As pessoas estão criando, compartilhando e armazenando dados a uma taxa mais rápida do que em qualquer outro momento da história. Quando se trata de inovar no armazenamento e transmissão desses dados, no Facebook estamos fazendo avanços não apenas em hardware – como discos rígidos maiores e equipamentos de rede mais rápidos – mas também em software. O software ajuda no processamento de dados através da compressão, que codifica informações, como texto, imagens e outras formas de dados digitais, usando menos bits do que o original. Esses arquivos menores ocupam menos espaço nos discos rígidos e são transmitidos mais rapidamente para outros sistemas. No entanto, há um trade-off para a compressão e descompressão de informações: o tempo. Quanto mais tempo gasto na compressão de um arquivo menor, mais lento os dados são para processar.
Hoje, o padrão atual de compressão de dados é Deflate, o algoritmo do núcleo dentro do Zip, gzip, e zlib . Por duas décadas, ele tem fornecido um equilíbrio impressionante entre velocidade e espaço, e, como resultado, é usado em quase todos os dispositivos eletrônicos modernos (e, não coincidentemente, usado para transmitir cada byte do próprio post do blog que você está lendo). Ao longo dos anos, outros algoritmos têm oferecido ou melhor compressão ou compressão mais rápida, mas raramente ambos. Acreditamos que mudamos isso.
Estamos felizes em anunciar o Zstandard 1.0, um novo algoritmo de compressão e implementação projetado para escalar com hardware moderno e comprimir de forma menor e mais rápida. O Zstandard combina avanços recentes na compressão, como a Entropia Finita State, com um projeto de performance-first – e depois otimiza a implementação para as propriedades exclusivas das CPUs modernas. Como resultado, melhora os trade-offs feitos por outros algoritmos de compressão e tem uma ampla gama de aplicabilidade com velocidade de descompressão muito alta. O Zstandard, disponível agora sob a licença BSD, foi projetado para ser usado em quase todos os cenários de compressão sem perdas, incluindo muitos onde os algoritmos atuais não são aplicáveis.
- Compressão de comparação
- Scalabilidade
- Baixo do capô
- Memória
- Um formato projetado para execução paralela
- Design sem ranhura
- Entropia de Estado Finito: Um compressor de probabilidade de próxima geração
- Modelagem de código de barras
- Zstandard na prática
- Dados pequenos
- Dicionários em ação
- Picking a compression level
- Try it out
- Mais para vir
Compressão de comparação
Existem três métricas padrão para comparar algoritmos de compressão e implementações:
- Rácio de compressão: O tamanho original (numerador) comparado com o tamanho comprimido (denominador), medido em dados sem unidade como uma razão de tamanho de 1,0 ou maior.
- Velocidade de compressão: Quão rapidamente podemos tornar os dados menores, medidos em MB/s dos dados de entrada consumidos.
- Velocidade de descompressão: Quão rapidamente podemos reconstruir os dados originais a partir dos dados comprimidos, medidos em MB/s para a taxa a que os dados são produzidos a partir dos dados comprimidos.
O tipo de dados a serem comprimidos pode afectar estas métricas, por isso muitos algoritmos são sintonizados para tipos específicos de dados, tais como texto em inglês, sequências genéticas, ou imagens rasterizadas. Entretanto, o Zstandard, assim como o zlib, é destinado à compressão de propósito geral para uma variedade de tipos de dados. Para representar os algoritmos em que a Zstandard deve trabalhar, neste post vamos usar o Silesia corpus, um conjunto de arquivos de dados que representam os tipos de dados típicos usados no dia-a-dia.
Algoritmos e implementações comumente usadas atualmente são zlib, lz4, e xz. Cada um destes algoritmos oferece diferentes trade-offs: lz4 visa a velocidade, xz visa rácios de compressão mais altos e zlib visa um bom equilíbrio de velocidade e tamanho. A tabela abaixo indica os trade-offs aproximados da taxa de compressão padrão dos algoritmos e velocidade para o corpus da Silesia, comparando os algoritmos por lzbench, um parâmetro de referência in-memory puro, destinado a modelar o desempenho do algoritmo bruto.
