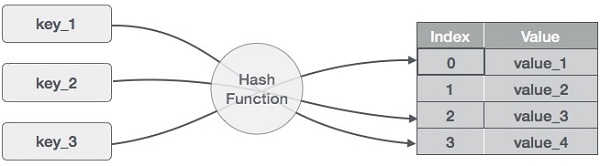
Hash-taulukko (Hash-taulukko) on tietorakenne, joka tallentaa dataa assosiatiivisesti. Hash-taulussa data tallennetaan array-muodossa, jossa jokaisella data-arvolla on oma yksilöllinen indeksiarvonsa. Tiedon hakemisesta tulee hyvin nopeaa, jos tiedämme halutun tiedon indeksin.
Siten siitä tulee tietorakenne, jossa lisäys- ja hakutoiminnot ovat hyvin nopeita tiedon koosta riippumatta. Hash-taulukko käyttää joukkoa tallennusvälineenä ja käyttää hash-tekniikkaa luodakseen indeksin, josta elementti on lisättävä tai josta se on löydettävä.
Hashing
Hashing on tekniikka, jolla avainarvojen alue muunnetaan joukkoon kuuluvien indeksien alueeksi. Käytämme modulo-operaattoria saadaksemme avainarvojen alueen. Tarkastellaan esimerkkinä hash-taulukkoa, jonka koko on 20 ja johon tallennetaan seuraavat kohteet. Elementit ovat muodossa (avain,arvo).
- (1,20)
- (2,70)
- (42,80)
- (4,25)
- (12,44)
- (14,32)
- (17,11)
- (13,78)
- (37,98)
| Sr.Nro. | 2 | ||
|---|---|---|---|
| 3 | 42 | 42 % 20 = 2 | 2 |
| 4 | 4 | 4 % 20 = 4 | 4 |
| 5 | 12 | 12 % 20 = 12 | 12 |
| 6 | 14 | 14 % 20 = 14 | 14 |
| 7 | 17 | 17 % 20 = 17 | 17 |
| 8 | 13 | 13 % 20 = 13 | 13 |
| 9 | 37 | 37 % 20 = 17 | 17 |
Lineaarinen koettelemus
Kuten näemme, voi käydä niin, että hashing-tekniikkaa käytetään jo käytetyn indeksin luomiseen arrayyn. Tällaisessa tapauksessa voimme etsiä seuraavaa tyhjää paikkaa matriisista katsomalla seuraavaan soluun, kunnes löydämme tyhjän solun. Tätä tekniikkaa kutsutaan lineaariseksi luotaukseksi.
| Sr.nro. | Key | Hash | Array Index | After Linear Probing, Array Index | |
|---|---|---|---|---|---|
| 1 | 1 | 1 % 20 = 1 | 1 | 1 | 1 |
| 2 | 2 | 2 % 20 = 2 | 2 | 2 | |
| 3 | 42 | 42 % 20 = 2 | 2 | 3 | |
| 4 | 4 | 4 % 20 = 4 | 4 | 4 | |
| 5 | 12 | 12 % 20 = 12 | 12 | 12 | |
| 6 | 14 | 14 % 20 = 14 | 14 | 14 | |
| 7 | 17 | 17 % 20 = 17 | 17 | 17 | |
| 8 | 13 | 13 % 20 = 13 | 13 | 13 | |
| 9 | 37 | 37 % 20 = 17 | 17 | 17 | 18 |
PERUSTOIMINTOJA
Seuraavaksi on esitetty hash-taulukoiden perusprimaariset operaatioihin liittyvät operaatiot.
-
Haku – Etsii elementin hash-taulukosta.
-
Sisällyttää – lisää elementin hash-taulukkoon.
-
poistaa – Poistaa elementin hash-taulukosta.
DataItem
Määrittää dataelementin, jolla on jokin tieto ja avain, jonka perusteella haku suoritetaan hash-taulukossa.
struct DataItem { int data; int key;};
Hash-menetelmä
Määritellään hash-menetelmä, jolla lasketaan dataelementin avaimen hash-koodi.
int hashCode(int key){ return key % SIZE;}
Hakuoperaatio
Kun jotain elementtiä halutaan hakea, lasketaan välitetyn avaimen hash-koodi ja etsitään elementti käyttämällä tätä hash-koodia indeksinä matriisissa. Käytä lineaarista luotainta saadaksesi elementin eteenpäin, jos elementtiä ei löydy lasketulla hash-koodilla.
Esimerkki
struct DataItem *search(int key) { //get the hash int hashIndex = hashCode(key); //move in array until an empty while(hashArray != NULL) { if(hashArray->key == key) return hashArray; //go to next cell ++hashIndex; //wrap around the table hashIndex %= SIZE; } return NULL; }
Sisäänsyöttöoperaatio
Kun elementti on lisättävä, laske välitetyn avaimen hash-koodi ja etsi indeksi käyttäen tuota hash-koodia indeksinä matriisissa. Käytä lineaarista etsintää tyhjään paikkaan, jos lasketulla hash-koodilla löytyy elementti.
Esimerkki
void insert(int key,int data) { struct DataItem *item = (struct DataItem*) malloc(sizeof(struct DataItem)); item->data = data; item->key = key; //get the hash int hashIndex = hashCode(key); //move in array until an empty or deleted cell while(hashArray != NULL && hashArray->key != -1) { //go to next cell ++hashIndex; //wrap around the table hashIndex %= SIZE; } hashArray = item; }
Poisto-operaatio
Kun elementti halutaan poistaa, lasketaan välitetyn avaimen hash-koodi ja etsitään indeksi käyttäen kyseistä hash-koodia indeksinä matriisissa. Käytä lineaarista luotainta saadaksesi elementin eteenpäin, jos elementtiä ei löydy lasketulla hash-koodilla. Kun se löytyy, tallenna sinne dummy-elementti, jotta hash-taulukon suorituskyky säilyy ennallaan.
Esimerkki
struct DataItem* delete(struct DataItem* item) { int key = item->key; //get the hash int hashIndex = hashCode(key); //move in array until an empty while(hashArray !=NULL) { if(hashArray->key == key) { struct DataItem* temp = hashArray; //assign a dummy item at deleted position hashArray = dummyItem; return temp; } //go to next cell ++hashIndex; //wrap around the table hashIndex %= SIZE; } return NULL; }
Tietääksesi hash-taulukon toteutuksesta C-ohjelmointikielellä, klikkaa tästä.
Vastaa