Tilaa päivittäiset yhteenvetomme jatkuvasti muuttuvasta hakumarkkinointimaisemasta.
Huomautus: Lähettämällä tämän lomakkeen hyväksyt Third Door Median ehdot. Kunnioitamme yksityisyyttäsi.

Internetfoorumeilla ja sisältöön liittyvissä Facebook-ryhmissä puhkeaa usein keskustelua siitä, miten Googlebot – jota kutsumme tässä hellävaraisesti GB:ksi – toimii, mitä se näkee ja mitä ei, millaisissa linkeissä se vierailee ja miten se vaikuttaa hakukoneoptimointiin.
Tässä artikkelissa esittelen kolme kuukautta kestäneen kokeiluni tulokset.
Viime kolmen kuukauden ajan GB on vieraillut luonani lähes päivittäin kuin ystävä, joka piipahtaa oluelle.
Joskus se oli yksin:
: 66.249.76.136 /page1.html Mozilla/5.0 (yhteensopiva; Googlebot/2.1; +http://www.google.com/bot.html)
: 66.249.76.136 /page5.html Mozilla/5.0 (yhteensopiva; Googlebot/2.1; +http://www.google.com/bot.html)
: 66.249.76.140 /page3.html Mozilla/5.0 (yhteensopiva; Googlebot/2.1; +http://www.google.com/bot.html)
: 66.249.64.72 /page2.html Mozilla/5.0 (yhteensopiva; Googlebot/2.1; +http://www.google.com/bot.html)
: 66.249.64.72 /page6.html Mozilla/5.0 (yhteensopiva; Googlebot/2.1; +http://www.google.com/bot.html)
Joskus se toi kaverinsa mukaan:
: 64.233.172.231 /page1.html Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, kuten Gecko; Google Search Console) Chrome/41.0.2272.118 Safari/537.36
: 66.249.69.235 /image.jpg Googlebot-Image/1.0
: 66.249.76.156 /page2.html Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, kuten Gecko) Chrome/41.0.2272.96 Mobile Safari/537.36 (yhteensopiva; Googlebot/2.1; +http://www.google.com/bot.html)
Ja meillä oli hauskaa pelatessamme erilaisia pelejä:
Catch: Havaitsin, kuinka GB rakastaa ajaa uudelleenohjauksia 301 ja indeksoida kuvia ja ajaa kanonisista.
Kätköily: Googlebot piileskeli piilotetussa sisällössä (jota se, kuten sen vanhemmat väittävät, ei siedä ja välttää)
Selviytyminen: Valmistelin ansoja ja odotin, että se laukaisi ne.
Esteet:
Kuten varmaan huomaatte, en pettynyt. Meillä oli valtavasti hauskaa ja meistä tuli hyviä ystäviä. Uskon, että ystävyydellämme on valoisa tulevaisuus.
Mutta mennäänpä asiaan!
Rakensin verkkosivuston, jossa oli ansioihin liittyvää sisältöä tähtienvälisestä matkatoimistosta, joka tarjoaa lentoja vielä löytymättömille planeetoille galaksissamme ja sen ulkopuolella.
Sisältö näytti olevan paljon ansioita, vaikka todellisuudessa se olikin pelkkää roskaa.
Kokeilusivuston rakenne näytti tältä:
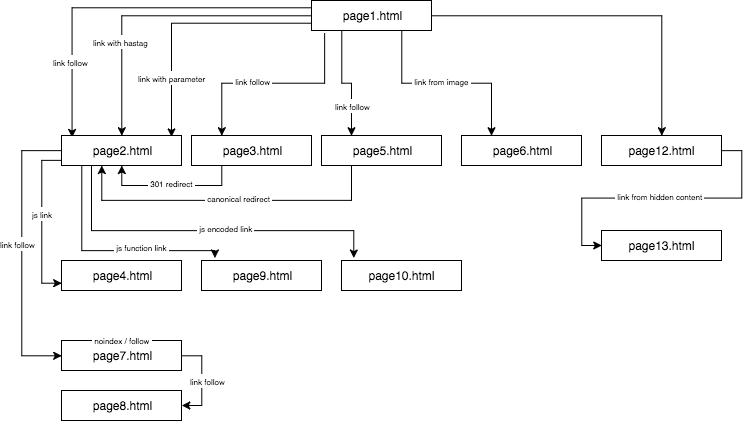
Tarjosin uniikkia sisältöä ja varmistin, että jokainen ankkuri/title/alt sekä muut kertoimet olivat globaalisti uniikkeja (valesanat). Lukijaa helpottaakseni en käytä kuvauksessa nimiä kuten anchor cutroicano matestito, vaan viittaan niihin nimillä anchor1 jne.
