Les gens créent, partagent et stockent des données à un rythme plus rapide qu’à tout autre moment de l’histoire. Lorsqu’il s’agit d’innover sur le stockage et la transmission de ces données, chez Facebook, nous faisons des progrès non seulement dans le matériel – comme des disques durs plus grands et des équipements réseau plus rapides – mais aussi dans les logiciels. Les logiciels contribuent au traitement des données grâce à la compression, qui permet de coder des informations, comme du texte, des images et d’autres formes de données numériques, en utilisant moins de bits que l’original. Ces fichiers plus petits prennent moins de place sur les disques durs et sont transmis plus rapidement à d’autres systèmes. La compression et la décompression des informations ont toutefois un prix : le temps. Plus le temps consacré à la compression vers un fichier plus petit est important, plus les données sont lentes à traiter.
Aujourd’hui, la norme de compression de données régnante est Deflate, l’algorithme central à l’intérieur de Zip, gzip et zlib . Pendant deux décennies, il a fourni un équilibre impressionnant entre la vitesse et l’espace, et, par conséquent, il est utilisé dans presque tous les appareils électroniques modernes (et, ce n’est pas une coïncidence, utilisé pour transmettre chaque octet de l’article de blog même que vous lisez). Au fil des ans, d’autres algorithmes ont proposé soit une meilleure compression, soit une compression plus rapide, mais rarement les deux. Nous pensons avoir changé cela.
Nous sommes ravis d’annoncer Zstandard 1.0, un nouvel algorithme de compression et une implémentation conçus pour s’adapter au matériel moderne et compresser plus petit et plus rapidement. Zstandard combine les récentes percées en matière de compression, comme l’Entropie d’État Finie, avec une conception axée sur les performances – puis optimise la mise en œuvre pour les propriétés uniques des CPU modernes. En conséquence, il améliore les compromis faits par d’autres algorithmes de compression et offre un large éventail d’applications avec une vitesse de décompression très élevée. Zstandard, disponible dès maintenant sous la licence BSD, est conçu pour être utilisé dans presque tous les scénarios de compression sans perte, y compris beaucoup où les algorithmes actuels ne sont pas applicables.
- Comparaison de la compression
- Scalabilité
- Sous le capot
- Mémoire
- Un format conçu pour l’exécution parallèle
- Conception sans branchement
- Entropie d’état finie : Un compresseur de probabilité de nouvelle génération
- Modélisation du re-code
- Zstandard en pratique
- Petites données
- Dictionnaires en action
- Choisir un niveau de compression
- Try it out
- Plus à venir
Comparaison de la compression
Il existe trois métriques standard pour comparer les algorithmes de compression et les implémentations:
- Ratio de compression : La taille originale (numérateur) comparée à la taille compressée (dénominateur), mesurée en données sans unité comme un rapport de taille de 1,0 ou plus.
- Vitesse de compression : À quelle vitesse nous pouvons rendre les données plus petites, mesurée en Mo/s de données d’entrée consommées.
- Vitesse de décompression : À quelle vitesse nous pouvons reconstruire les données originales à partir des données compressées, mesurée en Mo/s pour le taux auquel les données sont produites à partir des données compressées.
Le type de données compressées peut affecter ces métriques, de sorte que de nombreux algorithmes sont réglés pour des types de données spécifiques, tels que le texte anglais, les séquences génétiques ou les images tramées. Cependant, Zstandard, comme zlib, est destiné à la compression à usage général pour une variété de types de données. Pour représenter les algorithmes sur lesquels Zstandard est censé travailler, nous utiliserons dans ce billet le corpus Silesia, un ensemble de fichiers représentant les types de données typiques utilisés tous les jours.
Certains algorithmes et implémentations couramment utilisés aujourd’hui sont zlib, lz4, et xz. Chacun de ces algorithmes offre différents compromis : lz4 vise la vitesse, xz vise des taux de compression plus élevés et zlib vise un bon équilibre entre vitesse et taille. Le tableau ci-dessous indique les compromis approximatifs entre le taux de compression par défaut des algorithmes et la vitesse pour le corpus Silesia en comparant les algorithmes par lzbench, un benchmark pur en mémoire destiné à modéliser les performances brutes des algorithmes.
