Tässä postauksessa tarkastelemme yleisimmin käytettyjä koneoppimisen algoritmeja. Niitä on valtavasti erilaisia, ja on helppo hämmentyä, kun kuulee sellaisia termejä kuin ”instanssipohjaiset oppimisalgoritmit” ja ”perceptron”.
Yleisesti kaikki koneoppimisalgoritmit jaetaan ryhmiin joko niiden oppimistyylin, toiminnon tai niiden ratkaisemien ongelmien perusteella. Tässä postauksessa esitellään oppimistyyliin perustuva luokittelu. Mainitsen myös yleisiä tehtäviä, joiden ratkaisemisessa nämä algoritmit auttavat.
Tänä päivänä käytettävien koneoppimisalgoritmien määrä on suuri, enkä mainitse niistä 100 %. Haluan kuitenkin antaa yleiskatsauksen yleisimmin käytetyistä.
- Valvotut oppimisalgoritmit
- Luokittelualgoritmit
- Naive Bayes
- Multinomial Naive Bayes
- Logistinen regressio
- Päätöspuut
- SVM (Support Vector Machine)
- Regressioalgoritmit
- Lineaarinen regressio
- Valvomattomat oppimisalgoritmit
- Klusterointi
- K-means-klusterointi
- K-nearest neighbor
- Dimensionaalisuuden vähentäminen
- Asosiaatiosääntöjen oppiminen
- Vahvistusoppiminen
- Q-oppiminen
- Ensemble-oppiminen
- Bagging
- Boosting
- Satunnaismetsä
- Stacking
- Neuraaliverkot
- Johtopäätös
Valvotut oppimisalgoritmit

Jos sinulle eivät ole tuttuja sellaiset termit kuin ”valvottu oppiminen” ja ”valvomaton oppiminen”, tutustu tekoälyä vs. ML-tietokoneoppimista käsittelevään postaukseemme, jossa tätä aihetta käsitellään yksityiskohtaisesti. Tutustutaan nyt algoritmeihin.
Luokittelualgoritmit
Naive Bayes

Bayesin luokittelualgoritmit ovat ML:ssä käytettävien todennäköisyysluokittelijoiden perhettä, joka perustuu Bayesin lauseen soveltamiseen.
Naive Bayesin luokittelija oli yksi ensimmäisistä koneoppimisessa käytetyistä algoritmeista. Se soveltuu binääri- ja moniluokkaiseen luokitteluun, ja sen avulla voidaan tehdä ennusteita ja ennustaa tietoja historiallisten tulosten perusteella. Klassinen esimerkki on roskapostin suodatusjärjestelmät, jotka käyttivät Naive Bayes -luokitusta vuoteen 2010 asti ja osoittivat tyydyttäviä tuloksia. Kun Bayesin myrkytys keksittiin, ohjelmoijat alkoivat kuitenkin miettiä muita tapoja suodattaa dataa.
Bayesin teoreeman avulla voidaan kertoa, miten jonkin tapahtuman esiintyminen vaikuttaa toisen tapahtuman todennäköisyyteen.
Tämä algoritmi laskee esimerkiksi tyypillisten sanojen perusteella todennäköisyyden sille, että tietty sähköpostiviesti on roskapostia tai ei ole. Yleisiä roskapostisanoja ovat ”tarjous”, ”tilaa nyt” tai ”lisätulot”. Jos algoritmi havaitsee nämä sanat, on suuri todennäköisyys, että sähköposti on roskapostia.
Naive Bayes olettaa, että ominaisuudet ovat riippumattomia. Siksi algoritmia kutsutaan naiiviksi.
Multinomial Naive Bayes
Naive Bayes -luokittelijan lisäksi tässä ryhmässä on muitakin algoritmeja. Esimerkiksi Multinomial Naive Bayes, jota käytetään yleensä asiakirjojen luokitteluun tiettyjen asiakirjassa esiintyvien sanojen esiintymistiheyden perusteella.
Bayesin algoritmeja käytetään edelleen tekstien luokitteluun ja petosten havaitsemiseen. Niitä voidaan soveltaa myös konenäköön (esimerkiksi kasvojen havaitsemiseen), markkinoiden segmentointiin ja bioinformatiikkaan.
Logistinen regressio
Na vaikka nimi saattaa tuntua vasta-intuitiiviselta, logistinen regressio on itse asiassa eräänlainen luokittelualgoritmi.
