka dolda paket längst ner i vagnen vid utcheckning (t.ex. AmazonGo). K-nearest neighbor används också inom bankväsendet för att upptäcka mönster i kreditkortsanvändning. kNN-algoritmer analyserar alla data och upptäcker ovanliga mönster som tyder på misstänkt aktivitet.
Dimensionalitetsreducering
Principal component analysis (PCA) är en viktig teknik att förstå för att effektivt kunna lösa ML-relaterade problem.
Föreställ dig att du har en massa variabler att ta hänsyn till. Du måste till exempel gruppera städer i tre grupper: bra att bo i, dåligt att bo i och så där. Hur många variabler måste du ta hänsyn till? Förmodligen en hel del. Förstår du sambanden mellan dem? Inte riktigt. Så hur kan du ta alla variabler som du har samlat in och fokusera på endast ett fåtal av dem som är viktigast?
I tekniska termer vill du ”minska dimensionen i ditt funktionsutrymme”. Genom att minska dimensionen på ditt feature space lyckas du få färre relationer mellan variabler att ta hänsyn till och du är mindre benägen att överanpassa din modell.
Det finns många sätt att uppnå dimensionalitetsreduktion, men de flesta av dessa tekniker faller in i en av två klasser:
- Feature Elimination;
- Feature Extraction.
Feature elimination innebär att du reducerar antalet features genom att eliminera några av dem. Fördelarna med denna metod är att den är enkel och att den bibehåller tolkningsbarheten hos dina variabler. Som nackdel kan dock nämnas att du får noll information från de variabler som du har bestämt dig för att ta bort.
Feature extraction undviker detta problem. Målet när man tillämpar denna metod är att extrahera en uppsättning egenskaper från det givna datasetet. Feature Extraction syftar till att minska antalet funktioner i en datamängd genom att skapa nya funktioner baserat på de befintliga (och sedan kasta de ursprungliga funktionerna). Den nya reducerade uppsättningen funktioner måste skapas på ett sätt som gör att den kan sammanfatta den mesta av den information som finns i den ursprungliga uppsättningen funktioner.
Principal Component Analysis är en algoritm för utvinning av funktioner. den kombinerar inmatningsvariablerna på ett visst sätt, och sedan är det möjligt att släppa de ”minst viktiga” variablerna samtidigt som man behåller de mest värdefulla delarna av alla variablerna.
En av de möjliga användningsområdena för PCA är när bilderna i dataseten är för stora. En reducerad funktionsrepresentation hjälper till att snabbt hantera uppgifter som bildmatchning och återvinning.
Associeringsregelinlärning
Apriori är en av de mest populära sökalgoritmerna för associeringsregler. Den kan bearbeta stora mängder data på relativt kort tid.
Saken är den att databaser i många projekt i dag är mycket stora, upp till gigabyte och terabyte. Och de kommer att fortsätta att växa. Därför behöver man en effektiv, skalbar algoritm för att hitta associativa regler på kort tid. Apriori är en av dessa algoritmer.
För att kunna tillämpa algoritmen är det nödvändigt att förbereda data, konvertera allt till binär form och ändra dess datastruktur.
I vanliga fall tillämpar man den här algoritmen på en databas som innehåller ett stort antal transaktioner, t.ex. på en databas som innehåller information om alla varor som kunderna har köpt i en stormarknad.
Reinforcement learning

Reinforcement learning är en av metoderna för maskininlärning som hjälper till att lära maskinen hur den ska interagera med en viss miljö. I det här fallet fungerar miljön (till exempel i ett videospel) som lärare. Den ger återkoppling till de beslut som datorn fattar. På grundval av denna belöning lär sig maskinen att vidta den bästa åtgärden. Det påminner om hur barn lär sig att inte röra en het stekpanna – genom att pröva och känna smärta.
Om man bryter ner denna process innebär den dessa enkla steg:
- Datorn observerar omgivningen;
- Väljer en viss strategi;
- Handlar i enlighet med denna strategi;
- Får antingen en belöning eller ett straff;
- Lär sig av denna erfarenhet och förfinar strategin;
- Upprepas tills den optimala strategin har hittats.
Q-Learning
Det finns ett par algoritmer som kan användas för Reinforcement Learning. En av de vanligaste är Q-learning.
Q-learning är en modellfri algoritm för förstärkningsinlärning. Q-learning bygger på den ersättning som erhålls från omgivningen. Agenten bildar en nyttofunktion Q, som därefter ger den en möjlighet att välja en beteendestrategi och ta hänsyn till erfarenheterna från tidigare interaktioner med miljön.