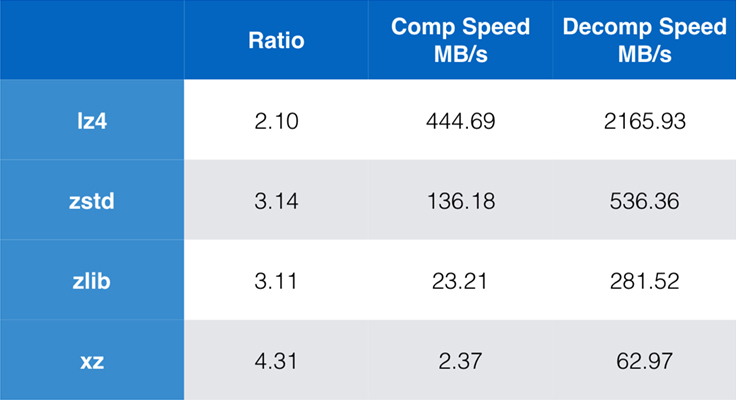
Como delineado, há frequentemente compromissos drásticos entre velocidade e tamanho. O algoritmo mais rápido, lz4, resulta em menores taxas de compressão; xz, que tem a maior taxa de compressão, sofre de uma velocidade de compressão lenta. Entretanto, o Zstandard, na configuração padrão, mostra melhorias substanciais tanto na velocidade de compressão quanto na velocidade de descompressão, enquanto comprime na mesma proporção que o zlib.
Embora o desempenho puro do algoritmo seja importante quando a compressão é embutida em um aplicativo maior, é extremamente comum também usar ferramentas de linha de comando para compressão – digamos, para compressão de arquivos de log, tarballs, ou outros dados similares destinados ao armazenamento ou transferência. Nesses casos, o desempenho é muitas vezes afetado pelo overhead, como o checksumming. Este gráfico mostra a comparação das ferramentas de linha de comando gzip e zstd no Centos 7 construído com o compilador padrão do sistema.
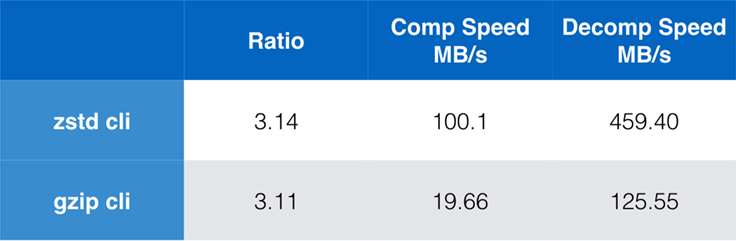
Os testes foram conduzidos 10 vezes cada um, com os tempos mínimos tomados, e foram conduzidos no ramdisk para evitar a sobrecarga do sistema de arquivos. Estes foram os comandos (que usam os níveis de compressão padrão para ambas as ferramentas):
zstd -c -3 silesia.tar > silesia.tar.zst # 67,432,740 byteszstd -d -c silesia.tar.zst > /dev/nullgzip -c -6 silesia.tar > silesia.tar.gz # 68,235,522 bytesgzip -d -c silesia.tar.gz > /dev/nullScalabilidade
Se um algoritmo é escalável, ele tem a capacidade de se adaptar a uma grande variedade de requisitos, e o Zstandard foi projetado para se sobressair na paisagem de hoje e escalar para o futuro. A maioria dos algoritmos tem “níveis” baseados em trade-offs de tempo/espaço: Quanto maior o nível, maior é a compressão alcançada com a perda da velocidade de compressão. Zlib oferece nove níveis de compressão; Zstandard oferece atualmente 22, o que permite trade-offs flexíveis e granulares entre a velocidade de compressão e os rácios para dados futuros. Por exemplo, podemos usar o nível 1 se a velocidade for mais importante e o nível 22 se o tamanho for mais importante.