Logistinen regressio on malli, joka tekee ennusteita käyttämällä logistista funktiota ulostulomuuttujan ja syötemuuttujan väliseen riippuvuuteen. Statquest teki hienon videon, jossa he selittävät lineaarisen ja logistisen regression eron käyttäen esimerkkinä lihavia hiiriä.
Päätöspuut
Päätöspuu on yksinkertainen tapa visualisoida päätöksentekomalli puun muodossa. Päätöspuiden etuna on, että niitä on helppo ymmärtää, tulkita ja visualisoida. Lisäksi ne vaativat vain vähän vaivaa tietojen valmisteluun.
Mutta niillä on myös suuri haittapuoli. Päätöksentekopuut voivat olla epävakaita datan pienimmänkin vaihtelun (varianssin) vuoksi. On myös mahdollista luoda liian monimutkaisia puita, jotka eivät yleisty hyvin. Tätä kutsutaan ylisovittamiseksi. Säkitys, tehostaminen ja regularisointi auttavat torjumaan tätä ongelmaa. Puhumme niistä myöhemmin tässä postauksessa.
Kaiken päätöspuun elementit ovat:
- Juurisolmu, joka esittää pääkysymyksen. Siitä lähtevät nuolet osoittavat alaspäin, mutta siihen ei osoiteta nuolia. Kuvittele esimerkiksi, että rakennat puun, jonka avulla päätät, millaista pastaa otat päivälliseksi.
- Haarat. Puun osa-aluetta kutsutaan oksaksi tai joskus alipuuksi.
- Päätöksentekosolmut. Nämä ovat juurisolmun alasolmuja, jotka voivat myös jakautua useampaan solmuun. Päätöksentekosolmut voivat olla ”carbonara?” tai ”sienien kanssa?”.
- Lehti- tai päätesolmut. Nämä solmut eivät jakaudu. Ne edustavat lopullisia päätöksiä tai ennusteita.
On myös tärkeää mainita jakaminen. Tällä tarkoitetaan solmun jakamista alasolmuihin. Esimerkiksi jos et ole kasvissyöjä, carbonara on ok. Mutta jos olet, syö pastaa sienien kanssa. On myös olemassa solmujen poistoprosessi, jota kutsutaan karsimiseksi.
Päätöksentekopuualgoritmeista käytetään nimitystä CART (Classification and Regression Trees). Päätöspuut voivat toimia kategorisen tai numeerisen datan kanssa.
- Regressiopuita käytetään, kun muuttujilla on numeerinen arvo.
- Luokittelupuita voidaan käyttää, kun data on kategorista (luokat).
Päätöspuut ovat melko intuitiivisia ymmärtää ja käyttää. Siksi puukaavioita käytetään yleisesti useilla eri toimialoilla ja tieteenaloilla. GreyAtom tarjoaa laajan katsauksen erityyppisiin päätöspuihin ja niiden käytännön sovelluksiin.
SVM (Support Vector Machine)
Tukivektorikoneet (Support Vector Machines)
Tukivektorikoneet (Support Vector Machines) ovat toinen ryhmä algoritmeja, joita käytetään luokittelu- ja joskus myös regressiotehtäviin. SVM on loistava, koska se antaa melko tarkkoja tuloksia minimaalisella laskentateholla.
SVM:n tavoitteena on löytää N-ulotteisesta avaruudesta (jossa N vastaa piirteiden lukumäärää) hypertaso, joka luokittelee datapisteet selvästi. Tulosten tarkkuus korreloi suoraan valitun hypertason kanssa. Meidän pitäisi löytää taso, jolla on suurin etäisyys molempien luokkien datapisteiden välillä.
Tämä hypertaso esitetään graafisesti viivana, joka erottaa yhden luokan toisesta. Datapisteet, jotka osuvat hypertason eri puolille, liitetään eri luokkiin.
