Dans ce post, nous allons jeter un coup d’œil aux algorithmes d’apprentissage automatique les plus utilisés. Il en existe une énorme variété, et il est facile de se sentir confus lorsque vous entendez des termes tels que « algorithmes d’apprentissage basés sur les instances » et « perceptron ».
En général, tous les algorithmes d’apprentissage automatique sont divisés en groupes basés soit sur leur style d’apprentissage, leur fonction ou les problèmes qu’ils résolvent. Dans ce post, vous trouverez une classification basée sur le style d’apprentissage. Je mentionnerai également les tâches courantes que ces algorithmes aident à résoudre.
Le nombre d’algorithmes d’apprentissage automatique qui sont utilisés aujourd’hui est important, et je ne mentionnerai pas 100% d’entre eux. Cependant, je voudrais donner un aperçu des plus couramment utilisés.
- Agorithmes d’apprentissage supervisé
- Algorithmes de classification
- Naive Bayes
- Bayes naïfs multinomiaux
- Régression logistique
- Arbres de décision
- SVM (Support Vector Machine)
- Algorithmes de régression
- Régression linéaire
- Algorithmes d’apprentissage non supervisé
- Clustering
- Clustering k-means
- K-nearest neighbor
- Réduction de la dimensionnalité
- Apprentissage de règles d’association
- Apprentissage par renforcement
- Q-Learning
- Apprentissage par assemblage
- Bagging
- Boosting
- Forêt aléatoire
- Stacking
- Réseaux neuronaux
- Conclusion
Agorithmes d’apprentissage supervisé

Si vous n’êtes pas familier avec des termes tels que « apprentissage supervisé » et « apprentissage non supervisé », consultez notre post AI vs ML où ce sujet est traité en détail. Maintenant, familiarisons-nous avec les algorithmes.
Algorithmes de classification
Naive Bayes

Les algorithmes bayésiens sont une famille de classificateurs probabilistes utilisés en ML, basés sur l’application du théorème de Bayes.
Le classificateur Naive Bayes a été l’un des premiers algorithmes utilisés pour l’apprentissage automatique. Il convient à la classification binaire et multiclasse et permet de faire des prédictions et de prévoir des données sur la base de résultats historiques. Un exemple classique est celui des systèmes de filtrage du spam qui ont utilisé Naive Bayes jusqu’en 2010 et ont montré des résultats satisfaisants. Cependant, lorsque l’empoisonnement bayésien a été inventé, les programmeurs ont commencé à penser à d’autres façons de filtrer les données.
En utilisant le théorème de Bayes, il est possible de dire comment l’occurrence d’un événement a un impact sur la probabilité d’un autre événement.
Par exemple, cet algorithme calcule la probabilité qu’un certain courriel soit ou non un spam en fonction des mots typiques utilisés. Les mots courants du spam sont « offre », « commander maintenant » ou « revenu supplémentaire ». Si l’algorithme détecte ces mots, il y a une forte probabilité que l’email soit un spam.
Naive Bayes suppose que les caractéristiques sont indépendantes. Par conséquent, l’algorithme est appelé naïf.
Bayes naïfs multinomiaux
En dehors du classificateur Bayes naïfs, il existe d’autres algorithmes dans ce groupe. Par exemple, Multinomial Naive Bayes, qui est généralement appliqué pour la classification de documents basée sur la fréquence de certains mots présents dans le document.
Les algorithmes bayésiens sont toujours utilisés pour la catégorisation de textes et la détection de fraude. Ils peuvent également être appliqués pour la vision artificielle (par exemple, la détection des visages), la segmentation du marché et la bioinformatique.
Régression logistique
Même si le nom peut sembler contra-intuitif, la régression logistique est en fait un type d’algorithme de classification.
La régression logistique est un modèle qui fait des prédictions en utilisant une fonction logistique pour trouver la dépendance entre les variables de sortie et d’entrée. Statquest a fait une excellente vidéo où ils expliquent la différence entre la régression linéaire et la régression logistique en prenant comme exemple des souris obèses.
Arbres de décision
Un arbre de décision est un moyen simple de visualiser un modèle de prise de décision sous la forme d’un arbre. Les avantages des arbres de décision sont qu’ils sont faciles à comprendre, à interpréter et à visualiser. De plus, ils demandent peu d’efforts pour la préparation des données.
