Signez-vous pour nos récapitulations quotidiennes du paysage du marketing de recherche en constante évolution.
Note : En soumettant ce formulaire, vous acceptez les conditions de Third Door Media. Nous respectons votre vie privée.

Sur les forums internet et les groupes Facebook liés au contenu, des discussions éclatent souvent sur le fonctionnement de Googlebot – que nous appellerons tendrement GB ici – et sur ce qu’il peut et ne peut pas voir, sur le type de liens qu’il visite et sur son influence sur le référencement.
Dans cet article, je vais présenter les résultats de mon expérience de trois mois.
Presque quotidiennement depuis trois mois, GB m’a rendu visite comme un ami qui passe boire une bière.
Parfois, il était seul :
: 66.249.76.136 /page1.html Mozilla/5.0 (compatible ; Googlebot/2.1 ; +http://www.google.com/bot.html)
: 66.249.76.136 /page5.html Mozilla/5.0 (compatible ; Googlebot/2.1 ; +http://www.google.com/bot.html)
: 66.249.76.140 /page3.html Mozilla/5.0 (compatible ; Googlebot/2.1 ; +http://www.google.com/bot.html)
: 66.249.64.72 /page2.html Mozilla/5.0 (compatible ; Googlebot/2.1 ; +http://www.google.com/bot.html)
: 66.249.64.72 /page6.html Mozilla/5.0 (compatible ; Googlebot/2.1 ; +http://www.google.com/bot.html)
Il a parfois amené ses copains:
: 64.233.172.231 /page1.html Mozilla/5.0 (X11 ; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko ; Google Search Console) Chrome/41.0.2272.118 Safari/537.36
: 66.249.69.235 /image.jpg Googlebot-Image/1.0
: 66.249.76.156 /page2.html Mozilla/5.0 (Linux ; Android 6.0.1 ; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, comme Gecko) Chrome/41.0.2272.96 Mobile Safari/537.36 (compatible ; Googlebot/2.1 ; +http://www.google.com/bot.html)
Et nous avons eu beaucoup de plaisir à jouer à différents jeux:
Catch : J’ai observé comment GB aime exécuter des redirections 301 et crawler des images, et courir à partir de canoniques.
Cache-cache : Googlebot se cachait dans le contenu caché (que, comme ses parents le prétendent, il ne tolère pas et évite)
Survie : j’ai préparé des pièges et attendu qu’il les déclenche.
Obstacles : J’ai placé des obstacles avec différents niveaux de difficulté pour voir comment mon petit ami allait y faire face.
Comme vous pouvez probablement le dire, je n’ai pas été déçu. Nous nous sommes beaucoup amusés et nous sommes devenus de bons amis. Je crois que notre amitié a un bel avenir.
Mais venons-en au fait !
J’ai construit un site web avec du contenu lié aux mérites à propos d’une agence de voyage interstellaire offrant des vols vers des planètes encore inconnues dans notre galaxie et au-delà.
Le contenu semblait avoir beaucoup de mérites alors qu’en fait c’était un tas d’absurdités.
La structure du site expérimental ressemblait à ceci:
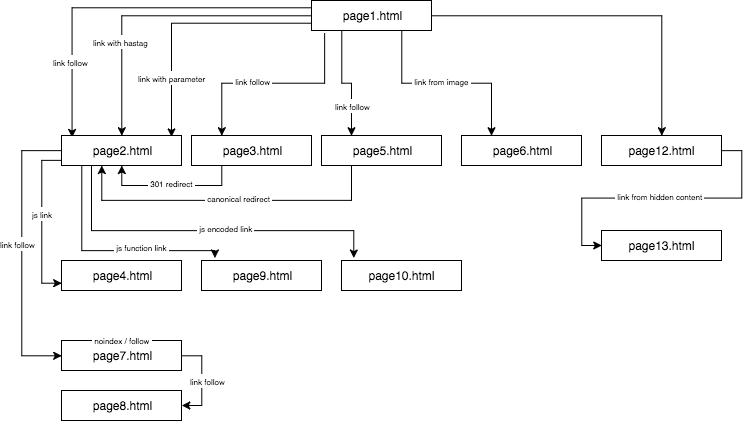
J’ai fourni un contenu unique et je me suis assuré que chaque ancre/titre/alt, ainsi que d’autres coefficients, étaient globalement uniques (faux mots). Pour faciliter les choses au lecteur, dans la description, je n’utiliserai pas de noms comme anchor cutroicano matestito, mais je les désignerai plutôt comme anchor1, etc.
