Neste post, vamos dar uma olhada nos algoritmos de aprendizagem de máquinas mais amplamente utilizados. Existe uma enorme variedade deles, e é fácil sentir-se confuso quando se ouvem termos como “algoritmos de aprendizagem baseados em instância” e “perceptron”.
Usualmente, todos os algoritmos de aprendizagem de máquinas são divididos em grupos baseados no seu estilo de aprendizagem, função, ou nos problemas que resolvem. Neste post, você encontrará uma classificação baseada no estilo de aprendizagem. Também mencionarei as tarefas comuns que estes algoritmos ajudam a resolver.
O número de algoritmos de aprendizagem de máquina que são usados hoje em dia é grande, e não mencionarei 100% deles. Entretanto, eu gostaria de fornecer uma visão geral dos mais usados.
- Supervised learning algorithms
- Classificação de algoritmos
- Naive Bayes
- Multinomial Naive Bayes
- Regessão logística
- Árvores de decisão
- SVM (Support Vector Machine)
- Algoritmos de regressão
- Regressão linear
- Algoritmos de aprendizagem não supervisionada
- Clustering
- K significa clustering
- K-nearest neighbor
- Dimensionalidade reduzida
- Asociation rule learning
- Aprendizagem de reforço
- Q-Learning
- Ensemble learning
- Bagging
- Boosting
- Florestas aleatórias
- Aferição
- Redes neurais
- Conclusão
Supervised learning algorithms

Se você não está familiarizado com termos como “supervisioned learning” e “unsupervised learning”, confira nosso post AI vs. ML onde este tópico é abordado em detalhes. Agora, vamos nos familiarizar com os algoritmos.
Classificação de algoritmos
Naive Bayes

Os algoritmos Bayesianos são uma família de classificadores probabilísticos usados no ML baseados na aplicação do teorema de Bayes.
Naive classificador Bayes foi um dos primeiros algoritmos utilizados para a aprendizagem de máquinas. Ele é adequado para classificação binária e multiclasse e permite fazer previsões e dados de previsão com base em resultados históricos. Um exemplo clássico é o sistema de filtragem de spam que usou Naive Bayes até 2010 e mostrou resultados satisfatórios. Entretanto, quando o envenenamento Bayesiano foi inventado, os programadores começaram a pensar em outras maneiras de filtrar dados.
Usando o teorema de Bayes, é possível dizer como a ocorrência de um evento impacta a probabilidade de outro evento.
Por exemplo, este algoritmo calcula a probabilidade de um determinado email ser ou não spam com base nas palavras típicas usadas. Palavras comuns de spam são “oferta”, “encomendar agora”, ou “rendimento adicional”. Se o algoritmo detectar essas palavras, há uma grande possibilidade de que o e-mail seja spam.
Naive Bayes assume que as características são independentes. Portanto, o algoritmo é chamado de naive.
Multinomial Naive Bayes
Parte do classificador Naive Bayes, existem outros algoritmos neste grupo. Por exemplo, Multinomial Naive Bayes, que é normalmente aplicado para classificação de documentos com base na freqüência de certas palavras presentes no documento.
Algoritmos bayesianos ainda são usados para categorização de texto e detecção de fraude. Eles também podem ser aplicados para visão mecânica (por exemplo, detecção de face), segmentação de mercado e bioinformática.
Regessão logística
Even embora o nome possa parecer contra-intuitivo, a regressão logística é na verdade um tipo de algoritmo de classificação.
Regessão logística é um modelo que faz previsões usando uma função logística para encontrar a dependência entre as variáveis de saída e entrada. Statquest fez um ótimo vídeo onde eles explicam a diferença entre regressão linear e logística tomando como exemplo ratos obesos.
Árvores de decisão
Uma árvore de decisão é uma maneira simples de visualizar um modelo de tomada de decisão na forma de uma árvore. As vantagens das árvores de decisão são que elas são fáceis de entender, interpretar e visualizar. Além disso, elas exigem pouco esforço na preparação dos dados.