Cependant, ils ont aussi un gros inconvénient. Les arbres peuvent être instables à cause des plus petites variations (variance) des données. Il est également possible de créer des arbres trop complexes qui ne généralisent pas bien. C’est ce qu’on appelle l’overfitting. La mise en sac, le boosting et la régularisation permettent de lutter contre ce problème. Nous allons en parler plus tard dans le post.
Les éléments de chaque arbre de décision sont :
- Nœud racine qui pose la question principale. Il a les flèches qui pointent vers le bas à partir de lui mais pas de flèches qui pointent vers lui. Par exemple, imaginez que vous construisez un arbre pour décider quel type de pâtes vous devriez avoir pour le dîner.
- Branches. Une sous-section d’un arbre est appelée une branche ou parfois un sous-arbre.
- Nœuds de décision. Ce sont les sous-nœuds pour le nœud racine qui peut également être divisé en plus de nœuds. Vos nœuds de décision peuvent être « carbonara ? » ou « avec champignons ? ».
- Les feuilles ou les nœuds terminaux. Ces nœuds ne se divisent pas. Ils représentent les décisions finales ou les prédictions.
En outre, il est important de mentionner la division. Il s’agit du processus de division d’un nœud en sous-nœuds. Par exemple, si vous n’êtes pas végétarien, la carbonara est acceptable. Mais si vous l’êtes, mangez des pâtes aux champignons. Il existe également un processus de suppression des nœuds appelé élagage.
Les algorithmes d’arbres de décision sont appelés CART (Classification and Regression Trees). Les arbres de décision peuvent fonctionner avec des données catégorielles ou numériques.
- Les arbres de régression sont utilisés lorsque les variables ont une valeur numérique.
- Les arbres de classification peuvent être appliqués lorsque les données sont catégorielles (classes).
Les arbres de décision sont assez intuitifs à comprendre et à utiliser. C’est pourquoi les diagrammes d’arbres sont couramment appliqués dans un large éventail d’industries et de disciplines. GreyAtom fournit un large aperçu des différents types d’arbres de décision et de leurs applications pratiques.
SVM (Support Vector Machine)
Les machines à vecteurs de support sont un autre groupe d’algorithmes utilisés pour les tâches de classification et, parfois, de régression. Le SVM est génial car il donne des résultats assez précis avec une puissance de calcul minimale.
Le but du SVM est de trouver un hyperplan dans un espace à N dimensions (où N correspond au nombre de caractéristiques) qui classe distinctement les points de données. La précision des résultats est directement liée à l’hyperplan que nous choisissons. Nous devons trouver un plan qui présente la distance maximale entre les points de données des deux classes.
Cet hyperplan est représenté graphiquement comme une ligne qui sépare une classe d’une autre. Les points de données qui tombent sur différents côtés de l’hyperplan sont attribués à différentes classes.
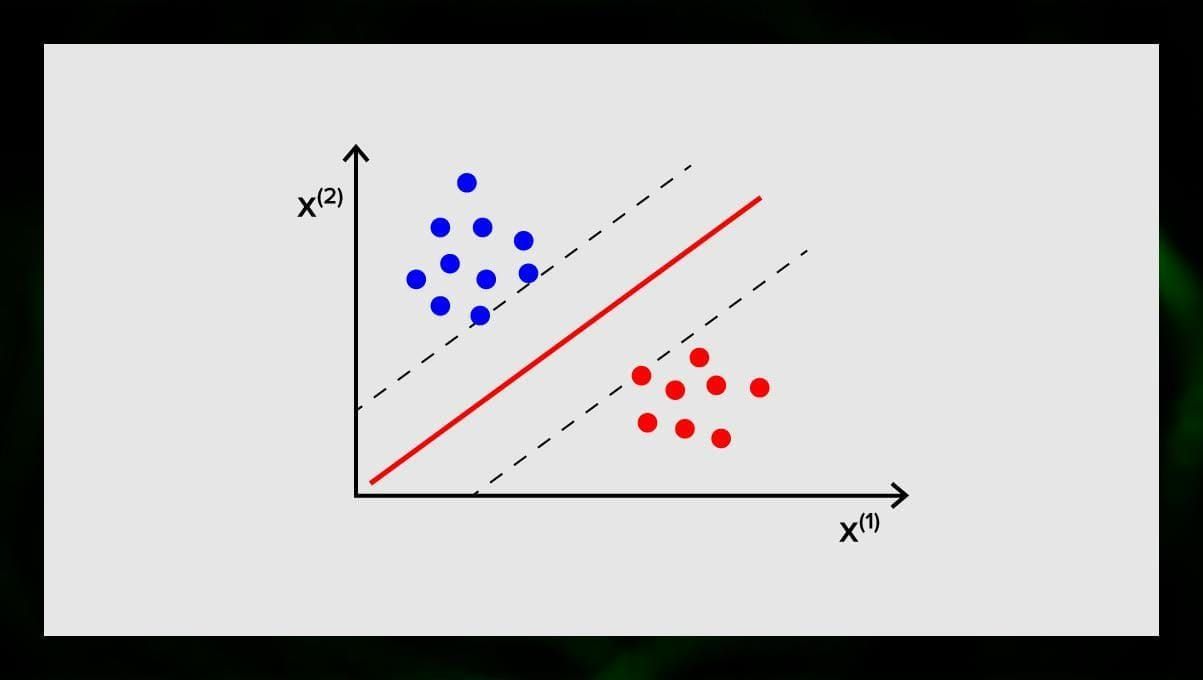
