Ihmiset luovat, jakavat ja tallentavat tietoja nopeammin kuin koskaan aiemmin historiassa. Kun on kyse innovoinnista tuon datan tallentamisessa ja siirtämisessä, me Facebookissa edistymme paitsi laitteistoissa – kuten suuremmissa kiintolevyissä ja nopeammissa verkkolaitteissa – myös ohjelmistoissa. Ohjelmistot auttavat tietojenkäsittelyssä pakkaamalla tietoja, kuten tekstiä, kuvia ja muita digitaalisia tietoja, käyttämällä alkuperäistä vähemmän bittejä. Nämä pienemmät tiedostot vievät vähemmän tilaa kiintolevyltä ja siirtyvät nopeammin muihin järjestelmiin. Tietojen pakkaamisessa ja purkamisessa on kuitenkin haittapuolensa: se vie aikaa. Mitä enemmän aikaa kuluu pienempään tiedostoon pakkaamiseen, sitä hitaammin tietoa käsitellään.
Tänään hallitseva tiedonpakkausstandardi on Deflate, joka on Zip-, gzip- ja zlib-ohjelmien ydinalgoritmi. Kahden vuosikymmenen ajan se on tarjonnut vaikuttavan tasapainon nopeuden ja tilan välillä, ja sen seurauksena sitä käytetään lähes jokaisessa nykyaikaisessa elektronisessa laitteessa (ja, mikä ei ole sattumaa, sitä käytetään tämän lukemasi blogikirjoituksen jokaisen tavun siirtämiseen). Vuosien mittaan muut algoritmit ovat tarjonneet joko parempaa pakkausta tai nopeampaa pakkausta, mutta harvoin molempia. Uskomme, että olemme muuttaneet tämän.
Olemme iloisia voidessamme julkistaa Zstandard 1.0:n, uuden pakkausalgoritmin ja -toteutuksen, joka on suunniteltu skaalautumaan nykyaikaisen laitteiston kanssa ja pakkaamaan pienempiä ja nopeammin. Zstandardissa yhdistyvät viimeaikaiset pakkauksen läpimurrot, kuten Finite State Entropy, suorituskykylähtöiseen suunnitteluun – ja sitten optimoidaan toteutus nykyaikaisten suorittimien ainutlaatuisia ominaisuuksia varten. Tämän ansiosta se parantaa muiden pakkausalgoritmien tekemiä kompromisseja, ja sillä on laaja sovellusalue ja erittäin suuri purkunopeus. Zstandard, joka on nyt saatavilla BSD-lisenssillä, on suunniteltu käytettäväksi lähes kaikissa häviöttömän pakkauksen skenaarioissa, myös monissa sellaisissa, joihin nykyiset algoritmit eivät sovellu.
- Pakkauksen vertailu
- Skaalautuvuus
- Konepellin alla
- Muisti
- Rinnakkaista suoritusta varten suunniteltu muoto
- Haaraton suunnittelu
- Finite State Entropy: A next-generation probability compressor
- Repkoodimallinnus
- Zstandard käytännössä
- Pieni data
- Sanakirjat toiminnassa
- Pakkaustason valitseminen
- Kokeile sitä
- Lisää tulossa
Pakkauksen vertailu
Pakkausalgoritmien ja -toteutusten vertailuun on olemassa kolme vakiomittaria:
- Pakkaussuhde: Alkuperäinen koko (osoittaja) verrattuna pakattuun kokoon (nimittäjä), mitattuna yksiköimättömänä datana kokosuhteena 1,0 tai suurempi.
- Pakkausnopeus: Kuinka nopeasti saadaan data pienemmäksi, mitattuna MB/s syötetystä datasta kulutettuna.
- Puristusnopeus: Kuinka nopeasti voimme palauttaa alkuperäisen datan pakatusta datasta, mitattuna MB/s nopeudella, jolla dataa tuotetaan pakatusta datasta.
Pakattavan datan tyyppi voi vaikuttaa näihin mittareihin, joten monet algoritmit on viritetty tietyntyyppistä dataa, kuten englanninkielistä tekstiä, geneettisiä sekvenssejä tai rasteroituja kuvia varten. Zstandard, kuten zlib, on kuitenkin tarkoitettu yleiskäyttöiseen pakkaukseen useille eri tietotyypeille. Edustaaksemme algoritmeja, joiden odotetaan toimivan Zstandardin kanssa, käytämme tässä postauksessa Silesia-korpusta, joka koostuu tiedostoista, jotka edustavat tyypillisiä päivittäin käytettäviä tietotyyppejä.