En av fördelarna med Q-learning är att den kan jämföra den förväntade nyttan av de tillgängliga åtgärderna utan att bilda miljömodeller.
Ensemble learning

Ensemble learning är en metod för att lösa ett problem genom att bygga flera ML-modeller och kombinera dem. Ensembleinlärning används främst för att förbättra prestandan hos modeller för klassificering, prediktion och funktionsapproximation. Andra tillämpningar av ensembleinlärning är att kontrollera det beslut som fattas av modellen, välja optimala funktioner för att bygga modeller, inkrementell inlärning och icke-stationär inlärning.
Nedan följer några av de vanligaste ensembleinlärningsalgoritmerna.
Bagging
Bagging står för bootstrap aggregering. Det är en av de tidigaste ensemblealgoritmerna med förvånansvärt bra prestanda. För att garantera mångfalden av klassificerare använder man bootstrappade kopior av träningsdata. Det innebär att olika delmängder av träningsdata dras slumpmässigt – med ersättning – från träningsdatamängden. Varje delmängd träningsdata används för att träna en annan klassificerare av samma typ. Därefter kan enskilda klassificerare kombineras. För att göra detta måste man ta en enkel majoritetsomröstning av deras beslut. Den klass som tilldelades av majoriteten av klassificerarna är ensemblebeslutet.
Boosting
Denna grupp av ensemblealgoritmer liknar bagging. Boosting använder också en mängd olika klassificerare för att göra ett nytt urval av data och väljer sedan den optimala versionen genom majoritetsomröstning. Vid boosting tränar man iterativt svaga klassificerare för att sätta ihop dem till en stark klassificerare. När klassificerarna läggs till brukar de tillskrivas vissa vikter, som beskriver noggrannheten i deras förutsägelser. När en svag klassificerare läggs till i ensemblen beräknas vikterna på nytt. Felaktigt klassificerade ingångar får mer vikt och korrekt klassificerade instanser förlorar vikt. På så sätt fokuserar systemet mer på exempel där en felaktig klassificering erhållits.
Randomskog
Randomskogar eller slumpmässiga beslutsskogar är en ensembleinlärningsmetod för klassificering, regression och andra uppgifter. För att bygga en slumpmässig skog måste man träna en mängd beslutsträd på slumpmässiga urval av träningsdata. Resultatet av den slumpmässiga skogen är det mest frekventa resultatet bland de enskilda träden. Slumpmässiga beslutsskogar bekämpar framgångsrikt överanpassning på grund av algoritmens _allmänna _natur.
Stacking
Stacking är en teknik för ensembleinlärning som kombinerar flera klassificerings- eller regressionsmodeller via en meta-klassificerare eller en meta-regressor. Modellerna på basnivå tränas baserat på en fullständig träningsuppsättning, och sedan tränas metamodellen på utgångarna från modellerna på basnivå som funktioner.
Neurala nätverk
Ett neuralt nätverk är en sekvens av neuroner som är sammankopplade med synapser, vilket påminner om strukturen i den mänskliga hjärnan. Den mänskliga hjärnan är dock ännu mer komplex.
Det fantastiska med neurala nätverk är att de kan användas för i princip alla uppgifter, från filtrering av skräppost till datorseende. De används dock normalt för maskinöversättning, anomalidetektering och riskhantering, taligenkänning och språkgenerering, ansiktsigenkänning med mera.
Ett neuralt nätverk består av neuroner, eller noder. Var och en av dessa neuroner tar emot data, bearbetar dem och överför dem sedan till en annan neuron.