Notez que la dimension de l’hyperplan dépend du nombre de caractéristiques. Si le nombre de caractéristiques d’entrée est de 2, alors l’hyperplan est juste une ligne. Si le nombre de caractéristiques d’entrée est de 3, alors l’hyperplan devient un plan à deux dimensions. Il devient difficile de dessiner un modèle sur un graphique lorsque le nombre de caractéristiques est supérieur à 3. Donc, dans ce cas, vous utiliserez des types de noyaux pour le transformer en un espace à 3 dimensions.
Pourquoi cela s’appelle-t-il une machine à vecteurs de support ? Les vecteurs de support sont les points de données les plus proches de l’hyperplan. Ils influencent directement la position et l’orientation de l’hyperplan et nous permettent de maximiser la marge du classificateur. En supprimant les vecteurs de support, on modifie la position de l’hyperplan. Ce sont ces points qui nous aident à construire notre SVM.
Les SVM sont maintenant activement utilisés dans le diagnostic médical pour trouver des anomalies, dans les systèmes de contrôle de la qualité de l’air, pour l’analyse financière et les prédictions en bourse, et le contrôle des défauts des machines dans l’industrie.
Algorithmes de régression
Les algorithmes de régression sont utiles dans l’analytique, par exemple, lorsque vous essayez de prédire les coûts pour les titres ou les ventes pour un produit particulier à un moment donné.
Régression linéaire
La régression linéaire tente de modéliser la relation entre les variables en ajustant une équation linéaire aux données observées.
Il existe des variables explicatives et des variables dépendantes. Les variables dépendantes sont les choses que l’on veut expliquer ou prévoir. Les explicatives, comme il suit pour le nom, expliquent quelque chose. Si vous voulez construire une régression linéaire, vous supposez qu’il existe une relation linéaire entre vos variables dépendantes et indépendantes. Par exemple, il existe une corrélation entre les mètres carrés d’une maison et son prix ou la densité de population et les endroits où l’on trouve des kebabs dans la région.
Une fois que vous faites cette hypothèse, vous devez ensuite déterminer la relation linéaire spécifique. Vous devrez trouver une équation de régression linéaire pour un ensemble de données. La dernière étape consiste à calculer le résidu.
Note : Lorsque la régression dessine une ligne droite, elle est dite linéaire, lorsqu’il s’agit d’une courbe – polynomiale.
Algorithmes d’apprentissage non supervisé

Parlons maintenant des algorithmes qui sont capables de trouver des modèles cachés dans des données non étiquetées.
Clustering
Le clustering signifie que nous divisons les entrées en groupes selon le degré de leur similarité les unes par rapport aux autres. Le clustering est généralement l’une des étapes de la construction d’un algorithme plus complexe. Il est plus simple d’étudier chaque groupe séparément et de construire un modèle basé sur leurs caractéristiques, plutôt que de travailler avec tout en même temps. La même technique est constamment utilisée dans le marketing et les ventes pour répartir tous les clients potentiels en groupes.