Joitakin nykyään yleisesti käytettyjä algoritmeja ja toteutuksia ovat zlib, lz4 ja xz. Kukin näistä algoritmeista tarjoaa erilaisia kompromisseja: lz4 pyrkii nopeuteen, xz pyrkii suurempaan pakkaussuhteeseen ja zlib pyrkii hyvään tasapainoon nopeuden ja koon välillä. Alla olevasta taulukosta käy ilmi algoritmien oletuspakkaussuhteen ja nopeuden karkeat kompromissit Silesia-korpuksen osalta vertailemalla algoritmeja lzbenchillä, joka on puhtaasti muistissa suoritettava vertailuarvo, joka on tarkoitettu mallintamaan algoritmien raakaa suorituskykyä.
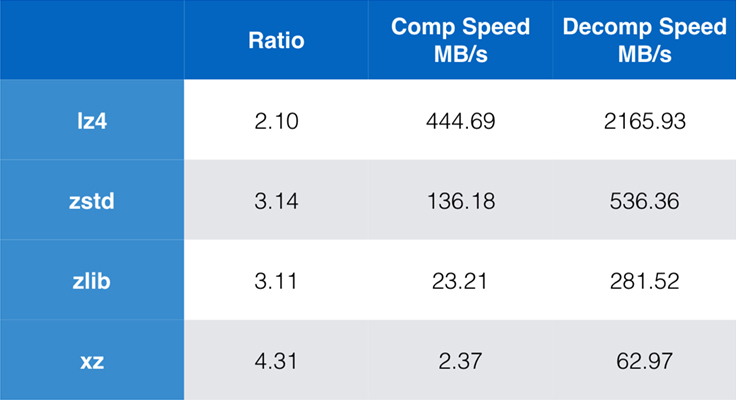
Kuten on hahmoteltu, nopeuden ja koon välillä tehdään usein rajuja kompromisseja. Nopein algoritmi, lz4, johtaa alhaisempiin pakkaussuhteisiin; xz, jolla on korkein pakkaussuhde, kärsii hitaasta pakkausnopeudesta. Zstandard osoittaa kuitenkin oletusasetuksilla huomattavia parannuksia sekä pakkaus- että purkamisnopeudessa, vaikka se pakkaa samalla suhdeluvulla kuin zlib.
Vaikka pelkkä algoritmin suorituskyky on tärkeää, kun pakkaus on upotettu osaksi suurempaa sovellusta, on erittäin yleistä käyttää myös komentorivityökaluja pakkaamiseen – esimerkiksi lokitiedostojen, tarballien tai muiden vastaavien tallennettavaksi tai siirrettäväksi tarkoitettujen tietojen pakkaamiseen. Näissä tapauksissa suorituskykyyn vaikuttavat usein yleiskustannukset, kuten tarkistussummat. Tässä kaaviossa esitetään gzip- ja zstd-komentorivityökalujen vertailu Centos 7:llä, joka on rakennettu järjestelmän oletuskääntäjällä.
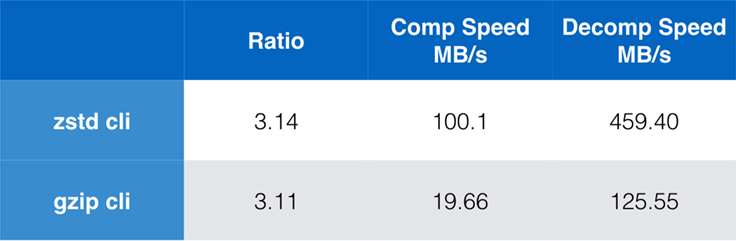
Testit suoritettiin kumpikin 10 kertaa, joista otettiin minimiajat, ja ne suoritettiin ramdisk-levyllä tiedostojärjestelmän ylikuormituksen välttämiseksi. Nämä olivat komennot (joissa käytetään molempien työkalujen oletuspakkaustasoja):
zstd -c -3 silesia.tar > silesia.tar.zst # 67,432,740 byteszstd -d -c silesia.tar.zst > /dev/nullgzip -c -6 silesia.tar > silesia.tar.gz # 68,235,522 bytesgzip -d -c silesia.tar.gz > /dev/nullSkaalautuvuus
Jos algoritmi on skaalautuva, sillä on kyky mukautua monenlaisiin vaatimuksiin, ja Zstandard on suunniteltu niin, että se voi kunnostautua nykyisessä maisemassa ja skaalautua tulevaisuuteen. Useimmissa algoritmeissa on ”tasoja”, jotka perustuvat ajan ja tilan välisiin kompromisseihin: Mitä korkeampi taso, sitä suurempi pakkaus saavutetaan pakkausnopeuden menetyksellä. Zlib tarjoaa yhdeksän pakkaustasoa; Zstandard tarjoaa tällä hetkellä 22 tasoa, mikä mahdollistaa joustavat, rakeiset kompromissit pakkausnopeuden ja suhteiden välillä tulevaa dataa varten. Voimme esimerkiksi käyttää tasoa 1, jos nopeus on tärkein, ja tasoa 22, jos koko on tärkein.