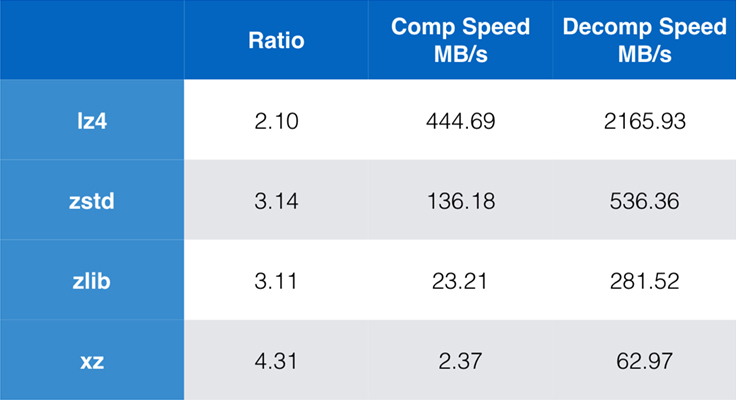
Comme souligné, il y a souvent des compromis drastiques entre la vitesse et la taille. L’algorithme le plus rapide, lz4, entraîne des taux de compression plus faibles ; xz, qui a le taux de compression le plus élevé, souffre d’une vitesse de compression lente. Cependant, Zstandard, au réglage par défaut, montre des améliorations substantielles de la vitesse de compression et de la vitesse de décompression, tout en compressant au même ratio que zlib.
Alors que les performances de l’algorithme pur sont importantes lorsque la compression est intégrée dans une application plus large, il est extrêmement courant d’utiliser également des outils de ligne de commande pour la compression – par exemple, pour compresser des fichiers journaux, des tarballs, ou d’autres données similaires destinées au stockage ou au transfert. Dans ces cas, les performances sont souvent affectées par les frais généraux, tels que l’addition de contrôle. Ce tableau montre la comparaison des outils de ligne de commande gzip et zstd sur Centos 7 construit avec le compilateur par défaut du système.
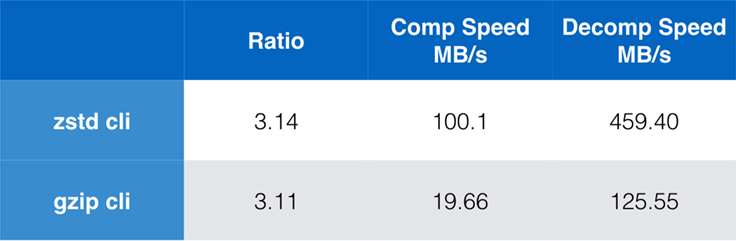
Les tests ont été effectués chacun 10 fois, avec les temps minimums pris, et ont été effectués sur ramdisk pour éviter la surcharge du système de fichiers. Voici les commandes (qui utilisent les niveaux de compression par défaut pour les deux outils):
zstd -c -3 silesia.tar > silesia.tar.zst # 67,432,740 byteszstd -d -c silesia.tar.zst > /dev/nullgzip -c -6 silesia.tar > silesia.tar.gz # 68,235,522 bytesgzip -d -c silesia.tar.gz > /dev/nullScalabilité
Si un algorithme est évolutif, il a la capacité de s’adapter à une grande variété d’exigences, et Zstandard est conçu pour exceller dans le paysage actuel et pour évoluer dans le futur. La plupart des algorithmes ont des « niveaux » basés sur des compromis temps/espace : Plus le niveau est élevé, plus la compression est importante, mais avec une perte de vitesse. Zlib propose neuf niveaux de compression ; Zstandard en propose actuellement 22, ce qui permet des compromis flexibles et granulaires entre la vitesse de compression et les ratios pour les données futures. Par exemple, nous pouvons utiliser le niveau 1 si la vitesse est la plus importante et le niveau 22 si la taille est la plus importante.