Les algorithmes de clustering très courants sont le clustering k-means et le k-plus proche voisin.
Clustering k-means
Le clustering k-means divise l’ensemble des éléments de l’espace vectoriel en un nombre prédéfini de clusters k. Un nombre incorrect de clusters invalidera cependant l’ensemble du processus, il est donc important de l’essayer avec des nombres variables de clusters. L’idée principale de l’algorithme k-means est que les données sont divisées de manière aléatoire en clusters, puis le centre de chaque cluster obtenu à l’étape précédente est recalculé de manière itérative. Ensuite, les vecteurs sont à nouveau divisés en clusters. L’algorithme s’arrête lorsqu’à un certain point, il n’y a pas de changement dans les clusters après une itération.
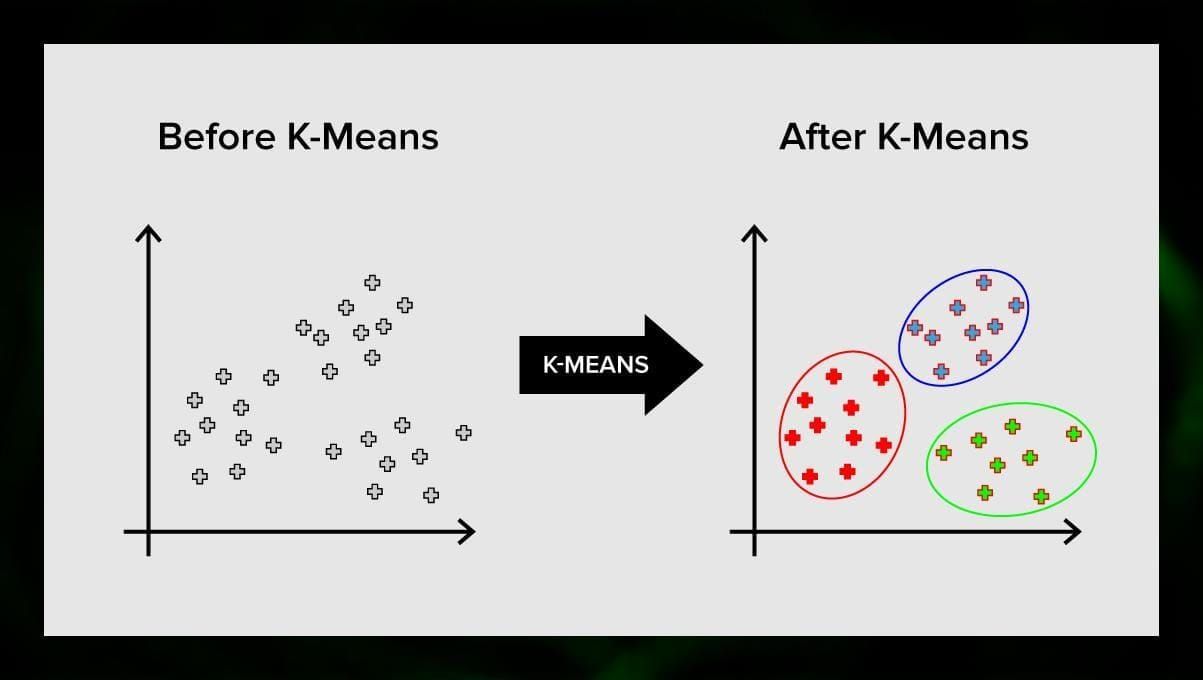
Cette méthode peut être appliquée pour résoudre des problèmes lorsque les clusters sont distincts ou peuvent être séparés les uns des autres facilement, sans chevauchement de données.
K-nearest neighbor
kNN signifie k-nearest neighbor. C’est l’un des algorithmes de classification les plus simples parfois utilisé dans les tâches de régression.
Pour entraîner le classificateur, il faut disposer d’un ensemble de données avec des classes prédéfinies. Le marquage se fait manuellement en faisant intervenir des spécialistes du domaine étudié. En utilisant cet algorithme, il est possible de travailler avec plusieurs classes ou de clarifier les situations où les entrées appartiennent à plus d’une classe.
La méthode est basée sur l’hypothèse que des étiquettes similaires correspondent à des objets proches dans l’espace vectoriel des attributs.