Alhaalla on kaavio Zstandardin ja zlibin kaikilla tasoilla saavutetuista pakkausnopeuksista ja -suhteista. x-akseli on laskeva logaritminen asteikko megatavuina sekunnissa; y-akseli on saavutettu pakkaussuhde. Voit vertailla algoritmeja valitsemalla nopeuden, jolloin näet algoritmien kyseisellä nopeudella saavuttamat eri suhteet. Samoin voit valita suhdeluvun ja nähdä, kuinka nopeasti algoritmit toimivat, kun ne saavuttavat kyseisen tason.
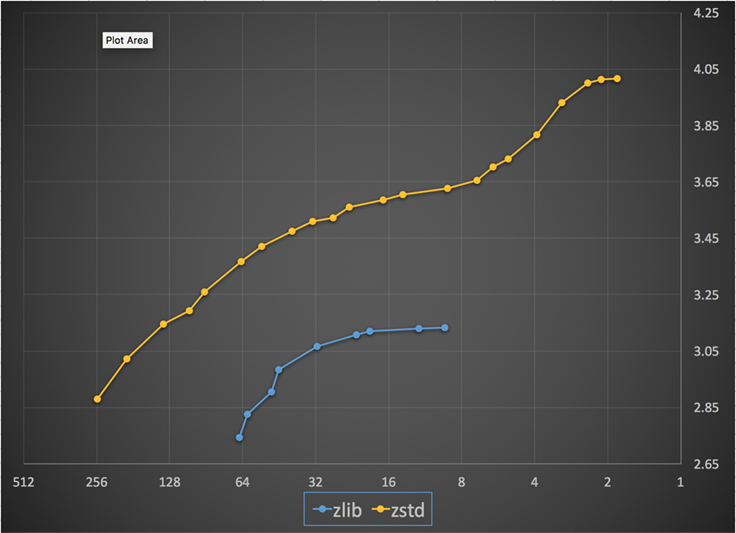
Millä tahansa pystysuoralla viivalla (eli pakkausnopeudella) Zstandard saavuttaa suuremman pakkaussuhteen. Silesia-korpuksen osalta purkunopeus – suhteesta riippumatta – oli noin 550 MB/s Zstandardilla ja 270 MB/s zlibillä. Kaavio osoittaa toisen eron Zstandardin ja vaihtoehtojen välillä: Käyttämällä yhtä algoritmia ja toteutusta Zstandard mahdollistaa paljon tarkemman hienosäädön kutakin käyttötapausta varten. Tämä tarkoittaa, että Zstandard voi kilpailla joidenkin nopeimpien ja korkeimpien pakkausalgoritmien kanssa ja säilyttää samalla huomattavan purkunopeusedun. Nämä parannukset näkyvät suoraan nopeampana tiedonsiirtona ja pienempinä tallennustilavaatimuksina.
Toisin sanoen zlibiin verrattuna Zstandard skaalautuu:
- Samalla pakkaussuhteella se pakkaa huomattavasti nopeammin: ~3-5x.
- Se on samalla pakkausnopeudella huomattavasti pienempi: 10-15 prosenttia pienempi.
- Se on melkein 2x nopeampi purettaessa, pakkaussuhteesta riippumatta; komentorivin työkaluluvut osoittavat vielä suuremman eron: yli 3x nopeampi.
- Se skaalautuu paljon suuremmille pakkaussuhteille säilyttäen samalla salamannopeat purkunopeudet.
Konepellin alla
Zstandard parantaa zlibiä yhdistämällä useita viimeaikaisia innovaatioita ja kohdistamalla ne nykyaikaiseen laitteistoon:
Muisti
Suunnittelultaan zlib on rajoitettu 32 kilotavun suuruiseen paketti-ikkunaan, mikä oli järkevä valinta 90-luvun alussa. Mutta nykypäivän laskentaympäristö voi käyttää paljon enemmän muistia – jopa mobiilissa ja sulautetuissa ympäristöissä.
Zstandardilla ei ole mitään luontaista rajoitusta, ja se voi käsitellä teratavun verran muistia (vaikkakin se tekee niin harvoin). Esimerkiksi 22 tasosta alempi käyttää 1 Mt tai vähemmän. Yhteensopivuuden takaamiseksi monenlaisten vastaanottojärjestelmien kanssa, joissa muisti voi olla rajallista, on suositeltavaa rajoittaa muistin käyttö 8 MB:iin. Tämä on kuitenkin virityssuositus, ei pakkausmuodon rajoitus.
Rinnakkaista suoritusta varten suunniteltu muoto
Tämän päivän suorittimet ovat erittäin tehokkaita ja pystyvät antamaan useita käskyjä sykliä kohti useiden ALU:iden (aritmeettiset logiikkayksiköt) ja yhä kehittyneemmän järjestyksen ulkopuolisen suorituksen suunnittelun ansiosta.
Keskeisesti se tarkoittaa, että jos:
a = b1 + b2
c = d1 + d2
tällöin sekä a että c lasketaan rinnakkain.