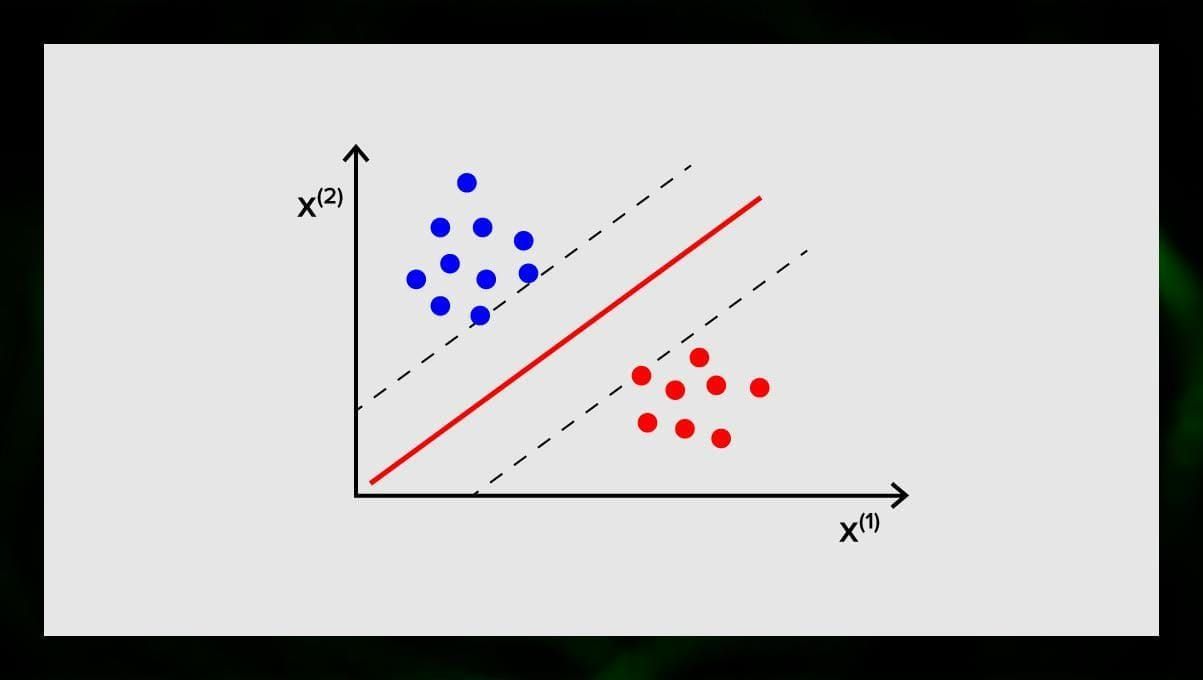
Huomaa, että hypertason ulottuvuus riippuu piirteiden määrästä. Jos syötettävien piirteiden määrä on 2, hypertaso on vain viiva. Jos syötettävien piirteiden määrä on 3, niin hypertasosta tulee kaksiulotteinen taso. Mallin piirtäminen kuvaajaan käy vaikeaksi, kun piirteiden määrä on yli 3. Joten tässä tapauksessa käytetään Kernel-tyyppejä muuttamaan se 3-ulotteiseksi avaruudeksi.
Miksi tätä kutsutaan tukivektorikoneeksi? Tukivektorit ovat datapisteitä, jotka ovat lähimpänä hypertasoa. Ne vaikuttavat suoraan hypertason sijaintiin ja orientaatioon, ja niiden avulla voimme maksimoida luokittelijan marginaalin. Tukivektoreiden poistaminen muuttaa hypertason sijaintia. Nämä pisteet auttavat meitä rakentamaan SVM:n.
SVM:ää käytetään nykyään aktiivisesti lääketieteellisessä diagnostiikassa poikkeavuuksien löytämiseksi, ilmanlaadun valvontajärjestelmissä, rahoitusanalyyseissä ja ennusteissa pörssissä sekä koneiden vianvalvonnassa teollisuudessa.
Regressioalgoritmit
Regressioalgoritmit ovat käyttökelpoisia analytiikassa, kun esimerkiksi yritetään ennustaa arvopapereiden kustannuksia tai tietyn tuotteen myyntiä tiettynä ajankohtana.
Lineaarinen regressio
Lineaarisella regressiolla yritetään mallintaa muuttujien välistä suhdetta sovittamalla lineaarinen yhtälö havaittuihin tietoihin.
On selittäviä ja riippuvia muuttujia. Riippuvat muuttujat ovat asioita, joita haluamme selittää tai ennustaa. Selittävät, kuten nimestä seuraa, selittävät jotain. Jos haluat rakentaa lineaarisen regression, oletat, että riippuvien ja riippumattomien muuttujien välillä on lineaarinen suhde. Esimerkiksi talon neliömetrien ja sen hinnan tai alueen asukastiheyden ja kebabpaikkojen välillä on korrelaatio.