Les systèmes logiciels modernes utilisent le kNN pour la reconnaissance visuelle des formes, par exemple pour scanner et détecter les paquets cachés au fond du panier lors du passage en caisse (par exemple, AmazonGo). Le K-nearest neighbor est également utilisé dans le secteur bancaire pour détecter des modèles d’utilisation des cartes de crédit. Les algorithmes kNN analysent toutes les données et repèrent les modèles inhabituels qui indiquent une activité suspecte.
Réduction de la dimensionnalité
L’analyse en composantes principales (ACP) est une technique importante à comprendre pour résoudre efficacement les problèmes liés au ML.
Imaginez que vous avez beaucoup de variables à prendre en compte. Par exemple, vous devez regrouper les villes en trois groupes : bon pour la vie, mauvais pour la vie et so-so. Combien de variables devez-vous prendre en compte ? Probablement beaucoup. Comprenez-vous les relations entre elles ? Pas vraiment. Alors comment pouvez-vous prendre toutes les variables que vous avez collectées et vous concentrer sur seulement quelques-unes d’entre elles qui sont les plus importantes ?
En termes techniques, vous voulez « réduire la dimension de votre espace de caractéristiques. » En réduisant la dimension de votre espace de caractéristiques, vous parvenez à obtenir moins de relations entre les variables à considérer et vous êtes moins susceptible de surajuster votre modèle.
Il existe de nombreuses façons de réaliser la réduction de la dimensionnalité, mais la plupart de ces techniques tombent dans l’une des deux classes suivantes :
- Élimination de caractéristiques;
- Extraction de caractéristiques.
L’élimination de caractéristiques signifie que vous réduisez le nombre de caractéristiques en éliminant certaines d’entre elles. Les avantages de cette méthode sont qu’elle est simple et qu’elle maintient l’interprétabilité de vos variables. Comme inconvénient, bien que, vous obtenez zéro information des variables que vous avez décidé d’abandonner.
L’extraction de caractéristiques évite ce problème. L’objectif lors de l’application de cette méthode est d’extraire un ensemble de caractéristiques à partir de l’ensemble de données donné. L’extraction de caractéristiques vise à réduire le nombre de caractéristiques dans un ensemble de données en créant de nouvelles caractéristiques basées sur les caractéristiques existantes (et en éliminant les caractéristiques originales). Le nouvel ensemble réduit de caractéristiques doit être créé de manière à pouvoir résumer la plupart des informations contenues dans l’ensemble original de caractéristiques.
L’analyse en composantes principales est un algorithme d’extraction de caractéristiques. elle combine les variables d’entrée d’une manière spécifique, et il est alors possible de laisser tomber les variables « les moins importantes » tout en conservant les parties les plus précieuses de toutes les variables.
L’une des utilisations possibles de l’ACP est lorsque les images de l’ensemble de données sont trop grandes. Une représentation réduite des caractéristiques aide à traiter rapidement des tâches telles que la correspondance et la recherche d’images.
Apprentissage de règles d’association
Apriori est l’un des algorithmes de recherche de règles d’association les plus populaires. Il est capable de traiter de grandes quantités de données dans un laps de temps relativement court.
Le fait est que les bases de données de nombreux projets sont aujourd’hui très grandes, atteignant des gigaoctets et des téraoctets. Et elles vont continuer à croître. Par conséquent, on a besoin d’un algorithme efficace et évolutif pour trouver des règles associatives dans un court laps de temps. Apriori est l’un de ces algorithmes.
Pour pouvoir appliquer l’algorithme, il est nécessaire de préparer les données, en les convertissant toutes sous la forme binaire et en modifiant leur structure de données.
En général, on fait fonctionner cet algorithme sur une base de données contenant un grand nombre de transactions, par exemple, sur une base de données qui contient des informations sur tous les articles que les clients ont achetés dans un supermarché.
Apprentissage par renforcement

L’apprentissage par renforcement est l’une des méthodes d’apprentissage automatique qui permet d’apprendre à la machine comment interagir avec un certain environnement. Dans ce cas, l’environnement (par exemple, dans un jeu vidéo) sert d’enseignant. Il fournit un retour d’information sur les décisions prises par l’ordinateur. En fonction de cette récompense, la machine apprend à adopter la meilleure ligne de conduite. Cela rappelle la façon dont les enfants apprennent à ne pas toucher une poêle à frire chaude – par des essais et en ressentant de la douleur.