No entanto, elas também têm uma grande desvantagem. As árvores podem ser instáveis devido até mesmo às menores variações (variância) nos dados. Também é possível criar árvores super-complexas que não se generalizam bem. Isto é chamado de sobreajustamento. Ensacar, impulsionar e regularizar ajuda a combater este problema. Vamos falar sobre eles mais tarde no post.
Os elementos de cada árvore de decisão são:
- Nó de raiz que faz a pergunta principal. Ele tem as setas apontando para baixo a partir dele, mas nenhuma seta apontando para ele. Por exemplo, imagine que você está construindo uma árvore para decidir que tipo de massa você deve ter para o jantar.
- Branches. Uma subseção de uma árvore é chamada de ramo ou às vezes de sub-árvore.
- Nós de decisão. Estes são os sub-nós para o nó raiz que também podem ser divididos em mais nós. Os seus nós de decisão podem ser “carbonara?” ou “com cogumelos?”.
- Leaves ou nós terminais. Estes nós não se dividem. Eles representam decisões ou previsões finais.
Também, é importante mencionar a divisão. Este é o processo de divisão de um nó em subnós. Por exemplo, se você não é vegetariano, carbonara está bem. Mas se você for, coma massa com cogumelos. Há também um processo de remoção de nós chamado poda.
Algoritmos de árvore de decisão são chamados de CART (Árvores de Classificação e Regressão). Árvores de decisão podem funcionar com dados categóricos ou numéricos.
- Árvores de regressão são usadas quando as variáveis têm valor numérico.
- Árvores de classificação podem ser aplicadas quando os dados são categóricos (classes).
Árvores de decisão são bastante intuitivas de entender e usar. É por isso que os diagramas de árvores são comumente aplicados em uma ampla gama de indústrias e disciplinas. GreyAtom fornece uma ampla visão geral dos diferentes tipos de árvores de decisão e suas aplicações práticas.
SVM (Support Vector Machine)
As máquinas vetoriais de suporte são outro grupo de algoritmos usados para tarefas de classificação e, às vezes, de regressão. SVM é ótimo porque dá resultados bastante precisos com o mínimo poder de computação.
O objetivo do SVM é encontrar um hiperplano num espaço N-dimensional (onde N corresponde ao número de características) que classifica distintamente os pontos de dados. A precisão dos resultados está diretamente correlacionada com o hiperplano que escolhemos. Devemos encontrar um plano que tenha a distância máxima entre pontos de dados de ambas as classes.
Este hiperplano é representado graficamente como uma linha que separa uma classe da outra. Pontos de dados que caem em diferentes lados do hiperplano são atribuídos a diferentes classes.
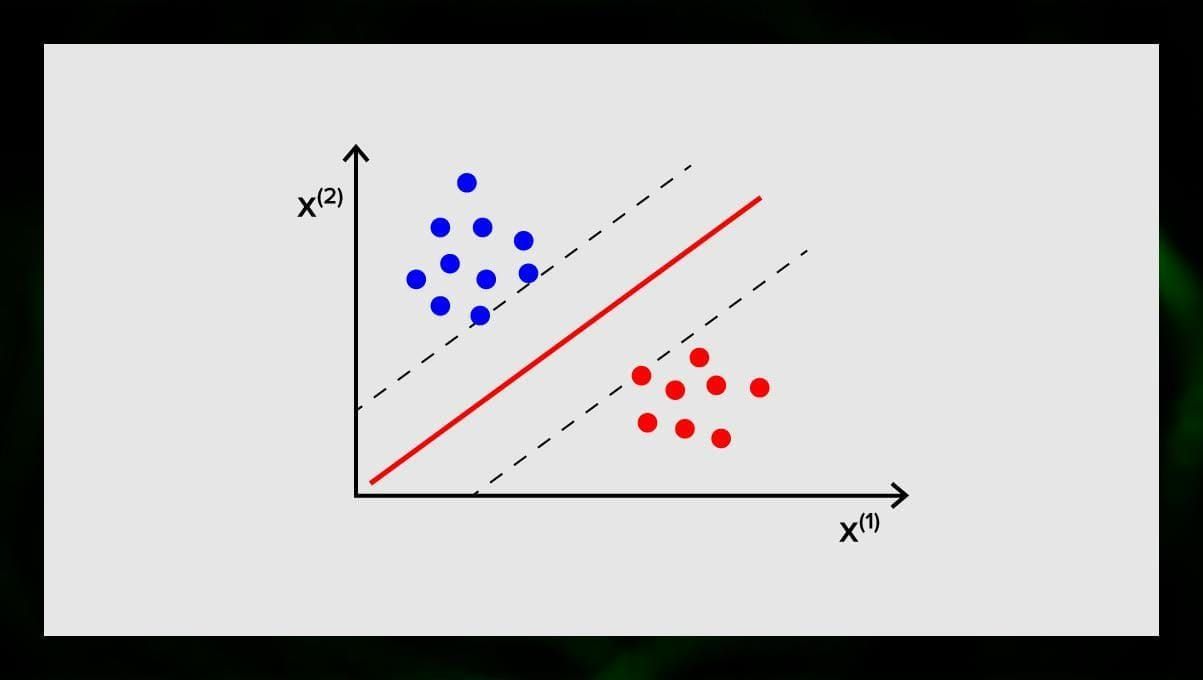