Kun oletat tuon oletuksen, sinun on seuraavaksi selvitettävä konkreettinen lineaarinen suhde. Sinun on löydettävä lineaarinen regressioyhtälö aineistolle. Viimeinen vaihe on laskea residuaali.
Huomautus: Kun regressio piirtää suoran viivan, sitä kutsutaan lineaariseksi, kun se on käyrä – polynomiksi.
Valvomattomat oppimisalgoritmit

Keskustellaanpa nyt algoritmeista, jotka pystyvät etsimään piileviä malleja merkitsemättömästä aineistosta.
Klusterointi
Klusterointi tarkoittaa, että jaamme syötteet ryhmiin sen mukaan, kuinka samankaltaisia ne ovat keskenään. Klusterointi on yleensä yksi vaihe monimutkaisemman algoritmin rakentamisessa. On yksinkertaisempaa tutkia jokaista ryhmää erikseen ja rakentaa malli niiden ominaisuuksien perusteella kuin käsitellä kaikkea kerralla. Samaa tekniikkaa käytetään jatkuvasti markkinoinnissa ja myynnissä kaikkien potentiaalisten asiakkaiden jakamiseksi ryhmiin.
Erittäin yleisiä klusterointialgoritmeja ovat k-means-klusterointi ja k-nearest neighbor.
K-means-klusterointi
K-means-klusterointi jakaa vektoriavaruuden elementtien joukon ennalta määrättyyn määrään klustereita k. Väärä määrä klustereita kuitenkin mitätöi koko prosessin, joten on tärkeää kokeilla sitä vaihtelevilla klusterimäärillä. K-means-algoritmin pääidea on, että data jaetaan satunnaisesti klustereihin, minkä jälkeen kunkin edellisessä vaiheessa saadun klusterin keskipiste lasketaan iteratiivisesti uudelleen. Sitten vektorit jaetaan uudelleen klustereihin. Algoritmi pysähtyy, kun jossain vaiheessa klustereissa ei tapahdu muutosta iteraation jälkeen.
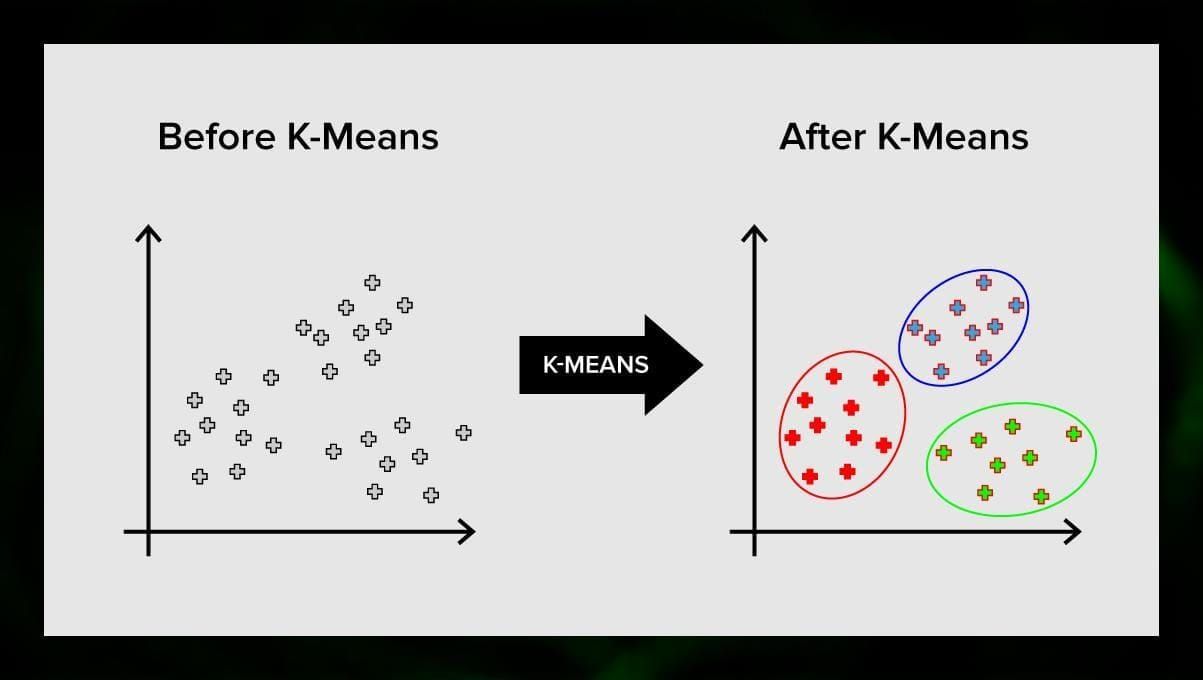
Menetelmää voidaan soveltaa ongelmien ratkaisemiseen silloin, kun klusterit ovat toisistaan erillisiä tai ne voidaan helposti erottaa toisistaan, eikä aineisto ole päällekkäistä.