Tämä on mahdollista vain, jos niiden välillä ei ole mitään yhteyttä. Siksi tässä esimerkissä:
a = b1 + b2
c = d1 + a
c:n on odotettava, että a lasketaan ensin, ja vasta sen jälkeen aloitetaan c:n laskenta.
Nykyaikaisen suorittimen hyödyntämiseksi on siis suunniteltava operaatiovirta, jossa on vain vähän tai ei lainkaan datariippuvuuksia.
Tämä saavutetaan Zstandardilla erottamalla data useisiin rinnakkaisiin virtoihin. Uuden sukupolven Huffman-dekooderi, Huff0, pystyy dekoodaamaan useita symboleja rinnakkain yhdellä ytimellä. Tällainen hyöty kumuloituu monisäikeistyksellä, joka käyttää useita ytimiä.
Haaraton suunnittelu
Uudet suorittimet ovat tehokkaampia ja yltävät hyvin korkeisiin taajuuksiin, mutta tämä on mahdollista vain monivaiheisen lähestymistavan ansiosta, jossa käsky jaetaan useista vaiheista koostuvaan putkeen. Jokaisella kellojaksolla CPU pystyy antamaan useiden operaatioiden tuloksen, riippuen käytettävissä olevista ALU:ista. Mitä enemmän ALU:ita käytetään, sitä enemmän työtä CPU tekee ja sitä nopeammin pakkaaminen tapahtuu. Nykyaikaisen suorittimen suorituskyvyn kannalta on ratkaisevan tärkeää, että ALU:t saavat työtä.
Tämä osoittautuu vaikeaksi. Tarkastellaan seuraavaa yksinkertaista tilannetta:
if (condition) doSomething() else doSomethingElse()Koska CPU kohtaa tämän, se ei tiedä mitä tehdä, koska se riippuu condition:n arvosta. Varovainen suoritin odottaisi condition:n tulosta ennen kuin työskentelisi kummassakin haarassa, mikä olisi äärimmäisen tuhlaavaa.
Tämän päivän suorittimet pelaavat uhkapeliä. Ne tekevät sen älykkäästi, kiitos haaraennustimen, joka kertoo niille pohjimmiltaan todennäköisimmän tuloksen condition:n evaluoinnista. Kun veto on oikea, putki pysyy täynnä ja ohjeita annetaan jatkuvasti. Kun veto on väärä (virheennuste), suorittimen on keskeytettävä kaikki spekulatiivisesti aloitetut operaatiot, palattava haarautumiseen ja otettava toinen suunta. Tätä kutsutaan putkistohuuhteluksi, ja se on erittäin kallista nykyaikaisissa suorittimissa.
Kaksikymmentäviisi vuotta sitten putkistohuuhtelu ei ollut ongelma. Nykyään se on niin tärkeää, että on välttämätöntä suunnitella haarautumattomien algoritmien kanssa yhteensopivia formaatteja. Katsotaanpa esimerkkinä bittivirran päivitystä:
/* classic version */while (nbBitsUsed >= 8) { /* each while test is a branch */ accumulator <<= 8; accumulator += *byte++; nbBitsUsed -= 8;} /*>/* branch-less version */nbBytesUsed = nbBitsUsed >> 3;nbBitsUsed &= 7;ptr += nbBytesUsed;accumulator = read64(ptr);Kuten näet, haarautumattomalla versiolla on ennakoitavissa oleva työmäärä, ilman mitään ehtoa. Suoritin tekee aina saman työn, eikä tätä työtä koskaan heitetä pois väärän ennusteen takia. Sen sijaan klassinen versio tekee vähemmän työtä, kun (nbBitsUsed < 8). Mutta itse testi ei ole ilmainen, ja aina kun testi arvuutellaan väärin, se johtaa koko putken huuhteluun, joka maksaa enemmän kuin haarautumattoman version tekemä työ.
Kuten arvata saattaa, tällä sivuvaikutuksella on vaikutuksia tapaan, jolla data pakataan, luetaan ja dekoodataan. Zstandard on luotu olemaan ystävällinen haarautumattomille algoritmeille, erityisesti kriittisissä silmukoissa.
Finite State Entropy: A next-generation probability compressor
Pakkauksessa data muutetaan ensin joukoksi symboleita (mallinnusvaihe), ja sitten nämä symbolit koodataan käyttämällä mahdollisimman vähän bittejä. Tätä toista vaihetta kutsutaan Claude Shannonin muistoksi entropiavaiheeksi, joka laskee tarkasti symbolijoukon pakkausrajan tietyillä todennäköisyyksillä (jota kutsutaan ”Shannonin rajaksi”). Tavoitteena on päästä lähelle tätä rajaa käyttäen mahdollisimman vähän suorittimen resursseja.