Je vous suggère de garder la carte ci-dessus ouverte dans une fenêtre séparée pendant que vous lisez cet article.
- Partie 1 : Premier lien compte
- Lien vers un site web avec une ancre
- Lien vers un site web avec un paramètre
- Lien vers un site web à partir d’une redirection
- Lien vers une page utilisant une balise canonique
- Partie 2 : Budget du crawl
- Lien JavaScript avec un événement onclick
- Lien JavaScript avec une fonction interne
- Lien JavaScript avec codage
- Partie 3 : Contenu caché
- A propos de l’auteur
Partie 1 : Premier lien compte
L’une des choses que je voulais tester dans cette expérience de référencement était la règle du premier lien compte – si elle peut être omise et comment elle influence l’optimisation.
La règle du premier lien compte dit que sur une page, Google Bot ne voit que le premier lien vers une sous-page. Si vous avez deux liens vers la même sous-page sur une page, le second sera ignoré, selon cette règle. Google Bot ignorera l’ancre dans le deuxième et dans chaque lien consécutif lors du calcul du rang de la page.
C’est un problème largement surveillé par de nombreux spécialistes, mais qui est présent surtout dans les boutiques en ligne, où les menus de navigation déforment considérablement la structure du site web.
Dans la plupart des magasins, nous avons un menu déroulant statique (visible dans la source de la page), qui donne, par exemple, quatre liens vers les catégories principales et 25 liens cachés vers les sous-catégories. Pendant le mappage de la structure d’une page, GB voit tous les liens (sur chaque page avec un menu), ce qui fait que toutes les pages ont la même importance pendant le mappage et que leur puissance (jus) est distribuée uniformément, ce qui ressemble à peu près à ceci :
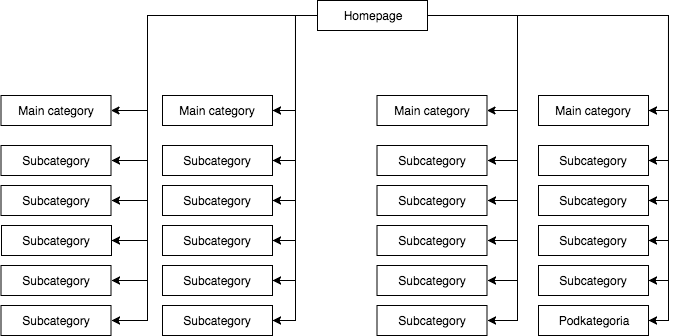
La structure de page la plus courante mais, à mon avis, la mauvaise.
L’exemple ci-dessus ne peut pas être appelé une structure correcte parce que toutes les catégories sont liées à partir de tous les sites où il y a un menu. Par conséquent, tant la page d’accueil que toutes les catégories et sous-catégories ont un nombre égal de liens entrants, et la puissance de l’ensemble du service web circule à travers eux avec une force égale. Par conséquent, la puissance de la page d’accueil (qui est habituellement la source de la plus grande partie de la puissance en raison du nombre de liens entrants) est divisée en 24 catégories et sous-catégories, de sorte que chacune d’entre elles ne reçoit que 4 pour cent de la puissance de la page d’accueil.
Comment la structure devrait ressembler:

Si vous avez besoin de tester rapidement la structure de votre page et de la crawler comme Google, Screaming Frog est un outil utile.
Dans cet exemple, le pouvoir de la page d’accueil est divisé en quatre et chacune des catégories reçoit 25 pour cent du pouvoir de la page d’accueil et en distribue une partie aux sous-catégories. Cette solution offre également de meilleures chances de créer des liens internes. Par exemple, si vous écrivez un article sur le blog de la boutique et que vous souhaitez créer un lien vers l’une des sous-catégories, GB remarquera le lien lors de l’exploration du site. Dans le premier cas, il ne le fera pas en raison de la règle du premier lien qui compte. Si le lien vers une sous-catégorie était dans le menu du site web, alors celui de l’article sera ignoré.