Suositan, että pidät yllä olevan kartan auki erillisessä ikkunassa lukiessasi tätä artikkelia.
- Osa 1: First link counts
- Linkki ankkurilla
- Linkki verkkosivulle, jossa on parametri
- Linkki sivustolle uudelleenohjauksesta
- Linkki sivulle käyttämällä kanonista tagia
- Osa 2: Crawl-budjetti
- JavaScript-linkki onclick-tapahtumalla
- Javascript-linkki sisäisellä toiminnolla
- JavaScript-linkki koodauksen kanssa
- Osa 3: Piilotettu sisältö
- Tietoa kirjoittajasta
Osa 1: First link counts
Ensimmäinen linkki lasketaan
Ensimmäinen linkki lasketaan -sääntö oli yksi niistä asioista, joita halusin testata tässä SEO-kokeilussa – voidaanko se jättää pois ja miten se vaikuttaa optimointiin.
Ensimmäinen linkki lasketaan -sääntö sanoo, että Google Bot näkee sivulla vain ensimmäisen linkin alasivulle. Jos yhdellä sivulla on kaksi linkkiä samalle alasivulle, toinen linkki jätetään tämän säännön mukaan huomiotta. Google Bot jättää huomiotta toisen ja jokaisen peräkkäisen linkin ankkurin, kun se laskee sivun sijoitusta.
Ongelma on laajalti monien asiantuntijoiden valvoma, mutta sitä esiintyy erityisesti verkkokaupoissa, joissa navigointivalikot vääristävät merkittävästi sivuston rakennetta.
Useimmissa kaupoissa on staattinen (sivun lähdeviitteessä näkyvä) pudotusvalikko, joka antaa esimerkiksi neljä linkkiä pääkategorioihin ja 25 piilotettua linkkiä alakategorioihin. Sivurakennetta kartoitettaessa GB näkee kaikki linkit (jokaisella sivulla, jossa on valikko), mikä johtaa siihen, että kaikki sivut ovat kartoituksen aikana yhtä tärkeitä ja niiden teho (mehu) jakautuu tasaisesti, mikä näyttää suunnilleen tältä:
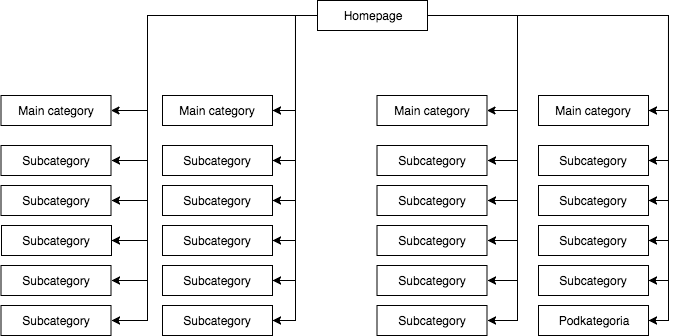
Yleisin, mutta mielestäni väärä sivurakenne.
Ylläolevaa esimerkkiä ei voi kutsua oikeaksi rakenteeksi, koska kaikki kategoriat ovat linkitetty kaikilta sivuilta, joissa on valikko. Näin ollen sekä etusivulla että kaikilla kategorioilla ja alaluokilla on yhtä paljon saapuvia linkkejä, ja koko verkkopalvelun voima virtaa niiden kautta yhtä voimakkaasti. Näin ollen etusivun teho (joka yleensä saa suurimman osan tehosta saapuvien linkkien määrän vuoksi) jaetaan 24 luokkaan ja alaluokkaan, joten kukin niistä saa vain 4 prosenttia etusivun tehosta.