Nota que a dimensão do hiperplano depende do número de características. Se o número de características de entrada for 2, então o hiperplano é apenas uma linha. Se o número de características de entrada for 3, então o hiperplano torna-se um plano bidimensional. Torna-se difícil desenhar em um gráfico um modelo quando o número de características excede 3. Então, neste caso, você estará usando tipos de Kernel para transformá-lo em um espaço tridimensional.
Por que isso é chamado de máquina vetorial de suporte? Vetores de suporte são pontos de dados mais próximos do hiperplano. Eles influenciam diretamente a posição e orientação do hiperplano e nos permitem maximizar a margem do classificador. A eliminação dos vectores de suporte irá alterar a posição do hiperplano. Estes são os pontos que nos ajudam a construir o nosso SVM.
SVM são agora activamente utilizados no diagnóstico médico para encontrar anomalias, em sistemas de controlo de qualidade do ar, para análise financeira e previsões no mercado de acções, e no controlo de falhas de máquinas na indústria.
Algoritmos de regressão
Algoritmos de regressão são úteis em análises, por exemplo, quando se tenta prever os custos de títulos ou vendas de um determinado produto num determinado momento.
Regressão linear
Regressão linear tenta modelar a relação entre as variáveis ajustando uma equação linear aos dados observados.
Existem variáveis explicativas e dependentes. Variáveis dependentes são coisas que queremos explicar ou prever. As explicativas, como se segue para o nome, explicam algo. Se você quiser construir uma regressão linear, você assume que existe uma relação linear entre suas variáveis dependentes e independentes. Por exemplo, há uma correlação entre os metros quadrados de uma casa e seu preço ou a densidade de população e kebab lugares na área.
Após fazer essa suposição, você precisa descobrir a próxima relação linear específica. Você precisará encontrar uma equação de regressão linear para um conjunto de dados. O último passo é calcular o residual.
Nota: Quando a regressão desenha uma linha reta, ela é chamada linear, quando é uma curva – polinomial.
Algoritmos de aprendizagem não supervisionada

Agora vamos falar sobre algoritmos que são capazes de encontrar padrões ocultos em dados não etiquetados.
Clustering
Clustering significa que estamos dividindo as entradas em grupos de acordo com o grau de similaridade entre eles. O agrupamento é normalmente um dos passos para construir um algoritmo mais complexo. É mais simples estudar cada grupo separadamente e construir um modelo baseado nas suas características, em vez de trabalhar com tudo ao mesmo tempo. A mesma técnica é constantemente utilizada em marketing e vendas para dividir todos os clientes potenciais em grupos.
Muitos algoritmos comuns de clustering são k significa clustering e k-nearest vizinho.
