Skriv upp dig för våra dagliga sammanfattningar av det ständigt föränderliga sökmarknadsföringslandskapet.
Notera: Genom att skicka in det här formuläret godkänner du Third Door Medias villkor. Vi respekterar din integritet.

På internetforum och innehållsrelaterade Facebook-grupper bryter ofta diskussioner ut om hur Googlebot fungerar – som vi här ömt ska kalla GB – och vad den kan och inte kan se, vilken typ av länkar den besöker och hur den påverkar SEO.
I den här artikeln kommer jag att presentera resultaten av mitt tre månader långa experiment.
Nästan dagligen under de senaste tre månaderna har GB besökt mig som en vän som kommer förbi på en öl.
Ibland var den ensam:
: 66.249.76.136 /page1.html Mozilla/5.0 (kompatibel; Googlebot/2.1; +http://www.google.com/bot.html)
: 66.249.76.136 /page5.html Mozilla/5.0 (kompatibel; Googlebot/2.1; +http://www.google.com/bot.html)
: 66.249.76.140 /page3.html Mozilla/5.0 (kompatibel; Googlebot/2.1; +http://www.google.com/bot.html)
: 66.249.64.72 /page2.html Mozilla/5.0 (kompatibel; Googlebot/2.1; +http://www.google.com/bot.html)
: 66.249.64.72 /page6.html Mozilla/5.0 (kompatibel; Googlebot/2.1; +http://www.google.com/bot.html)
Ibland tog den med sig sina kompisar:
: 64.233.172.231 /page1.html Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko; Google Search Console) Chrome/41.0.2272.118 Safari/537.36
: 66.249.69.235 /image.jpg Googlebot-Image/1.0
: 66.249.76.156 /page2.html Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2272.96 Mobile Safari/537.36 (kompatibel; Googlebot/2.1; +http://www.google.com/bot.html)
Och vi hade mycket roligt när vi spelade olika spel:
Catch: Jag observerade hur GB älskar att köra omdirigeringar 301, kryssa bilder och köra från canonicals.
Skydda och leta: Googlebot gömde sig i det dolda innehållet (som Googlebot enligt sina föräldrar inte tolererar och undviker)
Överlevnad: Jag förberedde fällor och väntade på att Googlebot skulle slå ut dem.
Hinder: Jag placerade ut hinder med olika svårighetsgrader för att se hur min lilla vän skulle hantera dem.
Som du säkert kan se blev jag inte besviken. Vi hade massor av kul och vi blev goda vänner. Jag tror att vår vänskap har en ljus framtid.
Men låt oss komma till saken!
Jag byggde en webbplats med meritrelaterat innehåll om en interstellär resebyrå som erbjuder flygningar till ännu oupptäckta planeter i vår galax och bortom den.
Innehållet verkade ha många meriter när det i själva verket var en massa nonsens.
Strukturen på den experimentella webbplatsen såg ut så här:
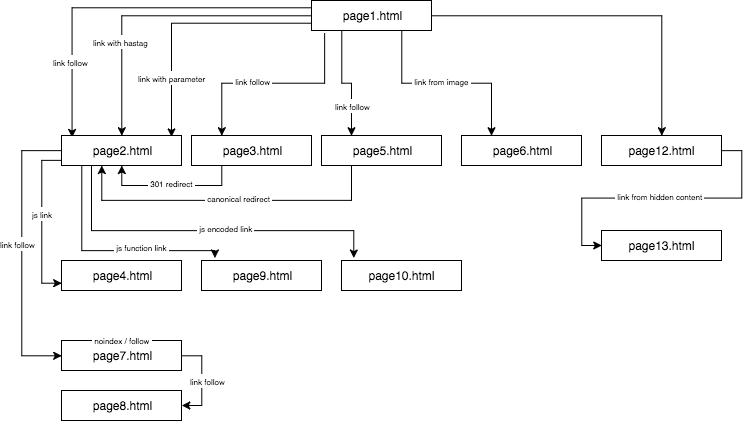
Jag tillhandahöll unikt innehåll och såg till att varje ankare/titel/alt, liksom andra koefficienter, var globalt unika (falska ord). För att underlätta för läsaren kommer jag i beskrivningen inte att använda namn som anchor cutroicano matestito, utan istället hänvisa till dem som anchor1, etc.