Below é um gráfico da velocidade de compressão e proporção alcançada para todos os níveis de Zstandard e zlib. O eixo x é uma escala logarítmica decrescente em megabytes por segundo; o eixo y é a taxa de compressão alcançada. Para comparar os algoritmos, você pode escolher uma velocidade para ver as várias relações que os algoritmos atingem a essa velocidade. Da mesma forma, você pode escolher uma razão e ver quão rápido os algoritmos são quando eles atingem esse nível.
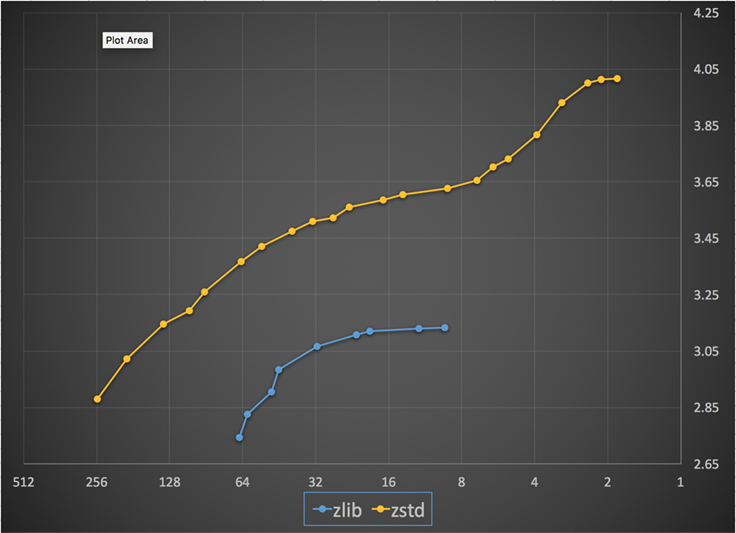
Para qualquer linha vertical (isto é, velocidade de compressão), Zstandard atinge uma razão de compressão maior. Para o corpus Silesia, a velocidade de descompressão – independentemente da razão – foi de aproximadamente 550 MB/s para Zstandard e 270 MB/s para zlib. O gráfico mostra outra diferença entre o Zstandard e as alternativas: Ao usar um algoritmo e implementação, o Zstandard permite uma sintonia muito mais fina para cada caso de uso. Isto significa que o Zstandard pode competir com alguns dos algoritmos de compressão mais rápidos e mais altos, mantendo uma vantagem substancial na velocidade de descompressão. Essas melhorias se traduzem diretamente em transferência de dados mais rápida e requisitos de armazenamento menores.
Em outras palavras, comparado com zlib, escalas Zstandard:
- Na mesma taxa de compressão, ele comprime substancialmente mais rápido: ~3-5x.
- Na mesma velocidade de compressão, é substancialmente menor: 10-15 por cento menor.
- É quase 2x mais rápido na descompressão, independentemente da taxa de compressão; os números de ferramentas da linha de comando mostram uma diferença ainda maior: mais de 3x mais rápido.
- Elava-se a rácios de compressão muito mais altos, enquanto sustentava velocidades de descompressão rápidas como um raio.
Baixo do capô
A zlib melhora com a combinação de várias inovações recentes e visando o hardware moderno:
Memória
Por projeto, a zlib é limitada a uma janela de 32 KB, que foi uma escolha sensata no início dos anos 90. Mas, o ambiente de computação atual pode acessar muito mais memória – mesmo em ambientes móveis e embutidos.
Zstandard não tem limite inerente e pode endereçar terabytes de memória (embora raramente o faça). Por exemplo, o menor dos 22 níveis usa 1 MB ou menos. Para compatibilidade com uma ampla gama de sistemas receptores, onde a memória pode ser limitada, é recomendado limitar o uso de memória a 8 MB. Esta é uma recomendação de ajuste, no entanto, não uma limitação do formato de compressão.