K significa clustering
K significa clustering divide o conjunto de elementos do espaço vectorial num número predefinido de clusters k. Um número incorrecto de clusters irá invalidar todo o processo, por isso é importante experimentá-lo com números variáveis de clusters. A idéia principal do algoritmo k significa que os dados são divididos aleatoriamente em clusters, e depois, o centro de cada cluster obtido no passo anterior é recalculado iterativamente. Em seguida, os vetores são divididos em clusters novamente. O algoritmo pára quando em algum momento não há mudança nos clusters após uma iteração.
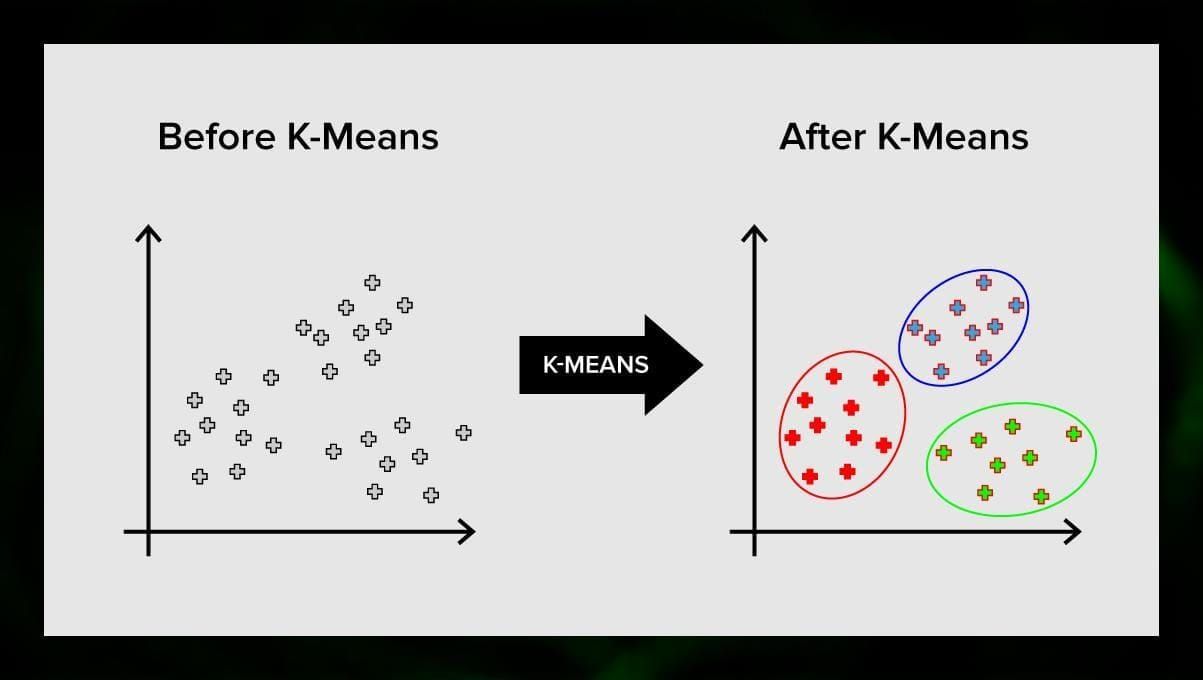
Este método pode ser aplicado para resolver problemas quando os clusters são distintos ou podem ser separados facilmente, sem sobreposição de dados.
K-nearest neighbor
kNN significa k-nearest neighbor. Este é um dos algoritmos de classificação mais simples às vezes usado em tarefas de regressão.
Para treinar o classificador, você deve ter um conjunto de dados com classes pré-definidas. A marcação é feita manualmente envolvendo especialistas na área estudada. Usando este algoritmo, é possível trabalhar com múltiplas classes ou limpar as situações em que os inputs pertencem a mais de uma classe.
O método é baseado na suposição de que etiquetas similares correspondem a objetos fechados no espaço vetorial de atributos.