Miltä rakenteen pitäisi näyttää:

Jos haluat nopeasti testata sivusi rakenteen ja indeksoida sen Googlen tavoin, Screaming Frog on hyödyllinen työkalu.
Tässä esimerkissä etusivun teho on jaettu neljään, ja kukin kategorioista saa 25 prosenttia etusivun tehosta ja jakaa osan siitä alaluokille. Tämä ratkaisu tarjoaa myös paremmat mahdollisuudet sisäiseen linkittämiseen. Kun esimerkiksi kirjoitat artikkelin kaupan blogiin ja haluat linkittää sen johonkin alaluokkaan, GB huomaa linkin indeksoidessaan sivustoa. Ensimmäisessä tapauksessa se ei tee sitä First Link Counts -säännön vuoksi. Jos linkki alaluokkaan oli sivuston valikossa, artikkelissa oleva linkki jätetään huomiotta.
Aloitin tämän SEO-kokeilun seuraavilla toimilla:
- Ensiksi sivulla1.html, lisäsin linkin alasivulle page2.html klassisena dofollow-linkkinä ankkurilla: anchor1.
- Seuraavaksi lisäsin saman sivun tekstiin hieman muokattuja viittauksia tarkistaakseni, olisiko GB innokas indeksoimaan niitä.
Tässä tarkoituksessa testasin seuraavia ratkaisuja:
- Verkkopalvelun etusivulle määrittelin yhden ulkoisen dofollow-linkin URL-ankkurilla varustetulle lausekkeelle (joten kaikki ulkoiset linkitykset etusivulle ja alasivuille tietyille lausekkeille olivat poissuljettuja) – se nopeutti palvelun indeksointia.
- Olin odottanut, että sivu2.html alkaisi sijoittua fraasille ensimmäisestä dofollow-linkistä (ankkuri1), joka tuli sivulta1.html. Tätä väärennettyä lausetta tai mitään muutakaan testaamaani ei löytynyt kohdesivulta. Oletin, että jos muut linkit toimisivat, myös sivu2.html sijoittuisi hakutuloksissa muiden linkkien sisältämille lauseille. Se kesti noin 45 päivää. Ja sitten pystyin tekemään ensimmäisen tärkeän johtopäätöksen:
Jopa sivusto, jossa avainsana ei ole sisällössä eikä metaotsikossa, mutta joka on linkitetty tutkitulla ankkurilla, voi helposti sijoittua hakutuloksissa korkeammalle kuin sivusto, joka sisältää tämän sanan, mutta johon ei ole linkitetty avainsanaa.
Lisäksi etusivu (page1.html), joka sisälsi tutkitun lauseen, oli verkkopalvelun vahvin sivu (linkitetty 78 prosentilla alasivuista), ja silti se sijoittui tutkitulla lauseella huonommin kuin alasivu (page2.html), joka oli linkitetty tutkittuun fraasiin.
Alhaalla esittelen neljä testaamaani linkkityyppiä, jotka kaikki tulevat ensimmäisen sivulle page2.html johtavan dofollow-linkin jälkeen.
Linkki ankkurilla
< a href=”page2.html#testhash” >anchor2< /a >
Ensimmäinen dofollow-linkin jälkeen koodiin tulevista lisälinkeistä oli ankkurilla (hashtag) varustettu linkki. Halusin nähdä, meneekö GB linkin läpi ja indeksoiko se myös sivun2.html lauseella anchor2, vaikka linkki johtaa kyseiselle sivulle (sivu2.html), mutta URL-osoite muuttuu muotoon page2.html#testhash uses anchor2.
Epäonnekseni GB ei koskaan halunnut muistaa tuota yhteyttä eikä se ohjannut valtaa alisivulle page2.html kyseisen lauseen kohdalla. Seurauksena on, että tämän artikkelin kirjoittamispäivänä hakutuloksissa lauseella anchor2 on vain alasivu page1.html, jossa sana löytyy linkin ankkurista. Kun googletetaan lausetta testhash, verkkotunnuksemme ei myöskään sijoita.