Jag föreslår att du håller kartan ovan öppen i ett separat fönster när du läser den här artikeln.
- Del 1: En av de saker som jag ville testa i det här SEO-experimentet var regeln First Link Counts – om den kan utelämnas och hur den påverkar optimeringen.
- Länk till en webbplats med ett ankare
- Länk till en webbplats med en parameter
- Länk till en webbplats från en omdirigering
- Länk till en sida med hjälp av den kanoniska taggen
- Del 2: Crawlbudgeten
- JavaScript-länk med en onclick-händelse
- Javascriptlänk med en intern funktion
- JavaScript-länk med kodning
- Del 3: Dolt innehåll
- Om författaren
Del 1: En av de saker som jag ville testa i det här SEO-experimentet var regeln First Link Counts – om den kan utelämnas och hur den påverkar optimeringen.
Regeln First Link Counts säger att på en sida ser Google Bot endast den första länken till en undersida. Om du har två länkar till samma undersida på en sida ignoreras den andra enligt denna regel. Google Bot kommer att ignorera ankaret i den andra och i varje påföljande länk när den beräknar sidans rank.
Det är ett problem som många specialister ser över, men som framför allt förekommer i nätbutiker, där navigeringsmenyer förvränger webbplatsens struktur avsevärt.
I de flesta butiker har vi en statisk (synlig i sidans källa) rullgardinsmeny, som ger till exempel fyra länkar till huvudkategorier och 25 dolda länkar till underkategorier. Under kartläggningen av en sidas struktur ser GB alla länkar (på varje sida med en meny) vilket resulterar i att alla sidor är lika viktiga under kartläggningen och att deras kraft (juice) fördelas jämnt, vilket ser ungefär så här ut:
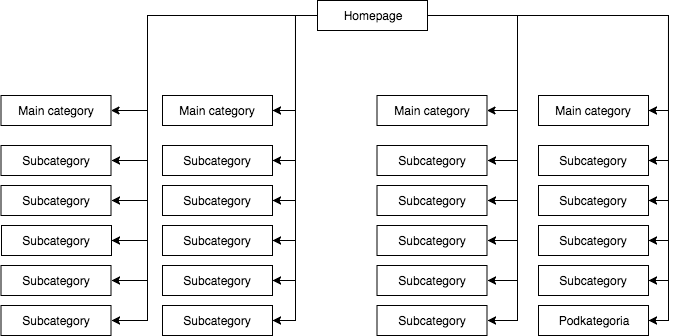
Den vanligaste, men enligt min mening felaktiga sidostrukturen.
Ovanstående exempel kan inte kallas för en riktig struktur eftersom alla kategorier är länkade från alla de sidor där det finns en meny. Därför har både startsidan och alla kategorier och underkategorier lika många inkommande länkar, och kraften från hela webbtjänsten flödar genom dem med samma styrka. Kraften från startsidan (som vanligtvis är källan till den mesta kraften på grund av antalet inkommande länkar) delas alltså upp på 24 kategorier och underkategorier, så att var och en av dem endast får 4 procent av startsidans kraft.
Så bör strukturen se ut:

Om du behöver snabbt testa strukturen på din sida och crawla den som Google gör är Screaming Frog ett användbart verktyg.
I det här exemplet är startsidans kraft uppdelad i fyra och var och en av kategorierna får 25 procent av startsidans kraft och fördelar en del av den till underkategorierna. Den här lösningen ger också en bättre chans till internlänkning. När du till exempel skriver en artikel på butikens blogg och vill länka till en av underkategorierna kommer GB att lägga märke till länken när de crawlar hemsidan. I det första fallet kommer den inte att göra det på grund av regeln om att den första länken räknas. Om länken till en underkategori fanns i webbplatsens meny kommer länken i artikeln att ignoreras.
Jag startade detta SEO-experiment med följande åtgärder:
- Först, på sidan1.html inkluderade jag en länk till en undersida page2.html som en klassisk dofollow-länk med ett ankare: anchor1.