Os sistemas de software modernos usam kNN para reconhecimento visual de padrões, por exemplo, para escanear e detectar pacotes escondidos no fundo do carrinho no check-out (por exemplo, AmazonGo). Os algoritmos kNN analisam todos os dados e detectam padrões incomuns que indicam atividade suspeita.
Dimensionalidade reduzida
Análise de componentes primitivos (PCA) é uma técnica importante para entender a fim de resolver efetivamente problemas relacionados ao ML.
Imagine que você tem um monte de variáveis a considerar. Por exemplo, você precisa agrupar as cidades em três grupos: boas para viver, más para viver e mais ou menos. Quantas variáveis você tem que considerar? Provavelmente, muitas. Você entende as relações entre elas? Na verdade, não. Então como você pode pegar todas as variáveis que você coletou e focar apenas em algumas delas que são as mais importantes?
Em termos técnicos, você quer “reduzir a dimensão do seu espaço de recursos”. Ao reduzir a dimensão do seu espaço de recursos, você consegue obter menos relações entre as variáveis a considerar e tem menos probabilidade de sobreajustar o seu modelo.
>
Existem muitas formas de alcançar a redução da dimensionalidade, mas a maioria destas técnicas cai em uma de duas classes:
- Eliminação de recursos;
- Eliminação de recursos.
Eliminação de recursos significa que você reduz o número de recursos eliminando alguns deles. As vantagens deste método são que ele é simples e mantém a interpretabilidade das suas variáveis. Como desvantagem, embora, você obtenha zero informação das variáveis que você decidiu abandonar.
Retirada de características evita este problema. O objetivo ao aplicar este método é extrair um conjunto de recursos do conjunto de dados dado. A extracção de características tem como objectivo reduzir o número de características num conjunto de dados, criando novas características baseadas nas existentes (e depois descartando as características originais). O novo conjunto reduzido de características tem que ser criado de forma que seja capaz de resumir a maioria das informações contidas no conjunto original de características.
Análise de componentes do PCA é um algoritmo para extração de características. ele combina as variáveis de entrada de uma forma específica, e então é possível abandonar as variáveis “menos importantes” enquanto ainda mantém as partes mais valiosas de todas as variáveis.
Uma das possíveis utilizações do PCA é quando as imagens no conjunto de dados são muito grandes. Uma representação reduzida de características ajuda a lidar rapidamente com tarefas como a correspondência e recuperação de imagens.
Asociation rule learning
Apriori é um dos mais populares algoritmos de pesquisa de regras de associação. Ele é capaz de processar grandes quantidades de dados num período de tempo relativamente pequeno.
O problema é que as bases de dados de muitos projetos hoje em dia são muito grandes, atingindo gigabytes e terabytes. E eles continuarão a crescer. Portanto, é necessário um algoritmo eficaz e escalável para encontrar regras associativas em um curto espaço de tempo. Apriori é um destes algoritmos.
Para poder aplicar o algoritmo, é necessário preparar os dados, convertendo-os todos para a forma binária e alterando a sua estrutura de dados.
Usualmente, você opera este algoritmo numa base de dados que contém um grande número de transacções, por exemplo, numa base de dados que contém informação sobre todos os itens que os clientes compraram num supermercado.
Aprendizagem de reforço

Aprendizagem de reforço é um dos métodos de aprendizagem de máquinas que ajuda a ensinar a máquina a interagir com um determinado ambiente. Neste caso, o ambiente (por exemplo, num jogo de vídeo) serve como o professor. Ele fornece feedback para as decisões tomadas pelo computador. Com base nesta recompensa, a máquina aprende a tomar o melhor curso de ação. Lembra a forma como as crianças aprendem a não tocar numa frigideira quente – através da experimentação e da sensação de dor.
Quebrar este processo, envolve estes simples passos:
- O computador observa o ambiente;
- Escolhe alguma estratégia;
- Acta de acordo com esta estratégia;
- Recebe ou uma recompensa ou uma penalização;
- Aprende desta experiência e refina a estratégia;
- Repetirá até encontrar a estratégia ideal.