Um formato projetado para execução paralela
As CPUs de hoje são muito poderosas e podem emitir várias instruções por ciclo, graças a múltiplas ALUs (unidades lógicas aritméticas) e cada vez mais avançado projeto de execução fora de ordem.
Em essência, significa que se:
a = b1 + b2
c = d1 + d2
>então ambos a e c serão calculados em paralelo.
Isto só é possível se não houver relação entre eles. Portanto, neste exemplo:
a = b1 + b2
c = d1 + a
c deve esperar que a seja calculado primeiro, e só então será c iniciado o cálculo.
Significa que, para tirar proveito da CPU moderna, é necessário desenhar um fluxo de operações com poucas ou nenhumas dependências de dados.
Isto é conseguido com o padrão Z, separando os dados em múltiplos fluxos paralelos. Um descodificador Huffman de nova geração, Huff0, é capaz de descodificar múltiplos símbolos em paralelo com um único núcleo. Tal ganho é cumulativo com multithreading, que usa múltiplos núcleos.
Design sem ranhura
Novas CPUs são mais potentes e atingem frequências muito altas, mas isto só é possível graças a uma abordagem de múltiplos estágios, onde uma instrução é dividida em um pipeline de múltiplos passos. Em cada ciclo do relógio, a CPU é capaz de emitir o resultado de múltiplas operações, dependendo das ALUs disponíveis. Quanto mais ALUs estiverem sendo usadas, mais trabalho a CPU está fazendo e, portanto, a compressão mais rápida está ocorrendo. Manter as ALUs alimentadas com trabalho é crucial para o desempenho da CPU moderna.
Isso acaba por ser difícil. Considere a seguinte situação simples:
if (condition) doSomething() else doSomethingElse() Quando encontra isto, a CPU não sabe o que fazer, pois depende do valor de condition. Uma CPU cautelosa esperaria pelo resultado de condition antes de trabalhar em qualquer um dos ramos, o que seria extremamente desperdiçador.
As CPUs de hoje jogam. Eles o fazem de forma inteligente, graças a um preditor de ramo, que lhes diz em essência o resultado mais provável da avaliação de condition. Quando a aposta está certa, o pipeline permanece cheio e as instruções são emitidas continuamente. Quando a aposta está errada (uma previsão errada), a CPU tem que parar todas as operações iniciadas especulativamente, voltar para o ramo e tomar a outra direção. Isto é chamado de pipeline flush, e é extremamente caro nas CPUs modernas.
Vinte e cinco anos atrás, o pipeline flush não era um problema. Hoje em dia, é tão importante que é essencial projetar formatos compatíveis com algoritmos sem ramificações. Como exemplo, vejamos uma atualização bit-stream:
/* classic version */while (nbBitsUsed >= 8) { /* each while test is a branch */ accumulator <<= 8; accumulator += *byte++; nbBitsUsed -= 8;} /*>/* branch-less version */nbBytesUsed = nbBitsUsed >> 3;nbBitsUsed &= 7;ptr += nbBytesUsed;accumulator = read64(ptr);Como você pode ver, a versão branchless tem uma carga de trabalho previsível, sem qualquer condição. A CPU fará sempre o mesmo trabalho, e esse trabalho nunca é jogado fora devido a uma previsão errada. Em contraste, a versão clássica faz menos trabalho quando (nbBitsUsed < 8). Mas o teste em si não é gratuito, e sempre que o teste é adivinhado incorretamente, ele resulta em uma descarga total do pipeline, que custa mais do que o trabalho feito pela versão sem ramificações.
Como você pode adivinhar, este efeito colateral tem impacto na forma como os dados são empacotados, lidos e decodificados. Zstandard foi criado para ser amigável a algoritmos sem ramificações, especialmente dentro de loops críticos.
Entropia de Estado Finito: Um compressor de probabilidade de próxima geração
Em compressão, os dados são primeiro transformados em um conjunto de símbolos (o estágio de modelagem), e depois esses símbolos são codificados usando um número mínimo de bits. Este segundo estágio é chamado de estágio de entropia, em memória de Claude Shannon, que calcula com precisão o limite de compressão de um conjunto de símbolos com determinadas probabilidades (chamado de “limite Shannon”). O objetivo é chegar perto deste limite, usando o menor número possível de recursos da CPU.
