Avoir une visibilité sur votre application Java est crucial pour comprendre comment elle fonctionne actuellement, comment elle a fonctionné un certain temps dans le passé, et augmenter votre compréhension de la façon dont elle pourrait fonctionner à l’avenir. Le plus souvent, l’analyse des journaux est le moyen le plus rapide de détecter ce qui a mal fonctionné, ce qui rend la journalisation en Java essentielle pour garantir la performance et la santé de votre application, ainsi que pour minimiser et réduire les temps d’arrêt. Le fait de disposer d’une solution de journalisation et de surveillance centralisée permet de réduire le temps moyen de réparation en améliorant l’efficacité de votre équipe Ops ou DevOps.
En suivant les bonnes pratiques, vous tirerez davantage de valeur de vos journaux et faciliterez leur utilisation. Vous serez en mesure d’identifier plus facilement la cause profonde des erreurs et des mauvaises performances et de résoudre les problèmes avant qu’ils n’aient un impact sur les utilisateurs finaux. Alors aujourd’hui, laissez-moi vous faire part de certaines des meilleures pratiques que vous ne devriez jurer de respecter lorsque vous travaillez avec des applications Java. Creusons un peu.
- Utiliser une bibliothèque de journalisation standard
- Sélectionnez judicieusement vos appendices
- Utiliser des messages significatifs
- Logging Java Stack Traces
- Logging Java Exceptions
- Utiliser le niveau de journal approprié
- Journal en JSON
- Maintenir la structure du journal cohérente
- Ajouter du contexte à vos logs
- Java Logging in Containers
- Ne pas journaliser trop ou trop peu
- Gardez le public à l’esprit
- Éviter de consigner des informations sensibles
- Utiliser une solution de gestion des journaux pour centraliser &Surveiller les journaux Java
- Conclusion
- Share
Utiliser une bibliothèque de journalisation standard
La journalisation en Java peut être réalisée de plusieurs façons différentes. Vous pouvez utiliser une bibliothèque de journalisation dédiée, une API commune, ou même simplement écrire les journaux dans un fichier ou directement dans un système de journalisation dédié. Cependant, lorsque vous choisissez la bibliothèque de journalisation pour votre système, pensez-y à l’avance. Les éléments à prendre en compte et à évaluer sont les performances, la flexibilité, les appenders pour de nouvelles solutions de centralisation des journaux, etc. Si vous vous attachez directement à un seul framework, le passage à une bibliothèque plus récente peut demander beaucoup de travail et de temps. Gardez cela à l’esprit et optez pour l’API qui vous donnera la possibilité de changer de bibliothèque de journalisation à l’avenir. Tout comme pour le passage de Log4j à Logback et à Log4j 2, lorsque vous utilisez l’API SLF4J, la seule chose que vous devez faire est de changer la dépendance, pas le code.
Si vous êtes novice en matière de bibliothèques de journalisation Java, consultez nos guides pour débutants :
- Tutoriel Log4j
- Tutoriel Logback
- Tutoriel Log4j2
- Tutoriel SLF4J
Sélectionnez judicieusement vos appendices
Les appendices définissent où vos événements de journalisation seront délivrés. Les appendices les plus courants sont les appendices de console et de fichier. Bien qu’utiles et largement connus, ils peuvent ne pas répondre à vos besoins. Par exemple, vous pouvez souhaiter écrire vos journaux de manière asynchrone ou expédier vos journaux sur le réseau en utilisant des appenders comme celui de Syslog, comme ceci:
<Appenders> <Console name="Console" target="SYSTEM_OUT"> <PatternLayout pattern="%d %level %c - %m%n"/> </Console> <Syslog name="Syslog" host="logsene-syslog-receiver.sematext.com" port="514" protocol="TCP" format="RFC5424" appName="11111111-2222-3333-4444-555555555555" facility="LOCAL0" mdcId="mdc" newLine="true"/></Appenders>
Toutefois, gardez à l’esprit que l’utilisation d’appenders comme celui présenté ci-dessus rend votre pipeline de journalisation sensible aux erreurs de réseau et aux perturbations de communication. Cela peut avoir pour conséquence que les journaux ne soient pas expédiés à leur destination, ce qui peut ne pas être acceptable. Vous voulez également éviter que la journalisation n’affecte votre système si l’appender est conçu de manière à bloquer. Pour en savoir plus, consultez notre article de blog Logging libraries vs Log shippers.