Q-Learning
Há um par de algoritmos que podem ser usados para a aprendizagem do Reforço. Um dos mais comuns é o Q-learning.
Q-learning é um algoritmo de aprendizagem de reforço livre de modelos. O Q-learning é baseado na remuneração recebida do ambiente. O agente forma uma função de utilidade Q, que posteriormente lhe dá a oportunidade de escolher uma estratégia de comportamento, e levar em conta a experiência de interações anteriores com o ambiente.
Uma das vantagens do Q-learning é que ele é capaz de comparar a utilidade esperada das ações disponíveis sem formar modelos ambientais.
Ensemble learning

Ensemble learning é o método de resolução de um problema através da construção de múltiplos modelos ML e sua combinação. A aprendizagem em conjunto é usada principalmente para melhorar o desempenho dos modelos de classificação, predição e aproximação de funções. Outras aplicações da aprendizagem em conjunto incluem a verificação da decisão tomada pelo modelo, selecionando características ótimas para construir modelos, aprendizagem incremental e aprendizagem não-estacionária.
Below são alguns dos algoritmos mais comuns de aprendizagem em conjunto.
Bagging
Bagging representa a agregação de bootstrap. É um dos primeiros algoritmos de ensamblagem, com um desempenho surpreendentemente bom. Para garantir a diversidade de classificadores, você utiliza réplicas de bootstrap dos dados de treinamento. Isso significa que diferentes subconjuntos de dados de treinamento são desenhados aleatoriamente – com substituição – a partir do conjunto de dados de treinamento. Cada subconjunto de dados de treinamento é usado para treinar um classificador diferente do mesmo tipo. Depois, os classificadores individuais podem ser combinados. Para isso, é necessário tomar uma maioria simples de votos nas suas decisões. A classe que foi atribuída pela maioria dos classificadores é a decisão do conjunto.
Boosting
Este grupo de algoritmos de conjunto é semelhante ao ensacamento. O Boosting também usa uma variedade de classificadores para fazer uma nova amostragem dos dados, e depois escolhe a versão ideal por votação por maioria. Ao impulsionar, você treina iterativamente classificadores fracos para montá-los em um classificador forte. Quando os classificadores são adicionados, eles são geralmente atribuídos em alguns pesos, que descrevem a precisão de suas previsões. Depois que um classificador fraco é adicionado ao conjunto, os pesos são recalculados. As entradas classificadas incorretamente ganham mais peso, e as instâncias classificadas corretamente perdem peso. Assim, o sistema se concentra mais em exemplos onde uma classificação errada foi obtida.
Florestas aleatórias
Florestas aleatórias ou de decisão aleatória são um método de aprendizado do conjunto para classificação, regressão, e outras tarefas. Para construir uma floresta aleatória, você precisa treinar uma grande quantidade de árvores de decisão em amostras aleatórias de dados de treinamento. A saída da floresta aleatória é o resultado mais freqüente entre as árvores individuais. Florestas de decisão aleatória lutam com sucesso contra o sobreajuste devido à _random _natureza do algoritmo.
Aferição
Aferição é uma técnica de aprendizagem em conjunto que combina múltiplos modelos de classificação ou regressão através de um metaclassificador ou um meta-regressor. Os modelos de nível base são treinados com base em um conjunto completo de treinamento, depois o meta-modelo é treinado nas saídas dos modelos de nível base como características.
Redes neurais
Uma rede neural é uma seqüência de neurônios conectados por sinapses, o que lembra a estrutura do cérebro humano. No entanto, o cérebro humano é ainda mais complexo.
O que é ótimo sobre as redes neurais é que elas podem ser usadas para basicamente qualquer tarefa, desde a filtragem de spam até a visão do computador. Entretanto, elas são normalmente aplicadas para tradução automática, detecção de anomalias e gerenciamento de riscos, reconhecimento de fala e geração de linguagem, reconhecimento facial e mais.
Uma rede neural consiste de neurônios, ou nós. Cada um desses neurônios recebe dados, processa-os e depois os transfere para outro neurônio.