Vous trouverez ci-dessous un graphique de la vitesse et du ratio de compression obtenus pour tous les niveaux de Zstandard et zlib. L’axe des x est une échelle logarithmique décroissante en mégaoctets par seconde ; l’axe des y est le taux de compression atteint. Pour comparer les algorithmes, vous pouvez choisir une vitesse pour voir les différents taux obtenus par les algorithmes à cette vitesse. De même, vous pouvez choisir un ratio et voir la vitesse des algorithmes lorsqu’ils atteignent ce niveau.
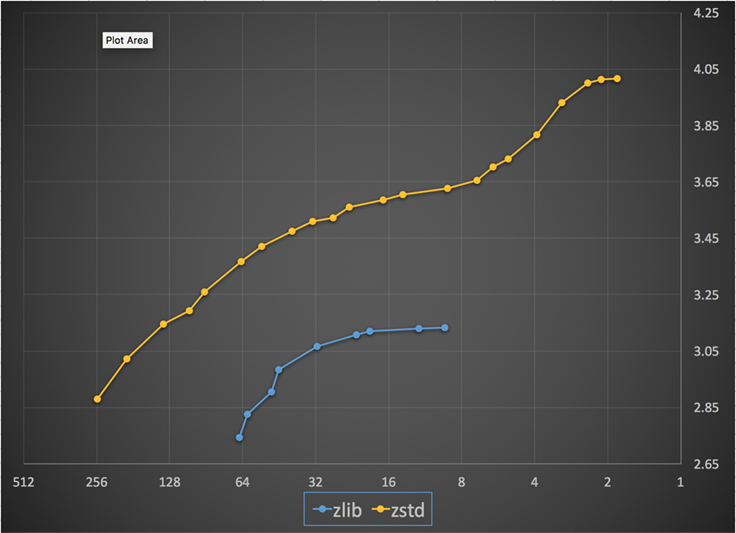
Pour toute ligne verticale (c’est-à-dire la vitesse de compression), Zstandard atteint un ratio de compression plus élevé. Pour le corpus Silesia, la vitesse de décompression – indépendamment du ratio – était d’environ 550 Mo/s pour Zstandard et 270 Mo/s pour zlib. Le graphique montre une autre différence entre Zstandard et les autres solutions : En utilisant un seul algorithme et une seule implémentation, Zstandard permet un réglage beaucoup plus fin pour chaque cas d’utilisation. Cela signifie que Zstandard peut rivaliser avec certains des algorithmes de compression les plus rapides et les plus élevés tout en conservant un avantage substantiel en termes de vitesse de décompression. Ces améliorations se traduisent directement par un transfert de données plus rapide et des exigences de stockage plus faibles.
En d’autres termes, par rapport à zlib, Zstandard évolue :
- Au même taux de compression, il compresse sensiblement plus vite : ~3-5x.
- À la même vitesse de compression, il est sensiblement plus petit : 10-15 pour cent plus petit.
- Il est presque 2x plus rapide à la décompression, quel que soit le taux de compression ; les chiffres de l’outil de ligne de commande montrent une différence encore plus grande : plus de 3x plus rapide.
- Il évolue vers des taux de compression beaucoup plus élevés, tout en maintenant des vitesses de décompression fulgurantes.
Sous le capot
Zstandard améliore zlib en combinant plusieurs innovations récentes et en ciblant le matériel moderne :
Mémoire
Par conception, zlib est limité à une fenêtre de 32 Ko, ce qui était un choix judicieux au début des années 90. Mais, l’environnement informatique d’aujourd’hui peut accéder à beaucoup plus de mémoire – même dans les environnements mobiles et embarqués.
Zstandard n’a pas de limite inhérente et peut adresser des téraoctets de mémoire (bien qu’il le fasse rarement). Par exemple, le plus bas des 22 niveaux utilise 1 Mo ou moins. Pour la compatibilité avec un large éventail de systèmes de réception, où la mémoire peut être limitée, il est recommandé de limiter l’utilisation de la mémoire à 8 Mo. Il s’agit toutefois d’une recommandation de réglage, et non d’une limitation du format de compression.
Un format conçu pour l’exécution parallèle
Les CPU d’aujourd’hui sont très puissants et peuvent émettre plusieurs instructions par cycle, grâce à de multiples ALU (unités arithmétiques logiques) et à une conception d’exécution hors ordre de plus en plus avancée.