Um algoritmo muito comum é a codificação de Huffman, em uso dentro de Deflate. Ele dá o melhor código de prefixo possível, assumindo que cada símbolo é descrito com um número natural de bits (1 bit, 2 bits …). Isto funciona muito bem na prática, mas o limite de números naturais significa que é impossível atingir altas taxas de compressão, porque um símbolo consome necessariamente pelo menos 1 bit.
Um método melhor é chamado de codificação aritmética, que pode chegar arbitrariamente perto do limite de Shannon -log2(P), consumindo assim bits fracionários por símbolo. Ele se traduz em uma melhor taxa de compressão quando as probabilidades são altas, mas também usa mais energia da CPU. Na prática, mesmo codificadores aritméticos otimizados lutam por velocidade, especialmente no lado da descompressão, o que requer divisões com um resultado previsível (por exemplo, não um ponto flutuante) e que se mostra lento.
Entropia de Estado Finito é baseada em uma nova teoria chamada ANS (Asymmetric Numeral System) por Jarek Duda. A Entropia de Estado Finito é uma variante que pré-computa muitos passos de codificação em tabelas, resultando em um codec de entropia tão preciso quanto a codificação aritmética, usando apenas adições, buscas em tabelas e turnos, que é mais ou menos o mesmo nível de complexidade de Huffman. Ele também reduz a latência para acessar o próximo símbolo, já que é imediatamente acessível a partir do valor de estado, enquanto Huffman requer uma operação prévia de decodificação de bit-stream. Explicar como ele funciona está fora do escopo deste post, mas se você estiver interessado, há uma série de artigos detalhando seu funcionamento interno.
Modelagem de código de barras
Modelagem de código de barras comprime eficientemente dados estruturados, que apresentam sequências de conteúdo quase equivalente, diferindo por apenas um ou poucos bytes. Este método não é novo mas foi usado pela primeira vez após a publicação de Deflate, portanto não existe dentro da zlib/gzip.
A eficiência da modelagem de repcode depende muito do tipo de dados sendo comprimidos, variando de um único a um melhoramento de compressão de dois dígitos. Estas melhorias combinadas somam-se a uma melhor e mais rápida experiência de compressão, oferecida dentro da biblioteca Zstandard.
Zstandard na prática
Como mencionado anteriormente, existem vários casos típicos de uso de compressão. Para que um algoritmo seja convincente, ele precisa ser extraordinariamente bom em um caso de uso específico, como a compressão de texto legível por humanos, ou muito bom em muitos casos de uso diversos. A norma Z adota esta última abordagem. Uma maneira de pensar sobre casos de uso é quantas vezes um dado específico pode ser descomprimido. O Zstandard tem vantagens em todos estes casos.
Muitas vezes. Para dados processados muitas vezes, a velocidade de descompressão e a capacidade de optar por uma taxa de compressão muito alta sem comprometer a velocidade de descompressão é vantajosa. O armazenamento do gráfico social no Facebook, por exemplo, é lido repetidamente enquanto você e seus amigos interagem com o site. Fora do Facebook, exemplos de quando os dados precisam ser descomprimidos muitas vezes incluem arquivos baixados de um servidor, como o código fonte para o kernel Linux ou os RPMs instalados em servidores, o JavaScript e CSS usado por uma página web, ou rodando milhares de MapReduces sobre dados em um armazém de dados.
