Inscrição para as nossas recapitulações diárias do sempre mutante cenário do marketing de busca.
Nota: Ao enviar este formulário, você concorda com os termos da Third Door Media. Respeitamos a sua privacidade.

Em fóruns da internet e grupos do Facebook relacionados ao conteúdo, muitas vezes surgem discussões sobre como o Googlebot funciona – que chamaremos ternamente GB aqui – e o que ele pode e não pode ver, que tipo de links ele visita e como ele influencia SEO.
Neste artigo, vou apresentar os resultados da minha experiência de três meses.
>
O mais importante diário dos últimos três meses, GB tem-me visitado como um amigo que passa por aqui para beber uma cerveja.
>
Às vezes estava sozinho:
: 66.249.76.136 /page1.html Mozilla/5.0 (compatível; Googlebot/2.1; +http://www.google.com/bot.html)
: 66.249.76.136 /page5.html Mozilla/5.0 (compatível; Googlebot/2.1; +http://www.google.com/bot.html)
: 66.249.76.140 /page3.html Mozilla/5.0 (compatível; Googlebot/2.1; +http://www.google.com/bot.html)
: 66.249.64.72 /page2.html Mozilla/5.0 (compatível; Googlebot/2.1; +http://www.google.com/bot.html)
: 66.249.64.72 /page6.html Mozilla/5.0 (compatível; Googlebot/2.1; +http://www.google.com/bot.html)
Por vezes trouxe os seus amigos:
: 64.233.172.231 /page1.html Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, como Gecko; Google Search Console) Chrome/41.0.2272.118 Safari/537.36
: 66.249.69.235 /image.jpg Googlebot-Image/1.0
: 66.249.76.156 /page2.html Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, como o Gecko) Chrome/41.0.2272.96 Mobile Safari/537.36 (compatível; Googlebot/2.1; +http://www.google.com/bot.html)
E nos divertimos muito jogando diferentes jogos:
Catch: Eu observei como GB adora rodar redirecionamentos 301 e crawl images, e rodar de canonicals.
Hide-and-seek: Googlebot estava escondido no conteúdo escondido (que, como seus pais dizem, não tolera e evita)
Survival: Preparei armadilhas e esperei que ele as soltasse.
Obstacles: Coloquei obstáculos com vários níveis de dificuldade para ver como o meu amiguinho lidaria com eles.
Como provavelmente se pode ver, não fiquei desapontado. Nós nos divertimos muito e nos tornamos bons amigos. Eu acredito que nossa amizade tem um futuro brilhante.
Mas vamos direto ao ponto!
Construí um site com conteúdo relacionado a méritos sobre uma agência de viagens interestelar oferecendo vôos para planetas ainda não descobertos em nossa galáxia e além.
O conteúdo parecia ter muitos méritos quando na verdade era um monte de bobagens.
A estrutura do website experimental parecia assim:
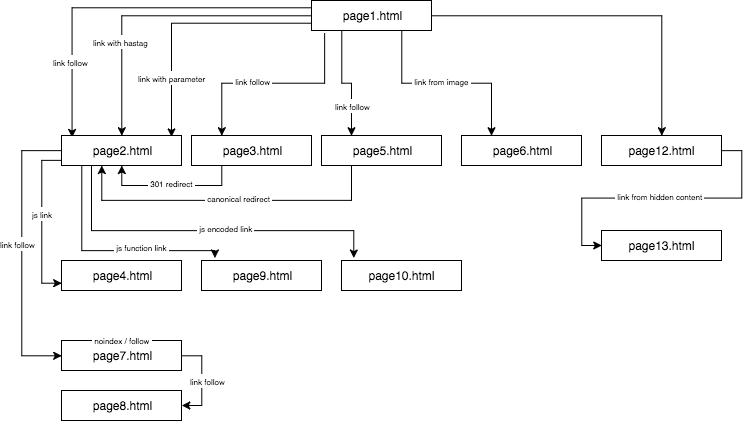
Forneci conteúdo único e certifiquei-me de que cada âncora/título/al, assim como outros coeficientes, eram globalmente únicos (palavras falsas). Para facilitar ao leitor, na descrição não vou usar nomes como âncora cutroicano matestito, mas sim referi-los como âncora1, etc.