Erittäin yleinen algoritmi on Huffman-koodaus, jota käytetään Deflatessa. Se antaa parhaan mahdollisen etuliitekoodin olettaen, että jokainen symboli kuvataan luonnollisella bittien määrällä (1 bitti, 2 bittiä …). Tämä toimii käytännössä hyvin, mutta luonnollisten lukujen rajoitus tarkoittaa, että sillä on mahdotonta saavuttaa suuria pakkaussuhteita, koska symboli kuluttaa väistämättä vähintään yhden bitin.
Parempi menetelmä on nimeltään aritmeettinen koodaus, joka voi päästä mielivaltaisesti lähelle Shannonin rajaa -log2(P), jolloin se kuluttaa murtobittejä symbolia kohti. Se johtaa parempaan pakkaussuhteeseen, kun todennäköisyydet ovat suuria, mutta se myös käyttää enemmän prosessoritehoa. Käytännössä jopa optimoidut aritmeettiset koodaajat kamppailevat nopeudesta, erityisesti purkupuolella, joka vaatii jakoja, joilla on ennustettava tulos (esim. ei liukulukua) ja joka osoittautuu hitaaksi.
Finite State Entropy perustuu Jarek Dudan uuteen teoriaan nimeltä ANS (Asymmetric Numeral System). Finite State Entropy on muunnelma, joka laskee monia koodausvaiheita etukäteen taulukoihin, jolloin tuloksena on yhtä tarkka entropia-koodekki kuin aritmeettinen koodaus, joka käyttää vain yhteenlaskuja, taulukoiden etsimistä ja siirtoja, mikä on suunnilleen yhtä monimutkaista kuin Huffman. Se myös vähentää viiveaikaa seuraavaan symboliin pääsemiseksi, koska se on välittömästi saatavilla tila-arvosta, kun taas Huffman vaatii edeltävän bittivirran dekoodausoperaation. Sen toiminnan selittäminen ei kuulu tämän postauksen piiriin, mutta jos olet kiinnostunut, on olemassa sarja artikkeleita, joissa kerrotaan yksityiskohtaisesti sen sisäisestä toiminnasta.
Repkoodimallinnus
Repkoodimallinnus pakkaa tehokkaasti strukturoitua dataa, jossa on sisällöltään lähes samanarvoisia sekvenssejä, jotka eroavat toisistaan vain yhden tai muutaman tavun verran. Tämä menetelmä ei ole uusi, mutta sitä käytettiin ensimmäisen kerran Deflaten julkaisun jälkeen, joten sitä ei ole olemassa zlib/gzip:ssä.
Repcode-mallinnuksen tehokkuus riippuu suuresti pakattavan datan tyypistä, ja se vaihtelee yhdestä kaksinumeroiseen pakkauksen parannukseen. Nämä yhteenlasketut parannukset johtavat parempaan ja nopeampaan pakkauskokemukseen, joka tarjotaan Zstandard-kirjastossa.
Zstandard käytännössä
Kuten aiemmin mainittiin, pakkaukselle on useita tyypillisiä käyttötapauksia. Jotta algoritmi olisi vakuuttava, sen on joko oltava poikkeuksellisen hyvä yhdessä tietyssä käyttötapauksessa, kuten ihmisen luettavissa olevan tekstin pakkaamisessa, tai erittäin hyvä monissa erilaisissa käyttötapauksissa. Zstandard noudattaa jälkimmäistä lähestymistapaa. Yksi tapa ajatella käyttötapauksia on se, kuinka monta kertaa tiettyä dataa voidaan purkaa. Zstandardilla on etuja kaikissa näissä tapauksissa.
Monta kertaa. Kun tietoja käsitellään useita kertoja, purkamisnopeus ja mahdollisuus valita erittäin korkea pakkaussuhde purkamisnopeudesta tinkimättä on edullista. Esimerkiksi Facebookin sosiaalisen graafin tallennusta luetaan toistuvasti, kun sinä ja ystäväsi olette vuorovaikutuksessa sivuston kanssa. Facebookin ulkopuolella esimerkkejä tilanteista, joissa data on purettava monta kertaa, ovat palvelimelta ladatut tiedostot, kuten Linux-ytimen lähdekoodi tai palvelimille asennetut RPM-ohjelmat, verkkosivun käyttämät JavaScript- ja CSS-ohjelmat tai tuhansien MapReduce-ohjelmien suorittaminen tietovarastossa olevan datan yli.
Kerran vain. Vain kerran pakatun datan osalta, erityisesti verkon välityksellä tapahtuvaa siirtoa varten, pakkaus on ohimenevä hetki tietovirrassa. Mitä vähemmän yleiskustannuksia palvelimelle aiheutuu, sitä enemmän palvelin pystyy käsittelemään pyyntöjä sekunnissa. Vähemmän yleiskustannuksia asiakkaalle tarkoittaa, että tietoja voidaan käsitellä nopeammin. Tyypillisesti tämä tulee esiin asiakkaan ja palvelimen välisissä tilanteissa, joissa tiedot ovat ainutlaatuisia asiakkaalle, kuten verkkopalvelimen vastaus, joka on mukautettu – esimerkiksi tiedot, joita käytetään renderöintiin, kun saat viestin ystävältäsi Messengerissä. Lopputuloksena mobiililaitteesi lataa sivut nopeammin, käyttää vähemmän akkua ja kuluttaa vähemmän datasopimusta. Erityisesti Zstandard soveltuu mobiiliskenaarioihin paljon paremmin kuin muut algoritmit, koska se käsittelee pientä dataa.
