Att ha insyn i din Java-applikation är avgörande för att förstå hur den fungerar just nu, hur den fungerade förr i tiden och för att öka din förståelse för hur den kan komma att fungera i framtiden. Oftast är analys av loggar det snabbaste sättet att upptäcka vad som gick fel, vilket gör att loggning i Java är avgörande för att säkerställa prestandan och hälsan hos din applikation, samt för att minimera och minska eventuell driftstopp. Att ha en centraliserad loggnings- och övervakningslösning bidrar till att minska Mean Time To Repair genom att förbättra effektiviteten hos ditt Ops- eller DevOps-team.
Om du följer goda rutiner får du ut mer värde av dina loggar och gör det lättare att använda dem. Du kommer lättare att kunna lokalisera grundorsaken till fel och dålig prestanda och lösa problem innan de påverkar slutanvändarna. Så idag vill jag dela med mig av några av de bästa metoderna som du bör svära på när du arbetar med Java-applikationer. Låt oss gräva i det.
- Använd ett standardloggningsbibliotek
- Välj dina appendrar klokt
- Use Meaningful Messages
- Loggning av Java Stack Traces
- Logging Java Exceptions
- Använd lämplig loggnivå
- Logga i JSON
- Håller loggstrukturen konsekvent
- Lägg till kontexten i dina loggar
- Java Logging in Containers
- Logga inte för mycket eller för lite
- Håller målgruppen i åtanke
- Undervik att logga känslig information
- Använd en logghanteringslösning för att centralisera & Övervaka Java-loggar
- Slutsats
- Aktie
Använd ett standardloggningsbibliotek
Loggning i Java kan göras på några olika sätt. Du kan använda ett dedikerat loggningsbibliotek, ett gemensamt API eller till och med bara skriva loggar till en fil eller direkt till ett dedikerat loggningssystem. När du väljer loggningsbibliotek för ditt system ska du dock tänka dig för. Saker att tänka på och utvärdera är prestanda, flexibilitet, appenders för nya loggcentraliseringslösningar och så vidare. Om du binder dig direkt till ett enda ramverk kan övergången till ett nyare bibliotek kräva en betydande mängd arbete och tid. Tänk på det och satsa på ett API som ger dig flexibiliteten att byta loggningsbibliotek i framtiden. Precis som vid bytet från Log4j till Logback och till Log4j 2 är det enda du behöver göra när du använder SLF4J API att ändra beroendet, inte koden.
Om du är nybörjare på loggningsbibliotek i Java kan du läsa våra nybörjarguider:
- Log4j Tutorial
- Logback Tutorial
- Log4j2 Tutorial
- SLF4J Tutorial
Välj dina appendrar klokt
Appenders definierar var dina loggningshändelser ska levereras. De vanligaste appenders är Console och File Appenders. Även om de är användbara och allmänt kända kanske de inte uppfyller dina krav. Du kanske till exempel vill skriva dina loggar på ett asynkront sätt eller så vill du skicka dina loggar över nätverket med hjälp av appenders som den för Syslog, så här:
<Appenders> <Console name="Console" target="SYSTEM_OUT"> <PatternLayout pattern="%d %level %c - %m%n"/> </Console> <Syslog name="Syslog" host="logsene-syslog-receiver.sematext.com" port="514" protocol="TCP" format="RFC5424" appName="11111111-2222-3333-4444-555555555555" facility="LOCAL0" mdcId="mdc" newLine="true"/></Appenders>
Hur som helst ska du komma ihåg att om du använder appenders som den som visas ovan så gör du din loggningspipeline känslig för nätverksfel och kommunikationsstörningar. Det kan leda till att loggar inte skickas till sin destination, vilket kanske inte är acceptabelt. Du vill också undvika att loggningen påverkar ditt system om appendern är utformad på ett blockerande sätt. Om du vill veta mer kan du läsa vårt blogginlägg Logging libraries vs Log shippers.