I sugere que você mantenha o mapa acima aberto em uma janela separada enquanto lê este artigo.
- Parte 1: O primeiro link conta
- Link para um site com uma âncora
- Link para um site com um parâmetro
- Link para um site a partir de um redirecionamento
- Link para uma página usando a tag canônica
- Parte 2: Orçamento de rastejamento
- JavaScript link com um evento onclick
- Javascript link com uma função interna
- JavaScript link com codificação
- Parte 3: Conteúdo Escondido
- Sobre o Autor
Parte 1: O primeiro link conta
Uma das coisas que eu queria testar nesta experiência SEO era a Regra da Contagem do Primeiro Link – se ele pode ser omitido e como ele influencia a otimização.
A Regra da Contagem do Primeiro Link diz que em uma página, o Google Bot vê apenas o primeiro link para uma subpágina. Se você tiver dois links para a mesma subpágina em uma página, o segundo será ignorado, de acordo com esta regra. O Google Bot irá ignorar a âncora no segundo e em cada link consecutivo enquanto calcula a classificação da página.
É um problema amplamente supervisionado por muitos especialistas, mas que está presente especialmente em lojas online, onde menus de navegação distorcem significativamente a estrutura do site.
Na maioria das lojas, temos um menu suspenso estático (visível na fonte da página), que dá, por exemplo, quatro links para categorias principais e 25 links ocultos para subcategorias. Durante o mapeamento da estrutura de uma página, GB vê todos os links (em cada página com um menu) o que resulta em todas as páginas terem a mesma importância durante o mapeamento e seu poder (sumo) é distribuído uniformemente, o que parece mais ou menos assim:
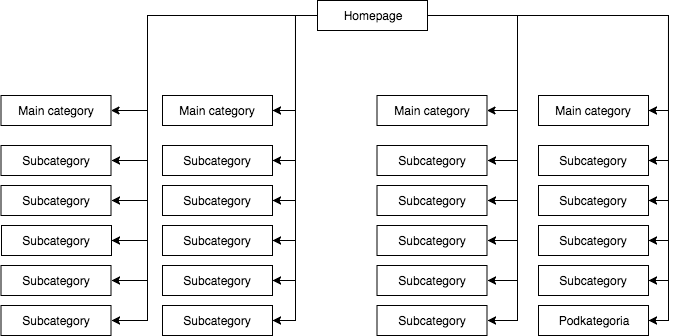
A mais comum, mas na minha opinião, a estrutura de página errada.
O exemplo acima não pode ser chamado de uma estrutura apropriada porque todas as categorias são linkadas de todos os sites onde há um menu. Portanto, tanto a página inicial como todas as categorias e subcategorias têm um número igual de links recebidos, e o poder de todo o serviço web flui através deles com a mesma força. Assim, o poder da página inicial (que normalmente é a fonte da maior parte do poder devido ao número de links recebidos) está sendo dividido em 24 categorias e subcategorias, de modo que cada uma delas recebe apenas 4 por cento do poder da página inicial.
Como a estrutura deve ser:

Se você precisar testar rapidamente a estrutura da sua página e rastreá-la como o Google faz, Screaming Frog é uma ferramenta útil.
Neste exemplo, a potência da página inicial é dividida em quatro e cada uma das categorias recebe 25% da potência da página inicial e distribui parte dela para as subcategorias. Esta solução também oferece uma melhor chance de ligação interna. Por exemplo, quando você escreve um artigo no blog da loja e quer fazer um link para uma das subcategorias, a GB notará o link enquanto rasteja o site. No primeiro caso, ele não o fará por causa da regra First Link Counts. Se o link para uma subcategoria estava no menu do site, então o do artigo será ignorado.
Iniciei esta experiência SEO com as seguintes ações:
- Primeiro, na página1.html, eu incluí um link para uma subpágina2.html como um link clássico dofollow com uma âncora: anchor1.