Utiliser des messages significatifs
L’une des choses cruciales lorsqu’il s’agit de créer des logs, et pourtant l’une des moins faciles, est d’utiliser des messages significatifs. Vos événements de journal devraient inclure des messages qui sont uniques à la situation donnée, les décrire clairement et informer la personne qui les lit. Imaginez qu’une erreur de communication se soit produite dans votre application. Vous pourriez le faire comme ceci:
LOGGER.warn("Communication error");
Mais vous pourriez aussi créer un message comme ceci:
LOGGER.warn("Error while sending documents to events Elasticsearch server, response code %d, response message %s. The message sending will be retried.", responseCode, responseMessage);
Vous pouvez facilement voir que le premier message informera la personne qui consulte les journaux de certains problèmes de communication. Cette personne aura probablement le contexte, le nom de l’enregistreur, et le numéro de ligne où l’avertissement s’est produit, mais c’est tout. Pour obtenir plus de contexte, cette personne devra examiner le code, savoir à quelle version du code l’erreur est liée, etc. Ce n’est pas amusant et souvent pas facile, et certainement pas quelque chose que l’on veut faire en essayant de dépanner un problème de production aussi rapidement que possible.
Le deuxième message est meilleur. Il fournit des informations exactes sur le type d’erreur de communication qui s’est produit, ce que l’application faisait à ce moment-là, le code d’erreur qu’elle a obtenu et la réponse du serveur distant. Enfin, il informe également que l’envoi du message sera retenté. Travailler avec de tels messages est définitivement plus facile et plus agréable.
Enfin, pensez à la taille et à la verbosité du message. N’enregistrez pas des informations trop verbeuses. Ces données doivent être stockées quelque part afin d’être utiles. Un seul message très long ne posera pas de problème, mais si cette ligne se répète des centaines de fois en une minute et que vous avez beaucoup de journaux verbeux, la conservation plus longue de ces données peut être problématique et, en fin de compte, coûtera également plus cher.
Logging Java Stack Traces
L’une des parties très importantes de la journalisation Java sont les traces de la pile Java. Jetez un coup d’œil au code suivant :
package com.sematext.blog.logging;import org.apache.logging.log4j.LogManager;import org.apache.logging.log4j.Logger;import java.io.IOException;public class Log4JExceptionNoThrowable { private static final Logger LOGGER = LogManager.getLogger(Log4JExceptionNoThrowable.class); public static void main(String args) { try { throw new IOException("This is an I/O error"); } catch (IOException ioe) { LOGGER.error("Error while executing main thread"); } }}
Le code ci-dessus entraînera la levée d’une exception et un message de journalisation qui sera imprimé sur la console avec notre configuration par défaut ressemblera à ceci :
11:42:18.952 ERROR - Error while executing main thread
Comme vous pouvez le voir, il n’y a pas beaucoup d’informations. Nous savons seulement que le problème s’est produit, mais nous ne savons pas où il s’est produit, ou quel était le problème, etc. Pas très informatif.
Maintenant, regardez le même code avec une déclaration de journalisation légèrement modifiée:
package com.sematext.blog.logging;import org.apache.logging.log4j.LogManager;import org.apache.logging.log4j.Logger;import java.io.IOException;public class Log4JException { private static final Logger LOGGER = LogManager.getLogger(Log4JException.class); public static void main(String args) { try { throw new IOException("This is an I/O error"); } catch (IOException ioe) { LOGGER.error("Error while executing main thread", ioe); } }}
Comme vous pouvez le voir, cette fois nous avons inclus l’objet d’exception lui-même dans notre message de journalisation:
LOGGER.error("Error while executing main thread", ioe);
Cela donnerait le journal d’erreur suivant dans la console avec notre configuration par défaut:
11:30:17.527 ERROR - Error while executing main threadjava.io.IOException: This is an I/O error at com.sematext.blog.logging.Log4JException.main(Log4JException.java:13)
Il contient des informations pertinentes – i.c’est-à-dire le nom de la classe, la méthode où le problème s’est produit, et enfin le numéro de ligne où le problème s’est produit. Bien sûr, dans des situations réelles, les traces de pile seront plus longues, mais vous devriez les inclure pour vous donner suffisamment d’informations pour un débogage correct.