Use Meaningful Messages
En av de viktigaste sakerna när det gäller att skapa loggar, men ändå en av de inte så enkla, är att använda meningsfulla meddelanden. Dina logghändelser bör innehålla meddelanden som är unika för den givna situationen, tydligt beskriva dem och informera den person som läser dem. Tänk dig att ett kommunikationsfel inträffade i ditt program. Du skulle kunna göra så här:
LOGGER.warn("Communication error");
Men du skulle också kunna skapa ett meddelande så här:
LOGGER.warn("Error while sending documents to events Elasticsearch server, response code %d, response message %s. The message sending will be retried.", responseCode, responseMessage);
Du kan lätt se att det första meddelandet kommer att informera den som tittar på loggarna om några kommunikationsproblem. Den personen kommer förmodligen att få kontexten, namnet på loggaren och radnumret där varningen inträffade, men det är allt. För att få mer sammanhang måste personen titta på koden, veta vilken version av koden som felet är relaterat till och så vidare. Detta är inte roligt och ofta inte lätt, och definitivt inte något man vill göra när man försöker felsöka ett produktionsproblem så snabbt som möjligt.
Det andra meddelandet är bättre. Det ger exakt information om vilken typ av kommunikationsfel som inträffade, vad programmet gjorde vid den tidpunkten, vilken felkod det fick och vad svaret från fjärrservern var. Slutligen informerar det också om att sändningen av meddelandet kommer att försöka igen. Att arbeta med sådana meddelanden är definitivt enklare och trevligare.
Tänk slutligen på meddelandets storlek och verbositet. Logga inte information som är alltför utförlig. Dessa uppgifter måste lagras någonstans för att vara användbara. Ett mycket långt meddelande är inget problem, men om den raden upprepas hundratals gånger på en minut och du har många verbose-loggar kan det bli problematiskt att hålla längre lagring av sådana data och i slutändan kostar det också mer.
Loggning av Java Stack Traces
En av de mycket viktiga delarna av Java-loggningen är Java-stacktraces. Ta en titt på följande kod:
package com.sematext.blog.logging;import org.apache.logging.log4j.LogManager;import org.apache.logging.log4j.Logger;import java.io.IOException;public class Log4JExceptionNoThrowable { private static final Logger LOGGER = LogManager.getLogger(Log4JExceptionNoThrowable.class); public static void main(String args) { try { throw new IOException("This is an I/O error"); } catch (IOException ioe) { LOGGER.error("Error while executing main thread"); } }}
Ovanstående kod kommer att resultera i att ett undantag kastas och ett loggmeddelande som skrivs ut till konsolen med vår standardkonfiguration kommer att se ut på följande sätt:
11:42:18.952 ERROR - Error while executing main thread
Som du kan se är det inte mycket information där. Vi vet bara att problemet inträffade, men vi vet inte var det inträffade eller vad problemet var osv. Inte särskilt informativt.
Klipp nu på samma kod med ett något modifierat loggningsmeddelande:
package com.sematext.blog.logging;import org.apache.logging.log4j.LogManager;import org.apache.logging.log4j.Logger;import java.io.IOException;public class Log4JException { private static final Logger LOGGER = LogManager.getLogger(Log4JException.class); public static void main(String args) { try { throw new IOException("This is an I/O error"); } catch (IOException ioe) { LOGGER.error("Error while executing main thread", ioe); } }}
Som du kan se har vi den här gången inkluderat själva undantagsobjektet i vårt loggningsmeddelande:
LOGGER.error("Error while executing main thread", ioe);
Det skulle resultera i följande fellogg i konsolen med vår standardkonfiguration:
11:30:17.527 ERROR - Error while executing main threadjava.io.IOException: This is an I/O error at com.sematext.blog.logging.Log4JException.main(Log4JException.java:13)
Det innehåller relevant information – i.D.v.s. namnet på klassen, metoden där problemet inträffade och slutligen radnumret där problemet inträffade. Naturligtvis kommer stacktraces i verkliga situationer att vara längre, men du bör inkludera dem för att ge dig tillräckligt med information för korrekt felsökning.
Om du vill veta mer om hur du hanterar Java-stacktraces med Logstash, se Hantering av flerradiga stacktraces med Logstash eller titta på Logagent som kan göra det åt dig utan problem.
Logging Java Exceptions
När du hanterar Java exceptions och stack traces bör du inte bara tänka på hela stack trace, de rader där problemet dök upp och så vidare. Du bör också tänka på hur du inte ska hantera undantag.