Mahdollisesti ei koskaan. Vaikka näennäisesti vastenmieliseltä tuntuukin, on usein niin, että jotakin dataa – kuten varmuuskopioita tai lokitiedostoja – ei koskaan pureta, mutta se voidaan lukea tarvittaessa. Tämäntyyppisen datan pakkaamisen on yleensä oltava nopeaa, tehtävä datasta pientä (tilanteeseen sopivalla ajan ja tilan suhteen kompromissilla) ja ehkä tallennettava tarkistussumma, mutta muuten sen on oltava näkymätöntä. Siinä harvinaisessa tapauksessa, että tieto on purettava, pakkauksen ei haluta hidastavan operatiivista käyttötapahtumaa. Nopea purkaminen on hyödyllistä, koska usein on kyse pienestä datan osasta (kuten tietystä tiedostosta varmuuskopiossa tai viestistä lokitiedostossa), joka on löydettävä nopeasti.
Kaikkiin näihin tapauksiin Zstandard tuo mahdollisuuden pakata ja purkaa pakkaus moninkertaisesti nopeammin kuin gzip, jolloin tuloksena syntyvä pakattu data on pienempää.
Pieni data
On toinenkin pakkauksen käyttötapauksista, joka jää vähemmälle huomiolle, mutta se voi olla hyvinkin tärkeätä: pieni data. Kyseessä ovat käyttötapaukset, joissa dataa tuotetaan ja kulutetaan pieniä määriä, kuten JSON-viestit web-palvelimen ja selaimen välillä (tyypillisesti satoja tavuja) tai tietokannan datasivut (muutama kilotavu).
Tietokannat tarjoavat mielenkiintoisen käyttötapauksen. MySQL:n, PostgreSQL:n ja MongoDB:n kaltaiset järjestelmät tallentavat reaaliaikaiseen käyttöön tarkoitettuja tietoja. Viimeaikaiset laitteistoedut, erityisesti flash-laitteiden (SSD) yleistyminen, ovat muuttaneet perusteellisesti tasapainoa koon ja läpäisykyvyn välillä – elämme nyt maailmassa, jossa IOP:t (IO-operaatiot sekunnissa) ovat melko korkeita, mutta tallennuslaitteidemme kapasiteetti on pienempi kuin silloin, kun kiintolevyt hallitsivat datakeskuksia.
Flash-tietokannalla on lisäksi mielenkiintoinen ominaisuus, joka koskee kirjoituksen kestävyyttä – kun laitteen samaan osaan on kirjoitettu tuhansia kirjoituksia, kyseinen osa ei enää voi ottaa vastaan kirjoituksia, mikä johtaa usein siihen, että laite poistetaan käytöstä. Siksi on luonnollista etsiä keinoja vähentää kirjoitettavan datan määrää, koska se voi tarkoittaa enemmän dataa palvelinta kohden ja laitteen polttamista loppuun hitaammin. Tiedonpakkaus on yksi strategia tähän, ja myös tietokannat optimoidaan usein suorituskyvyn kannalta, eli luku- ja kirjoitussuorituskyky ovat yhtä tärkeitä.
Tietokantojen kanssa tapahtuvaan tiedonpakkauksen käyttämiseen liittyy kuitenkin komplikaatio. Tietokannat haluavat käyttää dataa satunnaisesti, kun taas useimmat tyypillisimmät pakkauksen käyttötapaukset lukevat koko tiedoston lineaarisessa järjestyksessä. Tämä on ongelma, koska tiedonpakkaus toimii pohjimmiltaan ennustamalla tulevaisuutta menneisyyden perusteella – algoritmit tarkastelevat dataa peräkkäin ja ennustavat, mitä se voi nähdä tulevaisuudessa. Mitä tarkempia ennusteet ovat, sitä pienemmäksi datasta voidaan tehdä.
Kun pakkaat pientä dataa, kuten tietokannan sivuja tai mobiililaitteeseen lähetettäviä pieniä JSON-dokumentteja, ”menneisyyttä” ei yksinkertaisesti ole paljonkaan käytettävissä tulevaisuuden ennustamiseen. Pakkausalgoritmit ovat yrittäneet puuttua tähän käyttämällä ennalta jaettuja sanakirjoja tehokkaaseen hyppykäynnistykseen. Tämä tapahtuu jakamalla ennalta staattinen joukko ”menneisyyden” tietoja pakkauksen siemenenä.