Linkki verkkosivulle, jossa on parametri
sivu2.html?parametri=1
Aluksi GB oli kiinnostunut tästä hassusta osasta URL-osoitteessa heti kyselymerkin jälkeen ja ankkurista ankkuri3-linkin sisällä.
Kiinnostuneena GB yritti selvittää, mitä tarkoitin. Se ajatteli: ”Onko se arvoitus?” Välttääkseen kaksoissisällön indeksoinnin muiden URL-osoitteiden alla, kanoninen sivu2.html osoitti itseensä. Lokit rekisteröivät yhteensä 8 indeksointia tähän osoitteeseen, mutta johtopäätökset olivat melko surullisia:
- Kahden viikon kuluttua GB:n käyntitiheys väheni merkittävästi, kunnes se lopulta poistui eikä indeksoinut kyseistä linkkiä enää koskaan.
- sivua2.html ei indeksoitu lauseen anchor3 alle, eikä myöskään URL-parametrin parametri1:n kanssa. Search Consolen mukaan tätä linkkiä ei ole olemassa (sitä ei lasketa saapuvien linkkien joukkoon), mutta samaan aikaan lause anchor3 on listattu ankkuroiduksi lauseeksi.
Linkki sivustolle uudelleenohjauksesta
Haluin pakottaa GB:n indeksoimaan sivustoni enemmän, mikä johti siihen, että GB kirjasi parin päivän välein dofollow-linkin ankkurilla anchor4 sivulle page1.html, joka johtaa sivulle page3.html, joka ohjaa 301-koodilla sivulle page2.html. Valitettavasti, kuten parametrin sisältävän sivun tapauksessa, 45 päivän kuluttua sivu2.html ei vielä sijoittunut hakutuloksissa ankkuri4-lauseelle, joka esiintyi sivun1.html uudelleenohjatussa linkissä.
Mutta Google Search Console -palvelussa Anchor Texts -osiossa ankkuri4 on näkyvissä ja indeksoitu. Tämä voisi viitata siihen, että jonkin ajan kuluttua uudelleenohjaus alkaa toimia odotetusti, jolloin sivu2.html sijoittuu hakutuloksissa anchor4:n kohdalla, vaikka se on toinen linkki samalle kohdesivulle saman verkkosivuston sisällä.
Linkki sivulle käyttämällä kanonista tagia
Sivulle1.html sijoitin viittauksen sivulle5.html (seurantalinkki), jossa on anchor anchor5. Samaan aikaan sivulla5.html oli uniikkia sisältöä, ja sen päässä oli kanoninen tagi sivulle2.html.
< linkki rel=”canonical” href=”https://example.com/page2.html” />
Testi antoi seuraavat tulokset:
- Linkki ankkuri5-lauseella, joka ohjaa sivulle5.html, ohjautuu kanonisesti sivulle2.html ei siirtynyt kohdesivulle (kuten muissakin tapauksissa).
- sivu5.html indeksoitiin kanonisesta tagista huolimatta.
- sivu5.html ei sijoittunut hakutuloksissa ankkuri5:lle.
- sivu5.html sijoittui sivun tekstissä käytettyjen fraasien perusteella, mikä osoitti, että GB jätti kanoniset tagit täysin huomiotta.
Valtuutan väittää, että rel=canonicalin käyttäminen joidenkin sisältöjen indeksoinnin estämiseksi (esim. suodatuksen aikana) ei yksinkertaisesti voinut toimia.
Osa 2: Crawl-budjetti
Suunniteltaessa hakukoneoptimoinnin (SEO) strategiaa halusin saada GB:n tanssimaan minun tahdissani enkä päinvastoin. Tätä varten tarkistin SEO-prosessit palvelinlokien tasolla (käyttö- ja virhelokit), mikä antoi minulle valtavan edun. Sen ansiosta tiesin GB:n jokaisen liikkeen ja miten se reagoi SEO-kampanjan yhteydessä tekemiini muutoksiin (verkkosivuston rakenneuudistus, sisäisen linkitysjärjestelmän kääntäminen ylösalaisin, tietojen esittämistapa).