Undervik att tyst ignorera undantag. Du vill inte ignorera något viktigt. Gör till exempel inte så här:
try { throw new IOException("This is an I/O error");} catch (IOException ioe) {}
Lägg inte heller bara logga ett undantag och kasta det vidare. Det betyder att du bara har skjutit problemet uppåt i exekveringsstacken. Undvik även sådant här:
try { throw new IOException("This is an I/O error");} catch (IOException ioe) { LOGGER.error("I/O error occurred during request processing", ioe); throw ioe;}
Om du är intresserad av att lära dig mer om undantag kan du läsa vår guide om Java undantagshantering där vi tar upp allt från vad de är till hur du fångar och åtgärdar dem.
Använd lämplig loggnivå
När du skriver din applikationskod tänk efter två gånger om ett visst loggmeddelande. Inte varje bit information är lika viktig och inte varje oväntad situation är ett fel eller ett kritiskt meddelande. Använd också loggningsnivåerna konsekvent – information av liknande typ bör ligga på en liknande allvarlighetsnivå.
Både SLF4J-fasaden och varje Java-loggningsramverk som du kommer att använda tillhandahåller metoder som kan användas för att tillhandahålla en lämplig loggningsnivå. Till exempel:
LOGGER.error("I/O error occurred during request processing", ioe);
Logga i JSON
Om vi planerar att logga och titta på data manuellt i en fil eller i standardutgången kommer den planerade loggningen att vara mer än bra. Det är mer användarvänligt – vi är vana vid det. Men det är bara genomförbart för mycket små tillämpningar och även då föreslås att man använder något som gör det möjligt att korrelera mätdata med loggarna. Att göra sådana operationer i ett terminalfönster är inte roligt och ibland är det helt enkelt inte möjligt. Om du vill lagra loggar i logghanterings- och centraliseringssystemet bör du logga i JSON. Det beror på att parsing inte är gratis – det innebär vanligtvis att man måste använda reguljära uttryck. Naturligtvis kan du betala det priset i logghanteraren, men varför göra det om du enkelt kan logga i JSON. Loggning i JSON innebär också enkel hantering av stack traces, så ännu en fördel. Nåväl, du kan också bara logga till en Syslog-kompatibel destination, men det är en annan historia.
I de flesta fall räcker det med att inkludera rätt konfiguration för att aktivera loggning i JSON i ditt Java-loggningsramverk. Låt oss till exempel anta att vi har följande loggmeddelande inkluderat i vår kod:
LOGGER.info("This is a log message that will be logged in JSON!");
För att konfigurera Log4J 2 för att skriva loggmeddelanden i JSON skulle vi inkludera följande konfiguration:
<?xml version="1.0" encoding="UTF-8"?><Configuration status="WARN"> <Appenders> <Console name="Console" target="SYSTEM_OUT"> <JSONLayout compact="true" eventEol="true"> </JSONLayout> </Console> </Appenders> <Loggers> <Root level="info"> <AppenderRef ref="Console"/> </Root> </Loggers></Configuration>
Resultatet skulle se ut på följande sätt:
{"instant":{"epochSecond":1596030628,"nanoOfSecond":695758000},"thread":"main","level":"INFO","loggerName":"com.sematext.blog.logging.Log4J2JSON","message":"This is a log message that will be logged in JSON!","endOfBatch":false,"loggerFqcn":"org.apache.logging.slf4j.Log4jLogger","threadId":1,"threadPriority":5}
Håller loggstrukturen konsekvent
Strukturen på dina logghändelser bör vara konsekvent. Detta gäller inte bara inom ett enskilt program eller en uppsättning mikrotjänster, utan bör tillämpas i hela din applikationsstack. Med logghändelser med liknande struktur blir det lättare att titta på dem, jämföra dem, korrelera dem eller helt enkelt lagra dem i ett dedikerat datalager. Det är lättare att titta på data som kommer från dina system när du vet att de har gemensamma fält som allvarlighetsgrad och värdnamn, så att du enkelt kan dela upp data utifrån den informationen. För inspiration kan du ta en titt på Sematext Common Schema även om du inte är Sematext-användare.
Det är förstås inte alltid möjligt att behålla strukturen, eftersom hela din stack består av externt utvecklade servrar, databaser, sökmotorer, köer osv. som alla har sin egen uppsättning loggar och loggformat. Men för att hålla ditt och ditt teams förstånd minimera antalet olika strukturer för loggmeddelanden som du kan kontrollera.