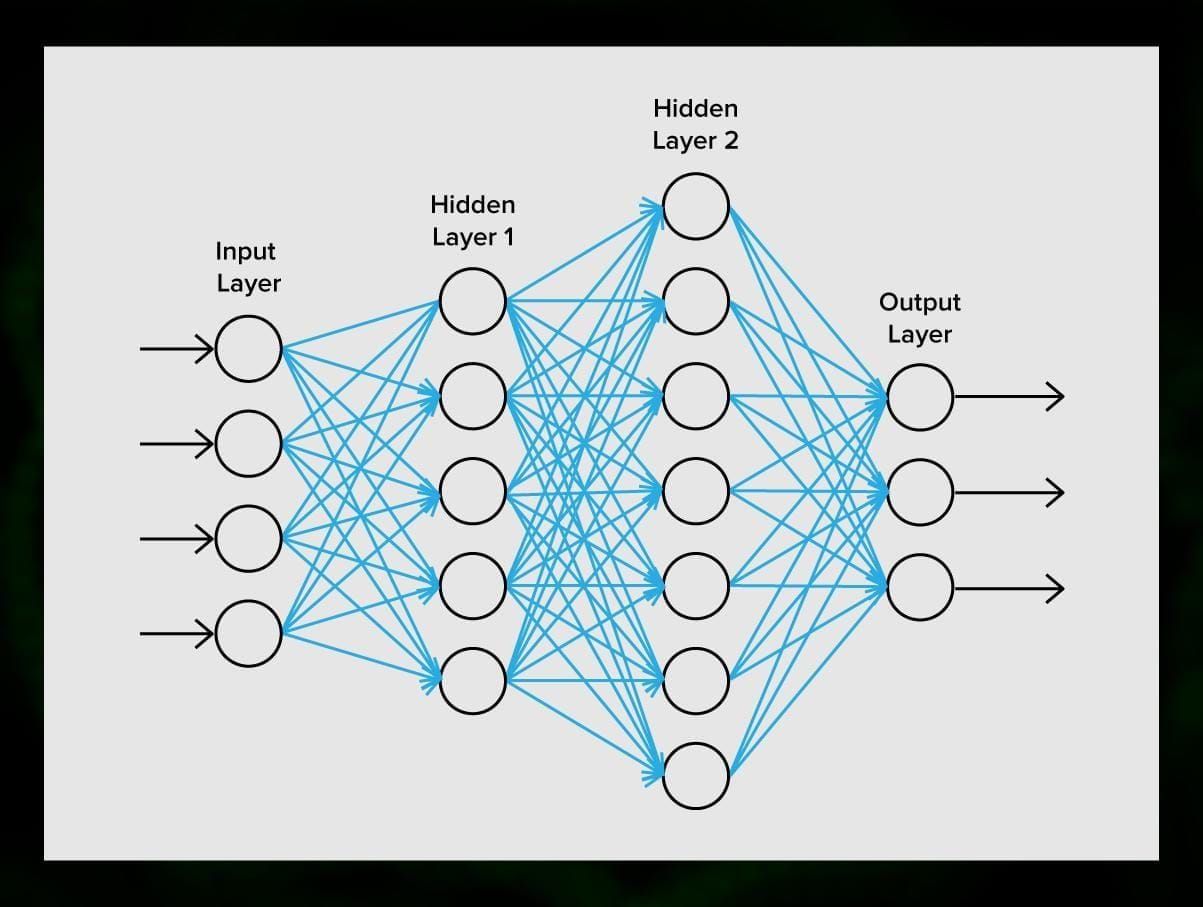
Todos os neurônios processam os sinais da mesma forma. Mas como então obtemos um resultado diferente? As sinapses que conectam os neurônios uns aos outros são responsáveis por isso. Cada neurônio é capaz de ter muitas sinapses que atenuam ou amplificam o sinal. Além disso, os neurónios são capazes de mudar as suas características ao longo do tempo. Escolhendo os parâmetros de sinapse corretos, seremos capazes de obter os resultados corretos da conversão das informações de entrada na saída.