Yksi tehtävistäni SEO-kampanjan aikana oli rakentaa verkkosivusto uudelleen siten, että GB:n piti vierailla vain niissä URL-osoitteissa, jotka se pystyi indeksoimaan ja jotka halusimme sen indeksoivan. Pähkinänkuoressa: Googlen indeksissä pitäisi olla vain ne sivut, jotka ovat meille SEO:n kannalta tärkeitä. Toisaalta GB:n pitäisi indeksoida vain ne sivustot, jotka haluamme Googlen indeksoivan, mikä ei ole kaikille itsestään selvää esimerkiksi silloin, kun verkkokauppa toteuttaa suodatuksen värien, koon ja hintojen mukaan, ja se tehdään manipuloimalla URL-parametreja, esim.:
example.com/women/shoes/?color=red&size=40&price=200-250
Voi käydä ilmi, että ratkaisu, joka sallii GB:n indeksoida dynaamisia URL-osoitteita, saa sen käyttämään aikaa niiden läpivalaisuun (ja mahdollisesti indeksointiin) sivun indeksoinnin sijaan.
example.com/women/shoes/
Tällaiset dynaamisesti luodut URL-osoitteet eivät ole vain hyödyttömiä vaan mahdollisesti haitallisia SEO:n kannalta, koska niitä voidaan erehtyä luulemaan ohueksi sisällöksi, mikä johtaa verkkosivujen sijoitusten laskuun.
Tässä kokeilussa halusin myös testata joitain jäsentelytapoja ilman rel=”nofollow” -toimintoa, GB:n estämistä robots.txt-tiedostossa tai osan HTML-koodista sijoittamista boteille näkymättömiin kehyksiin (estetty iframe).
Testasin kolmea erilaista JavaScript-linkkiä.
JavaScript-linkki onclick-tapahtumalla
Yksinkertainen JavaScriptillä rakennettu linkki
< a href=”javascript:void(0)” onclick=”window.location.href =’page4.html'” >ankkuri6< /a >
GB siirtyi helposti alasivulle page4.html ja indeksoi koko sivun. Alasivu ei sijoitu hakutuloksissa anchor6-lauseen osalta, eikä tätä lausetta löydy Google Search Consolen Anchor Texts -osiosta. Johtopäätös on, että linkki ei siirtänyt mehua.
Yhteenvetona:
- Klassinen JavaScript-linkki antaa Googlen indeksoida verkkosivuston ja indeksoida sivut, joihin se törmää.
- Se ei siirrä mehua – se on neutraali.
Javascript-linkki sisäisellä toiminnolla
Päätin nostaa pelin, mutta yllätyksekseni GB ylitti esteen alle kahdessa tunnissa linkin julkaisun jälkeen.
< a href=”javascript:void(0)” class=”js-link” data-url=”page9.html” >anchor7< /a >
Tämän linkin toimimiseen käytin ulkoista funktiota, jonka tarkoituksena oli lukea URL-osoite datasta ja ohjata – toivomukseni mukaan vain käyttäjän uudelleenohjaus – kohteeseen page9.html. Kuten aiemmassakin tapauksessa, sivu9.html oli täysin indeksoitu.
Mielenkiintoista on se, että muiden saapuvien linkkien puuttumisesta huolimatta sivu9.html oli GB:n kolmanneksi eniten vieraillut sivu koko verkkopalvelussa, heti sivu1.html:n ja sivu2.html:n jälkeen.
Olin käyttänyt tätä menetelmää aiemminkin verkkopalveluiden jäsentämiseen. Kuten näemme, se ei kuitenkaan enää toimi. SEO:ssa mikään ei elä ikuisesti, keltaisia sivuja lukuun ottamatta.
JavaScript-linkki koodauksen kanssa
Siltikään en luovuttanut, ja päätin, että on oltava keino sulkea ovi tehokkaasti GB:n edestä. Niinpä rakensin yksinkertaisen funktion, koodasin datan base64-algoritmilla, ja viittaus näytti tältä:
< a href=”javascript:void(0)” class=”js-link” data-url=”cGFnZTEwLmh0bWw=” >anchor8< /a >
Lopputuloksena GB ei kyennyt tuottamaan JavaScript-koodia, joka sekä purkaisi data-URL-attribuutin sisällön että ohjaisi uudelleen. Ja siinä se oli! Meillä on tapa jäsentää verkkopalvelu käyttämättä rel=nonfollowsia, jotta botit eivät voi ryömiä minne haluavat! Näin emme tuhlaa crawl-budjettia, mikä on erityisen tärkeää suurten verkkopalveluiden tapauksessa, ja GB tanssii vihdoinkin meidän tahdissamme. Riippumatta siitä, otettiinko toiminto käyttöön samalla sivulla head-osiossa vai ulkoisessa JS-tiedostossa, botista ei ole todisteita sen enempää palvelinlokeissa kuin Search Consolessakaan.