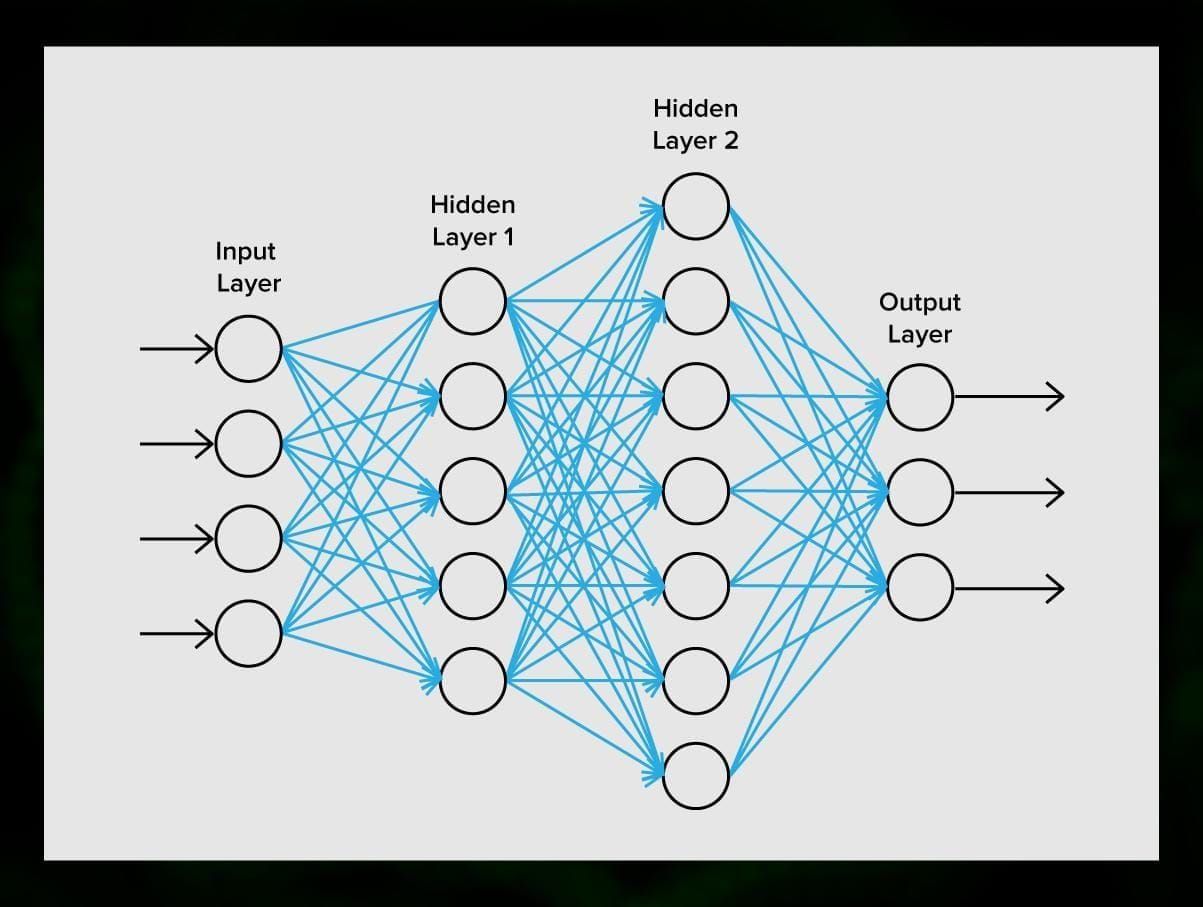
Varje neuron bearbetar signalerna på samma sätt. Men hur får vi då ett annat resultat? Det är synapserna som förbinder neuronerna med varandra som är ansvariga för detta. Varje neuron kan ha många synapser som dämpar eller förstärker signalen. Dessutom kan neuronerna ändra sina egenskaper med tiden. Genom att välja rätt synaps-parametrar kan vi få rätt resultat av den ingående informationens omvandling vid utgången.
Det finns många olika typer av NN:
- Feedforward neural networks (FF eller FFNN) och perceptrons § är mycket raka, det finns inga slingor eller cykler i nätverket. I praktiken används sådana nätverk sällan, men de kombineras ofta med andra typer för att få fram nya.
- Ett Hopfield-nätverk (HN) är ett helt anslutet neuralt nätverk med en symmetrisk matris av länkar. Ett sådant nätverk kallas ofta för ett associativt minnesnätverk. Precis som en person som ser ena halvan av bordet kan föreställa sig den andra halvan, kan detta nätverk, när det tar emot ett brusigt bord, återställa det fullt ut.
- Konvolutionella neurala nätverk (CNN) och djupa konvolutionella neurala nätverk (DCNN) skiljer sig mycket från andra typer av nätverk. De används vanligtvis för bildbehandling, ljud- eller videorelaterade uppgifter. Ett typiskt sätt att tillämpa CNN är att klassificera bilder.
Många olika typer av neurala nätverk är intressanta att observera. Det är möjligt att göra det i NN zoo.
Slutsats
Detta inlägg är en bred översikt över olika ML-algoritmer, men det finns fortfarande mycket att säga. Håll dig uppdaterad på vår Twitter, Facebook och Medium för fler guider och inlägg om de spännande möjligheterna med maskininlärning.
Lämna ett svar