Apenas uma vez. Para dados comprimidos apenas uma vez, especialmente para transmissão através de uma rede, a compressão é um momento fugaz no fluxo de dados. Quanto menos sobrecarga tiver no servidor, significa que o servidor pode lidar com mais pedidos por segundo. Quanto menos sobrecarga no cliente significa que os dados podem ser tratados mais rapidamente. Normalmente, isso ocorre em situações cliente/servidor onde os dados são únicos para o cliente, como uma resposta do servidor web que é personalizada – digamos, os dados usados para renderizar quando você recebe uma nota de um amigo no Messenger. O resultado líquido é que o seu dispositivo móvel carrega páginas mais rapidamente, usa menos bateria e consome menos do seu plano de dados. O padrão Z, em particular, adapta-se muito melhor aos cenários móveis do que outros algoritmos por causa de como ele lida com dados pequenos.
Possivelmente nunca. Embora aparentemente contra-intuitivo, é frequentemente o caso de um pedaço de dados – como backups ou arquivos de log – nunca será descompactado, mas pode ser lido se necessário. Para este tipo de dados, a compressão normalmente precisa ser rápida, tornar os dados pequenos (com um trade-off tempo/espaço adequado para a situação), e talvez armazenar um checksum, mas de outra forma ser invisível. Na rara ocasião em que ele precisa ser descomprimido, você não quer que a compressão retarde o caso de uso operacional. A descompressão rápida é benéfica porque muitas vezes é uma pequena parte dos dados (como um arquivo específico no backup ou mensagem em um arquivo de log) que precisa ser encontrada rapidamente.
Em todos esses casos, o Zstandard traz a capacidade de comprimir e descomprimir muitas vezes mais rápido que o gzip, com os dados comprimidos resultantes sendo menores.
Dados pequenos
Há outro caso de uso para compressão que recebe menos atenção, mas pode ser bastante importante: dados pequenos. Estes são padrões de uso onde os dados são produzidos e consumidos em pequenas quantidades, tais como mensagens JSON entre um servidor web e um navegador (normalmente centenas de bytes) ou páginas de dados em um banco de dados (alguns kilobytes).
Bases de dados fornecem um caso de uso interessante. Sistemas como MySQL, PostgreSQL e MongoDB armazenam todos os dados destinados a acesso em tempo real. As recentes vantagens de hardware, particularmente em torno da proliferação de dispositivos flash (SSD), mudaram fundamentalmente o equilíbrio entre tamanho e produção – agora vivemos em um mundo onde os IOPs (operações IO por segundo) são bastante altos, mas a capacidade dos nossos dispositivos de armazenamento é menor do que quando os discos rígidos governavam o centro de dados.
Além disso, o flash tem uma propriedade interessante em relação à resistência de gravação – depois de milhares de gravações na mesma seção do dispositivo, essa seção não pode mais aceitar gravações, muitas vezes levando o dispositivo a ser removido de serviço. Portanto, é natural buscar maneiras de reduzir a quantidade de dados sendo escritos, pois isso pode significar mais dados por servidor e queimar o dispositivo a um ritmo mais lento. A compressão de dados é uma estratégia para isso, e os bancos de dados também são frequentemente otimizados para o desempenho, o que significa que o desempenho de leitura e gravação é igualmente importante.
Mas há uma complicação na utilização da compressão de dados com bancos de dados. Os bancos de dados gostam de acessar dados aleatoriamente, enquanto a maioria dos casos típicos de uso para compressão lêem um arquivo inteiro em ordem linear. Isso é um problema porque a compressão de dados funciona essencialmente prevendo o futuro com base no passado – os algoritmos olham para seus dados sequencialmente e prevêem o que eles podem ver no futuro. Quanto mais precisas forem as previsões, menor pode ser a previsão dos dados.
Quando você está comprimindo dados pequenos, como páginas em uma base de dados ou pequenos documentos JSON sendo enviados para seu dispositivo móvel, simplesmente não há muito “passado” para usar para prever o futuro. Algoritmos de compressão têm tentado resolver isso usando dicionários pré-compartilhados para efetivamente dar o salto inicial. Isso é feito através do pré-sharing de um conjunto estático de dados “passados” como uma semente para a compressão.