Zstandard perustuu tähän lähestymistapaan erittäin optimoiduilla algoritmeilla ja sovellusliittymillä sanakirjojen pakkausta varten. Lisäksi Zstandard sisältää (zstd --train)työkaluja, joiden avulla voidaan helposti tehdä sanakirjoja räätälöityjä sovelluksia varten, sekä säännöksiä vakiosanakirjojen rekisteröimiseksi, jotta niitä voidaan jakaa laajempien yhteisöjen kanssa. Vaikka tiivistys vaihtelee datanäytteiden mukaan, pienen datan tiivistys voi olla 2x-5x parempi kuin tiivistys ilman sanakirjoja.
Sanakirjat toiminnassa
Vaikka sanakirjalla voi olla vaikea leikkiä käynnissä olevan tietokannan yhteydessä (vaatiihan se huomattavia muutoksia tietokantaan), voit nähdä sanakirjoja toiminnassa muunlaisen pienen datan kanssa. JSON, pienen datan lingua franca nykymaailmassa, on yleensä pieniä, toistuvia tietueita. Saatavilla on lukemattomia julkisia tietokokonaisuuksia; tässä demonstraatiossa käytämme GitHubin ”user”-tietokokonaisuutta, joka on saatavilla HTTP:n kautta. Tässä on esimerkkitietue tästä datajoukosta:
{ "login": "octocat", "id": 1, "avatar_url": "https://github.com/images/error/octocat_happy.gif", "gravatar_id": "", "url": "https://api.github.com/users/octocat", "html_url": "https://github.com/octocat", "followers_url": "https://api.github.com/users/octocat/followers", "following_url": "https://api.github.com/users/octocat/following{/other_user}", "gists_url": "https://api.github.com/users/octocat/gists{/gist_id}", "starred_url": "https://api.github.com/users/octocat/starred{/owner}{/repo}", "subscriptions_url": "https://api.github.com/users/octocat/subscriptions", "organizations_url": "https://api.github.com/users/octocat/orgs", "repos_url": "https://api.github.com/users/octocat/repos", "events_url": "https://api.github.com/users/octocat/events{/privacy}", "received_events_url": "https://api.github.com/users/octocat/received_events", "type": "User", "site_admin": false }Kuten näet, tässä on melko paljon toistoa – voimme pakata nämä mukavasti! Kukin käyttäjä on kuitenkin hieman alle 1 kilotavun kokoinen, ja useimmat pakkausalgoritmit tarvitsevat todella enemmän dataa venyttääkseen jalkojaan. Tuhannen käyttäjän joukko vie pakkaamattomana noin 850 kilotavua. Soveltamalla naiivisti joko gzip:tä tai zstd:tä erikseen kuhunkin tiedostoon tämä laskee hieman yli 300 kilotavuun; ei hassumpaa! Mutta jos luomme kertaluonteisen, ennalta jaetun sanakirjan, zstd:n avulla koko putoaa 122 kilotavuun – jolloin alkuperäinen pakkaussuhde nousee 2,8-kertaisesta 6,9-kertaiseksi. Tämä on merkittävä parannus, joka on saatavissa suoraan zstd:
$ zstd --train -o ../json.zdict -r .sorting 982 files of total size 0 MB ...finding patterns ...statistics ...Save dictionary of size 65599 into file ../json.zdict$ du -h --apparent-size .846K .$ zstd --rm -D ../json.zdict -r .$ du -h --apparent-size .122K .Pakkaustason valitseminen
Kuten edellä on esitetty, Zstandard tarjoaa huomattavan määrän tasoja. Tämä räätälöinti on tehokasta, mutta johtaa vaikeisiin valintoihin. Paras tapa päättää on tarkastella tietojasi ja tehdä mittauksia sekä päättää, mitä kompromisseja haluat tehdä. Facebookissa pidämme oletustasoa 3 sopivana moniin käyttötapauksiin, mutta aika ajoin muokkaamme sitä hieman sen mukaan, mikä on pullonkaulamme (usein yritämme kyllästää verkkoyhteyden tai levyn karan); toisinaan taas välitämme enemmän tallennetusta koosta ja käytämme korkeampaa tasoa.
Loppujen lopuksi, jotta saat tarpeisiisi parhaiten räätälöidyt tulokset, sinun on otettava huomioon sekä käyttämäsi laitteisto että tiedot, joista välität – ei ole olemassa mitään tiukkoja ja nopeita määräyksiä, jotka voidaan tehdä ilman kontekstia. Epäselvissä tapauksissa kannattaa kuitenkin joko pitää kiinni oletustasosta 3 tai jostain tasosta 6-9, jotta nopeuden ja tilan välinen kompromissi olisi hyvä; säästä taso 20+ tapauksiin, joissa todella välität vain koosta etkä pakkausnopeudesta.