Ett sätt att hålla en gemensam struktur är att använda samma mönster för dina loggar, åtminstone de som använder samma loggningsramverk. Om dina applikationer och mikrotjänster använder Log4J 2 kan du till exempel använda ett mönster som detta:
<PatternLayout> <Pattern>%d %p %c{35}:%L - %m%n</Pattern></PatternLayout>
Om du använder ett enda eller en mycket begränsad uppsättning mönster kan du vara säker på att antalet loggformat förblir litet och hanterbart.
Lägg till kontexten i dina loggar
Informationskontext är viktigt och för oss utvecklare och DevOps är ett loggmeddelande information. Titta på följande loggpost:
An error occurred!
Vi vet att ett fel dök upp någonstans i programmet. Vi vet inte var det hände, vi vet inte vilken typ av fel det var, vi vet bara när det hände. Titta nu på ett meddelande med något mer kontextuell information:
com.sematext.blog.logging.ParsingErrorExample - A parsing error occurred for user with id 1234!
Samma loggpost, men mycket mer kontextuell information. Vi vet i vilken tråd det hände, vi vet vilken klass felet genererades på. Vi modifierade meddelandet också för att inkludera användaren som felet inträffade för, så att vi kan komma tillbaka till användaren om det behövs. Vi kan också inkludera ytterligare information som diagnostiska sammanhang. Tänk på vad du behöver och inkludera det.
För att inkludera kontextinformation behöver du inte göra så mycket när det gäller koden som ansvarar för att generera loggmeddelandet. PatternLayout i Log4J 2 ger dig till exempel allt du behöver för att inkludera kontextinformationen. Du kan använda ett mycket enkelt mönster som detta:
<PatternLayout pattern="%d{HH:mm:ss.SSS} %-5level - %msg%n"/>
Det kommer att resultera i ett loggmeddelande som liknar följande:
17:13:08.059 INFO - This is the first INFO level log message!
Men du kan också inkludera ett mönster som innehåller mycket mer information:
<PatternLayout pattern="%d{HH:mm:ss.SSS} %c %l %-5level - %msg%n"/>
Det kommer att resultera i ett loggmeddelande som detta:
17:24:01.710 com.sematext.blog.logging.Log4j2 com.sematext.blog.logging.Log4j2.main(Log4j2.java:12) INFO - This is the first INFO level log message!
Java Logging in Containers
Tänk på den miljö som din applikation kommer att köras i. Det är skillnad i konfigurationen av loggningen när du kör din Javakod i en VM eller på en bare-metal-maskin, det är skillnad när du kör den i en containeriserad miljö, och naturligtvis är det skillnad när du kör din Java- eller Kotlin-kod på en Android-enhet.
För att konfigurera loggningen i en containeriserad miljö måste du välja vilket tillvägagångssätt du vill använda. Du kan använda en av de medföljande loggningsdrivrutinerna – som journald, logagent, Syslog eller JSON-fil. För att göra det ska du komma ihåg att ditt program inte ska skriva loggfilen till containerns efemära lagring, utan till standardutgången. Det kan enkelt göras genom att konfigurera ditt loggningsramverk så att loggen skrivs till konsolen. Med Log4J 2 skulle du till exempel bara använda följande appenderkonfiguration:
<Appenders> <Console name="Console" target="SYSTEM_OUT"> <PatternLayout pattern="%d{HH:mm:ss.SSS} - %m %n"/> </Console></Appenders>
Du kan också helt utelämna loggningsdrivrutinerna och skicka loggar direkt till din centraliserade loggningslösning som vårt Sematext Cloud:
<Appenders> <Console name="Console" target="SYSTEM_OUT"> <PatternLayout pattern="%d %level %c - %m%n"/> </Console> <Syslog name="Syslog" host="logsene-syslog-receiver.sematext.com" port="514" protocol="TCP" format="RFC5424" appName="11111111-2222-3333-4444-555555555555" facility="LOCAL0" mdcId="mdc" newLine="true"/></Appenders>
Logga inte för mycket eller för lite
Som utvecklare har vi en tendens att tro att allting kan vara viktigt – vi tenderar att markera varje steg i vår algoritm- eller affärskod som viktigt. Å andra sidan gör vi ibland tvärtom – vi lägger inte till loggning där vi borde eller så loggar vi bara på loggnivåerna FATAL och ERROR. Båda tillvägagångssätten kommer inte att fungera särskilt bra. När du skriver din kod och lägger till loggning, tänk på vad som kommer att vara viktigt för att se om programmet fungerar korrekt och vad som kommer att vara viktigt för att kunna diagnostisera ett felaktigt programtillstånd och åtgärda det. Använd detta som ledstjärna när du bestämmer vad och var du ska logga. Tänk på att lägga till för många loggar kommer att sluta med informationströtthet och att inte ha tillräckligt med information kommer att resultera i oförmåga att felsöka.
