Avisibilizar sua aplicação Java é crucial para entender como ela funciona agora, como ela funcionou algum tempo no passado, e aumentar sua compreensão de como ela pode funcionar no futuro. Na maioria das vezes, analisar logs é a maneira mais rápida de detectar o que deu errado, fazendo com que o login em Java seja crítico para garantir o desempenho e a saúde da sua aplicação, bem como minimizar e reduzir qualquer tempo de inatividade. Ter uma solução centralizada de registro e monitoramento ajuda a reduzir o tempo médio para reparar, melhorando a eficácia de sua equipe de Ops ou DevOps.
Ao seguir as boas práticas você obterá mais valor dos seus registros e tornará mais fácil a sua utilização. Você será capaz de identificar mais facilmente a causa raiz dos erros e do mau desempenho e resolver problemas antes que eles afetem os usuários finais. Portanto, hoje, deixe-me compartilhar algumas das melhores práticas que você deve jurar ao trabalhar com aplicações Java. Vamos cavar em.
- Utilizar uma Biblioteca de Logging Padrão
- Selecione seus Appenders Sabiamente
- Use Meaningful Messages
- Logging Java Stack Traces
- Logging Java Exceptions
- Use Appropriate Log Level
- Log in JSON
- Calme a Estrutura de Log Consistente
- Adicionar contexto aos seus logs
- Java Logging in Containers
- Não faça Log Too Much ou Too Little
- Keep the Audience in Mind
- Anular Informação Sensível de Registo
- Utilizar uma Solução de Gerenciamento de Logs para Centralizar & Monitorar Logs Java
- Conclusion
- Partilhar
Utilizar uma Biblioteca de Logging Padrão
Ologging em Java pode ser feito de algumas maneiras diferentes. Você pode usar uma biblioteca de registro dedicada, uma API comum, ou até mesmo apenas escrever logs em arquivo ou diretamente em um sistema de registro dedicado. No entanto, ao escolher a biblioteca de registo para o seu sistema, pense mais à frente. Coisas a considerar e avaliar são desempenho, flexibilidade, anexos para novas soluções de centralização de logs, e assim por diante. Se você se amarrar diretamente a uma única estrutura, a mudança para uma biblioteca mais nova pode levar uma quantidade substancial de trabalho e tempo. Tenha isso em mente e vá para a API que lhe dará a flexibilidade para trocar bibliotecas de registro no futuro. Assim como com a troca do Log4j para Logback e para Log4j 2, ao utilizar a API do SLF4J a única coisa que você precisa fazer é mudar a dependência, não o código.
Se você é novo em bibliotecas de log Java, confira nossos guias para iniciantes:
- Log4j Tutorial
- Logback Tutorial
- Log4j2 Tutorial
- SLF4J Tutorial
Selecione seus Appenders Sabiamente
Aplicadores definem onde seus eventos de log serão entregues. Os appenders mais comuns são o Console e o File Appenders. Embora úteis e amplamente conhecidos, eles podem não preencher os seus requisitos. Por exemplo, você pode querer escrever seus logs de forma assíncrona ou você pode querer enviar seus logs pela rede usando appenders como o do Syslog, como este:
<Appenders> <Console name="Console" target="SYSTEM_OUT"> <PatternLayout pattern="%d %level %c - %m%n"/> </Console> <Syslog name="Syslog" host="logsene-syslog-receiver.sematext.com" port="514" protocol="TCP" format="RFC5424" appName="11111111-2222-3333-4444-555555555555" facility="LOCAL0" mdcId="mdc" newLine="true"/></Appenders>
No entanto, tenha em mente que usar appenders como o mostrado acima torna seu pipeline de logs suscetível a erros de rede e interrupções de comunicação. Isso pode resultar em logs não serem enviados para o seu destino, o que pode não ser aceitável. Você também quer evitar que o registro de dados afete seu sistema se o appender for projetado de forma bloqueadora. Para saber mais, verifique nosso blog Logging libraries vs Log shippers post.