En substance, cela signifie que si:
a = b1 + b2
c = d1 + d2
alors les deux a et c seront calculés en parallèle.
Cela n’est possible que s’il n’y a pas de relation entre eux. Par conséquent, dans cet exemple :
a = b1 + b2
c = d1 + a
c doit attendre que a soit calculé en premier, et ce n’est qu’ensuite que le calcul de c commencera.
Cela signifie que, pour tirer parti de l’unité centrale moderne, il faut concevoir un flux d’opérations avec peu ou pas de dépendances de données.
Cela est réalisé avec Zstandard en séparant les données en plusieurs flux parallèles. Un décodeur Huffman de nouvelle génération, Huff0, est capable de décoder plusieurs symboles en parallèle avec un seul cœur. Un tel gain est cumulatif avec le multithreading, qui utilise plusieurs cœurs.
Conception sans branchement
Les nouveaux CPU sont plus puissants et atteignent des fréquences très élevées, mais cela n’est possible que grâce à une approche multi-étapes, où une instruction est divisée en un pipeline de plusieurs étapes. À chaque cycle d’horloge, le processeur est capable d’émettre le résultat de plusieurs opérations, en fonction des UAL disponibles. Plus le nombre d’UAL utilisées est élevé, plus le CPU travaille, et donc plus la compression est rapide. Garder les UAL alimentées en travail est crucial pour les performances des CPU modernes.
Cela s’avère être difficile. Considérons la situation simple suivante :
if (condition) doSomething() else doSomethingElse()Lorsqu’elle rencontre cette situation, la CPU ne sait pas quoi faire, puisqu’elle dépend de la valeur de condition. Une unité centrale prudente attendrait le résultat de condition avant de travailler sur l’une ou l’autre branche, ce qui serait extrêmement gaspilleur.
Les unités centrales d’aujourd’hui jouent. Ils le font intelligemment, grâce à un prédicteur de branche, qui leur indique en substance le résultat le plus probable de l’évaluation de condition. Lorsque le pari est bon, le pipeline reste plein et les instructions sont émises en continu. Lorsque le pari est faux (une mauvaise prédiction), le CPU doit arrêter toutes les opérations commencées de manière spéculative, revenir à la branche, et prendre l’autre direction. Cela s’appelle une purge de pipeline, et est extrêmement coûteux dans les CPU modernes.
Il y a vingt-cinq ans, la purge de pipeline n’était pas un problème. Aujourd’hui, il est si important qu’il est essentiel de concevoir des formats compatibles avec les algorithmes sans branchements. À titre d’exemple, examinons une mise à jour de flux de bits :
/* classic version */while (nbBitsUsed >= 8) { /* each while test is a branch */ accumulator <<= 8; accumulator += *byte++; nbBitsUsed -= 8;} /*>/* branch-less version */nbBytesUsed = nbBitsUsed >> 3;nbBitsUsed &= 7;ptr += nbBytesUsed;accumulator = read64(ptr);Comme vous pouvez le voir, la version sans branchement a une charge de travail prévisible, sans aucune condition. Le CPU fera toujours le même travail, et ce travail n’est jamais jeté à cause d’une mauvaise prédiction. En revanche, la version classique effectue moins de travail lorsque (nbBitsUsed < 8). Mais le test lui-même n’est pas gratuit, et chaque fois que le test est deviné de manière incorrecte, il en résulte un rinçage complet du pipeline, ce qui coûte plus que le travail effectué par la version sans branche.
Comme vous pouvez le deviner, cet effet secondaire a des impacts sur la manière dont les données sont emballées, lues et décodées. Zstandard a été créé pour être amical envers les algorithmes sans branche, en particulier au sein des boucles critiques.
Entropie d’état finie : Un compresseur de probabilité de nouvelle génération
Dans la compression, les données sont d’abord transformées en un ensemble de symboles (l’étape de modélisation), puis ces symboles sont codés en utilisant un nombre minimal de bits. Cette deuxième étape est appelée étape d’entropie, en mémoire de Claude Shannon, qui calcule précisément la limite de compression d’un ensemble de symboles avec des probabilités données (appelée « limite de Shannon »). Le but est de se rapprocher de cette limite tout en utilisant le moins de ressources CPU possible.