J’ai commencé cette expérience de référencement avec les actions suivantes :
- Premièrement, sur la page1.html, j’ai inclus un lien vers une sous-page page2.html en tant que lien dofollow classique avec une ancre : ancre1.
- Puis, dans le texte de la même page, j’ai inclus des références légèrement modifiées pour vérifier si GB serait désireux de les crawler.
À cette fin, j’ai testé les solutions suivantes :
- Sur la page d’accueil du service web, j’ai attribué un lien dofollow externe pour une phrase avec une ancre URL (ainsi, tout lien externe de la page d’accueil et des sous-pages pour des phrases données était hors de question) – cela a accéléré l’indexation du service.
- J’ai attendu que la page2.html commence à être indexée pour une phrase à partir du premier lien dofollow (ancre1) provenant de la page1.html. Cette fausse phrase, ou toute autre que j’ai testée ne pouvait pas être trouvée sur la page cible. J’ai supposé que si d’autres liens fonctionnaient, alors la page2.html serait également classée dans les résultats de recherche pour d’autres expressions provenant d’autres liens. Cela a pris environ 45 jours. Et puis j’ai pu faire la première conclusion importante.
Même un site web, où un mot clé n’est ni dans le contenu, ni dans le méta titre, mais est lié à une ancre recherchée, peut facilement se classer dans les résultats de recherche plus haut qu’un site web qui contient ce mot mais n’est pas lié à un mot clé.
Ci-après, je présente quatre types de liens que j’ai testés, qui viennent tous après le premier lien dofollow menant à page2.html.
Lien vers un site web avec une ancre
< a href= »page2.html#testhash » >anchor2< /a >
Le premier des liens supplémentaires venant dans le code derrière le lien dofollow était un lien avec une ancre (un hashtag). Je voulais voir si GB passerait par le lien et indexerait également la page2.html sous la phrase anchor2, malgré le fait que le lien mène à cette page (page2.html) mais que l’URL soit modifiée en page2.html#testhash utilise anchor2.
Malheureusement, GB n’a jamais voulu se souvenir de cette connexion et il n’a pas dirigé le pouvoir vers la sous-page page2.html pour cette phrase. En conséquence, dans les résultats de recherche pour l’expression anchor2 le jour de la rédaction de cet article, il n’y a que la sous-page page1.html, où l’on trouve le mot dans l’ancre du lien. En googlant l’expression testhash, notre domaine n’est pas classé non plus.
Lien vers un site web avec un paramètre
page2.html?parameter=1
Initialement, GB s’est intéressé à cette drôle de partie de l’URL juste après le marqueur de requête et à l’ancre à l’intérieur du lien ancre3.
Intrigué, GB essayait de comprendre ce que je voulais dire. Il pensait : « Est-ce une énigme ? » Pour éviter d’indexer le contenu dupliqué sous les autres URL, la page2.html canonique pointait sur elle-même. Les journaux ont enregistré en tout 8 crawls sur cette adresse, mais les conclusions étaient plutôt tristes :
- Après 2 semaines, la fréquence des visites de GB a diminué de manière significative jusqu’à ce qu’il finisse par partir et ne plus jamais crawler ce lien.
- page2.html n’était pas indexée sous la phrase anchor3, ni le paramètre avec l’URL parameter1. Selon Search Console, ce lien n’existe pas (il n’est pas compté parmi les liens entrants), mais en même temps, la phrase anchor3 est répertoriée comme une phrase ancrée.
Lien vers un site web à partir d’une redirection
Je voulais forcer GB à crawler davantage mon site web, ce qui a entraîné GB, tous les deux jours, à entrer le lien dofollow avec une ancre anchor4 sur page1.html menant à page3.html, qui redirige avec un code 301 vers page2.html. Malheureusement, comme dans le cas de la page avec un paramètre, après 45 jours, la page2.html n’était pas encore classée dans les résultats de recherche pour la phrase anchor4 qui apparaissait dans le lien redirigé sur la page1.html.
Toutefois, dans Google Search Console, dans la section Anchor Texts, anchor4 est visible et indexé. Cela pourrait indiquer que, après un certain temps, la redirection commencera à fonctionner comme prévu, de sorte que la page2.html se classera dans les résultats de recherche pour l’ancre4, bien qu’il s’agisse du deuxième lien vers la même page cible au sein du même site Web.