Håller målgruppen i åtanke
I de flesta fall kommer du inte att vara den enda personen som tittar på loggarna. Kom alltid ihåg att. Det finns flera aktörer som kan titta på loggarna.
Utvecklaren kan titta på loggarna för felsökning eller under felsökningssessioner. För sådana personer kan loggarna vara detaljerade, tekniska och innehålla mycket djupgående information om hur systemet fungerar. En sådan person kommer också att ha tillgång till koden eller till och med känna till koden och du kan utgå från det.
Då finns DevOps. För dem kommer logghändelser att behövas för felsökning och bör innehålla information som är till hjälp vid diagnostik. Du kan anta kunskapen om systemet, dess arkitektur, dess komponenter och konfigurationen av komponenterna, men du bör inte anta kunskapen om plattformens kod.
Till sist kan dina programloggar läsas av dina användare själva. I sådana fall bör loggarna vara tillräckligt beskrivande för att hjälpa till att åtgärda problemet, om det ens är möjligt, eller för att ge tillräckligt med information till supportteamet som hjälper användaren. Att använda Sematext för övervakning innebär till exempel att installera och köra en övervakningsagent. Om du befinner dig bakom en mycket restriktiv brandvägg och agenten inte kan skicka mätvärden till Sematext, loggar den fel som syftar till att Sematext-användarna själva kan titta på också.
Vi skulle kunna gå vidare och identifiera ännu fler aktörer som kan titta på loggar, men den här listan bör ge dig en glimt av vad du bör tänka på när du skriver dina loggmeddelanden.
Undervik att logga känslig information
Känslig information bör inte finnas i loggar eller bör maskeras. Lösenord, kreditkortsnummer, personnummer, åtkomsttoken och så vidare – allt detta kan vara farligt om det läcker ut eller nås av personer som inte borde se det. Det finns två saker du bör tänka på.
Tänk efter om känslig information verkligen är nödvändig för felsökning. Kanske räcker det i stället för ett kreditkortsnummer att behålla informationen om transaktionsidentifieraren och datumet för transaktionen? Kanske är det inte nödvändigt att behålla socialförsäkringsnumret i loggarna när man enkelt kan lagra användaridentifieringen. Tänk på sådana situationer, tänk på vilka uppgifter du lagrar och skriv bara känsliga uppgifter när det verkligen är nödvändigt.
Den andra saken är att skicka loggar med känslig information till en värdloggtjänst. Det finns mycket få undantag där följande råd inte bör följas. Om dina loggar har och behöver ha känslig information lagrad, maskera eller ta bort den innan du skickar den till ditt centraliserade logglager. De flesta populära loggavsändare, som vår egen Logagent, innehåller funktionalitet som gör det möjligt att ta bort eller maskera känsliga uppgifter.
Finansiellt kan maskering av känslig information göras i själva loggningsramverket. Låt oss titta på hur det kan göras genom att utöka Log4j 2. Vår kod som producerar logghändelser ser ut på följande sätt (hela exemplet finns på Sematext Github):
public class Log4J2Masking { private static Logger LOGGER = LoggerFactory.getLogger(Log4J2Masking.class); private static final Marker SENSITIVE_DATA_MARKER = MarkerFactory.getMarker("SENSITIVE_DATA_MARKER"); public static void main(String args) { LOGGER.info("This is a log message without sensitive data"); LOGGER.info(SENSITIVE_DATA_MARKER, "This is a a log message with credit card number 1234-4444-3333-1111 in it"); }}
Om du skulle köra hela exemplet från Github skulle utmatningen se ut på följande sätt:
21:20:42.099 - This is a log message without sensitive data21:20:42.101 - This is a a log message with credit card number ****-****-****-**** in it
Du kan se att kreditkortsnumret maskerades. Detta gjordes eftersom vi lade till en anpassad omvandlare som kontrollerar om den givna markören skickas längs logghändelsen och försöker ersätta ett definierat mönster. Implementeringen av en sådan omvandlare ser ut på följande sätt:
@Plugin(name = "sample_logging_mask", category = "Converter")@ConverterKeys("sc")public class LoggingConverter extends LogEventPatternConverter { private static Pattern PATTERN = Pattern.compile("\b({4})-({4})-({4})-({4})\b"); public LoggingConverter(String options) { super("sc", "sc"); } public static LoggingConverter newInstance(final String options) { return new LoggingConverter(options); } @Override public void format(LogEvent event, StringBuilder toAppendTo) { String message = event.getMessage().getFormattedMessage(); String maskedMessage = message; if (event.getMarker() != null && "SENSITIVE_DATA_MARKER".compareToIgnoreCase(event.getMarker().getName()) == 0) { Matcher matcher = PATTERN.matcher(message); if (matcher.find()) { maskedMessage = matcher.replaceAll("****-****-****-****"); } } toAppendTo.append(maskedMessage); }}
Det är mycket enkelt och skulle kunna skrivas på ett mer optimerat sätt och borde också hantera alla möjliga kreditkortsnummerformat, men det räcker för det här ändamålet.