En décomposant ce processus, il implique ces étapes simples :
- L’ordinateur observe l’environnement ;
- Choisit une certaine stratégie ;
- Agit selon cette stratégie ;
- Reçoit une récompense ou une pénalité ;
- Apprend de cette expérience et affine la stratégie ;
- Répétition jusqu’à ce que la stratégie optimale soit trouvée.
Q-Learning
Il existe quelques algorithmes qui peuvent être utilisés pour l’apprentissage par renforcement. L’un des plus courants est le Q-learning.
Le Q-learning est un algorithme d’apprentissage par renforcement sans modèle. Le Q-learning est basé sur la rémunération reçue de l’environnement. L’agent forme une fonction d’utilité Q, qui lui donne par la suite la possibilité de choisir une stratégie de comportement, et de prendre en compte l’expérience des interactions précédentes avec l’environnement.
Un des avantages du Q-learning est qu’il est capable de comparer l’utilité attendue des actions disponibles sans former de modèles environnementaux.
Apprentissage par assemblage

L’apprentissage par assemblage est la méthode de résolution d’un problème en construisant plusieurs modèles ML et en les combinant. L’apprentissage d’ensemble est principalement utilisé pour améliorer les performances des modèles de classification, de prédiction et d’approximation de fonctions. D’autres applications de l’apprentissage d’ensemble comprennent la vérification de la décision prise par le modèle, la sélection de caractéristiques optimales pour la construction de modèles, l’apprentissage incrémental et l’apprentissage non stationnaire.
Vous trouverez ci-dessous certains des algorithmes d’apprentissage d’ensemble les plus courants.
Bagging
Bagging signifie agrégation par bootstrap. Il s’agit de l’un des premiers algorithmes d’ensemble, dont les performances sont étonnamment bonnes. Pour garantir la diversité des classificateurs, vous utilisez des répliques bootstrapées des données d’entraînement. Cela signifie que différents sous-ensembles de données de formation sont tirés au hasard – avec remplacement – de l’ensemble de données de formation. Chaque sous-ensemble de données d’entraînement est utilisé pour entraîner un classificateur différent du même type. Les classificateurs individuels peuvent ensuite être combinés. Pour ce faire, il faut procéder à un vote à la majorité simple de leurs décisions. La classe qui a été attribuée par la majorité des classificateurs est la décision d’ensemble.
Boosting
Ce groupe d’algorithmes d’ensemble est similaire au bagging. Le boosting utilise également une variété de classificateurs pour rééchantillonner les données, puis choisit la version optimale par vote majoritaire. Dans le boosting, vous entraînez de manière itérative des classificateurs faibles pour les assembler en un classificateur fort. Lorsque les classificateurs sont ajoutés, on leur attribue généralement certains poids, qui décrivent la précision de leurs prédictions. Après l’ajout d’un classificateur faible à l’ensemble, les poids sont recalculés. Les entrées incorrectement classées gagnent plus de poids, et les instances correctement classées en perdent. Ainsi, le système se concentre davantage sur les exemples où une classification erronée a été obtenue.
Forêt aléatoire
Les forêts aléatoires ou forêts de décision aléatoires sont une méthode d’apprentissage d’ensemble pour la classification, la régression et d’autres tâches. Pour construire une forêt aléatoire, vous devez entraîner une multitude d’arbres de décision sur des échantillons aléatoires de données d’entraînement. Le résultat de la forêt aléatoire est le résultat le plus fréquent parmi les arbres individuels. Les forêts de décision aléatoires combattent avec succès l’overfitting en raison de la _nature aléatoire_ de l’algorithme.
Stacking
Le stacking est une technique d’apprentissage d’ensemble qui combine plusieurs modèles de classification ou de régression via un méta-classifieur ou un méta-régresseur. Les modèles de niveau de base sont formés sur la base d’un ensemble d’apprentissage complet, puis le méta-modèle est formé sur les sorties des modèles de niveau de base comme caractéristiques.
Réseaux neuronaux
Un réseau neuronal est une séquence de neurones connectés par des synapses, ce qui rappelle la structure du cerveau humain. Cependant, le cerveau humain est encore plus complexe.