Use Meaningful Messages
Uma das coisas cruciais quando se trata de criar logs, mas uma das não tão fáceis é usar mensagens significativas. Seus eventos de log devem incluir mensagens que sejam exclusivas para a situação dada, descreva-as claramente e informe a pessoa que as lê. Imagine que ocorreu um erro de comunicação na sua aplicação. Você pode fazê-lo assim:
LOGGER.warn("Communication error");
Mas você também pode criar uma mensagem como esta:
LOGGER.warn("Error while sending documents to events Elasticsearch server, response code %d, response message %s. The message sending will be retried.", responseCode, responseMessage);
Você pode facilmente ver que a primeira mensagem irá informar a pessoa que está olhando para os logs sobre alguns problemas de comunicação. Essa pessoa provavelmente terá o contexto, o nome do logger, e o número da linha onde o aviso aconteceu, mas isso é tudo. Para obter mais contexto essa pessoa teria de olhar para o código, saber a que versão do código o erro está relacionado, e assim por diante. Isto não é divertido e muitas vezes não é fácil, e certamente não é algo que se queira fazer enquanto se tenta resolver um problema de produção o mais rápido possível.
A segunda mensagem é melhor. Ela fornece informações exatas sobre que tipo de erro de comunicação aconteceu, o que a aplicação estava fazendo no momento, que código de erro recebeu e qual foi a resposta do servidor remoto. Finalmente, também informa que o envio da mensagem será novamente testado. Trabalhar com tais mensagens é definitivamente mais fácil e mais agradável.
Finalmente, pense sobre o tamanho e verbosidade da mensagem. Não registe informação que seja demasiado verbosa. Estes dados precisam ser armazenados em algum lugar para que sejam úteis. Uma mensagem muito longa não será um problema, mas se essa linha estiver repetindo centenas de vezes em um minuto e você tiver muitos registros verbosos, manter uma retenção mais longa desses dados pode ser problemático e, no final do dia, também custará mais.
Logging Java Stack Traces
Uma das partes muito importantes do registro Java são os traços da pilha Java. Dê uma olhada no seguinte código:
package com.sematext.blog.logging;import org.apache.logging.log4j.LogManager;import org.apache.logging.log4j.Logger;import java.io.IOException;public class Log4JExceptionNoThrowable { private static final Logger LOGGER = LogManager.getLogger(Log4JExceptionNoThrowable.class); public static void main(String args) { try { throw new IOException("This is an I/O error"); } catch (IOException ioe) { LOGGER.error("Error while executing main thread"); } }}
O código acima resultará em uma exceção sendo lançada e uma mensagem de log que será impressa no console com a nossa configuração padrão terá a seguinte aparência:
11:42:18.952 ERROR - Error while executing main thread
Como você pode ver não há muita informação lá. Só sabemos que o problema ocorreu, mas não sabemos onde aconteceu, ou qual foi o problema, etc. Não muito informativo.
Agora, olhe para o mesmo código com uma declaração de registo ligeiramente modificada:
package com.sematext.blog.logging;import org.apache.logging.log4j.LogManager;import org.apache.logging.log4j.Logger;import java.io.IOException;public class Log4JException { private static final Logger LOGGER = LogManager.getLogger(Log4JException.class); public static void main(String args) { try { throw new IOException("This is an I/O error"); } catch (IOException ioe) { LOGGER.error("Error while executing main thread", ioe); } }}
Como pode ver, desta vez incluímos o próprio objecto de excepção na nossa mensagem de registo:
LOGGER.error("Error while executing main thread", ioe);
Isso resultaria no seguinte registo de erros no console com a nossa configuração padrão:
11:30:17.527 ERROR - Error while executing main threadjava.io.IOException: This is an I/O error at com.sematext.blog.logging.Log4JException.main(Log4JException.java:13)
Contém informação relevante – i.e. o nome da classe, o método onde o problema ocorreu, e finalmente o número da linha onde o problema aconteceu. Claro, em situações da vida real, os traços da pilha serão mais longos, mas você deve incluí-los para lhe dar informação suficiente para uma depuração adequada.
Para aprender mais sobre como lidar com os traços da pilha Java com a Logstash veja Manuseando Traços de Pilha Multiline com a Logstash ou veja o Logagent que pode fazer isso para você fora da caixa.
Logging Java Exceptions
Quando lidar com exceções Java e traços de pilha você não deve pensar apenas no traço de pilha inteira, nas linhas onde o problema apareceu, e assim por diante. Você também deve pensar em como não lidar com exceções.