Pour en savoir plus sur la façon de gérer les traces de pile Java avec Logstash, voir Handling Multiline Stack Traces with Logstash ou regarder Logagent qui peut faire cela pour vous hors de la boîte.
Logging Java Exceptions
Lorsque vous traitez les exceptions Java et les traces de pile, vous ne devez pas seulement penser à l’ensemble de la trace de pile, aux lignes où le problème est apparu, et ainsi de suite. Vous devez également penser à la façon de ne pas traiter les exceptions.
Évitez d’ignorer silencieusement les exceptions. Vous ne voulez pas ignorer quelque chose d’important. Par exemple, ne faites pas ceci :
try { throw new IOException("This is an I/O error");} catch (IOException ioe) {}
Aussi, ne vous contentez pas de consigner une exception et de la lancer plus loin. Cela signifie que vous venez de pousser le problème vers le haut de la pile d’exécution. Évitez également ce genre de choses :
try { throw new IOException("This is an I/O error");} catch (IOException ioe) { LOGGER.error("I/O error occurred during request processing", ioe); throw ioe;}
Si vous souhaitez en savoir plus sur les exceptions, lisez notre guide sur la gestion des exceptions en Java où nous couvrons tout, de ce qu’elles sont à la façon de les attraper et de les corriger.
Utiliser le niveau de journal approprié
Lorsque vous écrivez le code de votre application, pensez à deux fois à un message de journal donné. Tous les éléments d’information n’ont pas la même importance et toutes les situations inattendues ne constituent pas une erreur ou un message critique. En outre, utiliser les niveaux de journalisation de manière cohérente – les informations d’un type similaire devraient être sur un niveau de gravité similaire.
La façade SLF4J et chaque cadre de journalisation Java que vous utiliserez fournissent des méthodes qui peuvent être utilisées pour fournir un niveau de journal approprié. Par exemple :
LOGGER.error("I/O error occurred during request processing", ioe);
Journal en JSON
Si nous prévoyons de journaliser et de regarder les données manuellement dans un fichier ou la sortie standard, alors la journalisation prévue sera plus que bien. C’est plus convivial – nous sommes habitués à cela. Mais cela n’est viable que pour les très petites applications et même dans ce cas, il est suggéré d’utiliser quelque chose qui vous permettra de corréler les données métriques avec les journaux. Faire de telles opérations dans une fenêtre de terminal n’est pas amusant et parfois c’est tout simplement impossible. Si vous souhaitez stocker les journaux dans le système de gestion et de centralisation des journaux, vous devez les enregistrer en JSON. En effet, l’analyse syntaxique n’est pas gratuite – elle implique généralement l’utilisation d’expressions régulières. Bien sûr, vous pouvez payer ce prix dans l’expéditeur de journaux, mais pourquoi le faire si vous pouvez facilement vous connecter en JSON. La journalisation en JSON permet également de gérer facilement les traces de pile, ce qui constitue un autre avantage. Bon, vous pouvez aussi simplement journaliser vers une destination compatible Syslog, mais c’est une autre histoire.