Un algorithme très courant est le codage de Huffman, utilisé au sein de Deflate. Il donne le meilleur code préfixe possible, en supposant que chaque symbole est décrit avec un nombre naturel de bits (1 bit, 2 bits…). Cela fonctionne très bien en pratique, mais la limite des nombres naturels signifie qu’il est impossible d’atteindre des taux de compression élevés, car un symbole consomme nécessairement au moins 1 bit.
Une meilleure méthode est appelée codage arithmétique, qui peut se rapprocher arbitrairement de la limite de Shannon -log2(P), donc consommer des bits fractionnaires par symbole. Cela se traduit par un meilleur taux de compression lorsque les probabilités sont élevées, mais cela consomme également plus de puissance CPU. En pratique, même les codeurs arithmétiques optimisés luttent pour la vitesse, notamment du côté de la décompression, qui nécessite des divisions avec un résultat prévisible (par exemple, pas une virgule flottante) et qui s’avère lente.
L’entropie d’état finie est basée sur une nouvelle théorie appelée ANS (Asymmetric Numeral System) par Jarek Duda. Finite State Entropy est une variante qui précompute de nombreuses étapes de codage dans des tables, ce qui donne un codec entropique aussi précis que le codage arithmétique, n’utilisant que des additions, des consultations de tables et des décalages, ce qui représente à peu près le même niveau de complexité que Huffman. Il réduit également la latence pour accéder au symbole suivant, car il est immédiatement accessible à partir de la valeur d’état, alors que Huffman nécessite une opération préalable de décodage du flux binaire. Expliquer son fonctionnement sort du cadre de ce billet, mais si cela vous intéresse, il existe une série d’articles détaillant son fonctionnement interne.
Modélisation du re-code
La modélisation du re-code compresse efficacement les données structurées, qui présentent des séquences de contenu presque équivalent, ne différant que par un ou quelques octets. Cette méthode n’est pas nouvelle mais a été utilisée pour la première fois après la publication de Deflate, elle n’existe donc pas dans zlib/gzip.
L’efficacité de la modélisation du repcode dépend fortement du type de données à compresser, allant d’une amélioration de compression à un chiffre à deux chiffres. Ces améliorations combinées s’ajoutent à une expérience de compression meilleure et plus rapide, offerte au sein de la bibliothèque Zstandard.
Zstandard en pratique
Comme mentionné précédemment, il existe plusieurs cas d’utilisation typiques de la compression. Pour qu’un algorithme soit convaincant, il doit soit être extraordinairement bon dans un cas d’utilisation spécifique, comme la compression de texte lisible par l’homme, soit très bon dans de nombreux cas d’utilisation divers. Zstandard adopte cette dernière approche. Une façon de penser aux cas d’utilisation est de savoir combien de fois un élément de données spécifique peut être décompressé. Zstandard présente des avantages dans tous ces cas.
De nombreuses fois. Pour les données traitées de nombreuses fois, la vitesse de décompression et la possibilité d’opter pour un taux de compression très élevé sans compromettre la vitesse de décompression sont avantageuses. Le stockage du graphe social sur Facebook, par exemple, est lu à plusieurs reprises lorsque vous et vos amis interagissez avec le site. En dehors de Facebook, les exemples de cas où les données doivent être décompressées de nombreuses fois comprennent les fichiers téléchargés à partir d’un serveur, tels que le code source du noyau Linux ou les RPM installés sur les serveurs, le JavaScript et le CSS utilisés par une page Web, ou l’exécution de milliers de MapReduces sur les données d’un entrepôt de données.
Une seule fois. Pour les données compressées une seule fois, notamment pour la transmission sur un réseau, la compression est un moment fugace dans le flux de données. Moins il y a de frais généraux sur le serveur, plus celui-ci peut traiter de demandes par seconde. La réduction des frais généraux sur le client signifie que les données peuvent être traitées plus rapidement. En général, cela se produit dans des situations client/serveur où les données sont uniques pour le client, comme une réponse de serveur Web personnalisée – par exemple, les données utilisées pour le rendu lorsque vous recevez une note d’un ami sur Messenger. Le résultat net est que votre appareil mobile charge les pages plus rapidement, utilise moins de batterie et consomme moins de votre plan de données. Zstandard en particulier convient aux scénarios mobiles beaucoup mieux que les autres algorithmes en raison de la façon dont il gère les petites données.