Zstandard baseia-se nessa abordagem com algoritmos e APIs altamente otimizados para compressão de dicionários. Além disso, o Zstandard inclui ferramentas (zstd --train) para fazer facilmente dicionários para aplicações personalizadas e provisões para o registro de dicionários padrão para compartilhamento com comunidades maiores. Enquanto a compressão varia com base nas amostras de dados, a compressão de dados pequenos pode variar de 2x a 5x melhor que a compressão sem dicionários.
Dicionários em ação
Embora possa ser difícil jogar com um dicionário no contexto de uma base de dados em execução (requer modificações significativas na base de dados, afinal de contas), você pode ver dicionários em ação com outros tipos de dados pequenos. JSON, a lingua franca dos pequenos dados no mundo moderno, tende a ser registros pequenos e repetitivos. Existem inúmeros conjuntos de dados públicos disponíveis; para o propósito desta demonstração, usaremos o conjunto de dados “usuário” do GitHub, disponível via HTTP. Aqui está um exemplo de entrada deste conjunto de dados:
{ "login": "octocat", "id": 1, "avatar_url": "https://github.com/images/error/octocat_happy.gif", "gravatar_id": "", "url": "https://api.github.com/users/octocat", "html_url": "https://github.com/octocat", "followers_url": "https://api.github.com/users/octocat/followers", "following_url": "https://api.github.com/users/octocat/following{/other_user}", "gists_url": "https://api.github.com/users/octocat/gists{/gist_id}", "starred_url": "https://api.github.com/users/octocat/starred{/owner}{/repo}", "subscriptions_url": "https://api.github.com/users/octocat/subscriptions", "organizations_url": "https://api.github.com/users/octocat/orgs", "repos_url": "https://api.github.com/users/octocat/repos", "events_url": "https://api.github.com/users/octocat/events{/privacy}", "received_events_url": "https://api.github.com/users/octocat/received_events", "type": "User", "site_admin": false }Como você pode ver, há um pouco de repetição aqui – nós podemos comprimir estes bem! Mas cada usuário é um pouco menos de 1 KB, e a maioria dos algoritmos de compressão realmente precisa de mais dados para esticar suas pernas. Um conjunto de 1.000 usuários leva cerca de 850 KB para armazenar sem compressão. Aplicando nativamente ou gzip ou zstd individualmente a cada ficheiro, reduz isto para pouco mais de 300 KB; nada mau! Mas se criarmos um dicionário pré-partilhado único, com zstd o tamanho cai para 122 KB – levando a taxa de compressão original de 2,8x para 6,9. Esta é uma melhoria significativa, disponível fora da caixa com zstd:
$ zstd --train -o ../json.zdict -r .sorting 982 files of total size 0 MB ...finding patterns ...statistics ...Save dictionary of size 65599 into file ../json.zdict$ du -h --apparent-size .846K .$ zstd --rm -D ../json.zdict -r .$ du -h --apparent-size .122K .Picking a compression level
As shown above, Zstandard provides a substantial number of levels. Esta personalização é poderosa, mas leva a escolhas difíceis. A melhor maneira de decidir é rever os seus dados e medir, decidindo que compensações você quer fazer. No Facebook, nós achamos o nível padrão 3 adequado para muitos casos de uso, mas de tempos em tempos, vamos ajustar isso ligeiramente, dependendo de qual é o nosso gargalo (muitas vezes estamos tentando saturar uma conexão de rede ou spindle de disco); outras vezes, nós nos preocupamos mais com o tamanho armazenado e usaremos um nível mais alto.
Ultimamente, para os resultados mais adaptados às suas necessidades, você precisará considerar tanto o hardware que você usa quanto os dados com os quais você se preocupa – não há prescrições rígidas e rápidas que possam ser feitas sem contexto. Quando em dúvida, no entanto, ou se mantém com o nível padrão de 3 ou algo do intervalo de 6 a 9 para um bom trade-off de velocidade versus espaço; salve o nível 20+ para casos onde você realmente se importa apenas com o tamanho e não com a velocidade de compressão.