- Nästan, i texten på samma sida, inkluderade jag något modifierade referenser för att verifiera om GB skulle vara ivrig att crawla dem.
För detta ändamål testade jag följande lösningar:
- På webbtjänstens hemsida tilldelade jag en extern dofollow-länk för en fras med ett URL-ankare (så att all extern länkning av hemsidan och undersidorna för givna fraser var uteslutet) – det påskyndade indexeringen av tjänsten.
- Jag väntade på att page2.html skulle börja rankas för en fras från den första dofollow-länken (anchor1) som kom från page1.html. Denna falska fras, eller någon annan som jag testade kunde inte hittas på målsidan. Jag antog att om andra länkar skulle fungera så skulle page2.html också rankas i sökresultaten för andra fraser från andra länkar. Det tog ungefär 45 dagar. Och då kunde jag göra den första viktiga slutsatsen:
Även en webbplats, där ett nyckelord varken finns i innehållet eller i meta-titeln, men är länkat med ett forskat ankare, kan lätt rankas högre i sökresultaten än en webbplats som innehåller det här ordet men som inte är länkat till ett nyckelord.
För övrigt var startsidan (page1.html), som innehöll den undersökta frasen, den starkaste sidan i webbtjänsten (länkad från 78 procent av undersidorna) och ändå rankades den lägre på den undersökta frasen än undersidan (page2.html) som länkades till den undersökta frasen.
Nedan presenterar jag fyra typer av länkar som jag har testat, som alla kommer efter den första dofollow-länken som leder till page2.html.
Länk till en webbplats med ett ankare
< a href=”page2.html#testhash” >anchor2< /a >
Den första av de ytterligare länkar som kommer i koden bakom dofollow-länken var en länk med ett ankare (en hashtag). Jag ville se om GB skulle gå igenom länken och även indexera page2.html under frasen anchor2, trots att länken leder till den sidan (page2.html) men att URL:n ändras till page2.html#testhash använder anchor2.
Tyvärr ville GB aldrig komma ihåg den kopplingen och den dirigerade inte kraften till undersidan page2.html för den frasen. Som ett resultat av detta finns i sökresultaten för frasen anchor2 den dag då den här artikeln skrevs endast undersidan page1.html, där ordet återfinns i länkens ankare. När man googlar frasen testhash rankas inte heller vår domän.
Länk till en webbplats med en parameter
page2.html?parameter=1
Inledningsvis var GB intresserad av den här lustiga delen av URL:en strax efter frågetecknet och ankaret inne i anchor3-länken.
Intresserad försökte GB lista ut vad jag menade. Den tänkte: ”Är det en gåta?”. För att undvika att indexera det dubbla innehållet under de andra URL:erna pekade den kanoniska page2.html på sig själv. Loggarna registrerade sammanlagt 8 crawls på den här adressen, men slutsatserna var ganska sorgliga:
- Efter två veckor minskade frekvensen av GB:s besök betydligt tills GB till slut lämnade den och aldrig crawlade den länken igen.
- page2.html indexerades inte under frasen anchor3, och inte heller under parametern med URL-parameter1. Enligt Search Console finns den här länken inte (den räknas inte bland inkommande länkar), men samtidigt listas frasen anchor3 som en förankrad fras.
Länk till en webbplats från en omdirigering
Jag ville tvinga GB att crawla min webbplats mer, vilket resulterade i att GB med ett par dagars mellanrum skrev in dofollow-länken med ankaret anchor4 på page1.html som leder till page3.html, som omdirigeras med en 301-kod till page2.html. Tyvärr, precis som i fallet med sidan med en parameter, var page2.html efter 45 dagar ännu inte rankad i sökresultaten för frasen anchor4 som fanns i den omdirigerade länken på page1.html.
I Google Search Console, i avsnittet Anchor Texts, är dock anchor4 synligt och indexerat. Detta kan tyda på att omdirigeringen efter ett tag börjar fungera som förväntat, så att page2.html rankas i sökresultaten för anchor4 trots att det är den andra länken till samma målsida på samma webbplats.