Ce qui est génial avec les réseaux neuronaux, c’est qu’ils peuvent être utilisés pour pratiquement n’importe quelle tâche, du filtrage du spam à la vision par ordinateur. Cependant, ils sont normalement appliqués pour la traduction automatique, la détection des anomalies et la gestion des risques, la reconnaissance vocale et la génération de langage, la reconnaissance des visages, et plus encore.
Un réseau neuronal est constitué de neurones, ou nœuds. Chacun de ces neurones reçoit des données, les traite, puis les transfère à un autre neurone.
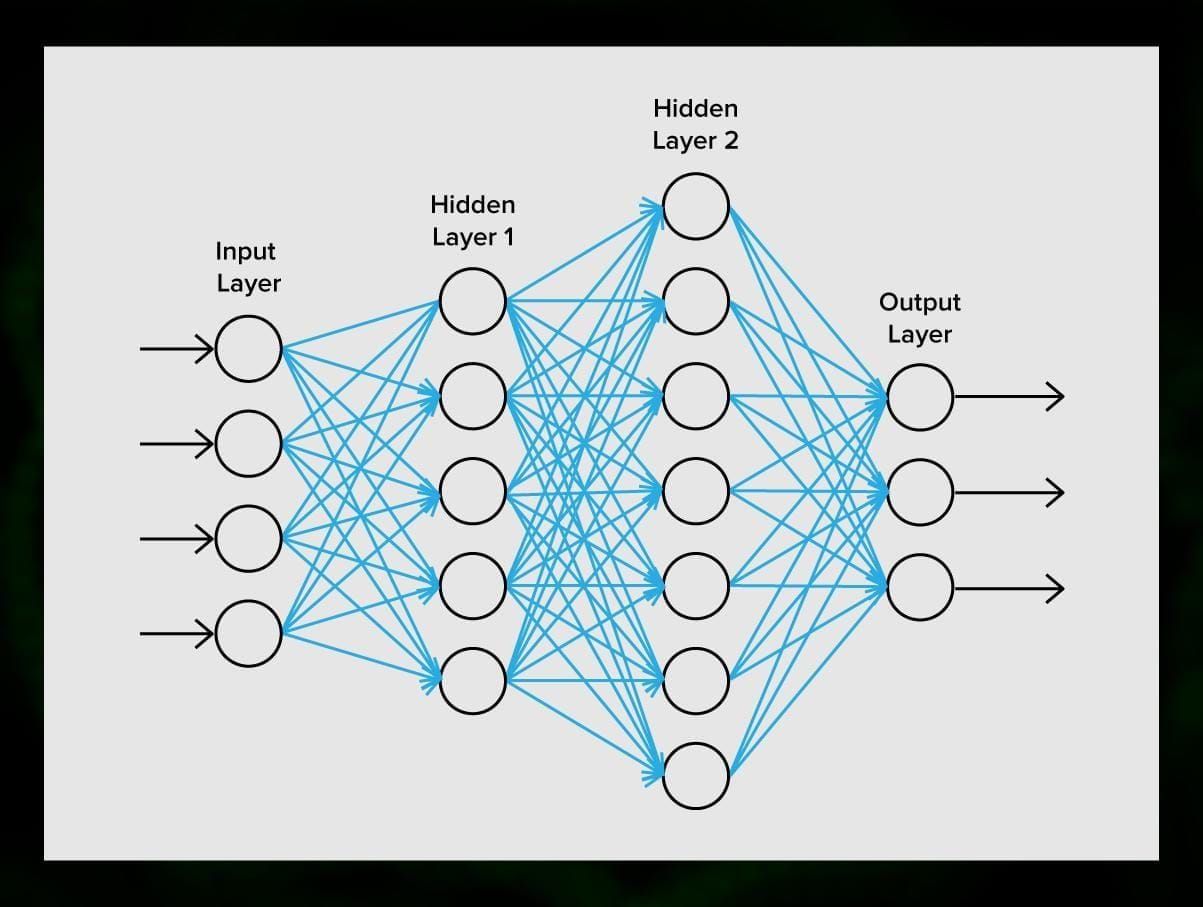
Chaque neurone traite les signaux de la même manière. Mais comment alors obtient-on un résultat différent ? Les synapses qui relient les neurones entre eux en sont responsables. Chaque neurone est capable d’avoir de nombreuses synapses qui atténuent ou amplifient le signal. En outre, les neurones sont capables de modifier leurs caractéristiques au fil du temps. En choisissant les bons paramètres des synapses, nous serons en mesure d’obtenir les bons résultats de la conversion des informations d’entrée à la sortie.