Kokeile sitä
Zstandard on sekä komentorivityökalu (zstd) että kirjasto. Se on kirjoitettu erittäin helposti siirrettävällä C-kielellä, joten se soveltuu käytännössä jokaiselle nykyään käytetylle alustalle – olipa kyse sitten yritystäsi pyörittävistä palvelimista, kannettavasta tietokoneesta tai jopa taskussasi olevasta puhelimesta. Voit napata sen github-arkistostamme, kääntää sen yksinkertaisella make install:llä ja alkaa käyttää sitä kuten gzip:
$ zstd access.logaccess.log : 8.07% (6695078 => 540336 bytes, access.log.zst)Kuten arvata saattaa, voit käyttää sitä osana komentoputkea esimerkiksi kriittisen MySQL-tietokantasi varmuuskopioimiseen:
$ mysqldump --single-transaction --opt pokemon | zstd -q -o /srv/backups/mysqldump.sql.zstKomento tar tukee erilaisia pakkaustoteutuksia valmiiksi, joten kun olet asentanut Zstandardin, pystyt heti työskentelemään Zstandardin avulla pakattujen tarballien kanssa. Tässä on yksinkertainen esimerkki, joka näyttää sen käytön tar:llä ja nopeuseron verrattuna gzip:iin:
$ time tar -I zstd -cf linux-4.6.4.tar.zst linux-4.6.4tar -I zstd -cf linux-4.6.4.tar.zst linux-4.6.4 3.15s user 0.50s system 107% cpu 3.396 total$ time tar -zcf linux-4.6.4.tar.gz linux-4.6.4tar -zcf linux-4.6.4.tar.gz linux-4.6.4 13.74s user 0.43s system 102% cpu 13.784 totalKomentorivikäytön lisäksi on olemassa API:t, jotka on dokumentoitu arkiston otsikkotiedostoissa (aloita täältä saadaksesi yleiskatsauksen API:ista). Mukana on myös zlib-yhteensopiva wrapper API (libWrapper) helpottaaksemme integrointia työkaluihin, joilla on jo zlib-rajapinnat. Lopuksi lisäämme useita esimerkkejä sekä peruskäytöstä että edistyneemmästä käytöstä, kuten sanakirjoista ja suoratoistosta, jotka löytyvät myös GitHub-arkistosta.
Lisää tulossa
Vaikka olemme saavuttaneet 1.0:n ja pidämme Zstandardia valmiina kaikenlaiseen tuotantokäyttöön, emme ole vielä valmiita. Tulevissa versioissa on tulossa:
- Monisäikeinen komentorivipakkaus entistäkin nopeampaan läpimenoon suurissa datajoukoissa, samanlainen kuin pigz-työkalu zlibille.
- Uudet pakkaustasot, molempiin suuntiin, jotka mahdollistavat entistäkin nopeamman pakkauksen ja suuremmat pakkaussuhteet.
- Yhteisön ylläpitämä valmiiksi määritetty joukko pakkaussanakirjoja yleisimmille datajoukoille, kuten JSON, HTML ja yleiset verkkoprotokollat.
Haluamme kiittää kaikkia koodin ja palautteen antajia, jotka auttoivat meitä pääsemään versioon 1.0. Tämä on vasta alkua. Tiedämme, että voidaksemme hyödyntää Zstandardin mahdollisuuksia tarvitsemme apuasi. Kuten edellä mainittiin, voit kokeilla Zstandardia jo tänään nappaamalla lähdekoodin tai valmiit binäärit GitHub-projektistamme tai, Mac-käyttäjille, asentamalla homebrew (brew install zstd):n kautta. Ottaisimme mielellämme vastaan kaikenlaista palautetta ja mielenkiintoisia käyttötapauksia, kuten myös lisäkielisidoksia ja apua sen integroimisessa suosikkiprojekteihisi avoimen lähdekoodin avulla.
Jalkahuomautuksia
- Vaikka häviötön tiedonpakkaus on tämän postauksen keskipiste, on olemassa myös siihen liittyvä, mutta hyvin erilainen häviöllinen tiedonpakkaus, jota käytetään ensisijaisesti kuviin, ääneen ja videokuvaukseen.
- Deflate, zlib, gzip – kolme nimeä, jotka ovat toisiinsa kietoutuneet. Deflate on algoritmi, jota zlib- ja gzip-toteutukset käyttävät. Zlib on Deflatea tarjoava kirjasto, ja gzip on komentorivityökalu, joka käyttää zlibiä datan deflatointiin sekä tarkistussummiin. Tämä tarkistussummaus voi aiheuttaa huomattavaa ylikuormitusta.
- Kaikki vertailuarvot suoritettiin 2,5 GHz:n kellotaajuudella toimivalla Intel E5-2678 v3:lla Centos 7 -koneessa. Komentorivityökalut (
zstdjagzip) rakennettiin järjestelmän GCC:llä, 4.8.5. Algoritmien vertailuarvot, jotka suoritettiin lzbenchillä, rakennettiin GCC:llä 6.
.
Vastaa