Dans la plupart des cas, pour activer la journalisation en JSON dans votre framework de journalisation Java, il suffit d’inclure la configuration appropriée. Par exemple, supposons que nous avons le message de journal suivant inclus dans notre code :
LOGGER.info("This is a log message that will be logged in JSON!");
Pour configurer Log4J 2 afin d’écrire les messages de journal en JSON, nous inclurions la configuration suivante :
<?xml version="1.0" encoding="UTF-8"?><Configuration status="WARN"> <Appenders> <Console name="Console" target="SYSTEM_OUT"> <JSONLayout compact="true" eventEol="true"> </JSONLayout> </Console> </Appenders> <Loggers> <Root level="info"> <AppenderRef ref="Console"/> </Root> </Loggers></Configuration>
Le résultat ressemblerait à ce qui suit :
{"instant":{"epochSecond":1596030628,"nanoOfSecond":695758000},"thread":"main","level":"INFO","loggerName":"com.sematext.blog.logging.Log4J2JSON","message":"This is a log message that will be logged in JSON!","endOfBatch":false,"loggerFqcn":"org.apache.logging.slf4j.Log4jLogger","threadId":1,"threadPriority":5}
Maintenir la structure du journal cohérente
La structure de vos événements de journal doit être cohérente. Cela n’est pas seulement vrai au sein d’une seule application ou d’un ensemble de microservices, mais devrait être appliqué à l’ensemble de votre pile d’applications. Avec des événements de journal structurés de manière similaire, il sera plus facile de les examiner, de les comparer, de les corréler ou simplement de les stocker dans un magasin de données dédié. Il est plus facile d’examiner les données provenant de vos systèmes lorsque vous savez qu’elles ont des champs communs tels que la gravité et le nom d’hôte, de sorte que vous pouvez facilement découper les données en fonction de ces informations. Pour vous inspirer, jetez un coup d’œil au schéma commun de Sematext, même si vous n’êtes pas un utilisateur de Sematext.
Bien sûr, conserver la structure n’est pas toujours possible, car votre pile complète se compose de serveurs développés en externe, de bases de données, de moteurs de recherche, de files d’attente, etc. qui ont chacun leur propre ensemble de journaux et de formats de journaux. Cependant, pour garder votre santé mentale et celle de votre équipe, minimisez le nombre de structures de messages de logs différentes que vous pouvez contrôler.
Une façon de garder une structure commune est d’utiliser le même modèle pour vos logs, au moins ceux qui utilisent le même framework de logging. Par exemple, si vos applications et microservices utilisent Log4J 2, vous pourriez utiliser un pattern comme celui-ci :
<PatternLayout> <Pattern>%d %p %c{35}:%L - %m%n</Pattern></PatternLayout>
En utilisant un seul ou un ensemble très limité de patterns, vous pouvez être sûr que le nombre de formats de logs restera petit et gérable.
Ajouter du contexte à vos logs
Le contexte de l’information est important et pour nous, développeurs et DevOps, un message de log est une information. Regardez l’entrée de journal suivante :
An error occurred!
Nous savons qu’une erreur est apparue quelque part dans l’application. Nous ne savons pas où elle s’est produite, nous ne savons pas quel type d’erreur c’était, nous savons seulement quand elle s’est produite. Maintenant, regardez un message avec un peu plus d’informations contextuelles:
com.sematext.blog.logging.ParsingErrorExample - A parsing error occurred for user with id 1234!
Le même enregistrement de journal, mais beaucoup plus d’informations contextuelles. Nous connaissons le thread dans lequel cela s’est produit, nous savons à quelle classe l’erreur a été générée. Nous avons également modifié le message pour inclure l’utilisateur pour lequel l’erreur s’est produite, afin de pouvoir revenir à l’utilisateur si nécessaire. Nous pourrions également inclure des informations supplémentaires, comme les contextes de diagnostic. Pensez à ce dont vous avez besoin et incluez-le.
Pour inclure des informations de contexte, vous n’avez pas à faire grand-chose en ce qui concerne le code qui est responsable de la génération du message de journal. Par exemple, le PatternLayout de Log4J 2 vous donne tout ce dont vous avez besoin pour inclure les informations de contexte. Vous pouvez opter pour un motif très simple comme celui-ci :
<PatternLayout pattern="%d{HH:mm:ss.SSS} %-5level - %msg%n"/>
Ce qui donnera un message de journal similaire au suivant :
17:13:08.059 INFO - This is the first INFO level log message!
Mais vous pouvez également inclure un motif qui comprendra beaucoup plus d’informations :
<PatternLayout pattern="%d{HH:mm:ss.SSS} %c %l %-5level - %msg%n"/>
Ce qui résultera en un message de journal similaire au suivant:
17:24:01.710 com.sematext.blog.logging.Log4j2 com.sematext.blog.logging.Log4j2.main(Log4j2.java:12) INFO - This is the first INFO level log message!