För att hoppa in i kodförklaringen vill jag också visa konfigurationsfilen log4j2.xml för det här exemplet:
<?xml version="1.0" encoding="UTF-8"?><Configuration status="WARN" packages="com.sematext.blog.logging"> <Appenders> <Console name="Console" target="SYSTEM_OUT"> <PatternLayout pattern="%d{HH:mm:ss.SSS} - %sc %n"/> </Console> </Appenders> <Loggers> <Root level="info"> <AppenderRef ref="Console"/> </Root> </Loggers></Configuration>
Som du kan se har vi lagt till attributet packages i vår konfiguration för att tala om för ramverket var det ska leta efter vår omvandlare. Sedan har vi använt mönstret %sc för att tillhandahålla loggmeddelandet. Vi gör det eftersom vi inte kan skriva över standardmönstret %m. När Log4j2 hittar vårt %sc-mönster kommer den att använda vår omvandlare som tar det formaterade meddelandet från logghändelsen och använder en enkel regex och ersätter datan om den hittades. Så enkelt är det.
En sak att notera här är att vi använder Marker-funktionen. Regexmatchning är dyrt och vi vill inte göra det för varje loggmeddelande. Därför markerar vi de logghändelser som ska bearbetas med den skapade markören, så att endast de markerade kontrolleras.
Använd en logghanteringslösning för att centralisera & Övervaka Java-loggar
Med programmens komplexitet kommer volymen av dina loggar också att växa. Du kan komma undan med att logga till en fil och bara använda loggar när felsökning behövs, men när mängden data växer blir det snabbt svårt och långsamt att felsöka på detta sätt När detta händer bör du överväga att använda en logghanteringslösning för att centralisera och övervaka dina loggar. Du kan antingen satsa på en intern lösning baserad på öppen källkod som Elastic Stack eller använda ett av de logghanteringsverktyg som finns på marknaden som Sematext Logs.