K-nearest neighbor
kNN on lyhenne englanninkielisistä sanoista k-nearest neighbor. Tämä on yksi yksinkertaisimmista luokittelualgoritmeista, jota käytetään joskus regressiotehtävissä.
Luokittelijan kouluttamiseksi tarvitaan joukko dataa, jossa on ennalta määritellyt luokat. Luokitus tehdään manuaalisesti, johon osallistuu tutkittavan alan asiantuntijoita. Tämän algoritmin avulla voidaan työskennellä useiden luokkien kanssa tai selvittää tilanteet, joissa syötteet kuuluvat useampaan kuin yhteen luokkaan.
Menetelmä perustuu oletukseen, että samankaltaiset merkinnät vastaavat läheisiä kohteita attribuuttivektoriavaruudessa.
Nykyaikaiset ohjelmistojärjestelmät käyttävät kNN:ää visuaaliseen hahmontunnistukseen, esimerkiksi ostoskärryn alaosaan piilotettujen pakettien skannaamiseen ja havaitsemiseen kassajonon yhteydessä (esim. AmazonGo). K-nearest neighboria käytetään myös pankkitoiminnassa havaitsemaan kuvioita luottokortin käytössä. kNN-algoritmit analysoivat kaiken datan ja havaitsevat epätavalliset kuviot, jotka viittaavat epäilyttävään toimintaan.
Dimensionaalisuuden vähentäminen
Pääkomponenttianalyysi (Principal Component Analysis, PCA) on tärkeä tekniikka, joka on ymmärrettävä ML:ään liittyvien ongelmien tehokkaassa ratkaisemisessa.
Kuvittele, että sinulla on paljon muuttujia, jotka sinun on otettava huomioon. Sinun on esimerkiksi klusteroitava kaupungit kolmeen ryhmään: hyvä asua, huono asua ja välttävä. Kuinka monta muuttujaa sinun on otettava huomioon? Todennäköisesti paljon. Ymmärrätkö niiden väliset suhteet? En oikeastaan. Miten voit siis ottaa kaikki keräämäsi muuttujat ja keskittyä vain muutamaan niistä, jotka ovat tärkeimpiä?
Teknisessä mielessä haluat ”pienentää ominaisuusavaruuden ulottuvuutta”. Pienentämällä piirreavaruutesi ulottuvuutta onnistut saamaan vähemmän muuttujien välisiä suhteita huomioon otettavaksi ja olet vähemmän todennäköisesti ylisovittamassa malliasi.
On monia tapoja saavuttaa ulottuvuuden pienentäminen, mutta suurin osa näistä tekniikoista kuuluu jompaankumpaan kahteen luokkaan:
- Ominaisuuksien eliminointi;
- Ominaisuuksien louhinta.
Ominaisuuksien eliminoinnilla tarkoitetaan sitä, että pienennät ominaisuuksien määrää eliminoimalla joitakin niistä. Tämän menetelmän etuna on, että se on yksinkertainen ja säilyttää muuttujien tulkittavuuden. Haittapuolena on tosin se, että saat nolla informaatiota muuttujista, jotka olet päättänyt poistaa.
Erillisominaisuuksien louhinta välttää tämän ongelman. Tätä menetelmää sovellettaessa tavoitteena on poimia joukko piirteitä annetusta tietokokonaisuudesta. Piirteiden uuttamisella pyritään vähentämään piirteiden määrää tietokokonaisuudessa luomalla uusia piirteitä olemassa olevien piirteiden perusteella (ja hylkäämällä sitten alkuperäiset piirteet). Uusi pelkistetty piirrejoukko on luotava siten, että se pystyy tiivistämään suurimman osan alkuperäisen piirrejoukon sisältämästä informaatiosta.
Pääkomponenttianalyysi on piirteiden louhinta-algoritmi. se yhdistelee syötemuuttujia tietyllä tavalla, minkä jälkeen on mahdollista pudottaa pois ”vähiten tärkeät” muuttujat, mutta säilyttää silti arvokkaimmat osat kaikista muuttujista.