Anular silenciosamente ignorando as exceções. Você não quer ignorar algo importante. Por exemplo, não faça isto:
try { throw new IOException("This is an I/O error");} catch (IOException ioe) {}
Também, não se limite a registar uma excepção e atire-a mais longe. Isso significa que você apenas empurrou o problema para a pilha de execução. Evite coisas como esta também:
try { throw new IOException("This is an I/O error");} catch (IOException ioe) { LOGGER.error("I/O error occurred during request processing", ioe); throw ioe;}
Se você estiver interessado em aprender mais sobre exceções, leia nosso guia sobre o tratamento de exceções Java onde nós cobrimos tudo desde o que elas são até como pegá-las e corrigi-las.
Use Appropriate Log Level
Quando escrever seu código de aplicação pense duas vezes sobre uma determinada mensagem de log. Nem toda informação é igualmente importante e nem toda situação inesperada é um erro ou uma mensagem crítica. Além disso, usando os níveis de log consistentemente – informações de um tipo similar devem estar em um nível de severidade similar.
Both SLF4J fachada e cada estrutura de log Java que você estará usando fornecer métodos que podem ser usados para fornecer um nível de log apropriado. Por exemplo:
LOGGER.error("I/O error occurred during request processing", ioe);
Log in JSON
Se planejamos registrar e olhar os dados manualmente em um arquivo ou na saída padrão, então o registro planejado será mais do que bom. É mais fácil de usar – estamos acostumados a isso. Mas isso só é viável para aplicações muito pequenas e mesmo assim é sugerido usar algo que lhe permita correlacionar os dados de métrica com os logs. Fazer tais operações em uma janela de terminal não é divertido e às vezes simplesmente não é possível. Se você quiser armazenar os logs no sistema de gerenciamento e centralização de logs, você deve fazer o login no JSON. Isso porque a análise não vem de graça – normalmente significa usar expressões regulares. É claro que você pode pagar esse preço no expedidor de logs, mas por que fazer isso se você pode facilmente logar no JSON. Logar no JSON também significa fácil manuseio de traços de pilha, portanto, mais uma vantagem. Bem, você também pode simplesmente logar em um destino compatível com Syslog, mas isso é uma história diferente.
Na maioria dos casos, para habilitar o log in JSON em sua estrutura de log Java é suficiente incluir a configuração adequada. Por exemplo, vamos assumir que temos a seguinte mensagem de log incluída no nosso código:
LOGGER.info("This is a log message that will be logged in JSON!");
Para configurar o Log4J 2 para escrever mensagens de log no JSON incluiríamos a seguinte configuração:
<?xml version="1.0" encoding="UTF-8"?><Configuration status="WARN"> <Appenders> <Console name="Console" target="SYSTEM_OUT"> <JSONLayout compact="true" eventEol="true"> </JSONLayout> </Console> </Appenders> <Loggers> <Root level="info"> <AppenderRef ref="Console"/> </Root> </Loggers></Configuration>
O resultado seria o seguinte:
{"instant":{"epochSecond":1596030628,"nanoOfSecond":695758000},"thread":"main","level":"INFO","loggerName":"com.sematext.blog.logging.Log4J2JSON","message":"This is a log message that will be logged in JSON!","endOfBatch":false,"loggerFqcn":"org.apache.logging.slf4j.Log4jLogger","threadId":1,"threadPriority":5}
Calme a Estrutura de Log Consistente
A estrutura dos seus eventos de log deve ser consistente. Isto não é apenas verdade dentro de uma única aplicação ou conjunto de microserviços, mas deve ser aplicado em toda a sua pilha de aplicações. Com eventos de log estruturados de forma similar será mais fácil de olhar para eles, compará-los, correlacioná-los ou simplesmente armazená-los em um armazenamento de dados dedicado. É mais fácil olhar para os dados provenientes dos seus sistemas quando você sabe que eles têm campos comuns como gravidade e nome da máquina, assim você pode facilmente fatiar e cortar os dados com base nessa informação. Para inspiração, dê uma olhada no Esquema Comum do Sematext mesmo que você não seja um usuário do Sematext.
Obviamente, manter a estrutura nem sempre é possível, porque sua pilha completa consiste de servidores, bancos de dados, mecanismos de busca, filas, etc. desenvolvidos externamente, cada um dos quais tem seu próprio conjunto de logs e formatos de log. No entanto, para manter a sanidade da sua equipa e da sua equipa, minimize o número de diferentes estruturas de mensagens de registo que pode controlar.