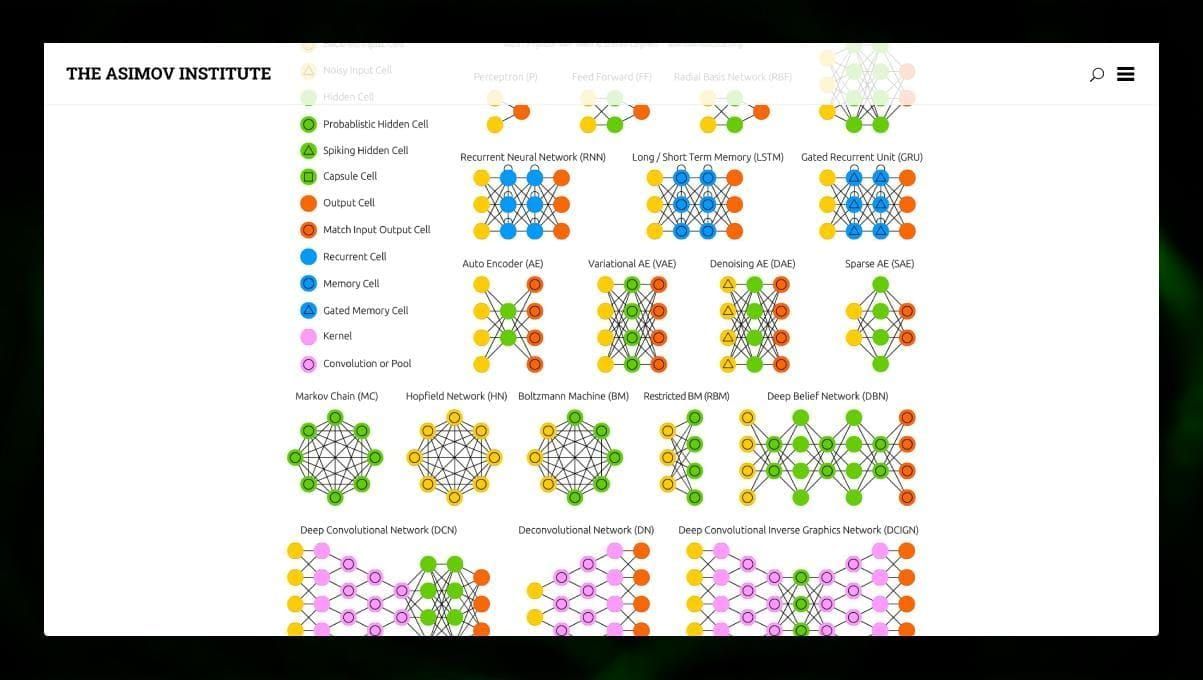
Existem muitos tipos diferentes de NN:
- Feedforward redes neurais (FF ou FFNN) e perceptrons § são muito simples, não há loops ou ciclos na rede. Na prática, tais redes são raramente utilizadas, mas frequentemente são combinadas com outros tipos para obter novas redes.
- A rede Hopfield (HN) é uma rede neural totalmente conectada com uma matriz simétrica de links. Tal rede é muitas vezes chamada de rede de memória associativa. Assim como uma pessoa que vê uma metade da tabela, pode imaginar a segunda metade, esta rede, recebendo uma tabela ruidosa, a restaura ao máximo.
- Redes neurais convolucionais (CNN) e redes neurais convolucionais profundas (DCNN) são muito diferentes de outros tipos de redes. Elas são normalmente usadas para processamento de imagens, tarefas relacionadas a áudio ou vídeo. Uma maneira típica de aplicar a CNN é classificar imagens.
Muitos tipos diferentes de redes neurais são interessantes de se observar. É possível fazer isso no zoo NN.
Conclusão
Este post é uma visão geral dos diferentes algoritmos ML, mas ainda há muito a ser dito. Fique ligado no nosso Twitter, Facebook e Médio para mais guias e posts sobre as excitantes possibilidades de aprendizagem de máquinas.
Deixe uma resposta