- Next, no texto da mesma página, eu incluí referências ligeiramente modificadas para verificar se GB estaria ansioso para rastejá-las.
Para este fim, testei as seguintes soluções:
- Para a página inicial do serviço web, atribuí um link dofollow externo para uma frase com uma âncora URL (assim qualquer link externo da página inicial e das subpáginas para determinadas frases estava fora de questão) – acelerou a indexação do serviço.
- Esperava que a página2.html começasse a classificação para uma frase do primeiro link dofollow (âncora1) vindo da página1.html. Esta frase falsa, ou qualquer outra que eu testei, não pôde ser encontrada na página de destino. Eu assumi que se outros links funcionassem, então a página2.html também classificaria nos resultados da busca por outras frases a partir de outros links. Demorou cerca de 45 dias. E então pude fazer a primeira conclusão importante.
Even um website, onde uma palavra-chave não está nem no conteúdo, nem no meta título, mas está ligada a uma âncora pesquisada, pode facilmente ser classificada nos resultados da pesquisa mais alto do que um website que contém esta palavra, mas não está ligada a uma palavra-chave.
Mais, a página inicial (página1.html), que continha a frase pesquisada, era a página mais forte do serviço web (ligada a partir de 78 por cento das subpáginas) e, ainda assim, classificou-se mais abaixo na frase pesquisada do que na subpágina (página2.html) ligada à frase pesquisada.
Below, apresento quatro tipos de links que testei, todos eles vêm depois do primeiro link dofollow que levou à página2.html.
Link para um site com uma âncora
< a href=”page2.html#testhash” >anchor2< /a >
O primeiro dos links adicionais que vem no código por trás do link dofollow foi um link com uma âncora (uma hashtag). Eu queria ver se GB passaria pelo link e também indexaria página2.html sob a frase anchor2, apesar de o link levar a essa página (página2.html) mas a URL sendo alterada para página2.html#testhash usa anchor2.
Felizmente, GB nunca quis lembrar essa conexão e não direcionou o poder para a subpágina page2.html para essa frase. Como resultado, nos resultados da pesquisa para a frase anchor2 no dia da escrita deste artigo, existe apenas a subpágina page1.html, onde a palavra pode ser encontrada na âncora do link. Ao pesquisar no Google a frase testhash, o nosso domínio também não está classificado.
Link para um site com um parâmetro
página2.html?parâmetro=1
Inicialmente, GB estava interessado nesta parte engraçada da URL logo após a marca de consulta e a âncora dentro do link anchor3.
Intrigued, GB estava a tentar perceber o que eu queria dizer. Ele pensou: “Será um enigma?” Para evitar a indexação do conteúdo duplicado sob as outras URLs, a página canônica2.html estava apontando para si mesma. Os logs ao todo registraram 8 rastejamentos neste endereço, mas as conclusões foram bastante tristes:
- Após 2 semanas, a frequência de visitas do GB diminuiu significativamente até que ele eventualmente saiu e nunca mais rastreou aquele link.
- page2.html não foi indexado sob a frase anchor3, nem o parâmetro com o parâmetro URL1. Segundo a Search Console, esse link não existe (não é contado entre os links recebidos), mas ao mesmo tempo, a frase anchor3 é listada como uma frase ancorada.
Link para um site a partir de um redirecionamento
Queria forçar GB a rastrear mais o meu site, o que resultou em GB, a cada dois dias, entrando no link dofollow com uma âncora de âncora4 na página1.html levando à página3.html, que redireciona com um código 301 para página2.html. Infelizmente, como no caso da página com um parâmetro, após 45 dias a página2.html ainda não estava classificada nos resultados da busca pela frase anchor4 que apareceu no link redirecionado em page1.html.
No entanto, no Google Search Console, na seção Anchor Texts, a anchor4 é visível e indexada. Isto pode indicar que, após algum tempo, o redirecionamento começará a funcionar como esperado, de modo que a página2.html irá classificar nos resultados da busca pela âncora4 apesar de ser o segundo link para a mesma página alvo dentro do mesmo website.