Yksi PCA:n mahdollisista käyttökohteista on se, että tietokokonaisuuteen sisältyvistä kuvista muodostuu liian suuri joukko. Pelkistetty ominaisuuksien esitys auttaa selviytymään nopeasti kuvien yhteensovittamisen ja haun kaltaisista tehtävistä.
Asosiaatiosääntöjen oppiminen
Apriori on yksi suosituimmista assosiaatiosääntöjen hakualgoritmeista. Se pystyy käsittelemään suuria määriä dataa suhteellisen pienessä ajassa.
Juttu on niin, että monien projektien tietokannat ovat nykyään hyvin suuria, jopa gigatavuja ja teratavuja. Ja ne kasvavat edelleen. Siksi tarvitaan tehokas, skaalautuva algoritmi assosiatiivisten sääntöjen löytämiseksi lyhyessä ajassa. Apriori on yksi näistä algoritmeista.
Voidakseen soveltaa algoritmia, on tarpeen valmistella tiedot, muuntaa ne kaikki binääriseen muotoon ja muuttaa niiden tietorakennetta.
Vakiintuneesti tätä algoritmia käytetään tietokannassa, joka sisältää suuren määrän transaktioita, esimerkiksi tietokannassa, joka sisältää tietoja kaikista tuotteista, joita asiakkaat ovat ostaneet supermarketissa.
Vahvistusoppiminen

Vahvistusoppiminen on yksi koneoppimisen menetelmistä, jonka avulla koneelle opetetaan, miten se toimii vuorovaikutuksessa tietyn ympäristön kanssa. Tällöin ympäristö (esimerkiksi videopelissä) toimii opettajana. Se antaa palautetta tietokoneen tekemille päätöksille. Tämän palkkion perusteella kone oppii valitsemaan parhaan toimintatavan. Se muistuttaa tapaa, jolla lapset oppivat olemaan koskematta kuumaan paistinpannuun – kokeilun ja kivun kokemisen kautta.
Purettaessa tämä prosessi alaspäin se sisältää seuraavat yksinkertaiset vaiheet:
- Tietokone tarkkailee ympäristöä;
- valitsee jonkin strategian;
- toimii tämän strategian mukaisesti;
- saa joko palkkion tai rangaistuksen;
- oppii tästä kokemuksesta ja tarkentaa strategiaa;
- toistaa, kunnes optimaalinen strategia on löydetty.
Q-oppiminen
Vahvistusoppimiseen voidaan käyttää paria algoritmia. Yksi yleisimmistä on Q-oppiminen.
Q-oppiminen on malliton vahvistusoppimisalgoritmi. Q-oppiminen perustuu ympäristöstä saatuun korvaukseen. Agentti muodostaa hyötyfunktion Q, joka myöhemmin antaa sille mahdollisuuden valita käyttäytymisstrategian ja ottaa huomioon kokemuksen aiemmista vuorovaikutuksista ympäristön kanssa.
Yksi Q-oppimisen eduista on se, että se pystyy vertailemaan käytettävissä olevien toimintojen odotettua hyödyllisyyttä ilman ympäristön mallien muodostamista.
Ensemble-oppiminen

Ensemble-oppiminen on menetelmä, jossa ongelma ratkaistaan rakentamalla useita ML-malleja ja yhdistämällä niitä. Ensemble-oppimista käytetään ensisijaisesti luokittelu-, ennuste- ja funktion approksimointimallien suorituskyvyn parantamiseen. Muita ensemble-oppimisen sovelluksia ovat esimerkiksi mallin tekemän päätöksen tarkistaminen, optimaalisten ominaisuuksien valitseminen mallien rakentamista varten, inkrementaalinen oppiminen ja epästationaarinen oppiminen.
Alhaalla on lueteltu joitakin yleisempiä ensemble-oppimisalgoritmeja.
Bagging
Bagging tarkoittaa bootstrap-aggregointia. Se on yksi varhaisimmista ensemble-algoritmeista, ja sen suorituskyky on yllättävän hyvä. Luokittelijoiden monimuotoisuuden takaamiseksi käytetään bootstrapattuja jäljennöksiä harjoitusaineistosta. Tämä tarkoittaa sitä, että eri harjoitusdatan osajoukot poimitaan satunnaisesti – korvaavasti – harjoitusaineistosta. Kunkin koulutusdatan osajoukon avulla koulutetaan erilainen samantyyppinen luokittelija. Sitten yksittäiset luokittelijat voidaan yhdistää. Tätä varten niiden päätöksistä on tehtävä yksinkertainen enemmistöäänestys. Luokittelijoiden enemmistön antama luokka on ensemble-päätös.