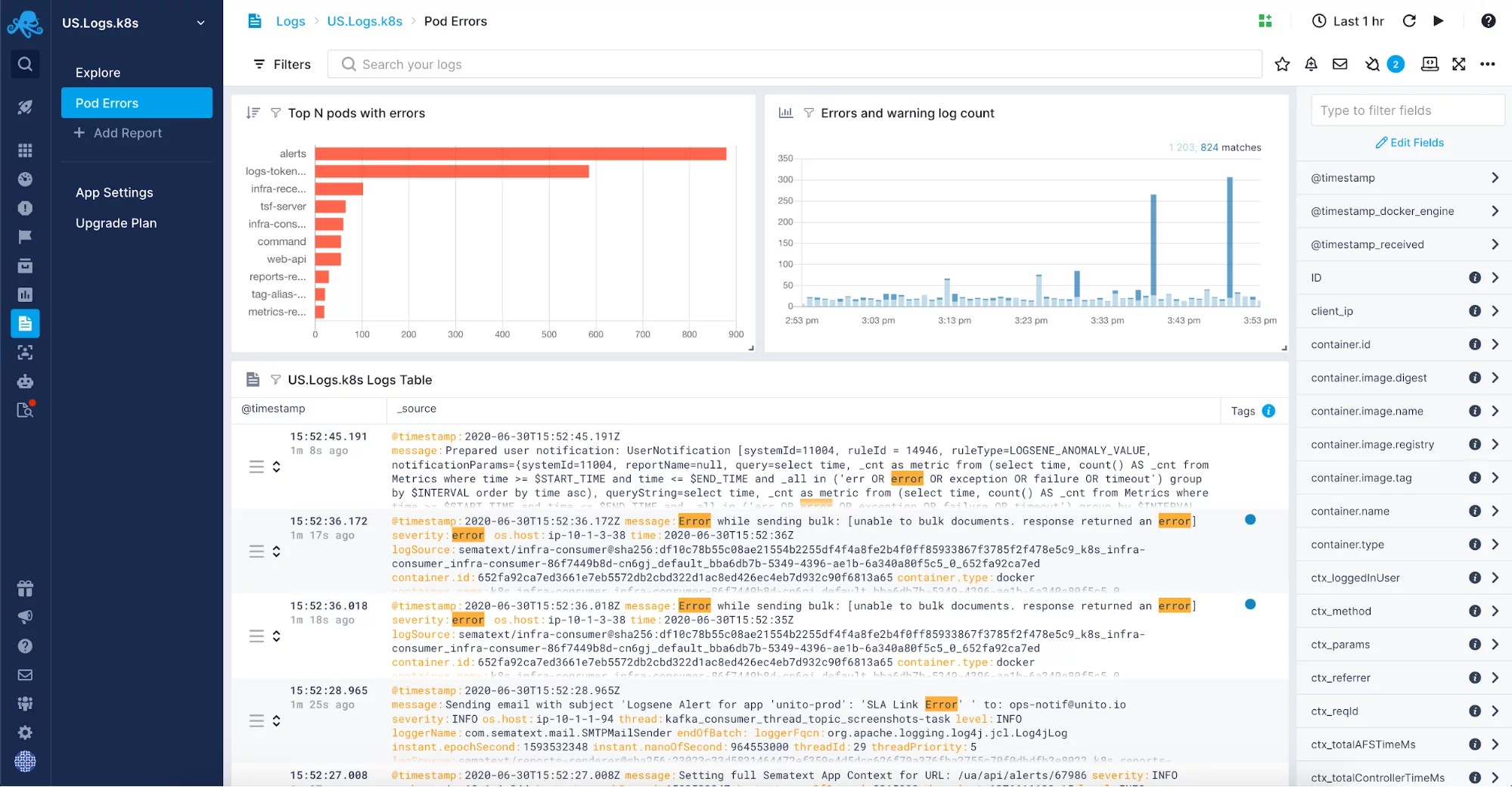
En fullt hanterad lösning för centralisering av loggar ger dig friheten att slippa hantera ännu en, vanligtvis ganska komplex, del av din infrastruktur. Istället kommer du att kunna fokusera på din applikation och behöver bara konfigurera loggtransporter. Du kanske vill inkludera loggar som JVM garbage collection-loggar i din hanterade logglösning. När du har aktiverat dem för dina program och system som arbetar på JVM vill du samla loggarna på ett enda ställe för loggkorrelation, logganalys och för att hjälpa dig att ställa in skräpplockningen i JVM-instanserna. Sådana loggar korrelerade med mätvärden är en ovärderlig informationskälla för felsökning av skräpinsamlingsrelaterade problem.
Om du är intresserad av att se hur Sematext Logs står sig mot liknande lösningar kan du gå vidare till vår artikel om den bästa logghanteringsprogramvaran eller blogginlägget där vi granskar några av de bästa verktygen för logganalys, men vi rekommenderar att du använder den 14-dagars kostnadsfria testversionen för att fullt ut utforska dess funktioner. Prova det och se själv!
Slutsats
Att införliva varje god praxis är kanske inte lätt att implementera direkt, särskilt inte för applikationer som redan är live och arbetar i produktion. Men om du tar dig tid och rullar ut förslagen ett efter ett kommer du att börja se en ökning av användbarheten av dina loggar. För fler tips om hur du får ut det mesta av dina loggar rekommenderar vi att du även går igenom vår andra artikel om bästa praxis för loggning där vi förklarar och ins och outs du bör följa oavsett vilken typ av app du arbetar med. Och kom ihåg att vi på Sematext hjälper organisationer med sina loggningsupplägg genom att erbjuda loggningskonsultationer, så ta kontakt om du har problem så hjälper vi dig gärna.
Aktie
.
Lämna ett svar