Uma forma de manter uma estrutura comum é usar o mesmo padrão para os seus registos, pelo menos os que estão a usar a mesma estrutura de registo. Por exemplo, se suas aplicações e microserviços usam Log4J 2 você poderia usar um padrão como este:
<PatternLayout> <Pattern>%d %p %c{35}:%L - %m%n</Pattern></PatternLayout>
Usando um único ou muito limitado conjunto de padrões você pode ter certeza que o número de formatos de log permanecerá pequeno e gerenciável.
Adicionar contexto aos seus logs
Contexto de informação é importante e para nós desenvolvedores e DevOps uma mensagem de log é informação. Veja a seguinte entrada de log:
An error occurred!
Sabemos que um erro apareceu em algum lugar na aplicação. Nós não sabemos onde aconteceu, não sabemos que tipo de erro foi, só sabemos quando aconteceu. Agora olhe para uma mensagem com um pouco mais de informação contextual:
com.sematext.blog.logging.ParsingErrorExample - A parsing error occurred for user with id 1234!
O mesmo registro de log, mas muito mais informação contextual. Sabemos a thread em que aconteceu, sabemos em que classe o erro foi gerado. Modificamos a mensagem também para incluir o usuário para o qual o erro aconteceu, para que possamos voltar ao usuário se necessário. Também podemos incluir informações adicionais como contextos de diagnóstico. Pense no que você precisa e inclua.
Para incluir informação de contexto você não precisa fazer muito quando se trata do código que é responsável por gerar a mensagem de log. Por exemplo, o PatternLayout no Log4J 2 dá-lhe tudo o que precisa para incluir a informação de contexto. Você pode ir com um padrão muito simples como este:
<PatternLayout pattern="%d{HH:mm:ss.SSS} %-5level - %msg%n"/>
Que resultará em uma mensagem de log semelhante à seguinte:
17:13:08.059 INFO - This is the first INFO level log message!
Mas você também pode incluir um padrão que incluirá muito mais informações:
<PatternLayout pattern="%d{HH:mm:ss.SSS} %c %l %-5level - %msg%n"/>
Que resultará numa mensagem de log como esta:
17:24:01.710 com.sematext.blog.logging.Log4j2 com.sematext.blog.logging.Log4j2.main(Log4j2.java:12) INFO - This is the first INFO level log message!
Java Logging in Containers
Pense sobre o ambiente em que a sua aplicação vai ser executada. Há uma diferença na configuração de registro quando você está executando seu código Java em uma VM ou em uma máquina bare-metal, é diferente quando você está executando em um ambiente em container, e é claro, é diferente quando você executa seu código Java ou Kotlin em um dispositivo Android.
Para configurar o registro em um ambiente em container você precisa escolher a abordagem que você quer tomar. Você pode usar um dos drivers de registro fornecidos – como o journald, logagent, Syslog ou arquivo JSON. Para fazer isso, lembre-se que sua aplicação não deve escrever o arquivo de log no armazenamento efêmero do contêiner, mas na saída padrão. Isso pode ser feito facilmente configurando sua estrutura de registro para escrever o registro no console. Por exemplo, com o Log4J 2 você usaria apenas a seguinte configuração do appender:
<Appenders> <Console name="Console" target="SYSTEM_OUT"> <PatternLayout pattern="%d{HH:mm:ss.SSS} - %m %n"/> </Console></Appenders>
Você também pode omitir completamente os drivers de log e enviar logs diretamente para sua solução centralizada de logs como nossa nuvem de Sematext:
<Appenders> <Console name="Console" target="SYSTEM_OUT"> <PatternLayout pattern="%d %level %c - %m%n"/> </Console> <Syslog name="Syslog" host="logsene-syslog-receiver.sematext.com" port="514" protocol="TCP" format="RFC5424" appName="11111111-2222-3333-4444-555555555555" facility="LOCAL0" mdcId="mdc" newLine="true"/></Appenders>
Não faça Log Too Much ou Too Little
Como desenvolvedores nós tendemos a pensar que tudo pode ser importante – nós tendemos a marcar cada passo de nosso algoritmo ou código de negócios como importante. Por outro lado, às vezes fazemos o oposto – não adicionamos logs onde deveríamos ou apenas registramos níveis de log FATAL e ERROR. Ambas as abordagens não vão funcionar muito bem. Ao escrever seu código e adicionar log, pense no que será importante para ver se a aplicação está funcionando corretamente e o que será importante para ser capaz de diagnosticar um estado errado da aplicação e corrigi-lo. Use isto como sua luz de orientação para decidir o que e onde registrar. Tenha em mente que adicionar demasiados logs irá acabar em fadiga de informação e não ter informação suficiente irá resultar na incapacidade de resolução de problemas.