Osa 3: Piilotettu sisältö
Viimeisessä testissä halusin tarkastaa, huomioiko ja indeksoiko ja indeksoiko GB esimerkiksi piilotetuissa välilehdissä olevan sisällön vai renderöiikö Google tällaisen sivun ja jättää piilotetun tekstin huomioimatta, kuten eräät erikoisasiantuntijat ovat väittäneet.”
Halusin siis saada joko vahvistuksen väitteeseeni, tai sitten hylätä sen. Tätä varten sijoitin yli 2000 merkkiä sisältävän tekstiseinän sivulle12.html ja piilotin tekstilohkon, jossa oli noin 20 prosenttia tekstistä (400 merkkiä), Cascading Style Sheetsillä ja lisäsin Näytä lisää -painikkeen. Piilotetun tekstin sisällä oli linkki sivulle13.html, jossa oli ankkuri anchor9.
Ei ole epäilystäkään siitä, että robotti voi renderöidä sivun. Voimme havaita sen sekä Google Search Consolessa että Google Insight Speedissä. Testeissäni kävi kuitenkin ilmi, että tekstilohko, joka näytettiin Näytä lisää -painikkeen napsauttamisen jälkeen, indeksoitiin kokonaan. Tekstiin piilotetut lauseet sijoittuivat hakutuloksissa, ja GB seurasi tekstiin piilotettuja linkkejä. Lisäksi piilotetun tekstilohkon linkkien ankkurit näkyivät Google Search Consolessa Anchor Text -osiossa, ja page13.html alkoi myös sijoittua hakutuloksissa hakusanalla anchor9.
Tämä on ratkaisevan tärkeää verkkokaupoille, joissa sisältö on usein sijoitettu piilotettuihin välilehtiin. Nyt olemme varmoja siitä, että GB näkee sisällön piilotetuissa välilehdissä, indeksoi ne ja siirtää mehua sinne piilotetuista linkeistä.
Tärkein johtopäätös, jonka vedän tästä kokeilusta, on se, että en ole löytänyt suoraa tapaa kiertää First Link Counts -sääntöä käyttämällä muokattuja linkkejä (linkit, joissa on parametri, 301-uudelleenohjaukset, canonicalit, ankkurilinkit). Samaan aikaan on mahdollista rakentaa verkkosivuston rakenne Javascript-linkkien avulla, minkä ansiosta olemme vapaita First Link Counts -säännön rajoituksista. Lisäksi Google Bot näkee ja indeksoi kirjanmerkkeihin piilotetun sisällön ja seuraa niihin piilotettuja linkkejä.
Tilaa päivittäiset yhteenvetomme jatkuvasti muuttuvasta hakumarkkinointimaisemasta.
Huomautus: Lähettämällä tämän lomakkeen hyväksyt Third Door Median ehdot. Kunnioitamme yksityisyyttäsi.
Tietoa kirjoittajasta

”Älä hyväksy ’vain’ korkeaa laatua. Kuka tahansa voi tehdä sen. Jos taivas on rajana, etsi korkeampi taivas.” Max Cyrek on Cyrek Digitalin toimitusjohtaja, digitaalisen markkinoinnin konsultti ja SEO-evankelista. Uransa aikana Max on yhdessä yli 30 hengen tiiminsä kanssa työskennellyt satojen yritysten kanssa auttaen niitä menestymään. Hän on työskennellyt digitaalisen markkinoinnin parissa lähes kymmenen vuotta, ja hän on erikoistunut tekniseen SEO:hon ja johtanut menestyksekkäitä markkinointiprojekteja.
Vastaa