Länk till en sida med hjälp av den kanoniska taggen
På page1.html har jag placerat en hänvisning till page5.html (följelänk) med ett ankare anchor5. Samtidigt fanns det på page5.html ett unikt innehåll och i dess huvud fanns en kanonisk tagg till page2.html.
< link rel=”canonical” href=”https://example.com/page2.html” />
Detta test gav följande resultat:
- Länken för frasen anchor5 som leder till page5.html omdirigerar kanoniskt till page2.html överfördes inte till målsidan (precis som i de andra fallen).
- page5.html indexerades trots den kanoniska taggen.
- page5.html rankades inte i sökresultaten för ankare5.
- page5.html rankades på de fraser som användes i sidans text, vilket visade att GB helt ignorerade de kanoniska taggarna.
Jag vågar påstå att det helt enkelt inte kan fungera att använda rel=canonical för att förhindra indexering av visst innehåll (t.ex. vid filtrering).
Del 2: Crawlbudgeten
När jag utformade en SEO-strategi ville jag få GB att dansa efter min pipa och inte tvärtom. För detta ändamål verifierade jag SEO-processerna på nivån för serverloggarna (åtkomstloggar och felloggar), vilket gav mig en stor fördel. Tack vare det kände jag till GB:s alla rörelser och hur den reagerade på de förändringar jag införde (omstrukturering av webbplatsen, upp och ner på systemet för interna länkar, sättet att visa information) inom ramen för SEO-kampanjen.
En av mina uppgifter under SEO-kampanjen var att bygga om en webbplats på ett sätt som skulle få GB att besöka endast de webbadresser som den skulle kunna indexera och som vi ville att den skulle indexera. Kort sagt: det ska bara finnas de sidor som är viktiga för oss ur SEO-synpunkt i Googles index. Å andra sidan bör GB bara gå igenom de webbplatser som vi vill ska indexeras av Google, vilket inte är uppenbart för alla, t.ex. när en nätbutik inför filtrering efter färger, storlek och priser, och det görs genom att manipulera URL-parametrarna, t.ex.:
example.com/women/shoes/?color=red&size=40&price=200-250
Det kan visa sig att en lösning som gör det möjligt för GB att crawla dynamiska webbadresser gör att den ägnar tid åt att genomsöka (och eventuellt indexera) dem istället för att crawla sidan.
example.com/women/shoes/
Dessa dynamiskt skapade webbadresser är inte bara värdelösa utan potentiellt skadliga för SEO eftersom de kan misstas för tunt innehåll, vilket leder till att webbplatsens ranking sjunker.
I det här experimentet ville jag också kontrollera några metoder för strukturering utan att använda rel=”nofollow”, blockera GB i filen robots.txt eller placera en del av HTML-koden i ramar som är osynliga för roboten (blockerad iframe).
Jag testade tre typer av JavaScript-länkar.
JavaScript-länk med en onclick-händelse
En enkel länk konstruerad på JavaScript
< a href=”javascript:void(0)” onclick=”window.location.href =’page4.html'” >anchor6< /a >
GB tog sig lätt vidare till undersidan page4.html och indexerade hela sidan. Undersidan rankas inte i sökresultaten för frasen anchor6, och denna fras kan inte hittas i avsnittet Anchor Texts i Google Search Console. Slutsatsen är att länken inte överförde juice.
För att sammanfatta:
- En klassisk JavaScript-länk gör det möjligt för Google att crawla webbplatsen och indexera de sidor som den kommer till.
- Den överför inte juice – den är neutral.
Javascriptlänk med en intern funktion
Jag bestämde mig för att höja spelet men till min förvåning övervann GB hindret på mindre än två timmar efter det att länken publicerats.
< a href=”javascript:void(0)” class=”js-link” data-url=”page9.html” >anchor7< /a >
För att sköta den här länken använde jag mig av en extern funktion som syftade till att läsa av URL:en från datan och omdirigera – endast omdirigering av en användare, som jag hoppades – till målet page9.html. Liksom i det tidigare fallet hade page9.html indexerats fullt ut.