Possiblement jamais. Bien que cela semble contre-intuitif, il arrive souvent qu’un élément de données – comme les sauvegardes ou les fichiers journaux – ne soit jamais décompressé mais puisse être lu si nécessaire. Pour ce type de données, la compression doit généralement être rapide, réduire la taille des données (avec un compromis temps/espace adapté à la situation), éventuellement stocker une somme de contrôle, mais être invisible. Dans les rares cas où il est nécessaire de décompresser les données, il ne faut pas que la compression ralentisse l’utilisation opérationnelle. La décompression rapide est bénéfique car il s’agit souvent d’une petite partie des données (comme un fichier spécifique dans la sauvegarde ou un message dans un fichier journal) qui doit être retrouvée rapidement.
Dans tous ces cas, Zstandard apporte la capacité de compresser et de décompresser plusieurs fois plus rapidement que gzip, avec les données compressées résultantes plus petites.
Petites données
Il existe un autre cas d’utilisation de la compression qui reçoit moins d’attention mais qui peut être assez important : les petites données. Il s’agit de modèles d’utilisation où les données sont produites et consommées en petites quantités, comme les messages JSON entre un serveur web et un navigateur (généralement des centaines d’octets) ou des pages de données dans une base de données (quelques kilo-octets).
Les bases de données fournissent un cas d’utilisation intéressant. Des systèmes tels que MySQL, PostgreSQL et MongoDB stockent tous des données destinées à un accès en temps réel. Les récents avantages matériels, notamment autour de la prolifération des dispositifs flash (SSD), ont fondamentalement changé l’équilibre entre la taille et le débit – nous vivons désormais dans un monde où les IOP (opérations d’entrée/sortie par seconde) sont assez élevées, mais où la capacité de nos dispositifs de stockage est inférieure à ce qu’elle était lorsque les disques durs régnaient sur le centre de données.
En outre, la flash a une propriété intéressante concernant l’endurance en écriture – après des milliers d’écritures sur la même section du dispositif, cette section ne peut plus accepter d’écritures, ce qui conduit souvent à la mise hors service du dispositif. Il est donc naturel de chercher des moyens de réduire la quantité de données écrites, car cela peut signifier plus de données par serveur et épuiser le dispositif à un rythme plus lent. La compression des données est une stratégie pour cela, et les bases de données sont aussi souvent optimisées pour les performances, ce qui signifie que les performances de lecture et d’écriture sont tout aussi importantes.
Il y a cependant une complication pour utiliser la compression des données avec les bases de données. Les bases de données aiment accéder aux données de manière aléatoire, alors que la plupart des cas d’utilisation typiques de la compression lisent un fichier entier dans un ordre linéaire. C’est un problème car la compression des données fonctionne essentiellement en prédisant l’avenir sur la base du passé – les algorithmes examinent vos données de manière séquentielle et prédisent ce qu’ils pourraient voir à l’avenir. Plus les prédictions sont précises, plus il peut réduire la taille des données.
Lorsque vous compressez de petites données, comme des pages dans une base de données ou de minuscules documents JSON envoyés à votre appareil mobile, il n’y a tout simplement pas beaucoup de « passé » à utiliser pour prédire l’avenir. Les algorithmes de compression ont tenté de remédier à ce problème en utilisant des dictionnaires pré-partagés pour démarrer efficacement. Cela se fait en partageant au préalable un ensemble statique de données « passées » comme graine pour la compression.
Zstandard s’appuie sur cette approche avec des algorithmes et des API hautement optimisés pour la compression de dictionnaires. En outre, Zstandard comprend des outils (zstd --train) permettant de créer facilement des dictionnaires pour des applications personnalisées et des dispositions pour enregistrer des dictionnaires standard afin de les partager avec de plus grandes communautés. Bien que la compression varie en fonction des échantillons de données, la compression des petites données peut aller de 2x à 5x mieux que la compression sans dictionnaire.