Boosting
Tämä ensemble-algoritmien ryhmä on samanlainen kuin bagging. Boosting käyttää myös erilaisia luokittelijoita datan uudelleennäytteenottoon ja valitsee sitten optimaalisen version enemmistöäänestyksellä. Boostingissa koulutetaan iteratiivisesti heikkoja luokittelijoita, jotta niistä saadaan koottua vahva luokittelija. Kun luokittimia lisätään, niille annetaan yleensä joitakin painoja, jotka kuvaavat niiden ennusteiden tarkkuutta. Kun kokonaisuuteen on lisätty heikko luokittelija, painot lasketaan uudelleen. Väärin luokitellut syötteet saavat lisää painoa, ja oikein luokitellut tapaukset menettävät painoa. Näin järjestelmä keskittyy enemmän esimerkkeihin, joissa saatiin virheellinen luokitus.
Satunnaismetsä
Satunnaismetsät tai satunnaiset päätösmetsät ovat ensemble-oppimismenetelmä luokitteluun, regressioon ja muihin tehtäviin. Satunnaismetsän rakentamiseksi on koulutettava lukuisia päätöspuita satunnaisnäytteillä harjoitusdatasta. Satunnaismetsän tuotos on yksittäisten puiden joukossa yleisin tulos. Satunnaiset päätösmetsät torjuvat menestyksekkäästi ylisovittamista algoritmin _sattumanvaraisen_luonteen vuoksi.
Stacking
Stacking on ensemble-oppimistekniikka, jossa yhdistetään useita luokitus- tai regressiomalleja metaluokittelijan tai metaregressorin avulla. Perustason mallit koulutetaan täydellisen harjoitusjoukon perusteella, minkä jälkeen metamalli koulutetaan perustason mallien tuotoksilla ominaisuuksina.
Neuraaliverkot
Neuraaliverkko on synapseilla toisiinsa kytkettyjen neuronien sarja, joka muistuttaa ihmisen aivojen rakennetta. Ihmisen aivot ovat kuitenkin vielä monimutkaisemmat.
Neuraaliverkoissa on hienoa se, että niitä voidaan käyttää periaatteessa mihin tahansa tehtävään roskapostin suodattamisesta tietokonenäköön. Tavallisesti niitä kuitenkin käytetään konekääntämiseen, poikkeavuuksien havaitsemiseen ja riskienhallintaan, puheentunnistukseen ja kielen tuottamiseen, kasvojen tunnistamiseen ja muuhun.