Java Logging in Containers
Pensez à l’environnement dans lequel votre application va s’exécuter. Il y a une différence dans la configuration de la journalisation lorsque vous exécutez votre code Java dans une VM ou sur une machine bare-metal, elle est différente lorsque vous l’exécutez dans un environnement conteneurisé, et bien sûr, elle est différente lorsque vous exécutez votre code Java ou Kotlin sur un appareil Android.
Pour configurer la journalisation dans un environnement conteneurisé, vous devez choisir l’approche que vous voulez adopter. Vous pouvez utiliser l’un des pilotes de journalisation fournis – comme le journald, logagent, Syslog ou le fichier JSON. Pour ce faire, rappelez-vous que votre application ne doit pas écrire le fichier journal dans le stockage éphémère du conteneur, mais dans la sortie standard. Pour ce faire, il suffit de configurer votre cadre de journalisation pour qu’il écrive le journal dans la console. Par exemple, avec Log4J 2, il suffit d’utiliser la configuration d’appender suivante:
<Appenders> <Console name="Console" target="SYSTEM_OUT"> <PatternLayout pattern="%d{HH:mm:ss.SSS} - %m %n"/> </Console></Appenders>
Vous pouvez également omettre complètement les pilotes de journalisation et expédier les journaux directement à votre solution de journaux centralisée comme notre Sematext Cloud:
<Appenders> <Console name="Console" target="SYSTEM_OUT"> <PatternLayout pattern="%d %level %c - %m%n"/> </Console> <Syslog name="Syslog" host="logsene-syslog-receiver.sematext.com" port="514" protocol="TCP" format="RFC5424" appName="11111111-2222-3333-4444-555555555555" facility="LOCAL0" mdcId="mdc" newLine="true"/></Appenders>
Ne pas journaliser trop ou trop peu
En tant que développeurs, nous avons tendance à penser que tout peut être important – nous avons tendance à marquer chaque étape de notre algorithme ou de notre code métier comme importante. D’un autre côté, nous faisons parfois le contraire – nous n’ajoutons pas de journalisation là où nous le devrions ou nous n’enregistrons que les niveaux de journalisation FATAL et ERROR. Les deux approches ne donneront pas de très bons résultats. Lorsque vous écrivez votre code et ajoutez la journalisation, pensez à ce qui sera important pour voir si l’application fonctionne correctement et à ce qui sera important pour pouvoir diagnostiquer un mauvais état de l’application et le réparer. Utilisez ces éléments comme guide pour décider quoi et où enregistrer. Gardez à l’esprit que l’ajout de trop de journaux se terminera par une fatigue de l’information et que le fait de ne pas avoir assez d’informations entraînera l’incapacité de dépanner.
Gardez le public à l’esprit
Dans la plupart des cas, vous ne serez pas la seule personne à regarder les journaux. N’oubliez jamais que. Il y a plusieurs acteurs qui peuvent regarder les journaux.
Le développeur peut regarder les journaux pour le dépannage ou pendant les sessions de débogage. Pour ces personnes, les journaux peuvent être détaillés, techniques et inclure des informations très profondes liées à la façon dont le système fonctionne. Une telle personne aura également accès au code ou connaîtra même le code et vous pouvez le supposer.
Puis il y a les DevOps. Pour eux, les événements de journal seront nécessaires pour le dépannage et devraient inclure des informations utiles au diagnostic. Vous pouvez assumer la connaissance du système, de son architecture, de ses composants et de la configuration des composants, mais vous ne devez pas assumer la connaissance du code de la plateforme.
Enfin, les journaux de votre application peuvent être lus par vos utilisateurs eux-mêmes. Dans ce cas, les journaux doivent être suffisamment descriptifs pour aider à résoudre le problème si cela est même possible ou donner suffisamment d’informations à l’équipe de support qui aide l’utilisateur. Par exemple, l’utilisation de Sematext pour la surveillance implique l’installation et l’exécution d’un agent de surveillance. Si vous êtes derrière un pare-feu très restrictif et que l’agent ne peut pas envoyer de métriques à Sematext, il consigne les erreurs visées que les utilisateurs de Sematext eux-mêmes peuvent consulter.