Keep the Audience in Mind
Na maioria dos casos, você não será a única pessoa a olhar para os logs. Lembre-se sempre disso. Há vários atores que podem estar olhando para os logs.
O desenvolvedor pode estar olhando para os logs para resolução de problemas ou durante as sessões de depuração. Para tais pessoas, os logs podem ser detalhados, técnicos e incluir informações muito profundas relacionadas com a forma como o sistema está a funcionar. Tal pessoa também terá acesso ao código ou mesmo saberá o código e você pode assumir que.
Então existem DevOps. Para eles, eventos de log serão necessários para a resolução de problemas e devem incluir informações úteis no diagnóstico. Você pode assumir o conhecimento do sistema, sua arquitetura, seus componentes e a configuração dos componentes, mas você não deve assumir o conhecimento sobre o código da plataforma.
Finalmente, os logs da sua aplicação podem ser lidos pelos próprios usuários. Nesse caso, os logs devem ser descritivos o suficiente para ajudar a corrigir o problema se isso for possível ou dar informações suficientes para a equipe de suporte ajudar o usuário. Por exemplo, usar Sematext para monitoramento envolve a instalação e execução de um agente de monitoramento. Se você estiver por trás de um firewall muito restritivo e o agente não puder enviar métricas para o Sematext, ele registra erros que visam que os próprios usuários do Sematext também possam olhar.
Podemos ir mais longe e identificar ainda mais actores que possam estar a olhar para os registos, mas esta lista restrita deve dar-lhe um vislumbre do que deve pensar quando escrever as suas mensagens de registo.
Anular Informação Sensível de Registo
A informação sensível não deve estar presente nos registos ou deve ser mascarada. Senhas, números de cartões de crédito, números de segurança social, fichas de acesso, etc. – tudo isso pode ser perigoso se vazado ou acessado por aqueles que não devem ver isso. Há duas coisas que você deve considerar.
Pense se a informação sensível é realmente essencial para a resolução de problemas. Talvez ao invés de um número de cartão de crédito, é suficiente manter as informações sobre o identificador da transação e a data da transação? Talvez não seja necessário manter o número de segurança social nos logs quando você pode facilmente armazenar o identificador do usuário. Pense em tais situações, pense nos dados que você armazena, e só escreva dados sensíveis quando for realmente necessário.
A segunda coisa é enviar os logs com informações sensíveis para um serviço de logs hospedado. Há muito poucas exceções onde os seguintes conselhos não devem ser seguidos. Se os seus logs têm e precisam de ter informação sensível armazenada, mascare-os ou remova-os antes de os enviar para o seu armazém centralizado de logs. Os expedidores de logs mais populares, como nosso próprio Logagent, incluem funcionalidade que permite a remoção ou mascaramento de dados sensíveis.
Finalmente, o mascaramento de informações sensíveis pode ser feito na própria estrutura de logs. Vamos ver como isso pode ser feito estendendo o Log4j 2. Nosso código que produz eventos de log parece ser o seguinte (exemplo completo pode ser encontrado no Sematext Github):
public class Log4J2Masking { private static Logger LOGGER = LoggerFactory.getLogger(Log4J2Masking.class); private static final Marker SENSITIVE_DATA_MARKER = MarkerFactory.getMarker("SENSITIVE_DATA_MARKER"); public static void main(String args) { LOGGER.info("This is a log message without sensitive data"); LOGGER.info(SENSITIVE_DATA_MARKER, "This is a a log message with credit card number 1234-4444-3333-1111 in it"); }}
Se você tivesse que executar todo o exemplo do Github o output seria o seguinte:
21:20:42.099 - This is a log message without sensitive data21:20:42.101 - This is a a log message with credit card number ****-****-****-**** in it
Você pode ver que o número do cartão de crédito foi mascarado. Isto foi feito porque adicionamos um conversor personalizado que verifica se o Marcador dado é passado ao longo do evento de log e tenta substituir um padrão definido. A implementação de tal Conversor tem a seguinte aparência:
@Plugin(name = "sample_logging_mask", category = "Converter")@ConverterKeys("sc")public class LoggingConverter extends LogEventPatternConverter { private static Pattern PATTERN = Pattern.compile("\b({4})-({4})-({4})-({4})\b"); public LoggingConverter(String options) { super("sc", "sc"); } public static LoggingConverter newInstance(final String options) { return new LoggingConverter(options); } @Override public void format(LogEvent event, StringBuilder toAppendTo) { String message = event.getMessage().getFormattedMessage(); String maskedMessage = message; if (event.getMarker() != null && "SENSITIVE_DATA_MARKER".compareToIgnoreCase(event.getMarker().getName()) == 0) { Matcher matcher = PATTERN.matcher(message); if (matcher.find()) { maskedMessage = matcher.replaceAll("****-****-****-****"); } } toAppendTo.append(maskedMessage); }}
É muito simples e poderia ser escrito de uma forma mais otimizada e também deveria lidar com todos os formatos de números de cartão de crédito possíveis, mas é o suficiente para este propósito.