Dictionnaires en action
Bien qu’il puisse être difficile de jouer avec un dictionnaire dans le contexte d’une base de données en cours d’exécution (cela nécessite des modifications importantes de la base de données, après tout), vous pouvez voir des dictionnaires en action avec d’autres types de petites données. JSON, la lingua franca des petites données dans le monde moderne, tend à être de petits enregistrements répétitifs. Il existe d’innombrables ensembles de données publiques disponibles ; pour les besoins de cette démonstration, nous utiliserons l’ensemble de données « user » de GitHub, disponible via HTTP. Voici un exemple d’entrée de cet ensemble de données :
{ "login": "octocat", "id": 1, "avatar_url": "https://github.com/images/error/octocat_happy.gif", "gravatar_id": "", "url": "https://api.github.com/users/octocat", "html_url": "https://github.com/octocat", "followers_url": "https://api.github.com/users/octocat/followers", "following_url": "https://api.github.com/users/octocat/following{/other_user}", "gists_url": "https://api.github.com/users/octocat/gists{/gist_id}", "starred_url": "https://api.github.com/users/octocat/starred{/owner}{/repo}", "subscriptions_url": "https://api.github.com/users/octocat/subscriptions", "organizations_url": "https://api.github.com/users/octocat/orgs", "repos_url": "https://api.github.com/users/octocat/repos", "events_url": "https://api.github.com/users/octocat/events{/privacy}", "received_events_url": "https://api.github.com/users/octocat/received_events", "type": "User", "site_admin": false }Comme vous pouvez le voir, il y a pas mal de répétitions ici – nous pouvons les compresser joliment ! Mais chaque utilisateur représente un peu moins de 1 Ko, et la plupart des algorithmes de compression ont vraiment besoin de plus de données pour se dégourdir les jambes. Un ensemble de 1 000 utilisateurs nécessite environ 850 Ko pour être stocké sans être compressé. En appliquant naïvement gzip ou zstd individuellement à chaque fichier, on réduit cette quantité à un peu plus de 300 Ko, ce qui n’est pas mal ! Mais si nous créons un dictionnaire pré-partagé à usage unique, avec zstd, la taille tombe à 122 Ko – faisant passer le taux de compression original de 2,8x à 6,9. Il s’agit d’une amélioration significative, disponible dès la sortie de l’emballage avec zstd:
$ zstd --train -o ../json.zdict -r .sorting 982 files of total size 0 MB ...finding patterns ...statistics ...Save dictionary of size 65599 into file ../json.zdict$ du -h --apparent-size .846K .$ zstd --rm -D ../json.zdict -r .$ du -h --apparent-size .122K .Choisir un niveau de compression
Comme indiqué ci-dessus, Zstandard fournit un nombre substantiel de niveaux. Cette personnalisation est puissante mais conduit à des choix difficiles. La meilleure façon de décider est d’examiner vos données et de mesurer, en décidant des compromis que vous voulez faire. Chez Facebook, nous trouvons que le niveau 3 par défaut convient à de nombreux cas d’utilisation, mais de temps en temps, nous l’ajustons légèrement en fonction de ce qu’est notre goulot d’étranglement (souvent, nous essayons de saturer une connexion réseau ou une broche de disque) ; d’autres fois, nous nous soucions davantage de la taille stockée et nous utiliserons un niveau plus élevé.
En fin de compte, pour obtenir les résultats les plus adaptés à vos besoins, vous devrez tenir compte à la fois du matériel que vous utilisez et des données dont vous vous souciez – il n’y a pas de prescriptions dures et rapides qui peuvent être faites sans contexte. Dans le doute, cependant, soit s’en tenir au niveau par défaut de 3 ou quelque chose de la gamme 6 à 9 pour un bon compromis de la vitesse par rapport à l’espace ; sauver le niveau 20 + pour les cas où vous vous souciez vraiment seulement de la taille et pas de la vitesse de compression.