Link para uma página usando a tag canônica
Na página1.html, coloquei uma referência à página5.html (siga o link) com uma âncora5. Ao mesmo tempo, na página5.html havia um conteúdo único, e em sua cabeça, havia uma tag canônica para page2.html.
< link rel=”canonical” href=”https://example.com/page2.html” />
Este teste deu os seguintes resultados:
- O link para a frase âncora5 direcionando para a página5.html redirecionando canonicamente para a página2.html não foi transferido para a página de destino (como nos outros casos).
- page5.html foi indexado apesar da tag canônica.
- page5.html não foi classificado nos resultados da busca pela âncora5.
- page5.html foi classificado nas frases usadas no texto da página, o que indicava que GB ignorou totalmente as tags canônicas.
Ousaria afirmar que usando rel=canônico para evitar a indexação de algum conteúdo (por exemplo, enquanto filtrando) simplesmente não poderia funcionar.
Parte 2: Orçamento de rastejamento
Enquanto desenhava uma estratégia SEO, eu queria fazer GB dançar ao meu som e não o contrário. Com este objectivo, verifiquei os processos de SEO ao nível dos logs do servidor (logs de acesso e logs de erros) o que me proporcionou uma enorme vantagem. Graças a isso, eu conhecia cada movimento do GB e como ele reagia às mudanças que eu introduzia (reestruturação do website, virar o sistema de links internos de cabeça para baixo, a forma de exibir informações) dentro da campanha SEO.
Uma das minhas tarefas durante a campanha SEO era reconstruir um website de forma a fazer com que o GB visitasse apenas aquelas URLs que ele fosse capaz de indexar e que nós queríamos que ele indexasse. Em poucas palavras: só deveriam existir as páginas que são importantes para nós do ponto de vista de SEO no índice do Google. Por outro lado, GB deve apenas rastrear os sites que queremos que sejam indexados pelo Google, o que não é óbvio para todos, por exemplo, quando uma loja online implementa a filtragem por cores, tamanho e preços, e isso é feito manipulando os parâmetros da URL, por exemplo:
example.com/women/shoes/?color=red&size=40&price=200-250
Pode acontecer que uma solução que permita ao GB rastrear URLs dinâmicas faça com que ele dedique tempo para pesquisá-las (e possivelmente indexá-las) em vez de rastrear a página.
example.com/women/shoes/
As URLs criadas dinamicamente não só são inúteis como potencialmente prejudiciais ao SEO porque podem ser confundidas com conteúdo fino, o que resultará na queda das classificações do website.
Com esta experiência eu também queria verificar alguns métodos de estruturação sem usar rel=”nofollow”, bloqueando GB no arquivo robots.txt ou colocando parte do código HTML em frames que são invisíveis para o bot (iframe bloqueado).
Testei três tipos de links JavaScript.
JavaScript link com um evento onclick
Um link simples construído em JavaScript
< a href=”javascript:void(0)” onclick=”window.location.href =’page4.html'” >anchor6< /a >
GB facilmente movido para a subpágina page4.html e indexado a página inteira. A subpágina não se classifica nos resultados da pesquisa da frase âncora6, e esta frase não pode ser encontrada na secção Anchor Texts no Google Search Console. A conclusão é que o link não transferiu o sumo.
Para resumir:
- Um link JavaScript clássico permite ao Google rastrear o site e indexar as páginas em que ele vem.
- Não transfere sumo – é neutro.
Javascript link com uma função interna
Decidi levantar o jogo mas, para minha surpresa, GB ultrapassou o obstáculo em menos de 2 horas após a publicação do link.
< a href=”javascript:void(0)” class=”js-link” data-url=”page9.html” >anchor7< /a >
Para operar este link, usei uma função externa, que tinha como objetivo ler o URL a partir dos dados e o redirecionamento – apenas o redirecionamento de um usuário, como eu esperava – para a página alvo9.html. Como no caso anterior, page9.html tinha sido totalmente indexada.
O que é interessante é que apesar da falta de outros links recebidos, page9.html foi a terceira página mais frequentemente visitada por GB em todo o serviço web, logo após page1.html e page2.html.