Antes de saltar para a explicação do código eu também gostaria de mostrar o arquivo de configuração log4j2.xml para este exemplo:
<?xml version="1.0" encoding="UTF-8"?><Configuration status="WARN" packages="com.sematext.blog.logging"> <Appenders> <Console name="Console" target="SYSTEM_OUT"> <PatternLayout pattern="%d{HH:mm:ss.SSS} - %sc %n"/> </Console> </Appenders> <Loggers> <Root level="info"> <AppenderRef ref="Console"/> </Root> </Loggers></Configuration>
Como você pode ver, nós adicionamos o atributo pacotes na nossa Configuração para dizer ao framework onde procurar o nosso conversor. Depois usamos o padrão %sc para fornecer a mensagem de log. Nós fazemos isso porque não podemos sobrescrever o padrão padrão %m. Assim que o Log4j2 encontrar o nosso padrão %sc ele usará o nosso conversor que toma a mensagem formatada do evento de log e usa um simples regex e substitui os dados se forem encontrados. Tão simples como isso.
Uma coisa a notar aqui é que estamos a usar a funcionalidade Marker. O Regex matching é caro e não queremos fazer isso para cada mensagem de log. É por isso que marcamos os eventos de log que devem ser processados com o Marcador criado, assim apenas os marcados são verificados.
Utilizar uma Solução de Gerenciamento de Logs para Centralizar & Monitorar Logs Java
Com a complexidade das aplicações, o volume dos seus logs também irá crescer. Você pode escapar com o registro em um arquivo e usar os logs somente quando a solução de problemas for necessária, mas quando a quantidade de dados crescer, torna-se rapidamente difícil e lento resolver os problemas desta maneira. Quando isto acontecer, considere o uso de uma solução de gerenciamento de logs para centralizar e monitorar seus logs. Você pode optar por uma solução interna baseada no software de código aberto, como Elastic Stack, ou usar uma das ferramentas de gerenciamento de logs disponíveis no mercado como Sematext Logs.
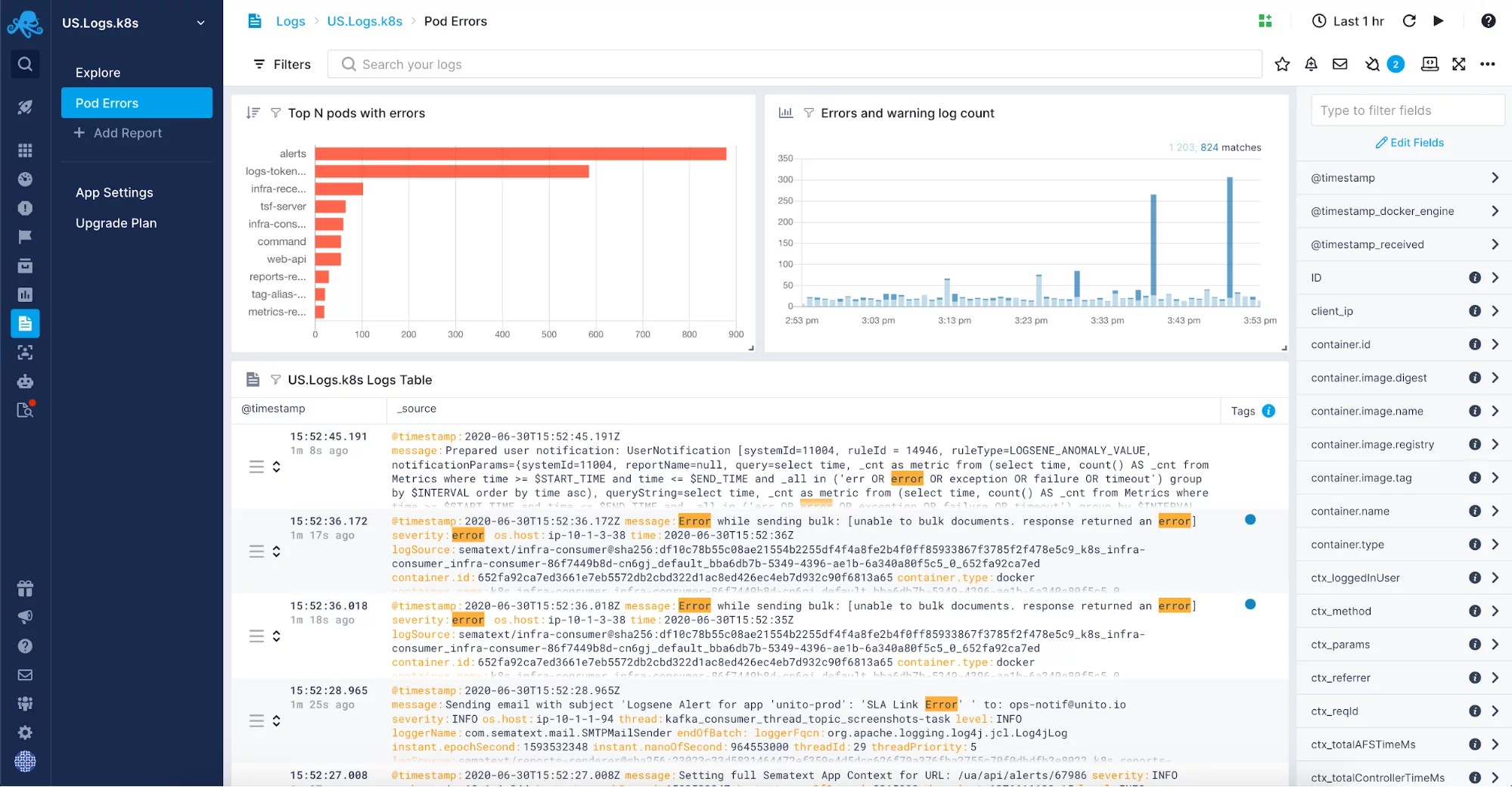