Nous pourrions aller plus loin et identifier encore plus d’acteurs qui pourraient regarder dans les journaux, mais cette liste restreinte devrait vous donner un aperçu de ce à quoi vous devriez penser lorsque vous rédigez vos messages de journal.
Éviter de consigner des informations sensibles
Les informations sensibles ne devraient pas être présentes dans les journaux ou devraient être masquées. Les mots de passe, les numéros de carte de crédit, les numéros de sécurité sociale, les jetons d’accès, et ainsi de suite – tout cela peut être dangereux en cas de fuite ou d’accès par ceux qui ne devraient pas voir cela. Il y a deux choses que vous devriez considérer.
Réfléchissez si les informations sensibles sont vraiment essentielles pour le dépannage. Peut-être qu’au lieu d’un numéro de carte de crédit, il est suffisant de conserver les informations sur l’identifiant de la transaction et la date de la transaction ? Peut-être n’est-il pas nécessaire de conserver le numéro de sécurité sociale dans les journaux lorsque vous pouvez facilement stocker l’identifiant de l’utilisateur. Pensez à de telles situations, pensez aux données que vous stockez, et n’écrivez des données sensibles que lorsque c’est vraiment nécessaire.
La deuxième chose est l’envoi de journaux contenant des informations sensibles à un service de journaux hébergés. Il y a très peu d’exceptions où les conseils suivants ne doivent pas être suivis. Si vos logs ont et doivent avoir des informations sensibles stockées, masquez-les ou supprimez-les avant de les envoyer à votre magasin de logs centralisé. La plupart des expéditeurs de journaux populaires, comme notre propre Logagent, incluent une fonctionnalité qui permet de supprimer ou de masquer les données sensibles.
Enfin, le masquage des informations sensibles peut être effectué dans le cadre de journalisation lui-même. Voyons comment cela peut être fait en étendant Log4j 2. Notre code qui produit des événements de log se présente comme suit (l’exemple complet peut être trouvé sur Sematext Github):
public class Log4J2Masking { private static Logger LOGGER = LoggerFactory.getLogger(Log4J2Masking.class); private static final Marker SENSITIVE_DATA_MARKER = MarkerFactory.getMarker("SENSITIVE_DATA_MARKER"); public static void main(String args) { LOGGER.info("This is a log message without sensitive data"); LOGGER.info(SENSITIVE_DATA_MARKER, "This is a a log message with credit card number 1234-4444-3333-1111 in it"); }}
Si vous deviez exécuter l’exemple complet à partir de Github, la sortie serait la suivante:
21:20:42.099 - This is a log message without sensitive data21:20:42.101 - This is a a log message with credit card number ****-****-****-**** in it
Vous pouvez voir que le numéro de carte de crédit a été masqué. Cela a été fait parce que nous avons ajouté un convertisseur personnalisé qui vérifie si le marqueur donné est transmis dans l’événement du journal et essaie de remplacer un modèle défini. L’implémentation d’un tel Converter se présente comme suit:
@Plugin(name = "sample_logging_mask", category = "Converter")@ConverterKeys("sc")public class LoggingConverter extends LogEventPatternConverter { private static Pattern PATTERN = Pattern.compile("\b({4})-({4})-({4})-({4})\b"); public LoggingConverter(String options) { super("sc", "sc"); } public static LoggingConverter newInstance(final String options) { return new LoggingConverter(options); } @Override public void format(LogEvent event, StringBuilder toAppendTo) { String message = event.getMessage().getFormattedMessage(); String maskedMessage = message; if (event.getMarker() != null && "SENSITIVE_DATA_MARKER".compareToIgnoreCase(event.getMarker().getName()) == 0) { Matcher matcher = PATTERN.matcher(message); if (matcher.find()) { maskedMessage = matcher.replaceAll("****-****-****-****"); } } toAppendTo.append(maskedMessage); }}
Il est très simple et pourrait être écrit de manière plus optimisée et devrait également gérer tous les formats possibles de numéros de cartes de crédit, mais il est suffisant pour cet objectif.