Try it out
Zstandard est à la fois un outil de ligne de commande (zstd) et une bibliothèque. Il est écrit en C hautement portable, ce qui le rend adapté à pratiquement toutes les plateformes utilisées aujourd’hui – qu’il s’agisse des serveurs qui font tourner votre entreprise, de votre ordinateur portable ou même du téléphone dans votre poche. Vous pouvez l’attraper à partir de notre dépôt github, le compiler avec un simple make install, et commencer à l’utiliser comme vous le feriez avec gzip:
$ zstd access.logaccess.log : 8.07% (6695078 => 540336 bytes, access.log.zst)Comme vous pouvez vous y attendre, vous pouvez l’utiliser dans le cadre d’un pipeline de commandes, par exemple, pour sauvegarder votre base de données MySQL critique:
$ mysqldump --single-transaction --opt pokemon | zstd -q -o /srv/backups/mysqldump.sql.zstLa commande tar prend en charge différentes implémentations de compression prêtes à l’emploi, donc une fois que vous installez Zstandard, vous pouvez immédiatement travailler avec des tarballs compressés avec Zstandard. Voici un exemple simple qui la montre en utilisation avec tar et la différence de vitesse par rapport à gzip:
$ time tar -I zstd -cf linux-4.6.4.tar.zst linux-4.6.4tar -I zstd -cf linux-4.6.4.tar.zst linux-4.6.4 3.15s user 0.50s system 107% cpu 3.396 total$ time tar -zcf linux-4.6.4.tar.gz linux-4.6.4tar -zcf linux-4.6.4.tar.gz linux-4.6.4 13.74s user 0.43s system 102% cpu 13.784 totalAu delà de l’utilisation en ligne de commande, il y a les APIs, documentées dans les fichiers d’en-tête dans le dépôt (commencez ici pour un aperçu des APIs). Nous incluons également une API wrapper compatible avec la zlib (libWrapper) pour une intégration plus facile avec les outils qui ont déjà des interfaces zlib. Enfin, nous incluons un certain nombre d’exemples, à la fois d’utilisation de base et d’utilisation plus avancée comme les dictionnaires et le streaming, également dans le dépôt GitHub.
Plus à venir
Bien que nous ayons atteint la 1.0 et que nous considérions que Zstandard est prêt pour tout type d’utilisation en production, nous n’avons pas terminé. À venir dans les futures versions :
- Compression en ligne de commande multithread pour un débit encore plus rapide sur les grands ensembles de données, similaire à l’outil pigz pour zlib.
- Nouveaux niveaux de compression, dans les deux sens, permettant une compression encore plus rapide et des ratios plus élevés.
- Un ensemble prédéfini, maintenu par la communauté, de dictionnaires de compression pour les ensembles de données courants tels que JSON, HTML et les protocoles réseau courants.
Nous tenons à remercier tous les contributeurs, à la fois du code et des commentaires, qui nous ont aidés à atteindre la version 1.0. Ce n’est que le début. Nous savons que pour que Zstandard soit à la hauteur de son potentiel, nous avons besoin de votre aide. Comme mentionné ci-dessus, vous pouvez essayer Zstandard dès aujourd’hui en récupérant les sources ou les binaires pré-construits sur notre projet GitHub, ou, pour les utilisateurs de Mac, en installant via homebrew (brew install zstd). Nous aimerions avoir vos commentaires et vos cas d’utilisation intéressants, ainsi que des liaisons de langage supplémentaires et de l’aide pour l’intégrer à vos projets open source préférés.
Footnotes
- Bien que la compression de données sans perte soit le point central de ce post, il existe un domaine connexe mais très différent de la compression de données avec perte, utilisé principalement pour les images, l’audio et la vidéo.
- Deflate, zlib, gzip – trois noms entrelacés. Deflate est l’algorithme utilisé par les implémentations zlib et gzip. Zlib est une bibliothèque fournissant Deflate, et gzip est un outil en ligne de commande qui utilise zlib pour la déflation des données ainsi que l’addition de contrôle. Cette somme de contrôle peut avoir une surcharge significative.
- Tous les benchmarks ont été effectués sur un Intel E5-2678 v3 fonctionnant à 2,5 GHz sur une machine Centos 7. Les outils en ligne de commande (
zstdetgzip) ont été construits avec le système GCC, 4.8.5. Les benchmarks algorithmiques réalisés par lzbench ont été construits avec GCC 6.
.
Laisser un commentaire