Lien vers une page utilisant une balise canonique
Sur la page1.html, j’ai placé une référence à la page5.html (lien suiveur) avec une ancre ancre5. En même temps, sur la page5.html, il y avait un contenu unique, et dans sa tête, il y avait une balise canonique vers la page2.html.
< lien rel= »canonique » href= »https://example.com/page2.html » />
Ce test a donné les résultats suivants :
- Le lien pour la phrase d’ancrage5 dirigeant vers page5.html redirigeant canoniquement vers page2.html n’a pas été transféré à la page cible (tout comme dans les autres cas).
- La page5.html a été indexée malgré la balise canonique.
- La page5.html ne s’est pas classée dans les résultats de recherche de l’ancre5.
- La page5.html s’est classée sur les phrases utilisées dans le texte de la page, ce qui indique que GB a totalement ignoré les balises canoniques.
J’oserais affirmer que l’utilisation de rel=canonical pour empêcher l’indexation de certains contenus (par exemple lors du filtrage) ne pourrait tout simplement pas fonctionner.
Partie 2 : Budget du crawl
En concevant une stratégie de référencement, je voulais faire en sorte que GB danse à ma mesure et non l’inverse. Dans ce but, j’ai vérifié les processus de référencement au niveau des journaux du serveur (journaux d’accès et journaux d’erreurs), ce qui m’a procuré un énorme avantage. Grâce à cela, je connaissais tous les mouvements de GB et sa réaction aux changements que j’ai introduits (restructuration du site web, mise sens dessus dessous du système de liens internes, manière d’afficher les informations) dans le cadre de la campagne de référencement.
L’une de mes tâches durant la campagne de référencement était de reconstruire un site web de manière à ce que GB ne visite que les URL qu’il serait capable d’indexer et que nous voulions qu’il indexe. En un mot : il ne devrait y avoir dans l’index de Google que les pages qui sont importantes pour nous du point de vue du référencement. D’autre part, GB ne devrait crawler que les sites web que nous voulons voir indexés par Google, ce qui n’est pas évident pour tout le monde, par exemple, lorsqu’une boutique en ligne met en place un filtrage par couleurs, tailles et prix, et que cela se fait en manipulant les paramètres de l’URL, par exemple :
exemple.com/femmes/chaussures/ ?color=red&size=40&price=200-250
Il peut s’avérer qu’une solution qui permet à GB de crawler des URL dynamiques lui fait consacrer du temps à les parcourir (et éventuellement à les indexer) au lieu de crawler la page.
exemple.com/femmes/chaussures/
Ces URL créées dynamiquement sont non seulement inutiles mais potentiellement nuisibles au référencement car elles peuvent être confondues avec du contenu mince, ce qui entraînera la chute du classement du site web.
Dans le cadre de cette expérience, j’ai également voulu vérifier certaines méthodes de structuration sans utiliser rel= »nofollow », bloquer les GB dans le fichier robots.txt ou placer une partie du code HTML dans des cadres invisibles pour le bot (iframe bloqué).
J’ai testé trois types de liens JavaScript.
Lien JavaScript avec un événement onclick
Un lien simple construit en JavaScript
< a href= »javascript:void(0) » onclick= »window.location.href =’page4.html' » >anchor6< /a >
GB est passé facilement sur la sous-page page4.html et a indexé la page entière. La sous-page n’est pas classée dans les résultats de recherche pour la phrase anchor6, et cette phrase ne peut pas être trouvée dans la section Anchor Texts dans Google Search Console. La conclusion est que le lien n’a pas transféré le jus.
En résumé :
- Un lien JavaScript classique permet à Google d’explorer le site Web et d’indexer les pages sur lesquelles il tombe.
- Il ne transfère pas de jus – il est neutre.
Lien JavaScript avec une fonction interne
J’ai décidé de relever le défi mais, à ma grande surprise, GB a surmonté l’obstacle en moins de 2 heures après la publication du lien.
< a href= »javascript:void(0) » class= »js-link » data-url= »page9.html » >anchor7< /a >
Pour faire fonctionner ce lien, j’ai utilisé une fonction externe, qui avait pour but de lire l’URL à partir des données et la redirection – uniquement la redirection d’un utilisateur, comme je l’espérais – vers la cible page9.html. Comme dans le cas précédent, la page9.html avait été entièrement indexée.