Avant de sauter dans l’explication du code, je voudrais également vous montrer le fichier de configuration log4j2.xml pour cet exemple :
<?xml version="1.0" encoding="UTF-8"?><Configuration status="WARN" packages="com.sematext.blog.logging"> <Appenders> <Console name="Console" target="SYSTEM_OUT"> <PatternLayout pattern="%d{HH:mm:ss.SSS} - %sc %n"/> </Console> </Appenders> <Loggers> <Root level="info"> <AppenderRef ref="Console"/> </Root> </Loggers></Configuration>
Comme vous pouvez le voir, nous avons ajouté l’attribut packages dans notre Configuration pour indiquer au framework où chercher notre convertisseur. Ensuite, nous avons utilisé le motif %sc pour fournir le message de journal. Nous faisons cela parce que nous ne pouvons pas écraser le motif %m par défaut. Une fois que Log4j2 trouve notre motif %sc, il utilisera notre convertisseur qui prend le message formaté de l’événement de journal et utilise une simple regex et remplace les données si elles ont été trouvées. Aussi simple que cela.
Une chose à remarquer ici est que nous utilisons la fonctionnalité de marqueur. La correspondance Regex est coûteuse et nous ne voulons pas le faire pour chaque message de journal. C’est pourquoi nous marquons les événements de journal qui doivent être traités avec le marqueur créé, de sorte que seuls ceux marqués sont vérifiés.
Utiliser une solution de gestion des journaux pour centraliser &Surveiller les journaux Java
Avec la complexité des applications, le volume de vos journaux augmentera également. Vous pouvez vous en sortir en enregistrant dans un fichier et en utilisant les journaux uniquement lorsque le dépannage est nécessaire, mais lorsque la quantité de données augmente, il devient rapidement difficile et lent de dépanner de cette façon Lorsque cela se produit, envisagez d’utiliser une solution de gestion des journaux pour centraliser et surveiller vos journaux. Vous pouvez opter pour une solution interne basée sur le logiciel libre, comme Elastic Stack, ou utiliser l’un des outils de gestion des journaux disponibles sur le marché, comme Sematext Logs.
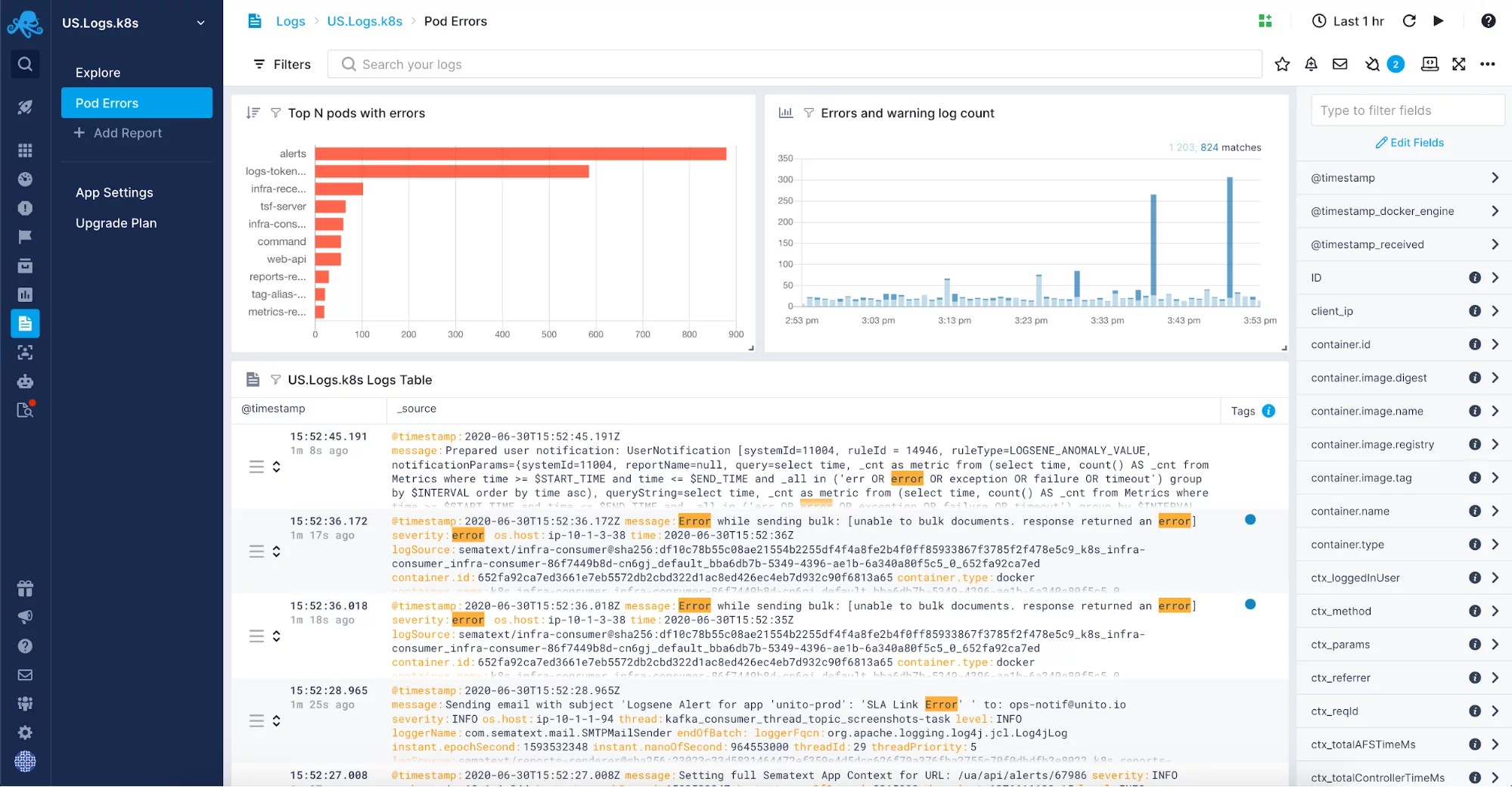