Neuraaliverkko koostuu neuroneista eli solmuista. Jokainen näistä neuroneista vastaanottaa dataa, käsittelee sitä ja siirtää sen sitten toiselle neuronille.
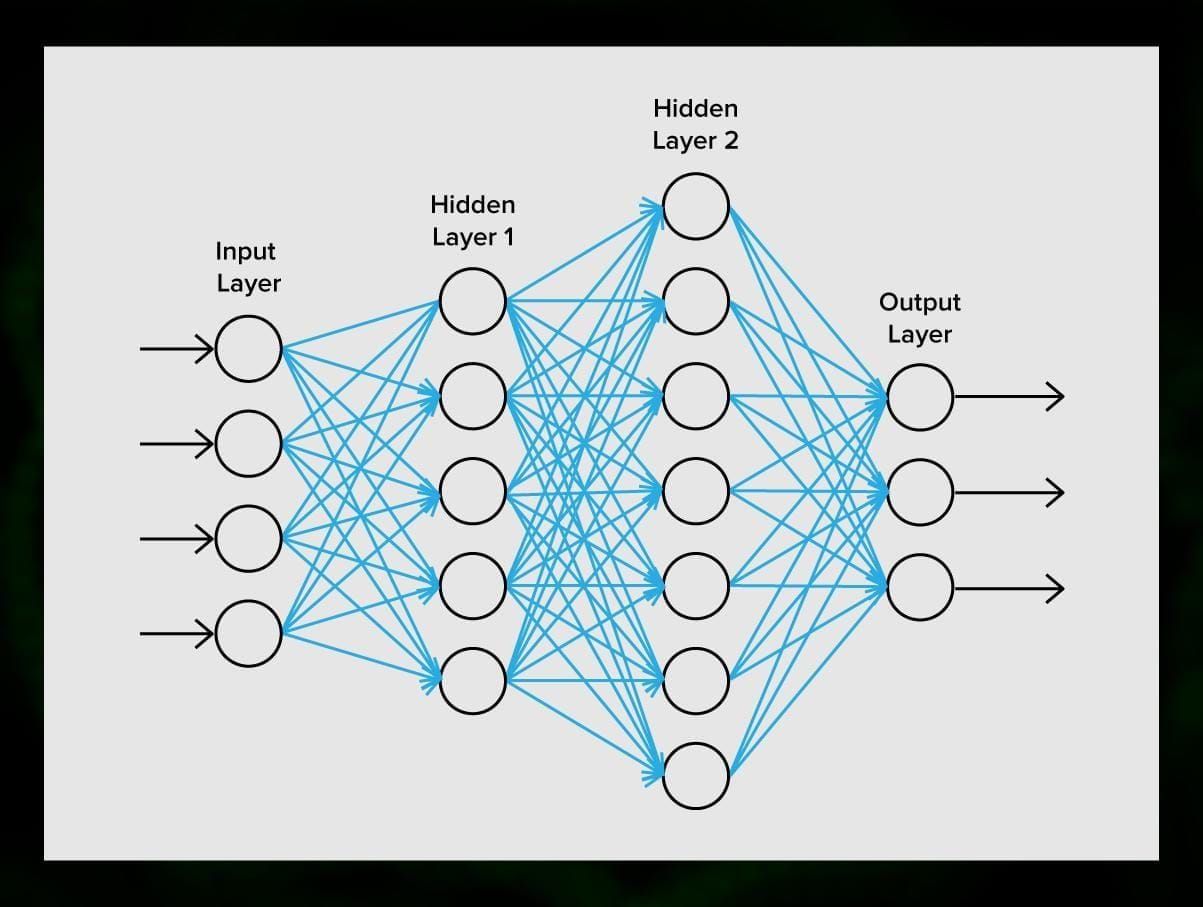
Kaikki neuronit käsittelevät signaalit samalla tavalla. Mutta miten sitten saadaan erilainen tulos? Siitä vastaavat neuroneita toisiinsa yhdistävät synapsit. Jokaisella neuronilla voi olla useita synapseja, jotka vaimentavat tai vahvistavat signaalia. Neuronit pystyvät myös muuttamaan ominaisuuksiaan ajan myötä. Valitsemalla oikeat synapsiparametrit, pystymme saamaan oikeat tulokset syötetyn informaation muuntamisesta ulostulossa.
Neuraalisia neuroverkkoja on monia eri tyyppejä:
- Feedforward neural networks (FF tai FFNN) ja perceptronit § ovat hyvin suoraviivaisia, verkossa ei ole silmukoita tai syklejä. Käytännössä tällaisia verkkoja käytetään harvoin, mutta niitä yhdistetään usein muihin tyyppeihin uusien verkkojen saamiseksi.
- Hopfield-verkko (HN) on täysin kytketty neuroverkko, jossa on symmetrinen linkkimatriisi. Tällaista verkkoa kutsutaan usein assosiatiivisen muistin verkoksi. Aivan kuten henkilö, joka näkee pöydän toisen puoliskon, voi kuvitella toisen puoliskon, tämä verkko, joka saa meluisan pöydän, palauttaa sen täyteen.
- Konvolutiiviset neuroverkot (CNN) ja syvät konvolutiiviset neuroverkot (Deep Convolutional Neural Networks, DCNN) eroavat hyvin paljon muista verkkotyypeistä. Niitä käytetään yleensä kuvankäsittelyyn, ääneen tai videoon liittyvissä tehtävissä. Tyypillinen tapa soveltaa CNN:ää on kuvien luokittelu.
Monia erilaisia neuroverkkotyyppejä on mielenkiintoista tarkastella. Se on mahdollista tehdä NN-eläintarhassa.
Johtopäätös
Tämä postaus on laaja katsaus erilaisiin ML-algoritmeihin, mutta vielä on paljon sanottavaa. Pysy kuulolla Twitterissämme, Facebookissamme ja Mediumissa saadaksesi lisää oppaita ja postauksia koneoppimisen jännittävistä mahdollisuuksista.
Vastaa