Uma solução de centralização de logs totalmente gerenciada lhe dará a liberdade de não precisar gerenciar mais uma parte, geralmente bastante complexa, de sua infra-estrutura. Em vez disso, você será capaz de se concentrar em sua aplicação e precisará configurar apenas o envio de logs. Você pode querer incluir logs como os logs de coleta de lixo da JVM na sua solução de gerenciamento de logs. Depois de ativá-los para suas aplicações e sistemas trabalhando na JVM você vai querer agregar logs em um único lugar para correlação de logs, análise de logs e para ajudá-lo a sintonizar a coleta de lixo nas instâncias da JVM. Tais logs correlacionados com métricas são uma fonte inestimável de informações para solucionar problemas relacionados à coleta de lixo.
Se você estiver interessado em ver como os logs Sematext se acumulam contra soluções similares, vá para o nosso artigo sobre o melhor software de gerenciamento de logs ou para o post do blog onde revisamos algumas das principais ferramentas de análise de logs, mas recomendamos que você use o teste gratuito de 14 dias para explorar completamente suas funcionalidades. Experimente e veja por si mesmo!
Conclusion
Incorporar toda e qualquer boa prática pode não ser fácil de implementar de imediato, especialmente para aplicações que já estão vivas e funcionando em produção. Mas se você tomar o tempo e lançar as sugestões uma após a outra, você começará a ver um aumento na utilidade dos seus logs. Para mais dicas de como tirar o máximo proveito de seus logs, recomendamos que você também leia nosso outro artigo sobre as melhores práticas de logaritmo, onde explicamos e insistimos que você deve seguir, independentemente do tipo de aplicativo com o qual você está trabalhando. E lembre-se que na Sematext ajudamos as organizações com suas configurações de logging, oferecendo consultoria em logging, portanto, se você estiver tendo problemas, ficaremos felizes em ajudar.
Deixe uma resposta