Une solution de centralisation des journaux entièrement gérée vous donnera la liberté de ne pas avoir à gérer une autre partie, généralement assez complexe, de votre infrastructure. Au lieu de cela, vous pourrez vous concentrer sur votre application et n’aurez besoin de configurer que l’expédition des journaux. Il se peut que vous souhaitiez inclure des journaux tels que ceux de la collecte des déchets de la JVM dans votre solution de gestion des journaux. Après les avoir activés pour vos applications et systèmes fonctionnant sur la JVM, vous voudrez regrouper les journaux en un seul endroit pour les corréler, les analyser et vous aider à régler la collecte des déchets dans les instances de la JVM. De tels journaux corrélés avec des métriques sont une source d’information inestimable pour le dépannage des problèmes liés au garbage collection.
Si vous souhaitez voir comment Sematext Logs se positionne par rapport à des solutions similaires, dirigez-vous vers notre article sur le meilleur logiciel de gestion de logs ou l’article de blog où nous passons en revue certains des meilleurs outils d’analyse de logs mais nous vous recommandons d’utiliser l’essai gratuit de 14 jours pour explorer pleinement ses fonctionnalités. Essayez-le et voyez par vous-même !
Conclusion
Incorporer chaque bonne pratique peut ne pas être facile à mettre en œuvre immédiatement, en particulier pour les applications qui sont déjà en direct et fonctionnent en production. Mais si vous prenez le temps de déployer les suggestions les unes après les autres, vous commencerez à constater une augmentation de l’utilité de vos journaux. Pour plus de conseils sur la façon de tirer le meilleur parti de vos journaux, nous vous recommandons également de consulter notre autre article sur les meilleures pratiques de journalisation où nous expliquons les tenants et aboutissants que vous devriez suivre, quel que soit le type d’application avec lequel vous travaillez. Et n’oubliez pas que chez Sematext, nous aidons les organisations avec leurs configurations de journalisation en offrant des conseils en matière de journalisation, alors contactez-nous si vous avez des problèmes et nous serons heureux de vous aider.
.
Laisser un commentaire