Ce qui est intéressant, c’est que malgré l’absence d’autres liens entrants, la page9.html était la troisième page la plus fréquemment visitée par GB dans l’ensemble du service web, juste après la page1.html et la page2.html.
J’avais déjà utilisé cette méthode pour structurer des services web. Cependant, comme nous pouvons le constater, elle ne fonctionne plus. En matière de référencement, rien n’est éternel, à part les pages jaunes.
Lien JavaScript avec codage
Mais je ne voulais pas abandonner et j’ai décidé qu’il devait y avoir un moyen de fermer efficacement la porte au visage de GB. J’ai donc construit une fonction simple, en codant les données avec un algorithme base64, et la référence ressemblait à ceci:
< a href= »javascript :void(0) » class= »js-link » data-url= »cGFnZTEwLmh0bWw= » >anchor8< /a >
En conséquence, GB n’a pas pu produire un code JavaScript qui à la fois décode le contenu d’un attribut data-URL et redirige. Et voilà ! Nous avons un moyen de structurer un service web sans utiliser de rel=nonfollows pour empêcher les bots de ramper où bon leur semble ! De cette façon, nous ne gaspillons pas notre budget de crawl, ce qui est particulièrement important dans le cas de gros services web, et GB danse enfin à notre rythme. Que la fonction ait été introduite sur la même page dans la section head ou dans un fichier JS externe, il n’y a aucune preuve de la présence d’un bot ni dans les journaux du serveur ni dans Search Console.
Partie 3 : Contenu caché
Dans le test final, je voulais vérifier si le contenu, par exemple, des onglets cachés serait pris en compte et indexé par GB ou si Google rendait une telle page et ignorait le texte caché, comme le prétendent certains spécialistes.
Je voulais confirmer ou infirmer cette affirmation. Pour ce faire, j’ai placé un mur de texte avec plus de 2000 signes sur la page12.html et j’ai caché un bloc de texte avec environ 20 % du texte (400 signes) dans des feuilles de style en cascade et j’ai ajouté le bouton show more. Dans le texte caché, il y avait un lien vers la page13.html avec une ancre anchor9.
Il ne fait aucun doute qu’un robot peut rendre une page. Nous pouvons l’observer à la fois dans Google Search Console et dans Google Insight Speed. Néanmoins, mes tests ont révélé qu’un bloc de texte affiché après avoir cliqué sur le bouton show more était entièrement indexé. Les phrases cachées dans le texte étaient classées dans les résultats de recherche et GB suivait les liens cachés dans le texte. De plus, les ancres des liens d’un bloc de texte caché étaient visibles dans Google Search Console dans la section Texte d’ancrage et page13.html a également commencé à se classer dans les résultats de recherche pour le mot clé anchor9.
Ceci est crucial pour les boutiques en ligne, où le contenu est souvent placé dans des onglets cachés. Maintenant, nous sommes sûrs que GB voit le contenu dans les onglets cachés, les indexe et transfère le jus des liens qui y sont cachés.
La conclusion la plus importante que je tire de cette expérience est que je n’ai pas trouvé un moyen direct de contourner la règle du premier lien compte en utilisant des liens modifiés (liens avec paramètre, redirections 301, canoniques, liens d’ancre). En même temps, il est possible de construire la structure d’un site web en utilisant des liens Javascript, grâce auxquels nous sommes libérés des restrictions de la règle First Link Counts. De plus, Google Bot peut voir et indexer le contenu caché dans les signets et il suit les liens qui y sont cachés.
Sign up for our daily recaps of the ever-changing search marketing landscape.
Note : En soumettant ce formulaire, vous acceptez les conditions de Third Door Media. Nous respectons votre vie privée.
A propos de l’auteur

« N’acceptez pas ‘juste’ une haute qualité. Tout le monde peut le faire. Si le ciel est la limite, trouvez un ciel plus élevé. » Max Cyrek est le PDG de Cyrek Digital, un consultant en marketing numérique et un évangéliste du référencement. Tout au long de sa carrière, Max, avec son équipe de plus de 30 personnes, a travaillé avec des centaines d’entreprises en les aidant à réussir. Il travaille dans le marketing numérique depuis près de dix ans et s’est spécialisé dans le référencement technique, en gérant des projets marketing réussis.
.
Laisser un commentaire