Try it out
Zstandard é tanto uma ferramenta de linha de comando (zstd) quanto uma biblioteca. Está escrito em C altamente portátil, tornando-o adequado para praticamente todas as plataformas utilizadas actualmente – quer sejam os servidores que gerem o seu negócio, o seu portátil, ou mesmo o telefone no seu bolso. Você pode pegá-lo do nosso repositório github, compilá-lo com um simples make install, e começar a usá-lo como você usaria gzip:
$ zstd access.logaccess.log : 8.07% (6695078 => 540336 bytes, access.log.zst)Como você pode esperar, você pode usá-lo como parte de um pipeline de comandos, por exemplo, para fazer backup do seu banco de dados MySQL crítico:
$ mysqldump --single-transaction --opt pokemon | zstd -q -o /srv/backups/mysqldump.sql.zst O comando tar suporta diferentes implementações de compressão fora da caixa, assim, uma vez que você instala o Zstandard, você pode trabalhar imediatamente com tarballs compactados com o Zstandard. Aqui está um exemplo simples que o mostra em uso com tar e a diferença de velocidade em comparação com o gzip:
$ time tar -I zstd -cf linux-4.6.4.tar.zst linux-4.6.4tar -I zstd -cf linux-4.6.4.tar.zst linux-4.6.4 3.15s user 0.50s system 107% cpu 3.396 total$ time tar -zcf linux-4.6.4.tar.gz linux-4.6.4tar -zcf linux-4.6.4.tar.gz linux-4.6.4 13.74s user 0.43s system 102% cpu 13.784 totalAlém do uso de linha de comando, existem as APIs, documentadas nos arquivos de cabeçalho do repositório (comece aqui para uma visão geral das APIs). Nós também incluímos uma API compatível com a zlib (libWrapper) para facilitar a integração com ferramentas que já possuem interfaces zlib. Finalmente, nós incluímos vários exemplos, tanto de uso básico quanto de uso mais avançado como dicionários e streaming, também no repositório GitHub.
Mais para vir
Embora tenhamos atingido a 1.0 e consideremos o Zstandard pronto para todo tipo de uso de produção, ainda não terminamos. Vindo em versões futuras:
- Compressão de linha de comando multi-tarefa para uma produção ainda mais rápida em grandes conjuntos de dados, semelhante à ferramenta pigz para zlib.
- Novos níveis de compressão, em ambas as direções, permitindo uma compressão ainda mais rápida e relações mais altas.
- Um conjunto pré-definido de dicionários de compressão mantidos pela comunidade para conjuntos de dados comuns, como JSON, HTML e protocolos de rede comuns.
Gostaríamos de agradecer a todos os colaboradores, tanto de código como de feedback, que nos ajudaram a chegar à 1.0. Isto é apenas o começo. Nós sabemos que para que a Zstandard esteja à altura do seu potencial, precisamos da sua ajuda. Como mencionado acima, você pode tentar o Zstandard hoje pegando o código fonte ou binários pré-construídos do nosso projeto GitHub, ou, para usuários Mac, instalando via homebrew (brew install zstd). Adoraríamos qualquer feedback e casos de uso interessantes que você tenha, assim como bindings adicionais de linguagem e ajuda na integração com seus projetos favoritos de código aberto.
Footnotes
- Embora a compressão de dados sem perdas seja o foco deste post, existe um campo relacionado mas muito diferente de compressão de dados com perdas, usado principalmente para imagens, áudio e vídeo.
- Deflate, zlib, gzip – três nomes entrelaçados. Deflate é o algoritmo usado pelas implementações da zlib e do gzip. Zlib é uma biblioteca que fornece Deflate, e gzip é uma ferramenta de linha de comando que usa zlib para Deflating data, bem como checksumming. Este checksumming pode ter overhead significativo.
- Todos os benchmarks foram executados em um Intel E5-2678 v3 rodando a 2,5 GHz em uma máquina Centos 7. Ferramentas de linha de comando (
zstdegzip) foram construídas com o sistema GCC, 4.8.5. Algoritmos de referência realizados pelo lzbench foram construídos com o GCC, 6.
Deixe uma resposta