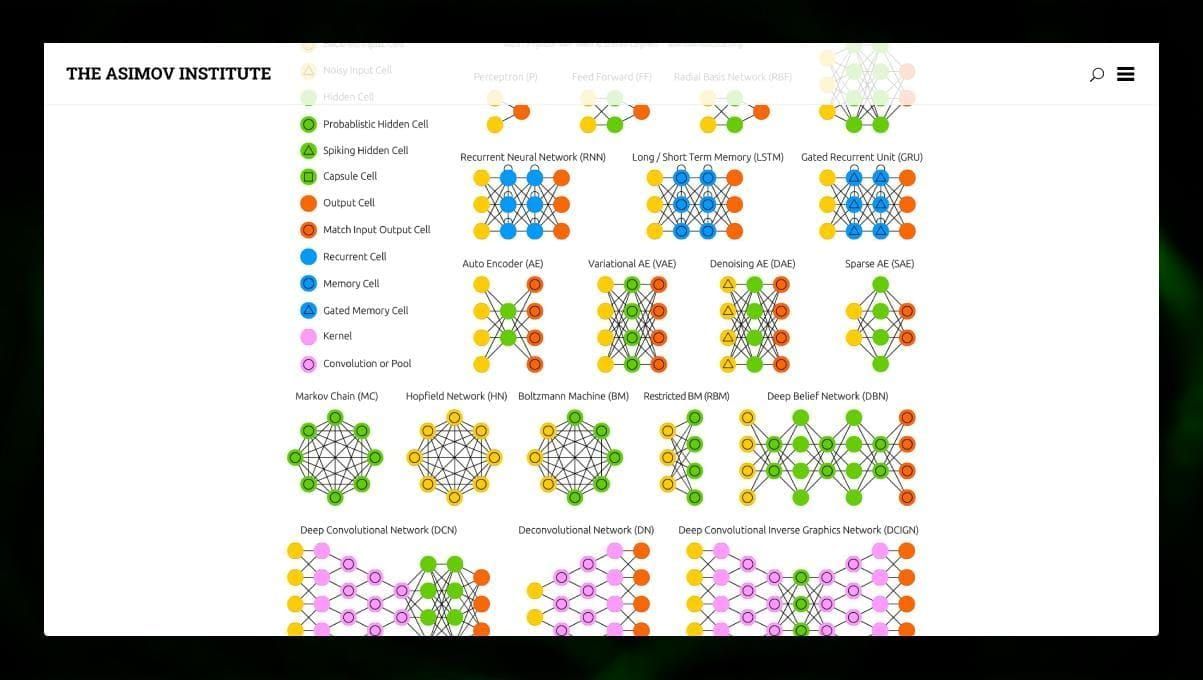
Il existe de nombreux types de NN :
- Les réseaux neuronaux à anticipation (FF ou FFNN) et les perceptrons § sont très directs, il n’y a pas de boucles ou de cycles dans le réseau. En pratique, ces réseaux sont rarement utilisés, mais ils sont souvent combinés avec d’autres types pour en obtenir de nouveaux.
- Un réseau Hopfield (HN) est un réseau neuronal entièrement connecté avec une matrice symétrique de liens. Un tel réseau est souvent appelé réseau de mémoire associative. Tout comme une personne qui voyant une moitié de la table, peut imaginer la seconde moitié, ce réseau, recevant une table bruyante, la restitue dans son intégralité.
- Les réseaux neuronaux convolutifs (CNN) et les réseaux neuronaux convolutifs profonds (DCNN) sont très différents des autres types de réseaux. Ils sont généralement utilisés pour le traitement des images, les tâches liées à l’audio ou à la vidéo. Une façon typique d’appliquer les CNN est de classer les images.
Plusieurs types de réseaux neuronaux sont intéressants à observer. Il est possible de le faire dans le zoo NN.
Conclusion
Ce post est un large aperçu des différents algorithmes ML, mais il y a encore beaucoup à dire. Restez à l’écoute de notre Twitter, Facebook et Medium pour d’autres guides et posts sur les possibilités passionnantes de l’apprentissage automatique.
Laisser un commentaire