Det intressanta är att trots avsaknaden av andra inkommande länkar var page9.html den tredje mest besökta sidan av GB i hela webbtjänsten, direkt efter page1.html och page2.html.
Jag hade använt den här metoden tidigare för att strukturera webbtjänster. Men som vi kan se fungerar den inte längre. Inom SEO lever ingenting för evigt, bortsett från de gula sidorna.
JavaScript-länk med kodning
Jag gav ändå inte upp och bestämde mig för att det måste finnas ett sätt att effektivt stänga dörren i ansiktet på GB. Så jag konstruerade en enkel funktion och kodade data med en base64-algoritm, och referensen såg ut så här:
< a href=”javascript:void(0)” class=”js-link” data-url=”cGFnZTEwLmh0bWw=” >anchor8< /a >
Som ett resultat av detta kunde GB inte producera en JavaScript-kod som både avkodar innehållet i ett data-URL-attribut och omdirigerar. Och där var det! Vi har ett sätt att strukturera en webbtjänst utan att använda rel=nonfollows för att hindra robotar från att krypa vart de vill! På så sätt slösar vi inte bort vår crawlbudget, vilket är särskilt viktigt när det gäller stora webbtjänster, och GB dansar äntligen efter vår pipa. Oavsett om funktionen infördes på samma sida i head-sektionen eller i en extern JS-fil finns det inga tecken på en bot vare sig i serverloggarna eller i Search Console.
Del 3: Dolt innehåll
I det sista testet ville jag kontrollera om innehållet i till exempel dolda flikar skulle beaktas och indexeras av GB, eller om Google renderade en sådan sida och ignorerade den dolda texten, vilket en del specialister har påstått.
Jag ville antingen bekräfta eller avfärda detta påstående. För att göra det placerade jag en vägg av text med över 2000 tecken på page12.html och dolde ett textblock med cirka 20 procent av texten (400 tecken) i Cascading Style Sheets och jag lade till knappen visa mer. I den dolda texten fanns en länk till page13.html med ett ankare anchor9.
Det råder ingen tvekan om att en bot kan rendera en sida. Vi kan observera det i både Google Search Console och Google Insight Speed. Trots detta visade mina tester att ett textblock som visades efter att ha klickat på knappen Visa mer helt och hållet indexerades. Fraserna som gömdes i texten rankades i sökresultaten och GB följde länkarna som gömdes i texten. Dessutom var förankringarna för länkarna från ett dolt textblock synliga i Google Search Console i avsnittet Anchor Text och page13.html började också rankas i sökresultaten för sökordet anchor9.
Detta är avgörande för nätbutiker, där innehållet ofta placeras i dolda flikar. Nu är vi säkra på att GB ser innehållet i dolda flikar, indexerar dem och överför saften från de länkar som är dolda där.
Den viktigaste slutsatsen som jag drar av det här experimentet är att jag inte har hittat något direkt sätt att kringgå regeln om att den första länken räknas genom att använda modifierade länkar (länkar med parameter, 301-omdirigeringar, kanoniska länkar, ankarlänkar). Samtidigt är det möjligt att bygga upp en webbplats struktur med hjälp av Javascript-länkar, tack vare vilka vi är fria från begränsningarna i First Link Counts Rule. Dessutom kan Google Bot se och indexera innehåll som är gömt i bokmärken och den följer de länkar som är gömda i dem.
Anmäl dig till våra dagliga sammanfattningar av det ständigt föränderliga landskapet för sökmarknadsföring.
Anmärkning: Genom att skicka in det här formuläret godkänner du Third Door Medias villkor. Vi respekterar din integritet.
Om författaren

”Acceptera inte ’bara’ hög kvalitet. Vem som helst kan göra det. Om himlen är gränsen, hitta en högre himmel.” Max Cyrek är vd för Cyrek Digital, en konsult inom digital marknadsföring och SEO-evangelist. Under hela sin karriär har Max, tillsammans med sitt team på över 30 personer, arbetat med hundratals företag för att hjälpa dem att lyckas. Han har arbetat med digital marknadsföring i nästan tio år och har specialiserat sig på teknisk SEO och hanterat framgångsrika marknadsföringsprojekt.
Lämna ett svar