Tinha usado este método antes para estruturar serviços web. Entretanto, como podemos ver, ele não funciona mais. Em SEO nada vive para sempre, excepto as Páginas Amarelas.
JavaScript link com codificação
Still, eu não desistiria e decidi que deve haver uma maneira de efetivamente fechar a porta na cara da GB. Então, construí uma função simples, codificando os dados com um algoritmo base64, e a referência ficou assim:
< a href=”javascript”:void(0)” class=”js-link” data-url=”cGFnZTEwLmh0bWw=” >anchor8< /a >
Como resultado, GB foi incapaz de produzir um código JavaScript que tanto decodificaria o conteúdo de um atributo data-URL como redirecionaria. E lá estava ele! Temos uma maneira de estruturar um serviço web sem usar rel=nonfolfollows para evitar que os bots rastejem para onde eles quiserem! Desta forma, não desperdiçamos o nosso orçamento de crawl, o que é especialmente importante no caso dos grandes serviços web, e a GB finalmente dança ao nosso ritmo. Quer a função tenha sido introduzida na mesma página na secção principal ou num ficheiro JS externo, não há evidência de um bot nos logs do servidor ou na Consola de Pesquisa.
Parte 3: Conteúdo Escondido
No teste final, eu queria verificar se o conteúdo em, por exemplo, abas ocultas seria considerado e indexado pelo GB ou se o Google renderizou tal página e ignorou o texto escondido, como alguns especialistas têm vindo a afirmar.
Queria confirmar ou rejeitar esta afirmação. Para isso, coloquei uma parede de texto com mais de 2000 sinais na página12.html e escondi um bloco de texto com cerca de 20% do texto (400 sinais) nas Folhas de Estilo em Cascata e adicionei o botão mostrar mais. Dentro do texto escondido havia um link para a página13.html com uma âncora9.
Não há dúvida de que um bot pode renderizar uma página. Podemos observá-lo tanto na Consola de Pesquisa do Google como no Google Insight Speed. No entanto, meus testes revelaram que um bloco de texto exibido após clicar no botão mostrar mais foi totalmente indexado. As frases ocultas no texto classificado nos resultados da pesquisa e GB estavam seguindo os links ocultos no texto. Além disso, as âncoras dos links de um bloco de texto oculto estavam visíveis no Console de pesquisa do Google na seção Texto da âncora e a página13.html também começou a classificar nos resultados de pesquisa para a âncora da palavra-chave9.
Isso é crucial para lojas on-line, onde o conteúdo é frequentemente colocado em abas ocultas. Agora temos a certeza que GB vê o conteúdo em abas ocultas, indexa-as e transfere o sumo dos links que lá estão escondidos.
A conclusão mais importante que estou a tirar desta experiência é que não encontrei uma forma directa de contornar a Regra de Contagem do Primeiro Link usando links modificados (links com parâmetro, 301 redireccionamentos, canónicos, links de âncoras). Ao mesmo tempo, é possível construir a estrutura de um website usando links Javascript, graças ao qual estamos livres das restrições da Regra de Contagem de Primeiros Links. Além disso, o Google Bot pode ver e indexar conteúdo escondido nos bookmarks e segue os links escondidos neles.
Assine para as nossas recapitulações diárias do sempre mutante cenário de marketing de busca.
Nota: Ao enviar este formulário, você concorda com os termos da Third Door Media. Respeitamos a sua privacidade.
Sobre o Autor

“Não aceite ‘apenas’ alta qualidade. Qualquer pessoa pode fazer isso. Se o céu é o limite, encontre um céu mais alto”. Max Cyrek é CEO da Cyrek Digital, um consultor de marketing digital e evangelista de SEO. Ao longo de sua carreira, Max, juntamente com sua equipe de mais de 30 pessoas, trabalhou com centenas de empresas ajudando-as a ter sucesso. Ele tem trabalhado em marketing digital por quase dez anos e tem se especializado em SEO técnico, gerenciando projetos de marketing de sucesso.
Deixe uma resposta